






目录
设置标签大小和位置
代码
# Matplotlib可以使用
# plt.xlabel(xlabel,size,rotation,horizontalalignment,verticalalignmnet)
# 函数对坐标轴进行设置其中:
# label:设置标签的内容
# rotation:设置标签的旋转度
# size:设置标签的大小
# horizontanlaignment:设置标签的左右位置,分别为center,right left
# verticalalignmnet:设置标签的上喜爱位置,分为center,bottom,top
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = np.arange(0, 20, 1)
y1 = (x - 9) ** 2 + 1
y2 = (x + 5) ** 2 + 8
plt.plot(x, y1, linestyle="-.", color='y', linewidth=5.0,label='01图例')
plt.plot(x, y2, marker='*', color='g', markersize=10,label='02图例')
plt.xlim(0, 20)
plt.ylim(0, 400)
# 给x轴加上标签
plt.xlabel('x轴', size=15)
# 给y轴加上标签
plt.ylabel("y轴", size=15,rotation=90,
# horizontalalignment='right',
# verticalalignment='bottom'
)
plt.title("标题")
# 设置图例
plt.legend(loc=0,fontsize='large',edgecolor='blue')
plt.show()
效果:
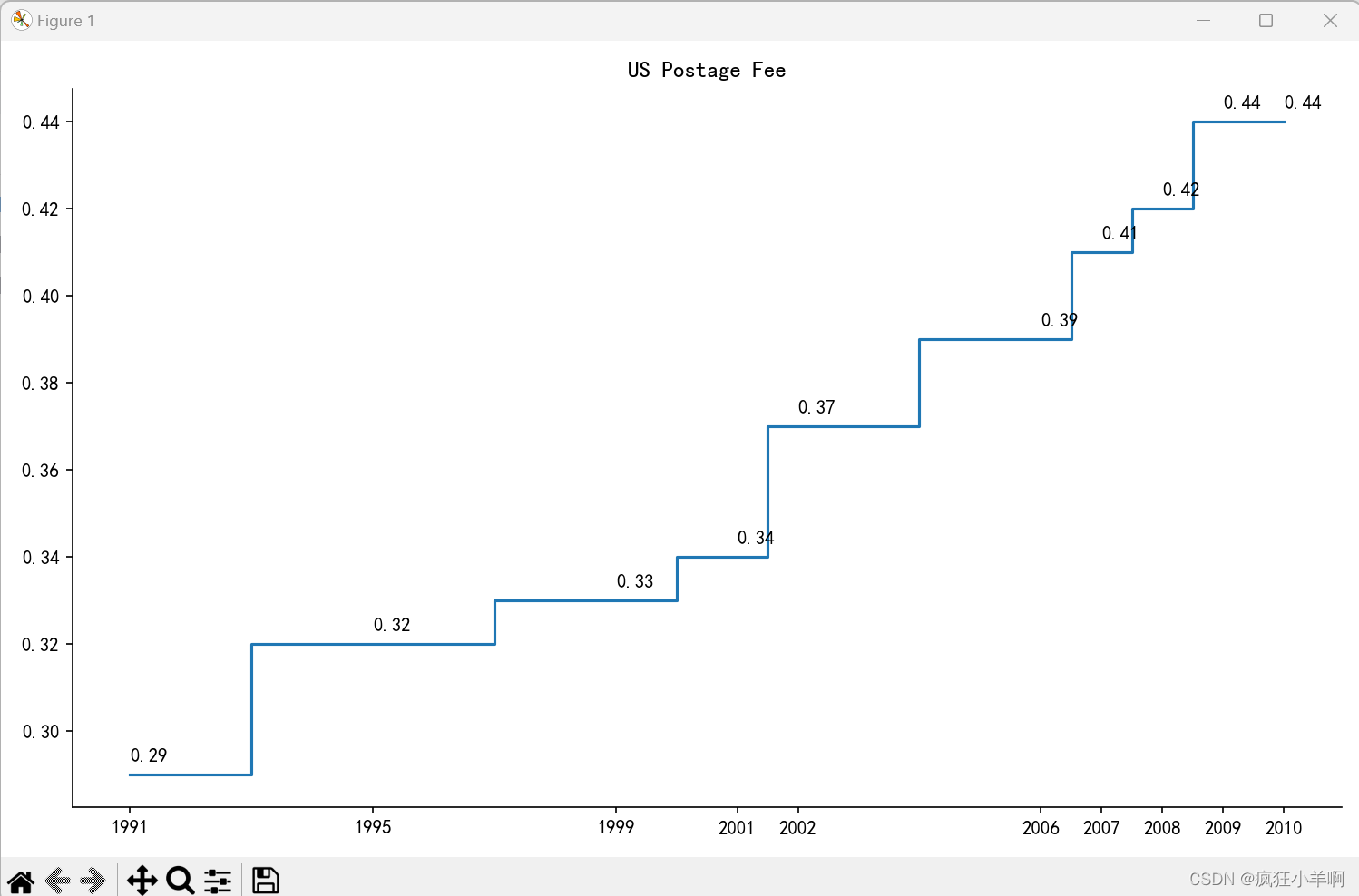
美国邮费阶梯图
文件
代码
import pandas as pd
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
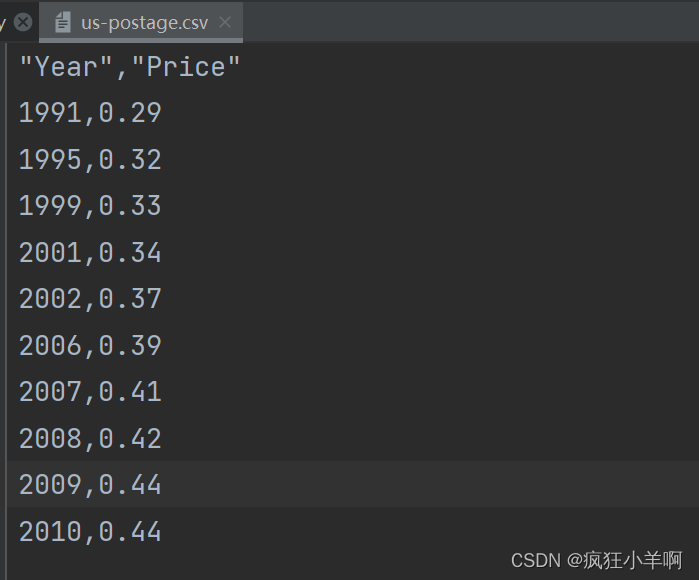
postage = pd.read_csv(r"us-postage.csv")
fig, ax = plt.subplots(figsize=(10, 6)) # 宽和高
ax.step(postage["Year"], postage["Price"], where="mid")
ax.set_title("US Postage Fee")
ax.set_xticks([i for i in postage["Year"]])
ax.spines["top"].set_visible(False)
# ax.spines["bottom"].set_visible(False)
# ax.spines["left"].set_visible(False)
ax.spines["right"].set_visible(False)
for i, j in zip(postage["Year"], postage["Price"]):
ax.text(x=i, y=j+0.003, s=j)
# 这段代码使用了matplotlib库中的text函数在坐标系ax上添加了一些文本标签。
# 通过使用zip函数,将postage["Year"]和postage["Price"]两个数组进行了迭代,
# 得到每个数据点的横坐标i和纵坐标j。
# 然后,通过调用ax.text函数,在每个数据点的位置上添加了一个文本标签。
# 其中,x=i表示文本标签的横坐标为i,y=j+0.003表示文本标签的纵坐标为j+0.003,s=j表示文本标签的内容为j。
# 通过这段代码,可以在图形上显示每个数据点的具体数值。
fig.set_tight_layout(tight=True)
plt.show()效果
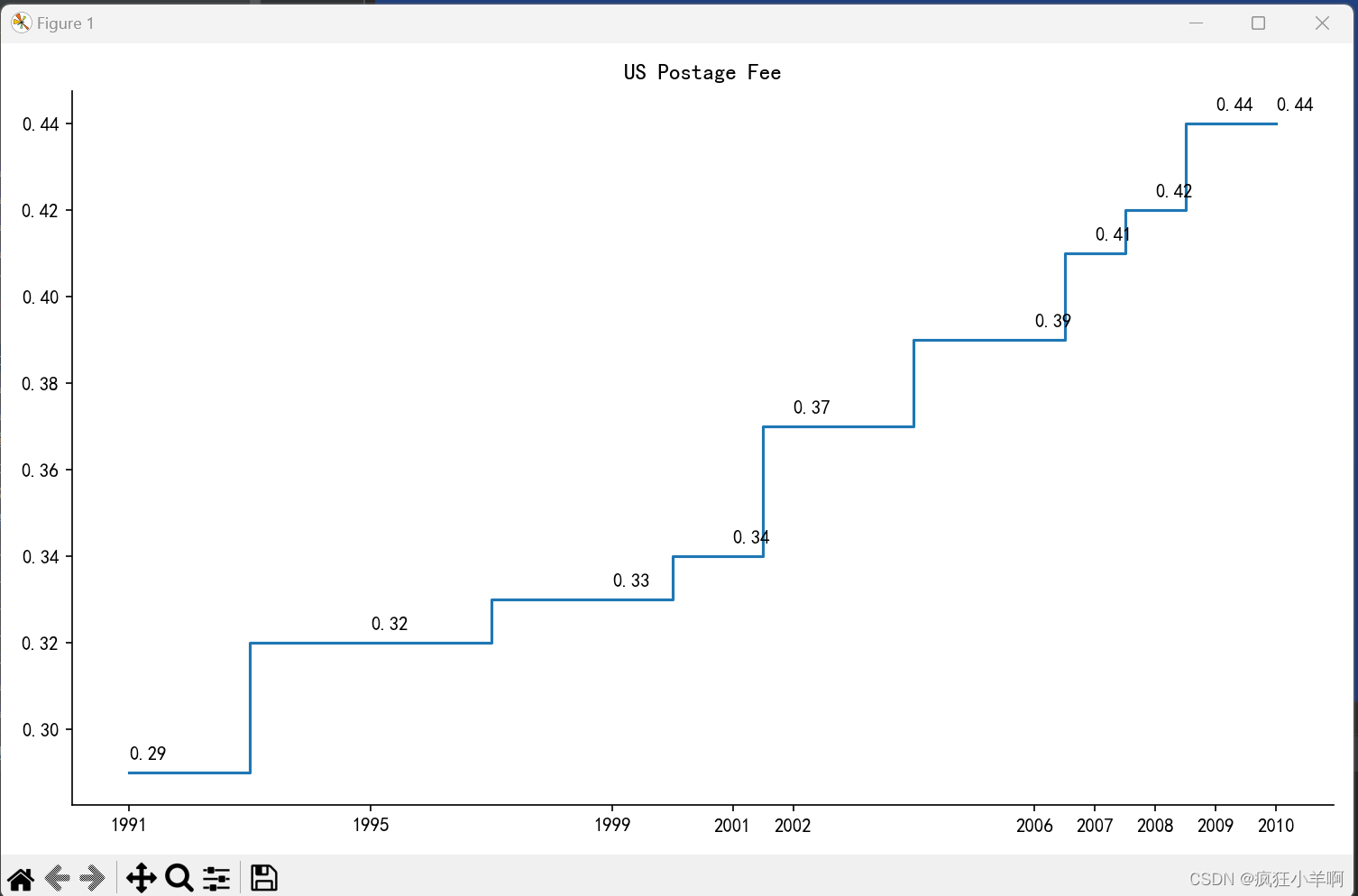
阶梯图和折线图(两个子图)
文件:
代码:
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据文件
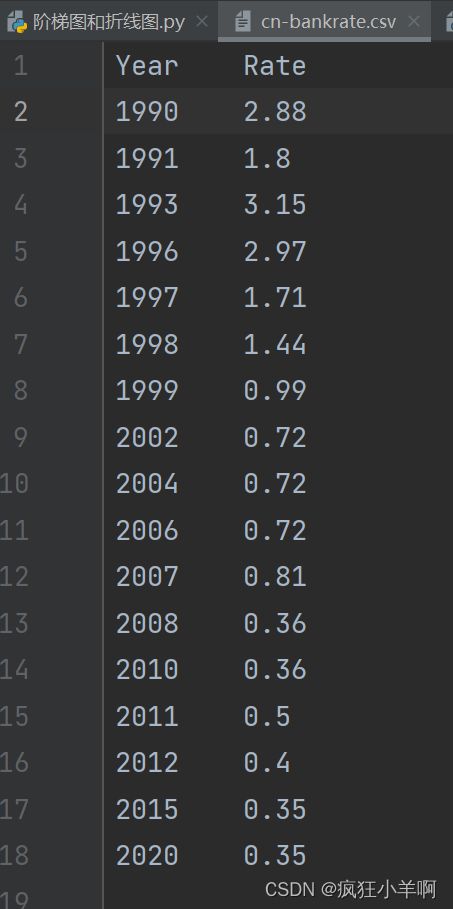
data = pd.read_csv('cn-bankrate.csv', sep='\t')
# 提取年份和利率列
# 提取了"Year"和"Rate"两列的数据,
# 分别存储在years和rates中
years = data['Year']
rates = data['Rate']
# 创建画布和子图区域
# 用plt.subplots()函数创建了一个14x10大小的画布,
# 并在该画布上创建了一个2x2的子图区域
fig, axs = plt.subplots(2, 2, figsize=(14, 10))
# 正常显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制阶梯图
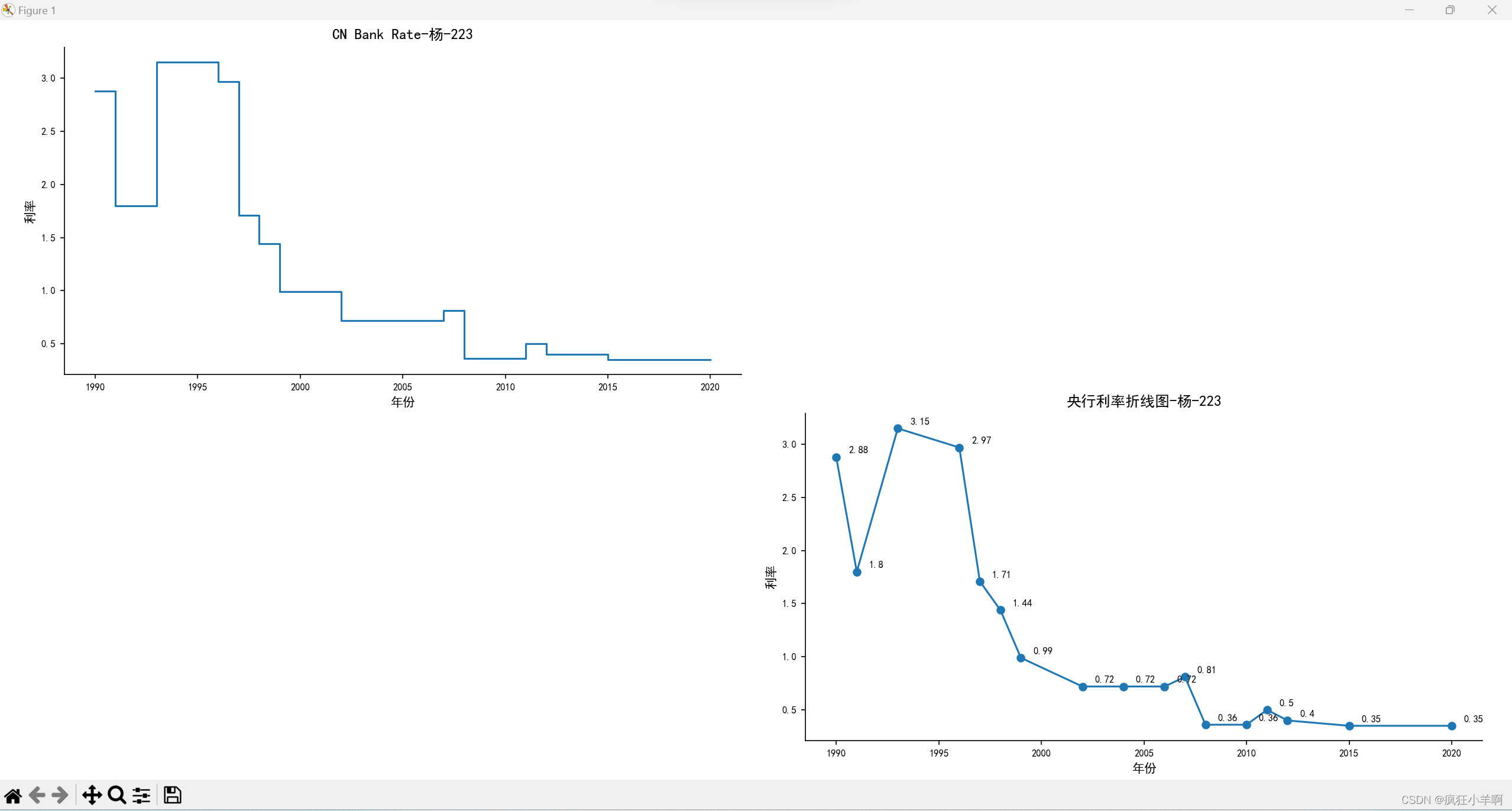
# 用axs[0, 0].step()函数绘制了央行利率的阶梯图。
# where='post'参数指定了阶梯的位置在后部
axs[0, 0].step(years, rates, where='post')
axs[0, 0].set_title('CN Bank Rate-杨-223', fontsize=12)
axs[0, 0].set_xlabel('年份', fontsize=10)
axs[0, 0].set_ylabel('利率', fontsize=10)
# 用axs[0, 0].tick_params()方法设置了子图的刻度标签的字号
# axis='both' 参数可以一次性设置子图中 x 轴和 y 轴的刻度线和刻度标签,避免重复的代码。
axs[0, 0].tick_params(axis='both', labelsize=8)
# axs[0, 0].spines方法
# 隐藏了第一个子图的右侧和上部的边框线,
axs[0, 0].spines['right'].set_visible(False)
axs[0, 0].spines['top'].set_visible(False)
# 设置刻度线的位置,使其位于底部和左侧。
axs[0, 0].xaxis.set_ticks_position('bottom')
axs[0, 0].yaxis.set_ticks_position('left')
# 绘制折线图
axs[1, 1].plot(years, rates, marker='o')
axs[1, 1].set_title('央行利率折线图-杨-223', fontsize=12)
axs[1, 1].set_xlabel('年份', fontsize=10)
axs[1, 1].set_ylabel('利率', fontsize=10)
# axs[1, 1].tick_params()方法设置第二个子图的刻度标签的字号
axs[1, 1].tick_params(axis='both', labelsize=8)
axs[1, 1].spines['right'].set_visible(False)
axs[1, 1].spines['top'].set_visible(False)
axs[1, 1].xaxis.set_ticks_position('bottom')
axs[1, 1].yaxis.set_ticks_position('left')
# 标注关键点
# 使用axs[0, 0].annotate()方法为阶梯图中的关键点添加利率值的注释
for i in range(len(years)):
axs[1, 1].annotate(rates[i],(years.iloc[i], rates.iloc[i]),
xytext=(10, 3), textcoords='offset points', fontsize=8)
# 隐藏无用子图
# fig.delaxes()方法
# 隐藏第一行第二列和第二行第一列的子图
fig.delaxes(axs[0, 1])
fig.delaxes(axs[1, 0])
# 用plt.tight_layout()方法自动调整子图的布局
plt.tight_layout()
# 显示绘制
plt.show()效果:
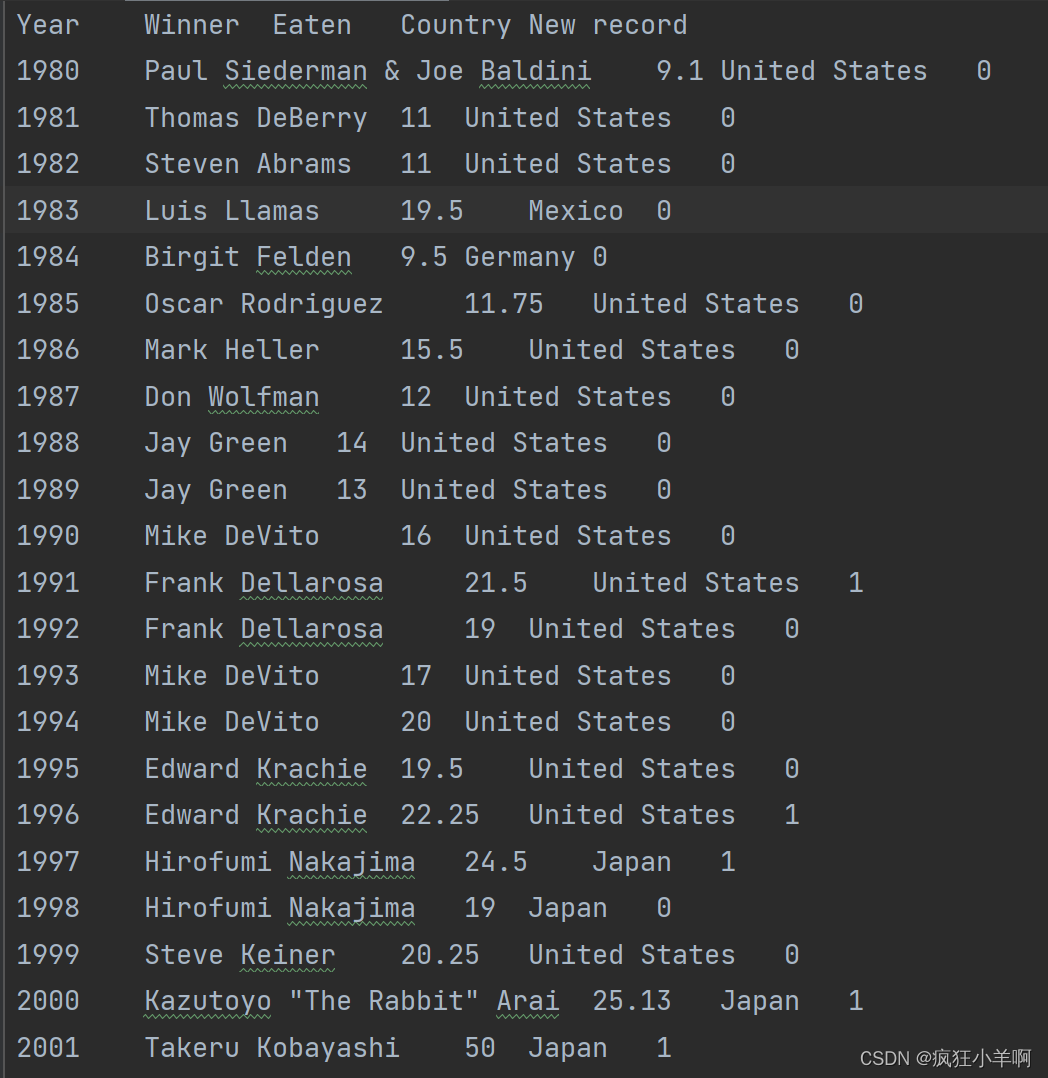
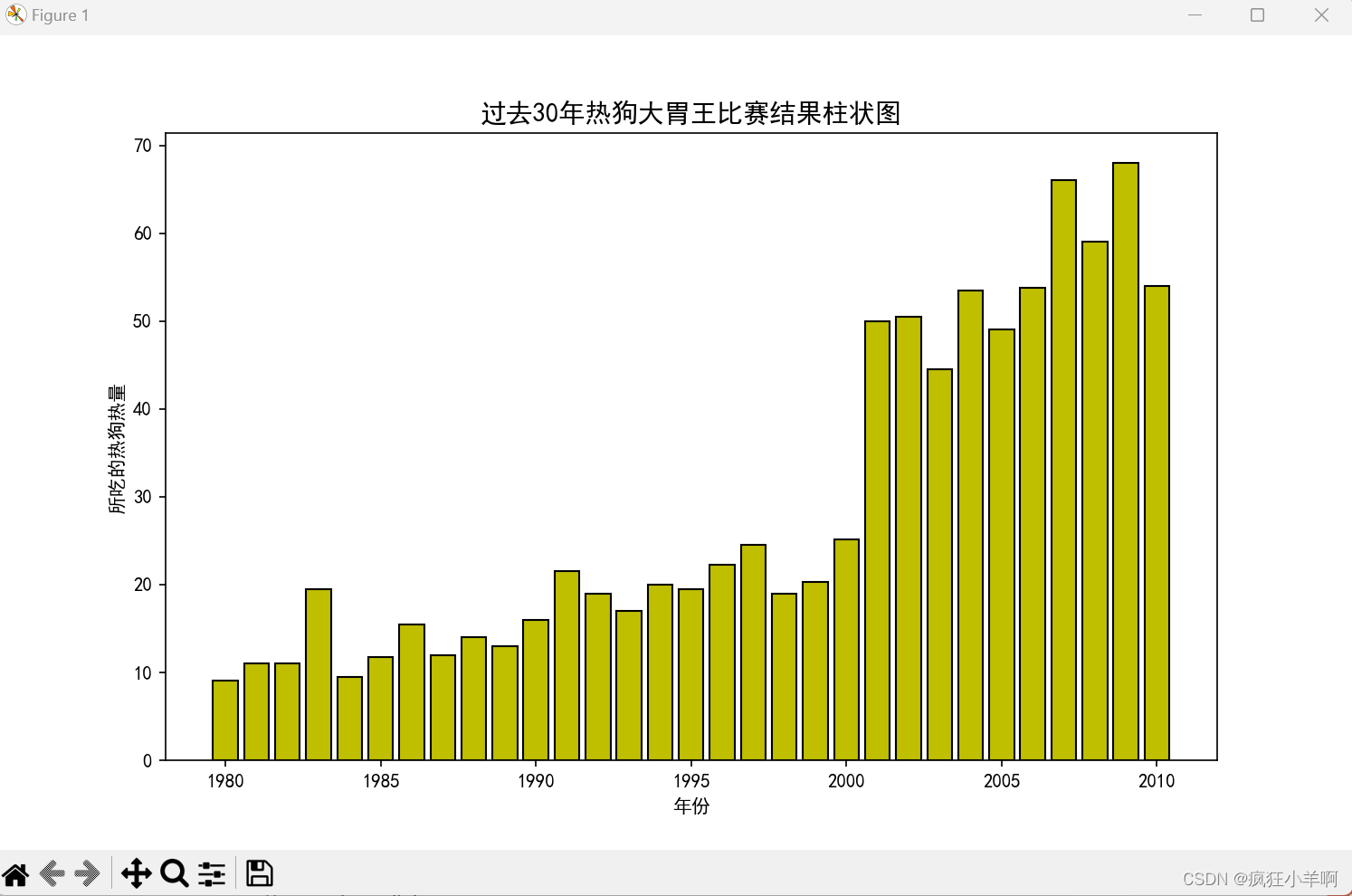
热狗大胃王比赛柱状图
文件:
代码:
import pandas as pd
from matplotlib import pyplot as plt
hotdog = pd.read_csv("hot-dog-contest-winners.csv",sep='\t')
fig, ax = plt.subplots(figsize=(10, 6))
# 显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x_data = hotdog['Year']
y_data = hotdog['Eaten']
plt.bar(x=x_data, height=y_data, color='y', edgecolor='k') # edgecolor='k'表示柱状图的边框颜色为黑色(black)
ax.set_title('过去30年热狗大胃王比赛结果柱状图', fontproperties='SimHei', fontsize=14)
ax.set_xlabel('年份')
ax.set_ylabel('所吃的热狗热量')
plt.show()效果:
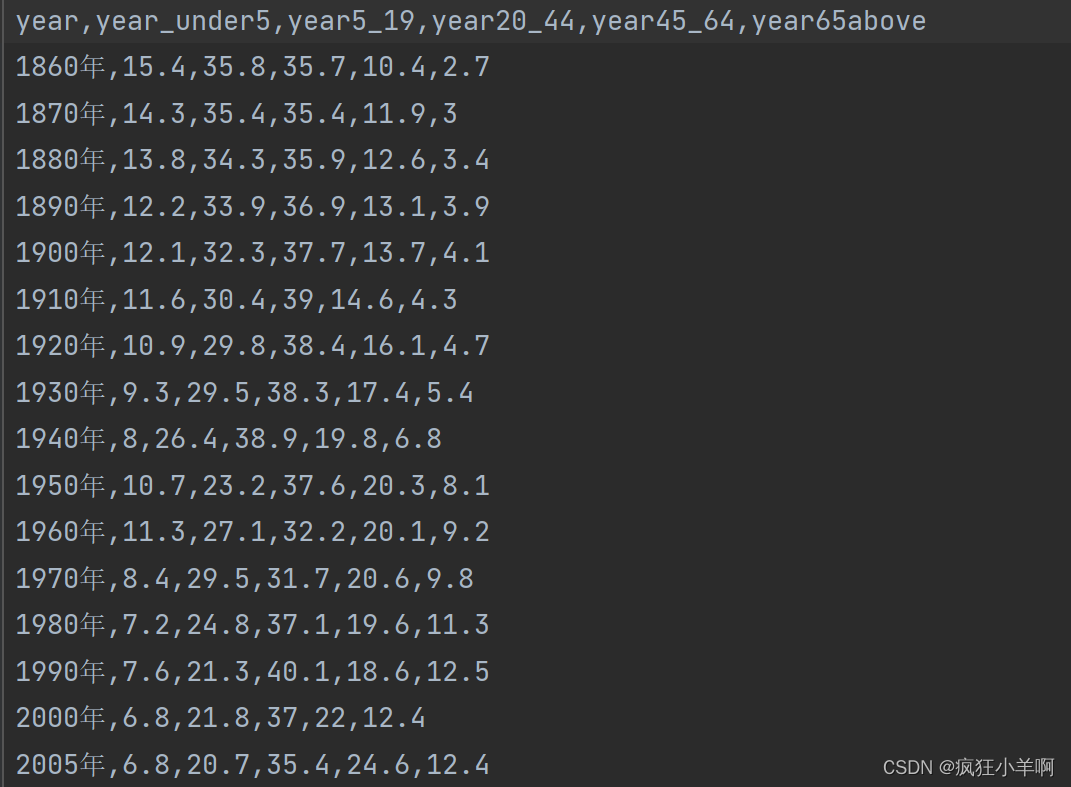
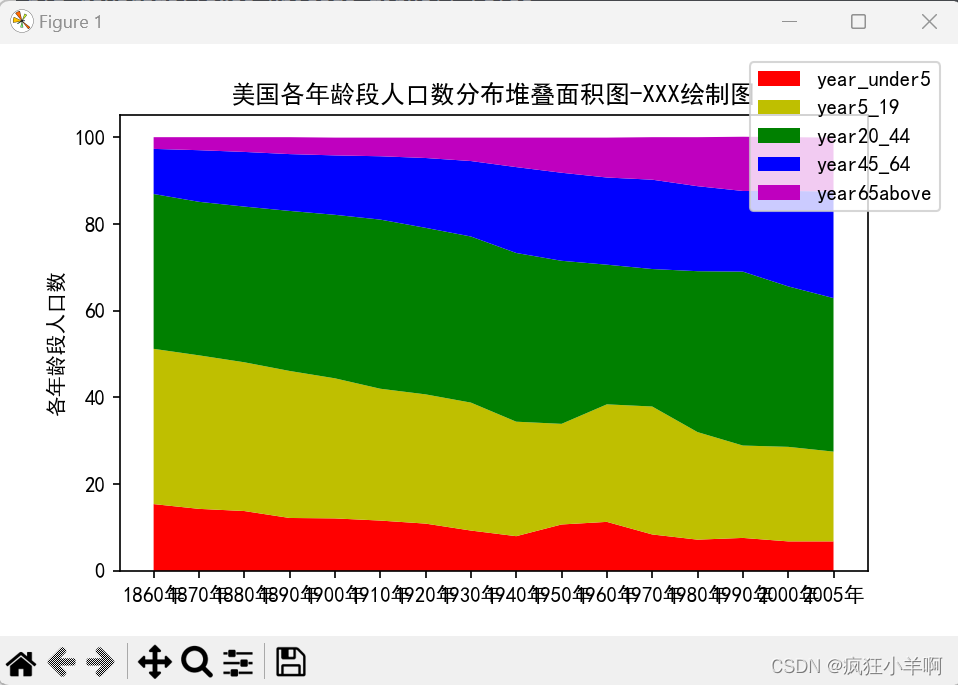
人口堆叠面积图
文件
代码
import matplotlib.pyplot as plt
import pandas as pd
us_population_rate = pd.read_csv(r"us_population_by_age.csv")
fig, ax=plt.subplots(figsize=(10,6))
plt.title("美国各年龄段人口数分布堆叠面积图-XXX绘制图")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False
x_year = us_population_rate['year']
year_under5 = us_population_rate['year_under5']
year5_19 = us_population_rate['year5_19']
year20_44 = us_population_rate['year20_44']
year45_64 = us_population_rate['year45_64']
year65above = us_population_rate['year65above']
plt.stackplot(x_year,year_under5,year5_19,year20_44,year45_64,year65above,baseline ='zero',colors=['r','y','g', 'b', 'm'])
plt.ylabel('各年龄段人口数')
plt.legend(['year_under5', 'year5_19', 'year20_44', 'year45_64', 'year65above'],bbox_to_anchor=(1.1,1.12),borderaxespad=0.1,fontsize = 10)
# bbox_to_anchor=(1.1,1.12)表示图例的位置,这里设置为相对于图表的右上角
# borderaxespad=0.1表示图例与图表边框之间的间距。
# fontsize=10表示图例文本的字体大小为10。
plt.show()效果:
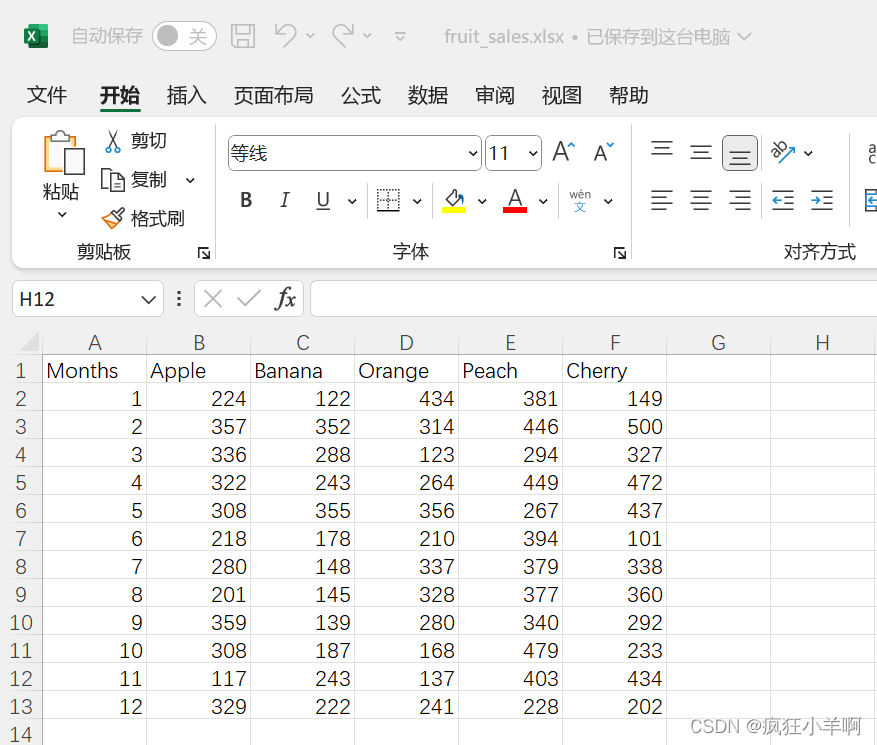
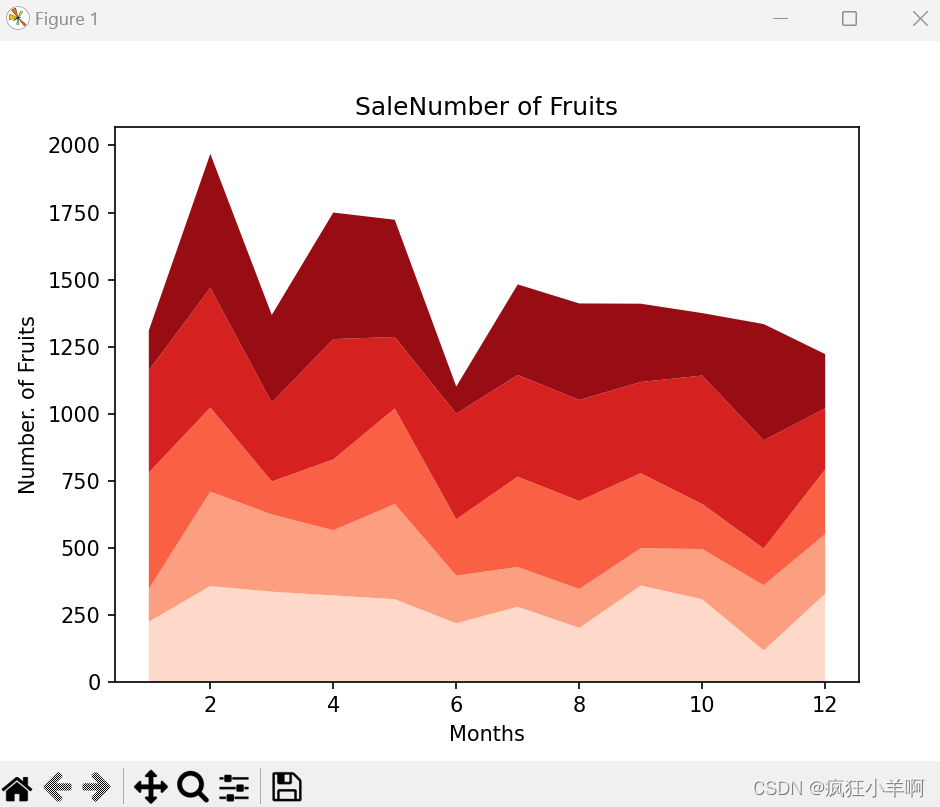
水果堆叠图
文件
代码
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
fruitData = pd.read_excel(r"fruit_sales.xlsx")
days = fruitData['Months']
Apple = fruitData['Apple']
Banana = fruitData['Banana']
Orange = fruitData['Orange']
Peach = fruitData['Peach']
Cherry = fruitData['Cherry']
camp1 = plt.cm.get_cmap('Reds')(np.linspace(0.15, 0.9, fruitData.shape[1]-1))
# 使用plt.cm.get_cmap()函数获取了一个名为'Reds'的颜色映射对象。
# 然后,使用np.linspace()函数生成了一个从0.15到0.9的等差数列,
# 数列的长度为fruitData.shape[1]-1。这个等差数列表示了一系列从0.15到0.9的数值。
# 将生成的数值作为参数传递给颜色映射对象,通过调用颜色映射对象的__call__()方法,
# 得到了一个包含了对应颜色的数组。这个数组表示了一系列从浅红色到深红色的颜色值。
plt.stackplot(days, Apple,Banana,Orange,Peach,Cherry,colors=camp1)
plt.xlabel('Months')
plt.ylabel('Number. of Fruits')
plt.title('SaleNumber of Fruits')
plt.show()效果:
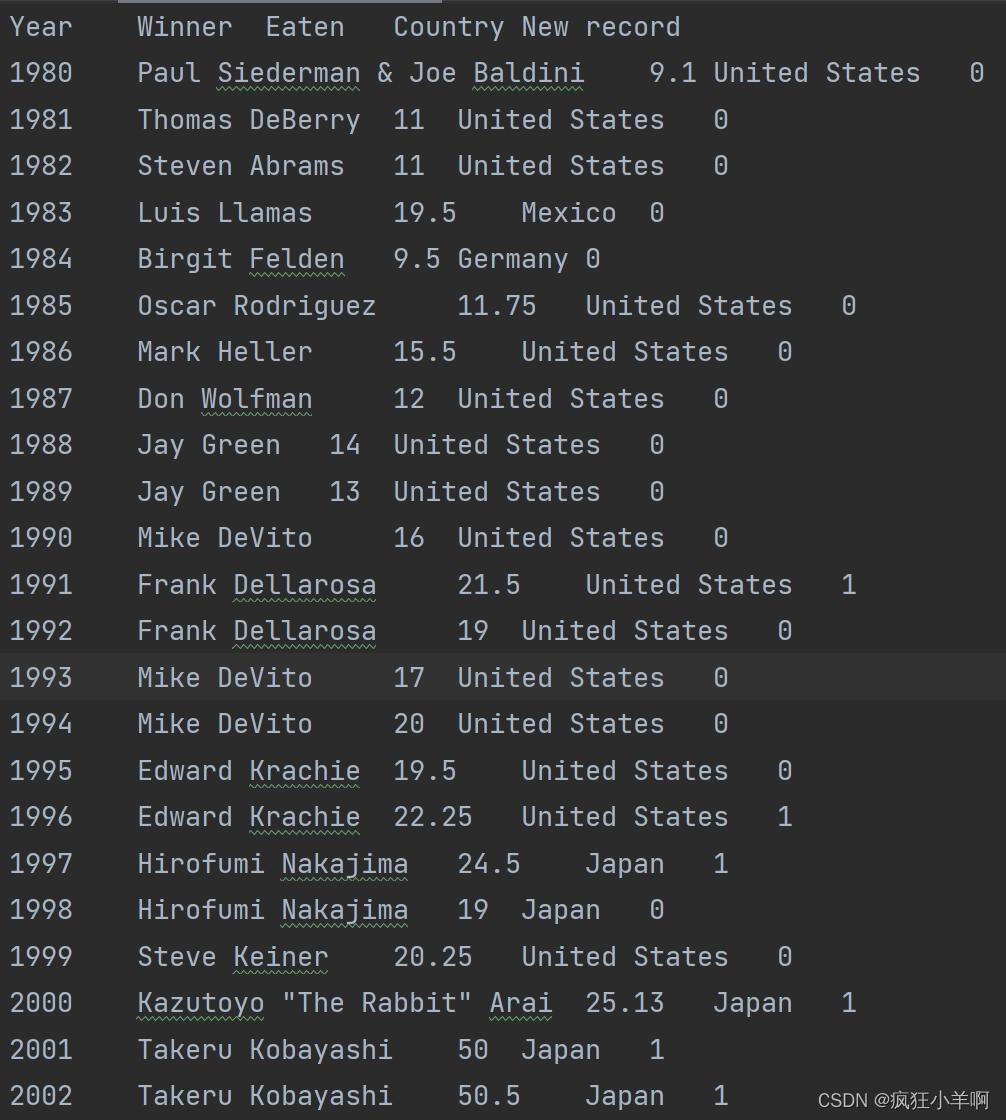
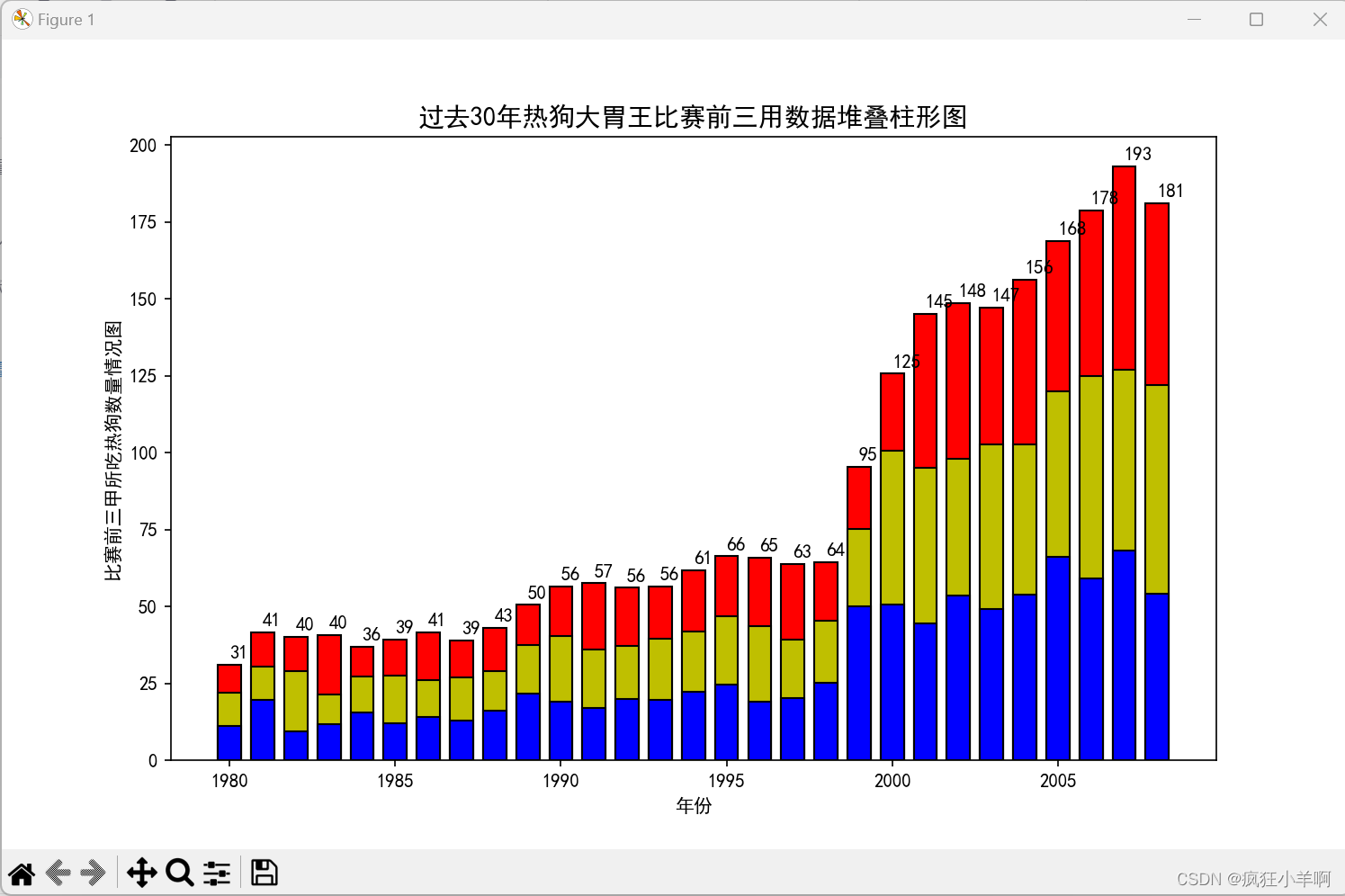
热狗大胃王比赛堆叠柱状图
文件
代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# delimiter="\t"。这个参数定义了用于分隔值的字符。在这个例子中,我们使用制表符 (“\t”) 作为分隔符,默认情况下使用逗号(“,”)。
hotdog = pd.read_csv(r"hot-dog-contest-winners.csv", delimiter="\t")
# fig 是一个代表整个图形的对象,而 ax 是一个代表轴(子图)的对象。
fig, ax = plt.subplots(figsize=(10, 6)) # (10英寸宽,6英寸高)
plt.rcParams['font.sans-serif'] = ['SimHei']
x_data = hotdog['Year']
y_data_1 = hotdog['Eaten']
y_data_2 = hotdog['Eaten'].shift(-1)
y_data_3 = hotdog['Eaten'].shift(-2)
plt.bar(x=x_data, height=y_data_1 + y_data_2 + y_data_3, width=0.7, color='r', edgecolor='k')
plt.bar(x=x_data, height=y_data_2 + y_data_3, width=0.7, color='y', edgecolor='k')
plt.bar(x=x_data, height=y_data_3, width=0.7, color='b', edgecolor='k')
ax.set_title('过去30年热狗大胃王比赛前三用数据堆叠柱形图', fontproperties='SimHei', fontsize=14)
ax.set_ylabel('比赛前三甲所吃热狗数量情况图')
ax.set_xlabel('年份')
for i, j in zip(hotdog['Year'], y_data_1 + y_data_2 + y_data_3):
if pd.notnull(j) and np.isfinite(j):
ax.text(x=i, y=j + 2, s=int(j))
plt.show()效果:
年龄占比堆叠图
文件:
代码:
import matplotlib.pyplot as plt
import pandas as pd
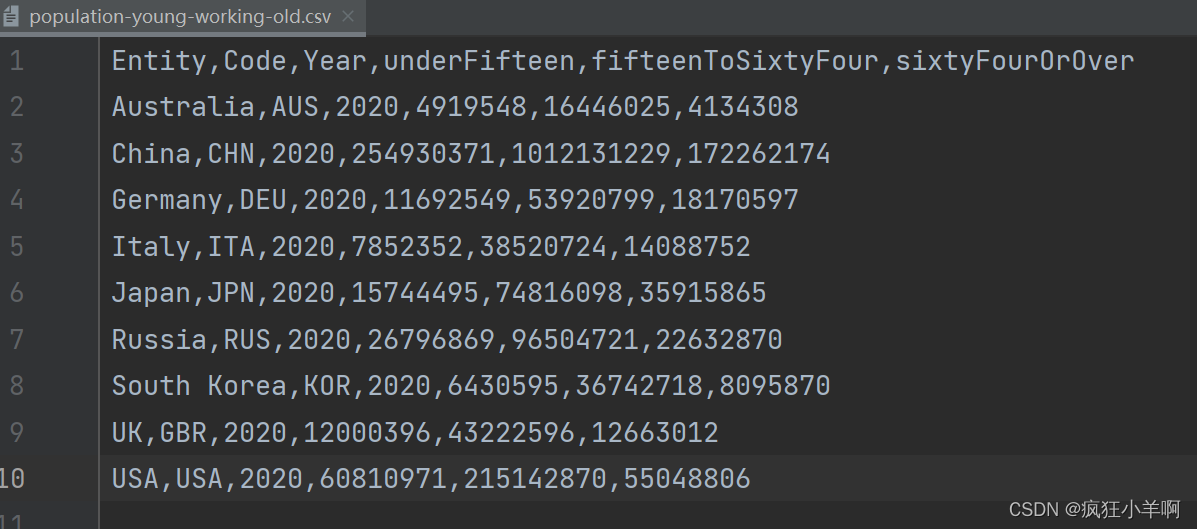
us_population_rate = pd.read_csv(r"population-young-working-old.csv")
fig, ax = plt.subplots(figsize=(10 , 6))
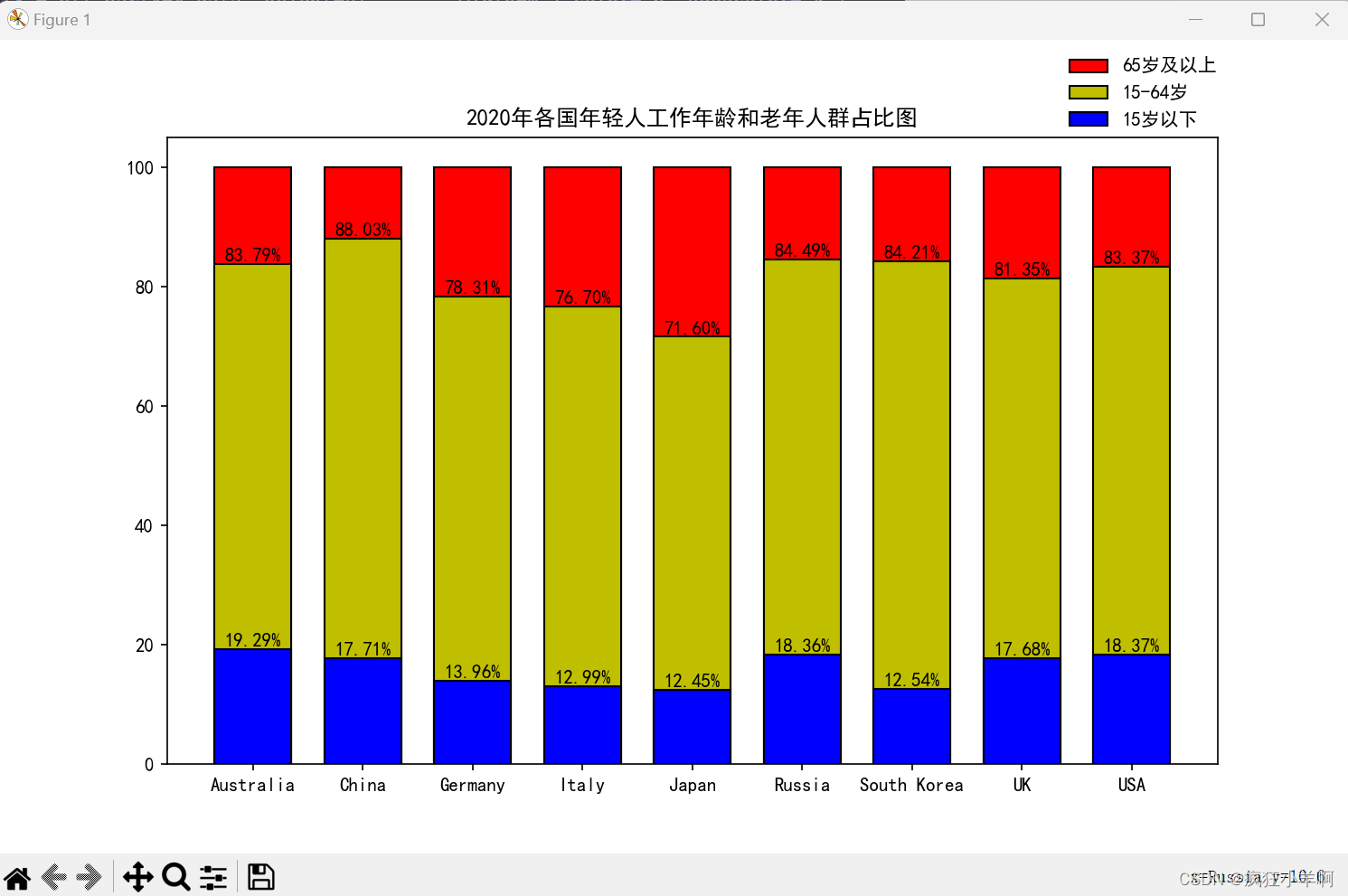
plt.title('2020年各国年轻人工作年龄和老年人群占比图')
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
x_data = us_population_rate['Entity']
y_data_1 = us_population_rate['underFifteen']
y_data_2 = us_population_rate['fifteenToSixtyFour']
y_data_3 = us_population_rate['sixtyFourOrOver']
sum_data = y_data_1 + y_data_2 + y_data_3
y1 = 100*y_data_1/sum_data
y2 = 100*y_data_2/sum_data
y3 = 100*y_data_3/sum_data
l1 = plt.bar(x=x_data, height=y1+y2+y3, width=0.7,color='r',edgecolor='k')
l2 = plt.bar(x=x_data, height=y1+y2, width=0.7,color='y',edgecolor='k')
l3 = plt.bar(x=x_data, height=y1, width=0.7,color='b',edgecolor='k')
plt.legend(frameon=False,handles=[l1,l2,l3],bbox_to_anchor=(0.85,1.0),
borderaxespad=0.1,labels=['65岁及以上','15-64岁','15岁以下'])
for x1, x2, ly1, ly2 in zip(x_data, x_data, y1,y2):
plt.text(x1, ly1, '%.2f%%' % ly1, ha='center', va='bottom')
plt.text(x1, (ly1+ly2),'%.2f%%' % (ly1+ly2),ha = 'center',va = 'bottom')
plt.show()效果:
时间饼图
文件:
代码
import matplotlib.pyplot as plt
import pandas as pd
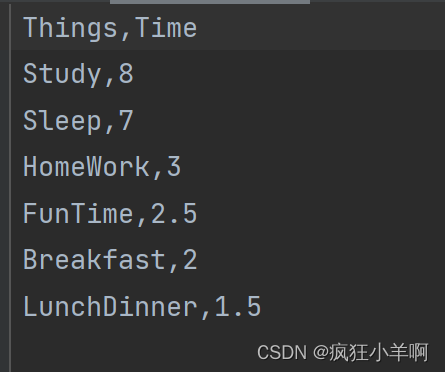
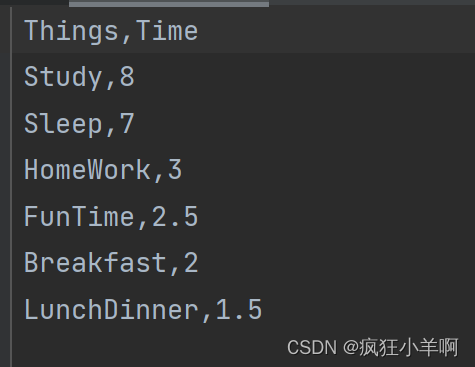
timeData = pd.read_csv(r"doubledec.csv")
plt.figure(figsize=(9,9))
plt.title('双减政策下的初中生时间馅饼图',fontdict={'fontsize':24},y=1.05)
plt.rcParams['font.sans-serif']=['SimHei']
labels = ['睡觉', '在校学习', '家庭作业', '自由活动', '午餐晚餐', '早餐及其它']
plt.pie(timeData['Time'], autopct='%1.1f%%', textprops={'fontsize': 12, 'color': 'b'}, labels=labels, startangle=180, counterclock=False)
plt.rcParams['legend.fontsize'] = 10
plt.legend(loc='lower left', frameon=False)
# 保证饼图呈现出圆形的效果
plt.axis('equal')
plt.show()
效果;
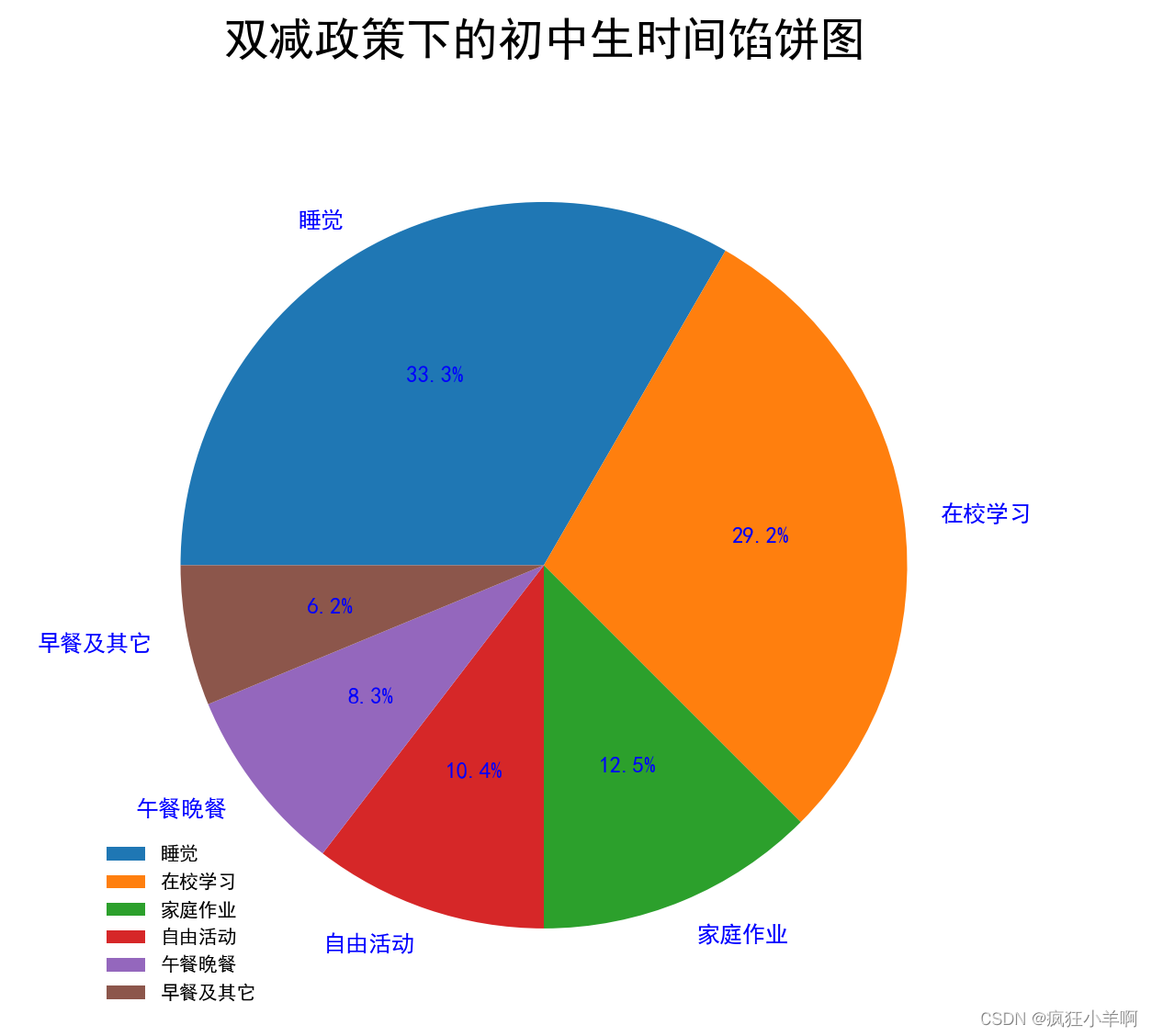
时间环形图
文件:
代码
import matplotlib.pyplot as plt
import pandas as pd
# 读取数据
timeData = pd.read_csv(r"doubledec.csv")
# 设置图形大小和标题
plt.figure(figsize=(9,9))
plt.title('双减政策下的初中生时间环形图',fontdict={'fontsize':24},y=1.05)
# 设置中文显示
plt.rcParams['font.sans-serif']=['SimHei']
# 设置标签和对应的数值
labels = ['睡觉', '在校学习', '家庭作业', '自山活动', '午餐晚餐', '早餐及其它']
sizes = timeData['Time']
# 绘制环形图
plt.pie(sizes, labels=labels, autopct='%1.1f%%',
startangle=180,
counterclock=False,
textprops={'fontsize': 12, 'color': 'b'},
wedgeprops={'width': 0.4})
plt.rcParams['legend.fontsize'] = 10
plt.axis('equal') # 保证长宽相等,使饼图为圆形
plt.show()效果:
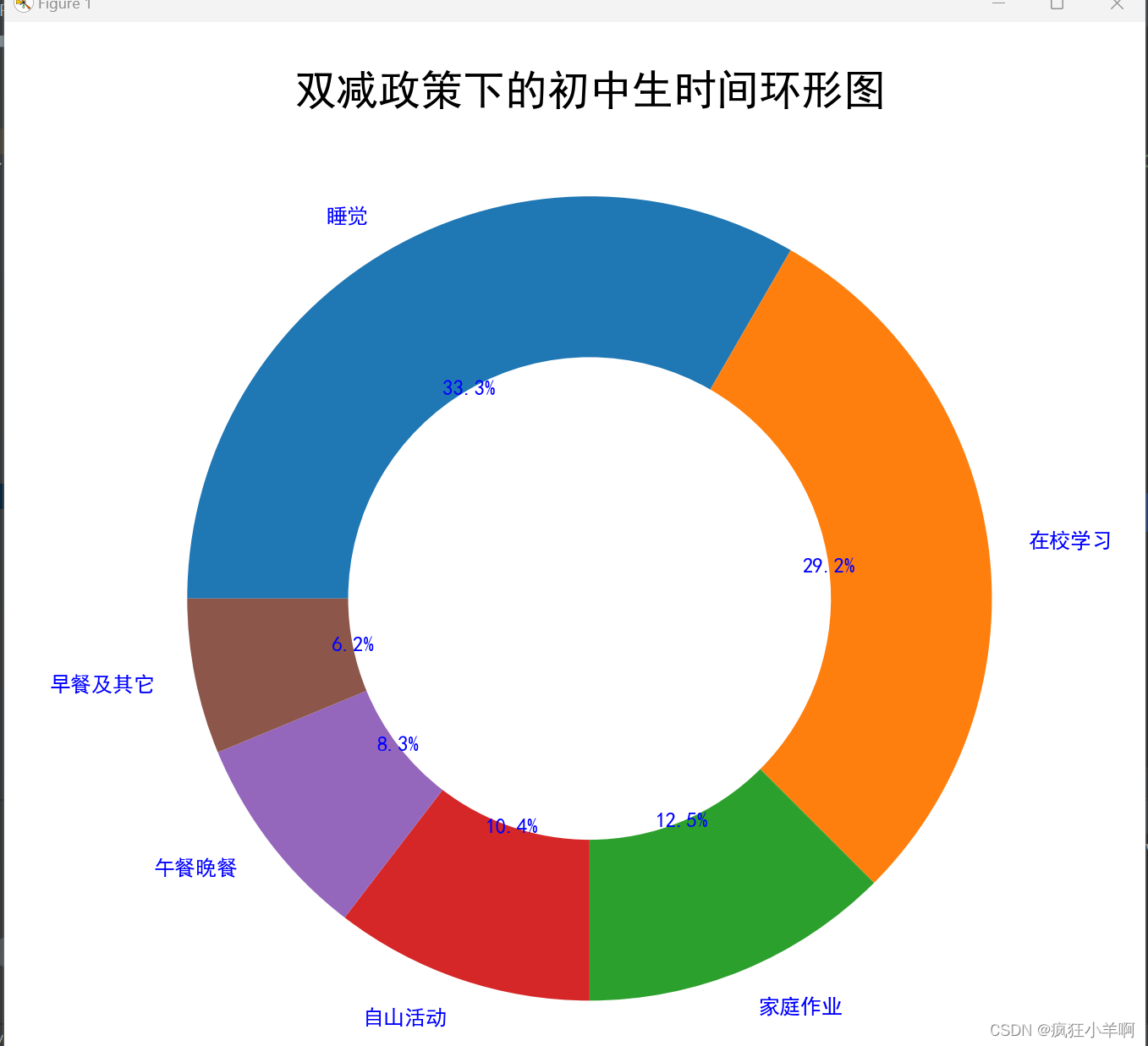
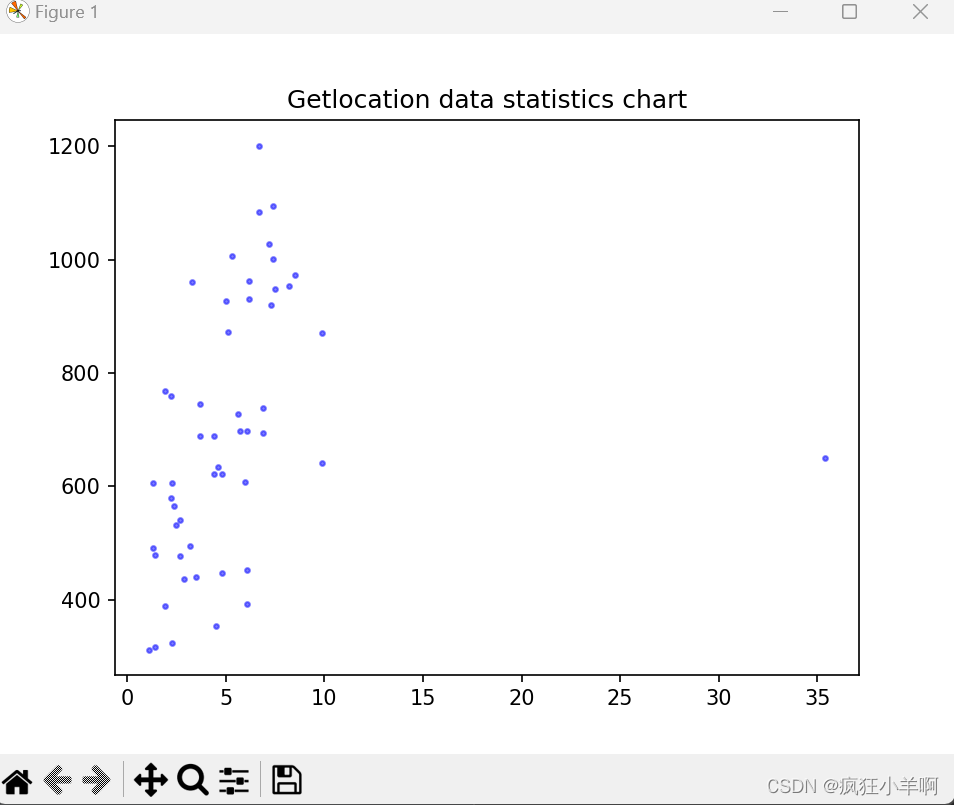
犯罪散点图
文件
代码;
import matplotlib.pyplot as plt
import pandas as pd
crime = pd.read_csv(r'crimeRatesByState2005.csv')
murder = crime['murder']
burglary = crime['burglary']
plt.scatter(murder,burglary,s=5,c='b',marker='o',alpha=0.5) # s:表示散点的大小5
plt.title("Getlocation data statistics chart")
plt.show()效果;
散点拟合曲线图
文件
代码
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
crime = pd.read_csv(r'crimeRatesByState2005.csv')
crime2 = crime[crime.state != 'Unite States']
crime2 = crime2[crime.state != 'District of Columbia']
# crime数据中排除了州名为'Unite States'和'District of Columbia'的行
murder = crime['murder']
burglary = crime['burglary']
plt.scatter(murder,burglary,s=5,c='b',marker='o',alpha=0.5)
plt.title("Getlocation data statistics chart")
# polyfit多项式曲线拟合函数
ploy = np.polyfit(murder,burglary,deg=1)
plt.plot(murder,np.polyval(ploy,murder))
plt.show()效果:

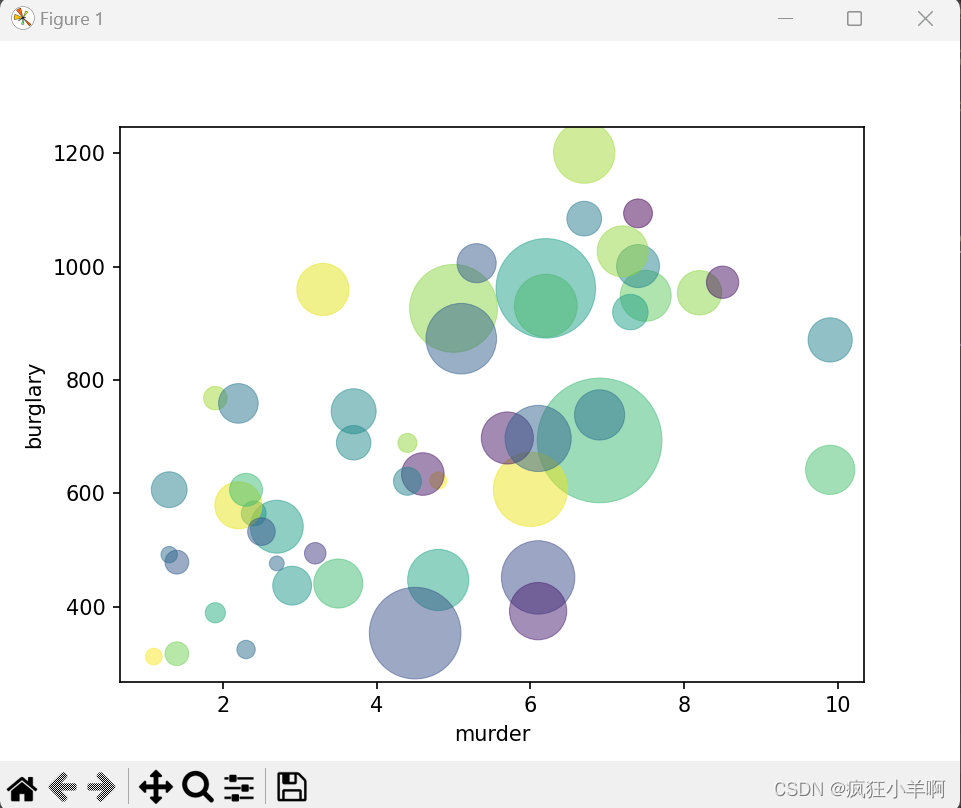
气泡图
文件:
代码
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
crime = pd.read_csv(r'crimeRatesByState2005.csv')
crime2 = crime[crime.state != "United States"]
crime2 = crime2[crime.state != "District of Columbia"]
s = list(crime2.population/10000)
colors = np.random.rand(len(list(crime2.murder)))
cm = plt.cm.get_cmap()
plt.scatter(x=list(crime2.murder), y=list(crime2.burglary), s=s, c=colors, cmap=cm, linewidth=0.5, alpha=0.5)
plt.xlabel("murder")
plt.ylabel("burglary")
plt.show()效果
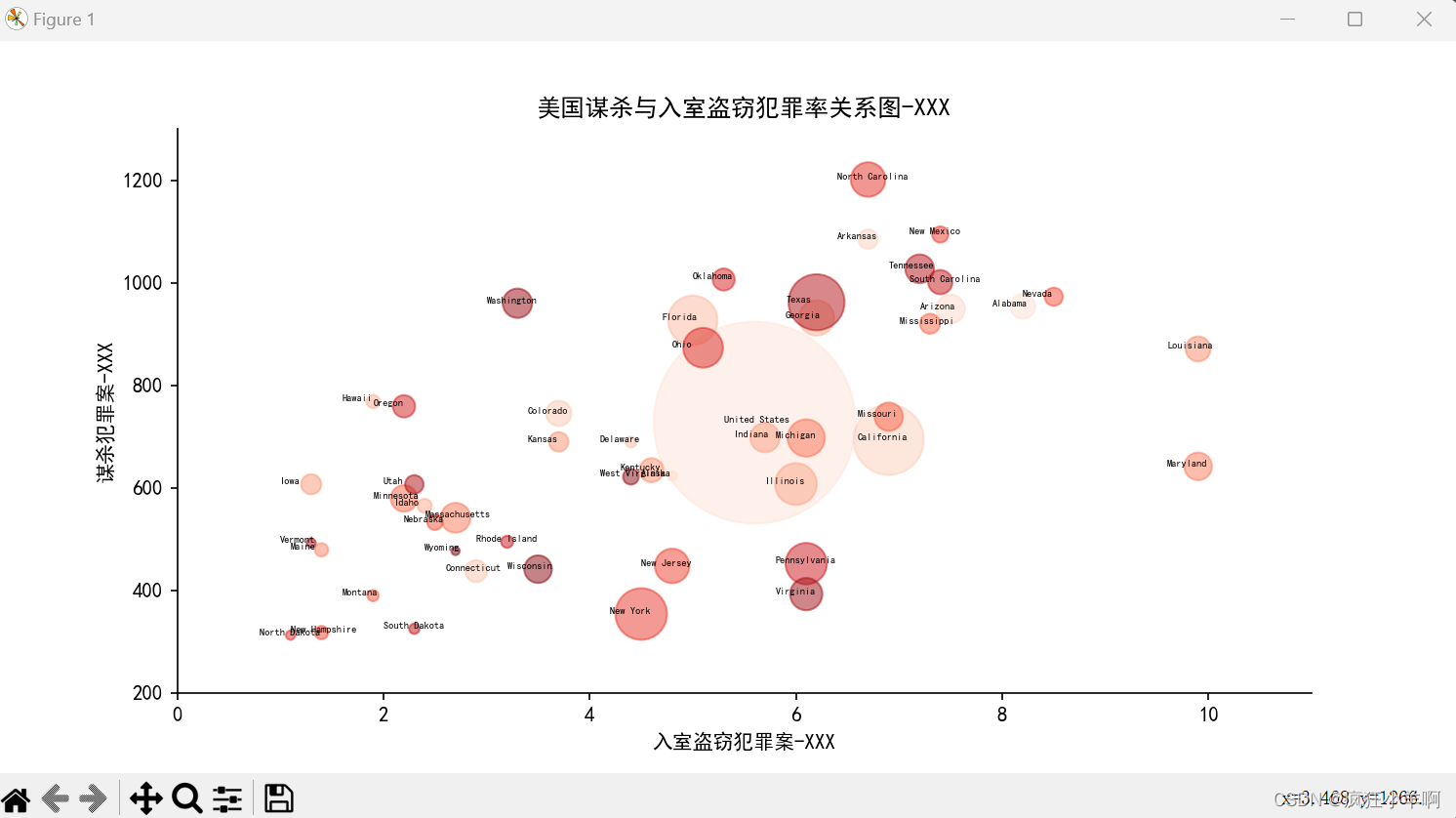
标注气泡图
文件:
代码
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
crime = pd.read_csv(r"crimeRatesByState2005.csv")
fig, ax = plt.subplots(figsize=(10,5))
crime.drop(index=crime[crime['state'] == 'United States'].index[0])
crime.drop(index=crime[crime['state'] == 'District of Columbia'].index[0],axis=0,inplace=True)
population = crime["population"]
state = crime["state"]
murder = crime["murder"]
burglary = crime["burglary"]
camp = plt.cm.get_cmap("Reds")(np.linspace(0.1,0.95,len(murder)))
camp1 = plt.cm.get_cmap('Reds')
colors = np.random.rand(len(murder))
ax.scatter(murder,burglary,s=population/30000,alpha=0.5,color=camp)
ax.set(xlim=(0,11),ylim=(200,1300))
ax.set_ylabel('谋杀犯罪案-XXX')
ax.set_xlabel('入室盗窃犯罪案-XXX')
plt.title('美国谋杀与入室盗窃犯罪率关系图-XXX')
for i, j, z in zip(murder,burglary,state):
ax.text(x=i-0.3,y=j-0.1,s=z,fontsize=5) # ax.text()函数在每个气泡上添加了对应的州名标注
plt.rcParams['font.sans-serif']=['SimHei']
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
plt.show()效果
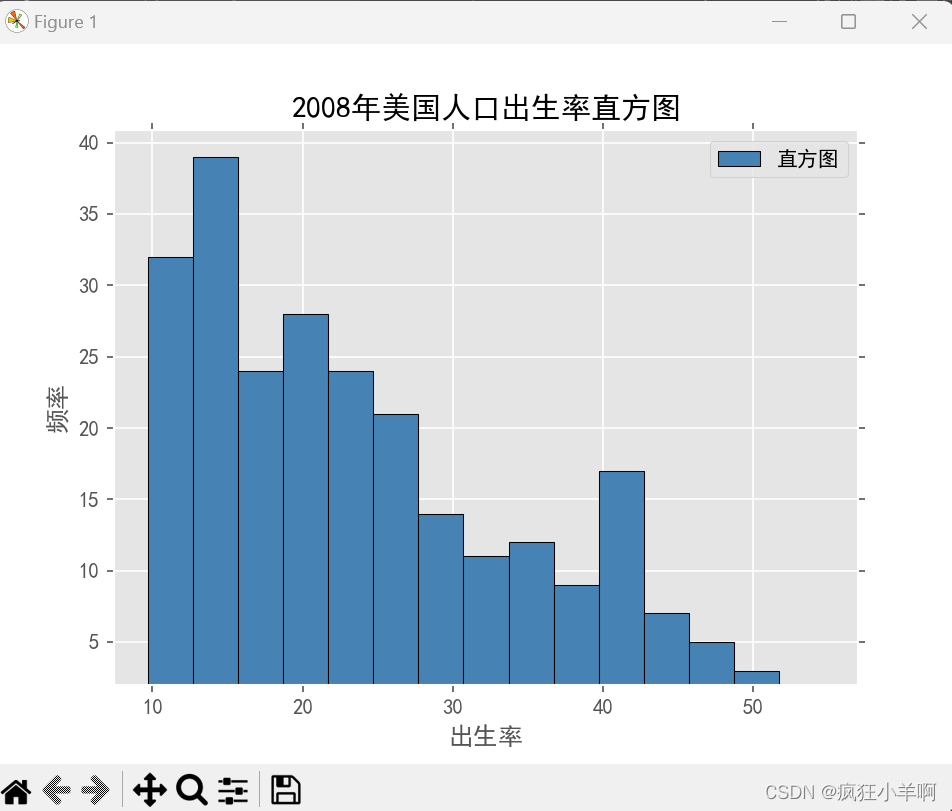
人口直方图
文件
代码
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
titanic = pd.read_csv(r'birth-rate.csv')
titanic.dropna(subset=['2008'],inplace=True)
# 使用ggplot样式,而不是matplotlib原生样式
plt.style.use('ggplot')
plt.hist(titanic['2008'],
# 设置bin的上限和下限范围,范围之外将被舍弃,
# 如果bin是一个序列,则范围无效
range=(8,54),
# 指定直方图的组距
bins=np.arange(titanic['2008'].min(),titanic['2008'].max(),3),
# 设置直方图的水平对齐方式,默认mid
align='right',
# 布尔值,默认false,若为True,则绘制频率分布直方图,若为false,则绘制频数分布直方图,
density=False,
# 设置直方图的类型
histtype='bar',
# 为直方图的每个条形添加基准线,默认0
bottom=2,
# color参数是设置直方图的颜色
color='steelblue',
# edgecolor设置直方图的边的颜色
edgecolor='k',
# 设置直方图的标签,可通过legend展示其图例
label='直方图',
# 设置直方图的摆放方向,默认垂直方向,horizontal vertical
orientation='vertical'
)
plt.title('2008年美国人口出生率直方图')
plt.xlabel('出生率')
plt.ylabel('频率')
# 更改刻度,刻度标签和网格线的外观
plt.tick_params(top='off',right='off')
plt.legend()
plt.show()效果:
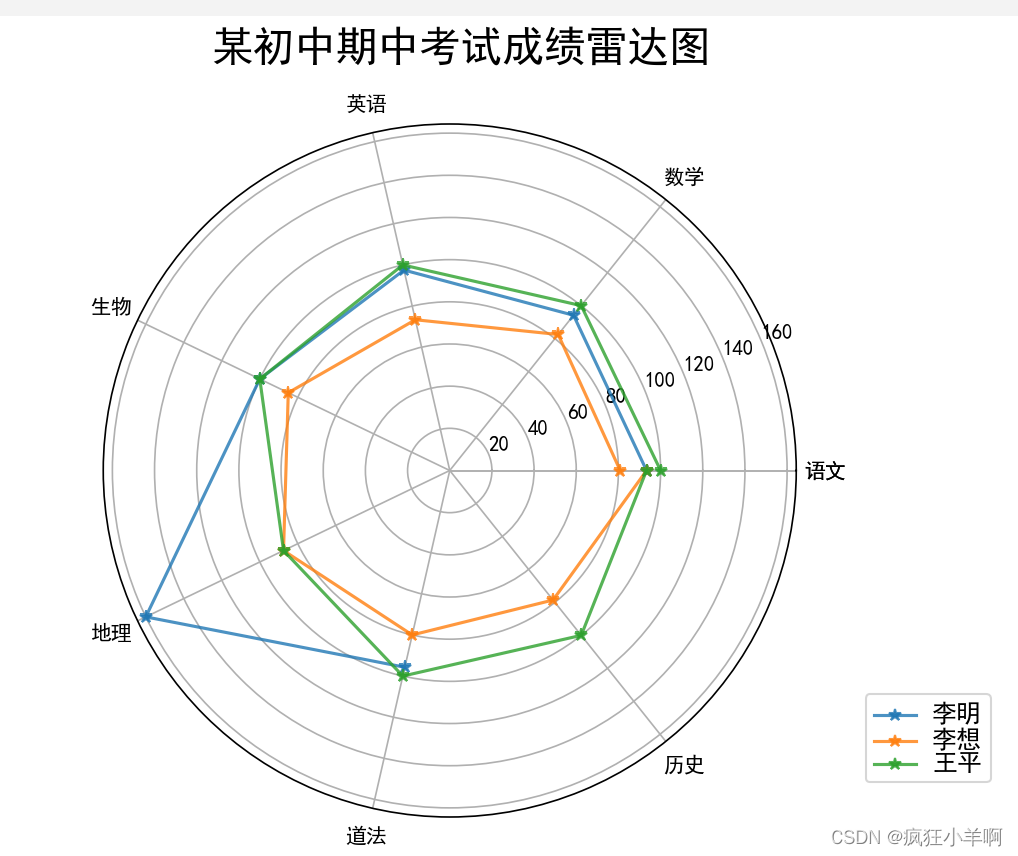
成绩雷达图
文件 无
代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
# data是传入的数据,index是索引,columns为指定的列名
dataset = pd.DataFrame(
data=[[112, 113, 117, 40, 64, 67], [97, 99, 88, 34, 35, 56, 55], [120, 120, 120, 40, 35, 70, 70]],
index=['李明', '李想', '王平'],
columns=['语文', '数学', '英语', '生物', '地理', '道法', '历史'])
radar_labels = dataset.index # 图例的标签
data = dataset.values # 数据值
data_labels = dataset.columns # 数据标签
nAttr = len(data[0])
# 设置角度(使用numpy的linspase函数构建雷达图数据角度序列)
angles = np.linspace(0, 2 * np.pi, nAttr, endpoint=False)
fullmark_list = [120, 120, 120, 40, 40, 70, 70]
fullmark_list_array = np.array(fullmark_list)
for i in range(0, len(data)):
data[i] = [float(i) for i in data[i]]
data[i] = np.array(data[i]) / fullmark_list_array * 100
data[i] = data[i].tolist()
data1 = [float(i) for i in data[0]]
data2 = [float(i) for i in data[1]]
data3 = [float(i) for i in data[2]]
# 将数据收尾闭合
data_a = np.concatenate((data1, [data1[0]]))
data_b = np.concatenate((data2, [data1[0]]))
data_c = np.concatenate((data3, [data1[0]]))
# 将角度和数据标签的首尾闭合
angles = np.concatenate((angles, [angles[0]]))
data_labels = np.concatenate((data_labels, [data_labels[0]]))
# 设置画布颜色和尺寸
fig = plt.figure(figsize=(10, 6))
# 雷达图需要投影为极坐标系
plt.subplot(111, polar=True)
# 绘图
plt.plot(angles, data_a, '*-', linewidth=1.5, alpha=0.8)
plt.plot(angles, data_b, '*-', linewidth=1.5, alpha=0.8)
plt.plot(angles, data_c, '*-', linewidth=1.5, alpha=0.8)
# 填充颜色
plt.thetagrids(angles * 180 / np.pi, data_labels)
plt.figtext(0.52, 0.95, '某初中期中考试成绩雷达图', ha='center', size=20)
# 设置图例
legend = plt.legend(radar_labels, loc=(1.1, 0.05), labelspacing=0.1)
plt.setp(legend.get_texts(), fontsize='large')
plt.grid(True)
plt.savefig('tongshi2.png')
plt.show()效果
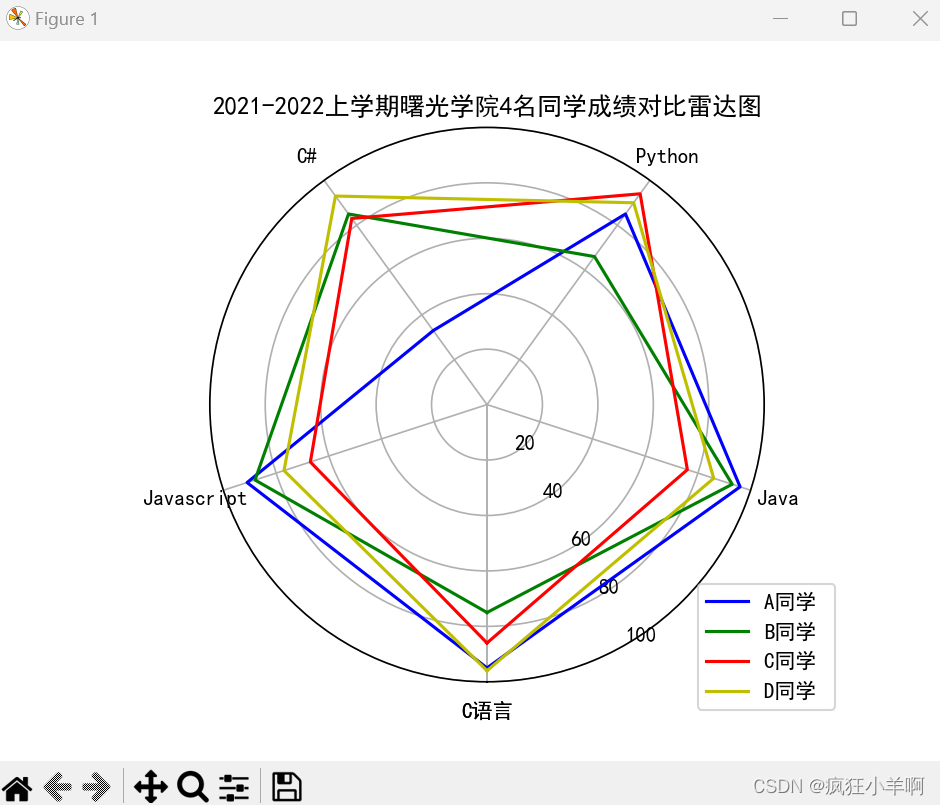
成绩对比雷达图
文件
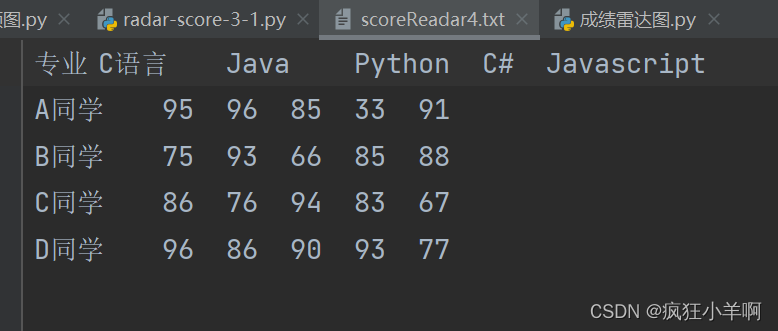
代码
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
filename = 'scoreReadar4.txt'
fp = open(filename, 'r' ,encoding='UTF-8')
List = []
flag = 0
s = fp.readline()
while s:
s = s.strip('\n')
new_s = s.split("\t")
List.append(new_s)
s = fp.readline()
data_length = len(List[0]) - 1
angles = np.linspace(0, 2*np.pi , data_length, endpoint=False)
labels = List[0][1:]
score = [item[1:] for item in List[1:]]
score_a = np.concatenate((score[0], [score[0][0]]))
score_b = np.concatenate((score[1], [score[1][0]]))
score_c = np.concatenate((score[2], [score[2][0]]))
score_d = np.concatenate((score[3], [score[3][0]]))
angles = np.concatenate((angles, [angles[0]]))
labels = np.concatenate((labels, [labels[0]]))
score_a = list(map(int, score_a))
score_b = [int(i) for i in score_b]
score_c = [int(i) for i in score_c]
score_d = [int(i) for i in score_d]
fig = plt.figure(dpi=100)
ax = plt.subplot(111, projection='polar')
ax.plot(angles, score_a, color="b")
ax.plot(angles, score_b, color="g")
ax.plot(angles, score_c, color="r")
ax.plot(angles, score_d, color="y")
ax.set_rgrids(np.arange(20, 120, 20))
ax.set_thetagrids(angles * 180 / np.pi, labels)
ax.set_theta_zero_location("S")
ax.set_rlabel_position(30)
ax.set_title("2021-2022上学期曙光学院4名同学成绩对比雷达图")
lenged_labels = [item[0] for item in List[1:]]
plt.legend(lenged_labels, loc=(0.88, -0.05))
plt.savefig('temp2.png')
plt.show()
效果
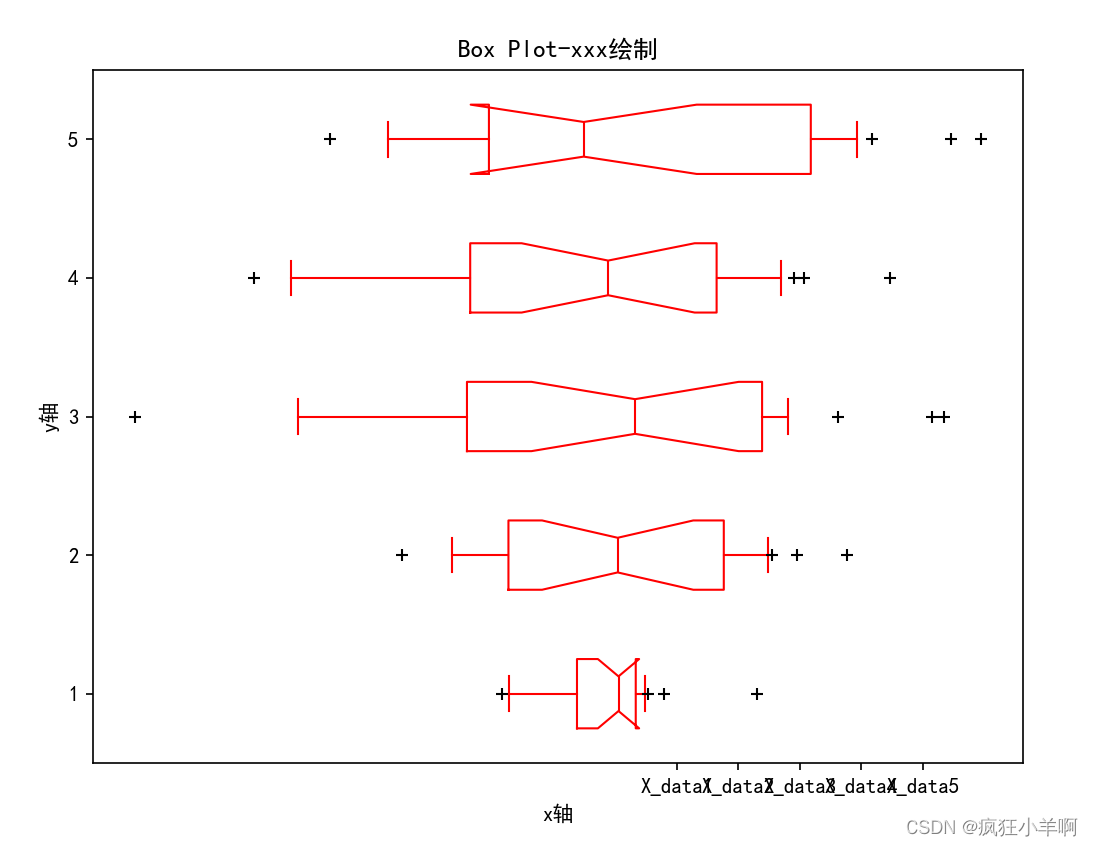
盒须图
文件 无
代码
import matplotlib.pyplot as plt
import numpy as np
data = [np.random.normal(0,std,20) for std in range(1,6)]
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
fig = plt.figure(figsize=(8,6))
box_plots = plt.boxplot(data,notch=True,sym='+',vert=False,
widths=0.5,whis=(5,85),positions=[1,2,3,5,4])
# notch:是否绘制缺口框,默认为False。
# sym:异常值的标记符号,默认为"+"
# vert:箱线图的方向,默认为垂直方向
# widths:箱线图的箱体宽度,默认为0.5
# whis:指定箱线图的须的范围,默认为(1,99),表示从第1个百分位数到第99个百分位数
# positions:指定每个箱线图的位置,默认为从1开始的递增整数
plt.xticks(np.arange(1,6),['X_data1','X_data2','X_data3','X_data4','X_data5'])
plt.xlabel('x轴')
plt.ylabel('y轴')
plt.title('Box Plot-xxx绘制')
for box in box_plots.values():
for line in box:
line.set_color('red')
plt.show()效果
讲话词云图
图片:
文件:

代码
import wordcloud
import matplotlib.pylab as plt
import jieba
import numpy as np
import PIL.Image as image
f = open(r"成立100周年讲话.txt", "r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t, cut_all=True)
# 定义空字符串ab,并使用循环遍历ls列表,
# 将不在停用词列表stop中的词拼接到字符串ab中
ab = ''
stop = ['和', '。', ',', '仍', '', '需', '\n', '还', '没', '的', '与']
for y in ls:
if y not in stop:
ab += y
# 使用jieba.add_word()函数添加自定义词"新时代"
# 再次使用jieba.lcut()函数对字符串ab进行分词,将分词结果保存在列表ls中
jieba.add_word("新时代")
ls = jieba.lcut(ab)
txt = ' '.join(ls)
mask = np.array(image.open("china.png"))
w = wordcloud.WordCloud(
font_path="C:\Windows\Fonts\STXINGKA.TTF",
font_step=1,
min_font_size=9,
max_font_size=80,
width=1000,
height=700,
background_color="white",
max_words=150,
stopwords=['的', '新', '与'],
margin=3,
mask=mask
)
w.generate(txt)
plt.figure(figsize=(10, 8))
plt.imshow(w, interpolation='bilinear')
w.to_file("grwordcloud1.png")
plt.axis("off") # 关闭坐标轴显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.show()效果

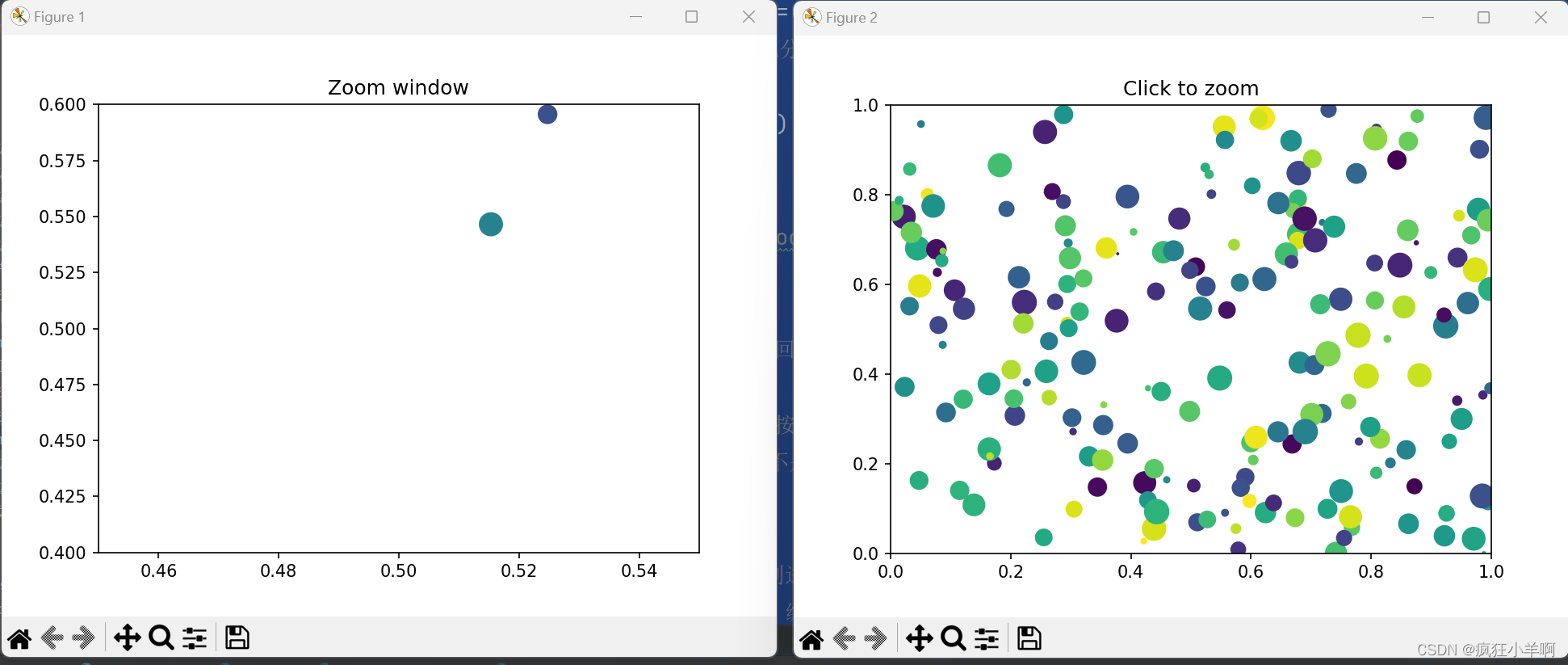
缩放散点图
文件 无
代码
#缩放
import matplotlib.pyplot as plt
import numpy as np
# 创建一个只包含一个字图的画图板,并返回这个画图板的figure对象figzoom和axes对象axzoom
figzoom, axzoom = plt.subplots()
# 创建一个只包含一个字图的画图板,并返回一个画图板的figure对象figsrc和axes对象axsrc
figsrc, axsrc = plt.subplots()
# 适应Axes对象的set函数设置用于axsrc子图的相关图表信息。设置横轴、纵轴刻度范围为0-1,坐标轴不自动缩放,标题为‘Click to zoom’
axsrc.set(xlim=(0, 1), ylim=(0, 1), autoscale_on=False, title='Click to zoom')
# 适应Axes对象的set函数设置用于axzoom子图的相关图表信息。
# 设置横轴刻度范围为0.45-0.55,纵轴刻度范围为0.4-0.6,坐标轴不自动缩放,标题为‘Zoom window’
axzoom.set(xlim=(0.45, 0.55), ylim=(0.4, 0.6), autoscale_on=False, title='Zoom window')
# 使用rand函数返回ndarray类型的4组随机分布的0-1之间的随机样本值,每组为200个数,
# 将这4组数据分别复制给x,y,s,c四个变量
x, y, s, c = np.random.rand(4, 200)
# 将s组数据的值扩大200倍
s *= 200
# 在使用x和y组数据分别在axsrc子图和axzoom子图上绘制对应的散点图,其中s组数据为散点的大小,c组数据为散点的颜色
axsrc.scatter(x, y, s, c)
axzoom.scatter(x, y, s, c)
# 定义处理'button_press_event'时间的回调函数ompress(event)
def onpress(event):
# event.button ==1代表事件发生时按下的鼠标左键,
# 此if语句代表如果在事件发生时如果不是按下的鼠标左键则不作处理
if event.button != 1:
return
# 如果事件发生时按下的是鼠标左键,则进行以下操作
# 将事件发生时鼠标左键所在位置的横、纵坐标值赋值给变量x,y
x, y = event.xdata, event.ydata
# 设置现实选择交互结果的axzoom子图的横轴刻度范围为x-0.1至x+0.1
axzoom.set_xlim(x - 0.1, x + 0.1)
# 设置现实选择交互结果的axzoom子图的纵轴刻度范围为y-0.1至y+0.1
axzoom.set_ylim(y - 0.1, y + 0.1)
# 重新绘制figzoom子图的内容
figzoom.canvas.draw()
# 绑定'button_press_event'事件及回调函数'onpress'
figsrc.canvas.mpl_connect('button_press_event', onpress)
plt.show()效果
















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











