







简介
深度学习技术正在重塑各个行业的智能化进程,而神经网络作为其核心基础,已经发展成为解决复杂问题的关键工具。本文将从神经网络的基本概念出发,系统讲解其数学原理、框架实现及企业级应用开发技术,提供完整的代码示例和实战经验。通过本文的学习,即使是零基础的开发者,也能掌握神经网络从理论到实践的全链路开发方法,实现真正的"从零到一"。
神经网络本质上是一组相互连接的计算单元,通过模拟生物神经元的工作方式,从输入数据中提取特征并生成预测结果。 它的核心优势在于能够自动学习数据中的复杂模式,无需人工设计特征。随着深度学习技术的不断进步,神经网络在图像识别、自然语言处理、推荐系统等领域展现出惊人的能力,成为现代AI应用的基石。
一、神经元结构与数学模型
神经网络由大量神经元构成,每个神经元接收输入信号并经过处理产生输出信号。人工神经元的数学模型是前馈神经网络的基础,它通过加权求和和激活函数模拟生物神经元的工作机制。
人工神经元的数学模型可以表示为:输出 = f(Σ(权重 × 输入) + 偏置),其中f是激活函数,Σ表示对所有输入与权重的乘积进行求和,偏置是模型的一个可学习参数。这个公式是神经网络计算的核心,每个神经元都执行这样的计算。
在Python中,可以使用PyTorch轻松实现一个神经元。以下是一个简单的单层神经网络示例:
import torch
import torch.nn as nn
class SimpleNeuralNet(nn.Module):
def __init__(self, input_dim, output_dim):
super(SimpleNeuralNet, self).__init__()
self.fc = nn.Linear(input_dim, output_dim) # 全连接层
def forward(self, x):
return self.fc(x) # 前向传播神经网络的结构分为输入层、隐藏层和输出层。输入层接收原始数据,隐藏层负责特征提取,输出层产生最终预测。在实际应用中,隐藏层的数量和神经元数量可以灵活调整,以适应不同复杂度的任务。
下表展示了不同神经元类型及其特点:
| 神经元类型 | 数学公式 | 优点 | 缺点 |
|---|---|---|---|
| 人工神经元 | f(Σ(w_i x_i) + b) | 计算简单高效,易于实现 | 无法精确模拟生物神经元的复杂特性 |
| 生物神经元 | 复杂的生物电化学过程 | 具有复杂的动态特性,能处理多种信号模式 | 难以用简单数学模型准确描述 |
二、激活函数:神经网络的非线性核心
激活函数是神经网络的关键组件,它引入非线性特性,使网络能够学习复杂的函数映射。激活函数的选择直接影响模型的性能和训练效率。
**ReLU(Rectified Linear Unit)**是当前最常用的激活函数,其公式为:f(x) = max(0, x)。ReLU函数计算简单,梯度稳定,能有效缓解梯度消失问题,适合深层网络。但ReLU存在"死神经元"问题,即当输入小于0时,神经元将停止学习。
Sigmoid函数将输出限制在(0,1)区间,适合二分类问题。但Sigmoid函数容易导致梯度消失,不适合深层网络。其数学公式为:σ(x) = 1/(1 + e^(-x))。
Tanh函数将输出限制在(-1,1)区间,对称的输出特性使其在某些任务中表现优于Sigmoid。但Tanh同样面临梯度消失问题,深层网络中使用受限。
Swish函数(x·σ(x))是一种平滑的激活函数,具有自门控特性,能根据输入动态调整激活程度。Swish在某些情况下比ReLU表现更好,特别是在深层网络中。
GELU函数结合了ReLU和Tanh的优点,能更好地捕捉输入数据的非线性特征,提高模型的泛化能力。GELU在Transformer等高级架构中应用广泛。
下图展示了不同激活函数及其导数的对比:
三、前馈神经网络原理
前馈神经网络(Feedforward Neural Network, FNN)是最基本的神经网络类型,其信息从输入层单向传播到隐藏层,再到输出层,没有反馈连接。这种结构使得前馈神经网络在处理静态数据(如图像、文本)时表现出色。
前馈神经网络的训练过程包括四个核心步骤:参数初始化、前向传播、计算误差和反向传播。参数初始化通常采用随机值或特定方法(如He初始化);前向传播将输入数据通过网络传递,计算预测值;计算误差是将预测结果与真实标签进行比较,常用损失函数如交叉熵(分类任务)或均方误差(回归任务);反向传播利用链式法则计算损失函数对各个参数的梯度,然后通过优化算法(如Adam、SGD)更新参数。
梯度下降是神经网络训练的基础优化方法,其原理是通过计算损失函数对参数的梯度,然后沿着梯度下降的方向调整参数,以最小化损失函数。在实际应用中,常用随机梯度下降(SGD)或其变体(如Adam、RMSProp)来加速训练过程。
学习率是优化过程中最关键的一个超参数,控制参数更新的幅度。学习率过大可能导致训练不稳定,过小则收敛缓慢。在2025年最新实践中,动态调整学习率(如余弦衰减、学习率预热)已成为标准做法。
下图展示了前馈神经网络的训练流程:
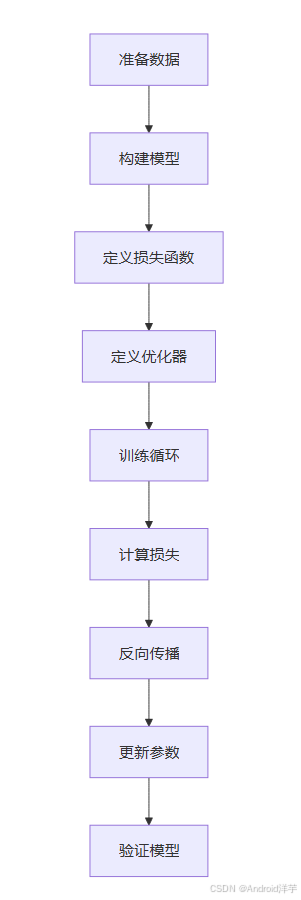
四、PyTorch与TensorFlow框架实战
在实际开
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











