






一、数据仓库和数据库
1)、操作型处理(数据库):叫联机事务处理OLTP(On-Line Transaction Processing),也可以称面向用户交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常进行增删改查操作。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
2)、分析型处理(数据仓库),叫联机分析处理OLAP(On-Line Analytical Processing),也可以称为面向专业分析人员进行数据分析,通常进行查询分析操作,一般针对某些主题的历史数据进行分析,支持管理决策。
3)、数据仓库主要特征:面向主题的(Subject-Oriented)、集成的(Integrated)、非易失的(Non-Volatile)和时变的(Time-Variant)
4)、数仓和数据库的区别:
数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的。主要区别如下:
数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库一般存储业务数据,数据仓库存储的一般是历史数据。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
5)、Hadoop不是数据仓库。原因:
- 数据结构不同:数据仓库一般采用以关系型数据库为基础的结构,而Hadoop则采用分布式文件系统(HDFS)存储数据。
- 数据存储方式不同:数据仓库一般采用增量加载方式存储数据,而Hadoop则采用全量存储方式。
- 数据处理方式不同:数据仓库使用SQL等关系型数据库的方式进行数据处理分析,而Hadoop则采用MapReduce等分布式计算方式。
- 数据存储能力不同:Hadoop可以存储更为大规模的海量数据,而数据仓库的存储能力与数据库本身相关。
- 运行环境不同:数据仓库一般运行于高端服务器上,而Hadoop可以运行在廉价的硬件设备上进行大规模的数据分析。
- 数据访问方式不同:数据仓库一般采用OLAP(联机分析处理)方式,Hadoop则采用OLTP(联机事务处理)方式。
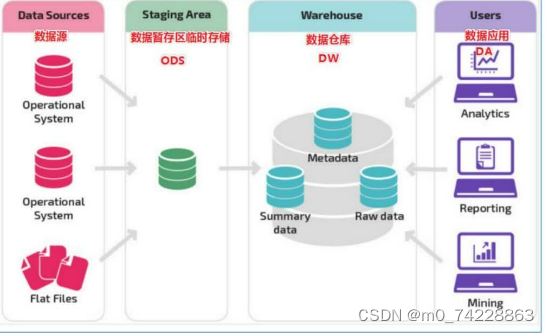
6)、数据仓库架构可分为三层——源数据层(ODS)、数据仓库层(DW)、数据应用层(DA或APP):
二、数据库
1.创建库的语法为CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION position];
2.删除库的语法为DROP DATABASE db_name [CASCADE];
三、数据表

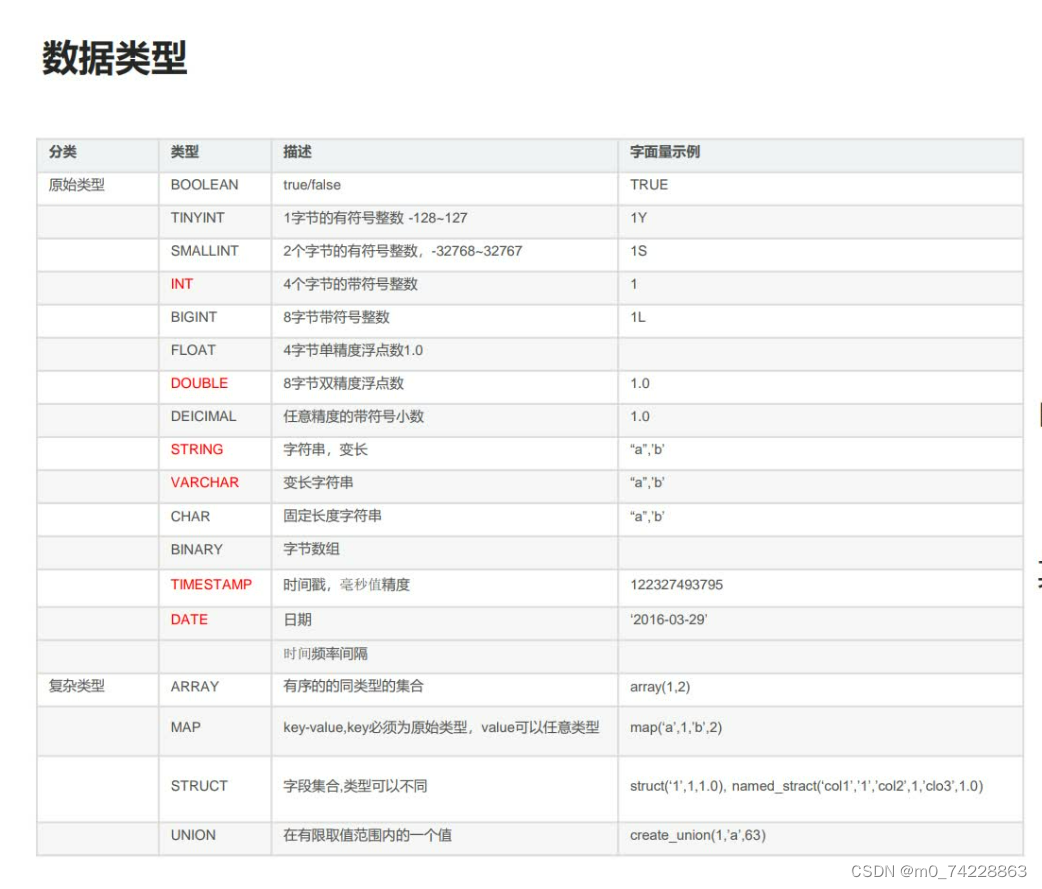
上表中红色的是使用比较多的类型!
1)、表分类:Hive中可以创建的表有好几种类型,分别是:
•内部表(MANAGED_TABLE)(CREATE TABLE table_name ...)未被external关键字修饰的即是内部表,内部表又称管理表或者托管表。删除内部表:直接删除元数据和存储的业务数据
分区表
分桶表
•外部表(EXTERNAL_TABLE)(CREATE EXTERNAL TABLE table_name ...)被external关键字修饰的即是外部表,外部表又称非管理表或者非托管表。删除外部表:仅仅是删除元数据,存储的业务数据并不会被删除
分区表
分桶表
•查看表类型和详情:
DESC FORMATTED表名;
•查看建表语句的语法:show create table表名;
•内部表转外部表alter table stu set tblproperties('EXTERNAL'='TRUE');
•外部表转内部表alter table stu set tblproperties('EXTERNAL'='FALSE');
•Hive映射表的流程步骤是什么? 创建表 加载数据 验证数据
•加载数据的语法
。LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE表名;
。INSERT INTO|OVERWRITE TABLE表名SELECT...
注意:使用LOAD语句:•数据来源本地,本地数据文件会保留,本质是本地文件上传•HDFS据来自HDFS,加载后文件不存在,本质是在HDFS上进行文件移动
➢导出数据的语法
•INSERT OVERWRITE [local] directory‘path’[format delimited]SELECT...;
•hive -f/-e执行语句或者脚本>文件名
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









