







 本文介绍了卷积神经网络(CNN)的基本原理,包括特征提取、全连接层、BP神经网络、卷积层的卷积和池化操作,以及误差计算、反向传播和权重更新的过程,重点讨论了不同优化器如SGD、Momentum、RMSProp和Adam的应用。
本文介绍了卷积神经网络(CNN)的基本原理,包括特征提取、全连接层、BP神经网络、卷积层的卷积和池化操作,以及误差计算、反向传播和权重更新的过程,重点讨论了不同优化器如SGD、Momentum、RMSProp和Adam的应用。
(PS:本博客仅用于记录个人笔记,所用图片和文字内容大部分来自b站up主:霹雳吧啦Wz,转载或引用请注明up主)
附上原up地址:

卷积神经网络(CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。
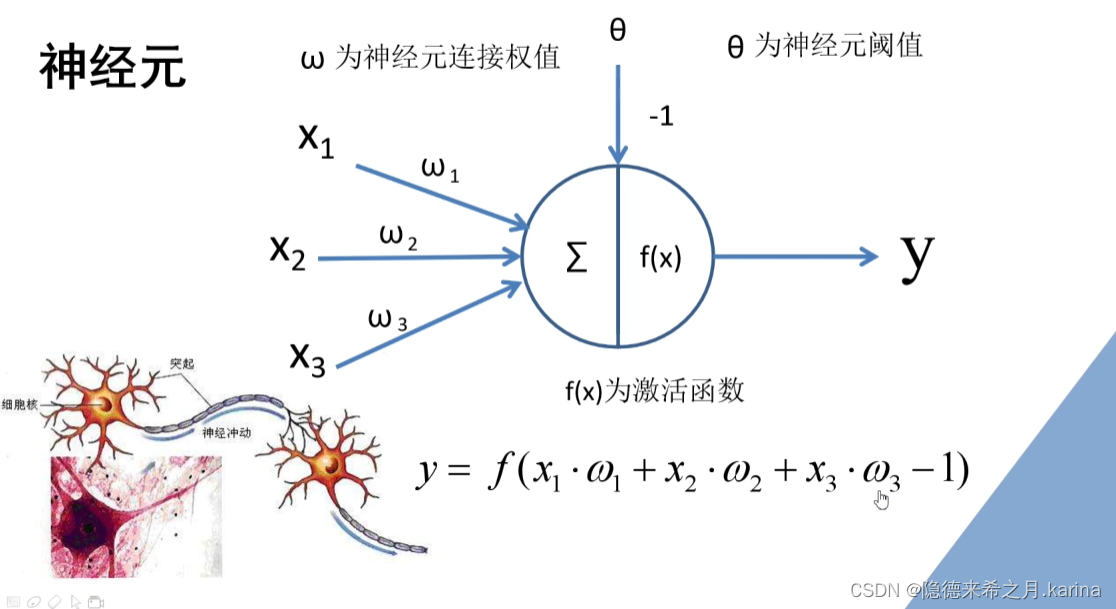
特征提取过程中,每个像素点会通过与各自的权重相乘进行特征提取,再加上一个偏置值。最后套上一个激活函数
参数:特征提取过程中的权重和偏置值个数
一、全连接层
全连接层,是每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
将神经元按列进行排列,列与列之间进行全连接,就得到了一个BP神经网络:
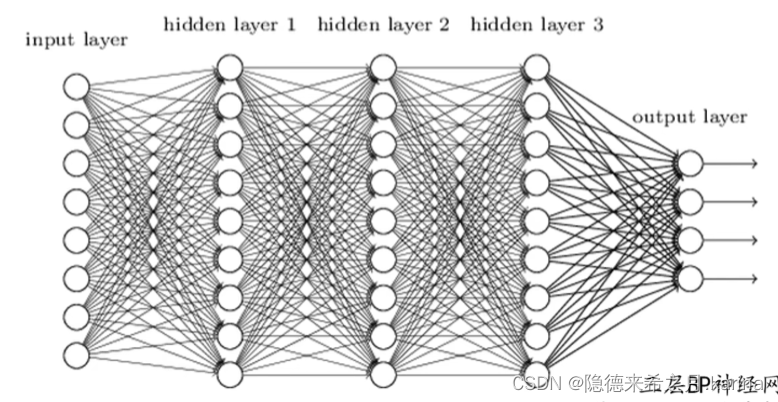
BP神经网络包括两个部分:信号的向前传播(计算误差)和误差的反向传播(调整权重和偏置值)。
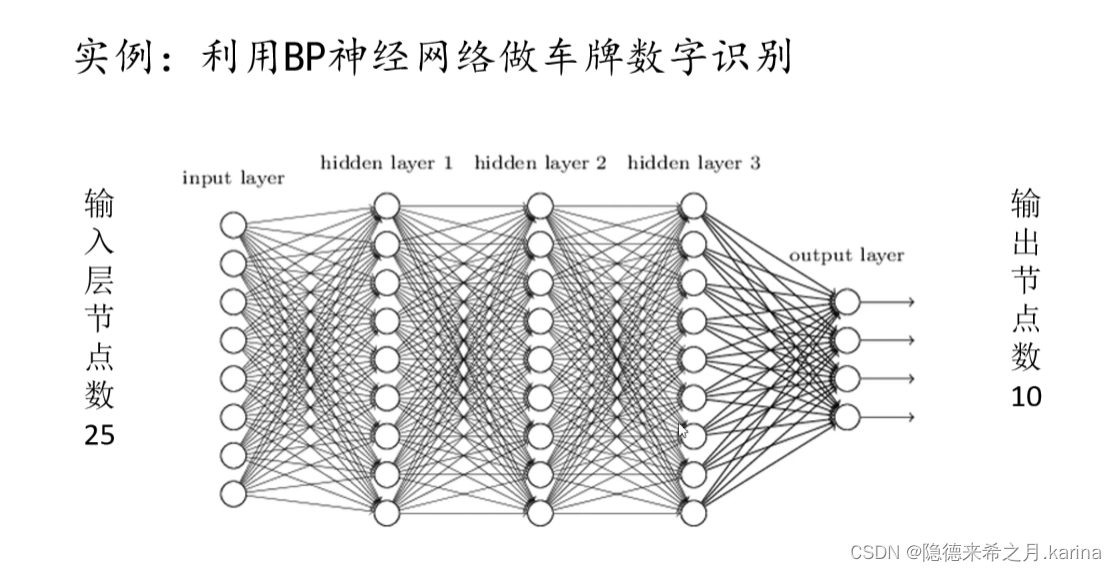
实例:利用BP神经网络做车牌数字识别
将车牌数字进行灰度化和二值化得到黑白图像

计算像素点的权重值
这里用一个5*3的滑块在图像上滑行(滤波器),计算白色像素点在每个滑块上的占比,即为该区域白色像素点的权重。得到一个5*5的权重矩阵。
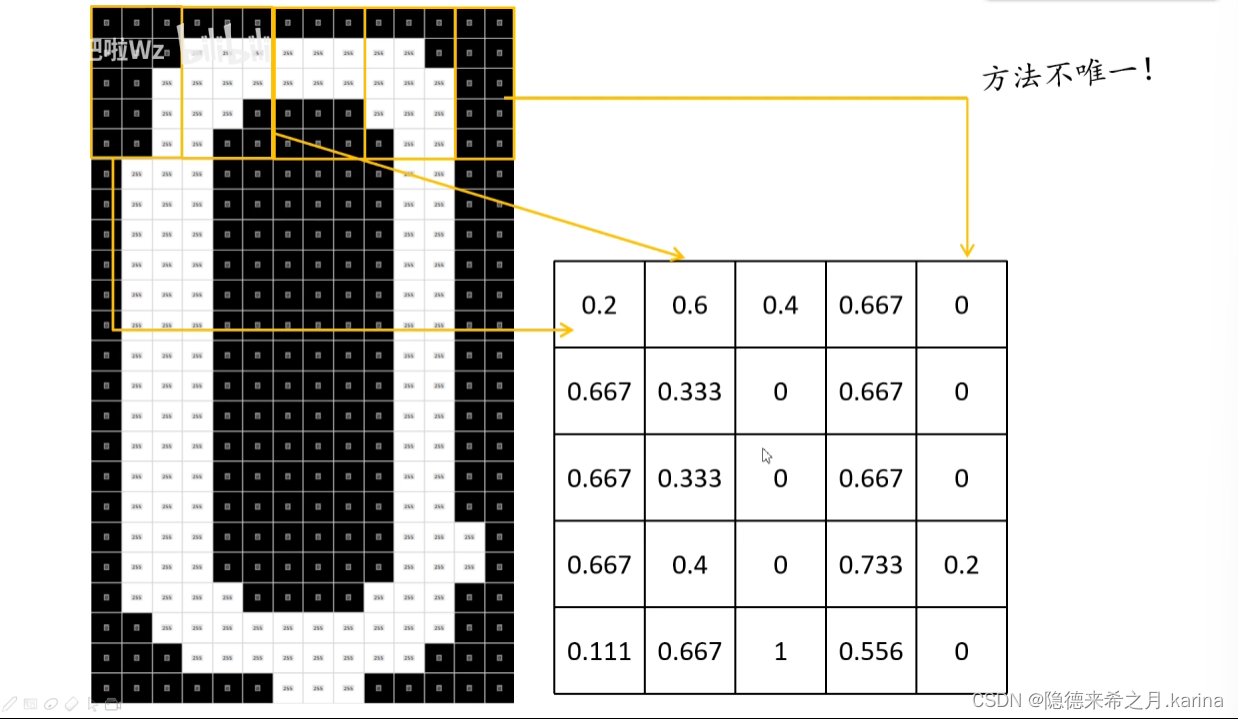
将矩阵展开为一个1*25的行向量,即为该神经网络的输入层。而输出层为10个节点(车牌数字0~9),隐藏层可按情况设置。
二、卷积层
卷积层(Convolutional layer)是cnn中的独特结构,由若干卷积单元组成。目的是对图像进行特征提取。
卷积:通过一定大小的卷积核在特征图像上滑动,将卷积核上的数值与所覆盖到的图像上对应数值相乘相加得到特征值,最后得到特征提取后(卷积后)的图像。
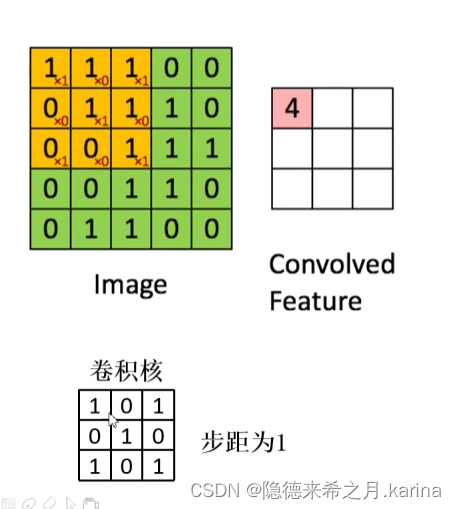
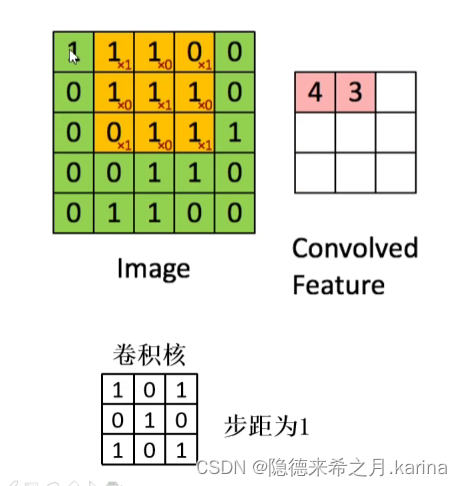
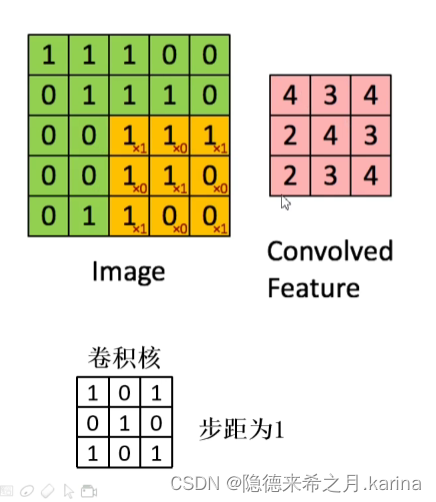
使用卷积,可以大大减少参数个数。
如:对于一张1280*720的图片,假设第一层隐藏层神经元个数为1000若使用全连接,则参数个数为1280*720*1000=921600000;若使用1000个5*5的卷积核,所需参数为5*5*1000=25000。
对于多维度的图像卷积,则:卷积核channel数=输入图像channel数,卷积核个数=输出图像个数
输入矩阵的各维度与卷积核的各维度分别进行卷积后,再相加,得到一个输出矩阵
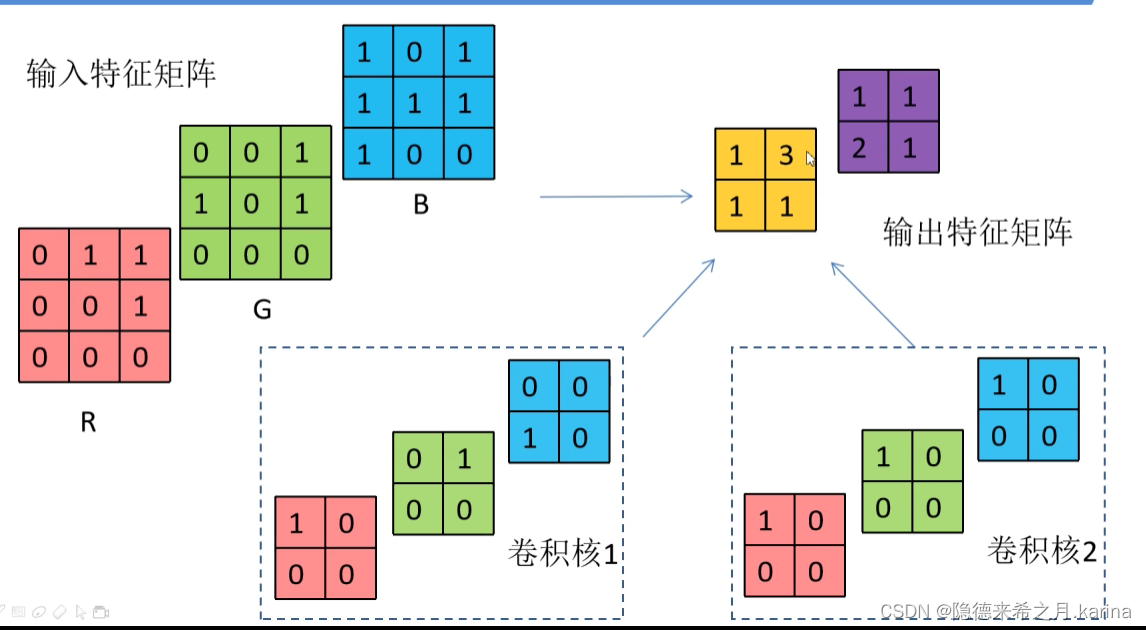
当考虑偏移量(偏置值)时,则对输出矩阵的个数值加上偏置值即可。
当卷积过程中出现卷积核越界的情况,则通过padding=a的方式,在原图像矩阵周围用0补齐a层
矩阵经卷积操作后的尺寸由以下因素决定:
1.输入图片大小 W*W
2.卷积核大小 F*F
3.卷积核滑动步长 S
4.padding的大小 P
经过卷积后的矩阵尺寸大小为:N=(W-F+2P)/S+1 (如果只补半圈,+P)
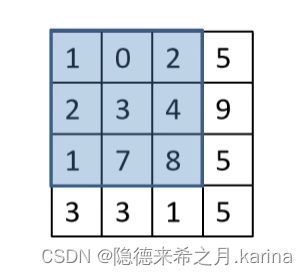 --->
---> 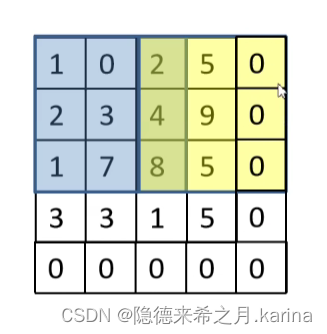 W=4, F=3, S=2, padding=1
W=4, F=3, S=2, padding=1
则:N=(4-3+1)/2+1=2,即输出矩阵大小为2*2
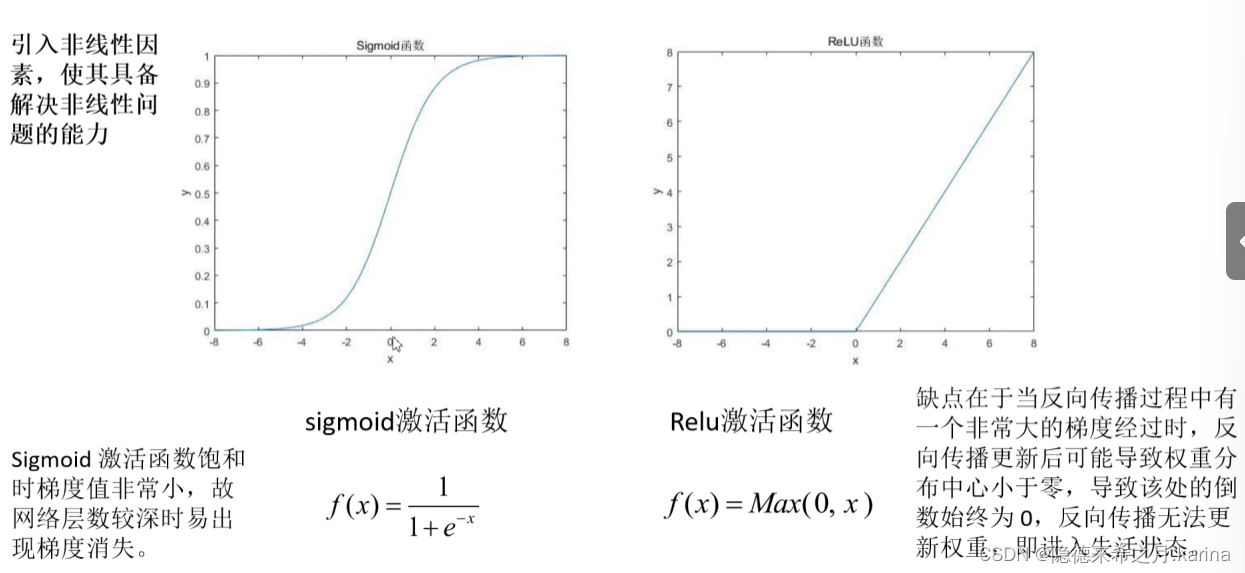
激活函数:引入非线性因素,使其具备解决非线性问题的能力
常用激活函数:Relu函数,sigmo函数等
三、池化层
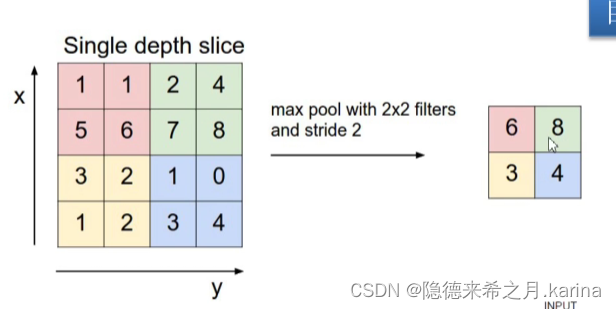
池化操作是卷积神经网络中的一个特殊操作,主要就是在一定区域内提取出该区域的关键性信息,其操作往往出现在卷积层之后,其能起到减少卷积层输出特征量数目的作用,从而能减少模型参数,同时能改善过拟合现象。
MaxPooling下采样:采样最大数值
AveragePooling:采样区域内平均值

池化层的特点:没有训练参数;只改变图像尺寸(W,H),不改变通道数(channel);一般池化核大小和步长相等(没有重合区域,将图像直接缩小为原来的一半)
四、误差的计算
某一节点输出值的计算:f(x1*w11+x2*w21+...+xn*wn1+b1)
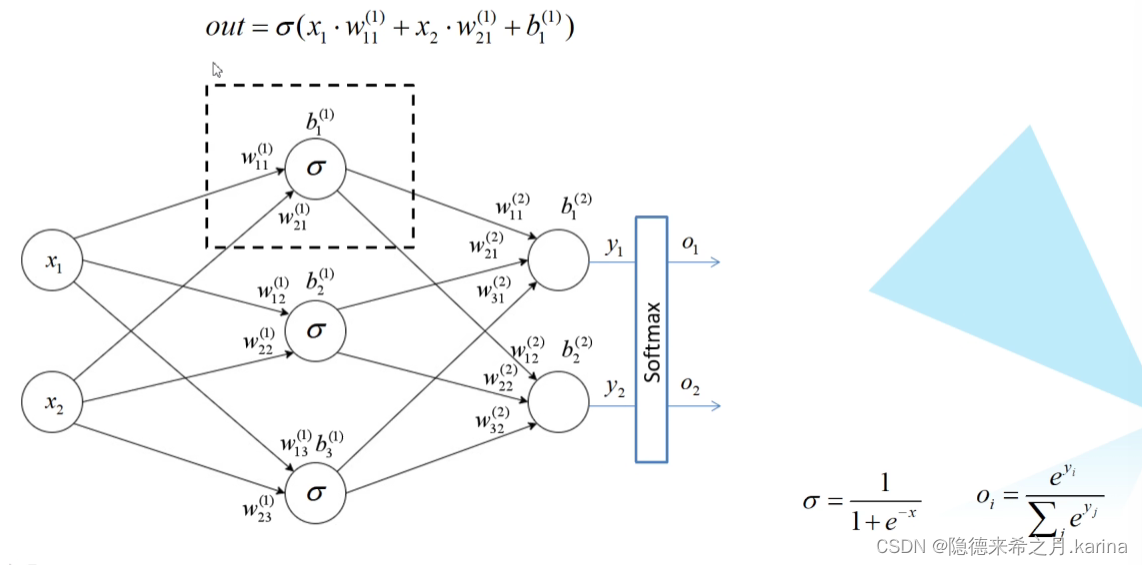
同理计算输出值(y1,y2):
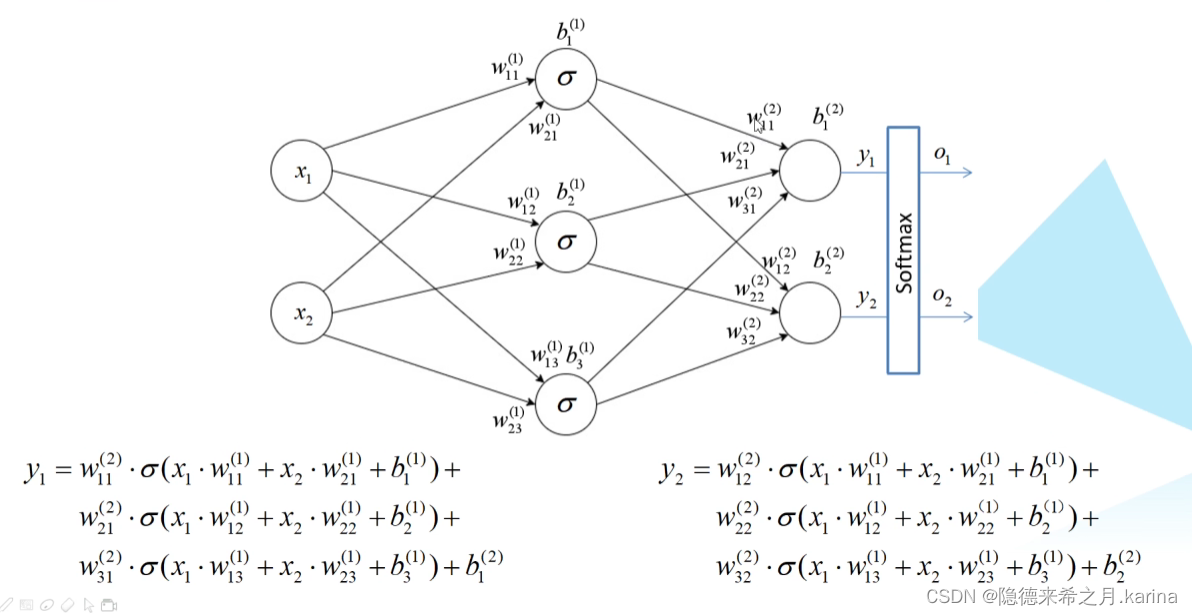
得到y1,y2后,再经过激活函数Softmax(使其满足概率分布,和为1)得到o1,o2
用交叉熵损失(Cross Entropy Loss)计算误差:

因此,上例的误差为:

五、误差的反向传播
将正向传播后得到的输出值与期望的输出值进行比较,得到误差值。通过计算每个结点的偏导数,就能得到每个结点的误差梯度。将误差值反向应用到误差梯度上,实现误差的反向传播。
例如:对w11(2)的损失梯度进行计算
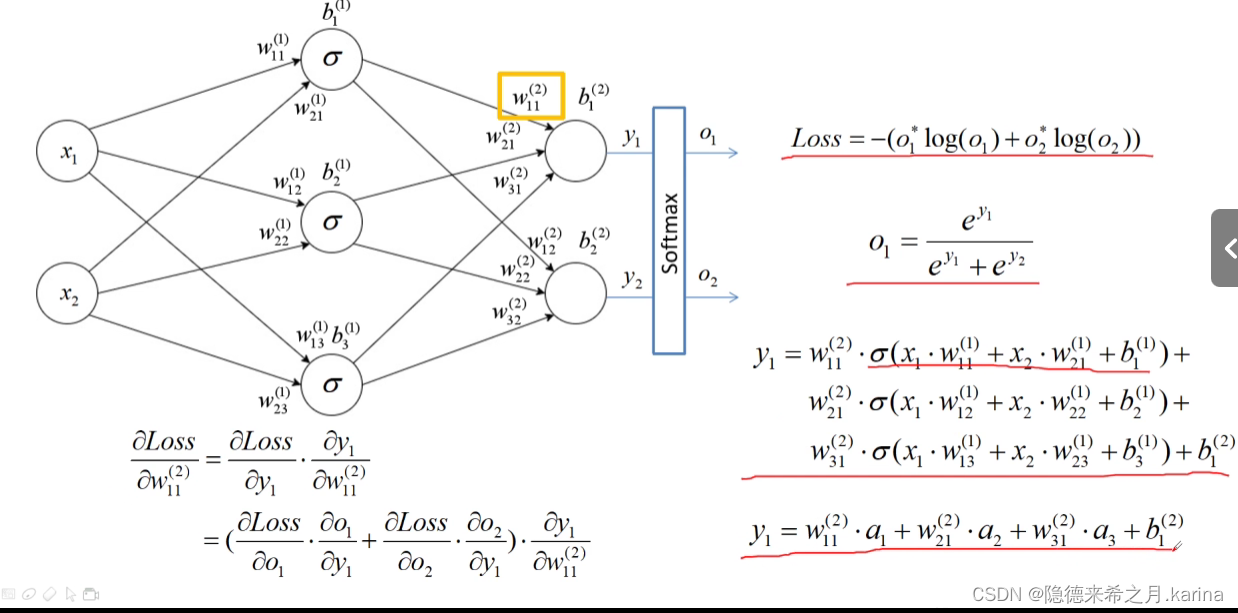


六、权重的更新
权重w更新公式为:

leaningrate为学习率
在实际应用中,我们不可能一次性将所有数据载入进行权重的更新和网络的训练,所以只能选择分批次(batch)训练。此时的损失梯度指向当前批次的最优方向(局部最优解)
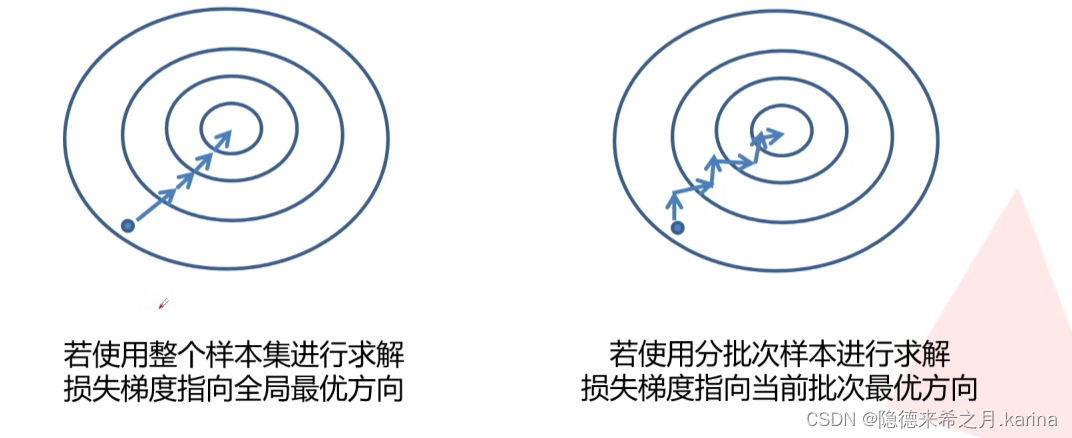
优化器(optimazer):使网络更快地收敛。我们需要这些最优化算法来将我们的模型训练至一个局部/全局最优处,从而得到我们需要的网络参数。
 https://blog.csdn.net/shanzsz/article/details/113177288
https://blog.csdn.net/shanzsz/article/details/113177288 
SGD优化器,利用设定的学习率α和计算出的损失梯度g对权重进行更新
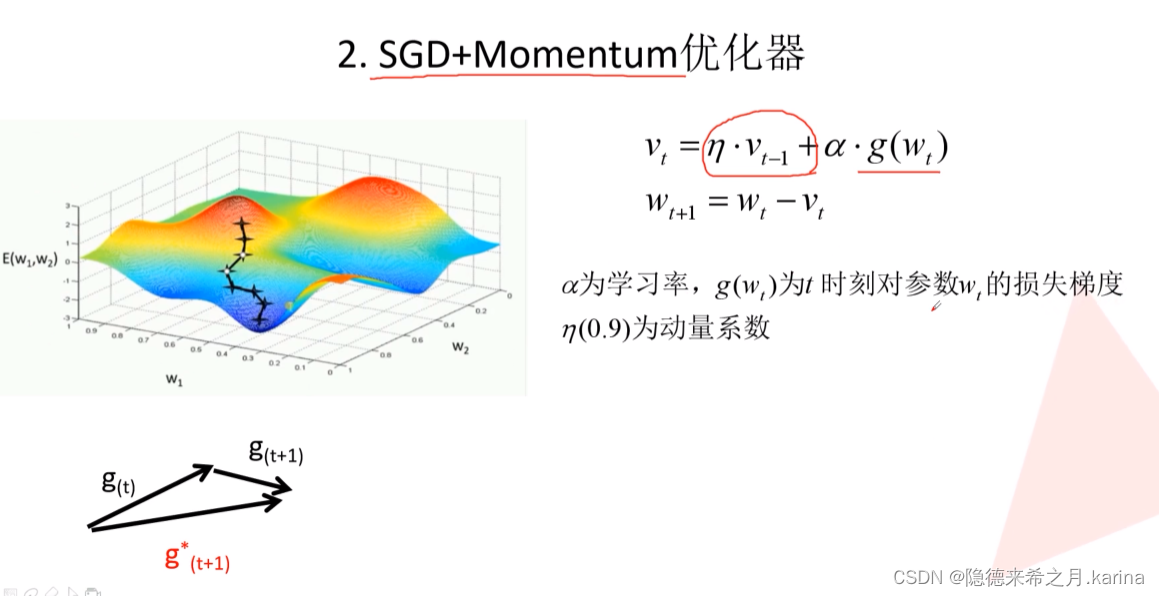
SGD+Momentum优化器,在SGD的基础上增加了一个动量,考虑了上一步梯度的效果,减少了样本噪声的干扰。
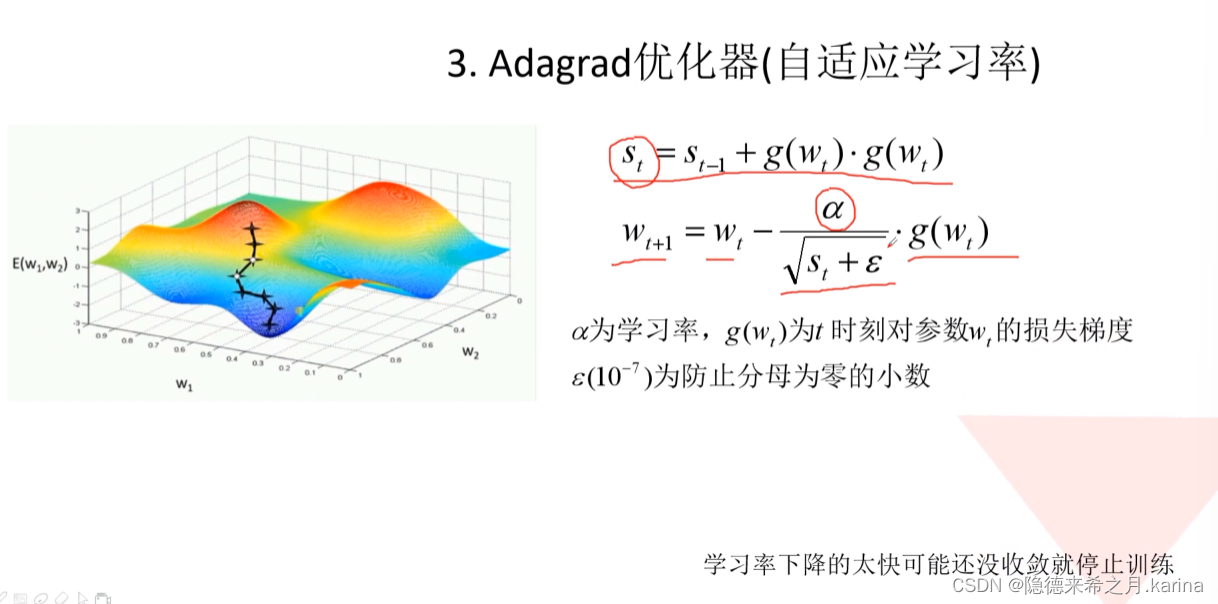
优化器,通过对St进行平方处理,使公式中的学习率越来越小,学习率的改变与梯度的改变相适应。
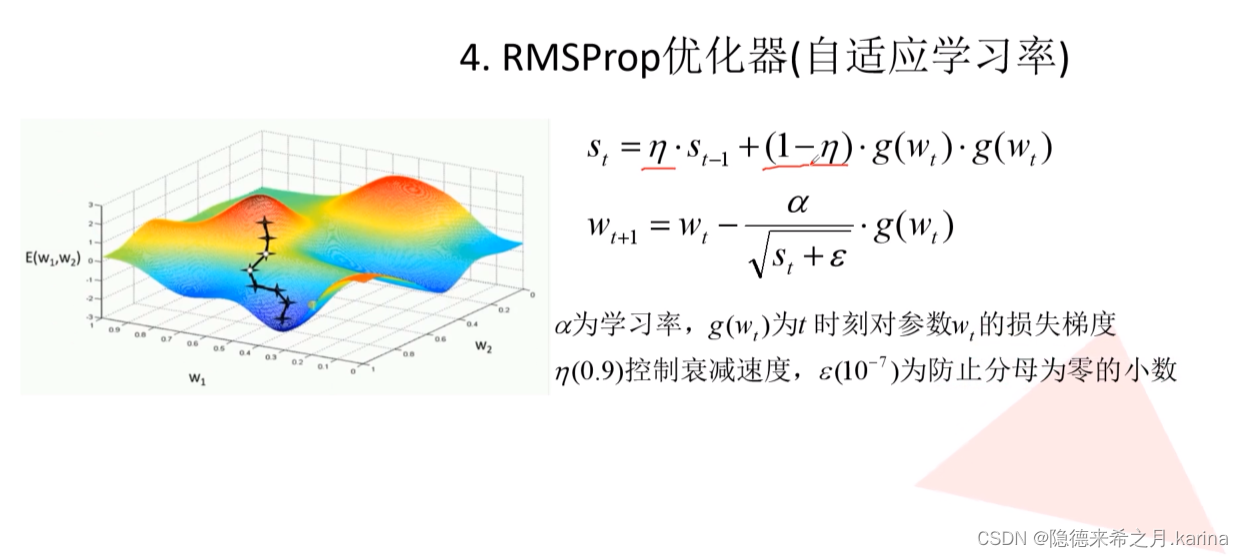
RMSProp优化器,在adagrad优化器的基础上,增加了两个系数,以控制学习率的衰减速度
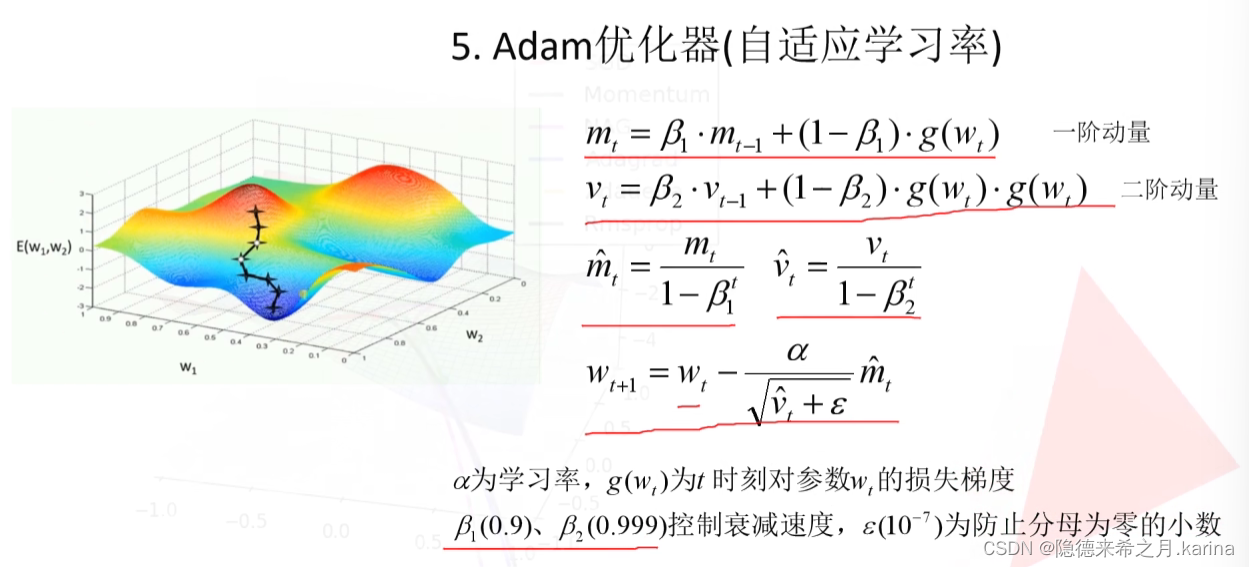
Adam优化器,加入了一阶二阶动量,既控制了学习率的衰减速率,也考虑了上一步梯度的作用(减少了噪声的影响)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









