






首先,我们需要打开命令行窗口,然后创建Scrapy项目。
打开命令行窗口的办法
(1)在桌面上 shift键+鼠标右键
(2) win搜索栏中搜索powellshell
打开命令行窗口后,在其中输入scrapy startproject scrapyDemo的命令即可创建一个名称为scrapyDemo的项目(项目名随意)。项目创建完成后,我们可以在pycharm中打开Scrapy项目。其中项目的目录结构如下:
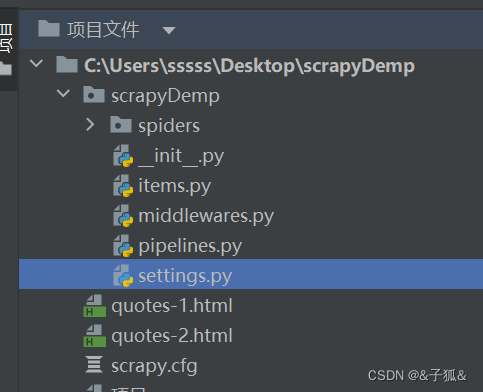
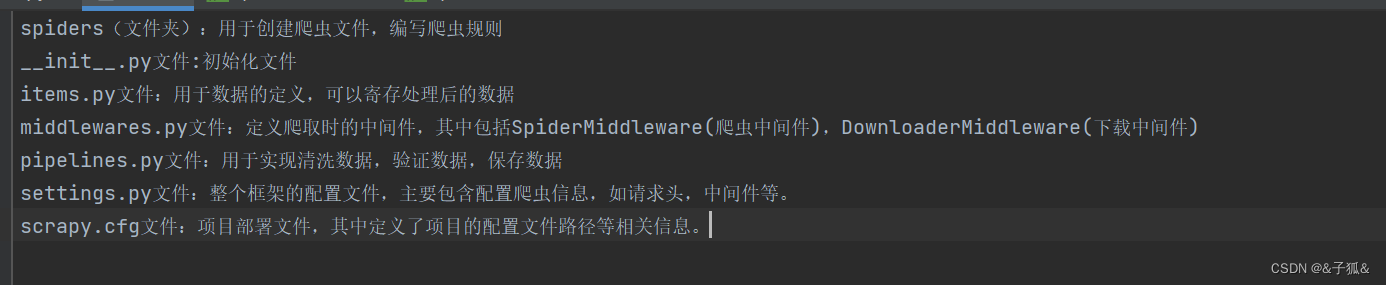
目录结构中的文件说明如下:
创建Scrapy项目后,我们就开始写爬虫。
在spiders(文件夹)中创建一个名称为crawl.py的爬虫文件,在该文件中输入爬虫的代码。
import scrapy #导入scrapy框架
class QuotesSpider(scrapy.Spider): #创建QuotesSpide类,并且该类继承自scrapy.Spider类
name = "quotes" #定义爬虫名称
def start_requests(self): #调用爬虫的方法
urls=[
'http://quotes.toscrape.com/page/1/', #设置爬取的网页地址(url)爬取两个网页
'http://quotes.toscrape.com/page/2/',
]
for url in urls: #循环,获取所有的网页地址
yield scrapy.Request(url=url,callback=self.parse) #发送网络请求
def parse(self, response): #处理结果
page=response.url.split("/")[-2] #获取页数
filename='quotes-%s.html'%page #根据页数设置文件名称
with open(filename,'wb') as f: #以写入文件的模式打开文件,如果没有该文件将创建该文件
f.write(response.body) #向文件中写入获取的html代码
self.log('Saved file %s'% filename) #输出保存文件的名称
测试:由于是在pycharm中输入的代码,所以在终端(Terminal)中输入scrapy crawl quotes,其中quotes是爬虫的名称,运行完成后,会在crawl.py文件的同级目录中自动生成两个.html文件。爬取的内容存在此处。















 9006
9006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









