






我们不仅是从零开始学习强化学习,而且是从零开始学习编程。在前两篇关于编程语言的学习之后,我们现在要进入人工智能程序编写的阶段。我们将编写一个真实的“强化学习”应用程序,这个程序将会非常有趣。让我们一起开始吧!
强化学习是机器学习领域中的一种重要方法。它能够通过与环境的交互来不断学习和改进自己的行为,因此被广泛运用于人工智能领域。
近年来,强化学习在各个领域都取得了重要的进展,其中最为著名的例子是人工智能软件阿尔法狗在围棋领域的胜利。通过强化学习的训练,阿尔法狗成功地战胜了围棋世界冠军,成为了人工智能领域的一项重要突破。
2023年备受瞩目的人工智能大语言模型,如ChatGPT等,已经具备了与人类自由对话的能力,并且可以进行诗歌创作、写文章、绘画、翻译、编程、游戏制作等多种任务,这些能力让它们在很多领域都可以替代人类完成工作。
我和ChatGPT简单聊了聊,问它使用了哪些学习方法?它回答说使用了包括强化学习在内的三种学习方式。

强化学习最早起源于心理学的研究成果。巴甫洛夫揭示了动物形成条件反射的能力,桑代克在此基础上提出了学习理论,即:好的结果会强化对应的行为,坏的结果会削弱对应的行为,有奖励的重复练习会增强这种联结。斯金纳通过对操作条件反射的研究,提出了强化理论,指出行为可以通过奖励和惩罚来塑造和改变。
在20世纪80年代兴起的人工智能研究中,研究者借鉴了心理学中的强化理论,并意识到,通过模拟动物学习的过程,可以为机器赋予学习和适应环境的能力。他们从心理学中引入“强化”这个词,将这种学习方法命名为“强化学习”。
强化学习是一种试错学习方法,类似于动物学习过程。例如,驯养员训练马戏团动物时,会对正确的动作给予食物奖励,以此引导动物逐渐学会复杂的动作。类似地,强化学习算法也是通过奖励机制来指导学习过程,使其能够改进自己的行为并逐渐学会复杂任务。
所以,我们给强化学习下一个形象的定义:利用奖励或惩罚的手段,训练动物做复杂动作的学习方式,就是强化学习。
本篇不会过多介绍强化学习的理论和算法演变历程,而是尽快进入强化学习的编程阶段,通过实例让大家能够更好地体验和理解。
因为在电脑上进行实验和研究比研究大脑更为迅捷和方便,再加上数学工具的支持,使得人工智能的某些方面已经超越了神经科学和心理学。因此,从事这两个领域研究的学者应更多关注人工智能的发展,以获得更多的借鉴和启示。
目前,大多数人工智能和强化学习程序都采用Python语言编写,因为它非常适合专业人士。然而,对于初学者来说,Python语言并不够友好。安装和配置Python编程环境的复杂程度足以使许多人望而却步,而学习Python语言和各种强化学习算法的原理则又会劝退多一半人。实际上,留下10%的人能够真正开始编程,这已经相当不错了。
为了解决这一问题,我参考AI生成的代码,将强化学习程序移植到Excel中。这样,学习者不需要安装或配置任何软件,只要电脑上已有办公软件Office,就能够开始编程了。
在Excel中内置的VBA编程语言简单易学。我们之前已经通过两篇文章讲解了主要的语句,并通过编程绘制了一个迷宫。此外,我们还绘制出一个动作参数表和一个策略表,使得迷宫中的老鼠能够实现随机移动。
接下来,我们会为这个“电子老鼠”赋予强化学习技能,很类似老鼠固有的条件反射学习能力。这样,它就能够自主学习并探索最短的路径来获取“食物”。
我们先回顾一下前两篇教程《零基础入门,用Excel 编写人工智能程序:老鼠迷宫》和《从零学起,用Excel VBA编程训练“人工智能老鼠”走迷宫(二)》中的主要内容(建议没读过的同学先点文章名字阅读),标题如下:
01 在Excel中编写和运行程序
02 编程基本操作
03 画迷宫
04 画参数表
05 画策略表
06 自定义函数
07 策略选择函数
08 求取下一步的行号和列号
09 老鼠随机行走
以下的标题序号接前文继续。
10 画价值表
在之前的教程中,我们创建了一个“策略表”,它存储了可采取动作的概率分布。在强化学习中,这个概率值也被称为“策略”,通常用π来表示。需要注意的是,这里的π并不是圆周率3.14的意思,而是来自英文单词“policy”(策略)的近似发音。
将要新建的“价值表”与“策略表”大小相同,都是9行4列。其中,行号代表迷宫的编号,列号代表“上、右、下、左” 4个方向。
“价值表”中的值代表每个可移动方向的价值,在强化学习中常被称为Q值,字母Q取自“Quality”,表示动作的质量或价值。其取值范围是0~1,Q值越大(越接近1)表示这个方向的价值越高,越有利于获得奖励。
我们把价值表的左上角,放在表格的第16行,第8列,我们定义两个常量代表这两个数字。定义常量的代码如下:
Const 价值表头行 = 16 '价值表Q左上角行号
Const 价值表头列 = 8 '价值表Q左上角列号这两句代码与之前定义的常量放在一起,放在整个程序的最上方,
下面是画价值表的过程定义及实现代码(代码显示不全可左右划动):
Sub 画价值表() '画价值表(Q表)
Dim 价值表初值 As Single '浮点型,价值表的初值
Dim 列号 As Integer '价值表的行号
Dim 行号 As Integer '价值表的列号
'画价值表表头
Cells(价值表头行 - 2, 价值表头列 + 1) = "价值表Q(动作的价值)"
Cells(价值表头行 - 2, 价值表头列 - 1) = "位置编号/"
Cells(价值表头行 - 1, 价值表头列 - 1) = "移动方向"
Cells(价值表头行 - 1, 价值表头列 + 0) = "0-上" '写价值表动作的方向
Cells(价值表头行 - 1, 价值表头列 + 1) = "1-右" '写价值表动作的方向
Cells(价值表头行 - 1, 价值表头列 + 2) = "2-下" '写价值表动作的方向
Cells(价值表头行 - 1, 价值表头列 + 3) = "3-左" '写价值表动作的方向
With Range(Cells(价值表头行, 价值表头列), Cells(价值表头行 + 8, 价值表头列 + 3))
.BorderAround LineStyle:=xlContinuous '画价值表四边单线边框
End With
Randomize (Timer) '初始化随机数
For 行号 = 0 To 8 '价值表行号从0~8循环
Cells(价值表头行 + 行号, 价值表头列 - 1) = 行号 '在价值表左侧写迷宫编号
For 列号 = 0 To 3 '价值表列号从0~3循环
If Cells(参数表头行 + 行号, 参数表头列 + 列号) <> 0 Then
'如果参数表同行同列的值不等于0,则:
Do While True '循环取一个非0随机数
价值表初值 = Rnd() '取得一个0~1之间的随机数作为价值表初值
If 价值表初值 <> 0 Then Exit Do '如果“价值表初值”不等于0,退出循环
Loop
Cells(行号 + 价值表头行, 列号 + 价值表头列) = 价值表初值 * 0.5 '填价值表(乘0.1取较低初值)
Else
Cells(行号 + 价值表头行, 列号 + 价值表头列) = 0 '如果参数表为0,则价值表也填0
End If
Next 列号
Next 行号
End Sub画价值表的过程与画策略表的过程类似,开始是定义内部变量和画表头。
填表的程序的主体结构依然是两个嵌套在一起的For循环语句,外圈的For循环是价值表的行号,从0到8,共9行。内圈的For循环是价值表的列号,从0到3,分别代表四个方向,即:0-上,1-右,2-下,3-左。
程序将向价值表中填初始值。如果在策略表中的某个方向的值为0,表示这个方向有墙,不能移动。填价值表时,该方向也填0,代表价值是0。
其他的方向是可移动的方向,填表时取一个0~1之间的随机数作为初始值。
当随机数的值过大时,可能会误导老鼠,使其误以为该方向有利于获得奖励,从而倾向于朝该方向前进,导致出现较多无效动作。
因此,在为价值表填写初值时,我们可以将得到的随机数乘以0.1,以便从一个较低的价值水平开始学习。这样有利于减少无效动作的发生。
画价值表的程序写好后,把调用“画价值表”的代码加入到“初始化”过程中,放在最后一句,如下:
Sub 初始化()
Range(Cells(2, 1), Cells(26, 12)).Clear '清空指定矩形区域
画迷宫 '调用“画迷宫()”过程
画动作参数表 '调用“画动作参数表()”过程
画策略表 '调用“画策略表()”过程
画价值表 '调用“画价值表()”过程
End Sub现在我们可以把光标放到“初始化”过程内部,按F5功能键执行这段程序,就可以看到画好的迷宫和三个表格。其中价值表右下方,如下图:

11 价值选择
利用价值表可以选择下一步移动的方向,方法是:当老鼠移动到迷宫中的某个单元格时,到价值表中查询对应位置的Q值最大的方向,并以这个方向作为下一步的前进方向。
可见,价值表中Q值的大小会对老鼠的方向选择起到非常大的作用。
Q值的大小对老鼠的方向选择起到了极其重要的作用。或许你会问,即使老鼠选择了Q值最大的方向,但是,我们在价值表中填写的初值是随机数,它会帮助老鼠吃到食物吗?
暂时不会。不过,不用着急。之后会根据得到的奖励来更新价值表。随着时间的推移,正确方向对应的Q值将会越来越大,最终Q值最大的方向将会是离奖励最近的方向。
下面是价值选择过程的定义和实现代码。
Function 价值选择(位置编号 As Integer) As Integer '按价值表选择价值最大的方向
Dim 最大Q值 As Single '价值表中该行的最大价值
Dim 当前Q值 As Single '价值表的当前Q值
Dim 表列号 As Integer '价值表的当前列号(表内列号)
最大Q值 = Application.Max(Range(Cells(价值表头行 + 位置编号, 价值表头列), Cells(价值表头行 + 位置编号, 价值表头列 + 3))) '求价值表中最大值
For 表列号 = 0 To 3 '价值表列号从0~3循环
当前Q值 = Cells(位置编号 + 价值表头行, 表列号 + 价值表头列) '取当前列号的Q值
If 当前Q值 = 最大Q值 Then '如果当前Q值=最大Q值,则:
价值选择 = 表列号 '函数返回价值表中最大Q值对应的列号
Exit For '跳出For循环
End If
Next 表列号
End Function12 探索与利用
在决策过程中,探索与利用是一个经典的难题,在一定条件下需要进行合理的权衡。
以挖矿或寻宝为例,一方面,往各处寻找和收集信息被称为探索,但过度的探索可能会浪费大量人力物力,却未能获得更多有用的信息。另一方面,一旦得到少量信息,就停止探索并开始进行利用,有可能会错过附近更为丰富的矿藏。
对人工智能的学习过程来说,如何用最少的时间获得最大的奖励,也需要在探索与利用之间进行合理的平衡。
常用的解决方案是ε贪心策略,即选定一个探索系数ε,取值0~1。每次决策时,以ε的概率去“探索”新的可能性;另一方面,以1-ε的概率“利用”已有的知识。这种策略在探索与利用之间实现了平衡,既不会过于频繁地进行探索,也不会过于依赖已知的最佳动作。
大脑中也存在类似的机制。研究表明,去甲肾上腺素可以影响运动系统,从而影响探索和利用之间的转换。高浓度的去甲肾上腺素会促使人们更倾向于冒险的行为。
下面编写一个名为“探索与利用”的函数完成这项工作。函数定义如下:
Function 探索与利用(ByRef 当前行 As Integer, ByRef 当前列 As Integer) As Integer
End Function这个函数有两个参数:“当前行”与“当前列”,是指“价值表”的当前行列。它们都使用“ByRef”传地址模式,即数据可以双向传送。
函数的代码如下:
Function 探索与利用(ByRef 当前行 As Integer, ByRef 当前列 As Integer) As Integer '获取下一步的方向
Dim 表列号 As Integer '表内列号
Dim 迷宫编号 As Integer '当前位置在价值表中的行号
Dim 随机数 As Single '随机数
Dim 探索系数ε As Single 'ε-贪心策略初值(探索的占比)
探索系数ε = 0.5 '探索系数ε取值0~1;取0全选价值表(利用),取1全选策略表(探索)
Randomize (Timer) '初始化随机数
随机数 = Rnd() '取得一个0~1之间的随机数
迷宫编号 = (当前行 - 迷宫头行) * 3 + (当前列 - 迷宫头列)
If 随机数 < 探索系数ε Then '部分按照策略表中的动作概率随机选方向
表列号 = 策略选择(迷宫编号)
Else '另一部分按照价值表中的最大价值选择方向
表列号 = 价值选择(迷宫编号)
End If
下一步位置 表列号, 当前行, 当前列 '取得下一步的行列号
探索与利用 = 表列号 '函数返回表列号
End Function在“探索与利用”函数中,探索系数ε取值为0.5,即50%的几率去探索,另50%的几率来利用。
13 Q学习(Q-learning)
Q学习是一种基于奖励的强化学习算法,是时序差分(temporal difference,TD)算法的一种。它主要通过预测不断地更新价值表来寻找最优策略。
价值表中的Q值代表了在该状态下采取某个移动方向所能获得的累计奖励。通过重复训练和学习,正确的策略所对应的Q值不断增加,逐渐成为离奖励最近的方向。
在各类学习算法中,Q学习是最接近动物或人类建立条件反射的学习方式。大脑很可能也使用了时序差分算法,通过释放多巴胺对正确的预测给予奖励,从而学会把刺激或行为与奖励建立联结。
Q学习更新价值表Q值的公式是:
新Q值=原Q值 + 学习率α *(奖励R + 折扣因子γ * 下步最大Q值 - 原Q值)
其中,括号里的内容叫做时序差分误差,简写为TD误差。
因此可以把上面的公式拆成两项,如下:
TD误差=(奖励R + 折扣因子γ * 下步最大Q值 - 原Q值)
新Q值=原Q值 + 学习率α *TD误差
其中:
奖励R:取值0或1,是达成目标时的奖励值,当老鼠找到食物时,奖励R的值为1,其他情况,奖励R的值为0。
折扣因子γ:取值0~1,是对下一步价值的折扣率,以权衡短期和长期奖励的重要性。折扣因子γ取值0.1和0.9分别对应了“短视”和“看长远”的情况。折扣因子γ越大,对未来奖励的重视程度越高,相反,折扣因子γ越小,越看中近期奖励。
经济学中的跨期选择和时间折扣与折扣因子γ 有类似的作用,都是用于衡量未来奖励或成本的重要性的参数。
有些人较有耐心,能放弃眼前的利益而去追求未来更大的收益,这些人的折扣因子γ较高。而孩童的折扣因子γ通常较低,他们很难拒绝眼前奖赏的诱惑,倾向于获得即时满足。
学习率α :取值0~1,是学习的效率,表示新获取的信息在多大程度上覆盖旧信息。学习率α值越大,学习效率越高。但是学习率不一定越大越好,过大的学习率容易被局部小奖励困住,从而错过别处的更大奖励。
较低等的动物,比如蜜蜂,学习率较高,能够仅仅通过一次停留就能将一朵花和奖励(花蜜)关联起来,而高等动物如哺乳动物的学习率比较低,需要经过多次接触才会建立联结,这样它们可以拥有更多的机会。
下步最大Q值:下一步在价值表中所对应的最大的一个Q值。
原Q值:在进行下一步之前,在价值表中当前行和当前列的Q值。
新Q值:使用Q学习公式计算出的新Q值,用来替换原Q值以更新价值表。
下面是Q学习的代码:
Sub Q学习(奖励R As Integer, 当前编号 As Integer, 当前表列号 As Integer, 下一步编号 As Integer)
Dim 学习率α As Single
Dim 折扣因子γ As Single
Dim 原Q值 As Single
Dim 下步最大Q值 As Single
Dim TD误差 As Single
学习率α = 0.1 '学习率,取值(0~1);越大学习越快,取较低的值0.1
折扣因子γ = 0.9 '折扣率,取值(0~1):越大越重视未来奖励,取较高的值0.9
原Q值 = Cells(价值表头行 + 当前编号, 价值表头列 + 当前表列号) '取得当前的价值Q
'以下是Q-Learning算法
If 奖励R = 0 Then '如果没有遇到“食物”
下步最大Q值 = Application.Max(Range(Cells(下一步编号 + 价值表头行, 价值表头列), Cells(下一步编号 + 价值表头行, 价值表头列 + 3))) '求最大值
TD误差 = 奖励R + 折扣因子γ * 下步最大Q值 - 原Q值 '计算TD误差
Else '如果遇到“食物”
TD误差 = 奖励R - 原Q值 '遇到"食物"后,本轮结束,所以计算时去掉了“下步最大Q值”
End If
Cells(当前编号 + 价值表头行, 当前表列号 + 价值表头列) = 原Q值 + 学习率α * TD误差 '更新价值表的Q值
Cells(当前编号 + 价值表头行, 当前表列号 + 价值表头列).Font.ColorIndex = 3 '把更新后的Q值改为红色
End Sub“Q学习”的程序结构很简单,取出价值表中指定行和指定列的Q值,然后用Q-learning算法计算出新的Q值。
计算时,遇到“食物”和没有遇到“食物”的TD误差的计算式有所不同:
没有遇到“食物”时,奖励R=0。由于任务还没有结束,需要继续走下一步,所以计算公式为:
TD误差=折扣因子γ * 下步最大Q值 - 原Q值
而当遇到“食物”时,奖励R=1。因为此轮任务已结束,无需走下一步了,所以公式中去掉“下步最大Q值”这一项,如下:
TD误差=奖励R - 原Q值
求得TD误差后,计算新Q值:
新Q值=原Q值 + 学习率α *TD误差
用Cells()语句把新的Q值写回到价值表中,覆盖掉“原Q值”。程序中把新写入的Q值改为红色,这样就可以直观看到价值表中有哪些值被更新了。
14 强化学习
在强化学习中,“Q学习”是一种时序差分算法,它的基本思想是,利用后续状态的价值估计来更新当前状态的价值估计,通过重复训练和反复迭代,从而使价值表中的Q值逐渐逼近真实值。
时序差分算法的核心在于差分计算,即计算当前状态和后续状态之间的差异,亦即Q-learning算法公式中的(下步最大Q值 - 原Q值)。时序差分算法会根据这个差分来更新价值表中的Q值。
如何取得这两项Q值呢?
假设老鼠处于迷宫中编号为4的单元格,它可以选择向右、下和左三个方向移动,如下图左半部分。
在右半部分的价值表中,老鼠的位置对应编号为4的行,三个可能的移动方向对应三个有效的Q值(图中被蓝绿色圈起来的三个值)。
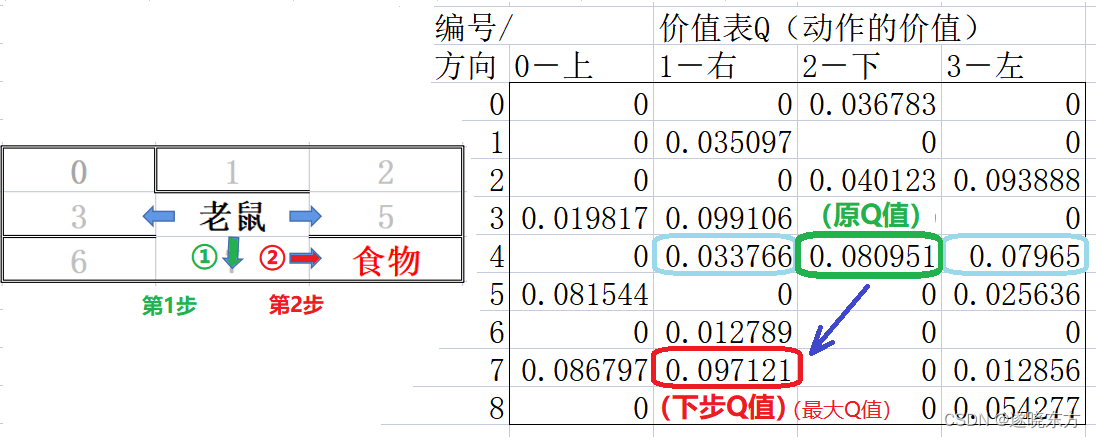
该取哪个值作为“原Q值”呢?只有在选定一个移动的方向后才能确定。
假设选择向下走,如左侧图中标号①的绿色箭头所指,则可以在右侧价值表中取得一个Q值,如图中绿色框圈住的数值,此值作为为“原Q值”。
老鼠从编号4向下移动一步后,将到达编号为7的单元格,对应价值表中行号为7的一行。在此位置也可以向三个方向移动,对应于价值表中的三个非0的Q值。
需要再得到一个Q值,才能进行差分计算,所以必须再选定下一个移动方向。根据Q学习算法,在该行三个Q值中选取最大的一个作为“下步Q值”,如右侧图中红色框圈住的数值,这个最大的Q值在价值表中第1列,对应着向右移动。即左侧图中标号②的红色箭头所指的方向。
可见,在任何位置,需要移动两步得到两个Q值,才能进行价值的差分计算。
计算价值差分并更新Q值的程序流程框图如下:
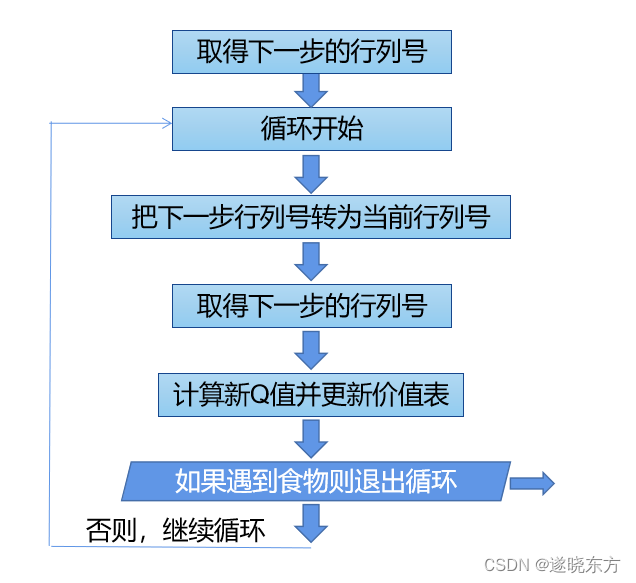
以上流程的执行过程是:老鼠从第一个位置开始,先移动两步,取得两个Q值,一个为“原Q值”,另一个为“下步Q值”(下步Q值取的是当前行的最大值),通过计算价值差分得到“新Q值”,并用“新Q值”更新“原Q值”。
然后进入一个循环过程,先把上一步的“下步Q值”变成“原Q值”,然后再移动一步,得到一个新的“下步Q值”,重新计算“新Q值”,更新“原Q值”。一直如此循环,直到遇到“食物”为止。
程序中通过调用“探索与利用”函数取得下一步的行号和列号。
调用“Q学习”过程计算新Q值并更新原Q值。
实现以上过程的代码如下:
Sub 强化学习()
Dim 当前行号 As Integer '老鼠移动前位置行号
Dim 当前列号 As Integer '老鼠移动前位置列号
Dim 下步行号 As Integer '老鼠移动后位置行号
Dim 下步列号 As Integer '老鼠移动后位置列号
Dim 当前编号 As Integer '当前位置编号(=价值表行号)
Dim 下步编号 As Integer '下一个位置编号(=价值表行号)
Dim 当前表列号 As Integer '当前位置在Q表中的列号
Dim 下步表列号 As Integer '下一个位置在Q表中的列号
Dim 奖励R As Integer '奖励值
下步行号 = 迷宫头行 '把下一步的行号设为迷宫起始行号
下步列号 = 迷宫头列 '把下一步的列号设为迷宫起始列号
Cells(下步行号, 下步列号) = "" '擦掉初始位置的老鼠,写入空字符""
下步编号 = (下步行号 - 迷宫头行) * 3 + (下步列号 - 迷宫头列) '计算迷宫当前位置编号
下步表列号 = 探索与利用(下步行号, 下步列号) '调用“探索与利用”取得下一步的方向对应的列号
Do While True '无限循环
当前行号 = 下步行号 '把下一步行号转为当前行号
当前列号 = 下步列号 '把下一步列号转为当前列号
当前编号 = 下步编号 '把下一步迷宫编号转为当前迷宫编号
当前表列号 = 下步表列号 '把下一步价值表的列号转为当前表列号
If Cells(下步行号, 下步列号) = "食物" Then '如果到达食物奖励点(终点)
奖励R = 1 '设定奖励值为1
Q学习 奖励R, 当前编号, 当前表列号, 下步编号 '调用“Q学习”过程,更新价值表Q值
Cells(下步行号, 下步列号) = "老鼠" '在终点画出新老鼠
Cells(下步行号, 下步列号).Font.ColorIndex = 5 '把终点的老鼠变为蓝色
延时 (0.5) '延时0.5秒
Exit Do
Else '如果没有“食物”,则:
奖励R = 0 '奖励值为0
下步编号 = (下步行号 - 迷宫头行) * 3 + (下步列号 - 迷宫头列) '计算下一步位置编号
下步表列号 = 探索与利用(下步行号, 下步列号) '调用“探索与利用”取得再下一步的方向列号
Q学习 奖励R, 当前编号, 当前表列号, 下步编号 '调用“Q学习”过程,更新价值表Q值
Cells(当前行号, 当前列号) = "" '擦掉当前位置的老鼠
If Cells(下步行号, 下步列号) <> "食物" Then '如果该位置没有"食物",则画老鼠
Cells(下步行号, 下步列号) = "老鼠" '在下一步的位置画出新老鼠
Cells(下步行号, 下步列号).Font.ColorIndex = 1 '设老鼠颜色为黑色
End If
End If
延时 (0.05) '延时0.05秒
Loop
End Sub15 主程序
主程序设定了一个“训练次数”变量,取值10次。然后循环10次调用“强化学习”过程。
以下是初始化过程及主程序代码。为了避免因缺少代码而导致程序无法运行,后面列出了所需的函数即过程的定义头部分。大家在三篇教程中找到这些函数和过程,把代码录入或粘贴进去即可。
'以下定义常量
Const 迷宫头行 = 4 '迷宫左上角的行号
Const 迷宫头列 = 2 '迷宫左上角的列号
Const 参数表头行 = 4 '动作参数表左上角行号
Const 参数表头列 = 8 '动作参数表左上角列号
Const 策略表头行 = 16 '策略表π左上角行号
Const 策略表头列 = 2 '策略表π左上角列号
Const 价值表头行 = 16 '价值表Q左上角行号
Const 价值表头列 = 8 '价值表Q左上角列号
Sub 初始化()
Range(Cells(2, 1), Cells(26, 12)).Clear '清空指定矩形区域
画迷宫 '调用“画迷宫()”过程
画动作参数表 '调用“画动作参数表()”过程
画策略表 '调用“画策略表()”过程
画价值表 '调用“画价值表()”过程
End Sub
Sub 主程序()
Dim 训练次数 As Integer '运行轮次数
Dim 当前次数 As Integer '
初始化 '调用“初始化”过程
Cells(迷宫头行 - 1, 迷宫头列 + 0) = "训练次数:" '写字符串"训练次数:"
训练次数 = 10 '指定本轮训练次数
For 当前次数 = 1 To 训练次数 '循环训练10次
Range(Cells(2, 1), Cells(26, 12)).Font.ColorIndex = 1 '将指定矩形区域字符设为黑色
画迷宫 '调用“画迷宫”过程重绘迷宫
延时 (0.5) '延时0.5秒
Cells(迷宫头行 - 1, 迷宫头列 + 1) = 当前次数 '写当前训练次数
' 随机行走 '随机走迷宫
强化学习
Next 当前次数
End Sub
Sub 画迷宫()
End Sub
Sub 画策略表() '设置动作方向的平均概率
End Sub
Function 策略选择(位置编号 As Integer) As Integer
End Function
Sub 下一步位置(当前方向 As Integer, ByRef 当前行 As Integer, ByRef 当前列 As Integer)
End Sub
Sub 随机行走()
End Sub
Sub 延时(T As Single)
End Sub
Sub 画价值表()
End Sub
Function 价值选择(位置编号 As Integer) As Integer
End Function
Function 探索与利用(ByRef 当前行 As Integer, ByRef 当前列 As Integer) As Integer
End Function
Sub Q学习(奖励R As Integer, 当前编号 As Integer, 当前表列号 As Integer, 下一步编号 As Integer)
End Sub
Sub 强化学习()
End Sub我们按F5运行这个主程序,发现,一开始时,老鼠像没头苍蝇一样随机乱跑,但是,随着训练次数的增加,老鼠逐渐找到吃到食物的最短路径,并倾向于按这条路径行走。
从价值表中也能看出,最短路径所对应的Q值在逐渐增加,离食物越近,Q值增加得越快。如下图:
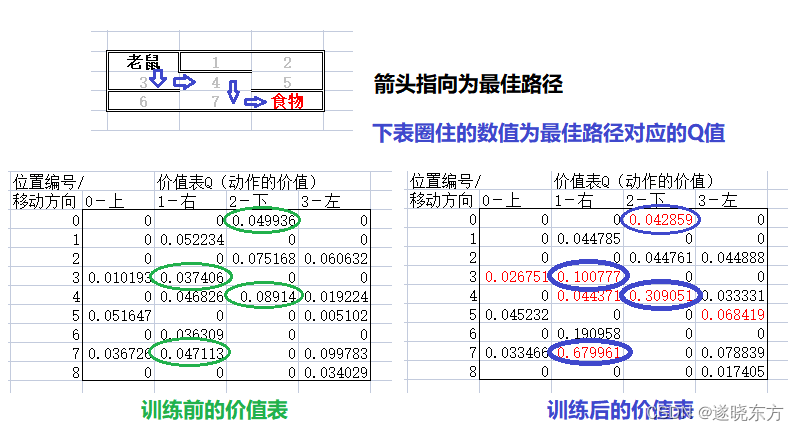
我们编写的这个强化学习程序适应性很强,即使改变食物的位置,也无需修改程序,老鼠依然能找到最短的路径。
还可以随意改变迷宫内部墙的数量和位置,也可以增加食物的数量,同样无需修改程序,老鼠都能找到最佳的路径。
修改“画迷宫”过程的代码,可以改变“食物”和迷宫内墙的数量和位置。下面是一个修改后的代码,画出一个新迷宫:
Sub 画迷宫()
Dim 迷宫行号 As Integer '迷宫内部的相对行号
Dim 迷宫列号 As Integer '迷宫内部的相对列号
Dim 迷宫编号 As Integer '迷宫内单元格的编号
'以下画迷宫边框,并设置迷宫区域字体属性
With Range(Cells(迷宫头行, 迷宫头列), Cells(迷宫头行 + 2, 迷宫头列 + 2))
.BorderAround LineStyle:=xlDouble '在迷宫四边框画双线
.HorizontalAlignment = xlCenter '设字符居中
.Font.ColorIndex = 15 '设字体为灰色
.Font.FontStyle = "Bold" '设字体为粗体
End With
'以下画迷宫内部墙
Cells(迷宫头行 + 0, 迷宫头列 + 0).Borders(xlEdgeRight).LineStyle = xlDouble '右侧画双线边框
Cells(迷宫头行 + 0, 迷宫头列 + 1).Borders(xlEdgeLeft).LineStyle = xlDouble '左侧画双线边框
Cells(迷宫头行 + 1, 迷宫头列 + 0).Borders(xlEdgeBottom).LineStyle = xlDouble '下边画双线边框
Cells(迷宫头行 + 2, 迷宫头列 + 0).Borders(xlEdgeTop).LineStyle = xlDouble '上边画双线边框
Cells(迷宫头行 + 1, 迷宫头列 + 1).Borders(xlEdgeTop).LineStyle = xlDouble '上边画双线边框
Cells(迷宫头行 + 0, 迷宫头列 + 1).Borders(xlEdgeBottom).LineStyle = xlDouble '下边画双线边框
Cells(迷宫头行 + 2, 迷宫头列 + 1).Borders(xlEdgeRight).LineStyle = xlDouble '右侧画双线边框
Cells(迷宫头行 + 2, 迷宫头列 + 2).Borders(xlEdgeLeft).LineStyle = xlDouble '左侧画双线边框
'以下画迷宫内部单元格的编号
迷宫编号 = 0 '设迷宫编号的初始值为0
For 迷宫行号 = 0 To 2 '迷宫当前行号=0,1,2
For 迷宫列号 = 0 To 2 '迷宫当前列号=0,1,2
Cells(迷宫头行 + 迷宫行号, 迷宫头列 + 迷宫列号) = 迷宫编号 '画迷宫内单元格的编号
迷宫编号 = 迷宫编号 + 1 '修改迷宫编号变为当前值+1
Next 迷宫列号
Next 迷宫行号
'以下写"老鼠"和"食物"
Cells(迷宫头行, 迷宫头列) = "老鼠" '在迷宫0号单元格写“老鼠”
Cells(迷宫头行, 迷宫头列).Font.ColorIndex = 1 '字体设为黑色
Cells(迷宫头行 + 0, 迷宫头列 + 1) = "食物" '在迷宫8号单元格写“食物”
Cells(迷宫头行 + 0, 迷宫头列 + 1).Font.ColorIndex = 3 '字体设为红色
End Sub画出的迷宫如下图,无需修改程序,老鼠依然能学会找到食物的最佳路径。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









