







java第十四章:集合
java第十四章:集合
集合框架体系图
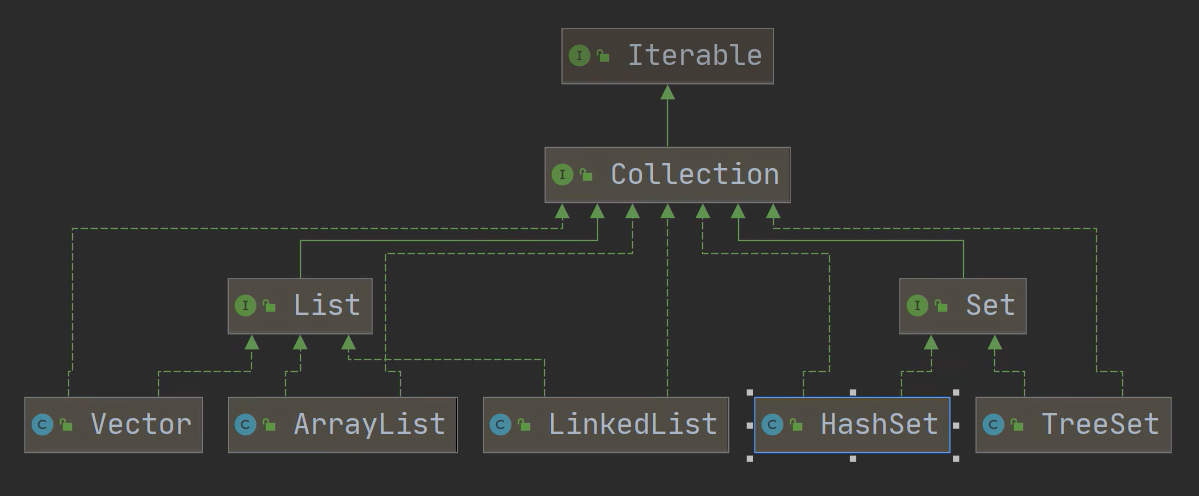
单列集合继承图
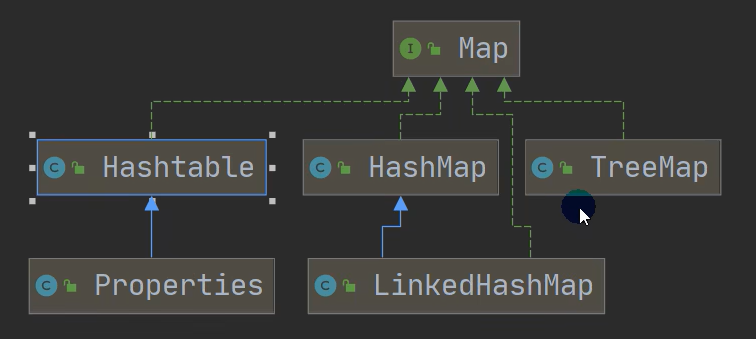
双列集合继承图
集合框架体系解读
1.集合主要是两组:
1):单列集合
2):双列集合
2.Collectin 接口有两个重要的子接口 List Set ,他们的实现子类都是单列集合
3.Map 接口的实现子类 是双列集合,存放的 K-V
ArrayList arrayList = new ArrayList();
arrayList.add("jack");
HashMap hashMap = new HashMap();
hashMap.put("NO1","北京");
Collection接口基本介绍
1.Collection实现子类可以存放多个元素,每个元素可以是Object
2.有些Collection的实现类,可以存放重复的元素,有些不可以
3.有些Collection的实现类,有些是有序的(List),有些是无序的(Set)
4.Collection接口没有直接的实现子类,是通过它的子接口Set和List来实现的
Collection接口常用方法
CRUD
- add
- remove
- contains
- size
- clear
- isEmpty
- addAll
- removeAll
- containsAll
package com.lcz.collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
/**
* @author lcz
* @version 1.0
* 关于:
* CRUD
* - add
* - remove
* - contains
* - size
* - clear
* - isEmpty
* - addAll
* - removeAll
* - containsAll
*/
@SuppressWarnings({"all"})
public class Collection_ {
public static void main(String[] args) {
List list = new ArrayList();
list.add(1);
list.add("sadfsa");
list.add(new Integer(10));
System.out.println(list.contains(1));
list.remove(1);
System.out.println(list.size());
System.out.println(list);
list.clear();
System.out.println(list);
System.out.println(list.isEmpty());
List list1 = new ArrayList();
list1.add('s');
list1.add("sdafs");
list.add(new Integer(100));
list.addAll(0,list1);
System.out.println(list);
list.containsAll(list1);
list.removeAll(list1);
System.out.println(list);
}
}
遍历集合的三种方式
Iterator(迭代器)
基本介绍
1.Iterator对象称为迭代器,主要用于遍历 Collection 集合中的元素
2.所有实现了Collection接口的集合类都有一个iterator()方法,用于返回一个实现了Iterator接口的对象,即可以返回一个迭代器
3.Iterator 仅用于遍历集合,本身并不存放对象
执行原理

增强for:简化版迭代器
普通for
//遍历集合三种方式
//(1):迭代器
//快捷键ii
System.out.println("===迭代器===");
Iterator iterator = list.iterator();
while (iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
}
//(2):增强for:底层仍调用迭代器,所以为简化版迭代器
//快捷键I
System.out.println("===增强for===");
for(Object obj:list){
System.out.println(obj);
}
//(3):普通for
//快捷键fori
System.out.println("===普通for===");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
List接口基本介绍
List接口是Collection接口的子接口
1.List集合类中元素有序(即添加顺序 和 取出顺序一致)、且可重复
2.List集合类支持索引
3.List接口的实现类:LinkedList、ArrayList、Vector
List接口常用方法
CRUD
- add(int index,Object ele)
- addAll(int index,Collection eles)
- get(int index)
- indexOf(Object obj)
- lastIndexOf(Object obj)
- remove(int index)
- set(int index,Object ele)
- subList(int fromIndex,int toIndex):返回从fromIndex到toIndex位置的 子集合
list.set(0,90);
System.out.println(list);
System.out.println(list.get(0));
System.out.println(list.indexOf(90));
list.add("sadfsadf");
list.add('c');
list.add(1,50);
System.out.println(list);
System.out.println(list.subList(0,2));
List三种遍历方式
-
迭代器
-
增强for
-
普通for
List排序

package com.lcz.collection;
import com.sun.javafx.fxml.expression.UnaryExpression;
import java.util.ArrayList;
import java.util.List;
/**
* @author lcz
* @version 1.0
* 关于:
* List接口的实现类进行排序并输出
*/
public class List_01 {
public static void main(String[] args) {
List list = new ArrayList();
list.add(new Book("西游记",10));
list.add(new Book("西游",9));
list.add(new Book("西游记降魔",12));
list.add(new Book("西游记3",11));
System.out.println("===未排序===");
for (Object o :list) {
System.out.println(o);
}
bubbleSort(list);
System.out.println("===按价格从低到高排序===");
for (Object o :list) {
System.out.println(o);
}
}
public static void bubbleSort(List list){
for (int i = 0; i < list.size(); i++) {
for (int j = 0; j < list.size() - 1 - i; j++) {
Book book1 = (Book) list.get(j);
Book book2 = (Book) list.get(j+1);
if(book1.getPrice() > book2.getPrice()){
list.set(j,book2);
list.set(j+1,book1);
}
}
}
}
}
class Book{
private String name;
private double price;
public Book(String name, double price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "名称:" + name + "\t" + "价格:" + price;
}
}
ArrayList类
ArrayList注意事项
1.ArrayList允许加入所有元素,包括null,且可多个null
2.ArrayList是由数组来实现数据存储的
3.ArrayList基本等同于Vector,但ArrayList存在线程安全问题(执行效率高),
多线程情况,不建议使用ArrayList
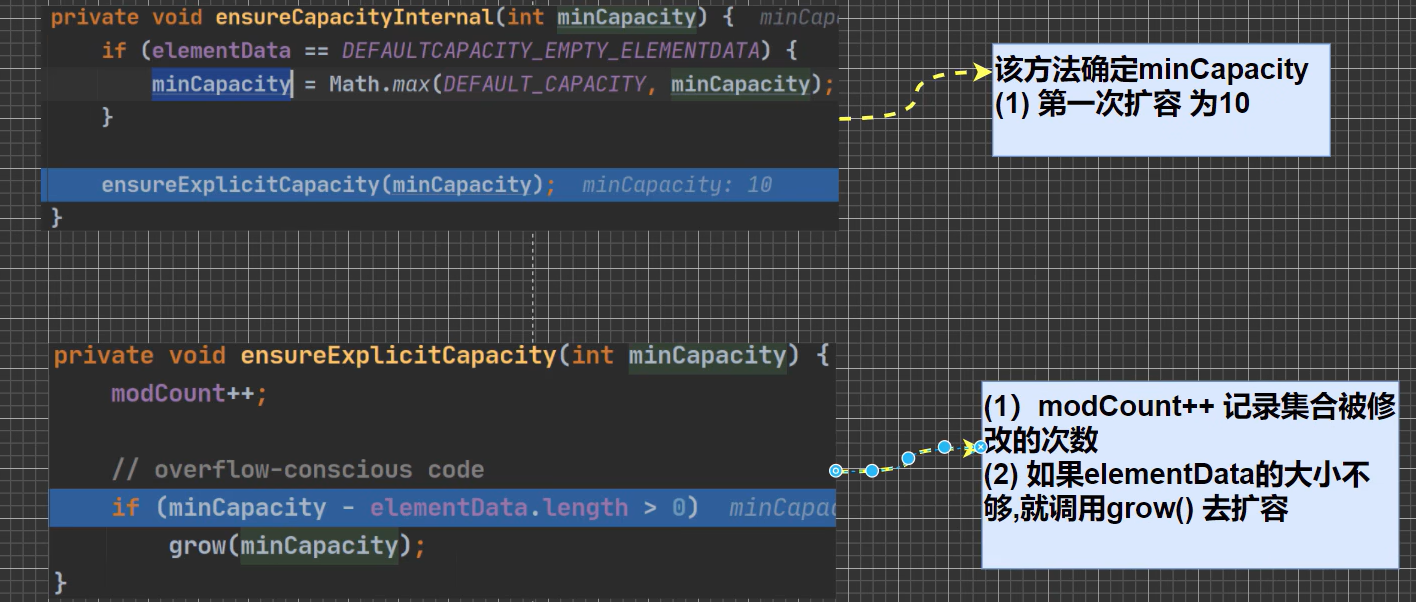
ArrayList底层结构和源码分析
结论



debug详细信息显示设置

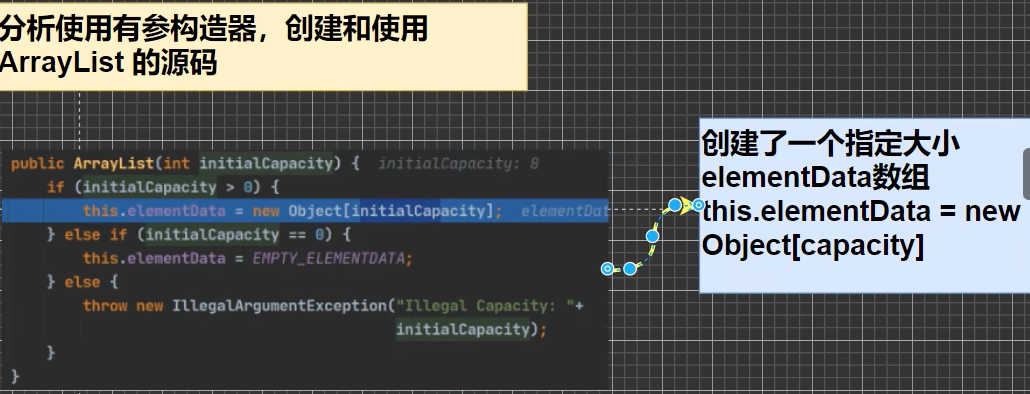
有参构造器创建对象

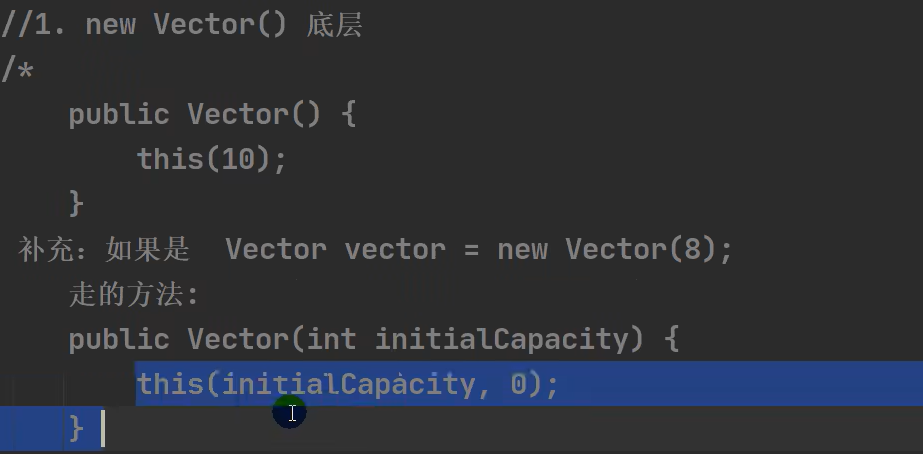
Vector类
基本介绍
1.底层也是一个对象数组
2.Vector是线程同步的,即线程安全,Vector类的操作方法带有synchronized
Vector和ArrayList的比较

源码分析

LinkedList类
基本介绍
1.底层实现了双向链表和双端队列特点
2.可以添加任意元素(元素可以重复),包括null
3.线程不安全,没有实同步
底层操作机制
1.底层维护了一个双向链表
2.LinkedList中维护了两个属性first、last分别指向首结点和尾结点
3.每个结点(Node对象),里面又维护了prev、next、item三个属性
4,所以LinkedList的元素的添加和删除,不是通过数组完成的,相对来说效率较高
模拟一个双向链表
package com.lcz.collection.list;
/**
* @author lcz
* @version 1.0
*
*需求:
* 模拟一个双向链表
*/
public class LinkedList_ {
public static void main(String[] args) {
Node node = new Node(1);
Node node1 = new Node(2);
Node node2 = new Node(3);
node.next = node1;
node1.next = node2;
node1.prev = node;
node2.prev = node1;
Node first = node;
Node last = node2;
//从头到尾进行遍历
System.out.println("从头到尾进行遍历");
while (first != null){
System.out.println(first.item);
first = first.next;
}
//从尾到头进行遍历
System.out.println("从尾到头进行遍历");
while (last != null){
System.out.println(last.item);
last = last.prev;
}
//插入一个新节点到node1和node2之间
System.out.println("插入一个node3:dsaf到node1:2和node2:3之间");
Node node3 = new Node("dsaf");
node3.prev = node1;
node3.next = node2;
node1.next = node3;
node2.prev = node3;
first = node;
last = node2;
while (first != null){
System.out.println(first.item);
first = first.next;
}
}
}
class Node{
public Node prev;
public Node next;
public Object item;
public Node(Object item) {
this.item = item;
}
public Object getItem() {
return item;
}
public void setItem(Object item) {
this.item = item;
}
@Override
public String toString() {
return "Node{" +
"item=" + item +
'}';
}
}
遍历三种方式
-
迭代器
-
增强for
-
普通for
Set接口
基本介绍
1.无序(添加和取出的顺序不一致),没有索引
2.不允许重复元素,所以最多包含一个null
常用方法
是Collection的子接口,常用方法和Collection一样
遍历方式两种
- 迭代器
- 增强for
注:因为不能索引方式获取元素,所以不能用普通for遍历
HashSet类
基本介绍
1.实现Set接口
2.HashSet实际上是HashMap:无参构造器创建一个HashMap对象
3.可以存放null值,但只能有一个
4.不保证元素有序,hash后,它的取出顺序一旦定下来就不变了
5.不能有重复元素/对象
HashSet底层机制说明
HashSet底层是HashMap,HashMap底层是(数组+链表+红黑树)
模拟简单的数组+链表结构
package com.lcz.collection.set;
/**
* @author lcz
* @version 1.0
*
* 需求:
* 模拟HashSet的底层
* HashMap的底层
* 数组+链表结构
*
*/
public class Structure {
public static void main(String[] args) {
//模拟一个HashSet的底层(HashMap的底层结构)
//1.创建一个数组,数组类型为 Node
//2.有些人直接把 Node[]当成 表
Node[] table = new Node[16];
Node node1 = new Node("lcz");
table[0] = node1;
Node node2 = new Node("lhc");
node1.next = node2;
}
}
class Node{
public Object obj;
public Node next;
public Node(Object obj) {
this.obj = obj;
}
}
结论
1.添加一个元素时,先获取元素的hash值(hashcode()方法通过一个计算得到),将hash值转成--索引值
2.找到存储数据表table,看这个索引的位置是否已经存放元素
3.若没有,直接加入
4.若有,则判断是否:
(1):两个Node结点的hash值一样
并且满足一下两个条件之一:
a:两个Node结点的key值(也就是添加的对象)相等(即地址相等)
b:添加的结点的key值不为空,且调用equals方法与另一个结点的key值相同,此equals方法可以重写,由程序员来控制
若满足上述所说:则不添加
若不满足,则添加至最后
5.在Java8中,如果一个链表的元素个数到达TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认 64),就会进行树化(红黑树)
过程分析
package com.lcz.collection.set;
import java.util.HashSet;
/**
* @author lcz
* @version 1.0
* 需求:
* Debug调试
* 对hashSet源码进行解读:
* 1.执行 HashSet()
* public HashSet() {
* map = new HashMap<>();
* }
* 2.执行 add()
* public boolean add(E e) {//e = "java"
* return map.put(e, PRESENT)==null;// HashSet类的(private static final) PRESENT = new Object();
* }
* 3. 执行put(),该方法会执行 hash(key) 得到key对应的hash值,算法:(h = key.hashCode()) ^ (h >>> 16)
* public V put(K key, V value) {//key = "java" value = PRESENT 共享
* return putVal(hash(key), key, value, false, true);
* }
* 4.执行 putVal()
* final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
* boolean evict) {
* Node<K,V>[] tab; Node<K,V> p; int n, i;//定义了辅助变量
* //table 就是 HashMap 的一个数组,类型是 Node[]
* //if 语句表示如果当前table是 null,或者长度为0
* //就进行第一次扩容,到16个空间
* if ((tab = table) == null || (n = tab.length) == 0)
* //resize()进行数组的扩容
* n = (tab = resize()).length;
* //(1):根据key,得到hash,与计算该key应该存放到table表中哪个索引位置
* //并把这个位置的对象赋给p
* //(2):判断p是否为null
* //(2.1):若 p 为null,表示还没有存放元素,就创建一个Node
* //(2.2):并存放此索引位置
* if ((p = tab[i = (n - 1) & hash]) == null)
* tab[i] = newNode(hash, key, value, null);
* else {
* //一个开发技巧:在需要局部变量(辅助变量)时,再创建
* Node<K,V> e; K k;
* //如果当前索引位置对应的第一个元素和准备添加的key的hash值一样
* //并且满足 下面两个条件之一:
* //(1):准备加入的 key 和 p 指向的Node结点的 key 是同一个对象(即地址相等)
* //(2):准备加入的 key 的 equals()方法 和 p 指向的Node结点的 key 比较后相同
* equals方法可以重写,由程序员来控制
* //就不能加入
* if (p.hash == hash &&
* ((k = p.key) == key || (key != null && key.equals(k))))
* e = p;//直接走向下方的添加失败的if结构
* //再判断 p 是不是一颗 红黑树
* //如果是 红黑树,就以红黑树的方式putTreeVal()进行添加
* else if (p instanceof TreeNode)
* e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
* else {//table对应索引位置可能已经是一个链表,需使用for循环比较
* //(1) 依次和该链表的元素进行比较,都不相同,则加入到该链表的最后
* // 注意把元素添加到链表后,立即判断,该链表是否已经达到8个结点
* // 若达到,则调用treeifyBin,对当前这个链表进行树化(转成红黑树)
* // 注意:转成红黑树时要进行判断,判断条件
* // if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
* // 若条件成立,则先table扩容
* // 不成立,才进行转成红黑树
* //(2) 依次和该链表的每一个元素进行比较的过程中,若有相同情况,就直接break;
* // 此时,循环一半,此时 e != null , 直接走向添加失败的if语句
* for (int binCount = 0; ; ++binCount) {
* //只有循环到最后e为null,才会添加成功,循环一般都会走下面的if语句添加失败
* if ((e = p.next) == null) {
* p.next = newNode(hash, key, value, null);
* if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
* treeifyBin(tab, hash);
* break;
* }
* if (e.hash == hash &&
* ((k = e.key) == key || (key != null && key.equals(k))))
* break;
* p = e;
* }
* }
* //添加失败的if语句
* if (e != null) { // existing mapping for key
* V oldValue = e.value;
* if (!onlyIfAbsent || oldValue == null)
* e.value = value;
* afterNodeAccess(e);
* return oldValue;//
* }
* }
* //走到这里就添加成功
* ++modCount;
* if (++size > threshold)//size 指添加的结点个数
* resize();//
* afterNodeInsertion(evict);
* return null;
* }
*/
public class Set_ {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
System.out.println(hashSet.add("java"));
System.out.println(hashSet.add("lcz"));
System.out.println(hashSet.add("java"));
System.out.println("set = " + hashSet);
}
}
验证扩容机制
package com.lcz.collection.set;
import java.util.HashMap;
import java.util.HashSet;
/**
* @author lcz
* @version 1.0
* 需求:
* 验证扩容机制: Debug调试
* 1.HashSet的底层是HashMap,第一次添加时,table 数组扩容到16
* 2.临界值是(threshold) 是 16 * 加载因子(loadFactor)是0.75 = 12
* 3.如果table数组中的元素个数 达到 临界值12,就会扩容到 16 *2 = 32
* 4.新的临界值,依次类推
*/
public class Set_01 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
for (int i = 0; i < 100; i++) {
hashSet.add(i);
}
}
}
验证树化机制
package com.lcz.collection.set;
import java.util.HashSet;
/**
* @author lcz
* @version 1.0
* 需求:
* 验证树化机制:Debug调试
*/
public class Set_02 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
for (int i = 0; i < 12; i++) {
hashSet.add(new A(i));
}
}
}
class A{
private int n;
public A(int n) {
this.n = n;
}
@Override
public int hashCode() {
return 100;
}
}
验证扩容机制条件
package com.lcz.collection.set;
import java.util.HashSet;
/**
* @author lcz
* @version 1.0
* 需求:
* 验证HashSet扩容机制条件:
* 是元素个数大于临界值,不是数组的12个空间被占用
*/
public class Set_03 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
for (int i = 0; i < 8; i++) {
hashSet.add(new A1(i));
}
for (int i = 0; i < 8; i++) {
hashSet.add(new B(i));
}
}
}
class A1{
private int n;
public A1(int n) {
this.n = n;
}
@Override
public int hashCode() {
return 100;
}
}
class B{
private int n;
public B(int n) {
this.n = n;
}
@Override
public int hashCode() {
return 200;
}
}
HashSet最佳实践

package com.lcz.collection.set.hashset;
import java.util.HashSet;
import java.util.Objects;
/**
* @author lcz
* @version 1.0
* 需求:
* 1.定义一个Employee类,包含name、age属性
* 2.创建3个Employee对象放入HashSet中
* 3.要求当name和age相同时,认为是相同员工,不能添加到HashSet集合中
*/
public class Exercise01 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(new Employee("lcz",20));
hashSet.add(new Employee("lhc",20));
hashSet.add(new Employee("孙悟空",1000));
hashSet.add(new Employee("孙悟空",1000));
System.out.println(hashSet);
}
}
class Employee{
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age && Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
HashSet课后练习

package com.lcz.collection.set.hashset;
import java.util.HashSet;
import java.util.Objects;
/**
* @author lcz
* @version 1.0
* 需求:
* 1.还是Employee1类,包含name、sal、birthday(MyDate类型,包含:year、month、day)
* 2.要求同exercise01
* 注意:因为Employee1重写的equals调用Objects的equals:
* public static boolean equals(Object a, Object b) {
* return (a == b) || (a != null && a.equals(b));
* }
* 所以需要重写MyDate类的equals方法
* 因为Employee1重写的hashCode()方法返回的hash值是根据所有参数的hashCode值经过一个算法得出的
* public static int hashCode(Object a[]) {
* if (a == null)
* return 0;
*
* int result = 1;
*
* for (Object element : a)
* result = 31 * result + (element == null ? 0 : element.hashCode());
*
* return result;
* }
* 所以要重写MyDate类的hashCode方法
*/
public class Exercise02 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(new Employee1("lhc",30000,new MyDate(2004,11,27)));
hashSet.add(new Employee1("lcz",30000,new MyDate(2004,11,27)));
hashSet.add(new Employee1("孙悟空",50,new MyDate(1655,11,10)));
hashSet.add(new Employee1("lhc",30000,new MyDate(2004,11,27)));
for (Object o :hashSet) {
System.out.println(o);
}
}
}
class Employee1{
private String name;
private double sal;
private MyDate birthday;
public Employee1(String name, double sal, MyDate birthday) {
this.name = name;
this.sal = sal;
this.birthday = birthday;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSal() {
return sal;
}
public void setSal(double sal) {
this.sal = sal;
}
public MyDate getBirthday() {
return birthday;
}
public void setBirthday(MyDate birthday) {
this.birthday = birthday;
}
@Override
public String toString() {
return "Employee1{" +
"name='" + name + '\'' +
", sal=" + sal +
", birthday=" + birthday +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee1 employee1 = (Employee1) o;
return Objects.equals(name, employee1.name) && Objects.equals(birthday, employee1.birthday);
}
@Override
public int hashCode() {
return Objects.hash(name, birthday);
}
}
class MyDate{
private int year;
private int month;
private int day;
public MyDate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyDate myDate = (MyDate) o;
return year == myDate.year && month == myDate.month && day == myDate.day;
}
@Override
public int hashCode() {
return Objects.hash(year, month, day);
}
}
LinkedHashSet类
基本介绍
1.LinkedHashSet是HashSet的子类
2.LinkedHashSet 底层是一个 LinkedHashMap,其是HashMap的子类,底层维护了一个数组+双向链表
3.LinkedHashSet用链表维护元素的次序,使得元素插入顺序和取出顺序一致,即有序
4,仍不可添重复元素
继承图

底层机制

1.在LinkedHashSet中维护了一个hash表和双向链表
(LinkedHashSet有head 和 tail)
2.每个结点有 pre 和 next 属性,形成双链表
3.在添加一个元素时,先求hash值,再求索引,确定该元素再hashtable的位置,然后将添加的元素加入到双向链表(如果已经存在,不添加)
tail.next = newElement;/简单指定
newElement.pre = tail;
tail = newElement;
4.确保了插入顺序和遍历顺序一致
源码解读
package com.lcz.collection.set.linkedhashset;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.LinkedHashSet;
import java.util.Set;
/**
* @author lcz
* @version 1.0
* 需求:Debug调试
* LinkedHashSet类源码解读
*
*/
public class LinkedHashSet_ {
public static void main(String[] args) {
LinkedHashSet set = new LinkedHashSet();
set.add("java");
set.add(456);
set.add(456);
set.add("lhc");
set.add("lcz");
System.out.println("set = " + set);
}
}
//1.LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)
//2.LinkedHashSet 底层结构(数组+双向链表)
//3.添加第一次时,直接将 table数组 扩容至16,存放的结点类型是LinkedLinkedHashMap$Entry
//4.数组是 HashMap$Node[] 存放的元素/数据是 LinkedHashMap$Entry类型
//展现的是多态,所以Entry继承Node,二者都是静态内部类
//之所以继承:因为双向链表实现需要扩展出before和after属性
/*
继承关系是在内部类完成的
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
*/
课后练习同HashSet类
Map接口
特点:
1.Map与Collection并列存在,用于保存具有映射关系的数据:Key:Value
2.Map中的 key 和 value 可以是任何引用类型的数据,会封装到HashMao$Node
3.Map中的 key 不允许重复,但 value 可以重复
4.Map中的 key 可以为null,value 也可以为null,注意 key 为null,只能有一个,value 为null,可以多个
5.常用String类作为Map的 key
6.key 和 value 之间存在单向一对一关系,即通过指定的key总能找到对应的value
7.Map存放数据的key-value示意图,一对 k-v 是放在一个HashMap$Node中的,又因为Node实现了 Entry 接口,所以一个Node结点就是一个Entry接口对象,将这些接口对象放到一个 类型为Entry的EntrySet(HashMap$EntrySet)中,所以有些书说 一对k-v就是一个Entry
8.将Key放入Set类型的KeySet(HashMap$KeySet)中,
将Value放入Collection类型的Values(HashMap$Values)中
源码剖析
package com.lcz.collection.map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @author lcz
* @version 1.0
* 需求:
* Map接口特点解读:
* 1.k-v 最后是 HashMap$Node node = newNode(hash,key,value,null)
* 2.k-v 为了方便程序员的遍历,还会创建一个 EntrySet集合,该集合存放的元素的类型是 Entry接口,
* 而一个Entry接口对象就有k-v,EntrySet<Entry<k,v>>,即 transient Set<Map.Entry<K,V>> entrySet;
* 3.entrySet 中,定义的类型是Set,存放元素的定义类型为Map.Entry<K,V>, 实际上存放的还是HashMap$Node(运行类型)
* 4.当把 HashMap$Node 对象 存放到 entrySet 就方便我们的遍历,因为Map.Entry 提供了重要方法:
* K getKey(); V getValue();
* 5.还会创建一个类型为Set的KeySet集合,存放的是K类型(Map对象的Key的类型)的Key,可以利用Set的三种遍历方式对键进行遍历
* 6.还会创建一个类型为Collection的Values集合,存放的V类型(Map对象的Value的类型)的Value,可以利用Collection的三种遍历方式对值进行遍历
* 7.KeySet、Values、entrySet都是HashMap的内部类,能作为集合是因为内部类实现了对应的集合接口
* 注:都不是真正的存放,都是指向HashMap$Node相关信息!!!
*/
public class Map_ {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("no1","lcz");
map.put("no2","lhc");
map.put(new Car1(),new Person());
System.out.println(map);
for (Object o :map.entrySet()) {
Map.Entry entry = (Map.Entry) o;
System.out.println(entry.getKey() + "=" + entry.getValue());
}
Set set1 = map.keySet();
Collection set2 = map.values();
System.out.println(set1);
System.out.println(set2);
for (Object o :set1) {
System.out.println(o);
}
for (Object o :set2) {
System.out.println(o);
}
System.out.println(set1.getClass());
System.out.println(set2.getClass());
}
}
class Car1{
}
class Person{
}
常用方法
1.put
2.remove
3.get
4.size
5.isEmpty
6.clear
7.containsKey
六种遍历方式
//六种遍历方式
System.out.println("===六种遍历方式===");
HashMap hashMap = new HashMap();
hashMap.put("man","lcz");
hashMap.put("woman","lhc");
hashMap.put("cf角色","暗夜");
//(1):先获取key,再根据key获取值
Set set = hashMap.keySet();
//1.1:迭代器
System.out.println("1.1迭代器");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "=" + hashMap.get(key));
}
//1.2增强for
System.out.println("1.2增强for");
for (Object key :set) {
System.out.println(key + "=" + hashMap.get(key));
}
//(2):获取值
//2.1:迭代器
System.out.println("2.1:迭代器");
Collection values = hashMap.values();
Iterator iterator1 = values.iterator();
while (iterator1.hasNext()) {
Object value = iterator1.next();
System.out.println(value);
}
//2.2:增强for
System.out.println("2.2:增强for");
for (Object o :values) {
System.out.println(o);
}
//(3):获取Entry接口对象,调用getKey和getValue方法获取键和值
Set set3 = hashMap.entrySet();
//3.1:迭代器
System.out.println("3.1:迭代器");
Iterator iterator2 = set3.iterator();
while (iterator2.hasNext()) {
Map.Entry entry = (Map.Entry) iterator2.next();
System.out.println(entry.getKey() + "=" + entry.getValue());
}
//3.2:增强for
System.out.println("3.2:增强for");
for (Object o :set3) {
Map.Entry entry = (Map.Entry) o;
System.out.println(entry.getKey() + "=" + entry.getValue());
}
Map接口练习题

package com.lcz.collection.map;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @author lcz
* @version 1.0
* 需求:
* 1.使用HashMap添加3个员工对象,要求:
* 键:员工id
* 值:员工对象
* 2.并遍历显示工资大于18000的员工
* 员工类:姓名、工资、id
*/
public class Exercise01 {
public static void main(String[] args) {
Map map = new HashMap();
Emp lcz = new Emp("lcz", 30000, 1);
Emp lhc = new Emp("lhc", 5000, 2);
Emp lcq = new Emp("lcq", 20000, 3);
map.put(lcz.getId(),lcz);
map.put(lhc.getId(),lhc);
map.put(lcq.getId(),lcq);
Set set = map.keySet();
for (Object key :set) {
Emp emp = (Emp) (map.get(key));//map.get(key)返回的是Object类型,所以需要向下转型
if(emp.getSal() > 18000)
System.out.println(key + "=" + map.get(key));
}
}
}
class Emp{
private String name;
private double sal;
private int id;
public Emp(String name, double sal, int id) {
this.name = name;
this.sal = sal;
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSal() {
return sal;
}
public void setSal(double sal) {
this.sal = sal;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
@Override
public String toString() {
return "Emp{" +
"name='" + name + '\'' +
", sal=" + sal +
", id=" + id +
'}';
}
}
HashMap类
底层机制结论
之前HashSet的底层就是它
1.HashMap底层维护了 Node 类型的数组table,默认为null
2.当创建对象时,将加载因子(loadfactor)初始化为0.75
3.当添加key-val时,将key的哈希值得到在table的索引,然后判断该索引处是否有元素,若没有,直接添加,若有,继续判断该元素的key和准备加入的key是否相等,若相等,则替换,若不相等,需要判断是树结构还是链表结构,做出相应处理,如果添加时发现容量达到临界值,需要扩容
4.第一次添加时,需要扩容table容量为16,临界值为12
5.以后再扩容,扩容table容量的2倍,临界值也变为2倍
6.在java8中,如果一条链表的元素个数超过TREEIFY_THRESHOLD,并且table的大小 >= MIN_TREEIFY_CAPACITY,就会进行树化(红黑树)
源码分析
package com.lcz.collection.map;
import java.util.HashMap;
/**
* @author lcz
* @version 1.0
* 需求:
* HashMap源码解读
* 跟HashSet源码相比:也就增加了个键相同,值替换的操作
* if (e != null) { // existing mapping for key
* V oldValue = e.value;
* if (!onlyIfAbsent || oldValue == null)//onlyIfAbsent = false
* e.value = value;//进行值的替换
* afterNodeAccess(e);
* return oldValue;
* }
*/
public class HashMap_ {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
hashMap.put("man","lcz");
hashMap.put("woman","lhc");
hashMap.put("man","lcz");
System.out.println(hashMap);
}
}
HashMap小结
1.HashMap是以key-val对的方式来存储数据(HashMap$Node类型)
2.key不能重复,但值可以重复,允许使用null键和null值
3.如果添加相同的key,则会覆盖
4.无序,即不能保证映射的顺序,因为底层是以hash表的方式来存储的
5.HashMap没有实现同步,线程不安全
Hashtable
基本介绍
1.存放的元素是键值对:即K-V
2.键和值都不能为null,否则会抛出NullPointerException
3.使用方法基本和HashMap一样
4.Hashtable 是线程安全的(synchronized),HashMap是线程不安全的
源码解读
package com.lcz.collection.map.hashtable;
import java.util.Hashtable;
/**
* @author lcz
* @version 1.0
* 需求:
* Hashtable类源码解读
* 1.底层有数组 Hashtable$Entry[],初始化大小为 11
* 临界值为 threshold = 8 (11*0.75)
* public Hashtable() {
* this(11, 0.75f);
* }
* this调用:
* this.loadFactor = loadFactor;
* table = new Entry<?,?>[initialCapacity];
* threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
* 2.扩容:按照自己的扩容机制进行扩容
* 3.执行方法 addEntry(hash,key,value,index);添加K-V,封装到Entry
* 4.当if (count >= threshold) {
* rehash();//进行扩容,扩容机制为:int newCapacity = (oldCapacity << 1) + 1;
* (两倍+1)
* 5.区别于HashMap:结点为Hashtable$Entry,为静态内部类Entry对象,此类实现Entry接口
* 仍有内部类KeySet,EntrySet,但Values变为ValueCollection,原理一样
*/
public class Hashtable_ {
public static void main(String[] args) {
Hashtable hashtable = new Hashtable();
hashtable.put("no1","lcz");
hashtable.put("no2","lhc");
hashtable.put("no1","lcz");
System.out.println(hashtable);
}
}
Hashtable和HashMap对比

Properties类
基本介绍
1.Properties类继承自Hashtable类并且实现了Map接口,也是使用一种键值对的形式来保存数据
2.特点和Hashtable类似
不允许存放null值
3.Properties还可用于从 XXX.properties文件中,加载数据到Properties类对象,并进行读取和修改
4.XXX.properties 文件通常作为配置文件
基本使用
CRUD
增:put
删:remove
改:put
查:get
getProperty
TreeSet类
基本介绍
1.实现Set接口的直接子类
1.当我们使用无参构造器,创建TreeSet时,仍然是无序的
2.若希望添加的元素,按照字符串大小进行排序
3.使用TreeSet提供的一个构造器,可以传入一个比较器(匿名内部类)
并指定排序规则
4.键和值都不能添加null值
源码解读
package com.lcz.collection.set.treeset;
import java.util.Comparator;
import java.util.TreeSet;
/**
* @author lcz
* @version 1.0
* 需求:
* TreeSet类特点:
* 1.当我们使用无参构造器,创建TreeSet时,仍然是无序的
* 2.若希望添加的元素,按照字符串大小进行排序
* 3.使用TreeSet提供的一个构造器,可以传入一个比较器(匿名内部类)
* 并指定排序规则
* 源码解读:
* TreeSet的底层就是TreeMap
* 1.构造器把传入的比较器对象,赋给了TreeSet的底层的TreeMap的属性 this.comparator
* public TreeMap(Comparator<? super K> comparator) {
* this.comparator = comparator;
* }
* 2.在调用 treeSet.add("jack") 底层会执行到
* if (cpr != null) {//cpr就是我们的匿名内部类对象
* do {
* parent = t;
* cmp = cpr.compare(key, t.key);//动态绑定到我们的匿名内部类(对象)的compare
* if (cmp < 0)
* t = t.left;
* else if (cmp > 0)
* t = t.right;
* else//如果相等,即返回0,这个key就加入失败
* return t.setValue(value);
* } while (t != null);
* }
*/
public class TreeSet_ {
public static void main(String[] args) {
//TreeSet treeSet = new TreeSet();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//return ((String)o1).compareTo(((String)o2));
return ((String)o1).length() - ((String)o2).length();
}
});
treeSet.add("jack");
treeSet.add("lhc");
treeSet.add("it");
treeSet.add("a");
//treeSet.add(null);
System.out.println(treeSet);
}
}
TreeMap类
基本介绍
同TreeSet类
1.实现Map接口的直接子类
2.当我们使用无参构造器,创建TreeMap时,仍然是无序的
3.若希望添加的元素,按照字符串大小进行排序
使用TreeMap提供的一个构造器,可以传入一个比较器(匿名内部类)
并指定排序规则
4.键和值都不能添加null值
源码解读
package com.lcz.collection.map.treemap;
import java.util.Comparator;
import java.util.TreeMap;
/**
* @author lcz
* @version 1.0
* 需求:
* TreeMap类源码解读:
* 1.当我们使用无参构造器,创建TreeMap时,仍然是无序的
* 2.构造器把传入的比较器对象,赋给了TreeSet的底层的TreeMap的属性 this.comparator
* public TreeMap(Comparator<? super K> comparator) {
* this.comparator = comparator;
* }
* 3.调用put方法
* 3.1第一次添加
* if (t == null) {
* compare(key, key); // type (and possibly null) check
*
* root = new Entry<>(key, value, null);
* size = 1;
* modCount++;
* return null;
* }
* 3.2以后添加
* Comparator<? super K> cpr = comparator;
* if (cpr != null) {
* do {//遍历所有key,给当前key找到合适位置
* parent = t;
* cmp = cpr.compare(key, t.key);//动态绑定到我们的匿名内部类对象的compare
* if (cmp < 0)
* t = t.left;
* else if (cmp > 0)
* t = t.right;
* else//如果相等,则返回0,不添加
* return t.setValue(value);
* } while (t != null);
* }
*/
public class TreeMap_ {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//return ((String)o1).compareTo(((String)o2));
return ((String)o2).length() - ((String)o1).length();
}
});
treeMap.put("jack","a");
treeMap.put("lhc","b");
treeMap.put("it","c");
treeMap.put("a","d");
//treeMap.put(null,'a');
//treeMap.put("z",null);
System.out.println(treeMap);
}
}
集合选型规则
取决于业务操作特点,然后根据集合实现类特性进行选择
1)先判断存储的类型(一组对象[单列]或一组键值对[双列])
2)一组对象[单列]:Collection接口
允许重复:List
增删多:LinkedList[底层维护了一个双向链表]
改查多:单线程:ArrayList[底层维护Object类型的可变数组]
多线程:Vector
不允许重复:Set
无序:HashSet[底层是HashMap,维护了一个哈希白哦,即(数组+链表+红黑树)]
排序:TreeSet
插入和取出顺序一致:LinkedHashSet(底层是LinkedHashMap,而其底层又为 HashMap),维护数组+双向链表
3)一组键值对[双列]:Map
键无序:单线程:HashMap[底层是:哈希表 jdk7:数组+链表,jdk8:数组+链表+红黑 树]
多线程:Hashtable
键排序:TreeMap
键插入和取出顺序一致:LinkedHashMap
读取文件:Properties
Collections工具类
介绍
1.是一个操作Set、List、Map等集合的工具类
2.提供了一系列静态的方法对集合元素进行排序、查询和修改等操作
常用方法
- reverse(List):反转List中元素的顺序
- shuffle(List):对List集合元素进行随机排序
- sort(List):根据元素的自然顺序对指定List集合元素按升序排序
- sort(List,Comparator):根据指定的比较器产生的顺序进行排序
- swap(List,int,int):将指定List集合中的 i 处元素和 j 处元素进行交换
查找替换
- Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection,Comparator):根据比较器指定的顺序,返回给定集合最大元素
- Object min(Collection)
- Object min(Collection,Comparator)
- int frequency(Collection,Object):返回指定集合中指定元素的出现次数
- void copy(List dest,List src):将src的内容复制到dest中
- boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换List对象的所有旧值
演示
package com.lcz.collection.collections;
import com.sun.xml.internal.ws.policy.privateutil.PolicyUtils;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
/**
* @author lcz
* @version 1.0
* 需求:
* Collections工具类常用方法
*/
public class Collections_ {
public static void main(String[] args) {
// - reverse(List):反转List中元素的顺序
ArrayList arrayList = new ArrayList();
arrayList.add("a");
arrayList.add("b");
arrayList.add("c");
arrayList.add("d");
System.out.println("翻转前");
System.out.println(arrayList);
Collections.reverse(arrayList);
System.out.println("翻转后");
System.out.println(arrayList);
// - shuffle(List):对List集合元素进行随机排序
Collections.shuffle(arrayList);
System.out.println("随机排序");
System.out.println(arrayList);
// - sort(List):根据元素的自然顺序对指定List集合元素按升序排序
//自然顺序:指按字符串大小
Collections.sort(arrayList);
System.out.println("自然排序升序后");
System.out.println(arrayList);
// - sort(List,Comparator):根据指定的比较器产生的顺序进行排序
Collections.sort(arrayList, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
System.out.println("按照字符串大小从小到大");
System.out.println(arrayList);
// - swap(List,int,int):将指定List集合中的 i 处元素和 j 处元素进行交换
Collections.swap(arrayList,0,1);
System.out.println("交换后");
System.out.println(arrayList);
//
// 查找替换
// - Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大值");
System.out.println(Collections.max(arrayList));
// - Object max(Collection,Comparator):根据比较器指定的顺序,返回给定集合最大元素
System.out.println("字符串长度大小最大值");
System.out.println(Collections.max(arrayList, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
}));
// - Object min(Collection)
// - Object min(Collection,Comparator)
// - int frequency(Collection,Object):返回指定集合中指定元素的出现次数
System.out.println("指定元素a出现次数");
System.out.println(Collections.frequency(arrayList,"a"));
// - void copy(List dest,List src):将src的内容复制到dest中
ArrayList arrayList1 = new ArrayList(10);
//设置初始容量为10,仍报异常,因为list是在第一次添加元素时,才创建底层的数组,之前数组为null
arrayList1.add("asdfas");
arrayList1.add("ljil");
Collections.copy(arrayList,arrayList1);
System.out.println("复制后");
System.out.println(arrayList);//可能会报异常:因为要求dest长度大于src长度,长度指元素个数
// - boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换List对象的所有旧值
Collections.replaceAll(arrayList,"c","lcz");
System.out.println("替换后");
System.out.println(arrayList);
}
}
本章作业
作业1
package com.lcz.collection.homework;
import java.util.ArrayList;
/**
* @author lcz
* @version 1.0
* 需求:
* 1.封装一个新闻类:包含标题和内容属性,提供get、set方法,重写toString方法,
* 打印对象时只打印标题
* 2.只提供一个带参数的构造器,实例化对象时,只初始化标题
* 新闻一:新冠确诊病例超千万,数百万印度教信徒负桓河”圣域“因民众担忧
* 新闻二:男子突然想起2各月前调的鱼经还在鱼兜里面,捞起一看赶紧放生!
* 3.将新闻对象添加到ArrayList集合中,并且进行倒序遍历;
* 4.在遍历集合过程中,对新闻标题进行处理,超过15个字的只保留前15个,在后面加”...“
* 5.在控制台打印遍历出经过处理的新闻标题
*/
public class Homework01 {
public static void main(String[] args) {
News news = new News("新冠确诊病例超千万,数百万印度教信徒负桓河”圣域“因民众担忧");
News news1 = new News("男子突然想起2各月前调的鱼经还在鱼兜里面,捞起一看赶紧放生!");
ArrayList arrayList = new ArrayList();
arrayList.add(news);
arrayList.add(news1);
for (int i = arrayList.size()-1; i >= 0; i--) {//调用处理title的方法,然后输出处理后的title
News temp = (News) (arrayList.get(i));
System.out.println(processTitle(temp.getTitle()));
}
}
public static String processTitle(String title){//将对title进行处理单独封装为一个方法去实现
if(title == null)
return "";
if (title.length() > 15)
return title.substring(0,16) + "...";
else
return title;
}
}
class News{
private String title;
private String content;
public News(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "News{" +
"title='" + title + '\'' +
'}';
}
}
作业2
package com.lcz.collection.homework;
import java.util.*;
/**
* @author lcz
* @version 1.0
* 需求:
* 1.使用HashMap类实例化一个Map类型的对象m,键(String)和值(int) 分别用于存储员工的姓名和工资,存入数据如下:
* jack——650元
* tom——1200元
* smith——2900元
* 2.将jack的工资更改为2600元
* 3.为所有员工工资加薪1000元
* 4.遍历集合中所有的员工
* 5.遍历集合中所有的工资
*/
public class Homework02 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("jack",650);
map.put("tom",1200);
map.put("smith",2900);
map.put("jack",2600);
Set entrySet = map.entrySet();
System.out.println("遍历所有员工:");
System.out.println("增强for:");
for (Object o :entrySet) {
Map.Entry entry = (Map.Entry) o;
System.out.println("员工姓名:" + entry.getKey() + ",员工工资:" + entry.getValue());
}
System.out.println("迭代器:");
Iterator iterator = entrySet.iterator();
while (iterator.hasNext()) {
Map.Entry entry = (Map.Entry) iterator.next();
System.out.println("员工姓名:" + entry.getKey() + ",员工工资:" + entry.getValue());
}
Collection values = map.values();
System.out.println("遍历所有工资:");
for (Object o :values) {
System.out.println("工资:" + o);
}
}
}
作业3
package com.lcz.collection.homework;
/**
* @author lcz
* @version 1.0
* 需求;
* 试分析HashSet和TreeSet分别如何实现去重的
* (1):HashSet的去重机制:hashCode() + equals(),底层先通过存入一个对象,进行运算得到一个hash值,
* 再根据hash值进行运算得到对应的索引,如果发现table索引所在的位置,没有数据,就直接存放,
* 如果有数据,就进行equals循环比较(for遍历链表),如果比较后,不相同,就加入,否则不加入
* (2):TreeSet的去重机制:如果你传入一个Comparator匿名对象,就使用实现的compare方法去重,如果方法返回0,
* 就认为是相同的数据元素,就不添加。
* 如果你没有传入一个Comparator匿名对象,则以你添加的对象实现Compareable接口的compareTo去重
*/
public class Homework03 {
}
作业4
package com.lcz.collection.homework;
import java.util.TreeSet;
/**
* @author lcz
* @version 1.0
* 需求:
* 分析代码是否报错
* 会报ClassCastException(类型转换错误)
* 原因:
* 1.因为未传入一个comparator匿名对象
* 2.则会根据添加的对象实现Comparable接口的compareTo方法进行去重
* 3.而Person未实现Coparable接口,所以将添加对象转化为Comparable接口类型时报错
*/
public class Homework04 {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
treeSet.add(new Person());
}
}
class Person{
}
作业5
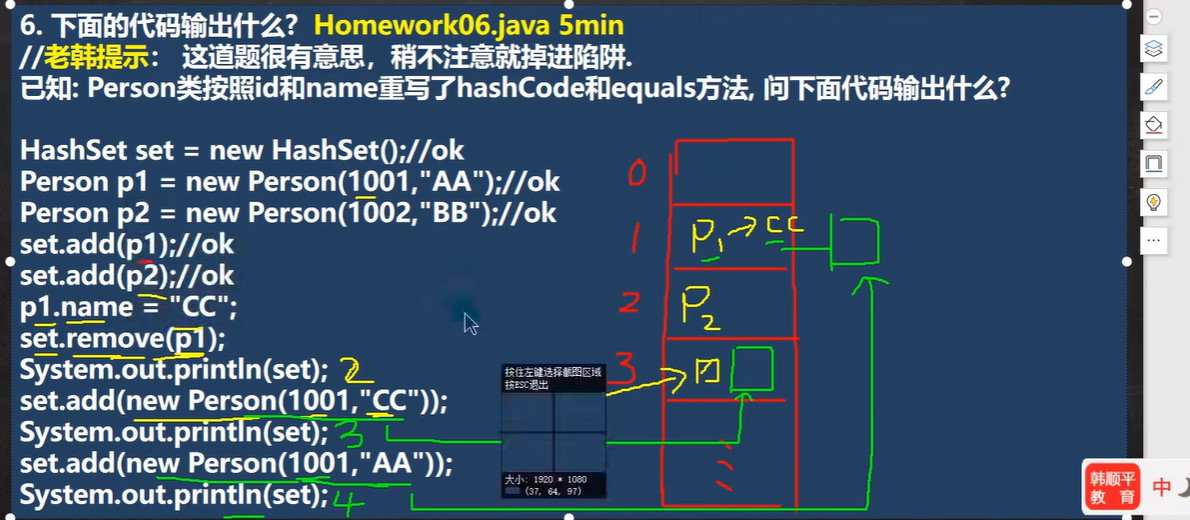
p1.name = "CC",
内容更改,计算出的hash值和对应的索引都会变,也就是删除p1失败
添加 1001 "CC" 成功
添加 1001 "AA" 成功
作业6
try = (Map.Entry) o;
System.out.println(“员工姓名:” + entry.getKey() + “,员工工资:” + entry.getValue());
}
System.out.println(“迭代器:”);
Iterator iterator = entrySet.iterator();
while (iterator.hasNext()) {
Map.Entry entry = (Map.Entry) iterator.next();
System.out.println(“员工姓名:” + entry.getKey() + “,员工工资:” + entry.getValue());
}
Collection values = map.values();
System.out.println(“遍历所有工资:”);
for (Object o :values) {
System.out.println(“工资:” + o);
}
}
}
作业3
```java
package com.lcz.collection.homework;
/**
* @author lcz
* @version 1.0
* 需求;
* 试分析HashSet和TreeSet分别如何实现去重的
* (1):HashSet的去重机制:hashCode() + equals(),底层先通过存入一个对象,进行运算得到一个hash值,
* 再根据hash值进行运算得到对应的索引,如果发现table索引所在的位置,没有数据,就直接存放,
* 如果有数据,就进行equals循环比较(for遍历链表),如果比较后,不相同,就加入,否则不加入
* (2):TreeSet的去重机制:如果你传入一个Comparator匿名对象,就使用实现的compare方法去重,如果方法返回0,
* 就认为是相同的数据元素,就不添加。
* 如果你没有传入一个Comparator匿名对象,则以你添加的对象实现Compareable接口的compareTo去重
*/
public class Homework03 {
}
作业4
package com.lcz.collection.homework;
import java.util.TreeSet;
/**
* @author lcz
* @version 1.0
* 需求:
* 分析代码是否报错
* 会报ClassCastException(类型转换错误)
* 原因:
* 1.因为未传入一个comparator匿名对象
* 2.则会根据添加的对象实现Comparable接口的compareTo方法进行去重
* 3.而Person未实现Coparable接口,所以将添加对象转化为Comparable接口类型时报错
*/
public class Homework04 {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
treeSet.add(new Person());
}
}
class Person{
}
作业5

p1.name = "CC",
内容更改,计算出的hash值和对应的索引都会变,也就是删除p1失败
添加 1001 "CC" 成功
添加 1001 "AA" 成功
作业6

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









