






封装
import sys
# 将上级目录中的embedding和database两个子目录添加到系统路径中,以便可以导入其中的模块
sys.path.append("../embedding")
sys.path.append("../database")
import os
# 从database目录的create_db模块导入create_db和load_knowledge_db函数
from database.create_db import create_db, load_knowledge_db
# 从embedding目录的call_embedding模块导入get_embedding函数
from embedding.call_embedding import get_embedding
# 数据库文件存储路径
DEFAULT_DB_PATH = "../database/knowledge_db"
# 存储向量数据库生成的向量数据
DEFAULT_PERSIST_PATH = "../database/vector_data_base"
# 定义一个函数用于获取或创建向量数据库对象
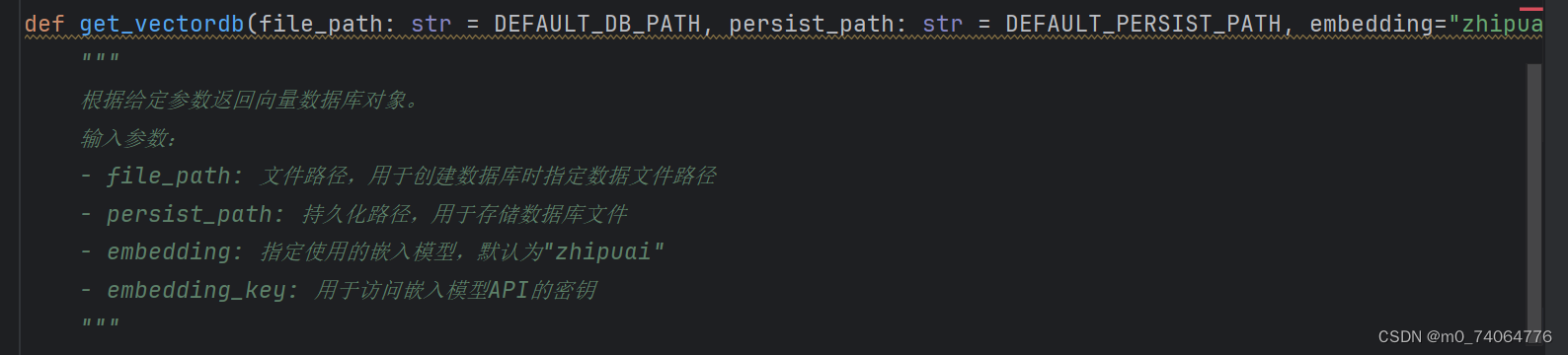
def get_vectordb(file_path: str = DEFAULT_DB_PATH, persist_path: str = DEFAULT_PERSIST_PATH, embedding="zhipuai", embedding_key: str = "7cf22af17f2d01144caf46eda1550b1e.hu1OH9O4YeKTWlgM"):
"""
根据给定参数返回向量数据库对象。
输入参数:
- file_path: 文件路径,用于创建数据库时指定数据文件路径
- persist_path: 持久化路径,用于存储数据库文件
- embedding: 指定使用的嵌入模型,默认为"zhipuai"
- embedding_key: 用于访问嵌入模型API的密钥
"""
# 根据指定的embedding类型和API密钥获取embedding对象
embedding = get_embedding(embedding=embedding, embedding_key=embedding_key)
# 检查指定的持久化路径是否存在
if os.path.exists(persist_path):
contents = os.listdir(persist_path)
# 如果路径存在但目录为空
if len(contents) == 0:
# 创建数据库,并加载知识库到向量数据库对象
vectordb = create_db(file_path, persist_path, embedding)
vectordb = load_knowledge_db(persist_path, embedding)
else:
# 如果目录不为空,直接从持久化路径加载向量数据库对象
vectordb = load_knowledge_db(persist_path, embedding)
else:
# 如果指定的持久化路径不存在,从头开始创建向量数据库
vectordb = create_db(file_path, persist_path, embedding)
vectordb = load_knowledge_db(persist_path, embedding)
return vectordb


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









