






-
Python数据分析概述
-
Python数据分析依赖的两个对象
-
表格对象实现统计分析
-
数据预处理
-
Matplotlib数据可视化
-
总结

Python数据分析概述
数据分析的概述
- 数据分析:用适当的统计分析方法将收集来的大量数据进行分析,将他们加以汇总和理解并消化,以求最大化地开发数据的功能,发挥数据的作用。为了提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
- 数据分析的类别:描述性数据分析、探索性数据分析、验证性数据分型。
- 广义的数据分析包括狭义数据分析和数据挖掘。
Python数据分析依赖的两个对象
1.导入外部数据
python中读取excel/csv文件的方法:调用pandas库的read_excel/csv函数
#读取cvs数据
data1 = pd.read_csv(r'D:\数据集合集/新用户表.csv',
sep=',',
encoding='gbk'
)
data1
#读取excel数据
data2 = pd.read_excel(r'D:\数据集合集/新明细表.xlsx')
data2
将表格上传至数据库
from sqlalchemy import create_engine
user = 'root' #用户名
password = '123456' #密码
ip = 'localhost' # ip地址
port = '3306' # 端口
database = 'data_analysis' # 数据库名
# 创建mysql引擎对象,将上述信息写入函数的参数中
engine = create_engine(f'mysql+pymysql://{user}:{password}@{ip}:{port}/{database}')
engine
# 将表data1写入engine中的数据库中的user表中
data1.to_sql('user',engine,index=False)Series序列对象
概念:
- 利用pandas库从外部读取数据到python中形成的表格叫做DataFrame表格对象
- Series序列对象即DataFrame表格对象中的某一列数据。
- Series序列对象简称序列对象,其数据类型是Series。
获取序列对象的方法:
从表格对象中提取序列对象:表格对象[列名称]。
手动生成一个序列对象: pd.Series(列表对象)类生成。
获取序列对象的方法
# 1. 通过表格对象获取
df = pd.read_excel('../数据集/各省份车辆销售数量.xlsx')
df['销售总数']
# 通过pd.Series类生成
series = pd.Series(['a','b','c'])
series
type(series)Series序列对象的属性
series = pd.Series(['a','b','c'])
print(series.values) # 值
print(series.index) # 索引
print(series.name) # 名称
print(series.dtypes) # 数据类型
print(series.size) # 数据个数
#Series序列对象中局部数据的访问方法
series = pd.Series(['a','b','c'])
print(series)
print('-'*20)
print(series[0])
print('-'*20)
print(series[0:2])
print('-'*20)
print(series[series!='a'])
#序列对象的运算
series = pd.Series([1,2,3])
print('序列对象:\n',series)
print('加法运算:\n',series+10)
print('乘法运算:\n',series*10)
print('两个序列对象的运算:\n',series*6+series*4)
print('字符串序列加法运算:\n',series.astype(str)+'天')
print('判断运算:\n',series==2)序列对象的常用方法
astype() 数据类型转换方法
series = pd.Series([1,2,3])
print(series)
print(series.astype('float'))
print(series.astype('str'))
print(series.astype('str')+'个')
#value_counts() 统计序列中元素出现的次数
print(series.sort_values())
#rank() 返回序列中数据大小的排名序号
print(series.rank(ascending=False))
# round() 控制数字型序列的小数点位
print(series.round(2))DataFrame表格对象
概念
- - 利用pandas库从外部读取数据到python中形成的表格叫做DataFrame表格对象
- - 表格对象的类型是DataFrame
# 表格对象的创建方法
df = pd.DataFrame(
[['张三','男'],['李四','女']],
columns=['姓名','性别']
)
# 表格对象的属性
print(df.values)
print(df.index)
print(df.columns)
print(df.shape)
# 表格对象的基本方法
df.info()
df.describe()表格对象实现统计分析
表格对象的增删查改
通过序列查询数据
- 访问单列:表格对象 ['列名称'] [行索引]
- 访问多列:表格对象 [['列名称1','列名称2',...]] [行索引]
df = pd.read_excel('../数据集/超市销售数据.xlsx')
df['顾客类型'][:5]
df[['顾客类型','性别']][:5]
loc方法
- 访问单列:表格对象.loc[行索引,'列名称']
-
语法:**表格对象.loc[ 布尔值序列 , 列索引 ]**
-
布尔值序列由一个序列对象做条件判断运算得到,如:df['年龄']==18
-
布尔值序列中True所在的行即满足条件的行
-
当列索引为":"时(查询所有的列),条件查询语句也可以简写为:**表格对象[布尔值序列]**
- 访问多列:表格对象.loc[行索引,['列名称1','列名称2',...]]
df = pd.read_excel('../数据集/超市销售数据.xlsx')
print(df.loc[:5,'顾客类型'])
print(df.loc[:5,['顾客类型','性别','商品类别']])
print(df.loc[:5,'顾客类型':'商品类别'])iloc方法
- 表格对象.iloc[行索引,列索引]
- 和loc方法的区别主要在列索引,iloc中的列索引表示列的序号,接收的是数字
df = pd.read_excel('../数据集/超市销售数据.xlsx')
df.iloc[:,[3,4,5]]query方法
- 语法:**表格对象.query(查询条件字符串)**
- 查询条件字符串:例如:'a>1','性别=="男"','a>1 and b==2'
# query方法
df = pd.read_excel('../数据集/超市销售数据.xlsx')
df.query('城市=="城市C" and 性别=="男" and 支付方式=="现金"')
表格对象删除数据
# 删除行
df.drop(0)
# 删除列
df.drop('姓名',axis=1)表格对象数据修改
df['姓名'][0] = '王五'分类统计分析
基本概念
- 分组分析又叫分组聚合先分组,后聚合。
- 分组指根据某个类别型变量 (如:性别)对一个结构化数据 (如一个表格对象)进行分组聚合指计算每个组的某个指标的聚合值,聚合值指求和、最值、均值这类由多个值聚合而来的指标。
# 指定分组变量
df.groupby('车辆ID')
# 指定聚合变量
df.groupby('车辆ID')['行驶时长']
# 指定聚合函数
df.groupby('车辆ID')['行驶时长'].sum()
#多变量分组聚合
df2.groupby(['车辆ID','日期'])['行驶时长'].sum()[:20]
# 计算平均速度、行驶时长的四分位数,保存到列表中
quantile_speed = [df['平均速度'].quantile(i) for i in [0,0.25,0.5,0.75,1]]
print(quantile_speed)
时间类型数据处理
字符串存储的时间
- 时间在任何计算机语言中都可以用字符串表示,如,2016/8/11 11:49:43'。
- 字符串存储的时间有一些缺点,如无法计算2016/8/11’ 和 2016/3/9’ 之间的天数。
时间类型的对象
- Pandas库中封装了多个和时间相关的类。
- 这些类对应的时间类型对象拥有可以方便地进行时间计算、局部时间提取的方法和属性常用的时间相关的类有 Timestamp、 Timedelta 和 Period。
Timestamp 时间对象
两种生成Timestamp时间对象的方法
- 通过 pd.Timestamp(类来生成
- 通过 pd.to_datetime(函数来生成
Timestamp时间对象的常用属性
- 时间对象可以通过其属性来查看它的局部时间
- 属性名分别为: yearmonth\dayhour\minute\second
- 分别对应着年、月、日、时、分、秒
# 通过pd.Timestamp()类来生成
time = pd.Timestamp(2022,3,18,13,39,0)
print('生成的时间是:',time)
print('它的类型是:',type(time))
# 通过pd.to_datetime()函数来生成
time_str = '2022-03-18 13:39:00'
print('时间字符串是:',time_str)
print('它的类型是:',type(time_str))
time2 = pd.to_datetime(time_str)
print('转换后的打印结果是:',time2)
print('它的类型是:',type(time2))
time = pd.Timestamp(2022,3,18,13,39,0)
print('生成的时间是:',time)
print('年:',time.year)
print('月:',time.month)
print('日:',time.day)
print('时:',time.hour)
print('分:',time.minute)
print('秒:',time.second)
# 时间差对象和时间对象的计算
time = pd.Timestamp(2022,3,18,13,39,0)
timedelta = pd.Timedelta(hours=1)
print(time)
print(time-timedelta)
#dt对象
# 生成季度数据
time_series.dt.quarter
# 生成星期几数据
time_series.dt.weekday
# 生成当年周数和星期几数据
time_series.dt.isocalendar()数据预处理
数据合并
拼接合并的概念
- 纵向拼接:指将两个列名相同的Dataframe表格对象上下拼接到一起。
- 横向拼接: 指将两个索引相同的Dataframe表格对象左右拼接到一起。
拼接合并的实现方法
- pd.concat()函数。
- 语法结构: pd.concat([表格对象1,表格对象],axis=0或1)。
- axis默认为0,表示横向拼接,axis=1时表示纵向拼接。
主键合并的概念
- 基于两个表共有的主键 (即某列数据)将两个表的数据根据主键相同原则进行拼接(匹配)
- 同理于SQL语言中的join语句、Excel中的VLOOKUP函数。
主键合并的方式
- 根据合并后显示数据的逻辑不同,将主键合并分为:左连接、右连接、内连接、外连接。
- 左连接:结果只显示左表的主键所对应的数据。
- 右连接:结果只显示右表的主键所对应的数据。
- 内连接: 结果只显示左表和右表共有的主键所对应的数据。
- 外连接:结果显示左表和右表所有的主键所对应的数据。
主键合并函数pd.merge()
df1 = pd.DataFrame(
[['甲',80],['乙',90],['丙',85]],
columns=['姓名','分数']
)
df2 = pd.DataFrame(
[['甲','男'],['乙','女'],['丁','男']],
columns=['姓名','性别']
)
# 左连接
pd.merge(df1,df2, how='left',on = '姓名')
# 右连接
pd.merge( df1,df2,how='right',on = '姓名')
# 内连接
pd.merge( df1, df2,how='inner',on = '姓名')
# 外连接
pd.merge(df1, df2,how='outer', on = '姓名')数据清洗
去除重复值
# 保存去重后的表
df2 = df.drop_duplicates(subset=['姓名']).reset_index(drop=True)表格对象.drop_duplicates(subset,keep)
- subset:接收列表对象,指定需要根据哪些列的数据来进行去重。
- keep:'first'保留重复的数据中的第一行数据;'last'保留重复的数据中的最后一行数据;
删除法处理缺失值
表格对象.dropna(axis,subset,how,inplace)
- axis:0或1,0表示删除行数据,1表示删除列数据,默认为0。
- subset:指定要删除的缺失值来自哪一(几)列。
- how:对表格对象多个字段的缺失值进行删除时使用。'any'表示任何一个字段有缺失就删除。'all'表示所有字段都缺失才删除。
- inplace:数据删除是否在原表中生效。
df_nan= pd.DataFrame(
[['甲',80,'1班'],[np.nan,np.nan,'1班'],['乙',np.nan,'1班']],
columns=['姓名','分数','班级']
)
# 任意一列有缺失数据就删除整行
df_nan.dropna(subset=['姓名','分数'],how='any')
# 所有列的数据都缺失才删除整行
df_nan.dropna(subset=['姓名','分数'],how='all')
df_nan2= pd.DataFrame(
[['甲',80,np.nan],[np.nan,90,'1班'],['乙',np.nan,'1班']],
columns=['姓名','分数','班级']
)
# 计算缺失值个数
df_user.isnull().sum()
# 特殊值法填充姓名
df_nan2['姓名'] = df_nan2['姓名'].fillna('某某')
# 平均值法填充分数
df_nan2['分数'] = df_nan2['分数'].fillna(df_nan2['分数'].mean())
# 众数法填充班级
df_nan2['班级'] = df_nan2['班级'].fillna(df_nan2['班级'].mode()[0])
异常值的数学定义
- 异常值:距离序列中大多数的数据很远的数
- 中位数:序列中50%的数小于这个数
- 上四分位数(Q3):序列中75%的数小于这个数
- 下四分位数(Q1):序列中25%的数小于这个数
- IQR :IQR = Q3 - Q1
- 异常值:序列中在范围 [Q1-1.5\*IQR,Q3+1.5\*IQR] 之外的数
# 用随机数来模拟一个数字型的序列
import numpy as np # 导入numpy库
mu = 0 # 随机数均值
sigma = 1000 # 随机数标准差
number = 1000 # 随机数个数
series = pd.Series(np.random.normal(mu,sigma,number)) # 正态分布随机数
bins = 100 # 直方图区间个数
series.hist(bins=bins)
# 定义函数返回序列的正常值区间
def normal_values(series):
'''
series:序列对象,用于计算其正常值区间
return:返回正常值区间的下界和上界
'''
Q1 = series.quantile(0.25)
Q3 = series.quantile(0.75)
IQR = Q3 - Q1
return Q1-1.5*IQR,Q3+1.5*IQR
# 返回随机数序列的正常值区间的下界和上界
normal_values(series)
# 条件查询出异常值
low,high = normal_values(series)
series[(series>high)|(series<low)]
# 剔除异常值:以查代删
series[(series<high)&(series>low)]
# 替换异常值:平均值法
series[(series>high)|(series<low)] = series.mean()
series[(series>high)|(series<low)] # 替换后查询不到异常值数据转换
哑变量处理
哑变量:类别型数据转换为数字型数据后生成的多个变量的总称
#调用语法:pd.get_dummies(data,prefix,prefix_sep,columns)**
- data:目标数据,可以是序列或者表格
- prefix:所有哑变量的列名称前缀
- prefix_sep:哑变量列名称前缀和原列名的连接符号,默认为'_'
- columns:当data传入表格时使用,指定要进行哑变量处理的列,接收一个列表
Matplotlib数据可视化
绘图函数
- - 以plot函数为例
- - 绘图语法: plt.plot(x,y,color,linestyle,marker,format_string …)
plt.plot(
[1,2,3,4,5],
[1,3,4,8,3],
linestyle = '--',
marker = '*',
color = 'g'
)
设置画布
- - 画布类似画画时的画板,决定了我们的图形的大小,默认的画布为白色,看不见其边界。
- - 语法: plot.figure(figsize,…)
- - figsize:接收元组(a,b),a表示画布的长,b表示画布的高
plt.figure(figsize=(8,2))
plt.plot([1,2],[1,3])plt.rcParams['font.family'] = 'SimHei' # 解决中文乱码
plt.xlabel('x轴') # 坐标轴名称
plt.ylabel('y轴')
# plt.xticks([1,2,3]) # 刻度
# plt.yticks([1,2,3])
plt.xlim(1,4) # 坐标轴范围
plt.ylim([1,5])
plt.grid() # 网格线
plt.show() # 只显示图像型图和直方图关于数据分布的显示效果对比
plt.rcParams['font.family'] = 'SimHei' # 解决中文乱码
plt.figure(figsize=(10,6))
plt.subplot(2,1,1)
min_age = int(df_air['年龄'].min()) # 最小客户年龄
max_age = int(df_air['年龄'].max()) # 最大客户年龄
plt.hist(
df_air['年龄'],
bins = [i for i in range(min_age,max_age,5)] # 以5为组距构造一个年龄区间列表
)
plt.title('用户年龄分布图')
plt.xlabel('年龄区间')
plt.ylabel('人数')
plt.subplot(2,1,2)
plt.boxplot(
df_air['年龄'].dropna(),
vert = False,
labels = ['年龄'],
whis = 3 # 放宽上下限的宽度,减少异常值的定义,尝试注释本行运行查看差异
)
plt.show()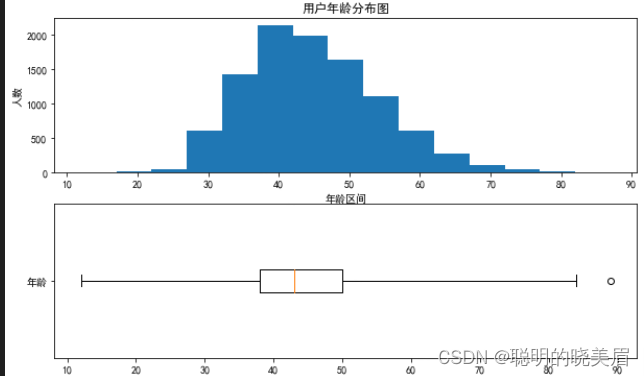
总结
以上为我在Python数据分析方面的经验和体会,希望对Python初学者和数据分析爱好者有所帮助。对于数据分析领域,我们需要不断学习和实践,掌握相关的技能和知识,从而更好地应对大数据时代的挑战。















 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









