







前言
最近在复习java的数据结构,到队列的时候深入了解了一下延迟队列。菜逼随便写点,大佬轻点喷。
延迟队列简介
延迟队列(DelayQueue)是Java并发包中提供的一种特殊的队列实现,它存储实现了Delayed接口的元素,并且这些元素会按照延迟时间进行排序,这些元素的延迟时间到达后,才能从延迟队列中取出并处理
延迟队列说明
DelayQueue 是一个 BlockingQueue(无界阻塞)队列,它封装了一个使用完全二叉堆排序元素的 PriorityQueue(优先队列)。在添加元素时使用 Delay(延迟时 间)作为排序条件,延迟最小的元素会优先放到队首。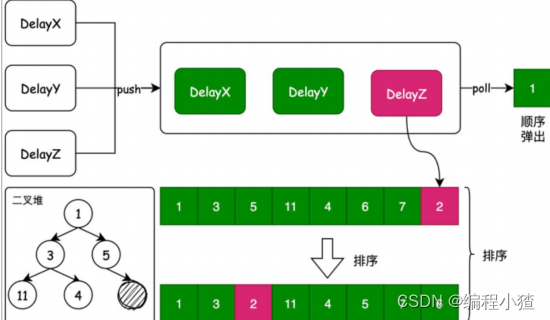 1.延迟队列的核心就是按照元素的延迟时间进行排序存放,这样才能让在延迟弹出元素的时候,按照所存放元素的排序进行输出。2.延迟队列内部封装了一个 PriorityQueue 优先队列,在PriorityQueue 优先队列中定义了这种排序方法,它的数据结构是数组实现的队列,但体现形式是一棵二叉堆树结构。在元素存放时,通过对存放元素的比较和替换形成二叉堆结构。下面介绍一下二叉堆结构
1.延迟队列的核心就是按照元素的延迟时间进行排序存放,这样才能让在延迟弹出元素的时候,按照所存放元素的排序进行输出。2.延迟队列内部封装了一个 PriorityQueue 优先队列,在PriorityQueue 优先队列中定义了这种排序方法,它的数据结构是数组实现的队列,但体现形式是一棵二叉堆树结构。在元素存放时,通过对存放元素的比较和替换形成二叉堆结构。下面介绍一下二叉堆结构
二叉堆结构
二叉堆是一种特殊结构的堆,它的表现形态可以是一棵完整或近似二叉树的结构。如接下来要实现的延迟队列中的元素存放,使用的就是 PriorityQueue 实现的平衡二叉堆结构,数据以队列形式存放在基础数组中。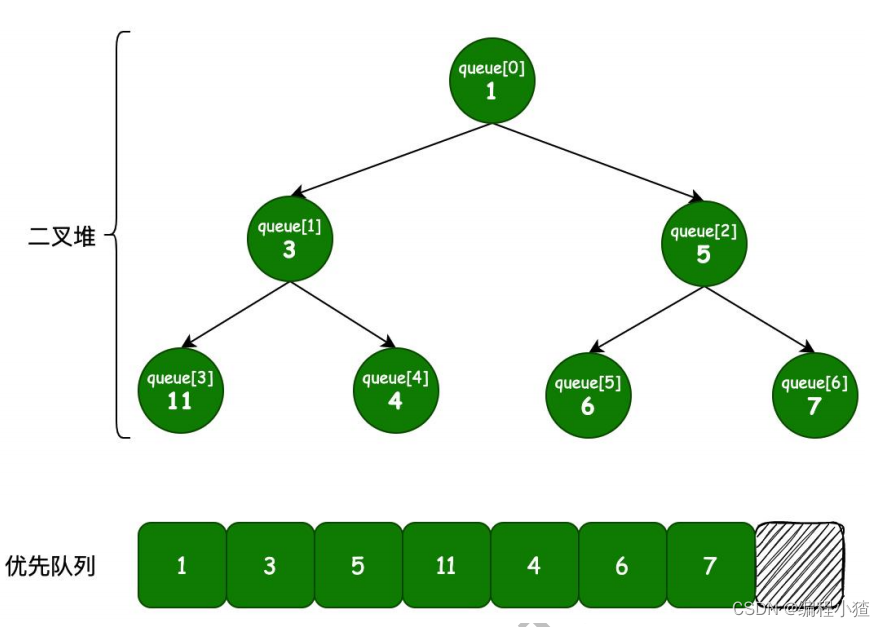 排序规则
排序规则1.父子节点索引关系:
a.假如父节点为 queue[n],那么左子节点为 queue[2n+1],右子节点为 queue[2n+2]
b.任意孩子节点的父节点位置,都是 n-1>>>1 相当于除 2 取整。>>>是位运算表达式,n-1>>>1的意思是将n-1转化为二进制数,将二进制数的所有位向右移动指定的位数(1),并用零来填充最高位。
2.节点间大小关系 :a.父节点小于等于任意孩子节点
b.同一层级的两个孩子节点大小不需要维护,它是在弹出元素的时候进行判断的3.子叶节点与非子叶节点 :一个长度为 size 的优先队列,当 index >= size >>> 1 时,该节点为
叶子节点。否则,为非叶子节点。
延迟队列应用
首先说一下延迟队列的特点
元素排序:延迟队列根据元素的延迟时间进行排序,延迟时间最短的元素排在队列的首部。
阻塞获取:当尝试取出元素时,如果当前没有到达延迟时间的元素,线程将会被阻塞,直到有元素可以取出。
基于这些特点,可以有以下应用场景,欢迎补充
定时任务调度:延迟队列常用于任务调度场景,可以将任务封装成延迟元素,根据延迟时间进行调度执行。
缓存过期管理:可以使用延迟队列来管理缓存中的元素,设置缓存过期时间作为延迟时间,当过期时间到达时,自动从缓存中移除。
定时提醒功能:可以使用延迟队列实现定时提醒功能,将提醒事件封装成延迟元素,根据提醒时间进行提醒。
延迟队列实现
实现介绍
实现延迟队列有两大核心:
1. 优先队列中的入队元素根据延迟时间进行自动排序
2.添加可重入锁ReentrantLock对阻塞队列的实现,加锁主要是确保线程安全、原子性以及元素顺序正确。
话不多说直接上源码,千言万语尽在其中
package DelayQueue.test;
import org.junit.jupiter.api.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import DelayQueue.DelayQueue;
import DelayQueue.Delayed;
import DelayQueue.Queue;
import java.util.concurrent.TimeUnit;
public class QueueTest {
private final Logger logger = LoggerFactory.getLogger(QueueTest.class);
@Test
public void test_queue() throws InterruptedException {
Queue<Job> queue = new DelayQueue<Job>();
queue.add(new Job("1号", 1000L));
queue.add(new Job("3号", 3000L));
queue.add(new Job("5号", 5000L));
queue.add(new Job("11号", 11000L));
queue.add(new Job("4号", 4000L));
queue.add(new Job("6号", 6000L));
queue.add(new Job("7号", 7000L));
queue.add(new Job("12号", 12000L));
queue.add(new Job("15号", 15000L));
queue.add(new Job("10号", 10000L));
queue.add(new Job("9号", 9000L));
queue.add(new Job("8号", 8000L));
while (true) {
Job poll = queue.poll();
if (null == poll) {
Thread.sleep(10);
continue;
}
logger.info(poll.getName());
}
}
static class Job implements Delayed {
private final String name;
private final Long begin;
private final Long delayTime;
public Job(String name, Long delayTime) {
this.name = name;
this.begin = System.currentTimeMillis();
this.delayTime = delayTime;//延时时长
}
@Override
public long getDelay(TimeUnit unit) {
//TimeUnit时间单位
return unit.convert(begin + delayTime - System.currentTimeMillis(),
TimeUnit.MICROSECONDS);
}
public String getName() {
return name;
}
@Override
public int compareTo(Delayed o) {
Job job = (Job) o;
return (int) (this.getDelay(TimeUnit.MICROSECONDS) - job.getDelay(TimeUnit.MICROSECONDS));
}
}
}
package DelayQueue;
public interface BlockingQueue<E> extends Queue<E>{
boolean add(E e);
boolean offer(E e);
}
package DelayQueue;
import java.util.concurrent.TimeUnit;
public interface Delayed extends Comparable<Delayed>{
long getDelay(TimeUnit unit);
}
package DelayQueue;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
import static java.util.concurrent.TimeUnit.NANOSECONDS;
//延迟队列说明
//DelayQueue 是一个 BlockingQueue(无界阻塞)队列,它封装了一个使用完全二
//叉堆排序元素的 PriorityQueue(优先队列)。在添加元素时使用 Delay(延迟时间)作为排序条件,延迟最小的元素会优先放到队首。
/*1.延迟队列的第一个核心点在于对所加入的元素按照一定的规则进行排序存放,这样才能让在延迟弹出元素的时候,按照所存放元素的排序
进行输出
2.那么这个延迟队列中用到的排序方式就是 PriorityQueue 优先队列,它的数据结构是
数组实现的队列,但体现形式是一棵二叉堆树结构。在元素存放时,通过对存放元
素的比较和替换形成二叉堆结构。
*/
//延迟队列实现介绍
/*
延迟队列的实现,主要为在优先队列的基础上,添加可重入锁 ReentrantLock 对阻塞队列的实现。当数据存放时,
按照二叉堆结构排序元素,出队时依照排序结构进行迁移
*/
//二叉堆结构说明
/*
二叉堆是一种特殊结构的堆,它的表现形态可以是一棵完整或近似二叉树的结构
例如本包中定义的PriorityQueue 就实现了平衡二叉堆结构,数据以队列形式存放在基础数组中
1.父子节点索引关系
a.假如父节点为 queue[n],那么左子节点为 queue[2n+1],右子节点为 queue[2n+2]
b.任意孩子节点的父节点位置,都是 n-1>>>1 相当于除 2 取整。>>>是位运算表达式,n-1>>>1的意思是将n-1转化为二进制数,
将二进制数的所有位向右移动指定的位数(1),并用零来填充最高位。
2.节点间大小关系
a.父节点小于等于任意孩子节点
b.同一层级的两个孩子节点大小不需要维护,它是在弹出元素的时候进行判断的
3.叶子节点与非叶子节点的关系
一个长度为 size 的优先级队列,当 index >= size >>> 1 时,该节点为
叶子节点。否则,为非叶子节点。
*/
public class DelayQueue<E extends Delayed> implements BlockingQueue<E> {
//内部加锁
/**
* 1.实现线程安全:延迟队列是在多线程环境下使用的,因此需要保证对队列的操作是线程安全的。通过加锁,可以确保同一
* 时间只有一个线程能够对队列进行修改或访问,从而避免多线程并发操作引发的数据不一致性或其他异常情况。
*
* 2.确保元素顺序:延迟队列通常是基于优先级队列(PriorityQueue)实现的,而PriorityQueue本身是线程不安全的。由于延迟队列
* 的特殊性,队列中的元素可能会在不同的时间点被消费,但消费的顺序要按照元素的延迟时间来确定。通过加锁,可以保证在入队和
* 出队操作时,维护队列的顺序,防止元素被错误地消费或出现乱序。
*
* 3.同步操作:在延迟队列中,可能存在一些需要同步的操作,例如元素的添加、删除、修改等。加锁可以使得这些操作变为原子操作
* ,确保它们的执行是完整的、互斥的,避免多线程之间的竞态条件和数据冲突。
*/
private final transient ReentrantLock lock = new ReentrantLock();
//内部封装优先队列
private final PriorityQueue<E> q = new PriorityQueue<E>();
//控制线程的等待和唤醒,该 Condition 实例上面定义的lock对象相关联,
// 以确保线程在等待或唤醒时能够正确地获取和释放锁。
private final Condition available = lock.newCondition();
@Override
public boolean add(E e) {
return offer(e);
}
@Override
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e);
//实现阻塞延迟功能,如果新添加的元素e在队列中是第一个元素,
// 则它成为了队列的头部元素,也就是最早的元素,因为队列是按照元素的延迟时间排序的。
// 此时需要唤醒一个正在等待的线程,让它去处理这个头部元素。
if (q.peek() == e) {
available.signal();
}
return true;
} finally {
lock.unlock();
}
}
@Override
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E first = q.peek();
if (first == null || first.getDelay(NANOSECONDS) > 0) {
return null;
} else {
return q.poll();
}
} finally {
lock.unlock();
}
}
@Override
public E peek() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return q.peek();
} finally {
lock.unlock();
}
}
}
package DelayQueue;
public interface Deque<E> extends Queue<E>{
void addFirst(E e);
void addLast(E e);
}
package DelayQueue;
import com.alibaba.fastjson.JSON;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
/**
* 优先队列
* @param <E>
*/
public class PriorityQueue<E> implements Queue<E> {
//日志打印
private Logger logger = LoggerFactory.getLogger(PriorityQueue.class);
//默认初始化长度
private static final int DEFAULT_INITIAL_CAPACITY = 11;
//底层为数组
transient Object[] queue;
//队列长度
private int size = 0;
public PriorityQueue() {
queue = new Object[DEFAULT_INITIAL_CAPACITY];
}
//入队
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
//i记录入队元素在数组中的索引
int i = size;
if (i >= queue.length) {
grow(i + 1);
}
size = i + 1;
if (i == 0) {
queue[0] = e;
} else {
//入队,进行优先排序
siftUp(i, e);
}
return true;
}
//队列扩容
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// 扩容机制
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
if (newCapacity - (Integer.MAX_VALUE - 8) > 0)
newCapacity = (minCapacity > Integer.MAX_VALUE - 8) ?
Integer.MAX_VALUE :
Integer.MAX_VALUE - 8;
//数组复制
queue = Arrays.copyOf(queue, newCapacity);
}
private void siftUp(int k, E x) {
siftUpComparable(k, x);
}
//元素入队进行优先排序,此处为实现优先队列的核心
@SuppressWarnings("unchecked")//抑制编译器产生的未检查类型转换警告
//此处是一个典型的应用场景:在使用泛型时,由于类型擦除机制,编译器无法在运行时检查泛型类型的正确性,
// 而产生未检查类型转换的警告。此时可以使用@SuppressWarnings("unchecked")注解来抑制这个警告。
private void siftUpComparable(int k, E x) {
//泛型类型转换,E类型或E的父类都可作为参数
Comparable<? super E> key = (Comparable<? super E>) x;
logger.info("【入队】元素:{} 当前队列:{}", JSON.toJSONString(key), JSON.toJSONString(queue));
while (k > 0) {
// 获取父节点Idx,相当于除以2
int parent = (k - 1) >>> 1;
logger.info("【入队】寻找当前节点的父节点位置。k:{} parent:{}", k, parent);
Object e = queue[parent];
// 如果当前位置元素,大于父节点元素,则退出循环
if (key.compareTo((E) e) >= 0) {
logger.info("【入队】值比对,父节点:{} 目标节点:{}", JSON.toJSONString(e), JSON.toJSONString(key));
break;
}
// 相反父节点位置大于当前位置元素,则进行替换
logger.info("【入队】替换过程,父子节点位置替换,继续循环。父节点值:{} 存放到位置:{}", JSON.toJSONString(e), k);
queue[k] = e;
k = parent;
}
queue[k] = key;
logger.info("【入队】完成 Idx:{} Val:{} \r\n当前队列:{} \r\n", k, JSON.toJSONString(key), JSON.toJSONString(queue));
}
@Override
public boolean add(E e) {
return offer(e);
}
//出队
@SuppressWarnings("unchecked")
@Override
public E poll() {
if (size == 0)
return null;
int s = --size;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}
private void siftDown(int k, E x) {
siftDownComparable(k, x);
}
//元素出队
@SuppressWarnings("unchecked")
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
// 先找出中间件节点
int half = size >>> 1;
while (k < half) {
// 找到左子节点和右子节点,两个节点进行比较,找出最大的值
int child = (k << 1) + 1;
Object c = queue[child];
int right = child + 1;
// 左子节点与右子节点比较,取最小的节点
if (right < size && ((Comparable<? super E>) c).compareTo((E) queue[right]) > 0) {
logger.info("【出队】左右子节点比对,获取最小值。left:{} right:{}", JSON.toJSONString(c), JSON.toJSONString(queue[right]));
c = queue[child = right];
}
// 目标值与c比较,当目标值小于c值,退出循环。说明此时目标值所在位置适合,迁移完成。
if (key.compareTo((E) c) <= 0) {
break;
}
// 目标值小于c值,位置替换,继续比较
logger.info("【出队】替换过程,节点的值比对。上节点:{} 下节点:{} 位置替换", JSON.toJSONString(queue[k]), JSON.toJSONString(c));
queue[k] = c;
k = child;
}
// 把目标值放到对应位置
logger.info("【出队】替换结果,最终更换位置。Idx:{} Val:{}", k, JSON.toJSONString(key));
queue[k] = key;
}
@SuppressWarnings("unchecked")
@Override
public E peek() {
return (size == 0) ? null : (E) queue[0];
}
}
package DelayQueue;
public interface Queue<E> {
boolean add(E e);
boolean offer(E e);
E poll();
E peek();
}
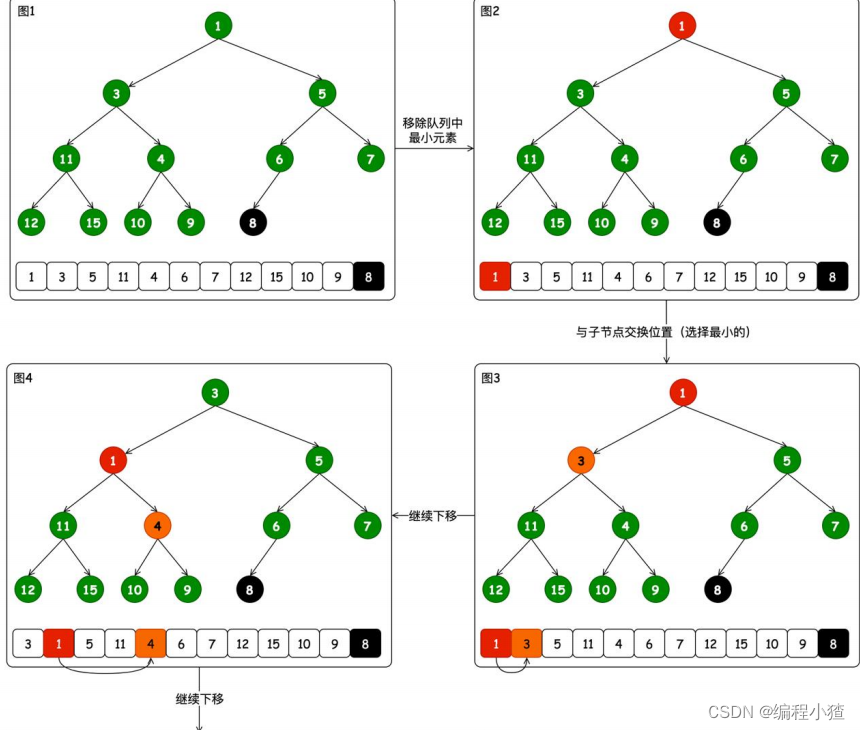
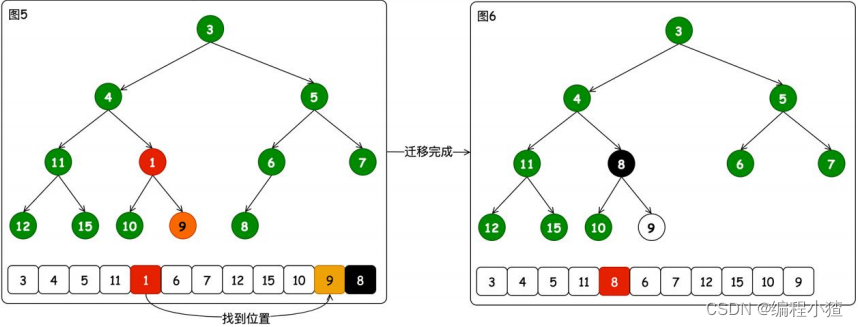
另外为方便大家理解入队出队元素的过程,附上过程图
入队

出队
出队很简单只需要将根元素直接出队删除即可。但是接下来的重排序还是比较复杂的,因为需要在根元素迁移走后,寻找另外的最小元素迁移到对头。这 个过程与入队正好相反,这是一个不断向下迁移的过程。


















 2172
2172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











