









 本文介绍了使用json和protobuf这两种工具进行数据序列化和反序列化的C++实现,包括json的轻量化特性、protobuf的效率优势,以及如何在代码中集成和处理不同格式的数据转换。
本文介绍了使用json和protobuf这两种工具进行数据序列化和反序列化的C++实现,包括json的轻量化特性、protobuf的效率优势,以及如何在代码中集成和处理不同格式的数据转换。
目录
现成的序列化,反序列化工具
引入
前一篇我们介绍了如何自己实现序列化和反序列化 --
- 但其实前人已经帮我们探索过了,已经实现出了很多的工具,我们只需要使用即可
- 当然,自己能写出来也是必要的能力,可以让你更好地理解其他工具的原理
json
可视化的序列化/反序列化,方便调试
是一种轻量级的数据交换格式
- 它是一种文本格式,用于在不同的系统之间传递和存储数据
- JSON格式易于阅读和编写,同时也易于解析和生成,因此在网络通信、数据存储和配置文件等场景中得到了广泛的应用
protobuf
强调效率
Protocol Buffers(简称 Protobuf)是一种由 Google 开发的轻量级、高效的数据序列化框架
- 它允许定义简单且高效的数据结构,然后使用自动生成的代码在各种编程语言之间轻松地序列化和反序列化这些结构化数据
Json
引入
接下来我们就在之前的网络计算器代码中使用一下json格式
- 感受它带来的便利
- 介绍一些在替换过程中会出现的问题
首先,我们需要先支持json (不同语言都提供支持json,这里以c++为例)
安装json库
在c++里需要安装第三方库 -- jsoncpp
- 里面包括头文件/usr/include/jsoncpp/json
- 库文件/lib64/libjsoncpp.so
- 安装命令 -- sudo yum install jsoncpp jsoncpp-devel
如何编译
和pthread库类似,需要我们手动在编译语句中链接jsoncpp库
- 这里插一嘴,动态库库名就是去掉前缀lib,去掉后缀.so的部分
- 可以直接定义一个变量Lib(不定义也行的啦,都可以),用它代替链接选项
- (Flag的作用将在下面介绍)
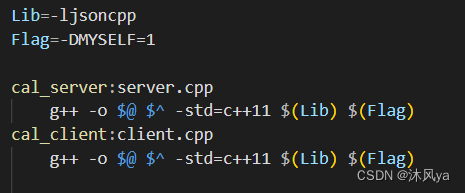
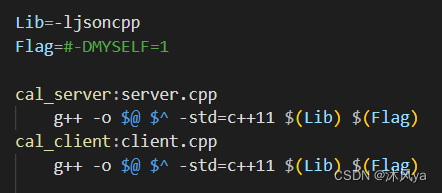
.PHONY:all all:cal_server cal_client Lib=-ljsoncpp Flag=#-DMYSELF=1 cal_server:server.cpp g++ -o $@ $^ -std=c++11 $(Lib) $(Flag) cal_client:client.cpp g++ -o $@ $^ -std=c++11 $(Lib) $(Flag) .PHONY:clean clean: rm -f cal_server cal_client
json格式
以key-value形式序列化
- 组织形式 -- {"key":value , ...}
- 多个kv用逗号隔开
- (不同的json对象,序列化后的格式略有不同)
本质上是一个大字符串

万能对象
介绍
json里有一个万能类Value
- 它可以表示 JSON 中的任何数据类型,会根据赋给它的值的类型自动推断其自身的类型
- 它可以作为对象或数组的容器
作为对象的容器时
- 它重载了[ ],可以像使用map一样插入键值对(值的类型不限定)
- 其中,key值要用双引号引起来:
Json::Value root; root["name"] = "John";- 访问时和map一样,知道key值就可以拿到对应的value
作为数组的容器时
- 需要显式告诉编译器,这里要实例化出一个数组类型 -- Json::Value array(Json::arrayValue)
- 插入数值时,使用append方法 -- array.append("apple")
- 访问时,可以使用下标访问对象,它也支持范围for这个语法糖

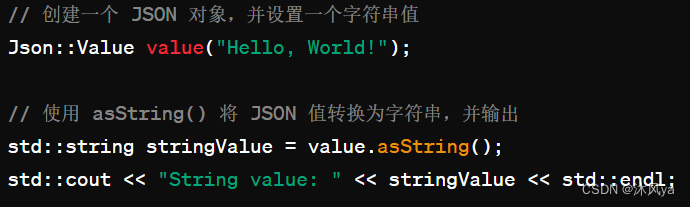
as...成员函数
可以使用json对象的成员函数 as... ,将json中的元素转换为指定格式
- 如果不指定类型,默认是Json::Value类型
示例:
序列化
介绍
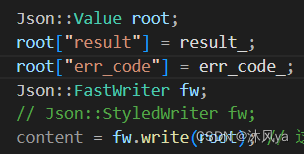
可以使用某些特定对象的write方法,对value对象进行序列化
- 传入value对象,生成string对象
特定对象
FastWriter
- 提供了一种快速的方式将 JSON 数据转换为字符串
- 它不对输出进行格式化,而是尽可能地减少生成的字符串的大小
StyledWriter
- 可读性会更好
- 它会对输出进行缩进和换行,每个键值对都单独占用一行
反序列化
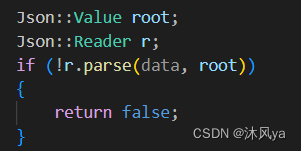
介绍
使用特定对象的parse方法,可以将string对象反序列化成value对象
- 传入string对象和value对象
- 返回bool值
特定对象
Reader
在代码里使用json
引入
知道了基本语法后,接下来就该把json插入到我们的代码里了
- 我们这里不把原来的自定义方法注释掉,而是采用条件编译
添加条件编译
介绍
采用宏定义,将自定义的序列化和使用json格式的序列化区分开
- 如果定义了MYSELF这个宏,就使用自定义方法
- 如果未定义,则使用json
定义宏
可以在编译器那里定义宏(这样不需要修改源代码,直接修改编译语句即可)
- 语法 -- -D+宏定义
- 宏定义语法 -- 宏=宏的数值
也可以使用变量替换掉我们定义的宏
- 使用的语法 -- $(变量名)
如果不需要这个宏定义,用#注释
原理
我们一直都知道,编译过程的第一步就是预处理
- 去掉注释,展开头文件,支持条件编译等
说明编译器具有对代码添加/修改/删除的能力,所以他自然也可以帮助我们新增一个宏定义
- 只不过这不是他自发的行为,而是我们主动让它去做的
代码
引入
因为我们的计算器直接对输入表达式进行计算
- 所以请求是没有序列化反序列化的(本来就是字符串),当然加了也可以,只不过这个json对象里只会有一个元素
而我们的输出结果是需要序列化/反序列化的
介绍
class response { public: response(int result, int err) : result_(result), err_code_(err) {} response() {} // 用于接收反序列化的对象 ~response() {} void serialize(std::string &content) { #ifdef MYSELF //-> "result_ err_code_" content = std::to_string(result_); content += " "; content += std::to_string(err_code_); #else Json::Value root; root["result"] = result_; root["err_code"] = err_code_; Json::FastWriter fw; // Json::StyledWriter fw; content = fw.write(root); // 这里生成的string对象里,末尾有\n,所以我们需要更换分隔符,否则代码会出错 std::cout<<"content: "<<content; #endif } bool deserialize(const std::string &data) { #ifdef MYSELF //"result_ err_code_" -> result_,err_code_ size_t pos = data.find(space_sep); if (pos == std::string::npos) { return false; } result_ = std::stoi(data.substr(0, pos)); err_code_ = std::stoi(data.substr(pos + 1)); return true; #else Json::Value root; Json::Reader r; if (!r.parse(data, root)) { return false; } result_ = root["result"].asInt(); err_code_ = root["err_code"].asInt(); return true; #endif } public: int result_; int err_code_; };
运行结果
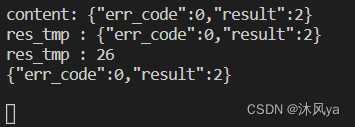
我们可以添加打印语句,来查看json序列化前后的字符串:
- content和第一个res_tmp都是序列化后的字符串(注意,这里我并没有打印换行符,它确实是自己转换后本来就有的,这里额外的换行符会导致代码出错,等会儿就会介绍这个问题,坑死我了)
- 第二个res_tmp是封装报头后的字符串(添加了有效载荷大小和两个分隔符)
注意点(decode代码)
千万不要以为这样就完事大吉了,因为它自行添加了我们定义的分隔符,就会导致有效载荷里包含了分隔符
- 但我们在解包时,是直接寻找分隔符的,所以找到的第二个分隔符少了一个单位
- 图示:
- 结合我们的代码:
size_t left = content.find(protocol_sep); if (left == std::string::npos) // 不完整的报文 { return false; } size_t right = content.find(protocol_sep, left + 1); if (right == std::string::npos) // 不完整的报文 { return false; }那么,就会判断出理论size和实际size不同->错误报文->被删除了
(坑死我了这个问题,debug了好久)
// 这样会导致万一有效载荷结尾正好有我们定义的分隔符,就会导致判断为错误报文,因为right指向少了一个字符 if (right - left != size + 1) // 错误的报文 -- right-left-1是实际有效长度,而size是理论有效长度,如果二者不匹配,说明封装上就有问题/传数据有问题 { // std::cout << "left:" << left << "right:" << right << "size:" << size; content.erase(0, size_arr.size() + 1 + right - left); // 两个分隔符+数字长度+实际数据长度 return false; }所以需要修改我们的判断语句:
// 改成下面这样,宽泛地判断即可(这样就不需要修改分隔符了,只要确保有效数据里不含分隔符即可,而不用考虑序列化后会不会包含) if (size + size_arr.size() + 2 > content.size()) // 如果有效载荷理论长度+size长度+两个分隔符>当前报文长度,说明此时报文不完整 { return false; }完整的decode代码:
bool decode(std::string &content, std::string &data) // 把非法的/处理完成的报文删除 { // std::cout << "content : " << content; size_t left = content.find(protocol_sep); if (left == std::string::npos) // 不完整的报文 { return false; } size_t right = content.find(protocol_sep, left + 1); if (right == std::string::npos) // 不完整的报文 { return false; } // 拆出size std::string size_arr = content.substr(0, left); if (size_arr[0] < '0' || size_arr[0] > '9') // 注意size_arr里存放的不一定是数字 { content.erase(0, size_arr.size() + 1); // 包括分隔符 return false; } int size = std::stoi(size_arr); // // 这样会导致万一有效载荷结尾正好有我们定义的分隔符,就会导致判断为错误报文,因为right指向少了一个字符 // if (right - left != size + 1) // 错误的报文 -- right-left-1是实际有效长度,而size是理论有效长度,如果二者不匹配,说明封装上就有问题/传数据有问题 // { // // std::cout << "left:" << left << "right:" << right << "size:" << size; // content.erase(0, size_arr.size() + 1 + right - left); // 两个分隔符+数字长度+实际数据长度 // return false; // } // 改成下面这样,宽泛地判断即可(这样就不需要修改分隔符了,只要确保有效数据里不含分隔符即可,而不用考虑序列化后会不会包含) if (size + size_arr.size() + 2 > content.size()) // 如果有效载荷理论长度+size长度+两个分隔符>当前报文长度,说明此时报文不完整 { return false; } data = content.substr(left + 1, size); // 截断size长度的数据(这个就是完整的有效数据) content.erase(0, size + size_arr.size() + 2); // 两个分隔符+数字的长度 return true; }

可以支持不同的序列化/反序列化方法
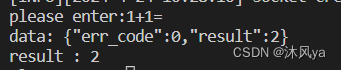
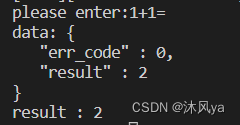
一旦修改后,我们就可以丝滑地切换不同的序列化/反序列化方法:
fastwriter:
styledwriter:
自定义:
- 因为打印的是反序列化后的结果,所以没有经过报头封装,所以没有换行符

原理
为什么我们的代码可以不需要修改,而支持不同格式的序列化字符串呢?
- 就是因为我们并不依靠分隔符来拿取有效载荷(万一某个格式里的字符串正好就包含我们自定义的分隔符呢),而是通过拆分出来的size直接读取对应长度的字符
- size中只会包含数字,不可能包含我们定义的\n,所以可以正确拿到报文大小,自然就可以拿到正确的有效载荷















 1148
1148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









