







目录
SEC("uprobe//proc/self/exe:uprobed_sub")
LIBBPF_OPTS(bpf_uprobe_opts, uprobe_opts);
bpf_program__attach_uprobe_opts()
uprobes
介绍
在 Linux 内核中,uprobes(用户空间探针)是一种动态追踪技术
- uprobe 允许用户在不修改程序源代码或重新编译的情况下,动态地向用户空间程序中注入代码,从而实现对程序行为的监视和调试
- 它依赖于内核中的 uprobes 子系统
示例代码
#include <stdio.h> #include <sys/types.h> #include <unistd.h> #include <sys/syscall.h> #include <linux/unistd.h> #include <sys/uio.h> #include <stdlib.h> #include <string.h> static int __attribute__((noinline)) my_function(int x) { printf("my_function called with argument: %d\n", x); return x * 2; } int main() { int result; pid_t pid = getpid(); // Attach uprobe to my_function long ret = syscall(__NR_uprobe, "/path/to/my_binary", "my_function", 0); if (ret < 0) { perror("Failed to attach uprobe"); exit(EXIT_FAILURE); } // Call my_function result = my_function(42); printf("Result: %d\n", result); return 0; }使用syscall将uprobes附加到某个路径下的可执行文件"my_binary"中的"my_function"函数中
除了上面这种使用系统调用的方式,也可以使用之前介绍kprobes时的register_kprobe的方式,调用register_uprobe来实现
ebpf的uprobe
介绍
它允许用户在用户空间中动态地插入和观察程序的探针,以便监视应用程序的行为、性能和调试信息
- 和linux中的uprobes技术功能类似,但它拥有更灵活、更高效的用户空间函数监视功能
- 通过 libbpf 库来实现,并且可以与其他 eBPF 功能和工具链集成
- 和kprobe类似,都可以在代码中动态插入探测点
- 但作用对象不一样,kprobe用于插入内核函数,uprobe插入用户空间函数

下面介绍的,是libbpf-bootstrap库中example下的uprobe代码:
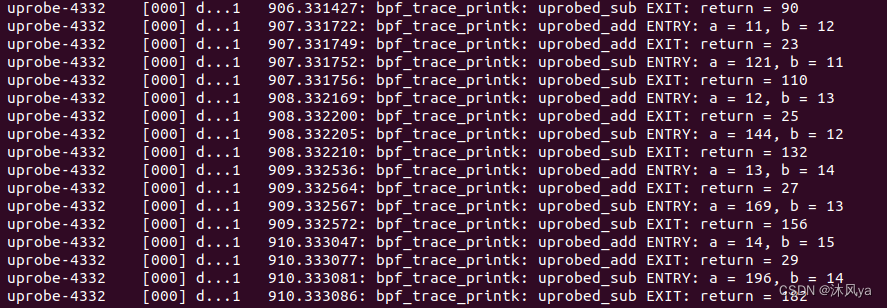
运行情况
相当于是用户层定义了俩函数,分别计算加减法
内核层在两个函数的出,入口放置了探测点
- 在入口打印两个参数的值
- 在出口打印返回值(也就是经过运算后的值)
代码解释
.bpf.c
源码
// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause /* Copyright (c) 2020 Facebook */ #include "vmlinux.h" #include <bpf/bpf_helpers.h> #include <bpf/bpf_tracing.h> char LICENSE[] SEC("license") = "Dual BSD/GPL"; SEC("uprobe") int BPF_KPROBE(uprobe_add, int a, int b) { bpf_printk("uprobed_add ENTRY: a = %d, b = %d", a, b); return 0; } SEC("uretprobe") int BPF_KRETPROBE(uretprobe_add, int ret) { bpf_printk("uprobed_add EXIT: return = %d", ret); return 0; } SEC("uprobe//proc/self/exe:uprobed_sub") int BPF_KPROBE(uprobe_sub, int a, int b) { bpf_printk("uprobed_sub ENTRY: a = %d, b = %d", a, b); return 0; } SEC("uretprobe//proc/self/exe:uprobed_sub") int BPF_KRETPROBE(uretprobe_sub, int ret) { bpf_printk("uprobed_sub EXIT: return = %d", ret); return 0; }
语法
SEC("uprobe")
一个BPF程序的section声明,表明以下的函数用于uprobe
- 如果采取这样的写法,那么就只给内核提供了该函数是有关uprobe的,但没有提供该探测点要放置在哪个进程的哪个函数
- 所以,需要在用户层代码里手动提供这些信息
SEC("uprobe//proc/self/exe:uprobed_sub")
这是Kprobe中SEC的另一种写法 -- ("uprobe形式//接口所在的可执行路径:要挂接的用户空间函数名")
- 如果采取这种写法,uprobe所需的条件就全部满足了,那么在用户层代码里就不需要手动处理了
.c
源码
// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) /* Copyright (c) 2020 Facebook */ #include <errno.h> #include <stdio.h> #include <unistd.h> #include <sys/resource.h> #include <bpf/libbpf.h> #include "uprobe.skel.h" static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args) { return vfprintf(stderr, format, args); } /* It's a global function to make sure compiler doesn't inline it. To be extra * sure we also use "asm volatile" and noinline attributes to prevent * compiler from local inlining. */ __attribute__((noinline)) int uprobed_add(int a, int b) { asm volatile (""); return a + b; } __attribute__((noinline)) int uprobed_sub(int a, int b) { asm volatile (""); return a - b; } int main(int argc, char **argv) { struct uprobe_bpf *skel; int err, i; LIBBPF_OPTS(bpf_uprobe_opts, uprobe_opts); /* Set up libbpf errors and debug info callback */ libbpf_set_print(libbpf_print_fn); /* Load and verify BPF application */ skel = uprobe_bpf__open_and_load(); if (!skel) { fprintf(stderr, "Failed to open and load BPF skeleton\n"); return 1; } /* Attach tracepoint handler */ uprobe_opts.func_name = "uprobed_add"; uprobe_opts.retprobe = false; /* uprobe/uretprobe expects relative offset of the function to attach * to. libbpf will automatically find the offset for us if we provide the * function name. If the function name is not specified, libbpf will try * to use the function offset instead. */ skel->links.uprobe_add = bpf_program__attach_uprobe_opts(skel->progs.uprobe_add, 0 /* self pid */, "/proc/self/exe", 0 /* offset for function */, &uprobe_opts /* opts */); if (!skel->links.uprobe_add) { err = -errno; fprintf(stderr, "Failed to attach uprobe: %d\n", err); goto cleanup; } /* we can also attach uprobe/uretprobe to any existing or future * processes that use the same binary executable; to do that we need * to specify -1 as PID, as we do here */ uprobe_opts.func_name = "uprobed_add"; uprobe_opts.retprobe = true; skel->links.uretprobe_add = bpf_program__attach_uprobe_opts( skel->progs.uretprobe_add, -1 /* self pid */, "/proc/self/exe", 0 /* offset for function */, &uprobe_opts /* opts */); if (!skel->links.uretprobe_add) { err = -errno; fprintf(stderr, "Failed to attach uprobe: %d\n", err); goto cleanup; } /* Let libbpf perform auto-attach for uprobe_sub/uretprobe_sub * NOTICE: we provide path and symbol info in SEC for BPF programs */ err = uprobe_bpf__attach(skel); if (err) { fprintf(stderr, "Failed to auto-attach BPF skeleton: %d\n", err); goto cleanup; } printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` " "to see output of the BPF programs.\n"); for (i = 0;; i++) { /* trigger our BPF programs */ fprintf(stderr, "."); uprobed_add(i, i + 1); uprobed_sub(i * i, i); sleep(1); } cleanup: uprobe_bpf__destroy(skel); return -err; }看着好像挺长的,其实我们可以把这份用户层代码分成个部分:
- 两个用户空间函数(即将被挂接的函数)
- ebpf程序的一些初始化
- 手动提供uprobe使用时需要的条件
- 挂载bpf程序
- for循环里调用那两个要被探测的函数
语法
asm volatile ("");

LIBBPF_OPTS(bpf_uprobe_opts, uprobe_opts);
定义了一个 bpf_uprobe_opts结构体,用于传递uprobe的选项,例如要跟踪的函数名称、是否是返回探针等
struct bpf_uprobe_opts { /* size of this struct, for forward/backward compatibility */ size_t sz; /* offset of kernel reference counted USDT semaphore, added in * a6ca88b241d5 ("trace_uprobe: support reference counter in fd-based uprobe") */ size_t ref_ctr_offset; /* custom user-provided value fetchable through bpf_get_attach_cookie() */ __u64 bpf_cookie; /* uprobe is return probe, invoked at function return time */ bool retprobe; /* Function name to attach to. Could be an unqualified ("abc") or library-qualified * "abc@LIBXYZ" name. To specify function entry, func_name should be set while * func_offset argument to bpf_prog__attach_uprobe_opts() should be 0. To trace an * offset within a function, specify func_name and use func_offset argument to specify * offset within the function. Shared library functions must specify the shared library * binary_path. */ const char *func_name; /* uprobe attach mode */ enum probe_attach_mode attach_mode; size_t :0; };
- 可以将这些选项传递给BPF程序的加载和附加函数,以实现相应的功能
- 这就是我们上面介绍的,为uprobe提供需要的条件
uprobe_opts.func_name
指定要跟踪的目标函数的函数名
uprobe_opts.retprobe
用于指示是否为返回探针
bpf_program__attach_uprobe_opts()
将bpf程序与用户空间探针(uprobe)相关联.并在指定的目标函数入口或返回处插入探针
struct bpf_link *bpf_program__attach_uprobe_opts(struct bpf_program *prog, pid_t pid, const char *binary_path, uint64_t offset,const struct bpf_uprobe_opts *opts);- 就像这样传参:
- 返回一个struct bpf_link结构的指针,表示创建的 BPF 程序链接


skel->links.uprobe_add
还记得我们的kprobe_bpf结构体吗,它会自动根据内核层代码生成结构体定义:
其中,progs结构体存放了探针函数的结构体指针
links结构体表示一个 BPF 程序与内核中特定探针(uprobe)的链接
- 存放的字段用于描述 BPF 程序与内核探针之间的关系,以及与之相关的资源信息

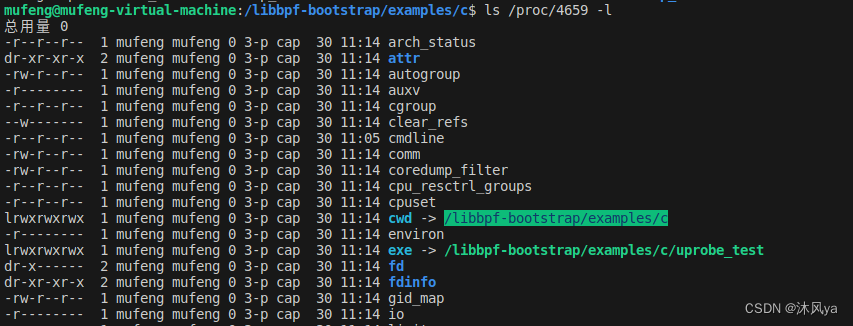
/proc/self/exe
一个进程的绝对地址
- 和之前在进程那里介绍过的cwd文件(工作目录)在同一个目录下:
修改内核层写法
介绍
所以我们考虑将减法那种提前提供好信息的写法改成需要手动绑定的加法
- 多练点没坏处嘛

.bpf.c
首先将减法这里的信息删掉,只剩下指定uprobe形式
SEC("uprobe") int BPF_KPROBE(uprobe_sub, int a, int b) { bpf_printk("uprobed_sub ENTRY: a = %d, b = %d", a, b); return 0; } SEC("uretprobe") int BPF_KRETPROBE(uretprobe_sub, int ret) { bpf_printk("uprobed_sub EXIT: return = %d", ret); return 0; }
.c
然后照猫画虎,给uprobe_opts提供相应的数据
以及使用bpf_program__attach_uprobe_opts函数将bpf程序与用户空间探针相关联
最后将返回值赋给skel的links结构
/* Attach tracepoint handler */ uprobe_opts.func_name = "uprobed_sub"; uprobe_opts.retprobe = false; /* uprobe/uretprobe expects relative offset of the function to attach * to. libbpf will automatically find the offset for us if we provide the * function name. If the function name is not specified, libbpf will try * to use the function offset instead. */ skel->links.uprobe_sub = bpf_program__attach_uprobe_opts(skel->progs.uprobe_sub, 0 /* self pid */, "/proc/self/exe", 0 /* offset for function */, &uprobe_opts /* opts */); if (!skel->links.uprobe_sub) { err = -errno; fprintf(stderr, "Failed to attach uprobe: %d\n", err); goto cleanup; } /* we can also attach uprobe/uretprobe to any existing or future * processes that use the same binary executable; to do that we need * to specify -1 as PID, as we do here */ uprobe_opts.func_name = "uprobed_sub"; uprobe_opts.retprobe = true; skel->links.uprobe_sub = bpf_program__attach_uprobe_opts( skel->progs.uprobe_sub, -1 /* self pid */, "/proc/self/exe", 0 /* offset for function */, &uprobe_opts /* opts */); if (!skel->links.uprobe_sub) { err = -errno; fprintf(stderr, "Failed to attach uprobe: %d\n", err); goto cleanup; }
将两个用户函数单拎到一个文件里
介绍
其实需要探测的用户空间函数和我们的bpf程序不在一个文件里的可能性更大,所以我们也需要学习该如何插入探测点到不在一个文件的函数
新建.c文件
放置我们的用户函数并调用
(可以限制一下a和b的大小,更方便看一些)
#include <stdio.h> #include <unistd.h> /* It's a global function to make sure compiler doesn't inline it. To be extra * sure we also use "asm volatile" and noinline attributes to prevent * compiler from local inlining. */ __attribute__((noinline)) int uprobed_add(int a, int b) { return a + b; } __attribute__((noinline)) int uprobed_sub(int a, int b) { return a - b; } int main() { int i = 0; for (i = 0;; i++) { /* trigger our BPF programs */ uprobed_add(i, i + 1); uprobed_sub(i * i, i); if (i >= 10) { i = 0; } } return 0; }
.c
然后将.c文件里有关这两个函数的代码删除
并且要在代码里提供用户函数所在的可执行文件的信息(通过命令行传入)
- 可执行文件的路径
- 进程pid(因为这里已知函数所在的进程,所以直接传入pid)
if (argc != 2) { fprintf(stderr, "./uprobe pid\n"); return 0; } int pid = atoi(argv[1]); char path[20]; snprintf(path, sizeof(path) - 1, "/proc/%s/exe", argv[1]); ... skel->links.uprobe_add = bpf_program__attach_uprobe_opts(skel->progs.uprobe_add, pid /* self pid */, path, 0 /* offset for function */, &uprobe_opts /* opts */); ... }
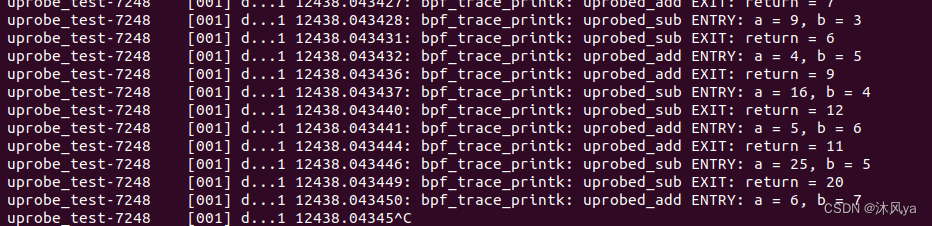
运行情况
将用户函数所在程序以后台任务的形式启动(其实都行,但后台方便一点,而且还会自动显示自己的pid):
将pid传入uprobe进程,即可指定bpf程序需要和哪个进程交互:
如果去掉写有用户函数的进程的符号链接
介绍
当可执行文件被 "strip" 后,符号表信息被去除
- 那么其他程序无法直接通过符号名称来访问其中的函数或变量
如果去掉了符号链接,那么里面包含的函数的符号也没有了
那其他程序将无法访问该函数,自然ebpf程序就无法在那两个函数的出入口放探测点
- 所以,我们需要手动链接
- 其实就是手动找到函数汇编代码的所在地址
问题
我们先来验证一下,被strip的用户函数程序,是否还能让bpf成功插入探测点
首先先备份一份可执行文件:
然后启动被strip的可执行文件:
启动bpf程序:
- 发现显示无法找到可执行文件的符号表,自然也无法找到add函数的符号


解决
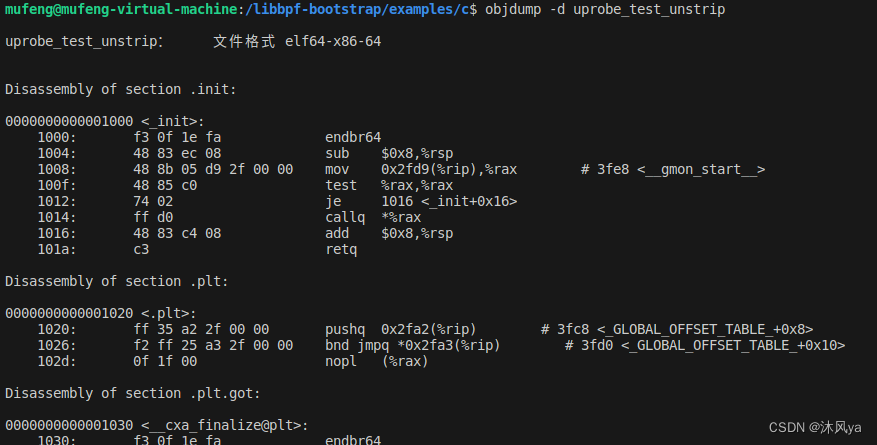
通过未被strip的程序找到用户函数符号的汇编地址:
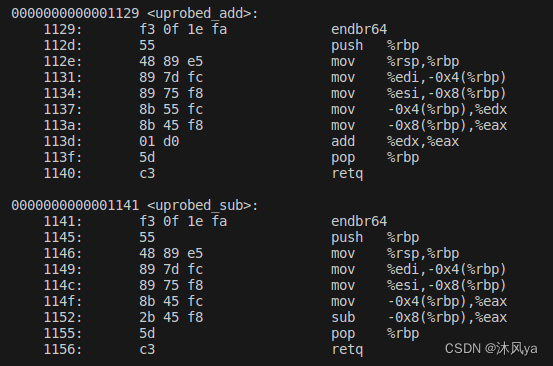
- 对没有strip的可执行文件进行反汇编,并查找 uprobe_add 和 uprobe_sub 符号的汇编指令地址
- 然后找到那两个函数的符号:
既然符号链接已经没有了,说明函数名已经没有用了,就需要在bpf程序中删除:
- (如果是修改后的.c文件,需要注释四处这句代码)
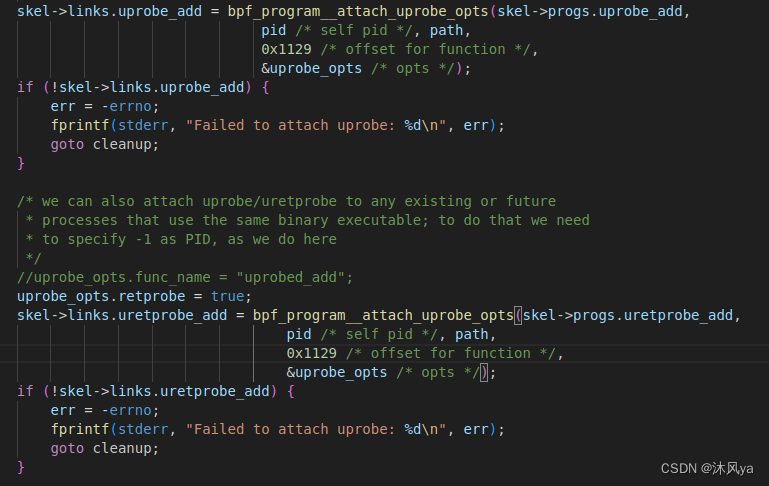
然后手动链接bpf程序和用户函数:
- func_offset 参数赋值 = 获取的函数符号汇编指令地址
重新编译后启动bpf程序:


















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









