






研究、应用与前景:基于事件的行人检测综述
链接: Research, Applications and Prospects of Event-Based Pedestrian Detection
目录
该文整理并分析了在自动驾驶领域基于事件的行人检测相关文献及数据集,深入探讨了当前的研究进展,是迄今为止较为全面且系统的综述。
一、引言
下图源自文章。

事件相机(也称“硅视网膜”)通过模仿哺乳动物视网膜的性能,每个像素独立运作,只对光强度的变化做出反应,因为事件相机只记录变化而不是全帧图像,所以它产生的数据量也更小,功耗更低,非常适合用于需要长期运行的设备。
事件相机能够在复杂、动态的环境中准确检测到行人,减少误报,并且在低光照或强光条件下依然能保持良好的表现,在行人检测中表现出色。
二、方法与分类
在第二章中,文章详细介绍了基于事件相机的行人检测(EB-PD)方法及其分类。
方法概述
其中:
- DVS: Dynamic Vision Sensors
- DIVAS: Digital Vision Sensors
- EVS: Event Vision Sensors
文章使用了IEEE Xplore数字图书馆、Springer、ScienceDirect、ACM和Google Scholar等数据库进行直接搜索,覆盖了2014年至2024年间的所有相关主题,总共收集了353篇文章。通过一定的标准,该文章最终筛选出了33篇文献。

三、分类与应用场景
大多数行人检测方法都集中在数据输入、预处理、特征工程和网络结构四个步骤上
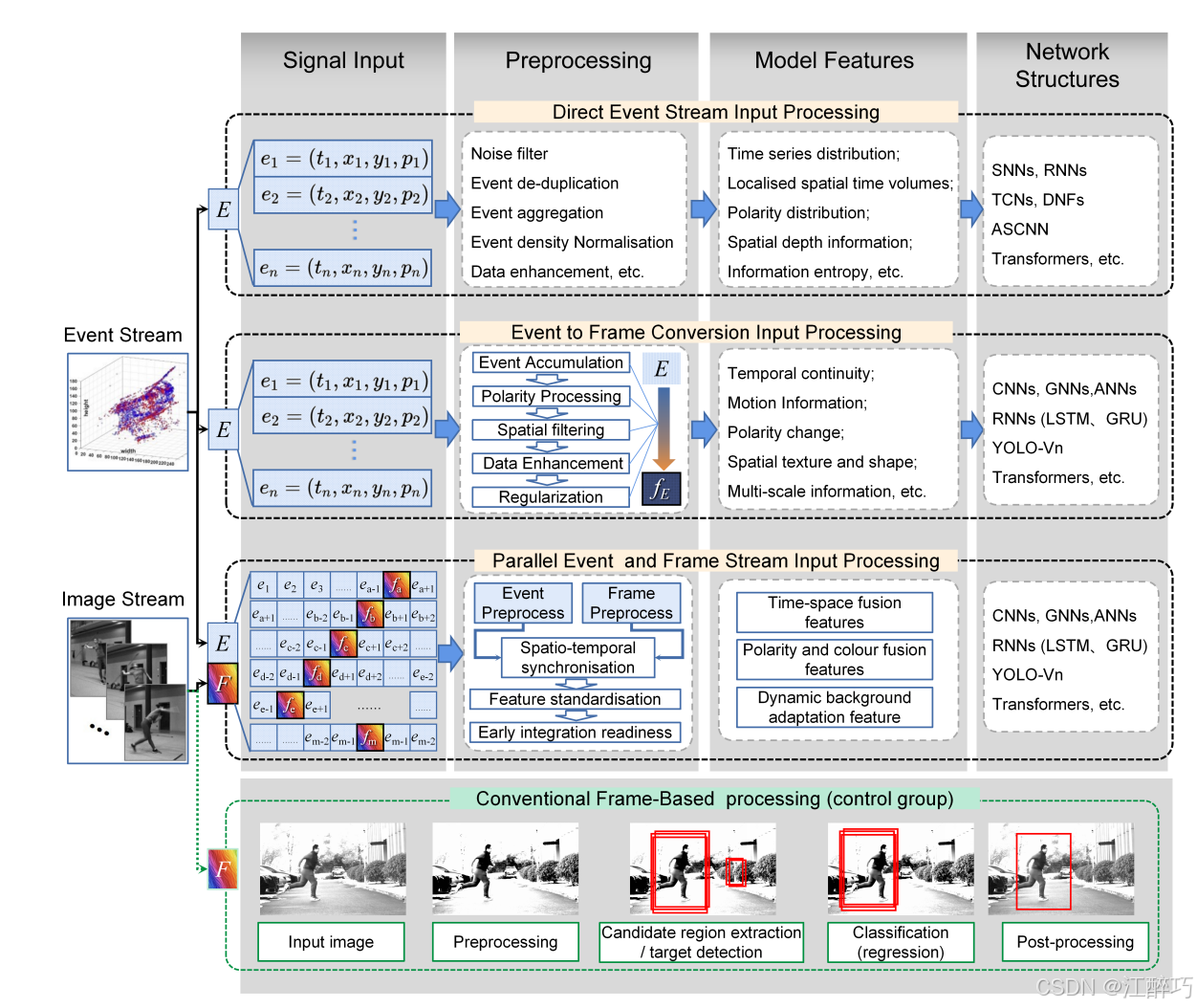
数据输入
- 直接事件流输入:利用事件相机捕捉到的高时间分辨率数据,直接输入事件流,以捕捉动态场景的细微变化。
- 事件到帧转换输入:将异步事件流转换为传统帧形式,以利用成熟的深度学习模型。这种方法适合需要利用空间信息的场景,但可能会丢失部分时间信息。
- 平行事件和帧流输入:结合事件流和帧流的优势,同时输入两种数据类型,实现时间和空间信息的综合处理。
预处理
- 预处理的目标是优化输入数据,使之适合特征提取和后续的模型处理。不同的数据输入方式对应不同的预处理步骤。
- 直接事件流输入:预处理包括噪声过滤、事件聚类、去重和密度归一化,旨在减少冗余数据并增强信号的时间精度。
- 事件到帧转换输入:主要通过事件整合、极性融合和空间连贯性增强,将异步事件流转换为连续帧,同时保持场景的空间一致性和运动信息。
- 平行事件和帧流输入:预处理集中于时间同步和特征标准化,确保事件流与帧流的时间一致性和数据均匀性,从而实现不同数据流的有效融合。
特征工程
- 特征工程是将预处理后的数据转化为能够表征场景的有用特征。
- 直接事件流输入:重点是提取时间特征,如时间动态和极性分布,通过捕捉局部的空间时间体积来理解场景的动态变化。
- 事件到帧转换输入:通过保持时间连续性,提取运动信息和空间纹理特征,以丰富模型对场景的理解。
- 平行事件和帧流输入:融合时间和空间特征,利用时间-空间结合的特征工程方法,生成包含运动和外观的强大表示,增强对复杂场景中行人动态的理解。
网络结构
- 模型网络部分讨论了如何设计和优化神经网络架构,以最大限度地利用特征工程提取到的信息。
- 常见的模型包括卷积神经网络(CNNs)和稀疏卷积网络(SNNs)。文章介绍了几种常用的网络架构,如YOLOv7、YOLOv5、YOLOv3和YOLO-tiny以及改进的模型如GA-BP神经网络和空间注意力模型(SAM)。
- 不同网络架构被选择用于处理不同类型的输入数据,结合输入数据的特性,模型架构进行了定制优化,以提高行人检测的精度和计算效率。
四、协同数据输入方法
直接事件流输入处理
这一部分介绍了如何处理事件相机生成的原始事件流数据。处理步骤包括噪声过滤、时间聚类、事件去重和密度归一化。这些步骤旨在清理并组织事件数据,使其更适合特征提取和后续的行人检测。通过这些预处理,事件流被优化为更有意义的特征输入,提高了行人检测的准确性。
事件流到事件帧输入处理
本部分讨论了将事件流转换为帧序列的方法,这种转换使得事件数据可以与传统基于帧的深度学习模型兼容。文章介绍了事件整合、极性融合、空间连贯性增强和帧间连续性等技术,通过这些处理步骤,将异步的事件流数据组织为具有时间和空间一致性的帧输入,从而使得复杂的行人检测任务得以实现。
平行事件与帧流输入处理
在这一部分,文章探讨了如何结合事件流和帧流的优势,实现两种数据流的时间同步和特征融合。通过同时处理事件流和帧流,模型能够综合利用事件流的时间分辨率和帧流的空间信息,从而在行人检测中取得更好的性能。文章还详细说明了时间同步、特征提取和数据融合的具体实现方法,展示了这一协同数据输入方法的有效性。
本章个人评述:本章详细阐述了如何通过处理和整合事件流与帧流来提高行人检测的准确性和效率。协同数据输入方法提供了一种有效的解决方案,使得基于事件相机的行人检测技术更具实用性和适应性。在以后实际应用中可以进一步优化这些技术,以应对更加多样化的场景需求。
五、预测模型
- 这一章主要讨论了在基于事件的行人检测(EB-PD)中,如何利用不同的预测模型来提高检测性能。
-
模型分类与比较
文章对不同的预测模型进行了分类和比较
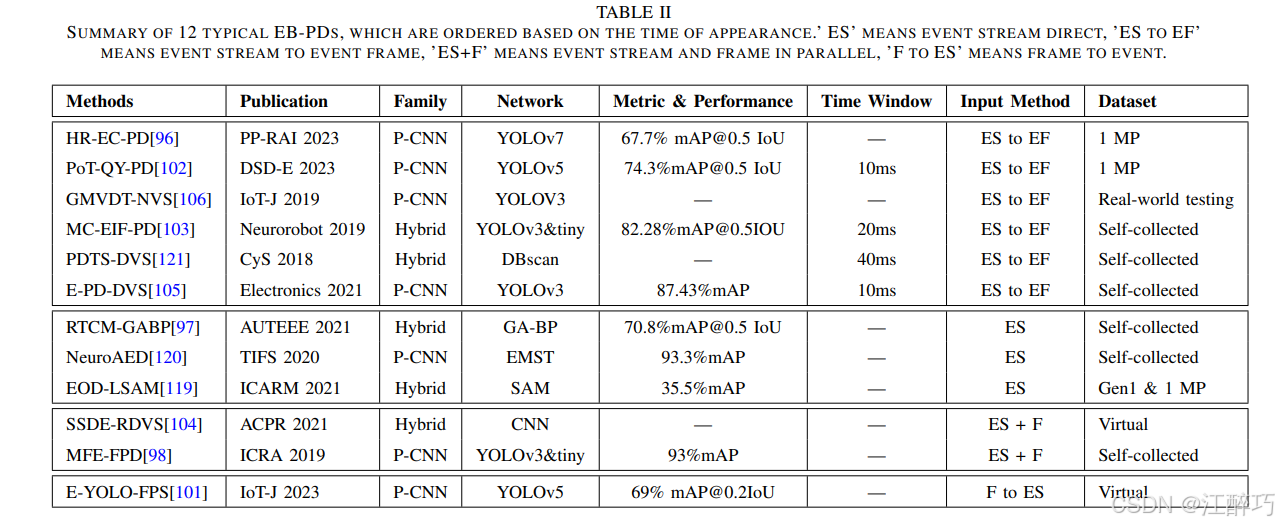 重点分析了这些模型在处理事件数据和帧数据时的表现差异。模型的选择通常取决于数据输入的方式以及应用场景的需求。
重点分析了这些模型在处理事件数据和帧数据时的表现差异。模型的选择通常取决于数据输入的方式以及应用场景的需求。 -
传统模型的局限性
文章指出,直接将事件流应用于传统的目标检测算法通常是不可行的。许多传统模型无法充分利用事件数据的高时间分辨率和低延迟特性,导致检测精度和实时性不足。为此,研究者们提出了一些新的模型架构和方法,以更好地适应事件数据的特性。 -
优化模型的应用
文章讨论了如何通过优化模型架构来提升检测效果。例如,使用YOLO系列模型(如YOLOv3、YOLOv5)来处理事件和帧数据的结合,利用其在实时检测中的优势。文章还介绍了一些改进的模型,如遗传算法-反向传播(GA-BP)神经网络和空间注意力模型(SAM),这些模型在特定场景下表现出色,通过优化特征提取和模型参数,提高了检测精度和计算效率。 -
应用场景与性能提升
文章最后探讨了这些预测模型在实际应用中的表现,尤其是在动态和复杂环境下的行人检测任务中。通过使用自收集的数据集和标准化测试方法,文章展示了如何根据具体场景需求,选择合适的模型以达到最佳效果。
-
本章个人评述:这一章详细分析了不同预测模型的优缺点,并提供了多种优化方案,这对于从事该领域研究的人员来说具有重要的参考价值。一方面,文章清楚地指出了传统目标检测模型在处理事件数据时的局限性,提醒研究者在设计和选择模型时,要充分考虑事件数据的特性。另一方面,文章介绍了一些先进的优化模型,如YOLO系列和GA-BP神经网络,展示了这些模型在提高检测精度和实时性方面的潜力。这些内容对于理解如何在复杂和动态环境中有效地进行行人检测,提供了有价值的指导。
六、数据集
文章详细介绍了几种关键的数据集,这些数据集专门用于或可以用于事件相机的行人检测任务。这些数据集包括PEDRo、PROPHESEE GEN1、Henri、PAFBenchmark、FJUPD、DVS-OUTLAB、DHP19、以及NU-AIR。文章还对各个数据集的采集过程、数据类型、分辨率、数据量以及采集环境进行了详细描述。例如,PEDRo数据集涵盖了不同光照条件下的行人数据,而NU-AIR数据集则使用了无人机捕捉的城市场景数据。
七、结论
本文的结论部分总结了基于事件相机的行人检测技术(EB-PD)的研究进展与应用前景。文章指出,事件相机作为一种新兴的视觉传感技术,具有高时间分辨率、低功耗、宽动态范围和抗运动模糊等优势,使其在行人检测中表现出色,尤其是在自动驾驶和智能监控等对实时性和精度要求较高的应用领域。
尽管EB-PD技术已经取得了显著进展,但文章也强调了当前研究面临的诸多挑战,如数据稀疏性与不平衡性、模型泛化能力不足、实时性和计算资源限制、多模态数据融合的困难,以及缺乏标准化评价体系。文章建议,未来的研究应致力于通过数据增强、自适应学习、硬件加速、创新的多模态融合方法以及建立标准化的数据集和评价体系来克服这些挑战,从而推动EB-PD技术的发展。
本文个人阅读评述:本文对基于事件相机的行人检测技术进行了系统性的综述,从数据输入、预处理、特征提取到模型设计,以及相关的数据集和评价指标都进行了详细探讨。通过这篇文章,从事基于事件的行人检测的研究人员应该能对优势和应用场景有了更全面的理解,特别是在高时间分辨率、低功耗和抗运动模糊方面的独特优势。文章不仅展示了现有技术的成就,也坦率地指出了当前研究的不足之处,尤其是在数据稀疏性、模型泛化能力和多模态数据融合等方面。这些挑战对实际应用提出了更高的要求,也为未来的研究指明了方向。文章在提出这些挑战的同时,还提供了可能的解决方案和未来的研究方向,这对于从事该领域研究的人员具有很强的指导意义。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









