







目录
一.结构体
(本篇不是对结构体的详细介绍)
(一)匿名结构体
struct { int a; int b; }x;可以不完全声明结构体,此时的x就是该结构体类型的变量
struct { int a; int b; }x; struct { int a; int b; }*y; int main() { y = &x; return 0; }这里在编译时会显示=两边类型不兼容(但并没有报错和警告,编译器为vs2019),所以可以知道这两个声明是两个不同的类型
(不太清楚这个有啥用,但多知道一点没坏处)
(二)结构体内存对齐
1.规则
- 第一个成员在结构体变量偏移量为0的地址处
- 其他成员要对齐到对齐数的整数倍的地址处
- 对齐数=编译器默认对齐数 和 该成员大小的 最小值
- vs中默认的对齐数为8
- 结构体总大小为每个成员的最大对齐数的整数倍
- 如果嵌套了结构体,嵌套的结构体对齐到自己的最大对齐数的整数倍, 整个结构体的大小是所有成员(包括嵌套的结构体的成员)的最大对齐数的整数倍
2.例题
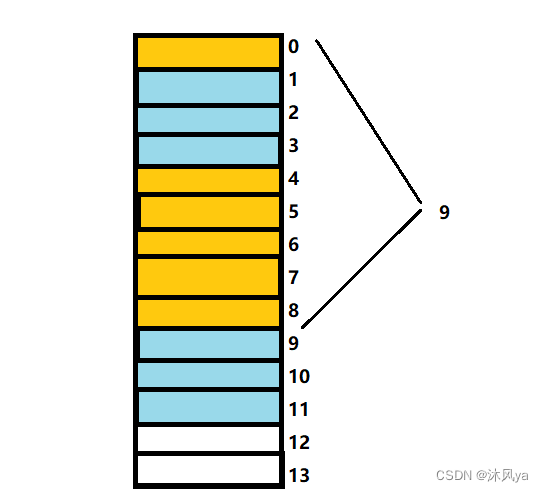
struct S1{ char c1; int i; char c2; };
- 黄色区域为结构体成员占用的内存,蓝色区域是由对齐规则产生的浪费的内存空间
- c1从0偏移量开始,占用一个字节
- i大小为四个字节,它的对齐数为4(4和8中取最小值),因此要偏移到4的倍数,此时的偏移量为1,不符合,而距离最近的符合条件的数字就是4,因此从偏移量为4的位置占用空间
- c2的对齐数是1(1和8中取最小值),此时的偏移量为7,下一个数字是8,8是1的倍数,因此继续占用一个字节
- 此时,成员已经占用空间完毕,但总大小为9,9不是4(1和4中取最大值)的倍数,距离9最近的符合的数为12,因此最终结构体的大小为12
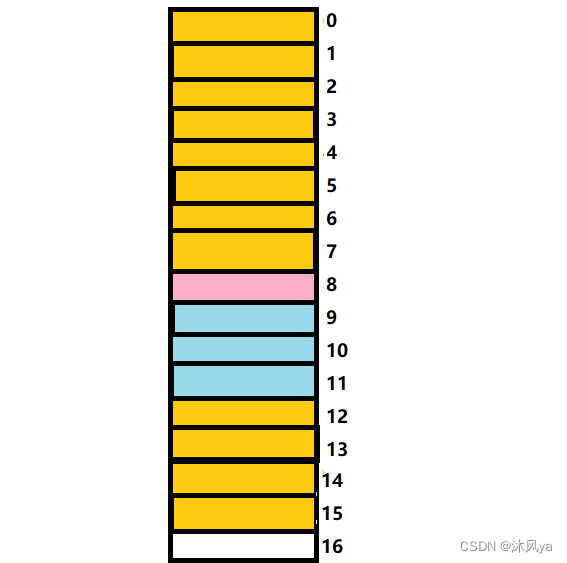
struct S1{ double a; char b; int c; }; struct S2{ char d; struct S1 s; double e; };
- 黄色和粉色区域为s成员占用空间,蓝色是s浪费的空间
- a占八个字节,从0偏移量开始
- b占一个字节,对齐数为1(1和8取最小值),8是1的倍数
- c占四个字节,对齐数为4(4和8取最小值),但9不是4的倍数,距离9最近的4的倍数为12,因此c从12偏移量开始占用空间
- s结构体总大小为16,最大对齐数为8(double a)
- 黄色和粉色区域为struct s2成员占用的空间,蓝色是struct s2浪费的空间
- d占一个字节
- s占16个字节,最大对齐数为8,因此从偏移量为8的位置开始占用空间
- e占八个字节,对齐数为8,此时偏移量为23,下一偏移量24恰好为8的倍数,因此继续占用
- 最后,该结构体总大小为32

3.为什么存在内存对齐
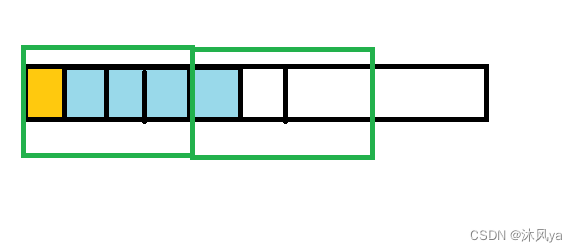
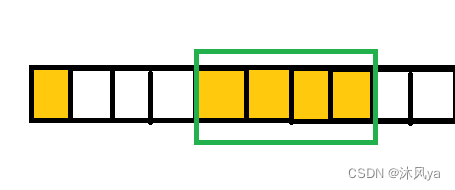
1. 平台原因 ( 移植原因 ) :不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。2. 性能原因 :数据结构 ( 尤其是栈 ) 应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。3.总结:内存对齐就是用空间换时间4.例题:struct a { char a; int b; };若我们的数据总线为32位,即一次读取数据大小为32bit,即四个字节,那么当不存在内存对齐时,我们需要两次才能读取到b(注意是从边界上读取)
如果存在内存对齐,只需要一次
4.修改默认对齐数
#pragma pack(2);这个预处理指令可以修改默认对齐数
#pragma pack();这个可以取消设置的默认对齐数,还原为默认
二.内存函数(memcpy和memmove)
(一)memcpy
1.函数原型
- dest是拷贝的目标地址,src是拷贝的起源地址,count是拷贝的字节数
- 它会返回目标地址

2.模拟实现
#include<assert.h>
void* work(void* p1, const void* p2, size_t n) { //const保证起源地址不被更改
void* ret = p1; //保存目标地址,以作为函数返回值
assert(p1 && p2); //断言,assert 宏的原型定义在 assert.h 中,其作用是如果它的条件返回错误,则终止程序执行,用来增加代码的安全性
while (n--) {
*(char*)p1 = *(char*)p2; //转换为单字节类型进行赋值
++(char*)p1; //进行运算时也需要转换类型,因为原类型为void*,无法进行运算
++(char*)p2;
}
return ret;
}
int main() {
int a[5] = { 1,2,3,4,5 };
int b[5] = { 0 };
int* p = work(b, a + 2, 8);
return 0;
} (代码结果)
(代码结果)
3.特殊情况
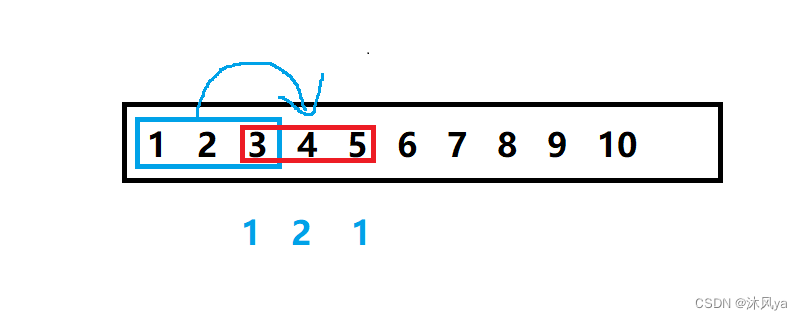
int a[] = { 1,2,3,4,5,6,7,8,9,10 }; int* p = memcpy(a+2 , a , 12);
按照我们上面对memcpy的模拟中,无法实现像该例子的拷贝,因为我们已经改变了要拷贝部分的元素
但是在vs2019中,似乎已经将memcpy修改成了可以处理重叠内存的问题(但不重要,只要我们自己学会怎么处理就行了)

(二)memmove
1.函数原型
可以看出来,memmove和memcpy的定义是大差不差的,但它可以实现重叠内存的拷贝(虽然是这么说的,但是感觉现在memcpy和memmove的功能区别不大耶,用啥应该都行,但保险起见,还是用memmove比较好)

2.模拟实现
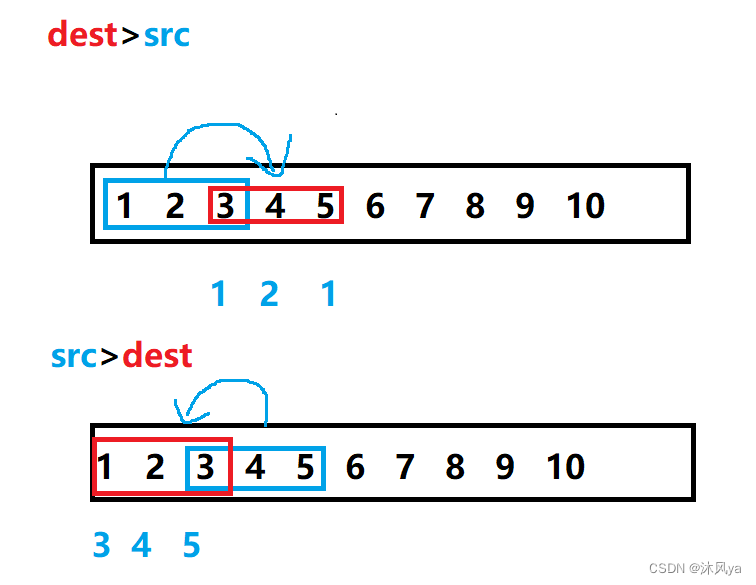
- 如果目的地址在起源地址之后:memcpy的方法不可行,会改变要拷贝部分的元素,因此我们需要换一种方法
- 如果起源地址在目的地址之后:上面的方法没有问题
- 新方法:
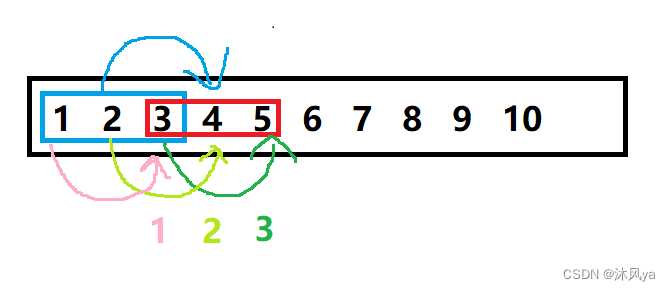
- 从要拷贝部分的末尾开始拷贝,将5改为3,再将4改为2,最后将3改为1
- 因此就不存在改变元素的问题了
- 所以我们需要处理一下起源地址和目标地址,每次循环时两个地址-1,并且总次数为count
void* work(void* p1, const void* p2, size_t n) {
void* ret = p1;
assert(p1 && p2);
if (p1 > p2) { //p1是目标地址,p2是起源地址
while (n--) {
*((char*)p1 + n) = *((char*)p2 + n);//第一次循环时n为2,刚好指向拷贝空间的最后一个元素
}
}
else {
while (n--) { //方法和之前的一样
*(char*)p1 = *(char*)p2;
++(char*)p1;
++(char*)p2;
}
}
return ret;
}
int main() {
int a[] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = work(a+2 , a , 12);
return 0;
}感谢观看~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









