







目录
LIBBPF_OPTS(bpf_uprobe_opts, attach_opts, .func_name = "malloc", .retprobe = false);
bpf_program__attach_uprobe_opts
bpf_map_get_next_key(fd, prev_key, &key)
bpftime(开源用户态 eBPF 运行时)
参考 -- bpftime: 让 eBPF 从内核扩展到用户空间 - 知乎 (zhihu.com),用户空间 eBPF 运行时:深度解析与应用实践 - 知乎 (zhihu.com)
引入
在内核态实现用户态追踪的性能损失
ebpf中的Uprobe 是一种强大的用户级动态追踪机制,它允许开发者在用户空间的程序中进行动态插入探测点
- eg:在函数的入口点、特定的代码偏移位置,以及函数的返回点
这种技术的实现是通过在指定的位置设置断点
- 例如在 x86 架构上使用 int3 指令:
- 当执行流到达这一点时,程序会陷入内核,触发一个事件,随后执行预定义的探针函数,完成后返回用户态继续执行
- 这种动态追踪方法,能够在系统范围内跟踪和插桩所有执行特定文件的进程 -- 即允许在不修改代码、重新编译或重启进程的情况下,收集性能分析和故障诊断的关键数据
但是,eBPF 虚拟机是在内核态执行的
- kprobe实现并不会被影响什么
- 但当前的 uprobe插入的探测点是在用户空间内的程序 -> 会在内核中引入两次上下文切换,造成了显著的性能开销(特别是在延迟敏感的应用中这种开销会严重影响性能)
- 和 Kprobe 相比,Uprobe 的开销接近十倍:
另一方面,Uprobe 目前也仅限于追踪,无法修改用户态函数的执行流程,或者修改函数的返回值
- 这也限制了 Uprobe 的使用场景,无法进行代码扩展、热补丁、缺陷注入等操作
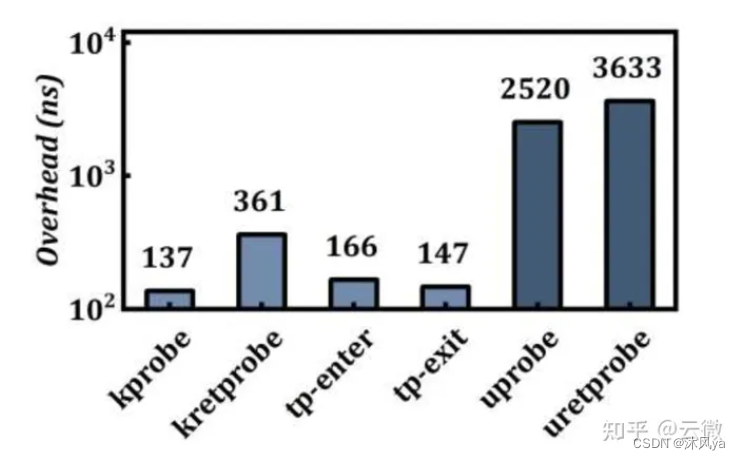
内核空间执行ebpf的弊端
在内核空间,ebpf的执行通常需要 root 访问权限
- 这可能无意中增加了系统的攻击面,使其容易受到例如容器逃逸或潜在的内核利用等安全威胁
而用户空间的实现,可以让ebpf程序在这种高风险环境之外运作
- 它们在用户空间中运行,大大降低了对高权限的依赖,从而减少了潜在的安全风险
内核态 -> 用户态
虽然eBPF 最初是为内核设计的,但它在用户空间也具有巨大的潜力 -- 也就是我们在上面介绍的两种原因(当然不止这些),以及内核对于GPL LICENSE的限制,这样自然而然地就催生出了早期的用户空间 eBPF 运行时
- eg: ubpf 和 rbpf
- GPL LICENSE -- 自由软件许可证
这些运行时允许开发者在内核之外利用 eBPF 的能力,提供了一个在内核之外的运行平台,扩展其实用性和适用性,同时不受限于 GPL LICENSE
但是,这些工具有很多缺点:
- 编写适用于 ubpf 和 rbpf 的程序可能需要一个特定的、和内核不完全兼容的工具链,同时只有有限的单线程哈希 maps 实现,难以运行实际的 eBPF 程序
- ubpf 和 rbpf 本身只是一个执行 eBPF 字节码虚拟机,在实际的使用中,依然需要编写胶水代码,和其他用户空间程序进行编译、链接后才能使用,它们本身也不提供动态追踪的功能
所以,bpftime就是基于[认识到其他用户空间运行时的弊端+ebpf的用户空间化的需求],设计出的一个高性能ebpf用户空间运行时
介绍
bpftime是基于 LLVM JIT/AOT 构建的bpftime是专为用户空间操作设计的一个高性能 eBPF 运行时
- bpftime 希望能保持和现有的内核 eBPF 的良好兼容性,作为内核 eBPF 的一种用户态替代和改进方案,并且希望能最大程度上利用现有 eBPF 丰富的生态和工具
- 它以其快速的 Uprobe 能力和 Syscall 钩子脱颖而出(尤其是uprobe性能比在内核中运行提供了10倍):
bpftime 可以类似 Kernel 中的 Uprobe 那样
- 自动将 eBPF 运行时注入到用户空间进程中
- 无需修改用户空间进程的代码,也无需进行重启进程即可使用
- 只不过一个运行在内核态,一个运行在用户态
在某些场景下,bpftime 可能能作为 kernel eBPF 的一种替代方案
- 它也不依赖于具体内核版本或 Linux 平台,可以在其他平台上运行
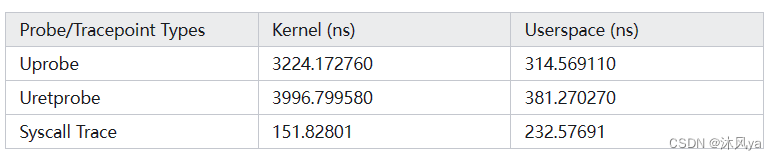
原理图
- 它是直接向用户空间程序里注入ebpf程序
- 并且创建了用户空间的两个共享内存,用于存放ebpf程序和用户程序之间的通信数据
- 它依赖于bpftime中提供的文件
除此之外,它也可以和内核内的uprobe一起运行:
- 可以看见,内核中的uprobe是需要依赖内核中的bpf沙盒程序的,所以他必然要经历内核与用户态之间的转换


示例代码
项目的安装方法在之前已经介绍过了 -- bpf,ebpf,libbpf,在ubuntu22中ebpf工具的安装和介绍(libbpf_bootstarp,eunomia-bpf,bpftiime),关系总结,ebpf程序执行流程_libbpf_bpftool ebpf-CSDN博客
如何编译和运行
我们以官方文档中的例子来测试(在bpftime目录下执行):
编译
make -C example/malloc当然也可以直接在malloc目录下执行make
运行
这里如果直接运行的话会提示缺少某个动态库文件
我们可以手动搞一个符号链接,让他可以识别上
或者在命令行里链接
- LD_PRELOAD是一个环境变量,用于指定要在程序运行时预加载的共享库
LD_PRELOAD=build/runtime/syscall-server/libbpftime-syscall-server.so example/malloc/malloc这是我们的ebpf程序
运行结果
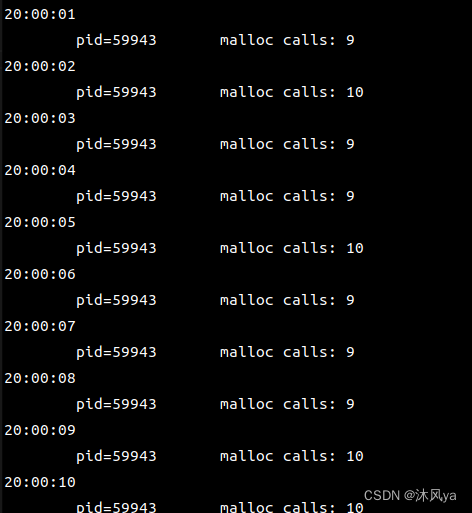
向内核注入ebpf程序,每隔1s打印一下时间,并从map中统计进程调用malloc的次数(此时因为还没有进程向map中插入数据,所以只会打印时间):

LD_PRELOAD=build/runtime/agent/libbpftime-agent.so example/malloc/victim这是测试程序
运行结果
运行测试代码,它每隔100ms调用一次malloc:
在他运行后,malloc程序就可以记录那个测试进程每秒执行的malloc次数了
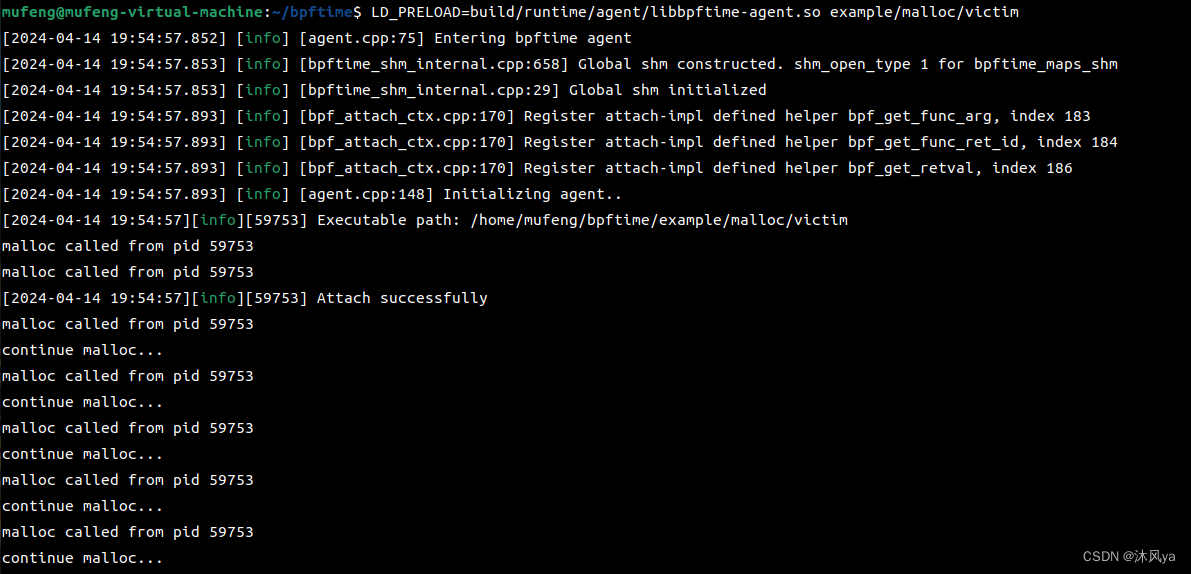
代码分析
.c
源码
// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) /* Copyright (c) 2020 Facebook */ #include <signal.h> #include <stdio.h> #include <time.h> #include <stdint.h> #include <sys/resource.h> #include <bpf/libbpf.h> #include <bpf/bpf.h> #include <unistd.h> #include <stdlib.h> #include "malloc.skel.h" #include <inttypes.h> #define warn(...) fprintf(stderr, __VA_ARGS__) static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args) { return vfprintf(stderr, format, args); } static volatile bool exiting = false; static void sig_handler(int sig) { exiting = true; } static int print_stat(struct malloc_bpf *obj) { time_t t; struct tm *tm; char ts[16]; uint32_t key, *prev_key = NULL; uint64_t value; int err = 0; int fd = bpf_map__fd(obj->maps.libc_malloc_calls_total); time(&t); tm = localtime(&t); strftime(ts, sizeof(ts), "%H:%M:%S", tm); printf("%-9s\n", ts); while (1) { //从一个 eBPF Map 中获取键值对并进行处理 err = bpf_map_get_next_key(fd, prev_key, &key);//获取下一个键,当prev=null时,获取第一个键 if (err) { if (errno == ENOENT) { //没有其他键 err = 0; break; } warn("bpf_map_get_next_key failed: %s\n", strerror(errno)); return err; } err = bpf_map_lookup_elem(fd, &key, &value); //查找指定键的值 if (err) { warn("bpf_map_lookup_elem failed: %s\n", strerror(errno)); return err; } printf(" pid=%-5" PRIu32 " ", key); printf(" malloc calls: %" PRIu64 "\n", value); err = bpf_map_delete_elem(fd, &key); //处理完成后删除,这样就能实现 记录1s中malloc调用的次数 if (err) { warn("bpf_map_delete_elem failed: %s\n", strerror(errno)); return err; } prev_key = &key;//更新prev } fflush(stdout); //及时刷新缓冲区 return err; } int main(int argc, char **argv) { struct malloc_bpf *skel; int err; /* Set up libbpf errors and debug info callback */ libbpf_set_print(libbpf_print_fn); /* Cleaner handling of Ctrl-C */ signal(SIGINT, sig_handler); signal(SIGTERM, sig_handler); /* Load and verify BPF application */ skel = malloc_bpf__open(); if (!skel) { fprintf(stderr, "Failed to open and load BPF skeleton\n"); return 1; } /* Load & verify BPF programs */ err = malloc_bpf__load(skel); if (err) { fprintf(stderr, "Failed to load and verify BPF skeleton\n"); goto cleanup; } LIBBPF_OPTS(bpf_uprobe_opts, attach_opts, .func_name = "malloc", .retprobe = false); //设置选项,宏定义一个类型为bpf_uprobe_opts的结构体attach_opts,设置监视函数名为malloc,在函数调用前设置执行钩子动作 struct bpf_link *attach = bpf_program__attach_uprobe_opts( //将 uprobes 附加到指定的函数上,并传递了设置的选项 //(指定了 BPF 程序的文件描述符,监视的进程pid,监视函数所在的共享对象的名称, skel->progs.do_count, -1, "libc.so.6", 0, &attach_opts); if (!attach) { fprintf(stderr, "Failed to attach BPF skeleton\n"); err = -1; goto cleanup; } while (!exiting) { sleep(1); print_stat(skel); //打印当前时间 } cleanup: /* Clean up */ malloc_bpf__destroy(skel); return err < 0 ? -err : 0; }总之,总体框架和libbpf-bootstrap工具中编写的用户层代码基本一致
- 它主要的工作是控制ebpf程序的生命周期,并且在将ebpf成功挂接到探测点时,每隔1s从map中获取数据,打印并删除
语法
#include "malloc.skel.h"
和libbpf-bootstrap工具一样,都会根据内核层代码生成skel.h辅助头文件,需要被用户层代码包含
LIBBPF_OPTS(bpf_uprobe_opts, attach_opts, .func_name = "malloc",
.retprobe = false);和之前介绍的语法是一样的,只是写法不同(这里是一块赋值,之前是分开赋值):
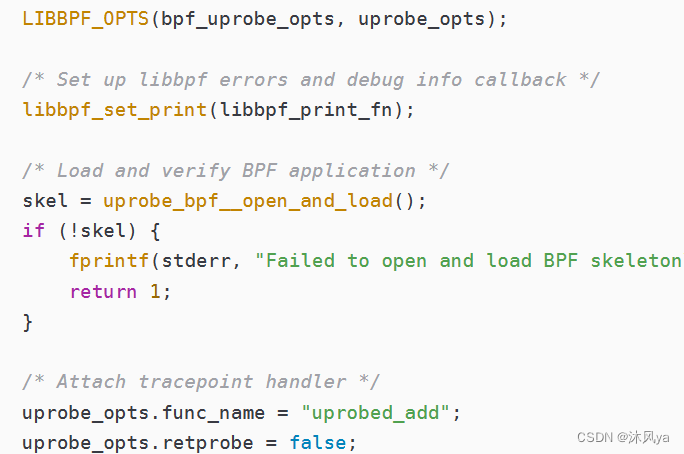
bpf_program__attach_uprobe_opts
第一个参数使用的是探测点函数的指针,它会在progs里被定义

bpf_map__fd()
使用该函数可以获取map的fd(用户层是通过fd操作map的)
- 参数是skel.h文件中自动为我们生成的malloc_bpf结构体中的maps中的字段(其实就是map对象名):

bpf_map_get_next_key(fd, prev_key, &key)
可以从map中(通过fd标识map)获取下一个键(赋值给key)
- 当prev=null时,获取第一个键
- 如果返回非0,表示没有找到;如果同时错误码被设置为ENOENT,说明此时map中没有其他键
bpf_map_delete_elem()
删除指定键值对
.bpf.c
源码
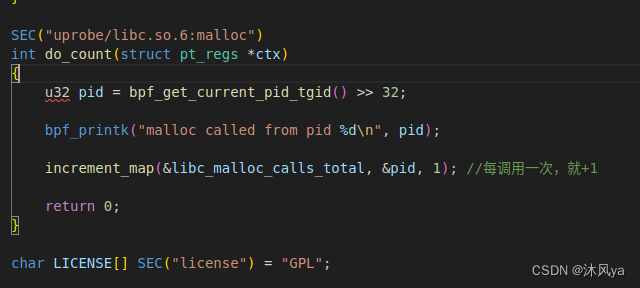
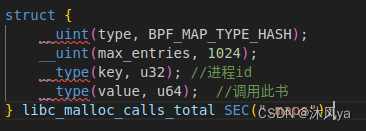
#define BPF_NO_GLOBAL_DATA #include <vmlinux.h> #include <bpf/bpf_helpers.h> #include <bpf/bpf_tracing.h> struct { __uint(type, BPF_MAP_TYPE_HASH); __uint(max_entries, 1024); __type(key, u32); //进程id __type(value, u64); //调用此书 } libc_malloc_calls_total SEC(".maps"); static int increment_map(void *map, void *key, u64 increment) { u64 zero = 0, *count = bpf_map_lookup_elem(map, key); if (!count) { //如果count不存在 bpf_map_update_elem(map, key, &zero, BPF_NOEXIST); count = bpf_map_lookup_elem(map, key); if (!count) { //如果还是不存在 return 0; } } //已经存在,更新次数 u64 res = *count + increment; bpf_map_update_elem(map, key, &res, BPF_EXIST); return *count; } SEC("uprobe/libc.so.6:malloc") int do_count(struct pt_regs *ctx) { u32 pid = bpf_get_current_pid_tgid() >> 32; bpf_printk("malloc called from pid %d\n", pid); increment_map(&libc_malloc_calls_total, &pid, 1); //每调用一次,就+1 return 0; } char LICENSE[] SEC("license") = "GPL";执行两种操作:
- 如果key值不存在,就插入(key,0)
- 如果key值存在,更新对应的value(+1)















 1282
1282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









