






2月15日
一.下载
1.操作步骤
一.登录www.mysql.com网站
二.在网页中单击downloads
三.在网页中单击“MySQL Community Server"
四.找到相应的版本单击”downloads"
2.实践
例如:尝试下载任意版本的mysql
二.安装
1.操作步骤
一.单击安装配件
二.完成相应配置
密码建议123456
三.单击finish完成安装
2.实践
例如:在我的操作系统下完成mysql的安装
课后任务:完成MySQL安装并完成职教云头脑风暴
2月20日
思政目标:精益求精
首先代码编辑要正确,拼写、大小写
其次标点符号,全部英文标点符
一、导入onlinedban'li案例库
1.操作步骤
第一步登录mysql
第二步创建"onlinedb"数据库
drop database onlinedb;#删除以前的onlinedb数据库
create database onlinedb;
第三步使用line数据库,即打开line
use onlinedb;即打开onlinedb
第四步将onlinedb数据库脚本文件开发,并完成复制
ctrl+a
ctrl+c
第五步在命令行中实现粘贴
ctrl+v
将光标放到工具的标题栏单击鼠标右键,选择编辑,粘贴
第六步测试数据导入情况
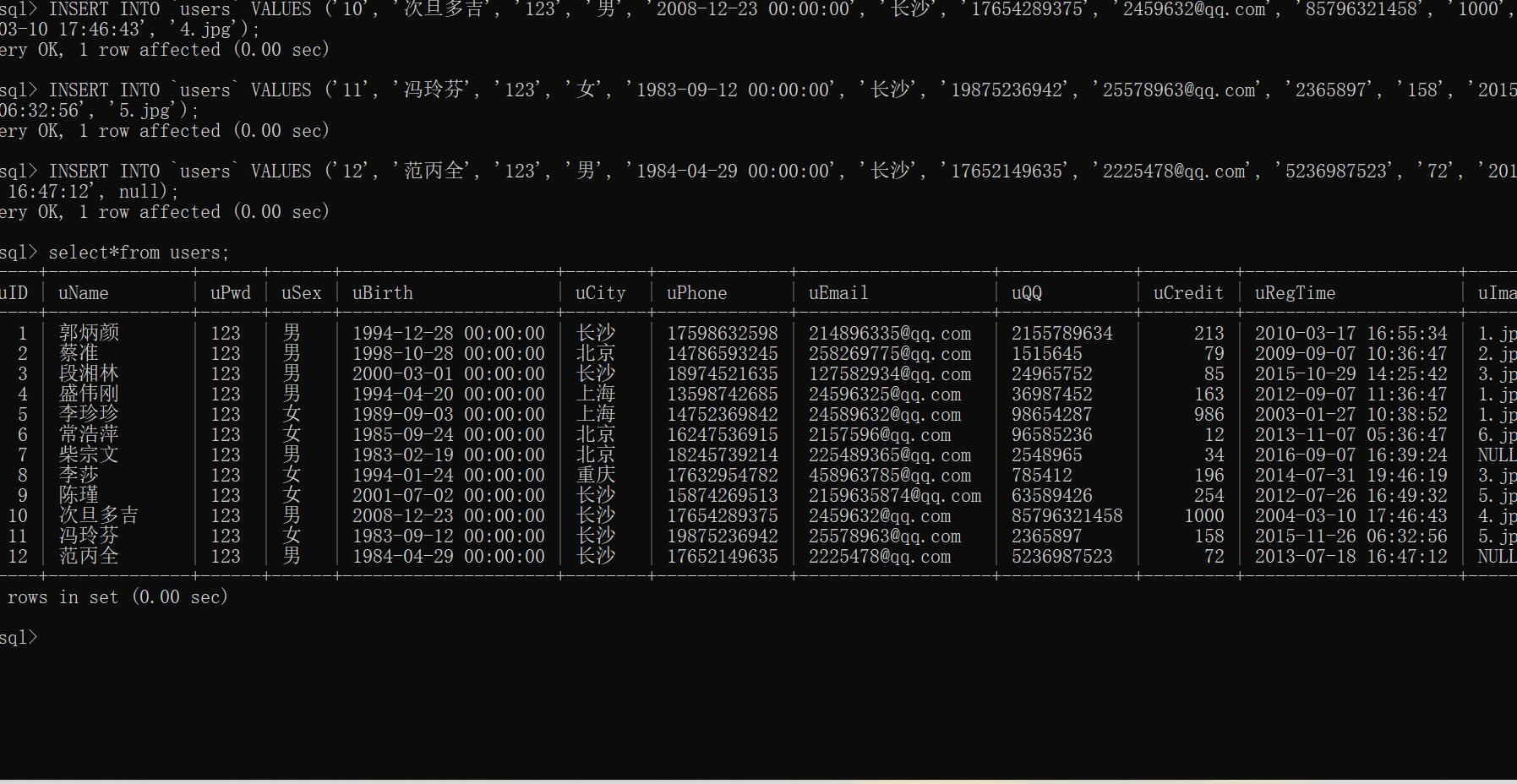
select * from users;
2.实践
例如:练习onlinedb的导入。
二、mysql文件夹认知(了解)p8
1.包含文件夹
bin
share
include
lib
data
my.ini
三、启动和停止mysql服务
1.方法分类:窗口操作法和命令行法
2.窗口操作法
任务场景:假设想登录mysql输入密码后闪退,这个问题一般情况下是服务没有启动的问题。最佳的解决方案启动服务即可。
(1)启动步骤
第一步打开控制面板
第二步找到服务对话框
第三步找到mysql服务,单击鼠标右键选择启动。
2月22日
一、使用net命令启动和停止mysql服务
1.格式
net start 服务名称
net stop 服务名称
2.实践
例如:尝试完成服务启动和停止
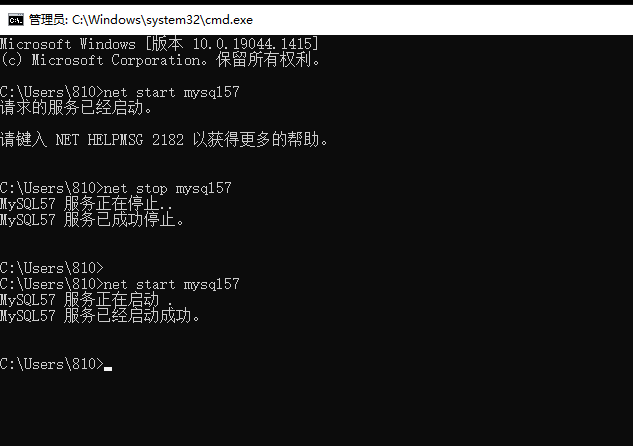
第一步打开命令行
在运行中输入cmd
第二步在命令行中输入
net start 服务名称MYSQL80
net stop 服务名称
注意:服务名称不是唯一,需要查看操作系统的信息
二、登录mysql服务器
1.格式
mysql -h hostname -u username -p
mysql为登录命令名,该文件存放在MySQL程序目录的bin文件夹下。
-h表示后面的参数hostname为服务器的主机地址,当客户端与服务器在同一台机器上时,hostname可以使用localhost或127.0.0.1。
-u表示后面的参数usemname为登录MySQL服务器的用户名。
-P表示后面的参数为指定用户的密码。
2.实践
例如:使用命令行登录mysql
第一步启动cmd
第二步切换路径到bin目录下
cd..
cd..
切换到c盘根目录
cd“c:\progrem files\mysql\mysql server5.7\bin"
第三步输入登录命令
mysql -h localhost -u root -p
单击回车
输入密码
三、mysql相关命令
1.命令参阅
p11 表1-1
2.实践
例如:
尝试使用mysql命令
2月27日
一、数据概念
二、数据库概念
三、数据库管理系统概念
四、数据系统概念
五、关系型数据库概念
六、SQL语句分类
1.DDL
create alter drop等包含数据库定义语句
2.DML
insert、update、delete等数据库的数据操作语句
3.DCL
实现对象的访问权限以及数据库操作事务的控制
grant、revoke、commit、rollback等
七、MYSQL图形化操作界面工具
navicat和workbench
八、字符集设置
任务场景:当向表中插入中文数据、查询包括中文字符的数据时,可能会出现乱码现象。
1.字符集分类
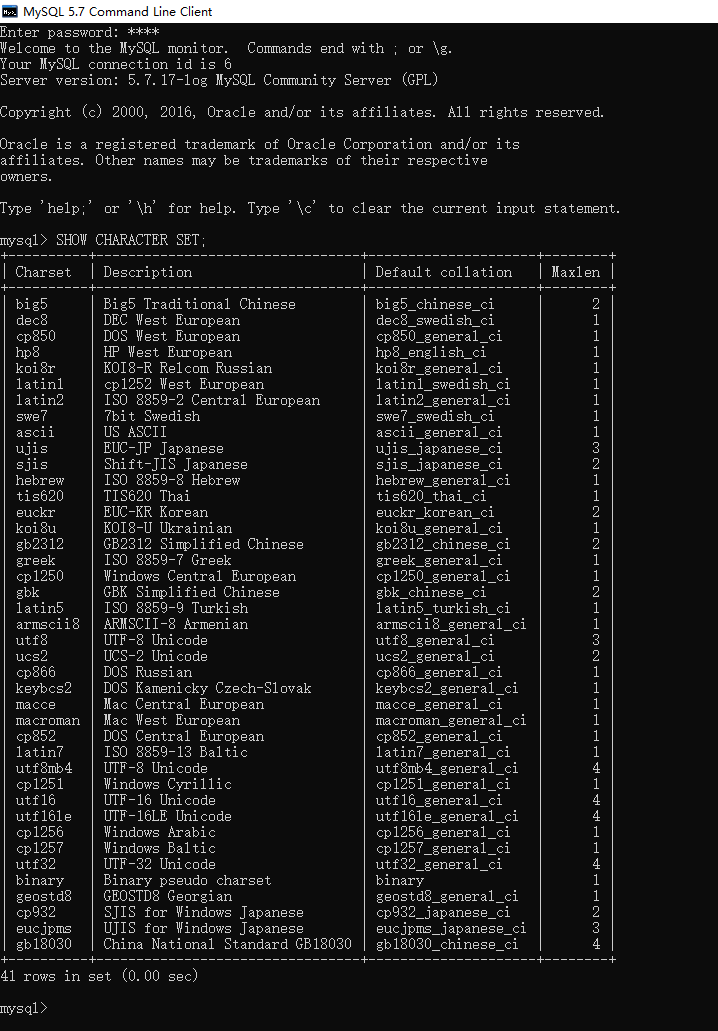
MYSQL一共有41种字符集,对于我们记住
utf8:通用转换格式。使用它不会出现乱码!!!
实践:尝试体验中文乱码报错。
#创建数据库trydb
create database trydb;
#切换数据库
use trydb;
#删除数据表user
DROP TABLE user;
#创建数据表user
CREATE TABLE user(name varchar(11) DEFAULT NULL)ENGINE=InnoDB DEFAULT CHARSET=latin1;
#在表中添加数据
insert into user values("carl");
insert into user values("哈哈");

课后任务
1.掌握数据基本概念
2.完成线上头脑风暴
3月1日
一、查看字符集和校对规则
1.查看字符集语法格式
SHOW CHARACTER SET;[like'匹配模式'|where条件表达式]
2.例如:查看数据库管理系统的字符集有哪些类型?
SHOW CHARACTER SET;
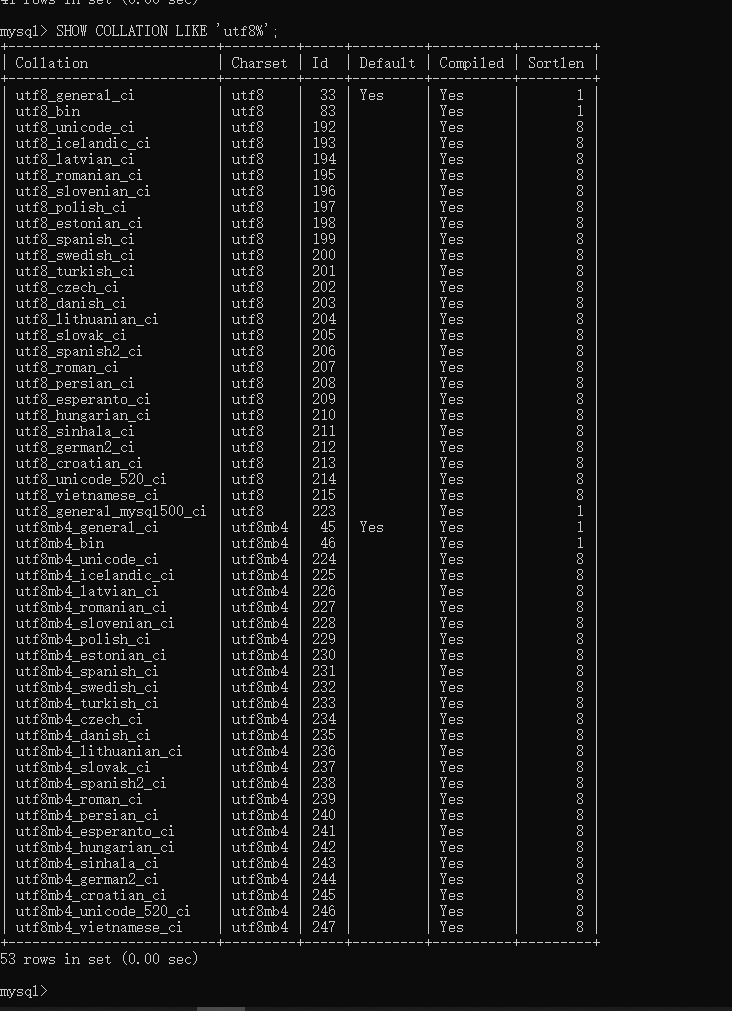
二、校对规则
1.查看字符集校对规则语法格式
SHOW COLLATION SET ‘匹配模式’
2.实践
例如:查看uft8相关字符集的匹配规则
SHOW COLLATION LIKE 'utf8%';
三、字符设置
1.MYSQL支持服务器(Server)、数据库(Database)、数据表(Table)、字段(Field)和连接层(Connection)五个层级的字符集设置
2、语法格式
set系统变量名=字符集名称
系统变量名:参阅p17 表1-2
3.实践
例如:使用MYSQL命令修改字符集。
MYSQL的SET命令可以修改变量的值,修改当前MYSQL服务器中各字符集的SQL命令如下:
#设置客户端字符集
mysql> SET character_set_client = utf8;
#设置连接层字符集
mysql> SET character_set_connection = utf8;
#设置数据库默认字符集
mysql> SET character_set_database = utf8;
#设置查询结果集
mysql> SET character_set_results = utf8;
#设置服务器字符集
mysql> SET character_set_server = utf8;

3月8日
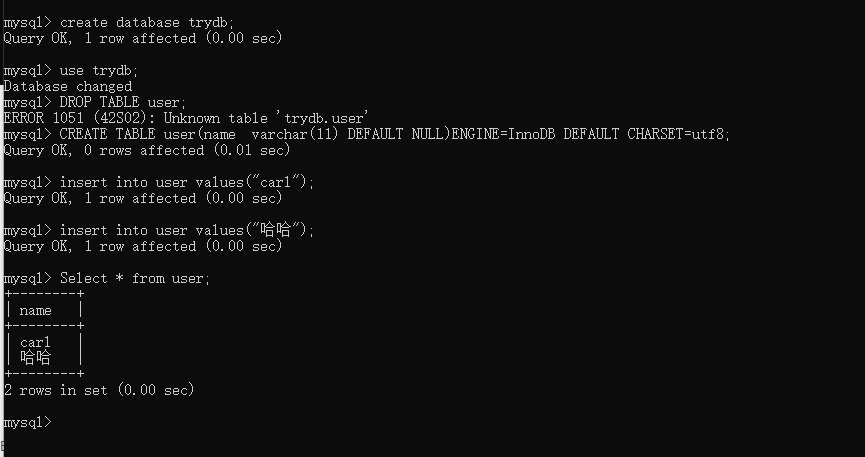
一、解决任务场景汉字不能正确插入的问题
1.实践
例如:回顾任务场景,完成user数据表的创建和记录的插入。
操作步骤如下:
创建一个数据库trydb
create database trydb;
use trydb;
#删除数据表user
DROP TABLE user;
#创建数据表user
CREATE TABLE user(name varchar(11) DEFAULT NULL)ENGINE=InnoDB DEFAULT CHARSET=utf8;
#在表中添加数据
insert into user values("carl");
insert into user values("哈哈");
#查询user数据表中的数据
Select * from user;
二、创建数据库
1.格式
CREATE DATABASE 数据库名
[DEFAULT] CHATACTER SET 编码方式
| [DEFAULT] COLLATE 排序规则
语法说明如下:
CREATE DATABASE:是SQL语言中用于创建数据库的命令;
数据库名:表示待创建的数据库名称,该名称在数据库服务器中是唯一的;
[DEFAULT] CHARACATER SET:指定数据库的字符集名称;
[DEFAULT] COLLATE collation_name:指定数据库的排序规则名称
2.实践
例如:使用SQL语句,创建名为onlinedb的数据库,默认字符集设置为gb2312,排序规则设置为gb2312_chinese_ci,显示结果如下。
drop database onlinedb;
CREATE DATABASE onlinedb CHARACTER SET gb2312 COLLATE gb2312_chinese_ci;

三、查看数据库
1.格式
SHOW DATABASES;
2.实践
例如:使用SHOW DATABASES语句,查看数据库服务器中存在的数据库。
SHOW DATABASES;

四、查看自己创建的数据库属性
1.格式
SHOW CREATE DATABASE 数据库名;
2.实践:
例如:使用SHOW语句,查看数据库onlinedb的信息。
SHOW CREATE DATABASE onlinedb;

3月13日
一、修改数据库
1.格式
ALTER DATABASE 数据库名;
[DEFAULT] CHATACTER SET 编码方式
| [DEFAULT] COLLATE 排序规则
语法说明如下:
ALTER DATABASE:是SQL语言中用于修改数据库的命令;
数据库名:表示待创建的数据库名称,该名称在数据库服务器中是唯一的
[DEFAULT] CHATACTER SET :指定数据库的字符集名称;
| [DEFAULT] COLLATE :指定数据库的排序规则名称
2.实践
例如:使用SQL语句,修改数据库onlinedb的字符集设置为uft8,排序规则为utf8_bin.
drop database onlinedb;
CREATE DATABASE onlinedb CHARACTER SET gb2312 COLLATE gb2312_chinese_ci;
SHOW CREATE DATABASE onlinedb;
ALTER DATABASE onlinedb CHARACTER SET utf8 COLLATE utf8_bin;
SHOW CREATE DATABASE onlinedb;

二、数据库删除
学习提示:删除数据库会删除该数据库中所有的表和所有的数据,且不能恢复,因此在执行删除数据库操作时要慎重。
1.格式
DROP DATABASE 数据库名;
2. 实践
例如:删除数据库服务器中名为onlinedb的数据库
show databases;
drop database onlinedb;
show databases;

三、存储引擎
1.定义
存储引擎就是数据的存储技术。针对不同的处理要求,对数据采用不同的存储机制、索引技巧、读写锁定水平等,在关系数据库数据的是以表的形式进行存储,因此存储引擎即为表的类型。
2.数据库的存储引擎功能:
决定了数据表在计算机中的存储方式,DBMS使用数据存储引擎进行创建、查询、修改数据。MySQ 数据库提供多种存储引擎,用户可选择合适的存储引擎,获得额外的速度或者功能,从而能改善应用的整体功能。MySQL的核心就是存储引擎。
3.分类
(1) InnoDB存储引擎
InnoDB是MySQL的默认事务型引擎,也是最重要、使用最广泛的存储引擎,被设计用来处理大量短期(short-lived) 事务。InnoDB的性能和自动崩溃恢复特性,使得它在非事务型存储的需求中也很流行,在MySQL- -般优先考虑InnoDB引擎。
(2) MyISAM存储引擎
MyISAM提供了大量的特性,包括全文索引、压缩、空间函数,广泛应用在Web和数据仓储应用环境下,但不支持事物和等级锁,崩溃后无法安全恢复等。由MyISAM引擎设计简单,数据以紧密格式存储,对只读的数据性能较好。
比如:检索论文的中国知网
(3) Memory存储引擎
Memory存储引擎将表中的数据存储到内存中,不需要进行磁盘I/O,且支持Hash索引,因此查询速度非常快,主要适用于目标数据较小,而且被非常频繁地访问的情况。
(4) C5v存储引擎
CSV存储弓|擎可将普通的CSV文件(逗号分割值的文件)作为MySQL的表来处理。CSV引擎可以在数据库运行时拷贝文件,可以将Exce|电子表格软件中的数据存储为CSV文件,并复制到MySQl的数据目录中,就可以在MySQL中打开。
3月15日
一、查看mysql支持的存储引擎
1.格式
SHOW ENGINES;
2.实践
例如:查看MySQL服务器系统支持的存储引擎。
SHOW ENGINES;

二、查询系统默认的存储引擎
1.格式
SHOW VARIABLES LIKE 'STORAGE_ENGINE';
2.实践
例如:查询系统默认的存储引擎。
SHOW VARIABLES LIKE 'DEFAULT_STORAGE_ENGINE';

三、整形
1.分类
TINYINT、SMALLINT、MEDIUMINT、INT(掌握)、BIGINT
2.实践
例如:创建整形数据的数据表test_int
drop database onlinedb;
create database onlinedb;
use onlinedb;
create table test_int
(int_1 int,
int_2 int unsigned,
int_3 int(6) zerofill,
int_4 tinyint,
int_5 tinyint unsigned);
查看数据表数据
select * from test_int;
向数据表中插入数据
insert into test_int values(100,100,100,100,100);
插入有问题的数据
insert into test_int values(100,-100,100,100,100);
查看数据表数据
select * from test_int;

四、小数
1.分类
浮点数和定点数
浮点数:数据值取近似值
定点数:数据值取精确值
FLOAT、DOUBLE、DECIMAL(M,D)或DEC(M,D)
2.格式
数据类型(M,D)
M:精度数据的总长度
D:数据点后面的位数
3.实践
例如:尝试创建test_dec数据表。
create table test_dec
(float_1 float(10,2),
float_2 double(10,2),
decimal_3 decimal(10,2));
查看数据表数据
select * from test_dec;
插入数据
insert into test_dec
values(12345678.99,12345678.99,12345678.99);
查看数据表数据
select * from test_dec;

3月20日
一、日期类型
1.分类
YEAR类型表示年份、DATE类型表示日期、TIME类型表示时间、DATETIME和TIMESTAMP表示日期时间
2.实践
例如:尝试使用日期类型数据
drop database onlinedb;
create database onlinedb;
use onlinedb;
create table test_date
(year_1 year,
date_2 date,
time_3 time,
datetime_4 datetime,
timestamp_5 timestamp);
应用函数完成数据的插入:、
insert into test_date
values(now(),current_date,current_time,current_timestamp,current_timestamp);
查询
select * from test_date;

二、字符型
1,。分类
字符串类型是在数据库中储存字符串的数据类型。
字符串类型包括CHAR、VARCHAR、BLOB、TEXT、ENUM、SET
2.实践
例如:尝试使用varchar数据类型。
create table test_char1
(varchar_1 varchar(65535));
create table test_char1
(varchar_1 varchar(21845));
create table test_char1
(varchar_1 varchar(21844));

例如:尝试定义test_char2数据表。
create table test_char2
(varchar_1 varchar(21844),
char_2 char(10));
create table test_char3
(char_2 char(10));
create table test_char2
(varchar_1 varchar(21834),
char_2 char(10));

3月22日
一、JSON数据
1.定义
一种轻量级数据交换格式。
2.分类
对象和数组
3.格式
对象:{键:值}
例如:{“性别”:“女”}
数组[值,值,值]
例如:[“星期一”,“星期二”]
4.实践
例如:创建test_json表,测试json类型的数据存储。
drop database onlinedb;
create database onlinedb;
use onlinedb;
create table test_json
(json_1 json,
json_2 json);
insert into test_json values
('{"u_num":"001","uname":"李鑫"}',
'["星期一",“星期二”]');
查询数据填充
select * from test_json;

二、查看数据表
表的定义:关系数据库中,表是以行与列的形式组织起来,数据存在于行与列香蕉的单元格中,一行数据表示一条唯一的记录,一行数据表示一个字段,唯一标识一行记录的属性称为主键。
格式
show tables;
实践
例如:查看onlinedb数据库数据表
show tables;

三、创建数据表
1.格式
CREATE TABLE表名(字段定义1,字段定义2,...字投定义n);
表名:表示所要创建的表的名称;
字段定义:定义表中的字段。包括字段名、数据类型、是否允许为空,指定默认值、主键约束、唯一性约束、 注释字段、
是否为外键以及字段类型的属性等。字段定义格式如下。
字段名类型[NOT NULL | NULL] [DEFAULT默认值][AUTO_ INCREMENT] [UNIQUE KEY | PRIMARY KEY][COMMENT '字符串'
][外键定义]
NULL (NOT NULL) :表示字段是否可以为空;
DEFUALT:指定字段的默认值;
AUTO_ INCREMENT: 设置字段为自增,只有整型类型的字段才能设置自增。自增默认从1开始,每个表只能有一一个自增字段;
UNIQUE KEY:唯一性约束;
PRIMARY KEY:主键约束;
COMMENT:注释字段;
外键定义:外键约束。
2.实践
例如:尝试完成users数据表创建,ulD、uName、uPwd、uSex,
create table users
(ulD int(11),
uName varchar(30),
uPwd varchar(50),
uSex char(8));
插入数据
insert into users values(100,'王鑫','123456','男');
insert into users values(100,'王鑫','123456','男');
查询语句
select *from users;

3月27日
任务场景:通过数据尝试应用我们发现不完整的数据表的创建会让很多非法数据存放到数据表中,这样会产生软件运行异常。那么为了数据创建的完整性、一致性我们需要在创建数据表的过程中加入约束规则。
一、避免数据的重复和空值
实践
例如:完成users数据表创建,uID、uName、uPwd、uSex,除此之外
uID列标题要求将来插入的数据非重复和非空数据,
uName列标题要求将来插入的数据非空,
uPwd列标题要求将来插入的数据非空,
uSex列标题要求将来插入的一个默认值“男”。
注意:
primary key约束,要求未来需要插入非重复和非空的数据。
not null约束,要求未来需要插入非空的数据。
default:要求未来需要自动插入数据或者修改数据。
drop database onlinedb;
create database onlinedb;
use onlinedb;
创建users数据表
create table users
(ulD int(11) primary key,
uName varchar(30) not null,
uPwd varchar(50) not null,
uSex char(8) default '男');
插入数据
insert into users values(100,'王鑫','123456','男');
insert into users values(100,'王鑫','123456','男');
通过这条记录添加的执行我们得到100这个数据值不可以重复插入两次,因为primary key主键约束的存在不可以插入重复值。
insert into users(uName,uPwd) values('德华','123456');
通过这条记录添加的执行我们得到空值不可以插入到ulD列标题下,因为primary key主键约束的存在不可以插入空值。
insert into users(uID,uPwd) values(200,'123456');
通过这条记录添加的执行我们得到空值不可以插入到uName列标题下,因为not null非空约束的存在不可以插入空值。
insert into users values(300,'琳琳','123456','女');
insert into users(uid,uname,upwd) values(400,'德华','123456');
通过这条记录添加执行我们可得到usex列表题下的数据值当我们不添加的时候它可以自动的完成数据默认值男这个数据的添加,因为usex列标题下我们定义了default
查看数据表中的数据
select *from users;

二、查看表结构
格式
desc table_name;
实践
例如:查看users数据表结构。
desc users;

三、使用show查看表结构
格式
show[full]columns from 表名;
实践
例如:查看users数据表结构
show full columns from users;

四、查看数据表创建语句
格式
show create table_name;
实践
例如:查看users数据表创建语句
show create table users;

3月29日
一、 纵向数据表结构查看
格式
\G
实践
例如:尝试查看纵向数据表结构。
drop database onlinedb;
create database onlinedb;
use onlinedb;
创建users数据表
create table users
(ulD int(11) primary key,
uName varchar(30) not null,
uPwd varchar(50) not null,
uSex char(8) default '男');
desc users \G;

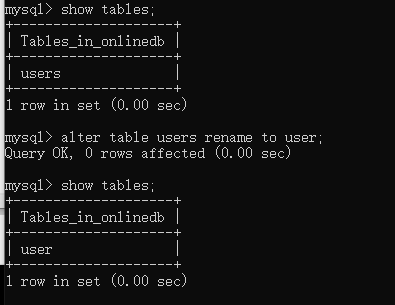
二、修改数据表名
格式
ALTER TABLE 旧表名 RENAME [TO] 新表名;
实践
例如:尝试将users修改为user
show tables;
alter table users rename to user;
show tables;
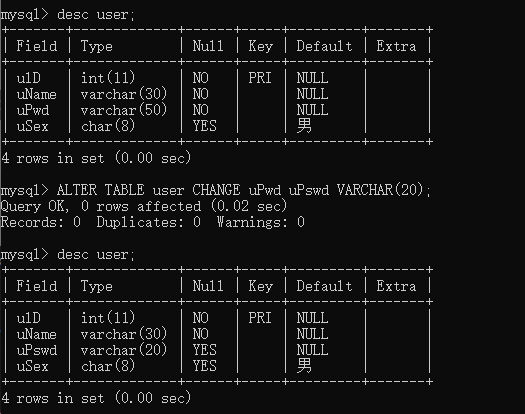
三、修改字段名
格式
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型;
实践
例如:在数据库onlinedb中,将user表名为uPwd字段名称修改为uPswd,长度改为可变20.
desc user;
ALTER TABLE user CHANGE uPwd uPswd VARCHAR(20);
desc user;
四、修改字段类型
格式
ALTER TABLE 表名 MODIFY 字段名 新数据类型;
实践
例如:在数据库onlinedb中,将user表中uPswd字段类型修改为VARBINARY,长度为20.
desc user;
ALTER TABLE user MODIFY uPswd VARBINARY(20);
desc user;

4月10日
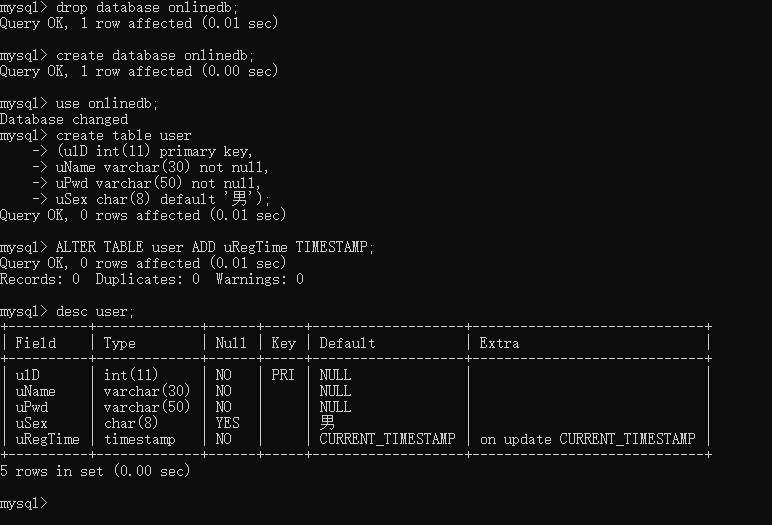
一、添加字段
格式
ALTER TABLE 表名 ADD 字段名 数据类型
2.实践
例如:在user表中增加字段uRegTim,用于存放用户的注册时间,其数据类型为TIMESTAMP。
删除数据库
drop database onlinedb;
创建数据库
create database onlinedb;
打开数据库
use onlinedb;
创建users数据表
create table user
(ulD int(11) primary key,
uName varchar(30) not null,
uPwd varchar(50) not null,
uSex char(8) default '男');
修改表结构添加字段名称
ALTER TABLE user ADD uRegTime TIMESTAMP;
查看表结构
desc user;
二、删除字段
格式
ALTER TABLE 表名 DROP 字段名;
实践
例如:删除user表中的字段uRegTime。
ALTER TABLE user DROP uRegTime;
查看表结构
desc user;

三、修改表的存储引擎
格式
ALTER TABLE user ENGINE=存储引擎名;
实践
例如:修改user表的存储引擎为MyISAM。
show create table user;
ALTER TABLE user ENGINE=MyISAM;
show create table user;

四、复制表结构及数据到新表
格式
CREATE TABLE 新表名 SELECT * FROM 源表名;
实践
例如:复制user表的到users表。
向user数据表填充数据
insert into user values(100,'王丽',123456,'女');
insert into user values(200,'张红',123456,'女');
select * from user;
show tables;
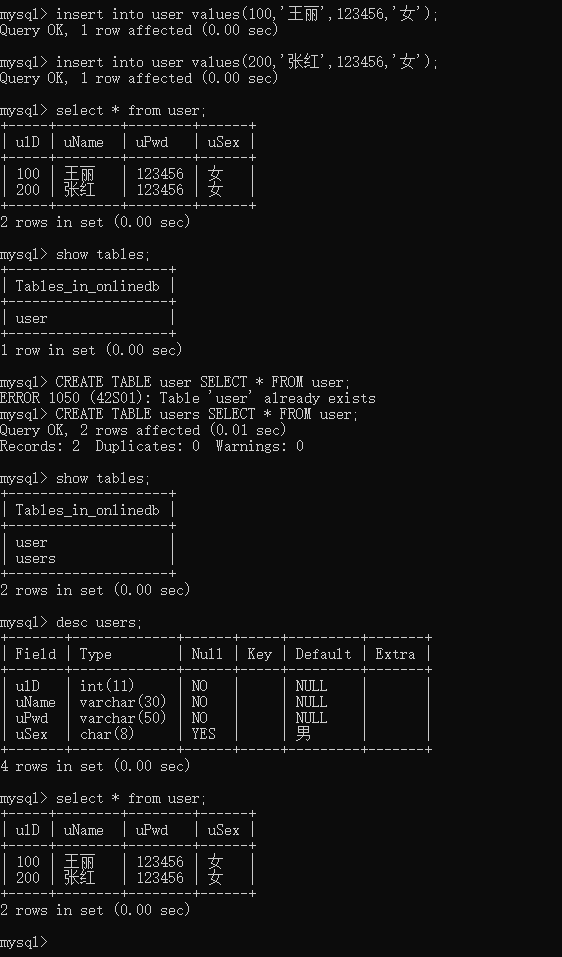
CREATE TABLE users SELECT * FROM user;
show tables;
desc users;
select * from user;
五、只复制表结构到新表
格式
CREATE TABLE 新表名 SELECT * FROM 源表名 WHERE FALSE;
实践
例如:复制user表的结构到temp表
CREATE TABLE temp SELECT * FROM user WHERE FALSE;
desc temp;
select * from temp;

六、使用like复制表结构
格式
CREATE TABLE 新表名 LIKE 源表名;
实践
例如:使用like复制user表的结构复制到tempUser表
CREATE TABLE tempUser LIKE user;
desc tempuser;
select * from tempuser;

4月17日
一、复制表的部分字段和数据到新表
格式
CREATE TABLE 新表名 AS(SELECT 字段1,字段2...... FROM 源表名)
实践
例如:复制user表中uName和uPwd两列数据到newUser表
删除数据库
drop database onlinedb;
创建数据库
create database onlinedb;
打开数据库
use onlinedb;
创建users数据表
create table user
(ulD int(11) primary key,
uName varchar(30) not null,
uPwd varchar(50) not null,
uSex char(8) default '男');
向user数据表填充数据
insert into user values(100,'王丽',123456,'女');
insert into user values(100,'王丽',123456,'女');
查看user数据表中的数据情况
select * from user;
查看当前数据库中有哪些数据表
show tables;
复制局部字段和数据到新表
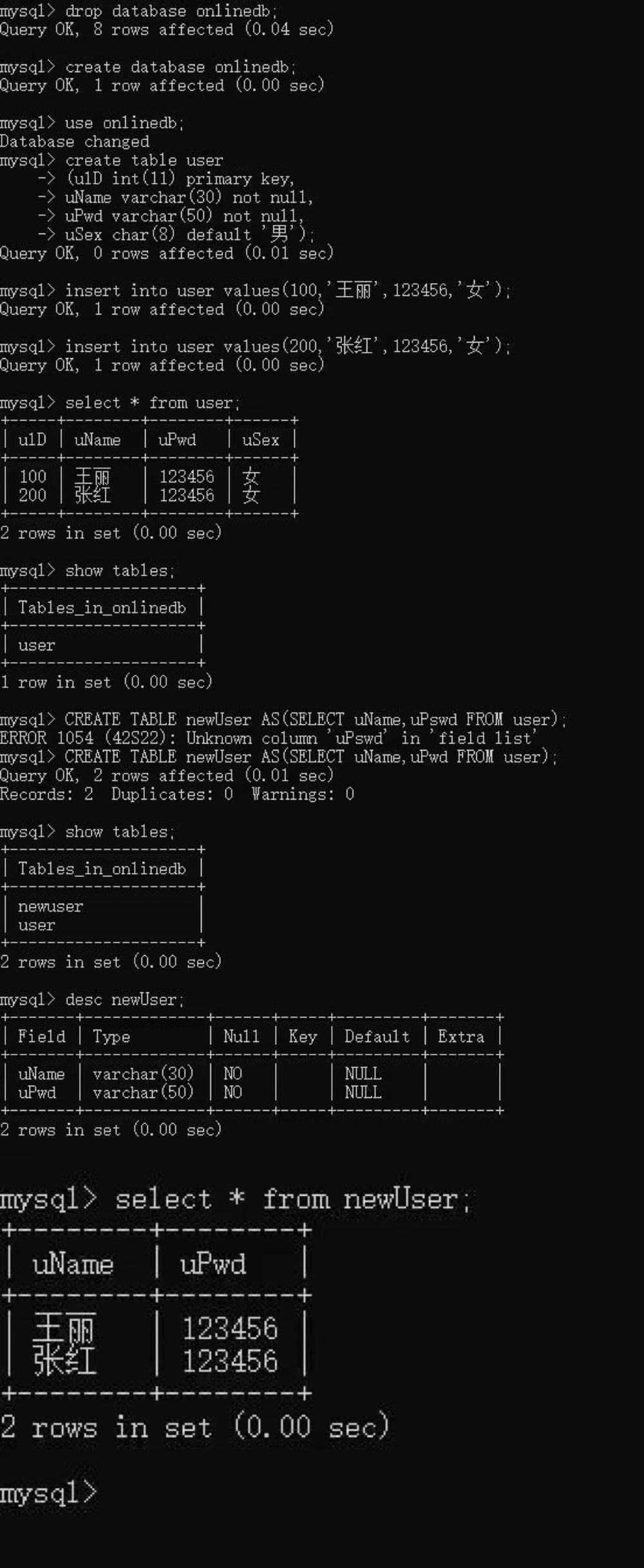
CREATE TABLE newUser AS(SELECT uName,uPwd FROM user);
查看当前数据库中有哪些数据表
show tables;
查看newUser数据表表结构
desc newUser;
查看newUser数据表中的数据
select * from newUser;
二、删除数据表
格式
DROP TABLE 表名;
实践
例如:删除newUser数据表。
drop table newUser;
例如:删除两张数据表
CREATE TABLE newUser AS(SELECT uName,uPwd FROM user);
DROP TABLE newuser,user;
show tables;

三、约束
定义
数据完整性指的是数据的准确性和逻辑一致性,用来防止数据库中存在不符合语义规定的数据或者因错误信息的输入输出造成无效操作或错误信息。
分类
主键约束:数据非空、非重复
非空约束:数据非空
默认值约束:用于指定字段的默认值
唯一约束:非重复
检查约束:用于指定字段取值范围
外键约束:限定两张数据表之间数据制约
四、主键
格式
列一级
字段名 数据类型 PRIMARY KEY
表一级
constaint 约束名 primary key(column)
实践
例如:尝试给user数据表uid定义主键约束
删除数据库
drop database onlinedb;
创建数据库
create database onlinedb;
打开数据库
use onlinedb;
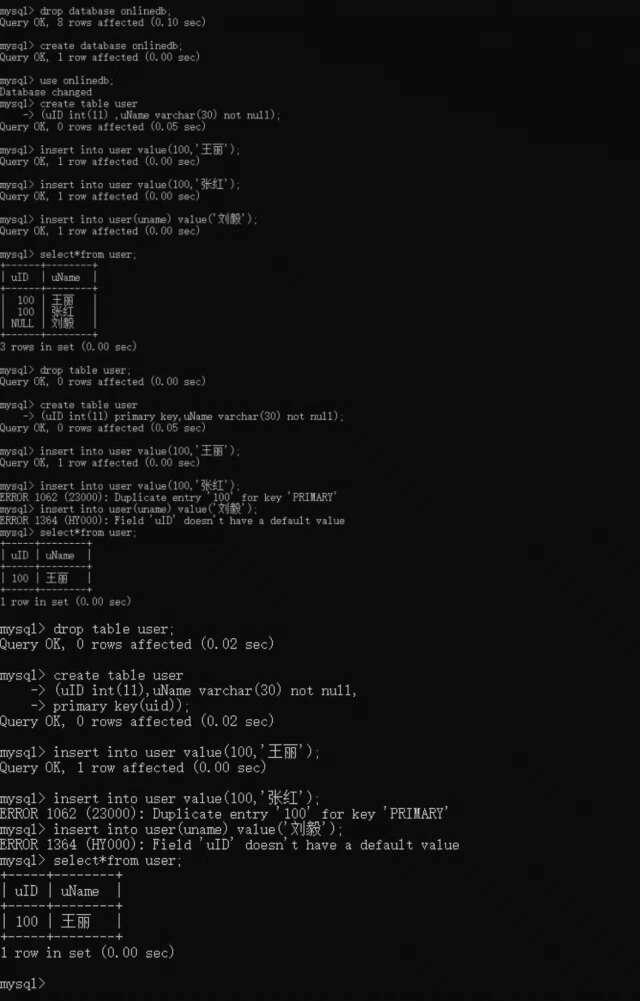
创建没有约束的user
create table user
(uID int(11),uName varchar(30) not null);
尝试感受插入空值和重复数据
insert into user value(100,'王丽');
insert into user value(100,'张红');
insert into user(uname) value('刘毅');
select *from user;
尝试感受不可以填充重复值和空值,创建列一级带约束的数据表结构
drop table user;
create table user
(uID int(11) primary key,uName varchar(30) not null);
尝试感受插入空值和重复数据
insert into user value(100,'王丽');
insert into user value(100,'张红');
insert into user(uname) value('刘毅');
select *from user;
尝试感受不可以填充重复值和空值,创建表一级带约束的数据表结构
drop table user;
create table user
(uID int(11),uName varchar(30) not null,
primary key(uid));
尝试感受插入空值和重复数据
insert into user value(100,'王丽');
insert into user value(100,'张红');
insert into user(uname) value('刘毅');
select *from user;
例如:完成购物车信息表SCarlnfo,完成购物车符合主键约束的定义。
CREATE TABLE SCarInfo
(gdID INT,uID INT,
scNum INT,
PRIMARY KEY(gdID,uID));
插入测试数据
insert into scarinfo values(10,10,10);
insert into scarinfo values(10,10,10);
insert into scarinfo values(20,20,10);
insert into scarinfo(scnum) values(10);
insert into scarinfo(uid,scnum) values(30,10);
查看数据表中的数据的填充。
select * from SCarinfo;
一、非空约束
格式
column datatype not null
实践
例如:实践非空约束
drop table user;
create table user
(uID int(11) primary key,uName varchar(30) not null);
尝试感受插入空值和重复数据
insert into user value(100,'王丽');
insert into user(uid) value(200);
查看数据表中的数据的填充。
select * from user;

4月20日
课程思政:软件的易用性
一、默认值约束
格式
属性名 数据类型 DEFAULT 默认值
实践
例如:尝试定义数据表默认值
定义没有默认值的数据表
CREATE TABLE SCarInfo
(gdID INT,uID INT,scNum INT,
PRIMARY KEY(gdID,uID));
尝试插入测试数据感受没有默认值的状态
insert into SCarInfo value(10,10,3);
insert into SCarInfo(gdid,uid) value(20,20);
查看数据表中的数据。
select * from SCarInfo;
定义有默认值的数据表
drop table SCarInfo;
CREATE TABLE SCarInfo
(gdID INT,uID INT,scNum INT DEFAULT 1,
PRIMARY KEY(gdID,uID));
尝试插入测试数据感受没有默认值的状态
insert into SCarInfo value(10,10,3);
insert into SCarInfo(gdid,uid) value(20,20);
查看数据表中的数据。
select * from SCarInfo;

二、unique
1.定义
UNIQUE约束又称唯—性约束,是指数据表中—列或—组列中只包含唯一值。
2.格式
属性名数据类型UNIQUE
3.实践
例如:尝试创建唯─性约束。
drop database onlinedb;
create database onlinedb;
use onlinedb;
创建无约束数据表
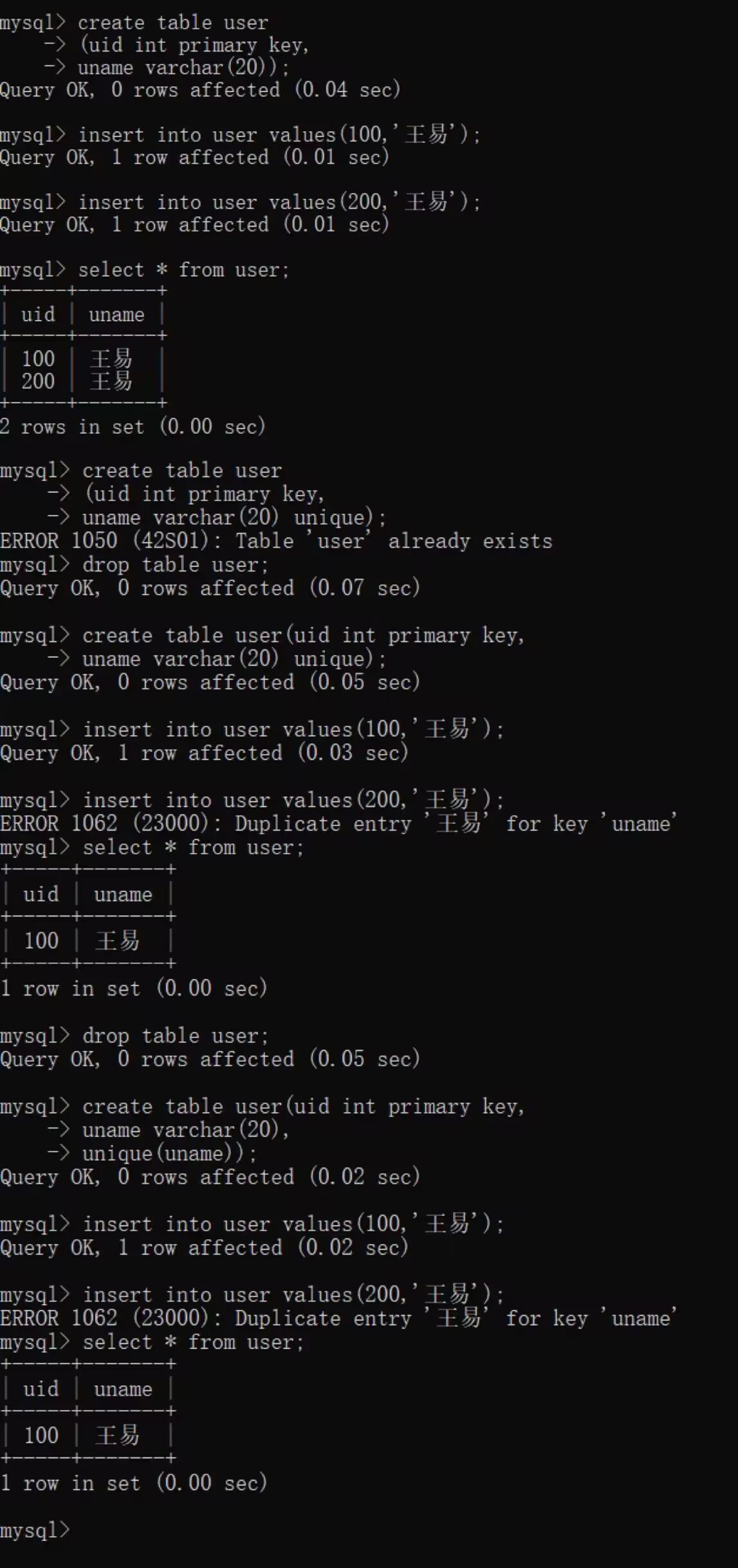
create table user(uid int primary key,
uname varchar(20));
尝试向数据表中填充数据
insert into user values(100,'王易');
insert into user values(200,'王易');
查看数据表中的数据
select * from user;
创建列—级唯—约束数据表
drop table user;
create table user(uid int primary key,
uname varchar(20) unique);
尝试向数据表中填充数据
insert into user values(100,'王易');
insert into user values(200,'王易');
查看数据表中的数据
select * from user;
创建表—级唯—约束数据表
drop table user;
create table user(uid int primary key,
uname varchar(20) ,
unique(uname));
尝试向数据表中填充数据
insert into user values(100,'王易');
insert into user values(200,'王易');
查看数据表中的数据
select * from user;
4月22日
一、表之间的关系
数据库中存在的数据表之间都有一定的关系
建立两张数据表的简单方法就是找到两张数据表中相同的列标题。
分清主表(父表)、从表(子表)
建立关联的列标题是其中一张表的主键,那么这张表就是主表。另一张表就是从表。
二、FOREIGN KEY约束
格式
表一级
CONSTRAINT 外键名 FOREIGN KEY(外键字段名)
REFERENCES 主表名(主键字段名)
列一级
column datatype FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)
实践
例如:尝试完成外键约束的创建。
drop database onlinedb;
create database onlinedb;
use onlinedb;
创建没有外键约束的数据表
第一步创建goodstype数据表
create table goodstype(tid int primary key,tname varchar(20));
第二步创建goods数据表。
create table goods(gid int primary key,tid int,gname varchar(20));
第三步填充数据
insert into goodstype values(1,'电子设备');
insert into goodstype values(2,'图书');
insert into goods values(1000,10,'华为手机');
insert into goods values(2000,12,'python数据分析');
第四步查看数据表中的数据
select * from goodstype;
select * from goods;
drop table goodstype;
drop table goods;
创建有外键约束的数据表
第一步创建goodstype数据表
create table goodstype(tid int primary key,tname varchar(20));
第二步创建goods数据表。
create table goods(gid int primary key,tid int,gname varchar(20),
constraint goods_tid_fk foreign key(tid) references goodstype(tid));
第三步填充数据
insert into goodstype values(10,'电子设备');
insert into goodstype values(20,'图书');
insert into goods values(1000,10,'华为手机');
insert into goods values(2000,12,'python数据分析');
第四步查看数据表中的数据
select * from goodstype;
select * from goods;

4月24日
假定将goodstype数据表的tid为10的数据修改为30
update goodstype
set tid=30
where tid=10;
假定将goodstype数据表的tid为10的数据删除
delete goodstype
where tid=10;
通过以上测试我们得到外键约束数据制约的两个特性
插入数据主表制约从表的数据
修改和删除数据是从表制约主表中的数据
但是在软件应用的过程中,我们很确定要修改或者删除主表中的数据。我们是否可以通过级联修改或者删除主表中的数据完成数据的修改?
如果使用外键约束定义的可选项如on delete cascade 和on update cascade就可以解决以上问题
一、on update cascade的使用
格式
表一级
CONSTRAINT 外键名 FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)on update cascade
实践
例如:尝试使用on update cascade.
drop database onlinedb;
create database onlinedb;
use onlinedb;
第一组体会没有on update cascade外键约束
第一步创建goodstype数据表
create table goodstype(tid int primary key,tname varchar(20));
第二步创建goods数据表。
create table goods(gid int primary key,tid int,gname varchar(20));
第三步填充数据
insert into goodstype values(1,'电子设备');
insert into goodstype values(2,'图书');
insert into goods values(1000,10,'华为手机');
insert into goods values(2000,12,'python数据分析');
第四步查看数据表中的数据
select * from goodstype;
select * from goods;
第五步将goodstype数据表的tid为10的数据修改为30
update goodstype
set tid=30
where tid=10;
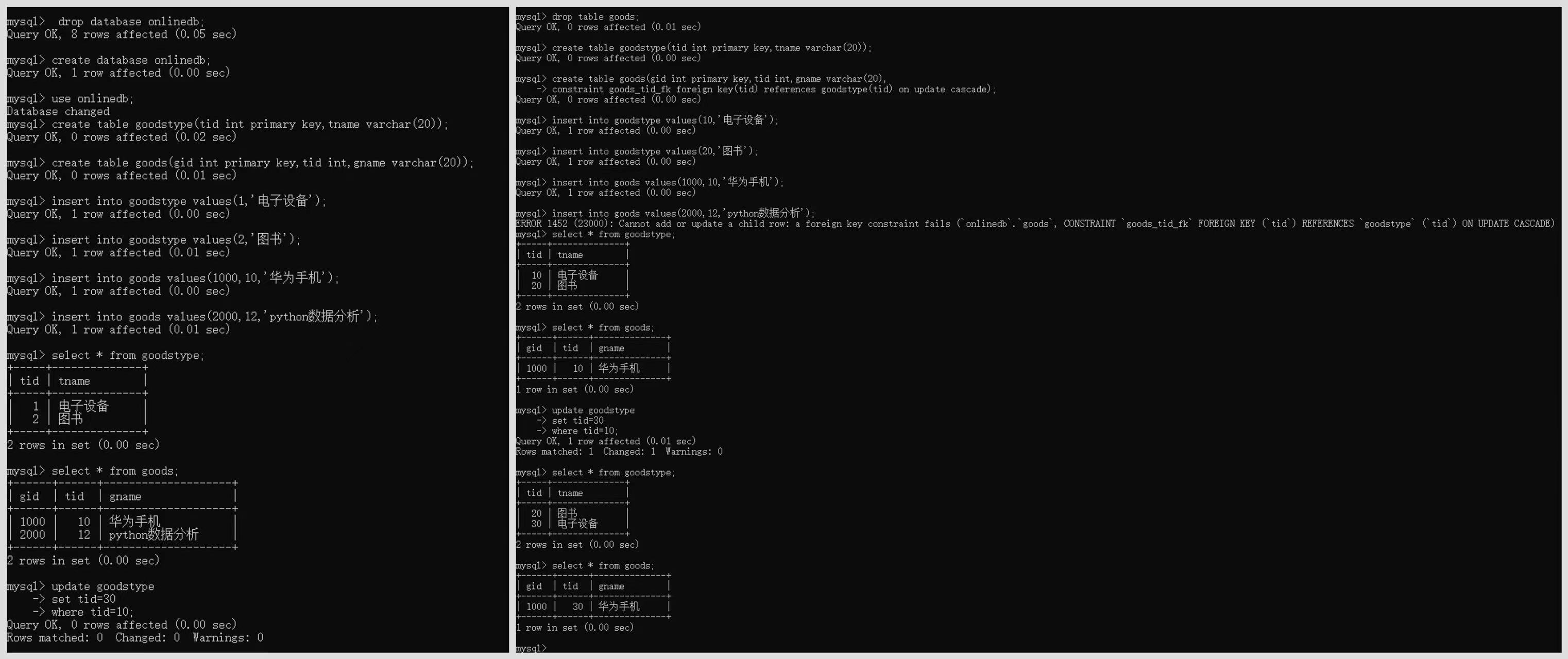
第二组体会on update cascade外键约束
drop table goodstype;
drop table goods;
第一步创建goodstype数据表
create table goodstype(tid int primary key,tname varchar(20));
第二步创建goods数据表。
create table goods(gid int primary key,tid int,gname varchar(20),
constraint goods_tid_fk foreign key(tid) references goodstype(tid) on update cascade);
第三步填充数据
insert into goodstype values(10,'电子设备');
insert into goodstype values(20,'图书');
insert into goods values(1000,10,'华为手机');
insert into goods values(2000,12,'python数据分析');
第四步查看数据表中的数据
select * from goodstype;
select * from goods;
第五步将goodstype数据表的tid为10的数据修改为30
update goodstype
set tid=30
where tid=10;
第六步查看数据表中的数据
select * from goodstype;
select * from goods;
二、on delete cascade
CONSTRAINT 外键名 FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)on delede cascade
实践
例如:尝试使用on update cascade.
drop database onlinedb;
create database onlinedb;
use onlinedb;
第一组体会没有on delete cascade外键约束
第一步创建goodstype数据表
create table goodstype(tid int primary key,tname varchar(20));
第二步创建goods数据表。
create table goods(gid int primary key,tid int,gname varchar(20),
constraint goods_tid_fk foreign key(tid) references goodstype(tid));
第三步填充数据
insert into goodstype values(10,'电子设备');
insert into goodstype values(20,'图书');
insert into goods values(1000,10,'华为手机');
insert into goods values(2000,12,'python数据分析');
第四步查看数据表中的数据
select * from goodstype;
select * from goods;
第五步将goodstype数据表的tid为10的数据修改为30
delete from goodstype
where tid=10;
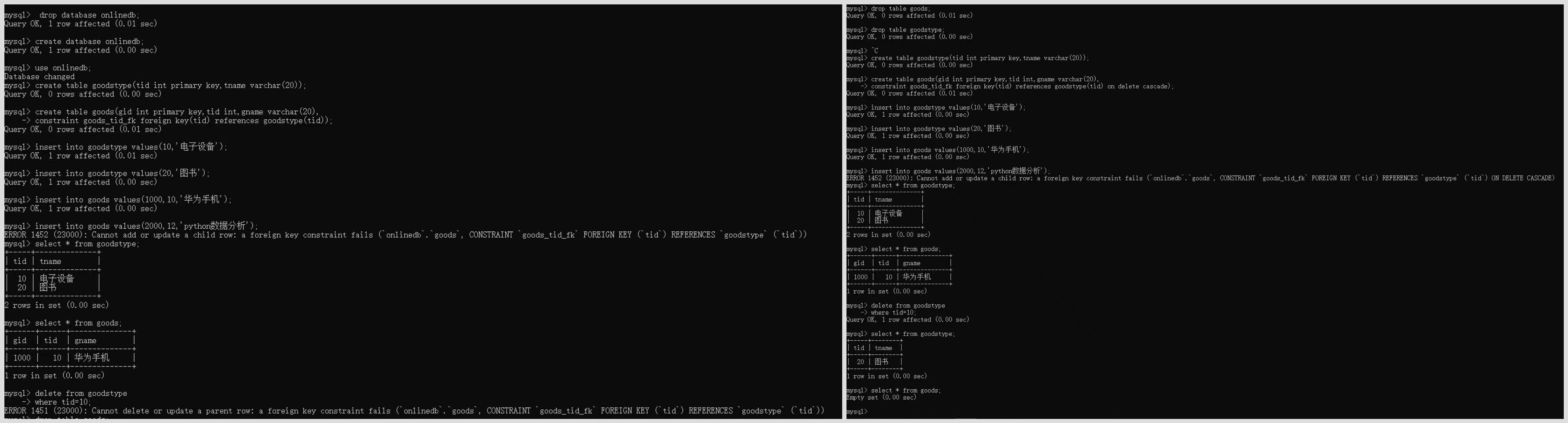
第二组体会on update cascade外键约束
drop table goods;
drop table goodstype;
第一步创建goodstype数据表
create table goodstype(tid int primary key,tname varchar(20));
第二步创建goods数据表。
create table goods(gid int primary key,tid int,gname varchar(20),
constraint goods_tid_fk foreign key(tid) references goodstype(tid) on delete cascade);
第三步填充数据
insert into goodstype values(10,'电子设备');
insert into goodstype values(20,'图书');
insert into goods values(1000,10,'华为手机');
insert into goods values(2000,12,'python数据分析');
第四步查看数据表中的数据
select * from goodstype;
select * from goods;
第五步将goodstype数据表的tid为10的数据修改为30
delete from goodstype
where tid=10;
第六步查看数据表中的数据
select * from goodstype;
select * from goods;
4月26日
一、约束删除
格式
alter table 表名 drop 约束类型[约束名]
实践
例如:尝试在goods数据表中删除goods_tid_fk约束。
alter table goods drop foreign key goods_tid_fk;

二、插入数据
格式
INSERT INTO 表名[(字段列表)] VALUES(值列表);
实践
例如:尝试向GoodsType数据表中填充数据,名称为"学习用品"的类别,其中类别ID为1.
select * from goodstype;
INSERT INTO GoodsType VALUES(1,"学习用品");
select * from goodstype;

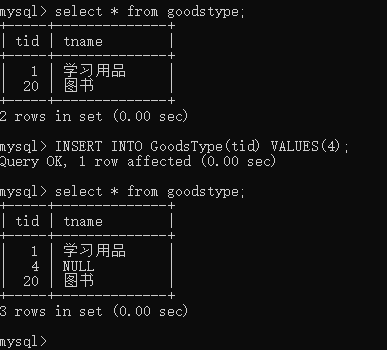
例如:尝试向GoodsType数据表中填充数据,其中类别ID为4.
select * from goodstype;
INSERT INTO GoodsType(tid) VALUES(4);
select * from goodstype;
三、replace
1.格式
REPLACE INTO 表名[(字段列表)] VALUES(值列表);
使用REPLACE时,首先尝试插入到数据表中,若检测表中已经有该记录(通过主键或唯一约束判断),则先删除此记录,然后再插入新的数据。
2.实践
例如:尝试向GoodsType数据表中填充数据,,名称为”汽车用品“的类别,其中类别ID为1.
select * from goodstype;
INSERT INTO GoodsType VALUES(1,'汽车用品');
select * from goodstype;
REPLACE INTO GoodsType VALUES(1,'汽车用品');
select * from goodstype;
5月6日
一、多条语句添加(insert)
格式
INSERT INTO 表名[(字段列表)] VALUES(值列表1)[(值列表2),...(值列表n)];
实践
例如:尝试向users表中添加三条新记录
创建没有外键约束的数据表
drop database onlinedb;
create database onlinedb;
use onlinedb;
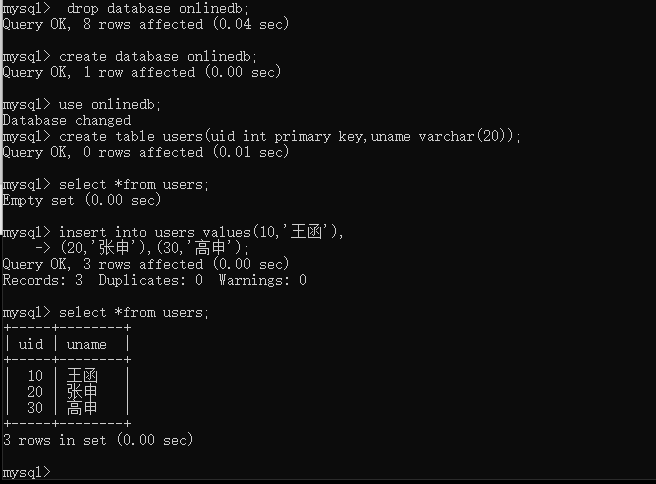
第一步创建users数据表
create table users(uid int primary key,uname varchar(20));
第二步查看数据表中的数据
select *from users;
第三步添加数据
insert into users values(10,'王函'),
(20,'张申'),(30,'高申');
第四步查看数据表中的数据
select *from users;
二、多条语句添加(replace)
格式
REPLACE INTO 表名[(字段列表)] VALUES(值列表1)[(值列表2),...(值列表n)];
实践
例如:尝试向users表中添加三条新记录
创建没有外键约束的数据表
drop database onlinedb;
create database onlinedb;
use onlinedb;
第一步创建users数据表
create table users(uid int primary key,uname varchar(20));
第二步查看数据表中的数据
select *from users;
第三步添加数据
replace into users values(10,'刘静'),
(20,'张勤'),(30,'王雨');
第四步查看数据表中的数据
select *from users;

三、插入其他表的数据
格式
INSERT INTO 目标数据表(字段列表1)
SELECT字段列表2 FROM 源数据表 WHERE 条件表达式;
实践
例如:尝试将表user中uname为王雨用户的信息填充到users1数据表中。
第一步创建users1数据表
create table users1(uid int primary key,uname varchar(20));
第二步查看数据表中的数据
select *from users1;
第三步填充数据
INSERT INTO users1(uid,uname)
SELECT uid,uname
FROM users
WHERE uname='王雨';
第四步查看数据表中的数据
select *from users1;

四、INSERT INTO 表名
SET 字段名1=值1[,字段名2=值2,....]
2、实践
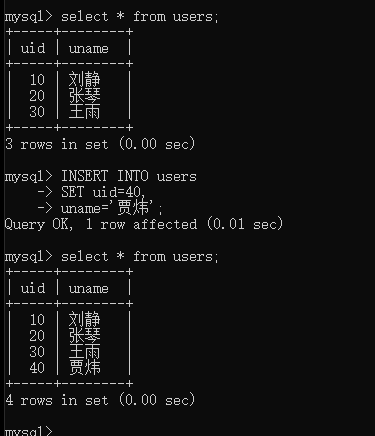
例如:尝试向users表中添加数据,其中uid的值为40,uName的值为“贾炜”。
第一步 查看数据表中的数据
select * from users;
第二步 填充数据
INSERT INTO users
SET uid=40,
uname='贾炜';
第三步 查看数据表中数据
select * from users;
5月8日
一、修改数据(update)
格式
UPDATE表名
SET 字段名1=值1,字段名2=取值2,.....,字段n=取值n
[WHERE 条件表达式];
实践
例如:将users数据表中uname王函修改为刘静。
drop database onlinedb;
create database onlinedb;
use onlinedb;
第一步创建users数据表
create table users(uid int primary key,uname varchar(20));
第二步查看数据表中的数据
select *from users;
第三步添加数据
insert into users values(10,'王函'),
(20,'张申'),(30,'高申');
第四步查看数据表中的数据
select *from users;
第五步修改数据
update users
set uname='刘静'
where uid=10;
第六步查看数据表中的数据
select *from users;

二、删除数据
格式
DELETE FROM 表名[WHERE 条件表达式];
实践
例如:删除刘静的数据
第一步删除数据
delete from users
where uname='刘静';
第二步查看数据表中的数据
select *from users;

例如:删除users数据表中的数据。
delete from users;
第二步查看数据表中的数据
select *from users;

三、删除所有数据
格式
TRUNCATE [TABLE] 表名
2.TRUNCATE和delete的区别
DELETE语句可以实现带条件的数据删除,TRUNCATE只能清除表中所有记录。
TRUNCATE语句清除表中记录后,再向表中插入记录时,自动增加的字段默认初始值重新从1开始:使用DELETE语句删除表中所有记录后,再向表中添加记录时,自增字段的值会从记录中该字段最大值加1开始编号。
使用DELETE语句每删除一行记录都会记录在系统操作日志中, TRUNCATE语句清空数据时,不会在日志中记录删除内容。若要清除表中所有数据TRUNCATE语句效率要高于DELETE语句。
3.实践
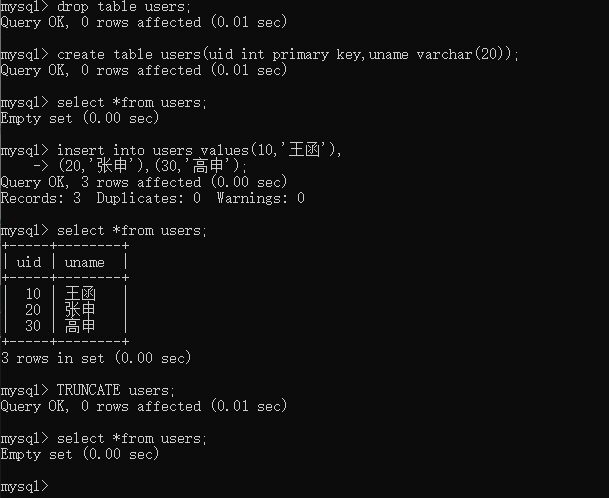
例如:删除users数据表中所有的数据
第一步创建users数据表
drop table users;
create table users(uid int primary key,uname varchar(20));
第二步查看数据表中的数据
select *from users;
第三步添加数据
insert into users values(10,'王函'),
(20,'张申'),(30,'高申');
第四步查看数据表中的数据
select *from users;
第五步删除数据
TRUNCATE users;
第六步查看数据表中的数据
select *from users;
5月10日
一、查询基本结构
1、格式
SELECT [ALL| DISTINCT ]*| 列名1[,列名2,......列名n]
FROM 表名
[WHERE条件表达式]
[GROUP BY 列名[ASC| DESC] [HAVING 条件表达式]]
[ORDER BY列名 [ASC| DESC],...]
[LIMIT [OFFSET] 记录数]
·SELECT 子句: 表示从表中查询指定的列
·FROM子句: 表示查询的数据源,可以是表或视图
WHERE子句: 用于指定查询筛选条件。
·GROUP BY子句: 用于将查询结果按指定的列进行分组;其中HAVING为可选参数,用
于对分组后的结果集进行筛选。
ORDER BY子句:用于对查询结果集按指定的列进行排序。
LIMIT子句: 用于限制查询结果集的行数。参数OFFSET为偏移量,当OFFSET值为0时表示从查询结果的第1条记录开始,如果OFFSET为1时,表示查询结果从第2条记录开始.
二、关键字 "*"
功能
替代数据表中所有的列标题
格式
select *
实践
例如:GoodsType(商品类别名)中所有的商品类别信息
use onlinedb;
select * from GoodsType;

三、查询指定的列
格式
SELECT 列名1[列名2,......列名n]
实践
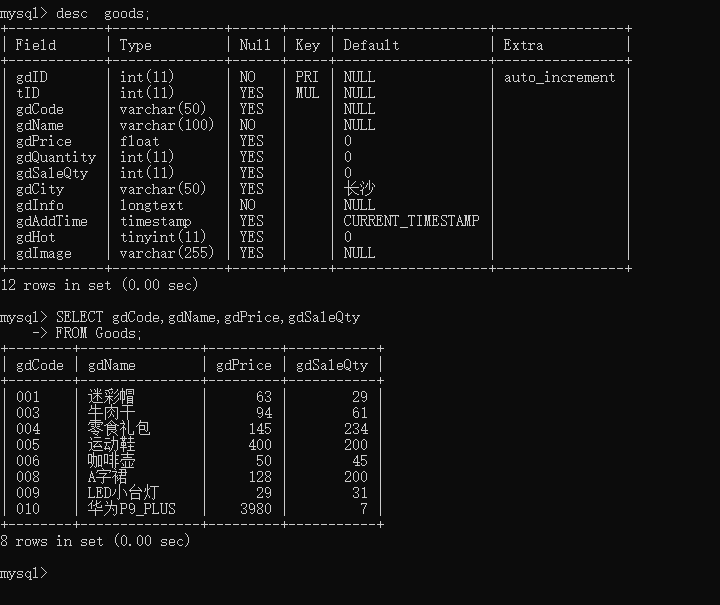
例如:查询Goods(商品信息表)中所有的商品编号,名称,价格和销售数量
desc goods;
SELECT gdCode,gdName,gdPrice,gdSaleQty
FROM Goods;
四、计算列值
格式
select 算术表达式
实践
例如:查询Goods中每件商品的销售总价,其中销售总价-销售数量*价格,显示商品名称和销售总价
SELECT gdName,gdSaleQty*gdPrice
FROM Goods;

五、使用函数计算列值
格式
select 函数
实践
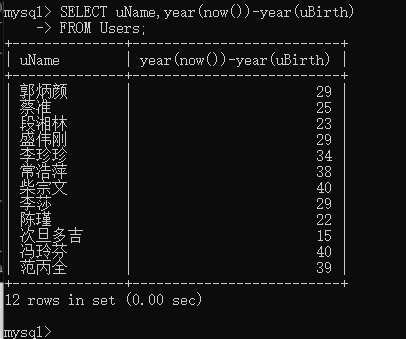
例如:查询Users(用户信息表)中,用户名和年龄。
注意
year()函数:获取日期时间的年份
now()函数:获取当前系统时间。
SELECT uName,year(now())-year(uBirth)
FROM Users;
六、AS关键字使用
功能给数据查询结果起一个新的列标题名称。
格式
select 原列标题名称 as 新列表题名称
实践
例如:查询Users(用户信息表)中,用户名字和年龄,在显示数据的时候列标题分别为姓名和年龄。
SELECT uName as 姓名,year(now())-year(uBirth) as 年龄
FROM Users;

七、使用比较运算符
分类
>、<、>=、<=、<>
实践
例如:查询Users表中uID为8的用户姓名
SELECT uID,uName
FROM Users
WHERE uID=8;

5月15日
一、逻辑运算符
分类
与:and
或:or
非:not
格式
where 表达式 逻辑运算符 表达式
实践
例如:查询Users表中2000年后出生的用户,且性别为"男"的用户姓名,电话号码,出生年月
打草稿
2000年后出生的用户:year(uBirth)>2000
性别为"男":uSex='男'
2000年后出生的用户,且性别为"男":year(uBirth)>2000 and uSex='男'
最终获得where条件子句
year(uBirth)>2000 and uSex='男'
最终获得where条件子句
where year(uBirth)>2000 and uSex='男'
最后融合查询语句
select uname,uphone,uBirth
from users
where year(uBirth)>2000 and uSex='男';

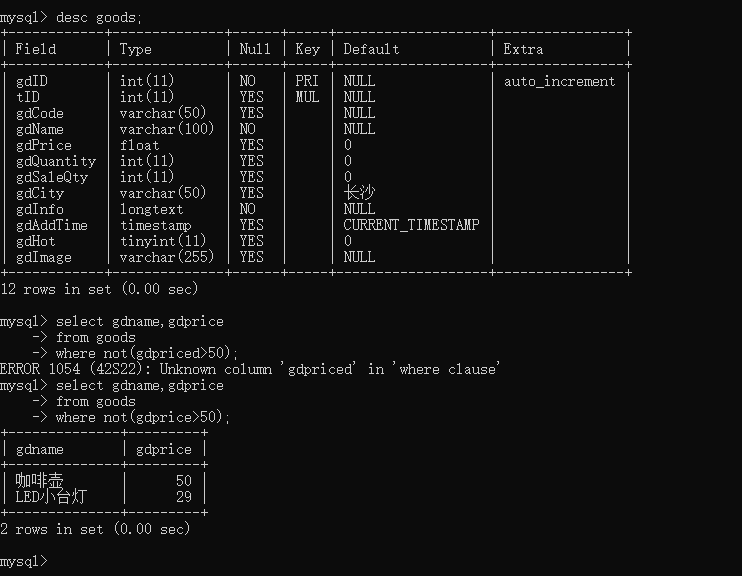
例如:查询Goods数据表中gdPrice不大于50的商品名称
打草稿
gdprice大于50
where gdprice>50
不大于50的
where not(gdprice>50)
最后融合查询语句
select gdname,gdprice
from goods
where not(gdprice>50);
例如:查询Goods表中gdCity值为"长沙"或"西安",且gdPrice小于等于50的商品名称
打草稿
gdCity值为"长沙":where gdcity='长沙'
gdCity值为"西安":where gdcity='西安'
gdPrice小于等于50:where gdprice<=50
where not(gdPrice>50)
逻辑运算
gdCity值为"长沙"或"西安",且gdPrice小于等于50
where gdcity='长沙' or gdcity='西安' and gdprice<=50
最后融合查询语句
SELECT gdName,gdPrice,gdCity
FROM goods
where (gdcity='长沙' or gdcity='西安' )and gdprice<=50;

二、BETWEEN AND运算符
功能
限定取值范围
格式
WHERE 表达式[NOT] BETWEEN 初始值 AND 终止值
实践
例如:查询Goods表中gdPriced在100至500的商品名称。
SELECT gdName,gdPrice
FROM goods
WHERE gdPrice BETWEEN 100 AND 500 ;

三、IN运算符
功能:
序列值的匹配
格式
WHERE表达式[NOT] IN (值1.值...值N)
实践
例如:查询Goods表中gdCity为长沙、西安、上海三个城市的商品名称。
SELECT gdName,gdCity
FROM goods
WHERE gdCity in ('长沙','西安','上海');

5月17日
一、LIKE运算符
功能
模糊匹配
格式
WHERE 列名 [NOT] LIKE '字符串' [ESCAPE '转义字符']
%:任意字符串
s%:表示查询以s开头的任意字符串,如small、star.....s..
%s:表示查询以s结尾的任意字符串,如address
%s%:表示查询包含s的任意字符串,如super、 course
:任何单个字符
[s:表示查询以s结尾且长度为2的字符串,如as
s_ :表示查询以s开头且长度为2的字符串,如sa
实践
例如:查询Users表中gdName为"李"开头的用户姓名、性别和手机号
打草稿
uname like '李%'
最后得到查询语句
use onlinedb;
SELECT uName,uSex,uPhone
FROM users
WHERE uName LIKE '李%';

例如:查询Users表中gdName第2个字为“湘”的用户姓名、性别和手机号。
打草稿
where uname like '_湘%'
最后得到查询语句
SELECT uName,uSex,uPhone
FROM users
where uname like '_湘%';
例如:查询Goods表中gdName以“华为P9_”开头的gdCode。
注意:转义字符为"\",比如在匹配字符的过程中包含_或者%,我们需要使用转义字符让这两个通配符去掉通配功能
打草稿
WHERE gdName LIKE '华为P9\_%'
最后得到查询语句
SELECT gdCode,gdName,gdPrice
FROM goods
WHERE gdName LIKE '华为P9\_%';

二、REGEXP运算符
功能
模糊匹配

2.格式
WHERE 列名 REGEXP '模式串'
3.实践
例如:查询Users表中uPhone以 “5"结尾用户的姓名,性别和电话。
打草稿:
WHERE uPhone REGEXP '5$'
最后得到查询语句
SELECT uName,uSex,uPhone
FROM users
WHERE uPhone REGEXP '5$';
例如:查询Users表中uPhone以“16,17,18"开头用户的姓名,性别和电话。
打草稿
WHERE uPhone REGEXP '^1[678]' ;
最后得到查询语句
SELECT uName,uSex,uPhone
FROM users
WHERE uPhone REGEXP '^1[678]' ;

5月24日
一、IS NULL运算符
格式
WHERE 列名 IS [NOT] NULL
实践
例如:查询Users表中uImage为空的用户姓名和性别。
打草稿
WHERE uImage IS NULL;
最后得到查询语句
SELECT uName,uSex,uImage
FROM users
WHERE uImage IS NULL;

二、DISTINCT消除重复结果集
1.格式
select DISTINCT 列名
2.实践
例如:查询goods表中gdPrice大于200的商品来源哪些城市。
SELECT DISTINCT gdCity
FROM goods
WHERE gdprice>200;
三、数据排序
格式
ORDER BY {列名|表达式|正整数}[ASC | DESC][,...n]
实践
例如:查询Goods表tID为1的商品编号、名称和价格,并按价格升序排列
打草稿
where tid=1
排序
order by gdprice
最后得到查询语句
升序
select tid,gdname,gdprice
from goods
where tid=1
order by gdprice;
降序
select tid,gdname,gdprice
from goods
where tid=1
order by gdprice desc;

例如:查询Goods表tID为1的商品编号、名称、价格和销售量,并先按销售量降序,再建个升序排列
打草稿
where tid=1
排序
order by gdSaleQty DESC,gdPrice
最后得到查询语句
SELECT gdCode,gdName,gdSaleQty,gdPrice
FROM goods
WHERE tID=1
ORDER BY gdSaleQty DESC,gdPrice;

三、使用LIMIT限制结果集返回的行数
1.格式
LIMIT [OFFSET,]记录数
2.实践
例如:查询Goods表前3行记录的商品编号、 名称和价格。
select *
from goods
limit 3;

6月5日
一、数据分组统计
格式
group by .....分组字段名称......[having]
[having] 条件的限定
实践
组函数
SUM 返回表达式中所有值的和
AVG 返回组中各值的平均值
MAX 返回表达式中的最大值
MIN 返回表达式中的最小值
COUNT 返回组中的项数
GROUP_ CONCAT 返回一个字符串结果,该结果由分组中的值连接组合而成
例如:查询goods表,统计所有商品的总销售量。
SELECT SUM(gdSaleQty) FROM goods;

例如:查询goods表,显示商品的最高价格。
SELECT MAX(gdPrice) FROM goods;

例如:查询orders表。显示购买过商品的用户人数
SELECT COUNT(DISTINCT uID)FROM orders;
例如:查询Users表,按uCity进行分组。
SELECT uID,uName,uSex,uCity
FROM Users
GROUP BY uCity;

例如:查询Users表,统计各城市的用户人数。
SELECT uCity,count(uid)
FROM Users
GROUP BY uCity;
例如:查询Users表,将同一城市的uID值用","连接起来,列名为uIDs。
SELECT uCity,GROUP_CONCAT(uID) as uIDs
FROM Users
GROUP BY uCity;

例如:查询Users表,将同一城市的uID值用下划线"_"连接起来,列名为uIDs。
SELECT uCity,GROUP_CONCAT(uID ORDER BY uID SEPARATOR'_') as uIDs
FROM Users
GROUP BY uCity;

例如:查询Users表,统计"上海"和"长沙"两地用户人数。
注意:GROUP和WITH ROLLUP一起使用,可以输出每一类分组的汇总值。
SELECT uCity,COUNT(*)
FROM users
WHERE uCity in('长沙','上海')
GROUP BY uCity
WITH ROLLUP;

例如:查询Users表,统计各城市的用户人数,显示人数在3人以上的城市。
GROUP BY和HAVING 一 起使用
HAVING关键字和WHERE关键字都用于设置条件表达式对查询结果集进行筛选
HAVING关键字后可以跟聚合函数,且只能跟GROUP BY-起使用
SELECT uCity,COUNT(*)
FROM users
GROUP BY uCity
HAVING COUNT(*)>=3;
SELECT uCity,COUNT(*)
FROM users
GROUP BY uCity;

注意:where子句是对原始数据的条件限定,having子句是对统计之后数据的条件限定
6月5日7、8
一、任务场景
实际应用中,数据查询的要求通常要涉及多张数据表。连接是多表数据查询的一种有效手段,本任务阐述外连接叉连接等连接方式,
灵活构建多表查询,以满足实际应用的需求。
二、多表连接分类
交叉连接
内连接
外连接
自连接
联合连接
三、交叉连接
概念
交叉连接是将左表中的每一行记录与右表中的所有记录进行连接,返回的记录行数是两个表的乘积。
注意
交叉连接在软件做数据压力测试的时候让他出现除此之外尽量避免交叉连接的出现。
格式
select column_name......
from table_name1 cross join table_name2;
实践
例如:查询会员能购买的所有可能的商品情况,列出uID、uName、gdID、gdName.
select users.uID,users.uName,goods.gdID,goods.gdName
from users cross join goods;

四、内连接
1.概念
内连接(INNER JOIN) :查询结果集返回与连接条件匹配的记录行,通常使用比较运算比较被连接的列值。
2.格式
SELECT [ALL | DISTINCT ]* |列名1[列名2,,.....列名n]
FROM表1 [别名1] JOIN表2 [别名2]
[ON表1关系列=表2.关系列]
( WHERE条件表达式];
3.实践
例如:查询Goods表中商品类别为"服饰"的商品ID、名称、价格及类别名称。
商品ID(Goods)、名称(GOODS)、价格(GOODS)及类别名称(catagory)。
通过分析发现goods数据表中的cid和catagory数据表中的cid可以做两张数据表的连接桥梁,因此连接语句应该是
ON goods.tid=goodstype.tid
最后得到查询语句
select goods.gdid, goods.gdName,goods.gdPrice,goodstype.tname
from goods join goodstype
ON goods.tid=goodstype.tid
where goodstype.tname='服饰';

例如:查询用户名为“段湘林”购买商品的订单总金额。
用户姓名,订单总金额来源于哪些表。
users和orders数据表通过uid连接
on users.uid=orders.uid
最后得到查询语句
select uName,SUM(oTotal)
from users join orders
on users.uid=orders.uid
where users.uname='段湘林';

例如:查询uName值为"段湘林"的购物车中的商品名称,价格及其购买数量。
段湘林
商品名称
购买数量
通过题设中三个关键词找到了三个数据源分类是
goods、users、cart
接下来找三个表的连接条件
on user.uid=scar.uid
on cart.gdid=goods.gdid
得到from
from users join scar on user.uid=scar.uid
jion goods on scar.gdid=goods.gdid
最后得到查询语句
select goods.gdname,goods.gdprice,scar.scnum
from users join scar on users.uid=scar.uid
join goods on scar.gdid=goods.gdid
where users.uname='段湘林';

6月6日
一、自连接
格式
select column
from table join table
2. 实践
例如:查询与段湘林在同一个城市的用户,列出用户名、邮箱和城市名。
通过关键词提取我们使用的数据源是users
通过查询需求得到连接条件
from users a join users b
on a.ucity=b.ucity
最后得到完整的查询语句
select a.uname,a.uemail,a.ucity
from users a join users b
on a.ucity=b.ucity
where b.uname='段湘林' and a.uname!='段湘林';

二、外连接
分类
左外连接:首先返回两表中相同的记录除此之外再返回左表中全部的记录。
右外连接:首先返回两表中相同的记录除此之外再返回右表中全部的记录。
完全外连接:首先返回两表中相同的记录除此之外再返回左右表中全部的记录。
2.格式
左外连接
SELECT [ALL | DISTINCT ]* |列名1[列名2,,.....列名n]
FROM表1 [别名1] left JOIN表2 [别名2]
[ON表1关系列=表2.关系列]
( WHERE条件表达式];
右外连接
SELECT [ALL | DISTINCT ]* |列名1[列名2,,.....列名n]
FROM表1 [别名1] right JOIN表2 [别名2]
[ON表1关系列=表2.关系列]
( WHERE条件表达式];
实践
例如:查询每个用户的订单金额,列出uID、uName,oTotal。
uID、uName,oTotal请问这个查询会涉及哪些数据源。
会涉及users、orders
select s.uID,uName,oTotal
from users s LEFT JOIN orders t
ON s.uID=t.uID;
例如:查询每个用户的订单数,列出uID,uName,ordernum(订单数)
SELECT s.uid,uname,oTotal
FROM orders t RIGHT JOIN users s
ON s.uid=t.uid;
6月7日
一、联合查询
1.任务场景
在多表查询过程我们还会碰到没有关系的数据表查询结果的合并,在这样的情况下我们需要使用联合
查询
2.概念
联合查询是将多个SELECT语句返回的结果集合并为单个结果集, 该结果集包含联合查询中的每一 个
查询结果集的全部行,参与查询的SELECT语句中的列数和列的顺序必须相同,数据类型也必须兼容。
3.格式
SELECT语句1 UNION[ALL] SELECT语句2
[UNION [ALL]<SELECT语句3>][.....n]
4.实践
例如:联合查询ulD值为1和2的用户信息,列出uld,uName,uSex。
列出uld,uName,uSex请问涉及到的数据源是哪张表?
user
第一步查询uid为1的用户信息
SELECT uId,uName,uSex
FROM users
WHERE uId=1;
第二步查询uid为2的用户信息
SELECT uId,uName,uSex
FROM users
WHERE uId=2;
第三步合并查询语句
SELECT uId,uName,uSex
FROM users
WHERE uId=1
UNION
SELECT uid,uName, uSex
FROM users
WHERE uId=2;

例如:联合查询tid值为1和2的商品信息,列出tid, gdName, gdPrice, 并按gdPrice从高到低排序,显示前三行记录。
列出tid, gdName, gdPrice, 并按gdPrice从高到低排序请问需要涉及到哪些数据源
goods|
第一步查询tid为1的商品信息
SELECT tId,gdName,gdPrice
FROM goods
WHERE tId=1;
第二步查询tid为2的商品信息
SELECT tId,gdName,gdPrice
FROM goods
WHERE tId=2;
第三步合并查询语句
SELECT tId,gdName,gdPrice
FROM goods
WHERE tId=1
UNION
SELECT tId,gdName,gdPrice
FROM goods
WHERE tId=2;
第四步实现排序和显示前三行
SELECT tId,gdName,gdPrice
FROM goods
WHERE tId=1
UNION
SELECT tId,gdName,gdPrice
FROM goods
WHERE tId=2
ORDER BY gdPrice DESC LIMIT 3;

二、子查询
任务场景
子查询是多表数据查询的另一种有效方法, 当数据查询的条件依赖于其他查询的结果时,使用子查询可以有效解决此类问题。本任务阐述了子查询用作表达式的查询技巧
格式
select column
from table
where (subquery子查询)
实践
例如:查询商品类别为"服饰"的商品ID、名称、价格及销售量
根据题设请问涉及哪些数据源
goods(商品信息表)和goodstype(商品类别表)通过分析这两张的类别id是相同的,可以作为连接桥梁
第一步查询商品类别为"服饰"的类别id
select tid
from goodstype
where tname='服饰';
第二步查询tid=1的商品id、名称及销售量
select gdid,gdname,gdprice,gdSaleQty
from goods
where tid=1;
第三步使用子查询合并以上语句
select gdid,gdname,gdprice,gdSaleQty
from goods
where tid=(select tid
from goodstype
where tname='服饰');

三、使用比较运算符的子查询
格式
WHERE 表达式 比较运算符(子查询)
实践
例如:查询商品名称为"LED小台灯”的评价信息和评价时间。
根据题设分析需要使用的数据源需要使用
goods(商品名称)和orderdetail(评价信息和评价时间)
又通过分析我们发现这两张数据表都有gdid,因此我们将gdid作为这两张数据表的连接桥梁
第一步查询LED小台灯的gdid
select gdid
from goods
where gdname='LED小台灯';
第二步查询gdid=9的评价信息和评价时间
SELECT dEvalution,odTime
FROM orderdetail
WHERE gdID=9;
第三步合并查询语句
SELECT dEvalution,odTime
FROM orderdetail
WHERE gdID= (SELECT gdID
FROM goods
WHERE gdName='LED小台灯');

例如:查询比商品"LED小台灯”销售量要少的商品信息,列出商品编号、商品名称、商品价格和商品销售量。
通过分析我们发现使用goods数据源是不是就能找到商品信息
第一步我们需要先查询"LED小台灯”的销售量
select gdsaleqty
from goods
where gdname='LED小台灯';
第二步查询销售量比31少的商品编号、商品名称、商品价格
select gdid,gdname,gdprice
from goods
where gdsaleqty < 31;
第三步将前两步的查询语句合并
select gdid,gdname,gdprice
from goods
where gdsaleqty < (
select gdsaleqty
from goods
where gdname='LED小台灯'
);

6月12日
一、使用IN关键字的子查询
格式
WHERE 表达式 [NOT] IN (子查询)
实践
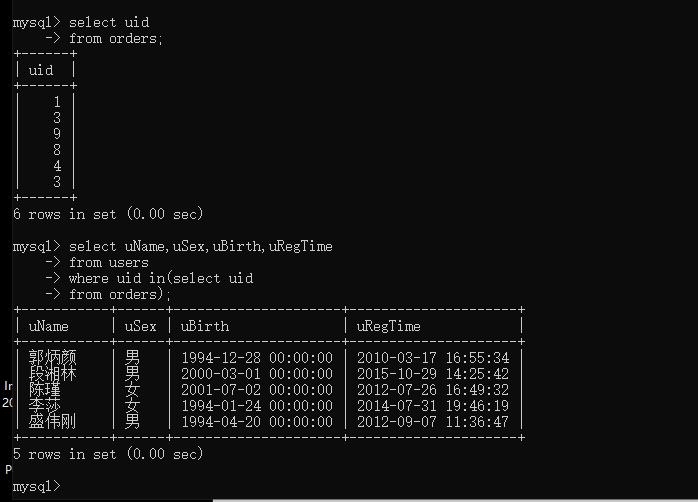
例如:查询已购物的会员信息,包括用户名,性别,出生年月和注册时间。
在这个查询中会涉及哪些数据源?
orders users
第一步在orders数据表中把uid查找出来
select uid
from orders;
第二步查询uid为1 3 9 8 4 3的用户信息
select uName,uSex,uBirth,uRegTime
from users
where uid in(1,3,9,8,4,3);
第三步合并以上查询语句
select uName,uSex,uBirth,uRegTime
from users
where uid in(select uid
from orders);
例如:查询消费金额在1000元以上的会员信息,包括用户名、性别、年龄和注册时间
在这个查询中会涉及哪些数据源?
orders users
第一步查询消费金额在1000元以上的会员信息
select uid
from orders
group by uid
having sum(ototal)>1000;
第二步查询uid为3 8的用户信息
select uName,uSex,uBirth,uRegTime
from users
where uid in(3,8);
第三步合并以上查询语句
select uName,uSex,uBirth,uRegTime
from users
where uid in(select uid
from orders
group by uid
having sum(ototal)>1000);














 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









