






在这篇文章后会结束list,同时我会回答以上四个问题
1、vector和list的区别?
2、vector和list底层是如何实现的?
3、vector是如何增容的?
4、什么是迭代器失效?
话不多说我们先解决list的const类型问题
template<class T,class Ref,class Ptr>
struct __list_iterator//迭代器
{
typedef __list_node<T> Node;
typedef __list_node<T, Ref, Ptr> Self;//对应于
//typedef __list_node<T,T&,T*> iterator;
//typdef __list_node<const T,const T&,const T*> const_iterator;
Node* _node;
__list_iterator(Node* node);//构造函数
:_node(node)
{}
Ref operator*(){
return _node->_data;
}
Ptr operator->(){
return &_node->_data;
}
};
template<class T>
class list//实现
{
typedef _list_node<T> Node;
public:
typedef __list_iterator<T,T&,T*> iterator;
typedef __list_iterator<const T, const T&, const T*> const_iterator;
//编译器会自动跳转到对应的T,Ref,Ptr
const_iterator begin()const{
return const_iterator(_head->_next);
}
iterator begin(){
return iterator(_head->next);
}
private:
Node* _head;
};看图捋清楚class list和struct __list_iterator中的模板关系
iterator中T*和Ptr的关系是互通的

const_iterator中的const T*和Ptr的关系也是互通的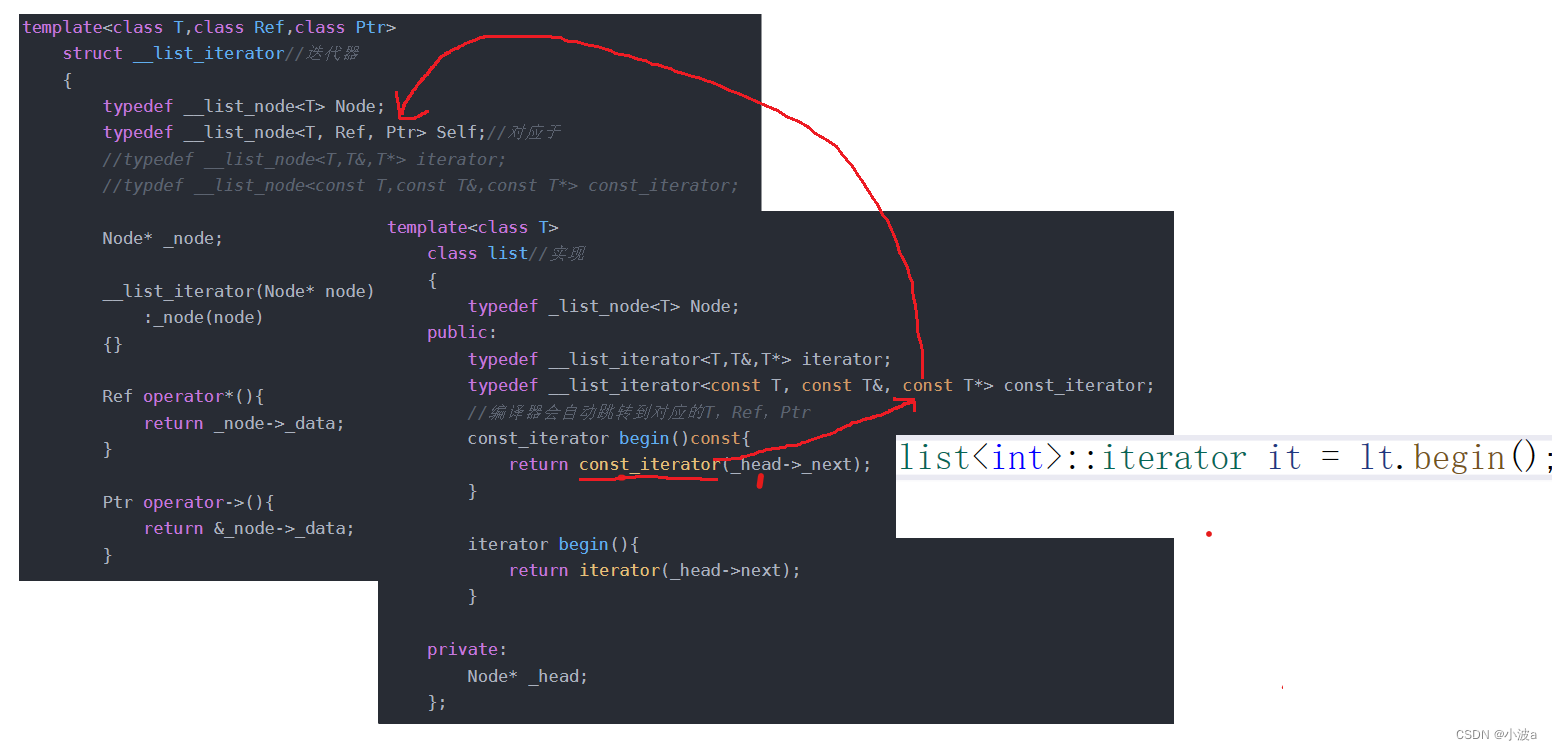
由此可知让迭代器单独为一个类的原因有两个;
1、在迭代器类中的任何成员函数只用写一个即可,不用像class list一样需要写非const版本和const版本两种,使得代码更加精简起来
2、将迭代器独立封装起来可以更好的区分迭代器可以做的行为(迭代器相关函数)和非迭代器可以做的行为,为了更好的理解。
Node* cur和iterator it的区别
当他们都指向同一个节点,那么在物理内存中他们都存的是中国节点地址,物理上是一样的
但是他们的类型不一样,他们的意义就不一样
比如*cur是一个指针的解引用,取到的值是节点
比如*it是去调用迭代器的operator*,返回值是节点中存的值
析构函数
~list()
{
clear();
delete _head;
_head = nullptr;
}我们想到析构函数可以用多个erase()函数来清理干净,但是用于清理空间的成员函数不仅仅只有析构函数,因此我们单独写出一个clear()来表示多个erase()
clear()
void clear()
{
//用迭代器循环到尾部
iterator it = begin();
whle(it != end())
{
erase(it++);
//用后置++,先清理当前节点,同时还跳转到下一节点
}
}erase()
iterator erase(iterator pos)
{
assert(pos != end());
Node* prev = pos._node->_prev;//pos前一个节点
Node* cur = pos._node->_next;//pos后一个节点
//prev和cur链接
prev->_next = cur;
cur->_prev = prev;
//释放空间
delete pos._node;
pos._node = nullptr;
return cur;
}pop_back()
void pop_back()
{
erase(--end());
//--end()相当于_head->_prev也就是尾节点
}中间插入insert()
插入到pos的前面一个节点(感觉好像没什么好注释的)
void insert(iterator pos, const T& x)//插入到pos的前面一个节点
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(x);
//prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
cur->_prev = newnode;
newnode->next = cur;
}深拷贝list(const list<T>& lt)
list(const list<T>& lt)
{
//开创一个自己的虚拟头节点
_head = new Node();
_head->_next = _head;
_head->_prev = _head;
//两种push_back都是迭代器但是后者更加简洁
/*const_iterator it = lt.begin();
while (it != lt.end())
{
push_back(*it);
++it;
}*/
for (auto e : lt)
push_back(e);
}赋值符号operator=[old]
//old方法
list<T>& operator=(const list<T>& lt)
{
if (this != <)
{
clear();//释放之前的空间内容
//如同拷贝函数
for (auto e : lt)
push_back(e);
}
}[new]
list<T>& operator=(list<T> lt)//取消const和引用
{
if(this!=<)
{
//交换内部数据,如果直接写swap(lt,this)也可
//但是运行效率会更慢
swap(lt._head->_prev, _head->prev);
swap(lt._head->_next, _head->_next);
swap(lt._head->_data, _head->_data);
}
return *this;
}到这里也就全部结束了,但是上面的4个问题却还未回答!
我用其优缺点便可回答前三个问题
下面我将详细介绍两者的优缺点
vector是一个可动态增长的数组,
优点:随机访问operator->很好的支持排序,二分查找、堆算法的等等
缺点:头部或者中间插入删除效率低+空间不够了以后增容的代价较大(开新空间,拷贝数据,释放就空间)
list是一个带头双向循环的链表
优点:任意位置插入删除数据效率高,时间复杂度o(1)
缺点:不支持随机访问
总结:vector和list是两个相辅相成,互补的容器。
list<int>::const_iterator it = lt.begin();
while (it != lt.end())
{
if (*it % 2 == 0)//删除偶数
{
lt.erase(it);//导致迭代器失效
}
else
++it;
}
list_print(lt);最后一个问题
4、因为erase(it)会导致it节点被释放,如果再对it进行++or--都会导致问题的出现
解决方法是让返回值返回到it即可
list<int>::const_iterator it = lt.begin();
while (it != lt.end())
{
if (*it % 2 == 0)
{
it = lt.erase(it);
}
else
++it;
}
list_print(lt);














 80
80











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









