







目录
一、Linux编译器 gcc/g++
基本定位:
1.我们已经能够使用vim在Linux下写代码了,接下来编译代码就要靠gcc/g++了,gcc/g++是Linux下的编译器,gcc只能编译C语言代码,不能编译C++代码,而g++既可以编译C语言代码,也可以编译C++代码
2.C源文件后缀是.c, C++源文件后缀是 .cpp / .cc / .cxx, 没有区别,只是使用习惯不同~
3.gcc/g++编译源文件可以指定形成的可执行程序的名称
4.如果用gcc编译c源文件报错,则采用 gcc test.c -std=c99



程序的翻译过程
1.编程语言/编译器的自举过程
早期只有二进制语言,后来人们觉得太麻烦了,于是发明了汇编语言,而机器只认识二进制语言,于是需要把汇编语言翻译成二进制语言,机器才能识别,因此人们用二进制语言写了一个简单的二进制编译器,把汇编翻译成了二进制,从此之后,就可以用汇编语言写一个编译器(编译器也是软件),叫做汇编编译器;
之后又出现了C/C++语言,人们用汇编语言写了一个简单的C/C++编译器,把C/C++语言翻译成汇编语言,汇编编译器再把汇编语言翻译成二进制语言,从此就可以用C/C++写编译器了,叫做C/C++编译器,这个过程叫做语言/编译器的自举过程
2.程序翻译的过程
(1)翻译过程理论
翻译过程就指的是将我们写的C/C++语言代码,翻译成机器可以认识的二进制语言的过程, 中间经历了下面四个阶段;之所以要经历好几个阶段,而不是从c语言直接到二进制文件,就是因为历史是这么发展过来的,我们可以站在巨人的肩膀上!
预处理
变化: code.c -> code.i 预处理完之后还是c语言
具体行为:
a.头文件展开
b.宏替换
c.去注释
d.条件编译
编译
变化: code.i -> code.s C语言变成了汇编语言
汇编
变化: code.s -> code.o 汇编语言变成了可重定位二进制文件
链接
变化: code.o -> a.out 二进制文件变成可执行程序
(2)翻译过程实操
gcc code.c -o mybin 这样会一次性把预处理,编译,汇编,链接的工作全部做完,不便于我们观察每个阶段,因此我们给gcc 后面带上不同选项,就可以让程序翻译到指定阶段就停下来~
指令操作
预处理 gcc -E code.c -o code.i
编译 gcc -S code.i -o code.s
汇编 gcc -c code.s -o code.o
链接 gcc code.o -o a.out
①预处理:
gcc -E code.c -o code.i
-E就是告诉gcc,翻译工作做到预处理完,就停下来,不要继续往后了!
-o就是指定生成的目标文件的名称
展开头文件,去注释,宏替换

图中已说明了头文件展开的本质就是拷贝头文件内容到源文件中, 因此linux系统肯定会去特定的路径下搜索头文件,进而拿到头文件内容~
条件编译

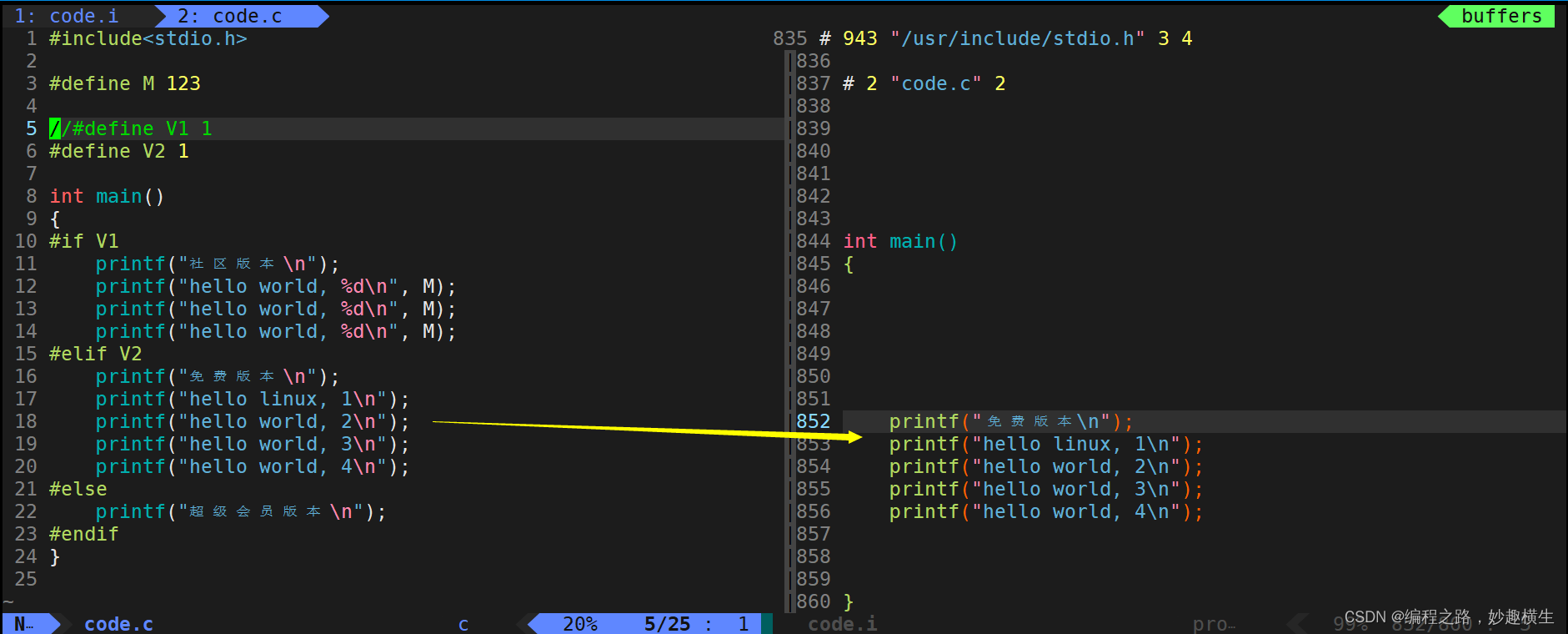

可以看到,通过条件编译,我们就可以实现对代码的动态裁剪
现实中有很多的软件都有专业版/社区版,只是功能有所差异,如果维护两份代码的话成本太高,因此可以通过条件编译选择性保留某些功能,这样就只需要一份源代码了~
②编译
gcc -S code.i -o code.s

③汇编
④链接

ps: 直接vim code.o 或者 vim a.out 是乱码,我们可以采用 od 查看二进制文件
小贴士:二进制文件不具有可执行功能
(3)详解链接过程
·对库的理解
我们在c语言中已经学过了不少库函数,库函数本质就是有一些高频并且需要被人大量使用的函数,有人帮我们把他们实现好了,我们就无需再实现,只需要调用即可,这样的话既提高了效率,又减少了bug的产生,而这批库函数就是以库的形式呈现给我们的
ldd 指令 查看一个可执行程序所依赖的第三方库的信息
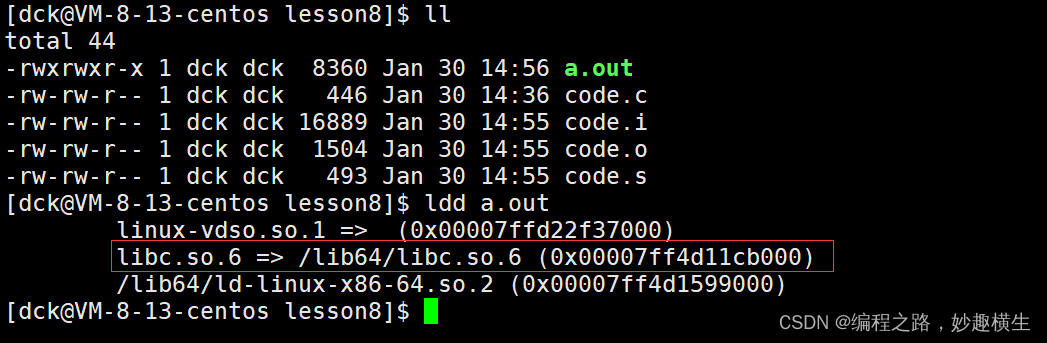
我们的代码+头文件+库文件 = 可执行程序
所以安装开发环境本质就是下载并安装头文件和库文件到开发环境的指定路径下,一定要被编译器自己能够找到!
·库的分类
libc.so.6。 库一般以lib开头,so 表明是库的类别是动态库, 6是版本号,一个库真正的名字是去掉前后缀,所以 libc.so.6 其实就是c标准库
Linux中 .so 是 动态库 ;.a 是 静态库, ll /lib64/* 可以看到动态库很多,静态库比较少
windows中 xxxx.dll是动态库,YYYY.lib是静态库
·动静态库的概念
1.动态库是C/C++或者其他第三方提供的所有方法的集合,被所有程序以链接(动态链接)的方式,关联起来
动态链接 ---》 每个函数在被编译器编译形成库的时候都有地址,库中所有的函数,都有入口地址,所谓的动态链接,其实就是要把连接的库中的函数地址拷贝到我们可执行程序的特定位置
2. 静态库是C/C++或者其他第三方提供的所有方法的集合,被所有程序以拷贝的方式,将需要的代码,拷贝到自己的可执行程序中!
静态链接 ---》 静态库的存在是为了被拷贝
·动静态库的优缺点
·动态库
优点:形成的可执行程序体积小, 节省资源(磁盘+内存)
因为只需要拷贝函数地址,所以体积小,由于可执行程序文件,要被保存在磁盘上,所以节省磁盘空间,又因为程序在被运行的时候要先被加载到内存中,所以体积小的话也节省内存空间
缺点:强依赖动态库,动态库没了,所有的依赖这个库的程序都无法运行了
·静态库
优点:无视库,可以独立运行
缺点:体积太大,浪费资源
·测试动静态库

默认情况下,云服务器是没有安装c静态库的,只有动态库,也就是说编译器默认链接的方式是动态链接,就是因为静态库的体积太大了!
总结
开发环境默认做以下几点:
1.下载开发环境 include, lib等
2.设置合理的查找路径
3.规定好形成可执行程序的链接方式
二、自动化构建代码 make/Makefile
我们已经能够在vim中编写代码了,也能够用gcc/g++编译代码了,而linux还给我们提供了自动化构建代码和自动化清理的方案,具体含义如下:
make是一个命令,Makefile是一个在当前目录下存在的一个具有特定格式的文本文件
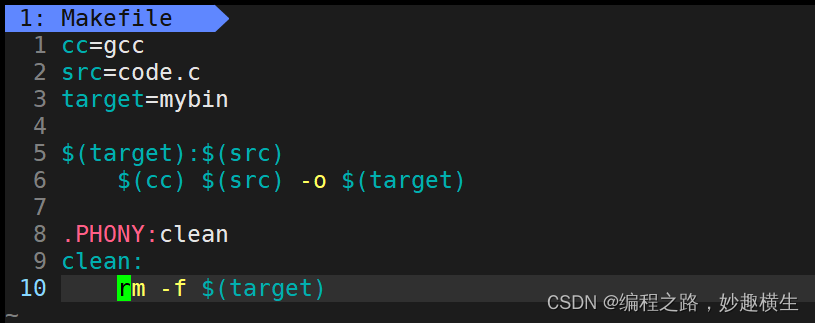
Makefile 内容模板
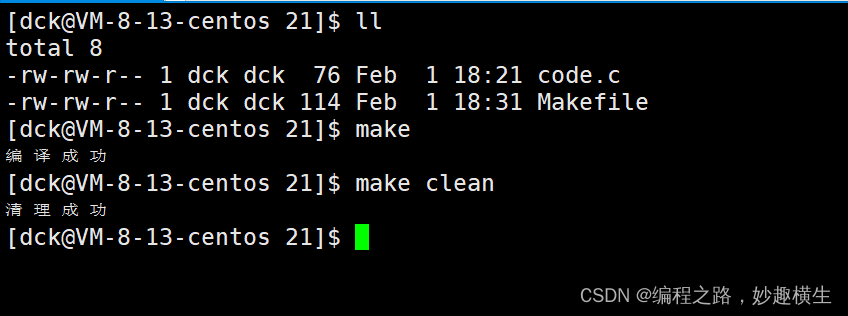
自动化构建与清理演示
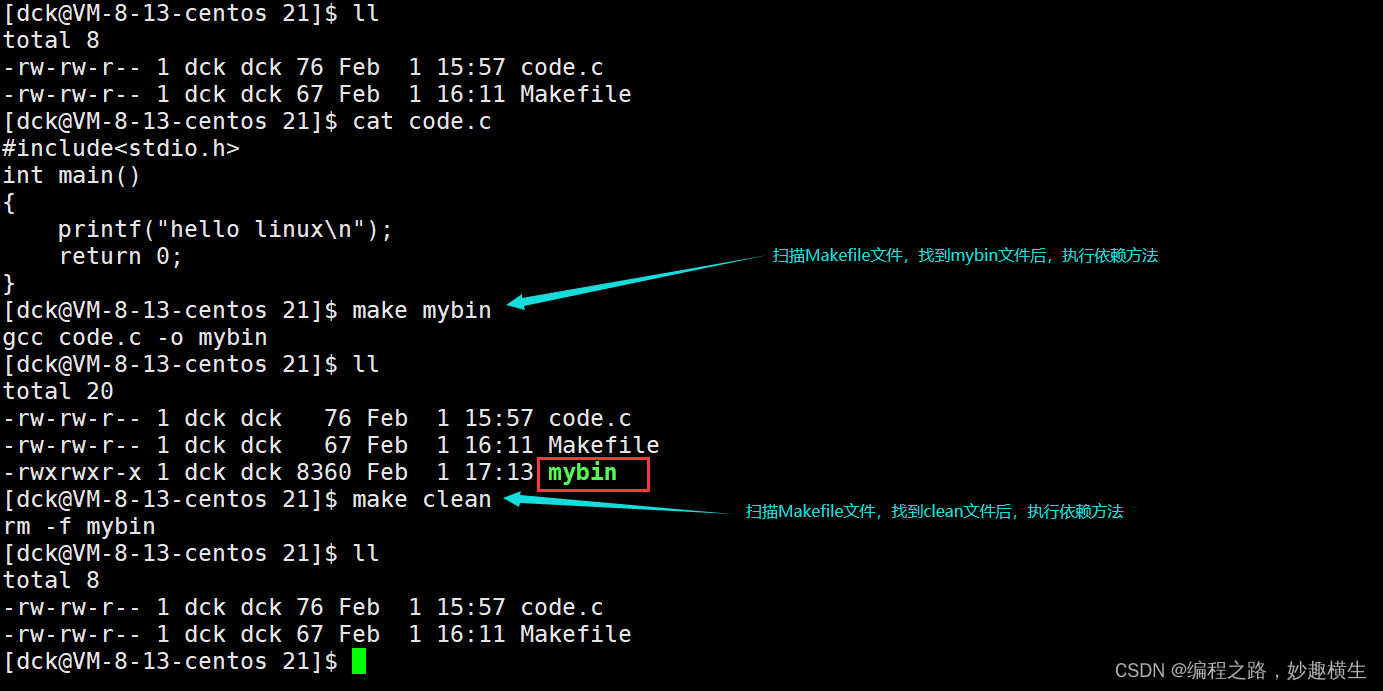
其中,只写make会扫描Makefile中从上到下遇到的第一个目标文件,并执行依赖方法
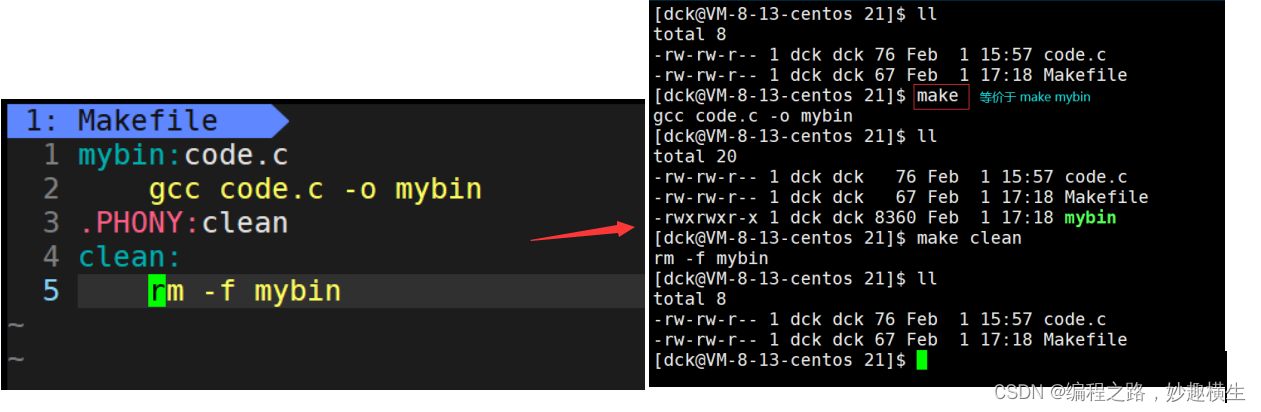
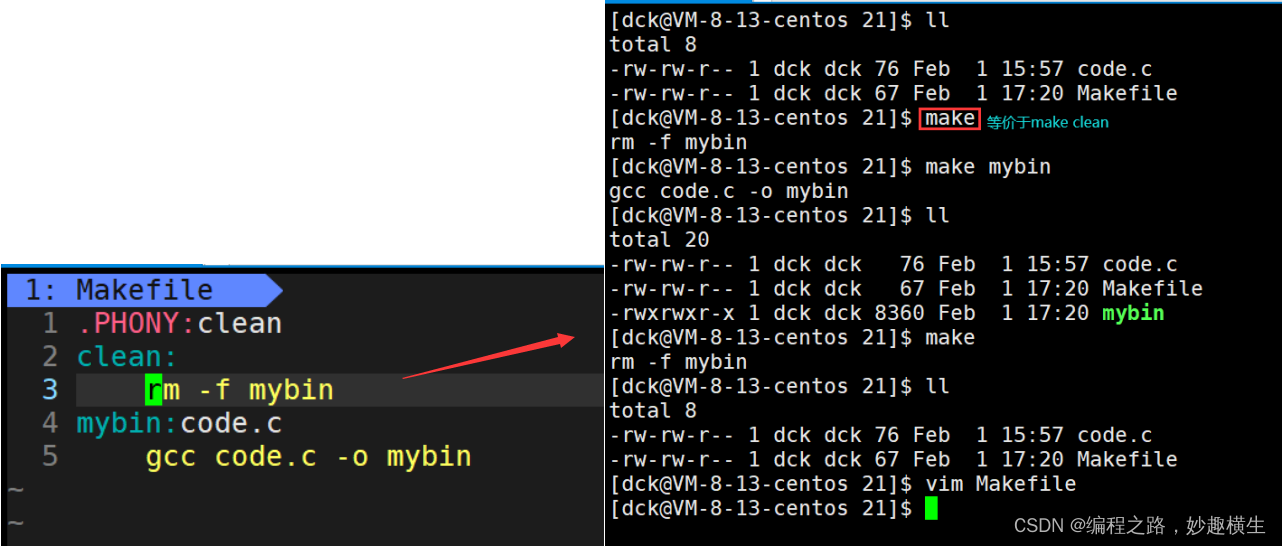
.PHONY 修饰的伪目标表示总是被执行的含义:
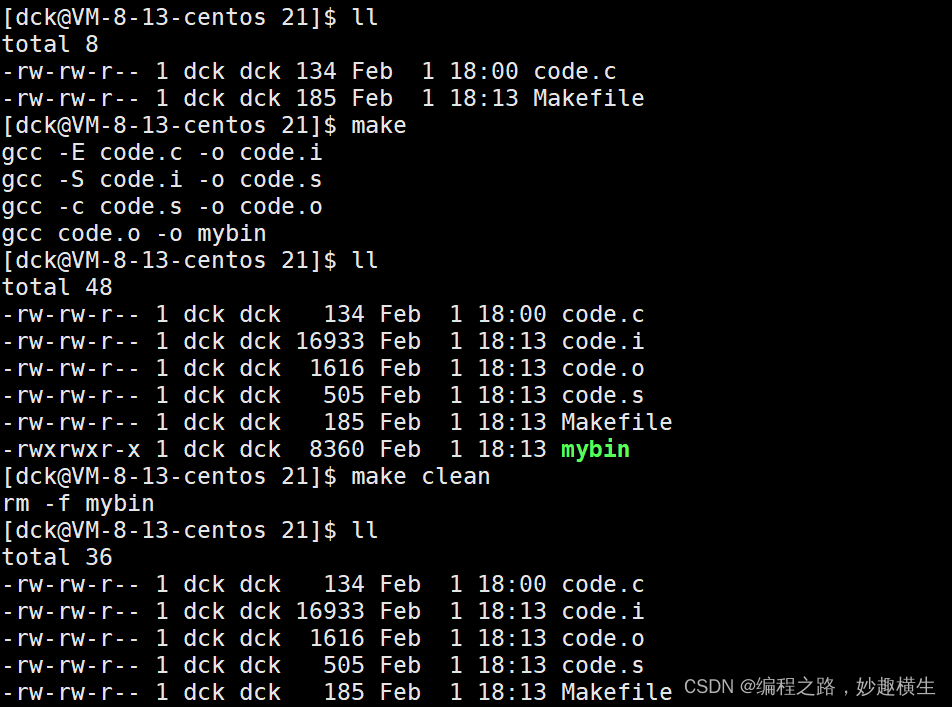
1.现象
第一次make的时候可以编译,第二次make就编译不通过了

而当我修改了源文件code.c的内容之后又能够编译了,但是再编译又不行了~

说明了make/Makefile能够识别出文件新旧,如果是旧文件就不编译了,因为当源文件比较多的时候都重新编译太耗费时间了,会降低编译效率!但是make/Makefile是如何识别文件新旧的呢??是通过对比可执行程序mybin和源文件的时间来确定文件新旧的!
2.文件的acm时间

Access 文件最近被访问的时间(包括ls, cd, cat, vim等)
Modify 文件最近的内容修改时间
Change 文件最近的属性修改时间
①直接修改文件属性,Ctime变了,MTime一般不变

②改变文件内容,Mtime变化,ATime和CTime也联动式地变化(比如文件大小)
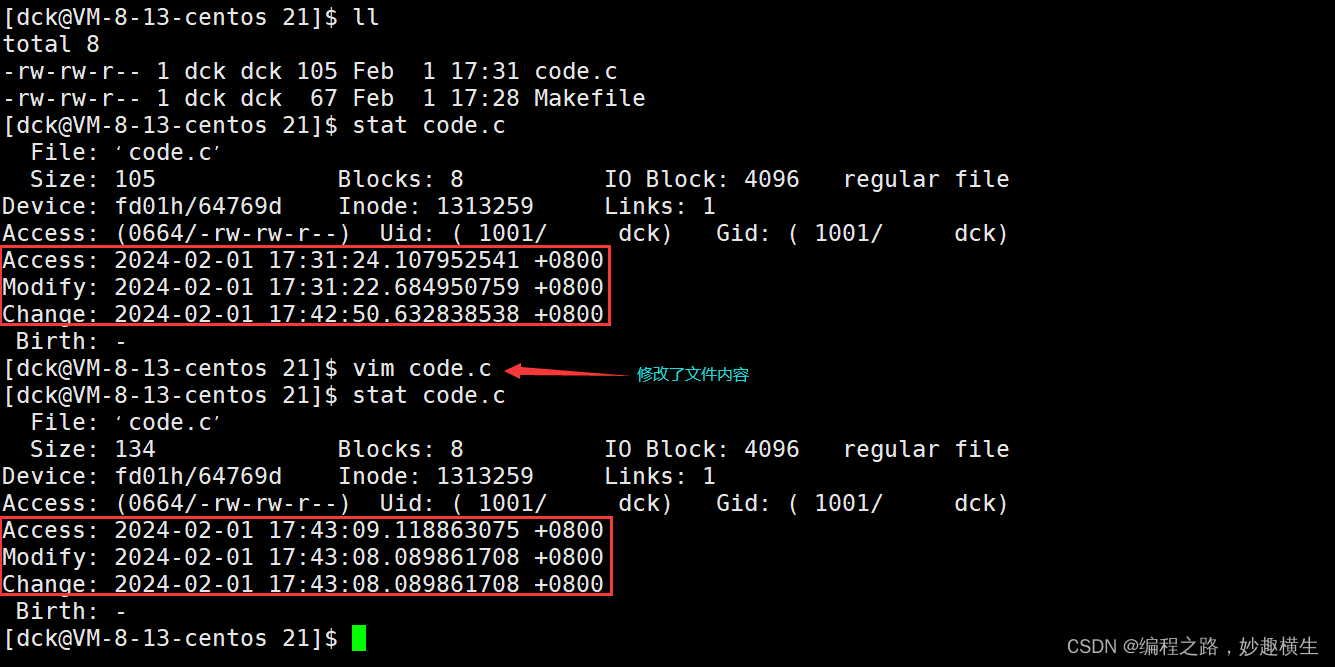
③访问文件,Atime有时变,有时不变
大多数情况下对一个文件最频繁的操作就是查看文件,而文件保存在磁盘上,访问磁盘的效率是表低下的,因此如果每次查看文件都要更改文件的Atime, 本质就是访问磁盘,减缓了操作系统效率,因此系统对于更改Atime添加了次数限制
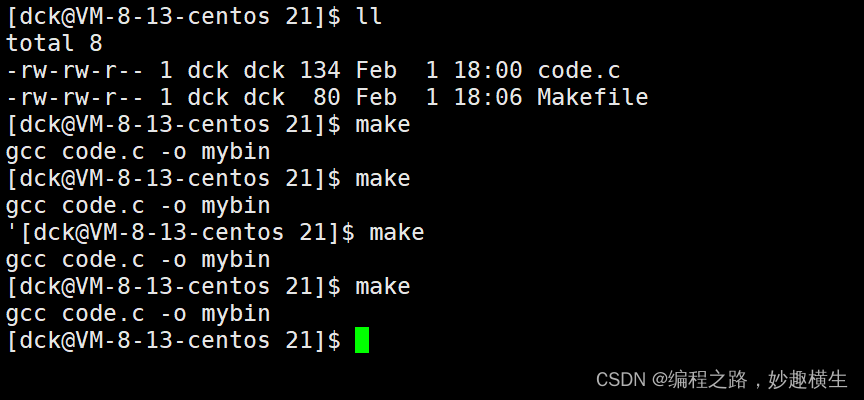
3.总是被执行的含义
上面提到,make/Makefile 是通过对比源文件和可执行程序的时间来确定要不要编译,而这个时间就指的是Mtime, 如果源文件时间 < 可执行程序,说明这个源文件已经是最新编译过的,将不再重新编译,如果原文件时间 > 可执行程序,说明这个源文件是新创建的,还没有被编译过,因此要编译!

总是被执行的含义就是如果被.PHONY 修饰,依赖方法总是执行,不被任何情况拦截(比如文件时间的前后关系)

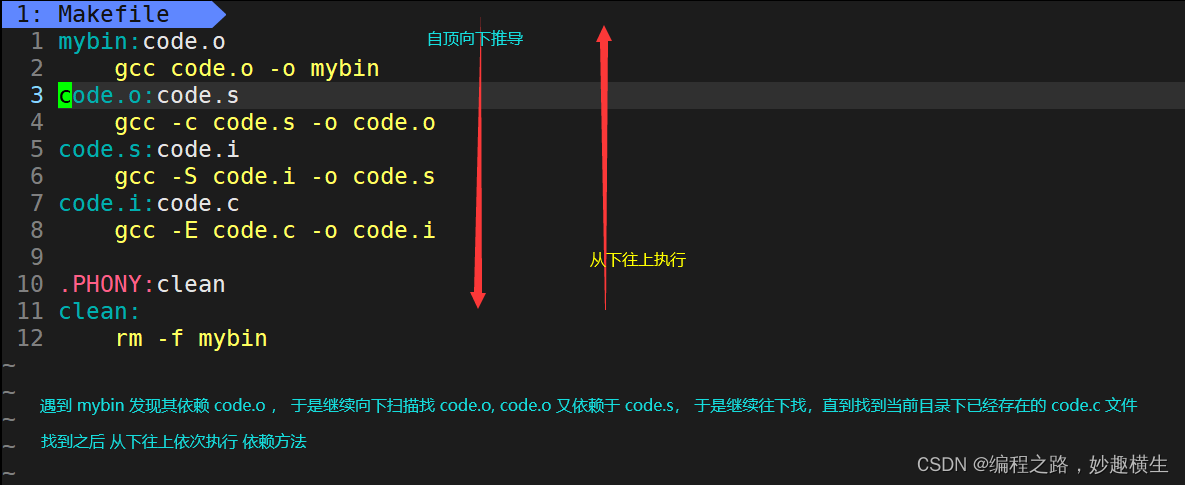
make/Makefile的自动推导能力
Makefile 的一些语法细节
1.让指定的依赖方法不回显


现在不想让执行的指令以及echo语句本身显示出来,只想让echo打印的内容显示出来,这时可以在依赖方法前面加@

2.变量/宏的替换

3.依赖关系的简写


当然也可以把上面两个语法细节结合起来写~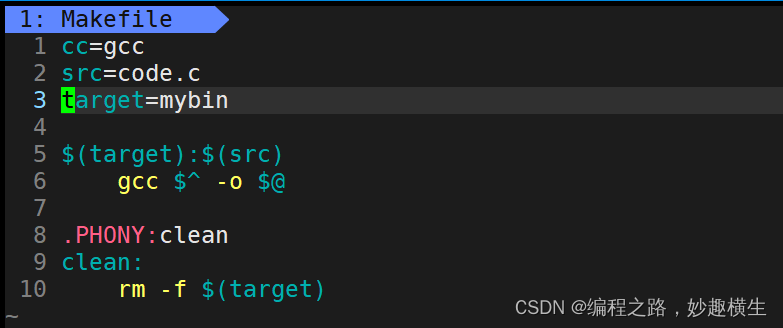

三、Linux第一个小程序---进度条
补充知识:
1.缓冲区
第一个程序:

第二个程序:

问题是第2个程序,执行流程肯定是顺序结构,先执行打印语句,但现象是先睡眠了两秒钟,说明打印出的内容只是暂时没有显示到屏幕上罢了,实际上打印的内容暂存在了缓冲区中,我们可以采用刷新缓冲区的方式来让打印内容立即显示到屏幕上!

而第一个程序之所以立马显示打印内容,是因为\n也是一种刷新缓冲区的方式,叫做行刷新!
2.回车换行
回车和换行其实是两个操作,不过C语言中的 \n 把两个操作都给做了,因此,如果我们只想回车(回到该行最开始) 而不到下一行, 可以用\r
倒计时程序

版本一:简单原理版本
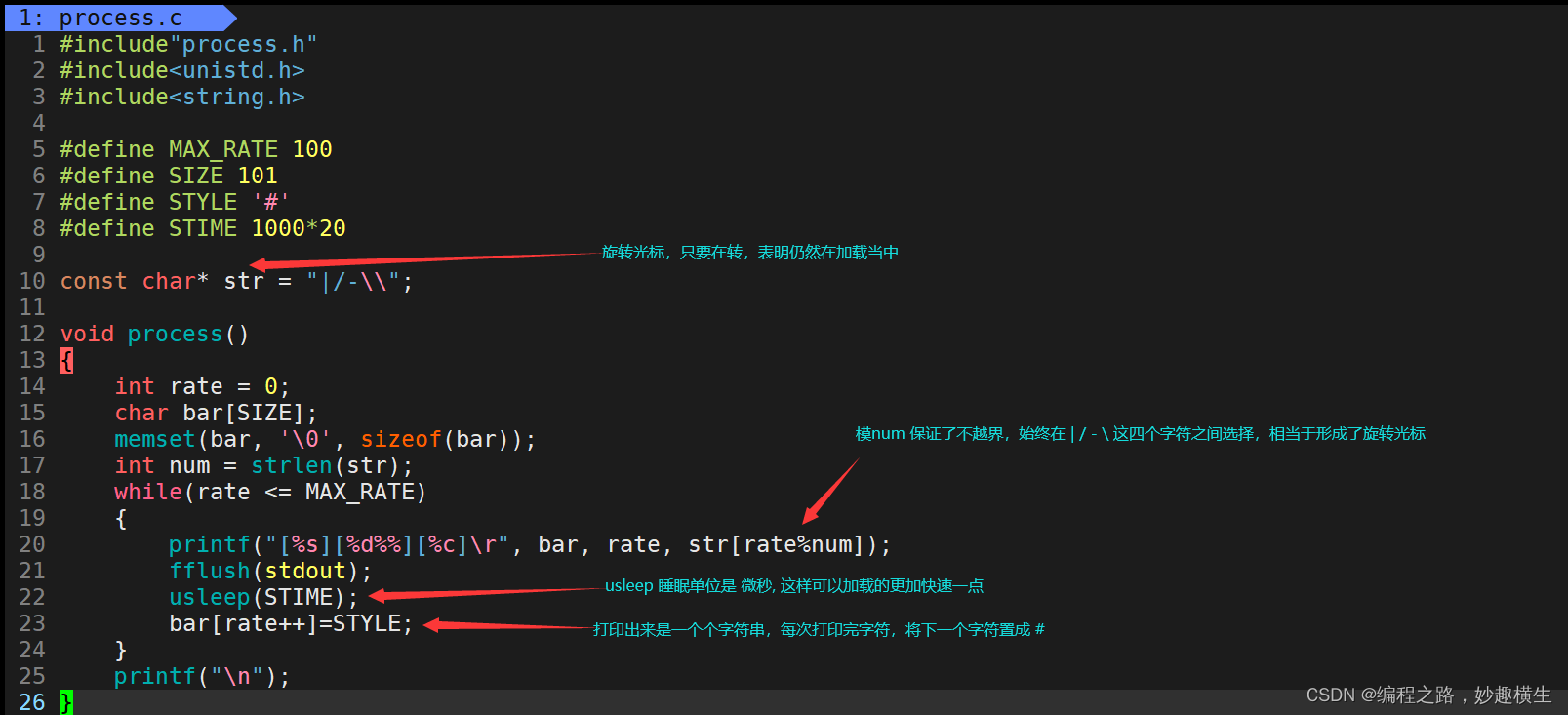

版本二:实际工程实践版本
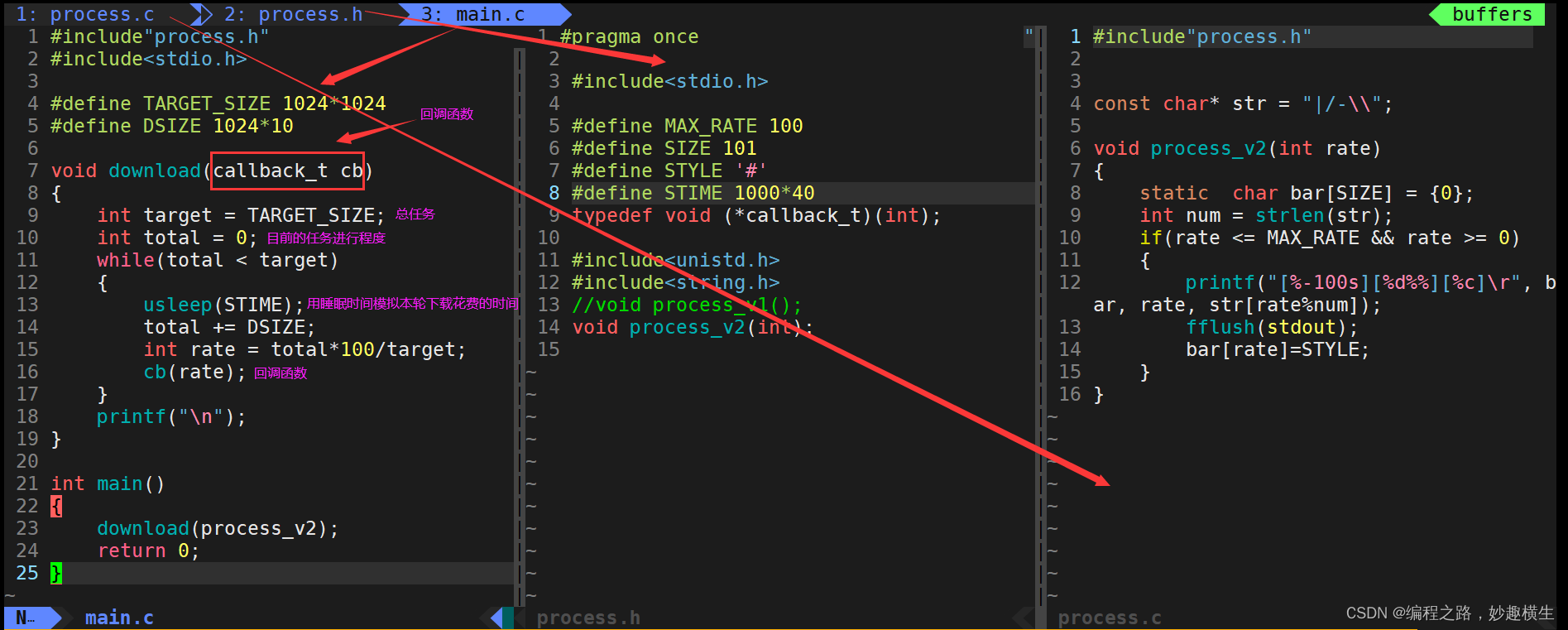
版本三:美化版本



















 1478
1478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









