







简介
生成式AI正以前所未有的速度改变我们的世界,从内容创作到智能客服,再到医疗诊断,它正在成为各行各业的核心驱动力。然而,构建一个高效、安全且负责任的生成式AI系统并非易事。本文将带你从零开始,逐步完成一个完整的生成式AI开发流程,并提供详细的代码示例和知识点解析,确保你能够轻松上手并深入理解每个环节。
第一章:明确业务需求与目标设定
1.1 确定应用场景
在开发任何AI系统之前,首先需要明确其应用场景和业务目标。这一步决定了后续的技术选型和开发方向。
案例:医疗问答助手
我们将构建一个医疗问答助手,帮助患者根据症状获取初步建议。
知识点解释:
- 业务场景定义:明确AI系统的具体用途,便于后续技术决策。
- 性能要求:设定可量化的指标,例如响应时间和准确率,作为系统优化的目标。
第二章:数据准备——构建高质量的数据基础
数据是生成式AI的核心,高质量的数据决定了模型的表现。本章将详细介绍数据收集、清洗、分割和向量化的过程。
2.1 数据收集
使用公开数据集或API获取相关数据。以下是调用PubMed API获取医疗文献的示例。
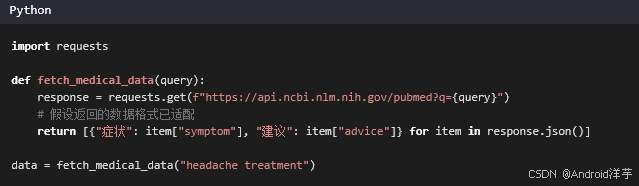
知识点解释:
- 数据来源:选择权威且相关的数据源,如PubMed。
- API调用:通过RESTful API获取实时数据,确保数据的时效性。
2.2 数据清洗
去除噪声数据(如特殊字符、HTML标签等),并将数据转换为统一格式。
知识点解释:
- 数据清洗:移除无关信息,确保数据质量。
- 正则表达式:用于模式匹配和字符串替换,是一种强大的文本处理工具。
2.3 数据分割
将数据划分为训练集和测试集,以便评估模型性能。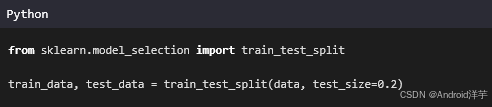
知识点解释:
- 数据分割:将数据分为训练集和测试集,防止过拟合。
- 比例分配:通常采用8:2的比例划分训练集和测试集。
2.4 数据向量化
将文本数据转化为机器学习模型可接受的数值形式。
知识点解释:
- 分词器(Tokenizer):将文本分割为单词或子词单元。
- 向量化:将文本转化为固定长度的数值向量,便于模型处理。
第三章:模型选择与微调
3.1 模型选择
根据任务需求选择合适的预训练模型。这里我们选择Hugging Face的BLOOM模型。
知识点解释:
- 预训练模型:基于大量数据训练的通用模型,可通过微调适应特定任务。
- BLOOM模型:支持多语言生成任务,适合跨语言应用场景。
3.2 微调模型
使用训练数据对模型进行微调,以提升其在特定任务上的表现。
知识点解释:
- TrainingArguments:配置训练参数,如批次大小、训练轮数等。
- Trainer API:简化模型训练过程,提供内置功能如评估和日志记录。
第四章:提示工程——提升生成质量
设计有效的提示模板,引导模型生成更精准的回答。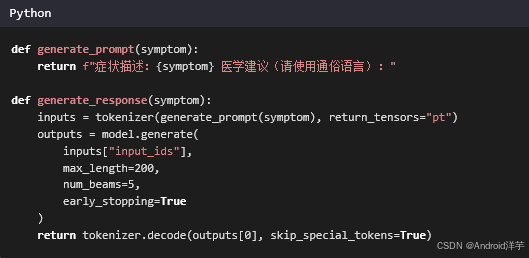
知识点解释:
- 提示模板:通过结构化输入引导模型生成符合预期的内容。
- Beam Search:一种解码策略,通过保留多个候选序列提高生成质量。
第五章:部署与监控
5.1 API部署
使用FastAPI创建RESTful API服务。
知识点解释:
- FastAPI:高性能的Python Web框架,适合构建API服务。
- Pydantic:用于数据验证和解析,确保输入数据的合法性。
5.2 内容过滤与监控
集成内容过滤机制,确保生成内容的安全性和适宜性。
知识点解释:
- 内容分类器:识别有害或不适当的内容,保障用户安全。
- 微软Content Filter:开源的文本分类模型,适用于内容审核。
第六章:伦理保障与合规性
确保生成式AI应用遵循最新的伦理指导原则,保护用户隐私,并提供透明的反馈机制是至关重要的。这不仅有助于建立用户信任,也是遵守法律和行业标准的要求。以下是具体措施:
1. 用户隐私保护
- 数据最小化:只收集对实现业务目标必要的最少信息量。
- 匿名化处理:在不影响功能的前提下,尽可能地将个人信息匿名化处理。
- 加密存储和传输:采用先进的加密技术来保护用户数据,无论是在存储还是传输过程中。
- 访问控制:严格限制对用户数据的访问权限,确保只有授权人员才能查看或使用这些数据。
2. 提供透明的反馈机制
- 明确告知:向用户清晰说明你的AI系统如何工作、它能做什么以及不能做什么,让用户了解他们与系统的交互方式。
- 用户同意:在收集任何个人数据之前,必须获得用户的明确同意,并给予用户选择是否参与的权利。
- 反馈渠道:提供易于使用的反馈机制,允许用户报告问题或提出疑问。及时响应并解决用户的问题,增强用户体验。
- 结果解释:对于关键决策(如信用评分、招聘筛选等),提供足够的透明度,让用户能够理解为什么做出这样的决定,并有机会申诉。
3. 遵循伦理指导原则
- 公平性:确保算法不会因为种族、性别、年龄等因素而产生偏见。定期评估模型的公平性,调整以消除潜在的歧视。
- 责任追究:制定明确的责任分配方案,一旦发生问题,可以迅速确定负责方,并采取适当的纠正措施。
- 持续监控与更新:随着社会价值观和技术的发展,持续更新AI系统以符合新的伦理标准。同时,对系统的表现进行监控,确保其行为始终符合预期和社会期望。
通过实施上述措施,不仅可以提升用户对AI系统的信任度,还能有效避免潜在的法律风险和社会争议。在设计和开发阶段就考虑到这些问题,可以帮助确保最终产品既安全又可靠,同时也为用户提供了一个更加公正透明的服务环境
第七章:总结与展望
经过全面的学习和实践,你现在应该已经掌握了从零开始构建生成式AI应用的核心技能。从明确业务需求到伦理部署的每一个步骤,我们都详细探讨了如何有效地设计、开发和部署一个高效、安全且负责任的生成式AI系统。接下来,让我们回顾一下整个过程,并展望未来可能的发展方向。
一、回顾学习旅程
-
明确业务需求
- 了解并定义了你的项目目标和应用场景。
- 设定了具体的性能指标,为后续开发提供了清晰的方向。
-
数据准备
- 学习了如何收集、清洗、分割以及向量化数据。
- 理解了高质量数据对于模型训练的重要性。
-
模型选择与微调
- 根据任务需求选择了合适的预训练模型,并对其进行了微调以适应特定场景。
- 掌握了如何设置训练参数来优化模型性能。
-
提示工程
- 学会了设计有效的提示模板,以提高生成内容的相关性和准确性。
- 理解了不同的解码策略(如Beam Search)对生成质量的影响。
-
部署与监控
- 使用FastAPI等工具快速部署了生成式AI服务。
- 集成了内容过滤机制,确保输出的安全性和适宜性。
-
伦理保障与合规性
- 强调了用户隐私保护的重要性,并介绍了如何提供透明的反馈机制。
- 探讨了如何遵循最新的伦理指导原则,确保系统的公平性和责任追究。
二、未来发展方向
-
持续学习与技术跟进
- 生成式AI是一个快速发展领域,新的技术和方法层出不穷。保持对最新研究和技术趋势的关注,将有助于你在未来的项目中保持竞争力。
- 参加相关的研讨会、阅读顶级会议论文(如NeurIPS、ICML),以及参与开源社区活动,都是很好的学习途径。
-
深化专业技能
- 在掌握了基本的开发流程后,可以进一步深入研究某一特定领域,比如自然语言处理中的对话系统、图像生成中的风格迁移等。
- 考虑专攻某个行业应用,如医疗保健、金融服务或教育技术,利用生成式AI解决具体行业的挑战。
-
关注伦理和社会影响
- 随着AI技术的普及,其带来的伦理和社会问题也日益受到关注。作为开发者,我们需要更加重视这些问题,积极参与讨论并寻找解决方案。
- 支持或发起关于AI伦理的研究项目,推动制定更严格的行业标准和法规。
-
跨学科合作
- 生成式AI的应用往往涉及多个学科的知识,包括计算机科学、心理学、社会学等。通过与其他领域的专家合作,可以创造出更具创新性和实用价值的产品。
- 考虑与其他专业人士共同开展项目,例如设计师、市场营销专家等,拓宽你的视野和资源网络。
结语:
本指南旨在为你提供一份详尽的路线图,帮助你从零开始构建一个成功的生成式AI应用。但请记住,这只是一个起点。随着技术的进步和个人经验的积累,你会发现更多的可能性。希望你能运用所学到的知识,在未来的项目中不断创新,为社会带来积极的变化。同时,始终保持对新技术的好奇心和探索精神,让自己的职业生涯不断前进。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











