






一、一维数组的定义
1.1定义方式:
类型说明符 数组名 【常量表达式】
eg: float s[10000] int a[10]
注意:①类型说明符指类型的类型符(定义的若干个元素都为同样的数据类型,但空类型不被允许!)
②数组名应该符合标识符规则
③常量表达式为数值,应该至少有一个元素且此处为整型常量表达式
注意:允许使用变量来指定数组元素
eg : int n = 10; int a[n];
1.2 一维数组元素的引用
C语言中规定只能逐个引用数组元素而不能一次引用整个数组
表示形式: 数组名【下标】 (下标为该数组中元素的编号)
eg : a[0] a[7]
int a[i];
a[i] = 1;
a[i]= 7 ;
....
定义a[10],元素编号为a[0] a[1]......a[8] a[9]
此时,a[i]称为数组元素的引用,数据类型为整型
“【 】”含义:
对数组定义时:【 】为类型说明符,作用仅仅说明 a 是个数组
对数组引用时:【 】为下标运算符,优先级一级
注意:①数组当中在存储元素时具有连续性(a[0]a[1]...a[9]在存储时内存中无间断)
②数组元素存储时具有有序性(下标越小的地址越靠前,越大越靠后)
③数组在内存存储时具有单一性(所有元素的数据类型与所定义的数据类型相同)
特别提醒 !!!
数组的越界访问:
eg : int a[10];
a[-1] = 100;
a[15]= 100;
此时程序执行时数据类型符合运算规则,系统不报算,可执行以上语句
但a[-1]a[15]等类似元素内容并非定义的数组a[10]中的实际访问内容,因此将会改动其他地址所存的内容,在计算机运行过程中一旦造成越界访问将造成不可预估的后果!!!
注:
数组不可被整体引用 eg: a = 1000
原因:①不可确定到底将所需数值赋值给了a中哪个元素
②对于赋值运算符左右两边来说数据类型不匹配且不兼容,(左边为数组型,右边为整型)
如何判断该数组是什么类型?
去掉变量名即为类型名
③C语言当中数组的数组名是有值的,其值表示数组的首元素地址
// a < = > &a[ 0 ]
数组的初始化:
a[10] = {0,1,2,3,4,5,6,7,8,9}
> a[10] = {0,1,2,3,4,5,6,7,8,9,10} (初始化数值多于数组元素) 此时10的值将会出现越界访问!
> a[10]={1,2, 3,4,5} (初始化数值少于数组元素)
此时a[10]中后五个元素的初始化数值一定是0!
a[10] = {0} 数组所有元素的值都为0
> 套用初始化列表器以后,在使用数组的时候可以省略数组的维度 eg: a[ ] ={0,1,2,3,4}
动态计算a[ ]中元素的个数
int main(void)
{
int a[] = {1,2,3,4,5,6,7,8,9,0,1,53,2,3,54,6,5,7,74,74};
int i;
int len = sizeof(a) / sizeof(a[0]);
for(i = 0;i < len;++i)
{
printf("%d\n",a[i]);
}
return 0;
}注意:数组在定义时,如果使用变量来指定数组元素个数,则不能按照上述sizeof代码运行,而是使用循环来初始化
重要算法练习:
1.逆序 【算法复杂度:n】
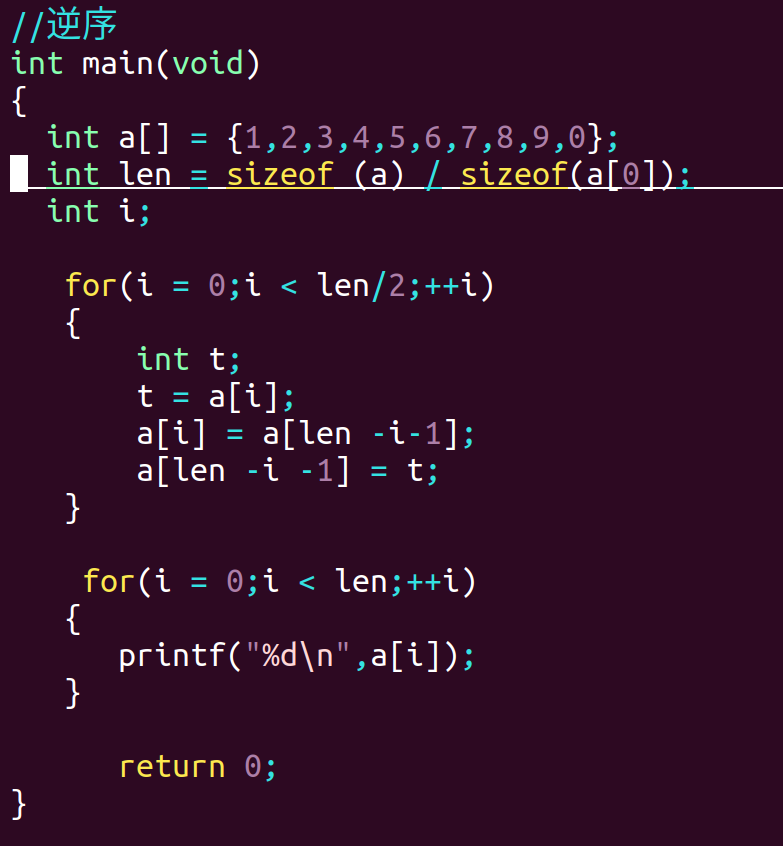
2. 排序
按照一定的大小关系进行排序,从小到大进行排序称为升序排序,从大到小称为降序排序,一般情况下无特殊说明默认为升序排序
2.1选择排序:
在合适的位置上放上合适的数 【算法复杂度:n^2】
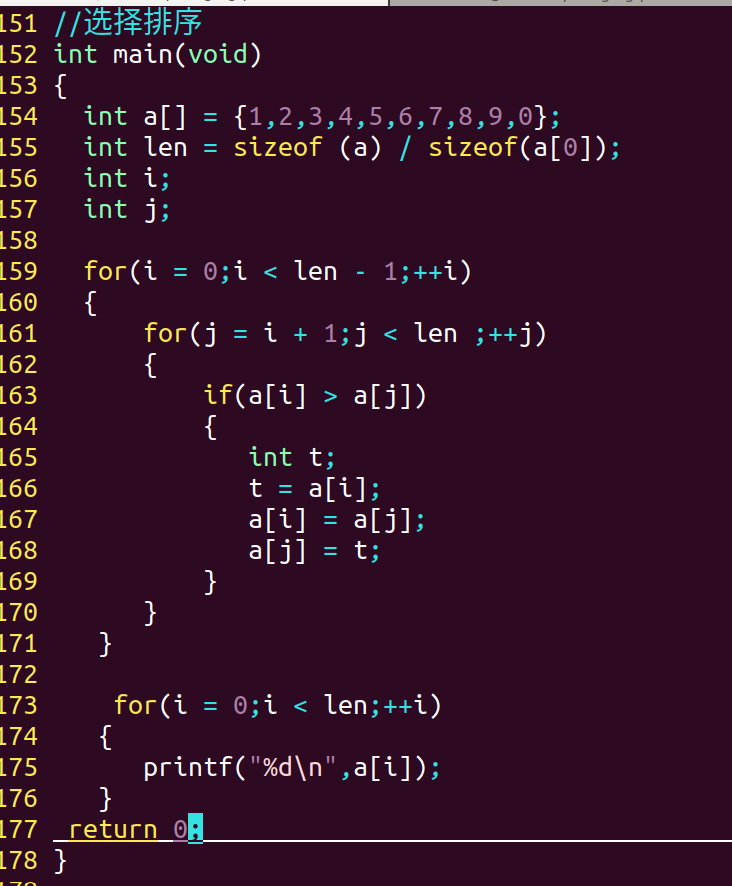
注意:①比较算法时二者必须能够进行比较才可使用
降序排序时,将163行代码改为: if(a[i] < a[j]); 即可
已知升序的情况下要整理为降序,有两种方法:
①改为降序排序 ②进行逆序
选择直接逆序效率更高(原因:逆序时间复杂度为n,降序时间复杂度为n^2)
2.2 冒泡排序:
相邻两个元素两两比较,小的放前,大的放后 【复杂度:n^2】
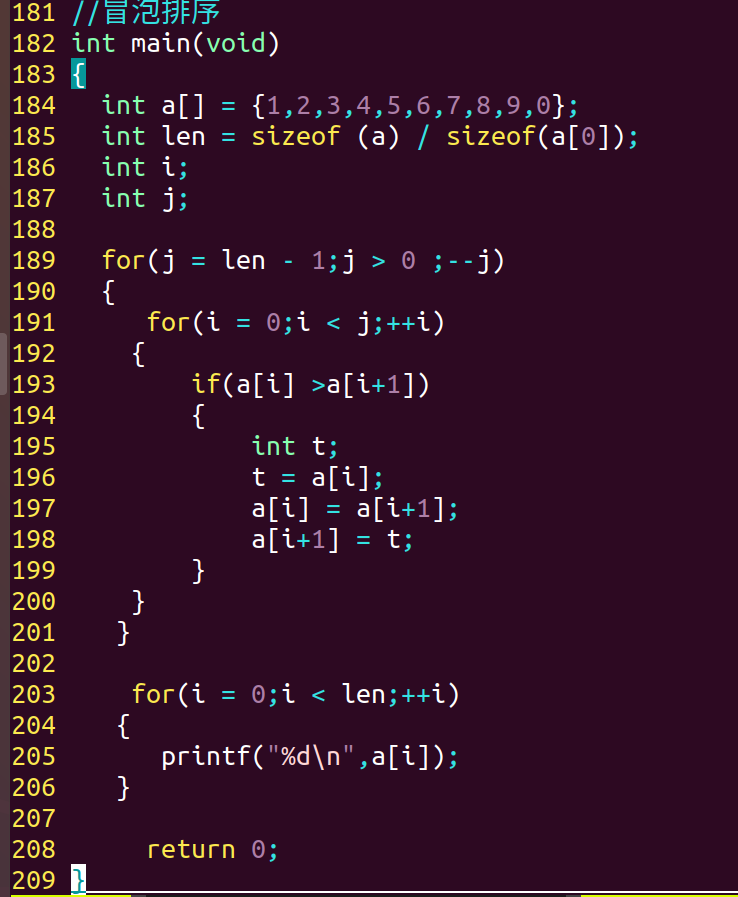
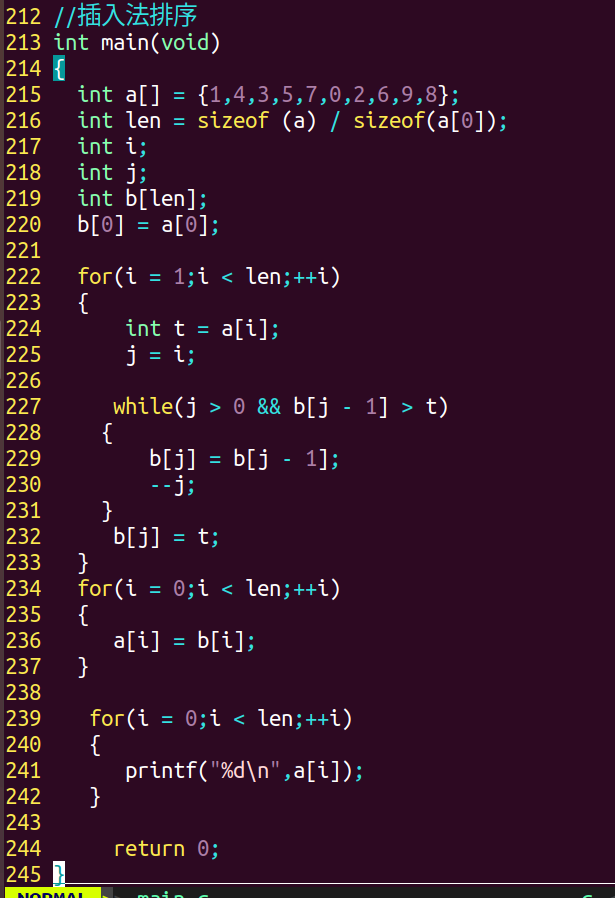
3.插入法排序: 【算法复杂度:n^2】
待排数组a[ ],创建数组b[ ],要求b数组长度大于等于a数组,即
int a[] = {......};
int len = sizeof (a) / sizeof(a[0]);
int b[len];
要求b数组当中的第一个元素与a数组当中的第一个元素相同,即
int b[len]; //此时b中为随机数
b[0] = a[0];
将a数组当中的元素逐个向b数组当中进行插入操作 ,每插入一个元素,要让 b数组当中的已插入元素成为一种有序序列,最终b数组中即为数组a中有序排列的复制品.
优化:(原地插入排序)
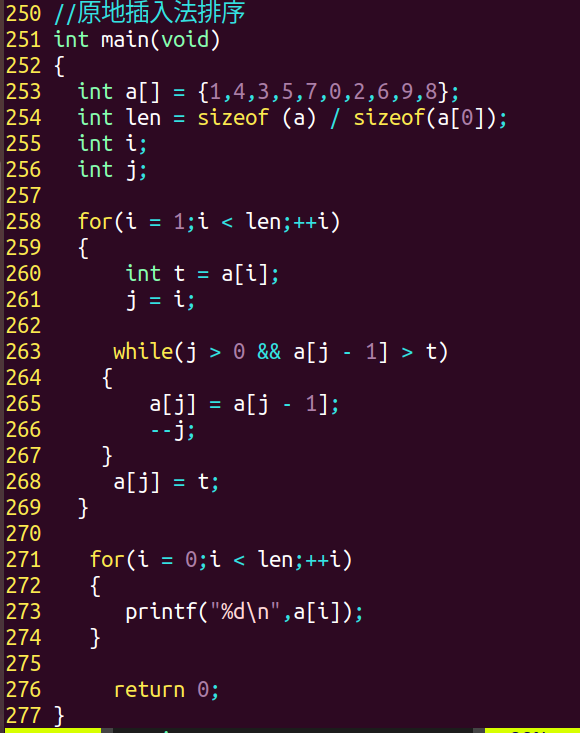
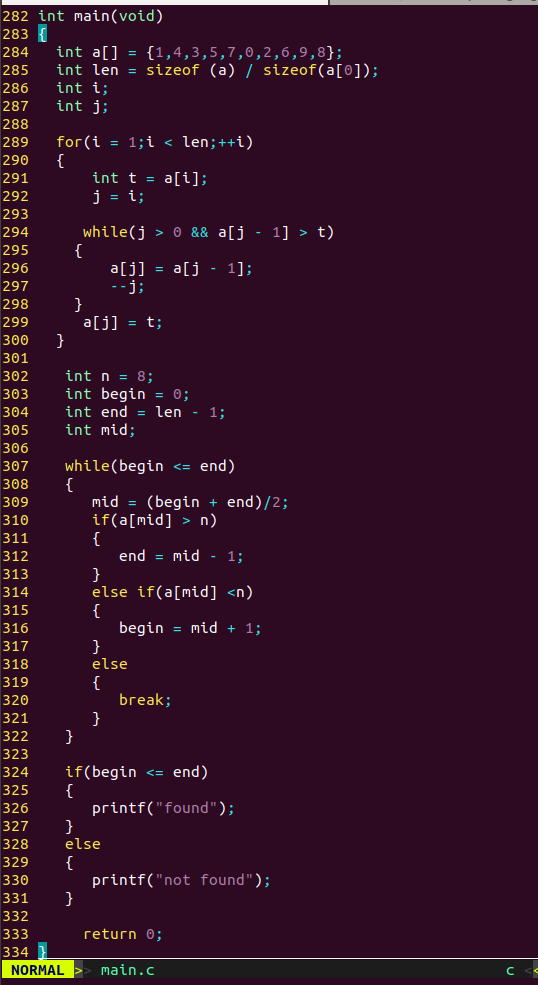
4.二分查找法 (找中间值) 【算法复杂度:log n】

















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









