









接上次博客:数据结构初阶(3)(链表:链表的基本概念、链表的类型、单向不带头非循环链表的实现、链表的相关OJ练习、链表的优缺点 )_di-Dora的博客-CSDN博客
目录
小练笔:
1、 ArrayList和LinkList的描述,下面说法错误的是?(D)
A.ArrayList和LinkedList都实现了List接口
B.ArrayList是可改变大小的数组,而LinkedList是双向链接串列
C.LinkedList不支持高效的随机元素访问
D.在LinkedList的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在ArrayList的中间插入或删除一个元素的开销是固定的
解析:
C. LinkedList 确实不支持高效的随机元素访问。由于LinkedList是基于链表的数据结构,访问元素需要从头节点开始逐个遍历,直到找到目标位置。相比之下,ArrayList支持基于索引的随机访问,可以通过索引直接访问元素,因为它是基于数组的数据结构。
D. 这个说法是错误的。
对于ArrayList,在中间插入或删除一个元素时,需要将该位置之后的所有元素向后移动,以腾出空间或填补删除的空位。这意味着剩余的元素都会被移动,所以插入或删除操作的开销是与列表长度相关的,具体来说是与剩余元素的数量成正比。因此,在ArrayList中,在中间插入或删除一个元素的开销是固定的。
而在LinkedList中,由于是使用链表实现,插入或删除中间元素时只需调整相邻节点的引用,开销较小,在插入或删除中间元素时只需调整相邻节点的引用,不需要移动其他元素
OJ练习
1、给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。
为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。
注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
这道题是面试中非常容易被考到的题。
这其实是一个追击问题。
在开始做这道题之前,我们需要先思考:
成环的思想是什么?
成环的思想是通过将链表的尾节点指向链表中的某个节点,从而形成一个环状结构。
具体而言,将链表的最后一个节点的 next 指针指向链表中的某个节点,即可创建一个环。
在快慢指针的算法中,当快指针走两步、慢指针走一步,它们最终会在环中的某个位置相遇。
假设链表带环,两个指针最后都会进入环,快指针先进环,慢指针后进环。
当慢指针刚进环时,可能就和快指针相遇了,最差情况下两个指针之间的距离刚好就是环的长度。此时,两个指针每移动一次,之间的距离就缩小一步,不会出现每次刚好是套圈的情况,因此:在慢指针走到一圈之前,快指针肯定是可以追上慢指针的,即相遇。
什么是套圈?
如果快指针每次走三步、四步等其他步长,却不一定可以判断链表中是否存在环!为什么呢?
原因是:快指针可能刚好跳过了慢指针,导致两个指针一直无法相遇。
“快指针走 2 步、慢指针走 1 步”的好处是什么?为什么不选择快指针走 4 步、慢指针走 3 步?
“ 快指针走 2 步、慢指针走 1 步 ” 可以最大程度地保证快指针能够追上慢指针,并且可以在最多相距一个环的长度的情况下判断链表中是否存在环。
注意:如果没有环,那么走的快的那一个指针一定先变为 null。
class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}
public class Solution {
public boolean hasCycle(ListNode head) {
if (head == null || head.next == null) {
return false;
}
ListNode slow = head;
ListNode fast = head.next;
while (slow != fast) {
if (fast == null || fast.next == null) {
return false;
}
slow = slow.next;
fast = fast.next.next;
}
return true;
}
}
}在该代码中,我们首先判断链表是否为空或者只有一个节点,如果是的话,说明不存在环,直接返回 false。
然后,我们初始化慢指针 slow 指向链表的头节点,快指针 fast 指向头节点的下一个节点。
接下来,我们使用一个循环来进行判断。在每一轮循环中,我们先判断快指针 fast 是否为空或者下一个节点是否为空,如果是的话,说明链表中不存在环,直接返回 false。否则,我们让慢指针 slow 前进一步,快指针 fast 前进两步。如果链表中存在环,那么快指针 fast 最终会追上慢指针 slow,它们会指向同一个节点,此时返回 true。
注意:
实际上,在上述代码中,将 fast 指针初始时指向 head.next 是为了避免在链表长度为奇数时进入死循环。
初始时,我们将slow指针指向头节点head,而将fast指针指向head.next的目的是为了使得两个指针以不同的起点开始遍历链表。
如果两个指针都从相同的起点开始,即slow和fast指针都指向head,那么在链表长度为奇数时会出现问题。由于fast指针每次移动两个节点,而slow指针每次只移动一个节点,所以当链表长度为奇数时,fast指针会比slow指针先到达链表尾部,无法正确判断是否存在循环。
因此,将fast指针初始时指向head.next可以确保在链表长度为奇数时,fast指针不会在slow指针之前到达链表尾部,从而保证了两个指针能够正确相遇。
总结起来,初始时将fast指针指向head.next是为了解决链表长度为奇数时的边界情况,确保两个指针能够正确相遇来判断是否存在循环。
另一种写法:
public boolean hasCycle(ListNode head) {
if(head == null) return false;
ListNode fast = head;
ListNode slow = head;
while(fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if(fast == slow) {
return true;
}
}
return false;
}这种实现方式仍然是有效的,不需要将fast指针初始时指向head.next的原因是,在循环的过程中,fast指针每次移动两个节点,而slow指针每次只移动一个节点。由于fast指针的速度更快,如果链表中存在循环,那么fast指针会追赶上slow指针并最终与其相遇。
当fast指针追赶上slow指针时,意味着链表中存在循环,这时可以返回true。如果循环结束时fast指针到达链表尾部(即fast指针为null),则说明链表中不存在循环,返回false。
所以,这种实现方式是利用了快慢指针的相对速度关系来判断循环,而不需要初始时将fast指针指向head.next。这种方法同样有效,并且在代码中更为简洁。
2、给定一个链表的头节点 head ,返回链表开始入环的第一个节点。
如果链表无环,则返回 null。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。
为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。
如果 pos 是 -1,则在该链表中没有环。
注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改链表。
关于这道题:我先把结论给到大家:
让一个指针从链表起始位置开始遍历链表,同时让一个指针从判环时相遇点的位置开始绕环运行,两个指针 都是每次均走一步,最终肯定会在入口点的位置相遇。
我们可以分两种情况讨论这个问题:(不管什么情况,两指针都最远最远相差一圈)
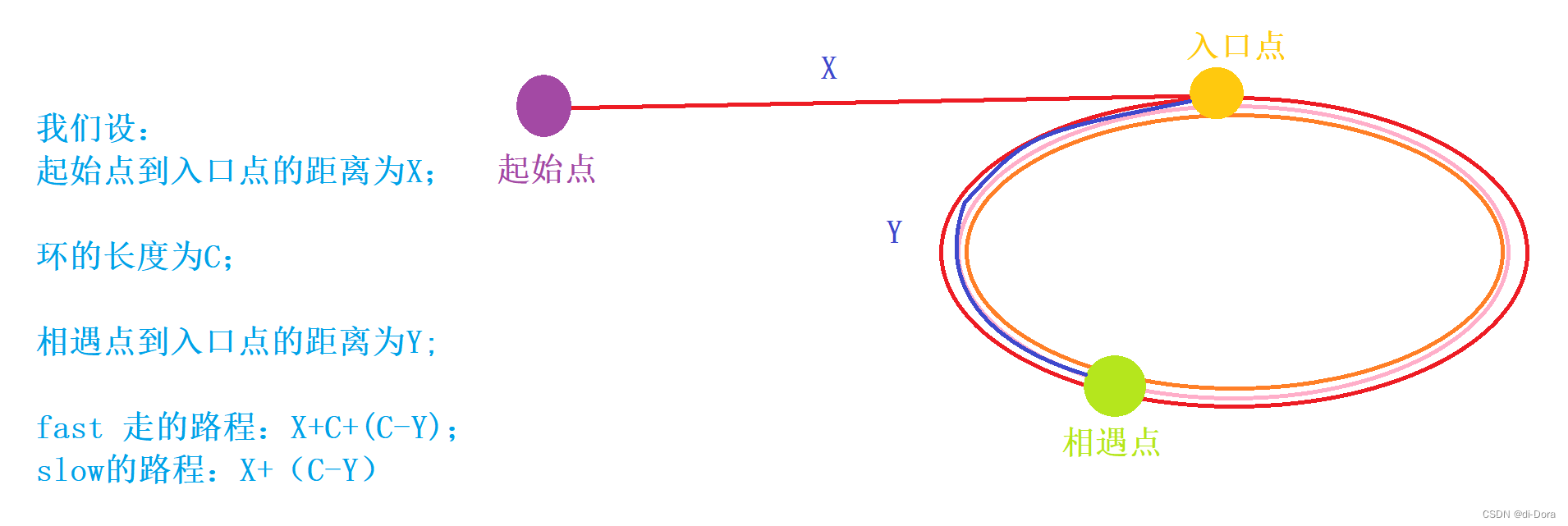
(1)、先考虑最快时间相遇的情况:快指针在慢指针进来前先走了一圈,再走第二圈的时候和慢指针相遇了。(不可能快指针一圈都没走完的情况下和慢指针相遇,因为那样就代表慢指针的速度比快指针还要快)
我们设:起始点到入口点的距离为X;
环的长度为C;
相遇点到入口点的距离为Y
那么:fast 走的路程:X+C+(C-Y); slow的路程:X+(C-Y)
因为 fast 的速度是 slow 的2倍:
X + C + ( C - Y ) =2 *【 X+(C - Y)】--------> X = Y
所以相遇后,把其中一个指针放到起始点,一个仍然放在相遇点,它们一起一步一步向前走,直到在入口点相遇。
(2)、考虑圈非常小的情况下,快指针一直绕圈,绕了 N 圈后才和慢指针相遇的情况。
我们可以直接得到等式:
X + NC + ( C - Y ) = 2 *【 X +(C - Y)】--------> X = NC - C + Y =(N - 1)C + Y
当N=1的时候,就是我们的第一种情况。
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode slow = head;
ListNode fast = head;
// 判断是否有环
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) {
break;
}
}
// 无环的情况
if (fast == null || fast.next == null) {
return null;
}
// 有环的情况,找到环的入口节点
ListNode ptr = head;
while (ptr != slow) {
ptr = ptr.next;
slow = slow.next;
}
return ptr;
}
}或者直接把 fast 移到前面:
public ListNode detectCycle() {
if(head == null) return null;
ListNode fast = head;
ListNode slow = head;
while(fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if(fast == slow) {
break;
}
}
if(fast == null || fast.next == null) {
return null;
}
fast = head;
while(fast != slow) {
fast = fast.next;
slow = slow.next;
}
return fast;
}3、给出一个升序排序的链表,删除链表中的所有重复出现的元素,只保留原链表中只出现一次的元素。
例如:
给出的链表为1→2→3→3→4→4→51→2→3→3→4→4→5, 返回1→2→51→2→5.
给出的链表为1→1→1→2→31→1→1→2→3, 返回2→32→3.
法一:
import java.util.*;
public class Solution {
public ListNode deleteDuplicates(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode dummy = new ListNode(-1);
dummy.next = head;
ListNode prev = dummy;
ListNode curr = head;
while (curr != null) {
boolean isDuplicate = false;
while (curr.next != null && curr.val == curr.next.val) {
curr = curr.next;
isDuplicate = true;
}
if (isDuplicate) {
prev.next = curr.next;
} else {
prev = curr;
}
curr = curr.next;
}
return dummy.next;
}
}解决思路:
- 首先进行特殊情况的判断,如果链表为空或者只有一个节点,则直接返回原链表头节点head,因为此时不会存在重复元素。
- 创建一个虚拟节点dummy,将其next指针指向原链表的头节点head,用于处理删除头节点的情况。
- 创建两个指针prev和curr,初始时分别指向虚拟节点dummy和链表的头节点head。
- 进入主循环,遍历整个链表。
- 在循环中,首先创建一个布尔变量isDuplicate,用于标记当前节点是否为重复节点。
- 内部循环,当当前节点的下一个节点不为null且当前节点的值与下一个节点的值相等时,将当前节点移动到下一个节点,同时将isDuplicate置为true,表示当前节点为重复节点。
- 判断isDuplicate的值,如果为true,说明当前节点为重复节点,需要删除。
- 删除操作:将前驱节点prev的next指针指向当前节点的下一个节点,跳过当前节点,实现删除操作。
- 如果isDuplicate为false,说明当前节点不是重复节点,将前驱节点prev移动到当前节点。
- 将当前节点curr移动到下一个节点。
- 循环结束后,返回虚拟节点dummy的下一个节点,即为去重后的链表头节点。
该算法通过使用虚拟节点和双指针的方法,遍历一次链表即可完成删除重复节点的操作。时间复杂度为O(N),其中N为链表的长度。
法二:
public ListNode deleteDuplication(ListNode pHead) {
ListNode cur = pHead;
ListNode newHead = new ListNode(-1);
ListNode tmpHead = newHead;
//遍历链表的每个节点
while(cur != null) {
if(cur.next != null && cur.val == cur.next.val) {
//一直让cur走到不重复的节点 然后把这个节点 加入到 不重复的链表当中
while(cur.next != null && cur.val == cur.next.val) {
cur = cur.next;
}
cur = cur.next;
}else {
tmpHead.next = cur;
tmpHead = tmpHead.next;
cur = cur.next;
}
}
//为了避免出现最后几个节点的vak都是重复的,最后还是需要手动置空。
tmpHead.next = null;
return newHead.next;
}双向链表——LinkedList
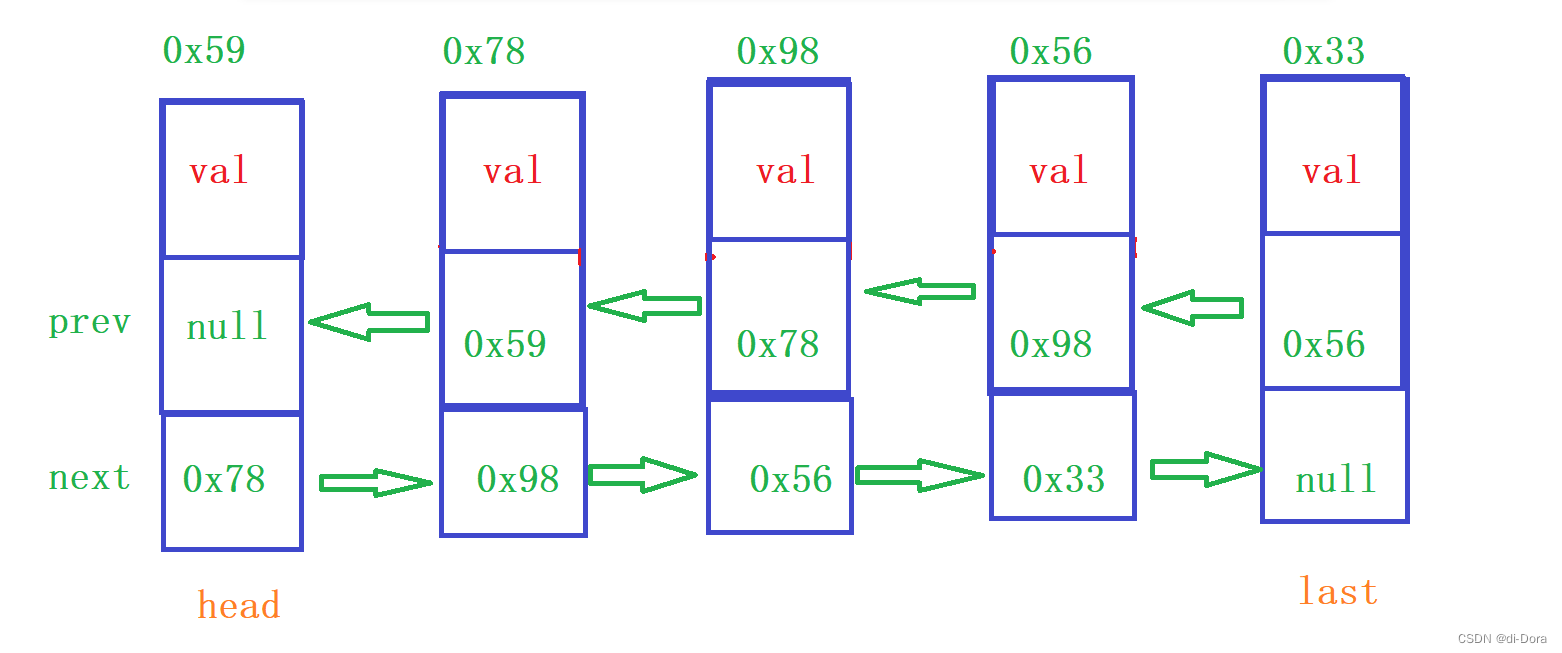
LinkedList是Java中的一个实现了List接口的双向链表数据结构。它以节点(Node)的形式存储元素,并通过引用将这些节点连接起来,形成一个链表。
与数组相比,链表不要求元素在内存中占用连续的空间。每个节点包含一个元素以及指向前一个节点和后一个节点的引用。这种双向链表的结构使得在任意位置插入或删除元素时不需要搬移其他元素,只需要修改节点的引用,因此在这些操作上具有较高的效率。
由于LinkedList是双向链表,每个节点除了存储元素值外,还保存了指向前一个节点和后一个节点的引用,因此可以方便地在链表的两个方向上进行遍历和操作。
双向链表在插入和删除元素时具有较高的灵活性和效率,但相比数组,在随机访问元素时的性能略低,因为需要通过遍历来找到目标位置。
因此,在需要频繁进行插入和删除操作,而对随机访问的需求相对较少的场景下,LinkedList是一个合适的数据结构选择。
LinkedList的注意事项
- LinkedList实现了List接口,因此它具有List接口定义的方法,例如add、remove、get 等操作,可以用作列表(List)的数据结构。
- LinkedList的底层使用了双向链表的数据结构。每个节点(Node)包含一个元素值以及指向前一个节点和后一个节点的引用,通过这些引用将节点连接起来形成链表结构。
- 由于LinkedList没有实现RandomAccess接口,它不支持随机访问。随机访问是指根据元素的索引直接访问元素,而不需要遍历链表。在LinkedList中,如果需要访问特定位置的元素,需要通过遍历来找到该位置,因此访问效率相对较低。
- LinkedList在任意位置插入和删除元素时具有较高的效率,时间复杂度为O(1)。由于链表的特性,只需要修改节点的引用即可完成插入或删除操作,不需要像数组那样搬移元素。
- 由于LinkedList在任意位置插入和删除元素的效率较高,而不需要移动其他元素,因此它比较适合在需要频繁进行插入和删除操作的场景中使用。例如,在实现栈、队列或需要频繁变动元素顺序的情况下,LinkedList是一个合适的选择。然而,如果需要频繁进行随机访问元素的操作,例如根据索引获取元素,可能会更适合使用基于数组的数据结构,如ArrayList。
LinkedList 的构造方法
LinkedList类提供了以下几种构造方法:
- LinkedList(): 创建一个空的LinkedList对象。
- LinkedList(Collection<? extends E> c): 创建一个包含指定集合中的元素的LinkedList对象。集合的元素将按照迭代器返回的顺序添加到链表中。
LinkedList<Integer> linkedList1 = new LinkedList<>();
LinkedList<Integer> linkedList2 = new LinkedList<>(Arrays.asList(1, 2, 3, 4, 5));需要注意的是,LinkedList实现了List接口,因此可以使用List接口定义的构造方法来创建LinkedList对象,例如ArrayList和Vector的构造方法。
LinkedList类的一些其他常用方法
LinkedList类提供了一些常用方法,下面是其中一些重要的方法介绍:
void addFirst(E e):在链表的开头插入指定的元素。
void addLast(E e):在链表的末尾插入指定的元素。
E getFirst():返回链表的第一个元素。
E getLast():返回链表的最后一个元素。
E removeFirst():移除并返回链表的第一个元素。
E removeLast():移除并返回链表的最后一个元素。
boolean remove(Object o):移除链表中第一次出现的指定元素。
boolean contains(Object o):判断链表是否包含指定元素。
int size():返回链表中的元素个数。
void clear():移除链表中的所有元素。
Iterator<E> iterator():返回一个迭代器,用于遍历链表中的元素。
ListIterator<E> listIterator():返回一个列表迭代器,用于在链表中双向遍历和操作元素。
boolean isEmpty():判断链表是否为空。
void add(int index, E element):在指定位置插入元素。
E remove(int index):移除并返回指定位置的元素。
E get(int index):返回指定位置的元素。
E set(int index, E element):将指定位置的元素替换为新的元素。
以上仅是LinkedList类的一部分方法,还有其他一些方法可以用于操作和处理链表。
我们可以用用看:
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
// 添加元素
linkedList.add("Apple"); // 将元素添加到链表末尾
linkedList.addFirst("Banana"); // 将元素添加到链表开头
linkedList.addLast("Cherry"); // 将元素添加到链表末尾
// 获取元素
String firstElement = linkedList.getFirst(); // 获取链表的第一个元素
String lastElement = linkedList.getLast(); // 获取链表的最后一个元素
System.out.println("First Element: " + firstElement);
System.out.println("Last Element: " + lastElement);
// 移除元素
linkedList.removeFirst(); // 移除链表的第一个元素
linkedList.removeLast(); // 移除链表的最后一个元素
// 判断元素是否存在
boolean containsApple = linkedList.contains("Apple"); // 判断链表是否包含指定元素
boolean containsBanana = linkedList.contains("Banana");
System.out.println("Contains Apple: " + containsApple);
System.out.println("Contains Banana: " + containsBanana);
// 获取链表大小
int size = linkedList.size(); // 返回链表中的元素个数
System.out.println("Size: " + size);
// 清空链表
linkedList.clear(); // 移除链表中的所有元素
// 判断链表是否为空
boolean isEmpty = linkedList.isEmpty(); // 判断链表是否为空
System.out.println("Is Empty: " + isEmpty);
}
}双向链表——LinkedList 的模拟实现
public class MyLinkedList {
// 节点类
private static class Node {
int val;
Node prev;
Node next;
public Node(int val) {
this.val = val;
}
}
private Node head; // 头节点
private Node last; // 尾节点
private int size; // 链表长度
public MyLinkedList() {
head = null;
last = null;
size = 0;
}
// 头插法
public void addFirst(int val) {
Node newNode = new Node(val);
if (head == null) {
head = newNode;
last = newNode;
} else {
newNode.next = head;
head.prev = newNode;
head = newNode;
}
size++;
}
// 尾插法
public void addLast(int val) {
Node newNode = new Node(val);
if (last == null) {
head = newNode;
last = newNode;
} else {
newNode.prev = last;
last.next = newNode;
last = newNode;
}
size++;
}
// 辅助方法:根据索引获取节点
private Node getNode(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException("Invalid index: " + index);
}
Node current = head;
for (int i = 0; i < index; i++) {
current = current.next;
}
return current;
}
// 任意位置插入,第一个数据节点为0号下标
public void addIndex(int index, int val) {
if (index < 0 || index > size) {
throw new IndexOutOfBoundsException("Invalid index: " + index);
}
if (index == 0) {
addFirst(val);
} else if (index == size) {
addLast(val);
} else {
Node newNode = new Node(val);
Node current = getNode(index);
Node prevNode = current.prev;
newNode.prev = prevNode;
newNode.next = current;
prevNode.next = newNode;
current.prev = newNode;
size++;
}
}
// 查找是否包含关键字 key 是否在双向链表中
public boolean contains(int key) {
Node current = head;
while (current != null) {
if (current.val == key) {
return true;
}
current = current.next;
}
return false;
}
// 删除第一次出现关键字为 key 的节点
public void remove(int key) {
Node current = head;
while (current != null) {
if (current.val == key) {
Node prevNode = current.prev;
Node nextNode = current.next;
if (prevNode == null) {
head = nextNode;
} else {
prevNode.next = nextNode;
}
if (nextNode == null) {
last = prevNode;
} else {
nextNode.prev = prevNode;
}
size--;
return;
}
current = current.next;
}
}
//第二种方法
public void remove2(int key) {
Node current = head;
while (current != null) {
if (current.val == key) {
//删除头节点
if(current==head){
head=head.next;
if(head!=null){
//考虑只有一个头节点,而且这个头节点还是我们要删除的
head.prev=null;
}else {
last=null;
}
}else {
//删除中间节点和尾巴节点
if(current.next!=null){
//删除中间节点
current.prev.next=current.next;
last=last.prev;
}else {
//删除尾巴节点
current.prev.next=current.next;
current.next.prev=current.prev;
}
}
return;
}else {
current = current.next;
}
}
}
// 删除所有值为 key 的节点
public void removeAllKey(int key) {
Node current = head;
while (current != null) {
if (current.val == key) {
Node prevNode = current.prev;
Node nextNode = current.next;
if (prevNode == null) {
head = nextNode;
} else {
prevNode.next = nextNode;
}
if (nextNode == null) {
last = prevNode;
} else {
nextNode.prev = prevNode;
}
size--;
}
current = current.next;
}
}
// 第二种方法
public void removeAllKey2(int key) {
Node current = head;
while (current != null) {
if (current.val == key) {
//删除头节点
if(current==head){
head=head.next;
if(head!=null){
//考虑只有一个头节点,而且这个头节点还是我们要删除的
head.prev=null;
}else {
last=null;
}
}else {
//删除中间节点和尾巴节点
if(current.next!=null){
//删除中间节点
current.prev.next=current.next;
last=last.prev;
}else {
//删除尾巴节点
current.prev.next=current.next;
current.next.prev=current.prev;
}
}
current = current.next;
}else {
current = current.next;
}
}
}
// 得到双向链表的长度 1
public int size() {
return size;
}
//得到双向链表的长度 2
public int size() {
int length = 0;
ListNode curr = head;
while (curr != null) {
length++;
curr = curr.next;
}
return length;
}
// 显示链表中的元素
public void display() {
Node current = head;
while (current != null) {
System.out.print(current.val + " ");
current = current.next;
}
System.out.println();
}
// 清空链表
public void clear() {
head = null;
last = null;
size = 0;
}
}
注意:这里任意位置添加节点的代码,如果只有 curr 和 newNode:
newNode.next = curr ;
curr.prev.next = newNode ;
newNode.prev = curr.prev ;
curr.prev = newNode ; 比如这样实现:
public class MyLinkedList {
static class ListNode {
private int val;
private ListNode prev;
private ListNode next;
public ListNode(int val) {
this.val = val;
}
}
public ListNode head;//双向链表的头节点
public ListNode last;//双向链表的尾巴
//得到链表的长度
public int size(){
ListNode cur = head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
public void display(){
ListNode cur = head;
while (cur != null) {
System.out.print(cur.val+" ");
cur = cur.next;
}
System.out.println();
}
//查找是否包含关键字key是否在链表当中
public boolean contains(int key){
ListNode cur = head;
while (cur != null) {
if(cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
//头插法
public void addFirst(int data){
ListNode node = new ListNode(data);
if(head == null) {
head = node;
last = node;
}else {
node.next = head;
head.prev = node;
head = node;
}
}
//尾插法
public void addLast(int data){
ListNode node = new ListNode(data);
if(head == null) {
head = node;
last = node;
}else {
last.next = node;
node.prev = last;
last = last.next;
}
}
//任意位置插入,第一个数据节点为0号下标
public void addIndex(int index,int data){
checkIndex(index);
if(index == 0) {
addFirst(data);
return;
}
if(index == size()) {
addLast(data);
return;
}
ListNode cur = searchIndex(index);
ListNode node = new ListNode(data);
node.next = cur;
cur.prev.next = node;
node.prev = cur.prev;
cur.prev = node;
}
private ListNode searchIndex(int index) {
ListNode cur = head;
while (index != 0) {
cur = cur.next;
index--;
}
return cur;
}
private void checkIndex(int index) {
if(index < 0 || index > size()) {
throw new IndexOutOfException("index 不合法!"+index);
}
//清空链表
public void clear() {
Node cur=head;
while (cur!=null){
Node curNext=cur.next;
cur.prev=null;
cur.next=null;
//此时出问题了,节点之间的联系断开了!所以修改之前先记录数据
cur=curNext;
}
head = null;
last = null;
}
}LinkedList的遍历方法
在LinkedList中,可以使用迭代器(Iterator)或增强for循环(enhanced for loop)来进行遍历。下面是两种常用的遍历方式的示例代码:
使用迭代器进行遍历:
import java.util.LinkedList;
import java.util.Iterator;
public class Main {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("Apple");
linkedList.add("Banana");
linkedList.add("Cherry");
// 使用迭代器进行遍历
Iterator<String> iterator = linkedList.iterator();
while (iterator.hasNext()) {
//还会让iterator自动向后走一步
String element = iterator.next();
System.out.println(element);
}
//倒着遍历
Iterator<String> iterator2 = linkedList.iterator(linkedList.size());
while (iterator2.hasPrevious()) {
//还会让iterator自动向后走一步
String element = iterator2.previous();
System.out.println(element);
}
}
}使用增强for循环进行遍历:
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("Apple");
linkedList.add("Banana");
linkedList.add("Cherry");
// 使用增强for循环进行遍历
for (String element : linkedList) {
System.out.println(element);
}
}
}ArrayList 和 LinkedList 的区别:
| 不同点 | ArrayList | LinkedList |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但是物理上不一定连续 |
| 随机访问 | 支持O(1) | 支持O(N) |
| 头插 | 需要搬移元素,效率低O(N) | 只需要修改引用的指向,时间复杂度为O(1) |
| 插入 | 空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效访问+频繁访问 | 任意位置插入和删除频繁 |
顺序表逆置存储
请用C语言完成算法,实现对顺序表逆置存储。逆置存储是指将元素线性关系逆置后的顺序存储,例如(a0,a1,a2),关系逆置后为(a2,a1,a0)
typedef struct seqList {
int n; // 当前元素数量
int maxLength; // 最大允许元素数量
ElemType *element; // 动态分配的数组,存储元素
} SeqList;
void Invert(SeqList *L) {
ElemType temp;
int i;
// 遍历顺序表的前半部分
for (i=0; i < L->n/2; i++) {
// 保存前半部分的当前元素
temp = L->element[i];
// 前半部分的当前元素 = 后半部分的对应元素
L->element[i] = L->element[L->n - 1 - i];
// 后半部分的对应元素 = 保存的前半部分的当前元素
L->element[L->n - 1 - i] = temp;
}
}
/*
算法思想:我们将顺序表的前半部分的每个元素与后半部分的对应元素交换,实现顺序表的逆置存储。
*/单链表的逆置存储
请用C语言完成下列算法,对单链表的逆置存储,逆置存储是指将元素线性关系逆置后的链表存储,例如(a0,a1,a2),关系逆置后为(a2,a1,a0)
typedef struct node
{
ElemType element;
struct node *link;
}Node;
typedef struct singlelist
{
Node *first;
int n;
}SingleList
void invert(SingleList *L) {
Node *p = L->first, *q;
L->first = NULL;
while (p != NULL) {
q = p->link;
p->link = L->first;
L->first = p;
p = q;
}
}
/*
算法思想:我们从头节点开始,依次将每个节点的link指针逆置,将当前节点的link指向前一个节点,最终完成链表的逆置存储。
*/1. 我们定义了一个函数 invert,它接受一个单链表 SingleList *L 作为参数,其中 SingleList 包含一个指向链表第一个节点的指针 first 和链表中节点数量的变量 n。
2. 在函数中,我们声明了两个指针变量 p 和 q,开始时将 p 指向链表的第一个节点 L->first。
3. 我们将链表的头节点指针 L->first设置为 NULL,这是为了将链表逆序存储,开始时新链表为空。
4. 使用一个 while 循环,我们遍历原链表中的每个节点。
5. 在每次迭代中,我们首先将 q 指向 p 的下一个节点,以便在逆序时不会丢失原链表的连接。
6. 接下来,我们将当前节点 p 的 link 指针指向新链表的头节点,这个操作实现了逆序。
7. 最后,我们将新链表的头节点指针 L->first 更新为当前节点 p,表示新链表的头节点已经变为 p。
8. 继续迭代,将 p 移动到下一个节点,直到遍历完整个原链表。
这样,当循环结束时,原链表中的元素顺序已经逆序排列在新链表中,完成了链表的逆置存储。这个算法不需要额外的空间,只是改变了节点之间的连接关系。
有序递增带表头结点单链表的合并
请用C语言完成下列算法,将两个有序递增的带表头结点的单链表合并为一个有序递增的单链表。
链表结点Node和链表SingleList结构体定义如下:
typedef struct node
{
ElemType element;
struct node *link;
}Node;
typedef struct headerlist
{
Node *head;
int n;
}HeaderList;
void MergeList1(HeaderList *La, HeaderList *Lb, HeaderList *Lc) {
// 合并链表La和Lb,合并后的新表使用头指针Lc指向
Node *pa, *pb, *pc, *q;
pa = La->head->link;
pb = Lb->head->link;
pc = Lc->head;
while (pa && pb) {
if (pa->element <= pb->element) {
pc->link = pa;
pc = pa;
pa = pa->link;
La->n--;
}
else if (pa->element > pb->element) {
pc->link = pb;
pc = pb;
pb = pb->link;
Lb->n--;
}
else {
pc->link = pa;
pc = pa;
pa = pa->link;
q = pb;
pb = pb->link;
free(q);
}
Lc->n++;
}
pc->link = pa ? pa : pb; // 插入剩余段
Lc->n += pa ? La->n : Lb->n;
}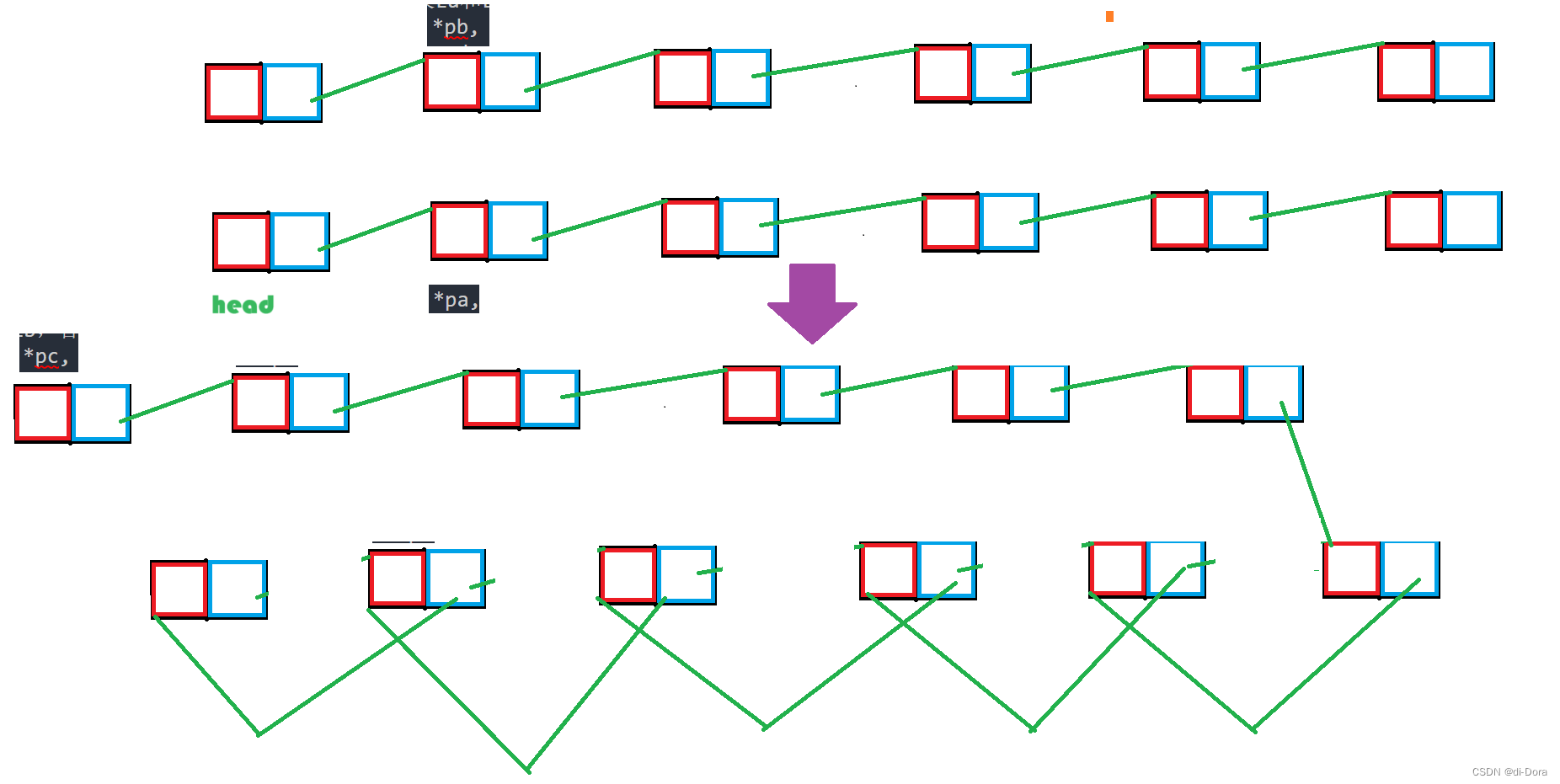
1. 首先,我们声明了四个指针变量:pa 用于遍历链表 La,pb 用于遍历链表 Lb、pc 用于构建新表 Lc,q 用于释放内存。
2. 我们将 pa 初始化为 La 的第一个节点(去除了表头结点),将 pb 初始化为 Lb 的第一个节点(去除了表头结点),将 pc 初始化为 Lc 的表头结点。
3. 进入一个 while 循环,这个循环用于遍历 La 和 Lb,并逐个比较它们的元素值。
4. 在每次循环迭代中,我们比较 pa 和 pb 当前节点的元素值。如果 pa 的元素值小于等于 pb 的元素值,我们将 pa 接入新表 Lc,并移动 pa 指针,同时减少 La 中的元素数量 La->n--。如果 pa 的元素值大于 pb 的元素值,我们将 pb 接入新表 Lc,并移动 pb 指针,同时减少 Lb 中的元素数量 Lb->n--。如果两个节点的元素值相等,我们将 pa 接入新表 Lc,同时释放 pb 所占用的内存,然后移动指针,减少相应链表中的元素数量。
5. 在每次迭代中,无论哪种情况,新表 Lc 中的元素数量 Lc->n++ 都会增加。
6. 循环结束后,我们需要处理可能剩余的未合并部分。我们检查 pa 是否为空,如果不为空,说明链表 La 中还有未合并的元素,直接将其接入新表 Lc。否则,将 pb 中的未合并元素接入新表 Lc。
+= 是一个复合赋值运算符,它用于将右侧的值加到左侧的值上,并将结果赋值给左侧的变量。在这里,Lc->n += pa ? La->n : Lb->n; 表示:
Lc->n 表示链表 Lc 的元素个数,n 是一个整数变量。
pa ? La->n : Lb->n 是一个条件表达式,它的作用是根据条件选择要加到 Lc->n 上的值。
如果 pa 不为空,即链表 La 中还有剩余元素,那么它将加上 La->n。这表示链表 La 中的元素已经成功合并到 Lc 中,所以将合并后的元素个数添加到 Lc 的元素个数上。如果 pa 为空,但 pb 不为空,即链表 Lb 中还有剩余元素,那么它将加上 Lb->n。这表示链表 Lb 中的元素已经成功合并到 Lc 中,所以将合并后的元素个数添加到 Lc 的元素个数上。
7. 最后,更新新表 Lc 中的元素数量,将其增加未合并元素的数量。
这样,循环结束后,新表 Lc 就包含了合并后的有序递增单链表,而原始链表 La 和 Lb 的内容也发生了相应的变化。这段代码实现了两个有序链表的合并,并且在合并的过程中,根据元素的大小关系,逐个将节点接入新表 Lc。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









