






一、SparkRDD
rdd的创建用法及实例
1. 创建RDD:
val lz_rdd = spark.sparkContext.parallelize(Seq(1, 2, 3, 4, 5))
2. 显示RDD中的元素:
lz_rdd.collect().foreach(println) 
3. 对RDD中的每个元素应用函数:
val lz_mappedRDD = lz_rdd.map(x => x * 2)
4. 对RDD中的元素进行过滤:
val lz_filteredRDD = lz_rdd.filter(x => x % 2 == 0)
5. 对RDD中的元素进行聚合:
val lz_sum = lz_rdd.reduce((x, y) => x + y)
6. 对RDD中的元素进行排序:
val lz_sortedRDD = lz_rdd.sortBy(x => x, ascending = false)
7. 对RDD中的每个分区应用函数:
val lz_mappedPartitionsRDD = lz_rdd.mapPartitions(iter => iter.map(_ * 2))
8. 对两个RDD进行笛卡尔积操作:
val lz_cartesianRDD = lz_rdd1.cartesian(rdd2)9. 计算RDD中元素的数量:
val lz_count = lz_rdd.count()
10. 对RDD中的元素进行去重:
val lz_distinctRDD = lz_rdd.distinct()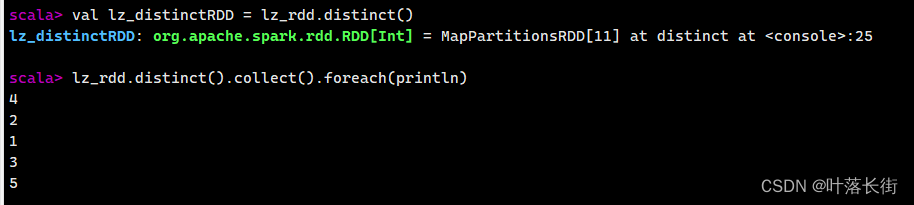
11. 对RDD中的元素进行采样:
val lz_sampledRDD = lz_rdd.sample(false, 0.5)
12. 对RDD中的元素进行分组:
val lz_groupedRDD = lz_rdd.groupBy(x => x % 2)
13. 对RDD中的元素进行缓存:
lz_rdd.cache()14. 将RDD保存到文件:
lz_rdd.saveAsTextFile("path/to/output")二、SparkSQL
DataFrame的创建用法及实例
1. 创建DataFrame:
val lz_df = spark.createDataFrame(Seq(
(1, "Alice"),
(2, "Bob"),
(3, "Charlie")
)).toDF("id", "name")
2. 显示DataFrame的结构:
lz_df.printSchema()
3. 显示DataFrame的内容:
lz_df.show()
4. 注册DataFrame为临时视图:
lz_df.createOrReplaceTempView("people")
5. 执行SQL查询:
val lz_result = spark.sql("SELECT * FROM people WHERE id = 1")
6. DataFrame转换操作:
val lz_mappedDF = lz_df.selectExpr("id", "UPPER(name) as name_upper")
7. DataFrame过滤操作:
val lz_filteredDF = lz_df.where("id > 1")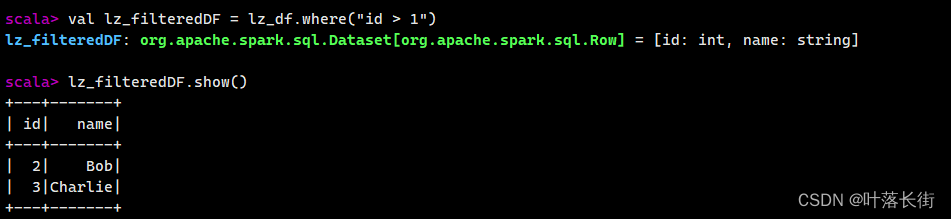
8. 对DataFrame进行分组聚合:
val lz_aggregatedDF = lz_df.groupBy("id").agg(sum("count"))9. DataFrame列的重命名:
val lz_renamedDF = lz_df.withColumnRenamed("name", "full_name")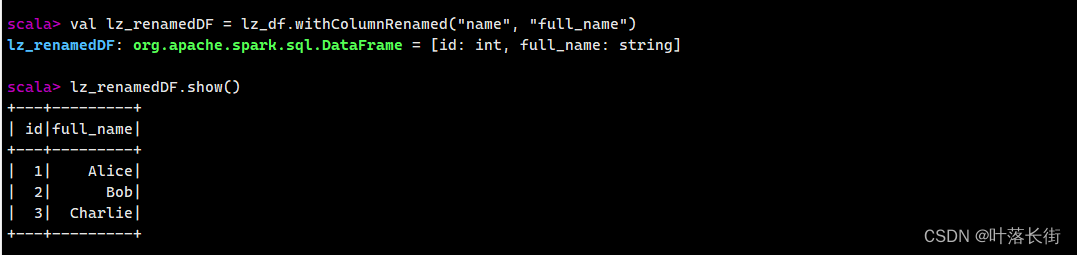
10. DataFrame的连接操作:
val lz_joinedDF = lz_df1.join(lz_df2, "key")11. DataFrame的交集操作:
val intersectedDF = df1.intersect(df2)12. DataFrame的并集操作:
val lz_unionedDF = lz_df1.union(lz_df2)13. DataFrame的差集操作:
val lz_subtractedDF = lz_df1.except(lz_df2)14. DataFrame的聚合操作:
val lz_aggregatedDF = lz_df.groupBy("key").agg(count("value"))Spark是一个快速、通用、可扩展的大数据处理框架,具有以下特点和优势:
1. **速度快**:Spark通过内存计算和优化的执行计划实现了比传统MapReduce更快的计算速度,尤其适用于迭代算法和交互式查询。
2. **通用性**:Spark提供了统一的编程模型,支持多种语言(如Scala、Java、Python、R和SQL),并且能够处理各种类型的数据,包括结构化数据、半结构化数据和非结构化数据。
3. **可扩展性**:Spark可以轻松地扩展到大规模集群,并且能够在数千台计算机上运行,处理PB级别的数据。
4. **内置库丰富**:Spark提供了丰富的内置库,包括Spark SQL、Spark Streaming、MLlib(机器学习库)和GraphX(图处理库),可以满足各种大数据处理需求。
5. **容错性**:Spark通过RDD(弹性分布式数据集)实现了容错性,可以自动恢复计算中断,并且可以在数据丢失的情况下重新计算丢失的数据。
6. **支持多种数据源**:Spark支持从多种数据源读取数据,包括HDFS、HBase、JDBC、Cassandra、Kafka等,并且可以将处理结果写入到多种存储系统中。
7. **生态系统丰富**:Spark拥有庞大的开源社区和丰富的生态系统,有大量的第三方库和工具可以扩展其功能和应用场景。
综上所述,Spark是一个强大的大数据处理框架,具有快速、通用、可扩展和容错等特点,适用于各种大数据处理和分析任务。















 1098
1098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









