






Linux机器学习环境配置
一、 实验目的:
1. 熟悉虚拟机软件的安装和使用;
2. 熟悉Linux操作系统的安装和使用;
3. 熟悉SSH方式远程登录Linux系统的方法;
4. 掌握Linux操作系统中Python及机器学习相关库的安装和使用;
5. 熟练掌握Linux操作系统中Anaconda的安装使用。
6. 熟练掌握Linux操作系统中Jupyter Notebook的安装使用。
二、实验要求:
1. 安装完成虚拟机软件;
2. 安装完成Linux操作系统;
3. 能用SSH方式远程登录Linux系统;
4. 安装完成Linux操作系统中Python及机器学习相关库;
5. 安装配置完成Linux操作系统中Anaconda。
6. 能使用Linux操作系统中Jupyter Notebook。
7. 完成Jupyter Notebook中一个简单机器学习算法。
- 实验工具与环境
- PC机
- Linux操作系统
- 浏览器:Internet Explorer、Firefox
- 其它软件:虚拟机软件、Centos文件包、putty、Python、Anaconda、Jupyter Notebook
四、实验步骤与内容:
1. 在你的Windows(或MacOS)操作系统安装虚拟机软件;
2. 在虚拟机软件中安装ubuntu虚拟机,安装时创建一个具有管理员权限的用户,后续的操作均以该用户登录;
3. 在ubuntu虚拟机中安装Python及机器学习相关库;
4. 在ubuntu虚拟机中安装并配置Anaconda的主目录;
6. 在ubuntu虚拟机中启动Jupyter Notebook服务,在宿主机中通过浏览器访问该服务器。(在Windows中远程连接Linux服务器的Jupyter),方法如下:
a) jupyter默认只能本地访问,如果想把它安装在服务器上,远程访问,如下配置:
步骤一:先创建配置文件: 在命令行窗口执行 $ jupyter notebook --generate-config
步骤二:启动ipython(在终端输入ipython)
创建远程连接密码: In [1]: from notebook.auth import passwd; passwd()
输入两次密码,将得到一个字符串,比如'argon2:$argon2id$v=19$m=10240,t=10,p=8$+eo4ymdFe9+O3enjhFik9g$qMwRGs/Ldq3YjbuGgmn5Xw',该终端不要关掉,复制该字符串,后面会用到;
exit() #退出
步骤三:打开配置文件,$ vim ~/.jupyter/jupyter_notebook_config.py,复制以下内容粘贴到配置文件中
c.NotebookApp.ip = '*' #允许所有ip访问
c.NotebookApp.password = u'刚才的密文'
c.NotebookApp.port = 8888 #指定一个商品,随便指定
c.NotebookApp.open_browser = False #不打开浏览器
c.InteractiveShellApp.matplotlib = 'inline' #直接显示matplotlib图形
步骤四:重新启动jupyter notebook #无界面
步骤五:本地访问http://localhost:8888
大家互相之间用windows客户端访问其它同学的服务器:http://服务器ip:8888
查看ip命令:ip address show
7. 在Jupyter Notebook中创建一个笔记文件,在其中完成一个简单K-Means聚类的例子,将30组随机生成的二维无标签数据分成两类,输出聚类参数及聚类模型图。
五、实验结果&总结(文件名以学号进行命名):
(列出实验过程中的收获和遇到的困难)
实验一:熟悉虚拟机软件的安装和使用
在windos中的官网中安装虚拟机,并按要求步骤安装
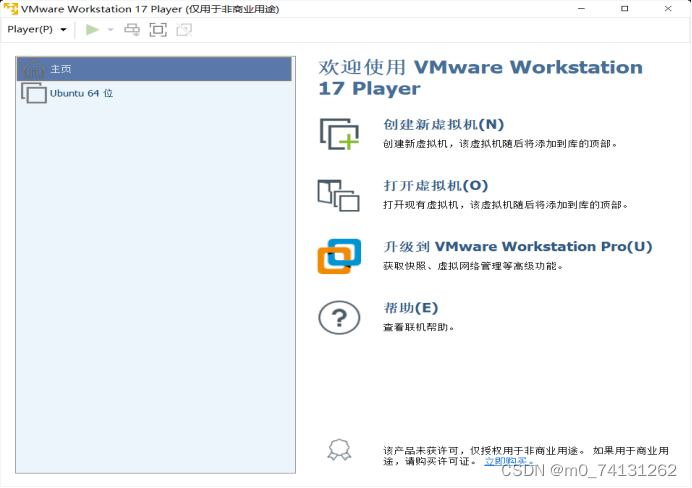
实验二:安装完成Linux操作系统
(1)点击创建新的虚拟机
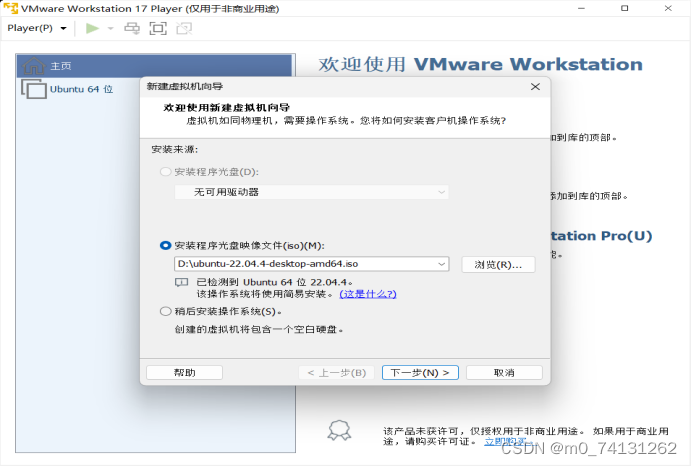
(2)我们需要一个Linux操作系统的光盘镜像文件,比如Ubutu、CentOS、Debian、红帽操作系统等。各有各的优势,这里我们演示的是ubutu操作系统。如
(3)要步骤创建好ubuntu虚拟机
(4)安装成功后,有很多人都困扰的一个问题是该操作系统是全英文的,我们非常需要将其修改成中文的,这里步骤稍微有点麻烦许多朋友都折腾老半天才改好。
因为网络上许多教程,我也不一一演示,这里推荐一个比较详细的教程:Ubuntu设置中文界面_ubuntu中文界面-CSDN博客,按该步骤即可完成。
实验三:能用SSH方式远程登录Linux系统
(1)、 确保 Linux 服务器已启用 SSH
首先,确保 Linux 服务器上已经安装并运行了 SSH 服务。可以使用以下命令来安装它:
sudo apt-get update
sudo apt-get install openssh-server
(2)确保 SSH 服务正在运行:
sudo service ssh status
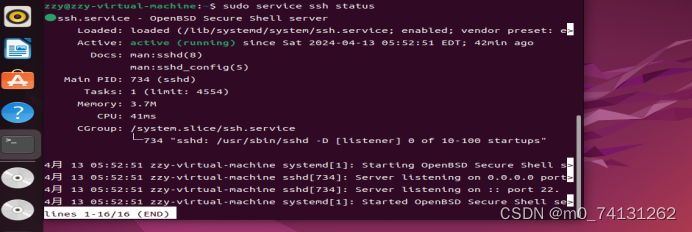
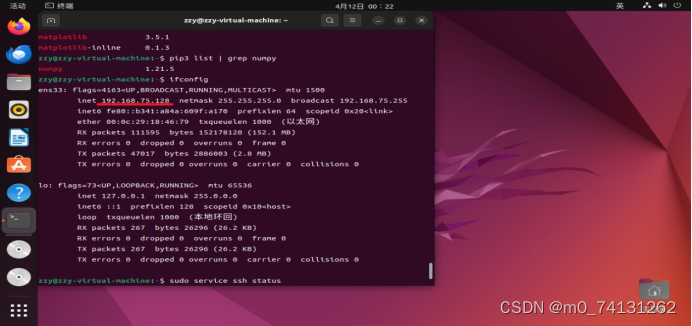
- 查看IP地址
输入命令:ifconfig
- 在本地windos操作系统中打开操作命令
输入:ssh 用户名@id
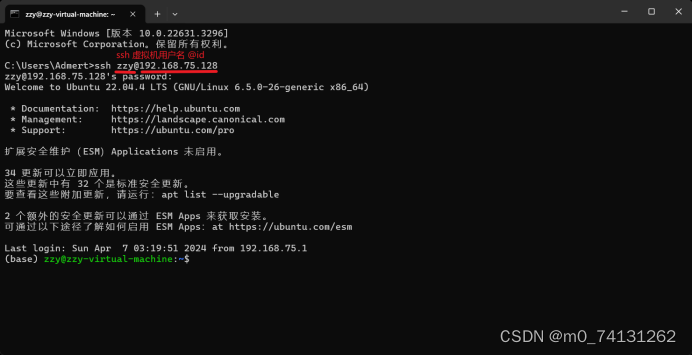
出现这样的就表明远程连接成功。
实验四:安装完成Linux操作系统中Python及机器学习相关库
Python及机器学习相关库有numpy、 matplotilb、 Mahotas、 Scikit-learn、scipy等很多实用及有趣的库,都可以尝试以下。
输入:sudo apt-get build-dep python-scipy/numpy/matplotilb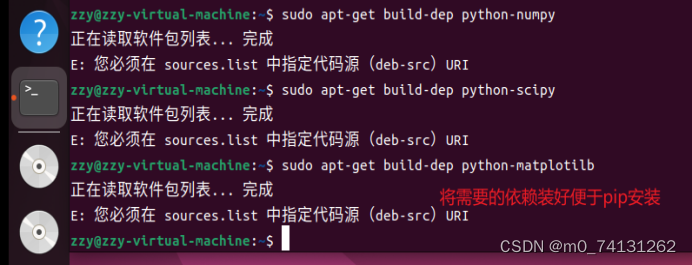
安装示例如下:
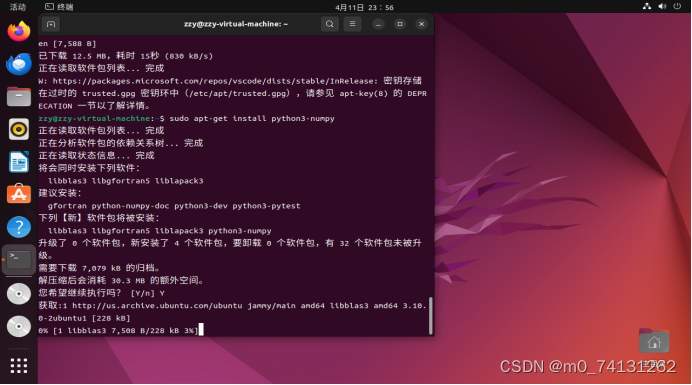
其他库与其操作都大差不差。
安装完成后输入:pip3 list | grep numpy/...检查是否安装成功。

也可进入python中导入该库看是否会报错来判断是否成功安装。
实验五:完成Linux操作系统中Anaconda的安装使用
- 在官网或者在清华镜像源中安装其安装包
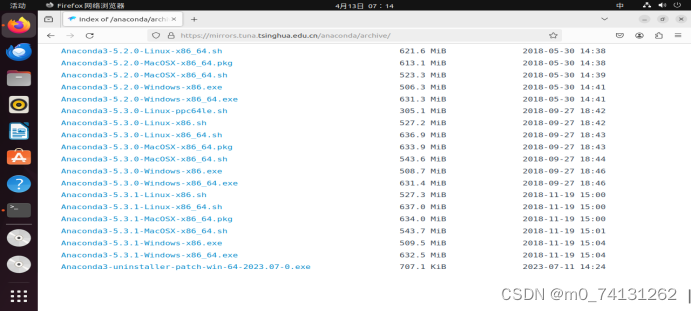
下载后出现
- 将其安装
输入:sh Anaconda3-5.3.0-Linux-x86_64.sh//注意改成自己下载的sh文件

按提示安装,有时需要输入yes。
安装成功后会出现该文件
但是许多人在时候输入conda命令会不成功,那是因为conda环境没配置好,我也在这困惑了一会。
- 配置conda环境
需要修改bashrc文件
输入命令:
vim /.bashrc
source /.bashrc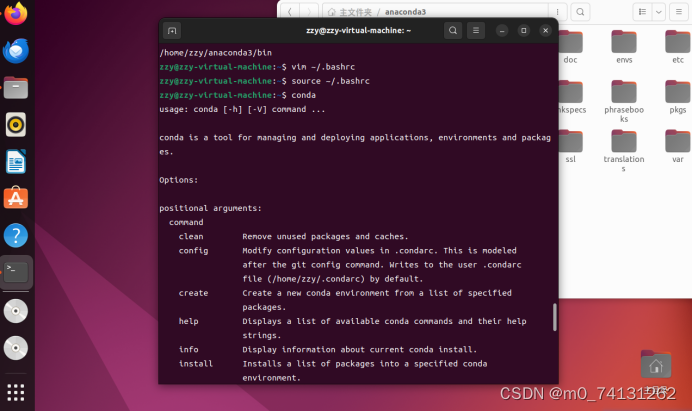
在最后一行中添加:export PATH="/home/zzy/anaconda3/bin:$PATH"
也可以不用打开文件直接修改,这里不作演示。
这时输入conda命令后就会出现
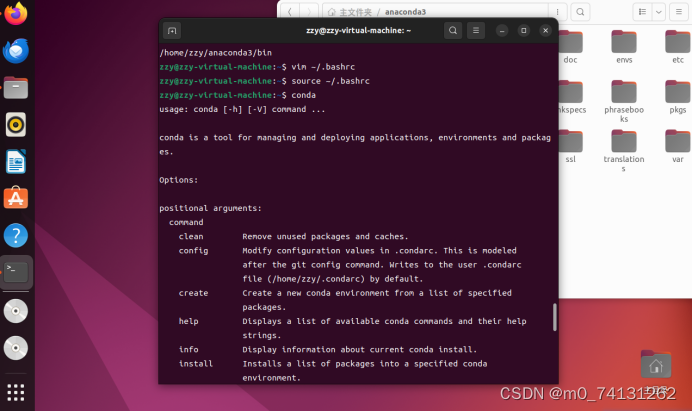
这样就是安装好adconda了。
实验六:使用Linux操作系统中Jupyter Notebook
一般来说adconda都会自带Jupyter,所以说主要按步骤安装好adconda的都可直接使用jupyter。
我这里也是,直接输入:jupyter notebook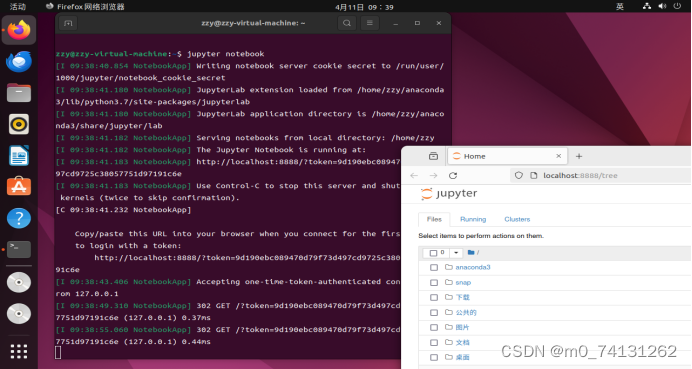
点开网页就可直接进入jupyter notebook
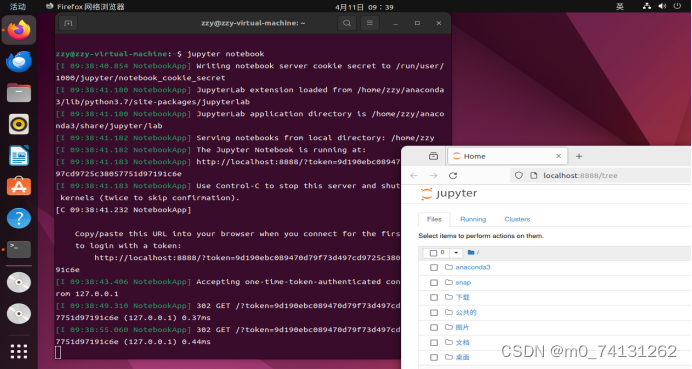
实验七:完成Jupyter Notebook中一个简单机器学习算法
使用numpy、sklearn和pandas库实验
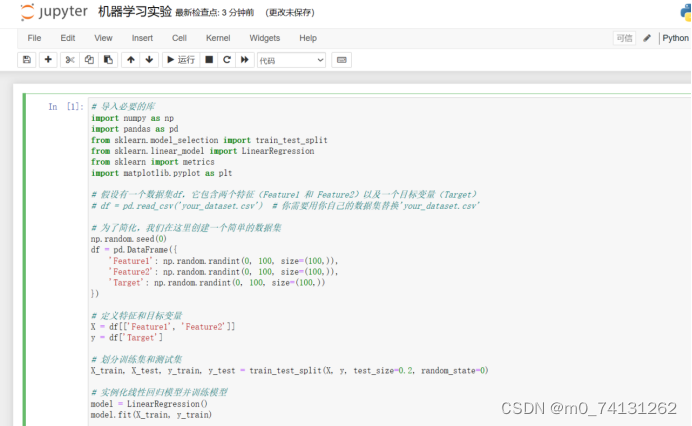
通过创建一个简单的数据集,并使用LinearRegression类来拟合一个线性模型,展示了如何在Python中使用scikit-learn库进行线性回归分析。
通过train_test_split函数将数据集划分为训练集和测试集,这是为了评估模型在未知数据上的表现。训练集用于训练模型,而测试集用于验证模型的预测能力。
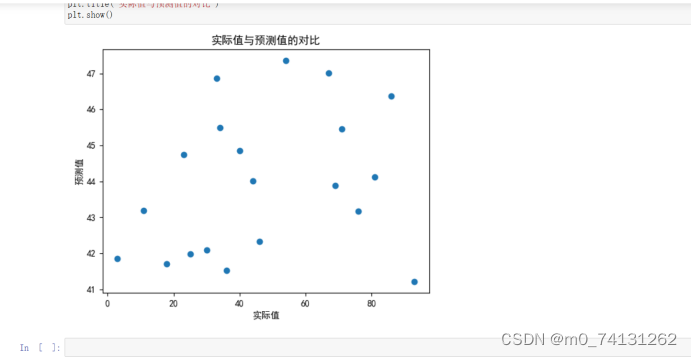
 实现可视化预测结果和实际结果的对比
实现可视化预测结果和实际结果的对比
六、附录:源代码
# 导入必要的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
import matplotlib.pyplot as plt
# 假设你有一个数据集df,它包含两个特征(Feature1 和 Feature2)以及一个目标变量(Target)
# df = pd.read_csv('your_dataset.csv') # 你需要用你自己的数据集替换'your_dataset.csv'
# 为了简化,我们在这里创建一个简单的数据集
np.random.seed(0)
df = pd.DataFrame({
'Feature1': np.random.randint(0, 100, size=(100,)),
'Feature2': np.random.randint(0, 100, size=(100,)),
'Target': np.random.randint(0, 100, size=(100,))
})
# 定义特征和目标变量
X = df[['Feature1', 'Feature2']]
y = df['Target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 实例化线性回归模型并训练模型
model = LinearRegression()
model.fit(X_train, y_train)
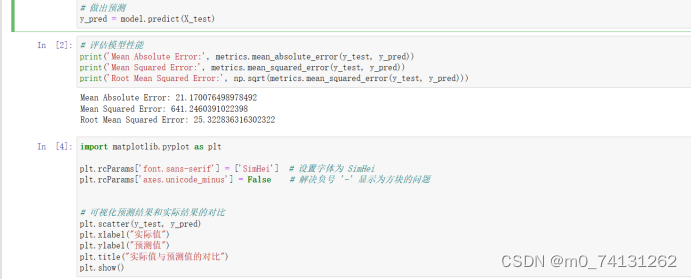
# 做出预测
y_pred = model.predict(X_test)
# 评估模型性能
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为 SimHei
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
# 可视化预测结果和实际结果的对比
plt.scatter(y_test, y_pred)
plt.xlabel("实际值")
plt.ylabel("预测值")
plt.title("实际值与预测值的对比")
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









