







接上次博客:学会使用MySQL数据库(1)数据库相关背景了解_di-Dora的博客-CSDN博客
目录
SQL语句
操作数据库的命令也称为“SQL语句”,你可以把它理解为一种编程语言。
具体来说,SQL(Structured Query Language)是一种用于操作关系型数据库的标准化查询语言。它被广泛用于管理和操作数据库中的数据。SQL语句用于执行各种任务,包括数据查询、数据插入、数据更新、数据删除以及数据库管理等操作。
SQL是与特定数据库管理系统(如MySQL、Oracle、SQL Server)相关的语言,但它遵循了一般的SQL标准,因此基本的SQL语法在不同的数据库系统之间是相似的。不同的数据库系统可能会有一些特定的扩展和功能,但大多数SQL命令都是通用的。 SQL语句是管理和查询数据库中数据的强大工具,它们被广泛用于应用程序开发、数据分析和数据库管理中。
SQL语句通常可以分为以下几类:
查询语句(SELECT)、插入语句(INSERT)、更新语句(UPDATE、删除语句(DELETE)、创建表语句(CREATE TABLE)、修改表结构语句(ALTER TABLE)、删除表语句(DROP TABLE)
这些语句我们接下来都会一一进行学习~
数据库的基本操作
此处的“数据库”实际上指的是一个逻辑上数据集合。
MySQL数据库使用表格来组织和存储数据,每个表都代表了一种特定类型的数据,并且包含了相关数据的行和列。多个表可以一起组成一个数据库(Database),也就是说,数据库其实是一个逻辑上的容器,用于存储一组相关联的表和数据。
每个数据库是一组相关联的表格的集合,而MySQL服务器负责管理和运行这些数据库。这种结构使得数据可以按照逻辑关系进行组织,从而更好地满足不同应用程序的需求。不同数据库之间是相互独立的,我们可以在同一个MySQL服务器上管理多个数据库,也就是说,一个MySQL服务器上可以有很多个表。
-
数据库(Database): 数据库是一个逻辑容器,用于组织和存储一组相关联的数据表。每个数据库具有唯一的名称,用于区分不同的数据集合。一个MySQL服务器可以容纳多个数据库,每个数据库都是相互独立的,有自己的表格和数据。
-
表格(Table): 表格是数据库中的基本数据存储单元。每个表格代表一种实体或数据类型,例如,可以有一个表格用于存储用户信息,另一个表格用于存储订单信息。表格由行(Rows)和列(Columns)组成,每行代表一个数据记录,每列代表数据记录中的一个字段。
接下来,我们就来看看对数据库的四大基操:
创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name其中:
- CREATE DATABASE: 是SQL的关键字,用于创建一个新的数据库。
- database_name :是你要创建的数据库的名称。这个名称应该是唯一的,用于标识数据库。
-
[IF NOT EXISTS]:方括号表示这部分是可选的。如果指定了IF NOT EXISTS,它的作用是在创建数据库之前检查是否已经存在具有相同名称的数据库。如果已存在同名数据库,且使用了 IF NOT EXISTS ,则不会创建新的数据库,而是保留已有的数据库。这部分的用途是避免SQL报错,实际工作中,我们很多时候是把一系列的SQL语句写到一个文件中然后批量执行,如果其中一条报错,后面的SQL就无法继续执行了。
-
create_specification:这部分表示数据库的创建规范,也是可选的。它用于指定数据库的一些属性,如字符集和排序规则。create_specification 可以包括以下内容:
-
[DEFAULT] CHARACTER SET charset_name:用于指定数据库的默认字符集,其中 charset_name 是字符集的名称。字符集决定了数据库中存储的文本数据的编码方式。如果不指定字符集,将使用数据库管理系统的默认字符集。
-
[DEFAULT] COLLATE collation_name:用于指定数据库的默认排序规则(collation),其中 collation_name 是排序规则的名称。排序规则决定了文本数据的比较和排序方式。如果不指定排序规则,将使用字符集的默认排序规则。
-
可能有同学就要问了:关键字是啥?
数据库关键字: 数据库系统中还可以有特定于数据库管理系统的关键字,用于执行系统级操作,如创建数据库、用户管理等。不同数据库系统(如MySQL、Oracle、SQL Server)可能具有不同的系统关键字。
SQL关键字: SQL(Structured Query Language)是用于数据库管理和查询的语言,它包含一组SQL关键字,用于执行数据库操作,如 SELECT、INSERT、UPDATE、DELETE 等。
我们的数据库名、表明、列名都不能和关键字重复,单词与单词之间至少要有一个空格。
还有,SQL的关键字是大小写不敏感的,你写 create,database……也可以。
SQL都需要以“ ; ”(英文)为结束标志。MySQL 客户端允许输入SQL的时候换行,但是敲下“ ; ”后再回车就代表输入结束了。
上面还有一点我想要着重讲讲:
设置字符集(character set):
创建数据库的时候我们是可以手动指定字符集的:character set 字符集名字 / characset 字符集名字
设置字符集这个操作蛮重要的,因为我们需要在数据库中保存中文,而MySQL默认的字符集是拉丁文,不支持中文,所以我们就必须要在创建数据库的时候手动指定编码方式为支持中文的编码(GBK、UTF8)。
在计算机中,一个汉字占几个字节?
不同的字符集,不同的编码方式下,一个汉字占几个字节都是不同的。
可能有的同学回答“2个字节!!!”,这时学习C语言的时候大家留下的印象,当时我们使用的是VS,在 Windows上写的代码。 Windows 简体中文版的默认字符集是GDK,VS默认的字符集适合系统一致的,也是GDK。在这个情况下一个汉字是占2个字节。
但是GDK现在已经用的越来越少了,我们主要是使用 UTF8 作为编码方式。UTF8 相较于GDK来说最大的特点应该是“变长编码”,里面的字符最短1个字节,最长4个字节,这样就留有一个更大的空间。它不仅仅可以表示中文,也可以表示世界上的任何一种语言文字。如果使用 UTF8编码,一个汉字通常是3个字节。
还有一个编码方式——unicode,一开始学Java字符的时候应该有提过。unicode是给一个一个的字符进行编码的,但是无法给“字符串”进行编码。比如,你把多个unicode编码的字符放到一起,构成一个字符串,就有可能会乱套,因为它无法区分字符和字符之间的边界。
基于unicode就演化出了一些可以给“字符串”编码的版本,比如utf8。
所以在Java中,如果我们谈到 char 类型的,它的内部编码往往是unicode,如果谈到string,内部编码一般是 utf8。当然,Java内部会自动为你完成编码转换。
所以我们在MySQL中就可以通过代码创建数据库的同时指定字符集。但是,MySQL的 utf8 是一个残本,不是完全体的 utf8,它少了一些 emoji 表情,后来MySQL又搞了个 utf8mb4,这个就是完全体的了,但是这东西是MySQL独有的,其他地方是见不到的。
如果系统没有 db_test 的数据库,则创建一个使用utf8mb4字符集的 db_test 数据库,如果有则不创建:
CREATE DATABASE IF NOT EXISTS db_test CHARACTER SET utf8mb4;MySQL的utf8编码不是真正的utf8,没有包含某些复杂的中文字符。MySQL真正的utf8是 使用utf8mb4,建议大家都使用utf8mb4
每种字符集都是一个巨大的码表,你可以在网上搜到这些码表。
查看数据库
列出当前的MySQL服务器上一共都有哪些数据库:
SHOW DATABASES;里面的数据库有些是系统自带的(红色框框),有些是我创建的:
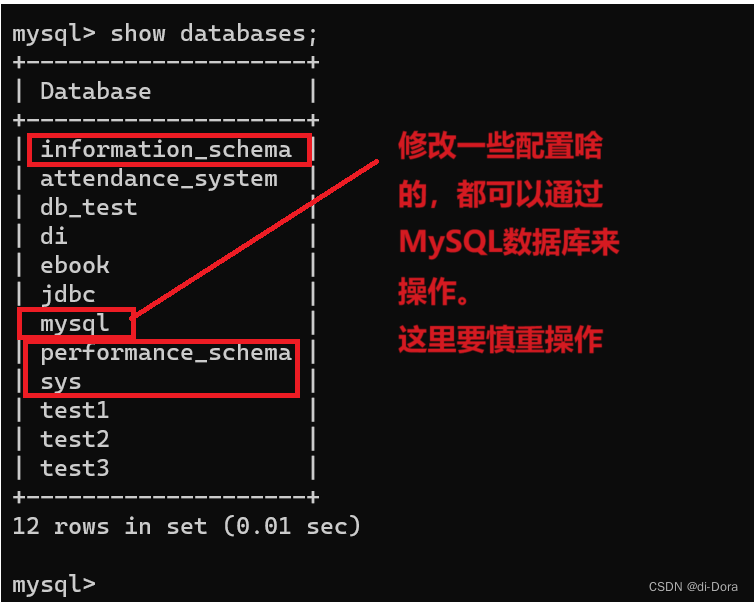
数据库中的内容都是持久化存储的,后续重启电脑啥的数据都是仍然存在的。
选中数据库
use 数据库名;数据库中最重要的操作就是针对表“增删改查”。表是从属于数据库的,要针对表操作,就需要先把当前选定的是那个数据库这个事情指定清楚。
删除数据库
数据库删除以后,内部看不到对应的数据库,里边的表和数据全部被删除。
DROP DATABASE [IF EXISTS] db_name;
drop database if exists db_test1;
drop database if exists db_test2;删除数据库操作是一个非常危险的操作。
很多时候公司未来避免出现删库的误操作,会采取一些措施:
-
权限控制:
- 通常,只有数据库管理员(DBA)或具有高级权限的用户才能执行危险的操作,如删除数据库。确保只有经过授权的人才能执行这些操作可以有效减少误操作的风险。
- 定期审查和更新权限:确保权限仍然符合业务需求,定期审查和更新权限列表。
-
备份和恢复:
- 定期备份数据:创建定期的数据库备份,以便在数据丢失或损坏时进行恢复。
- 自动化备份:使用自动化工具来定期创建备份,确保备份是可靠的。
- 测试恢复流程:定期测试数据库的恢复过程,以确保备份是可恢复的。
-
多人操作和审批流程:
- 实施多人操作原则:对于危险的数据库操作,要求两个或多个人合作执行,并且需要审批。
- 创建审批流程:建立明确的审批流程,以确保数据库操作在经过审核和批准后才能执行。
- 记录审批过程:记录每个操作的审批过程,以追踪谁执行了操作,并且谁批准了操作。
-
事务管理:
- 使用事务:对于需要一致性的操作,使用数据库事务来确保操作要么全部成功,要么全部失败。
- 事务回滚:在发生错误或异常情况下,确保事务能够回滚到原始状态,以维护数据一致性。
-
数据库监控和日志记录:
- 实施监控系统:使用数据库监控工具来监视数据库的性能和活动,检测异常操作。
- 记录数据库活动:启用详细的数据库日志记录,记录数据库操作,以便审计和故障排除。
-
定期维护和更新:
- 定期维护:执行定期的数据库维护任务,如索引重建、统计信息更新,以保持数据库性能。
- 更新数据库软件:及时升级数据库管理系统以获取最新的安全性补丁和功能改进。
-
安全性培训和教育:
- 培训用户和管理员:提供数据库安全性培训,确保用户和管理员了解最佳实践和潜在风险。
- 提高安全意识:促使所有数据库用户和管理员对数据库安全性问题保持警惕,报告异常操作和安全威胁。
MySQL中支持的数据类型
数值类型:
分为整型和浮点型
| 数据类型 | 大小 | 说明 | 对应java类型 |
| BIT[ (M) ] | M指定位数,默认为1 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | 常用Boolean对应BIT,此时 默认是1位,即只能存0和1 |
| TINYINT | 1字节 | Byte | |
| SMALLINT | 2字节 | Short | |
| INT | 4字节 | Integer | |
| BIGINT | 8字节 | Long | |
| FLOAT(M, D) | 4字节 | 单精度,M指定长度,D指定小数位数,会发生精度丢失 | Float |
| DOUBLE(M, D) | 8字节 | Double | |
| DECIMAL(M, D) | M/D最大值+2 | 双精度,M指定长度,D表示小数点位数,精确数值 | BigDecimal |
| NUMERIC(M, D) | M/D最大值+2 | 和DECIMAL一样 | BigDecimal |
1、(M,D):
- ():用来描述精度;
- M:表示小数的长度;
- D:表示小数点后的位数
- 例如: DOUBLE(3,1):长度是3,小数点后是1,像是99.5,19.0……
2、此处的 float 和 double 都是和Java/C 类似的,都是IEEE 754标准的浮点数,这些数据类型具有一定的精度限制,可能存在精度损失和舍入误差。用“==”来比较两个浮点数是非常危险的,0.1+0.2 != 0.3
3、为了解决上述精度丢失的问题,数据库引入了DECIMAL:
DECIMAL(或 NUMERIC)数据类型的存储方式与其他浮点数数据类型(如FLOAT和DOUBLE)不同。DECIMAL数据类型以一种不同的方式存储数值,通常使用字符串或者固定长度的二进制表示,而不是二进制浮点数表示。
DECIMAL数据类型存储精确的十进制数值,通常用于需要保持数值精度和避免浮点数精度问题的场景,如货币金额或精确计算。存储方式通常采用以下两种之一:
-
字符串存储: 在某些数据库系统中,
DECIMAL数据类型的值会以字符串的形式存储,其中包含数字和小数点。这种方式可以确保数值的精度不受二进制浮点数表示的限制。例如,一个DECIMAL(10,2) 列可以存储类似于 "12345.67" 的字符串。 -
固定长度的二进制存储: 在其他数据库系统中,DECIMAL数据类型的值可能会以固定长度的二进制表示方式存储。这种方式也可以确保数值的精度,因为它不受浮点数精度问题的影响。每个DECIMAL的值都占据固定数量的字节,不会有舍入误差。
无论使用哪种存储方式,DECIMAL数据类型的值都被视为精确数值,而不会涉及到浮点数的近似表示。这使得它非常适用于需要高精度计算的场景,如金融和精确的计算应用。
但需要注意,由于其精确性,DECIMAL数据类型可能占用更多的存储空间,因此在设计数据库时需要权衡存储空间和精度的需求,而且,Decimal也舍弃了运算速度。
Decimal 存储小数的方式使用十进制浮点数格式,也称为 BCD(Binary-Coded Decimal)格式。它是一种精确表示小数的方式,主要用于需要高精度计算的场景,例如财务和货币计算。
Decimal 的存储方式主要有以下特点:
- 尾数是十进制数:Decimal 使用十进制数表示尾数,每位数值为 0 到 9,因此可以直接精确表示小数部分,而不会产生二进制浮点数舍入误差。
- 无指数:与 IEEE 754 不同,Decimal 不使用指数来表示小数点位置。相反,它采用固定点数格式,小数点的位置在尾数中是固定的。
- 精度固定:Decimal 有固定的精度,通常是 28 位或更多位小数。这意味着在计算过程中不会出现浮点数精度损失,从而得到更高的计算精度。
相比之下,IEEE 754 是一种采用二进制浮点数格式来表示小数的方式。它使用尾数和指数的组合来表示小数值,可以表示非常大范围的数值,但在高精度小数计算时可能会存在舍入误差。
Decimal 和 IEEE 754 的主要区别在于数据表示的方式。Decimal 使用十进制表示尾数,没有指数,因此可以精确地表示小数值。而 IEEE 754 使用二进制表示尾数和指数,可以表示更广泛的数值范围,但在高精度计算时会出现浮点数精度损失。
由于 Decimal 的精度固定,没有浮点数精度损失的问题,因此它在涉及高精度小数计算的场景中,例如金融和货币计算,更适合使用,能够提供更高的计算精度。
4、Decimal 对应 java 的类型是BigDecimal:
BigDecimal 是 Java 中提供的一个用于高精度小数计算的类。它可以用于执行精确的十进制运算,避免了浮点数精度问题,特别适用于财务和货币计算等需要高精度的场景。
以下是 BigDecimal 类的一些重要特点和功能:
- 高精度:BigDecimal 可以处理任意位数的小数,没有固定的精度范围,因此能够执行高精度计算,避免了浮点数精度损失。
- 精确运算:BigDecimal 提供了精确的加、减、乘、除等运算方法,确保计算结果的精确性。
- 支持舍入模式:在执行除法运算时,可以指定舍入模式来决定结果的舍入方式,如ROUND_UP、ROUND_DOWN、ROUND_CEILING 等。
- 不可变性:BigDecimal 是不可变类,一旦创建了一个 BigDecimal 对象,其值不可更改。每个运算都会返回一个新的 BigDecimal 对象,保持了数据的完整性。
- 支持精确对比:BigDecimal 提供了 equals() 和 compareTo() 方法,用于精确比较两个 BigDecimal 对象是否相等或大小关系。
- 构造方法:可以使用不同的构造方法创建 BigDecimal 对象,包括使用字符串、整数或浮点数来表示数值。
- 异常处理:在出现无法精确表示的数值或除以零等异常情况时,BigDecimal 会抛出 ArithmeticException 异常。
使用 BigDecimal 时需要注意以下几点:
- 在进行 BigDecimal 的运算时,要确保使用 BigDecimal 的方法进行计算,而不是直接使用普通的算术运算符。
- 要格外注意在除法运算中指定舍入模式,以确保结果的精确性。
- 创建 BigDecimal 对象时,建议使用字符串来表示数值,避免使用浮点数,以免造成精度损失。
由于 BigDecimal 提供了高精度的十进制计算,它在需要精确计算的场景中是一个非常有用的工具。
5、MySQL也提供了无符号版本的数据类型(unsigned),但是官方文档上明确写了不建议使用,会在未来版本废除。Java中没有无符号类型,python和JS也没有。因为无符号类型的数据相减可能会产生溢出的情况:10(un) - 20(un) = 一个很大的数字。
字符串类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
| VARCHAR (SIZE) | 0-65,535字节 | 可变长度字符串 | String |
| TEXT | 0-65,535字节 | 长文本数据 | String |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 | String |
| BLOB | 0-65,535字节 | 二进制形式的长文本数据 | byte[] |
1、 VARCHAR (SIZE)里面的(SIZE)表示该类型里最多能存储几个字符(不是字节!)。
当你写了SIZE为10,不是说,当前就立即分配10个字符的存储空间,而是会先分配一个比较小的空间,如果不够再自动扩展,最大的空间不会超过10。
2、VARCHAR适合较短的文本,TEXT适合较长的文本,而MEDIUMTEXT适用于更大的文本内容。
3、BLOB是存储二进制数据的。数据分为文本数据(存储的都是字符,这些字符都是可以在对应的码表上查到的)和二进制数据(在码表上查不到的就是二进制数据,比如音乐、图片、视频等等)。
一般我们很少会在数据库中的某一列中存储特别大的数据(一张图片可能就会超过64k),这么做会大大影响到数据库的增删改查的效率。
实际开发中如果需要保存图片,一般都是把图片单独放到专门的目录中,然后让数据库保存图片的路径。
日期类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
| DATETIME | 8字节 | 范围从1000到9999年,不会进行时区的检索及转换。 | java.util.Date、 java.sql.Timestamp |
| TIMESTAMP | 4字节 | 范围从1970到2038年,自动检索当前时 区并进行转换。 | ava.util.Date、 java.sql.Timestamp |
1、TIMESTAMP——时间戳:
时间戳是指一个特定时间点在计算机或其他系统中的表示方式。它通常是一个数字或字符串,用于记录一个事件或数据在某个特定时间发生或创建的日期和时间信息。
在计算机科学和编程中,时间戳通常是一个表示自特定固定时间(通常是1970年1月1日 00:00:00 UTC)经过了多少秒或毫秒的整数值。这种时间表示方式称为Unix时间戳或Epoch时间。例如,Unix时间戳为0表示1970年1月1日 00:00:00 UTC,而Unix时间戳为1612345678表示2021年2月3日 12:34:38 UTC。
计算当前时刻和基准时刻的秒数/毫秒数。微秒数/……之差,通过这样的计算,计算机就会知道当前的时间是啥了,并且系统一般会提供一些API帮我们去进行一些时间戳和格式化时间的相互转换。
但是使用4个字节的这个秒级时间戳其实都已经捉襟见肘。当前的时间都快要超过4个字节的范围了(有符号数:-21亿~21亿;无符号数:0~42亿9千万)(Java中没有无符号类型,MySQL中虽然有,但是也不推荐用),差不多到2038年,4个字节就无法继续表示秒级时间戳了。
所以现在我们多是使用这个8个字节的DATETIME。
2、DATETIME 类型的值可以是类似于 "2023-09-13 14:30:45" 的时间戳,包括年、月、日、小时、分钟和秒的信息。
如果我们只需要表示日期而不包括时间,可以考虑使用 DATE 数据类型,它只包含年、月、日的信息。但是如果我们需要更高精度的时间表示,就需要考虑使用 TIMESTAMP 数据类型,它包括毫秒级的时间信息。
在Java中,DATETIME这个类型只能表示年月日,不能表示时分秒,所以我们一般用TIMESTAMP 数据类型,好在Java中的这个类型是8个字节的毫秒级时间戳。
数据表的操作
针对数据表的操作,前提是选中数据库。
一个表包含很多行,每一行也称为一条记录;一行里可以有很多列,每一列也称为是一个字段,每个列都有一个具体的类型。
创建表
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
);-
CREATE TABLE:这是 SQL 命令的一部分,用于指示要创建一个新的数据库表。
-
table_name:这是你要创建的表的名称。表名通常用来标识和引用该表。如果你确实想让表名/列名和关键字一样,那么你可以使用反引号“ ` ”(英文)来吧表名/列名引起来。
-
( field1 datatype, field2 datatype, field3 datatype ):这部分是表的列定义,包括列名和数据类型。具体解释如下:
-
field1, field2, field3:这些是表的列名,用于标识每个表列的名称。
-
datatype:这里应该指定每个列的数据类型。数据类型定义了每个列可以存储的数据的类型。例如,可以使用数据类型如 INT(整数)、VARCHAR(可变长度字符串)、DATE(日期)等。
-
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
age INT,
position VARCHAR(100)
);
可以使用comment增加字段说明。
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '员工ID',
name VARCHAR(255) COMMENT '员工姓名',
age INT COMMENT '员工年龄',
position VARCHAR(100) COMMENT '员工职位'
);
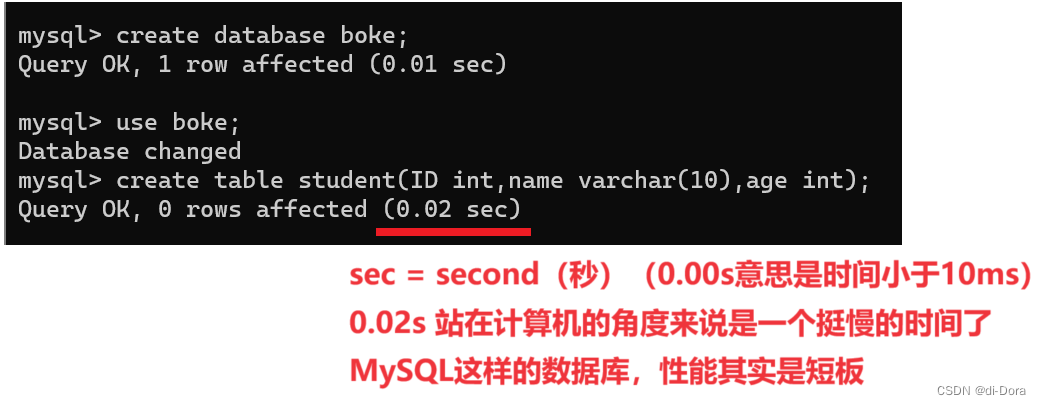
查看该数据库中所有的表
查看当前数据库中的所有表:一定要先选定一个数据库,不然就会出现“No database selected”的报错信息。
SHOW TABLES; 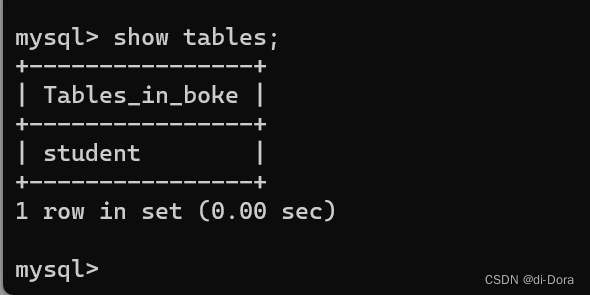
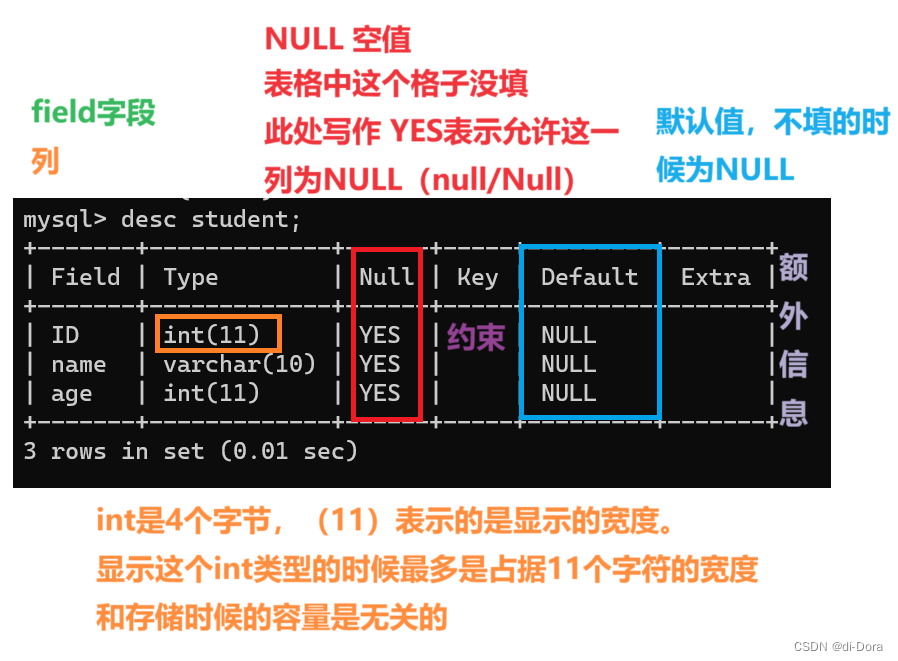
查看指定表的结构
desc = describle
desc 表名;
删除表
删除表的同时也会把表里的数据给一起删除掉。
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...删除表也一定要慎重,是非常危险的!
删除表的严重性可能比删除数据库更严重!因为如果是删库操作,程序会第一时间报错,你就可能通过处理把之前备份的数据恢复回去。但是如果是删表操作,程序就不一定第一时间报错了,发现的时间就会更晚,程序就以错误的状态在生产环境中有运行了很长时间。
-- 删除 stu_test 表
drop table stu_test;
-- 如果存在 stu_test 表,则删除 stu_test 表
drop table if exists stu_test;
一些小练习:MySQL里面的注释是在前面加““--空格+描述”
mysql> -- 创建数据库
mysql> create database if not exists bit32mall
-> default character set utf8 ;
Query OK, 1 row affected (0.00 sec)
mysql> -- 选择数据库
mysql> use bit32mall;
Database changed
mysql> -- 创建数据库表
mysql> -- 商品
mysql> create table if not exists goods
-> (
-> goods_id int comment '商品编号',
-> goods_name varchar(32) comment '商品名称',
-> unitprice int comment '单价,单位分',
-> category varchar(12) comment '商品分类',
-> provider varchar(64) comment '供应商名称'
-> );
Query OK, 0 rows affected (0.03 sec)
mysql> -- 客户
mysql> create table if not exists customer
-> (
-> customer_id int comment '客户编号',
-> name varchar(32) comment '客户姓名',
-> address varchar(256) comment '客户地址',
-> email varchar(64) comment '电子邮箱',
-> sex bit comment '性别',
-> card_id varchar(18) comment '身份证'
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> -- 购买
mysql> create table if not exists purchase
-> (
-> order_id int comment '订单号',
-> customer_id int comment '客户编号',
-> goods_id int comment '商品编号',
-> nums int comment '购买数量'
-> );
Query OK, 0 rows affected (0.01 sec)
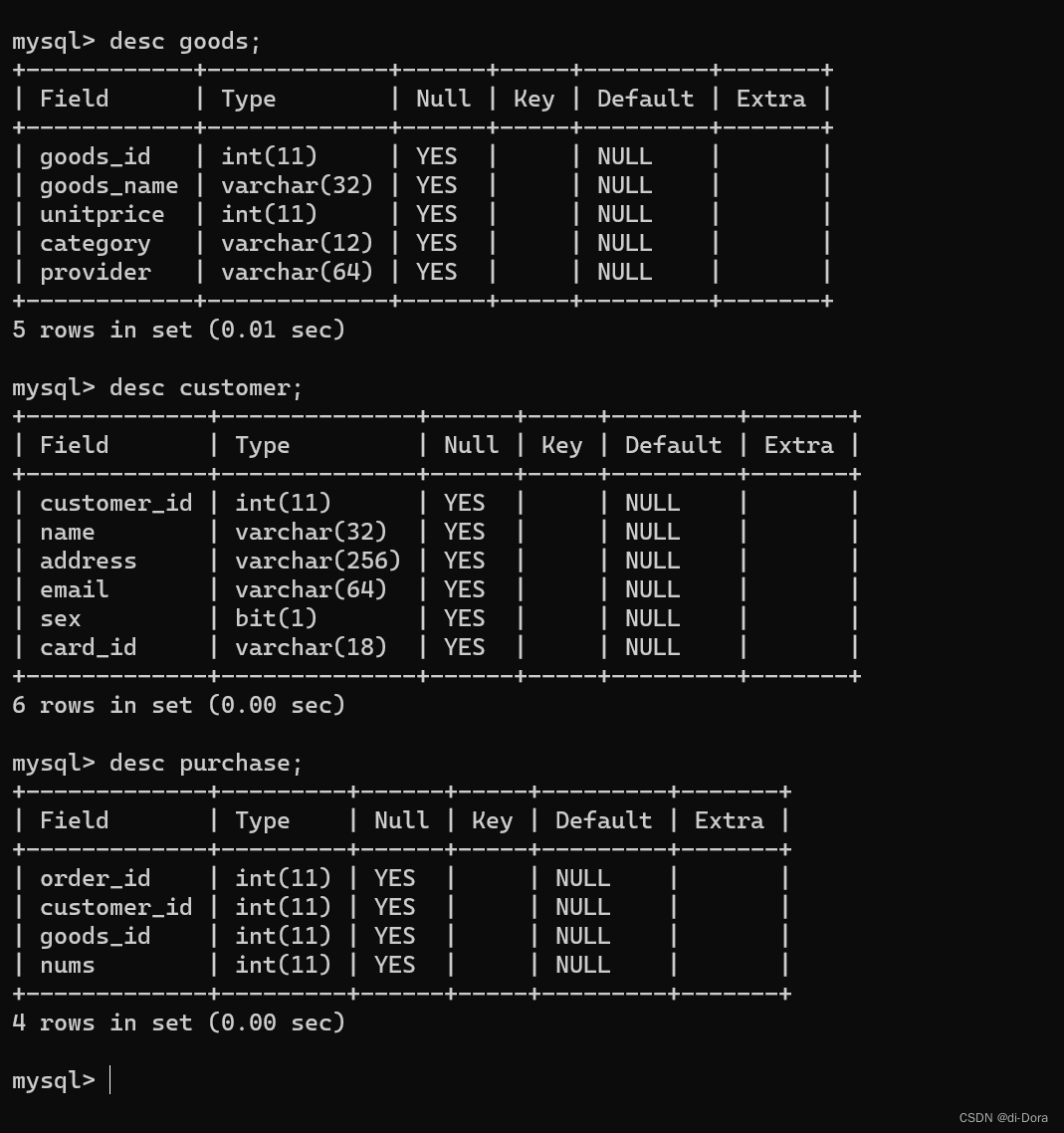
这里需要提一点,涉及到金额时,一般都是带小数的,那么我们应该用什么数据类型?
用DOUBLE吗?不可以啊,算钱一定要算的精确;
那么用DECIMAL?可以是可以,但是效率又太低;
最好的选择时使用 INT,此时我们以分为单位,做一个单位转换即可。
MySQL表的增删改查
CRUD,即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写。
新增(Create)
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...-
INSERT INTO table_name:这部分指定了要插入数据的目标表的名称。
-
[(column [, column] ...)]:这部分是可选的,用于指定要插入数据的列。如果你不指定列名,将会插入所有表的列中。如果你只想为部分列插入数据,可以在括号中列出列名。
-
VALUES (value_list) [, (value_list)] ...:这部分指定了要插入的数据值。每个 value_list 包含了要插入的一行数据的值,这些值按照表的列顺序排列。
-
value_list: value, [, value] ...:这部分指定了每个数据行中的值,以逗号分隔。每个值必须与表的对应列数据类型相匹配。
-- 创建一张学生表
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT,
sn INT comment '学号',
name VARCHAR(20) comment '姓名',
qq_mail VARCHAR(20) comment 'QQ邮箱'
);单行数据 + 全列插入
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
INSERT INTO student VALUES (100, 10000, '李雷', NULL);
INSERT INTO student VALUES (101, 10001, '韩梅梅', '13416');多行数据 + 指定列插入
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致
INSERT INTO student (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙悟空');
在指定列插入时,剩下的没有被指定的列就会被填充成默认值。
SQL没有“字符”这个类型,所以可以使用 ' 或者 " 来表示字符串。
一次插入多行记录,相比于一次插入一行,分多次插入,要快很多。
因为MySQL是一个客户端服务器结构的程序。
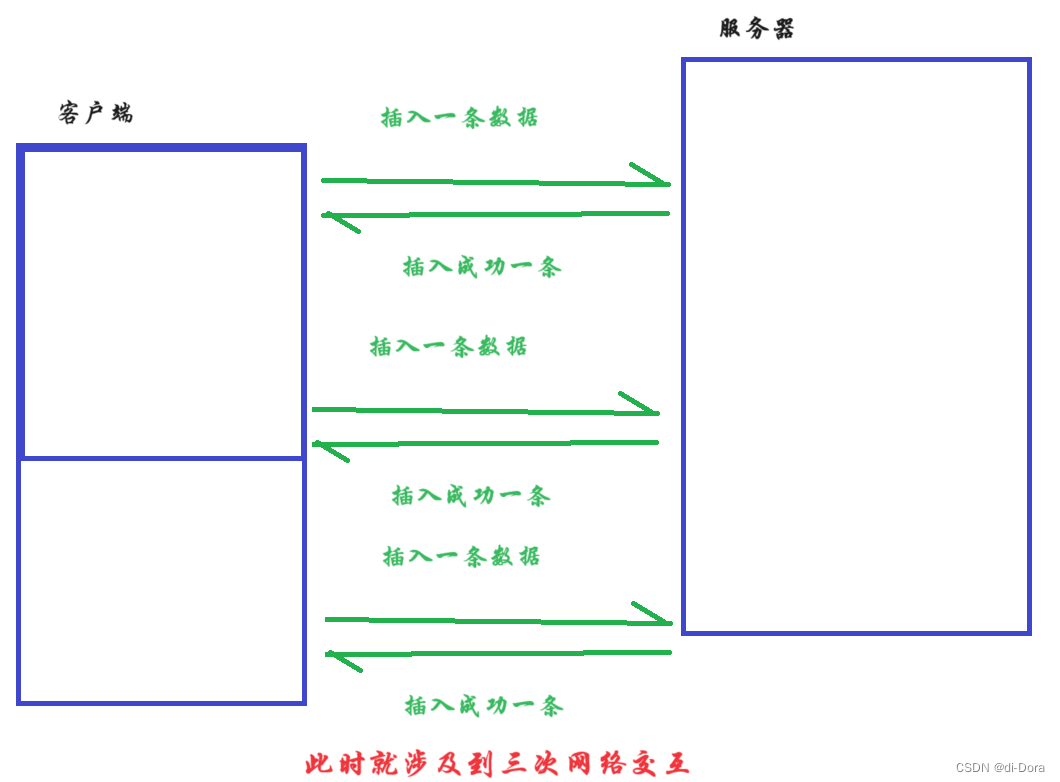
只用交互一次:
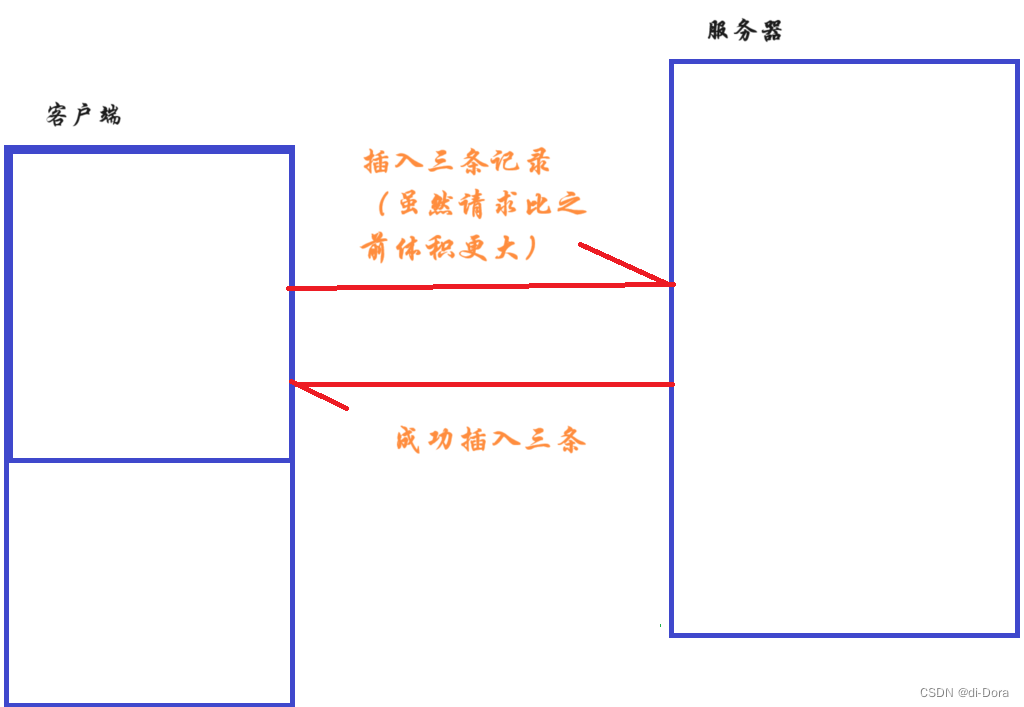


这里的提示就是反馈效果,客户端给服务器发起插入请求,服务器要返回这次 插入操作是否成功了。
-- 创建学生考试成绩表
CREATE TABLE student_scores (
student_id INT PRIMARY KEY,
student_name VARCHAR(50),
exam_date DATETIME,
subject VARCHAR(20),
score DECIMAL(3, 1)
);
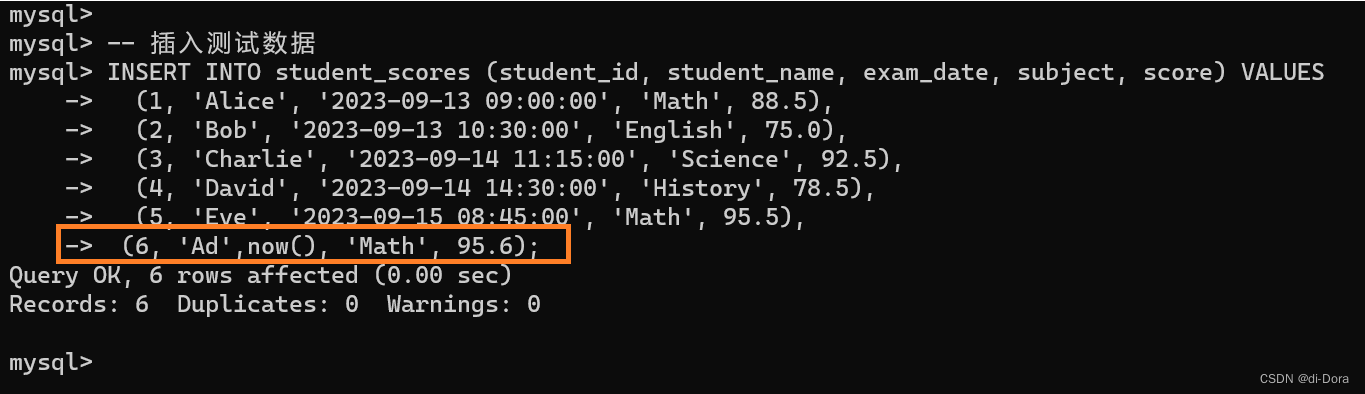
-- 插入测试数据
INSERT INTO student_scores (student_id, student_name, exam_date, subject, score) VALUES
(1, 'Alice', '2023-09-13 09:00:00', 'Math', 88.5),
(2, 'Bob', '2023-09-13 10:30:00', 'English', 75.0),
(3, 'Charlie', '2023-09-14 11:15:00', 'Science', 92.5),
(4, 'David', '2023-09-14 14:30:00', 'History', 78.5),
(5, 'Eve', '2023-09-15 08:45:00', 'Math', 95.5);
上面的例子很好的补充了我们该如何插入一个DATETIME的类型:
用一个固定格式的字符串来表示日期: 类似'2023-09-13 09:00:00'
如果我们想填写的时间日期就是当前的时刻,该怎么办?
SQL提供了一个现成的函数——now( ):
查询(Retrieve)
看到现在,你可能会觉得SQL的增删改都挺简单的,但是到了查询,我们的内容一下子就丰富起来了!先来简单看看语法吧!
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
为了学习“查询”的SQL语句,我们先来搞张表:
-- 创建学生信息表
DROP TABLE IF EXISTS student_info;
CREATE TABLE student_info (
id INT,
full_name VARCHAR(50),
age INT,
gender VARCHAR(10),
major VARCHAR(50)
);
-- 插入测试数据
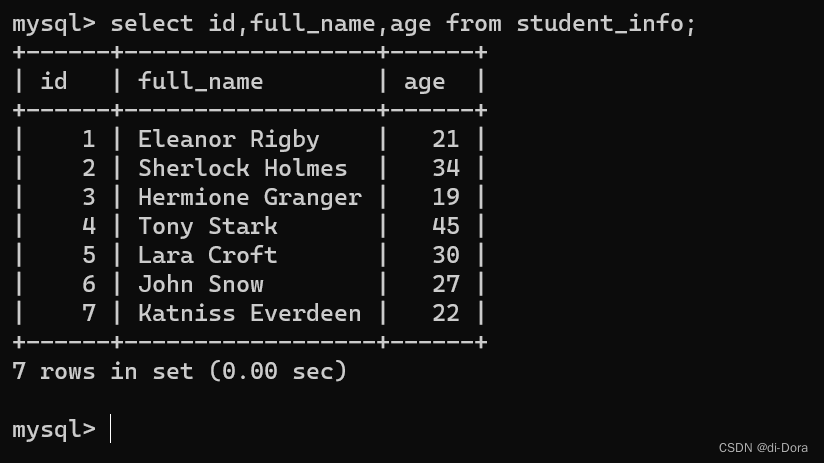
INSERT INTO student_info (id, full_name, age, gender, major) VALUES
(1, 'Eleanor Rigby', 21, 'Female', 'Music'),
(2, 'Sherlock Holmes', 34, 'Male', 'Detective Science'),
(3, 'Hermione Granger', 19, 'Female', 'Magic Studies'),
(4, 'Tony Stark', 45, 'Male', 'Engineering'),
(5, 'Lara Croft', 30, 'Female', 'Archaeology'),
(6, 'John Snow', 27, 'Male', 'Winter Studies'),
(7, 'Katniss Everdeen', 22, 'Female', 'Survival Skills');
全列查询
全列查询(Full-Column Scan)是数据库查询中的一个术语,指的是在数据库表中检索所有列的数据,而不仅仅是特定列或特定条件下的列。
当我们执行全列查询时,数据库系统会扫描整个表的每一行,并返回每一行中所有列的数据。
-
没有指定特定的列:如果查询语句中没有指定要检索哪些列,而是使用通配符(如SELECT *),则会执行全列查询,返回所有列的数据。
-
需要获取完整的行数据:某些查询需要获取完整的行数据,而不仅仅是特定列的数据。这可能发生在需要对整行进行计算、过滤或排序的情况下。
-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用
SELECT * FROM exam_result;这里是查询出来之后,服务器通过网络把这些数据返回给客户端的。并且在客户端以表格的形式打印出来:

MySQL 是一个“客户端-服务器”结构的程序,客户端这里进行的操作都会通过请求发送给服务器,服务器查询的结果就会听过响应返回给客户端。如果数据库当前这个表中的数据特别多就可能会产生问题!!!
1、读取硬盘,把硬盘的IO给跑满了。此时程序的其他部分想访问硬盘就会非常慢;
2、操作网络,可能把网卡的的带宽也跑满了,此时其他客户端想通过网络访问服务器也会非常慢。
这些拥堵就可能导致客户端无法顺利访问到数据库,进一步也就对整个系统造成影响,相当于我们的数据库服务器彻底挂了……
所以,尽管全列查询在某些情况下是必要的,但它通常会导致较大的性能开销,特别是对于包含大量行和列的大型表格。因此,在实际应用中,我们最好只检索需要的列数据,以提高查询性能。可以通过明确指定要检索的列,而不是使用通配符,来避免执行全列查询。这将减少数据传输和处理的负担,从而提高查询效率。
指定列查询
指定列查询(Column Projection)指的是在查询语句中明确指定要检索的列,而不是检索整个表中的所有列数据。这样做的目的是为了减少查询的开销,提高查询性能,并减少数据传输的负担。
当进行指定列查询时,查询语句中的SELECT子句会列出需要检索的列名,而不是使用通配符(如SELECT *)来表示要获取所有列的数据。
指定列查询的优点包括:
-
减少数据传输:只检索需要的列可以减少从数据库服务器到客户端的数据传输量,节省带宽和降低延迟。
-
提高性能:只检索需要的列可以减少数据库系统的计算和 IO 开销,从而提高查询性能。
-
降低内存消耗:只存储需要的列数据可以减少内存消耗,对于大型数据集或内存有限的系统尤为重要。
-- 指定列的顺序不需要按定义表的顺序来
--select 列名,列名 …… FROM 表名
SELECT id,full_name,major
FROM student_info;
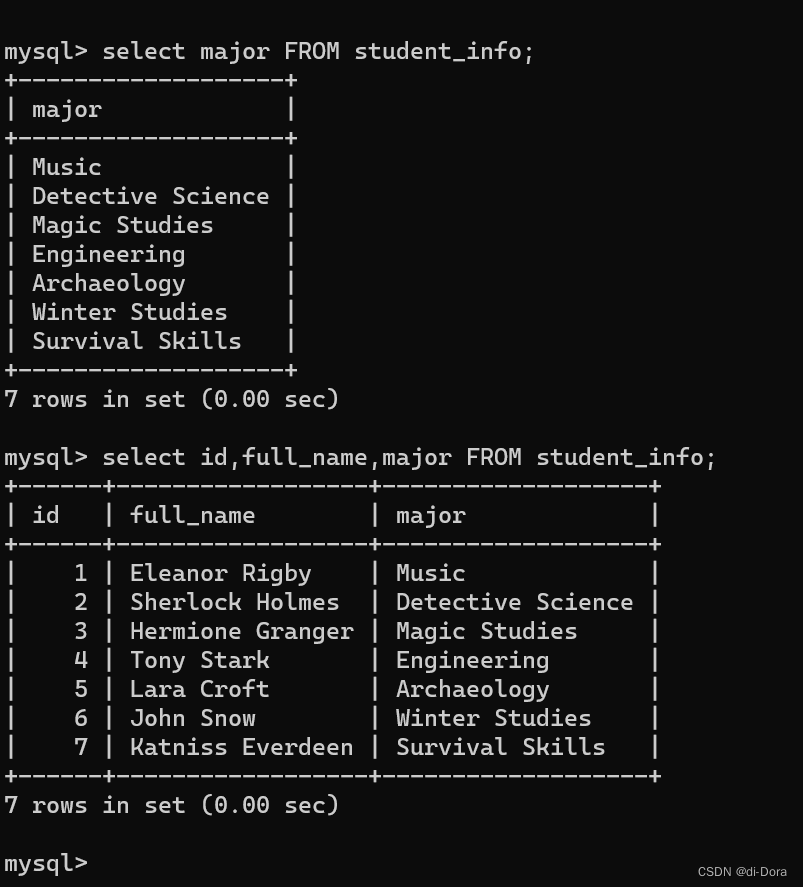
查询字段为表达式
"查询字段为表达式" 指的是在数据库查询中,查询的结果列不仅可以直接来自数据库表中的列,还可以通过表达式计算生成。这些表达式可以包括各种数学运算、逻辑运算、字符串操作、函数调用等,用于生成结果集中的列值。这些表达式允许在查询过程中对数据进行计算、转换或操作,而不仅仅是简单地选择数据库表中的列。
- 一边查询一边进行计算:在查询的时候写出由列名构成的表达式,把指定列中的所有行带入表达式中参与计算。
- 可以进行一些简单的统计操作:表达式查询时列和列之间的运算,把每一行都带入这样的运算中,而不是行和行之间的计算
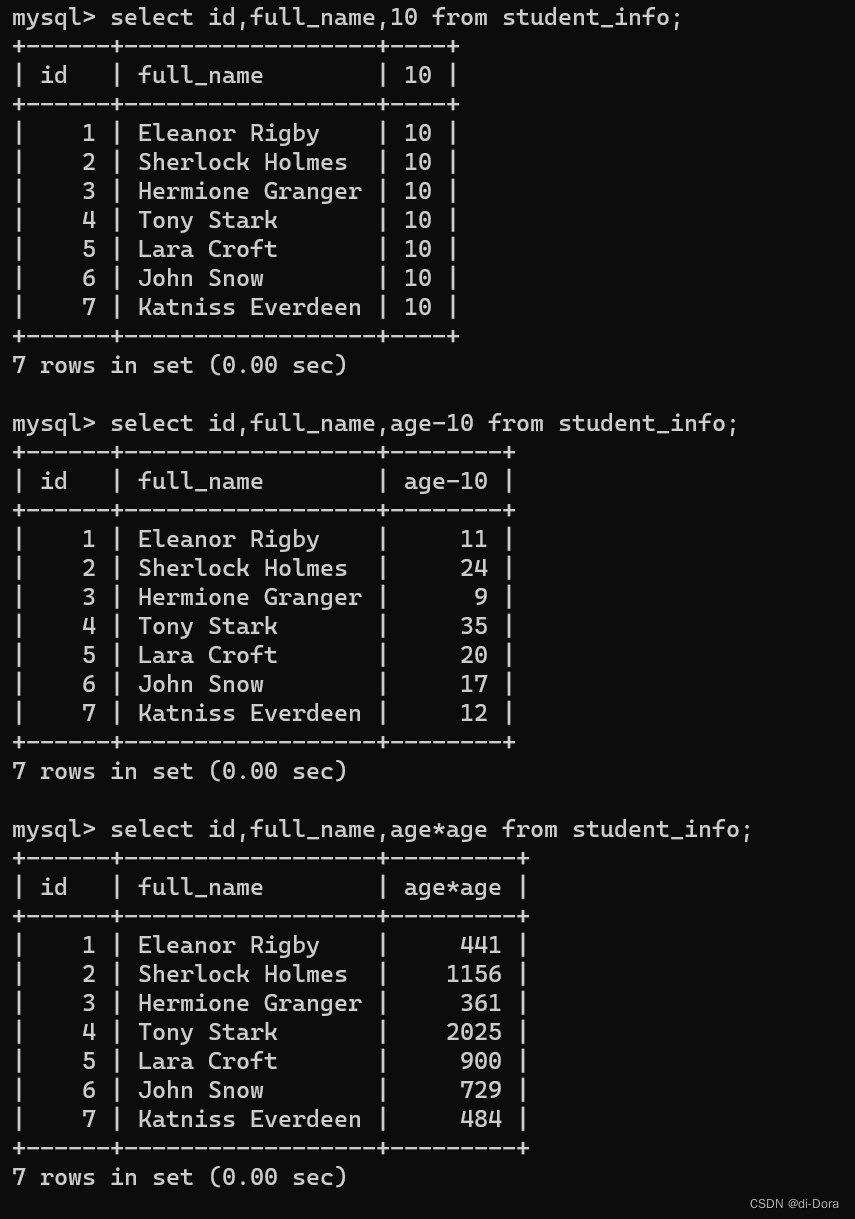
-- 表达式不包含字段
select id,full_name,10 from student_info;
-- 表达式包含一个字段
select id,full_name,age*10+6 from student_info;
-- 表达式包含多个字段
select id,full_name,age+id*3 from student_info;
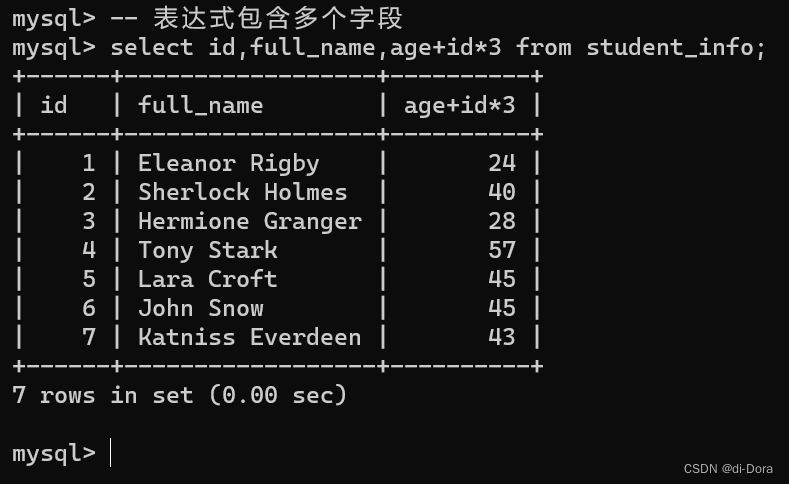
上述操作并不会修改数据库服务器上的原始数据,只是在最终响应里的“临时结果”做了计算。
“客户端——服务器”结构的数据库进行查询的时候是把服务器里的数据读出来,计算后返回给客户端,并且以临时表的形式展示。这些计算结果会存储在查询的临时结果集中,而不会对实际数据库中的数据进行修改。
在查询字段为表达式时,可以进行各种计算和操作,以根据查询的需要生成所需的列值。这允许我们在查询过程中执行动态的数据操作,而不仅仅是简单地检索原始数据。这对于生成复杂的报表、计算汇总统计信息、筛选数据和进行数据转换非常有用。
别名
查询的时候可以给列/表达式指定别名,甚至是给表。
在 SQL 查询中,我们可以通过使用别名为列、表达式和表指定更易读或更具描述性的名称,以提高查询结果的可读性。
别名是通过使用AS关键字来定义的,AS关键字是可以被省略而直接使用空格的。但是不建议!
SELECT column [AS] alias_name [...] FROM table_name;
--列指定别名:
SELECT first_name AS "First Name", last_name AS "Last Name"
FROM employees;
--"first_name" 和 "last_name" 列被赋予了别名 "First Name" 和 "Last Name",使查询结果更易读。
--为表达式指定别名:
SELECT id, name, (chinese + math + english) AS "Total Score"
FROM exam_result;
--这里,表达式 (chinese + math + english) 被赋予了别名 "Total Score",以描述总分列的含义。
--为表指定别名:
SELECT id, name
FROM exam_result AS "Exam Scores";
-- 结果集中,表头的列名=别名
SELECT id, full_name,age-id-12 入职年头 FROM student_info;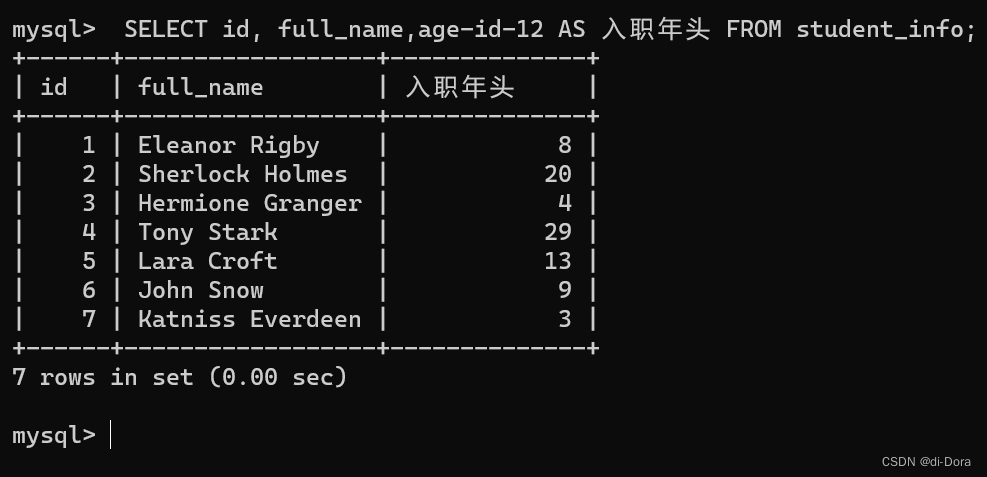
去重:DISTINCT
DISTINCT 是 SQL 查询中的一个关键字,用于去除查询结果集中的重复行,只保留唯一的行。当我们在查询中使用 DISTINCT 时,它会在查询结果中基于指定列的唯一值来进行去重操作。
我们重新搞个表:
-- 创建考试成绩表
DROP TABLE IF EXISTS exam_result;
CREATE TABLE exam_result (
id INT,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
);
-- 插入测试数据
INSERT INTO exam_result (id,name, chinese, math, english) VALUES
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98.5, 90),
(4,'曹孟德', 82, 84, 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);
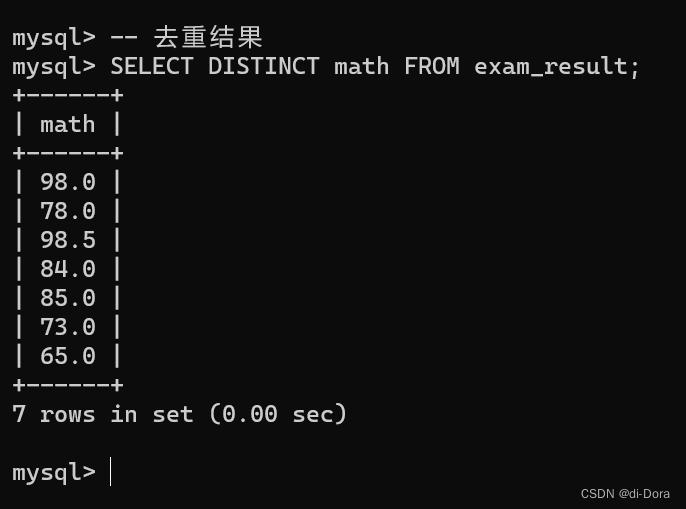
在这个查询中,DISTINCT 关键字用于去除 "exam_result" 表中 "math" 列中的重复值。查询结果将只包含唯一的成绩,而重复的成绩将被去除:
-- 去重结果
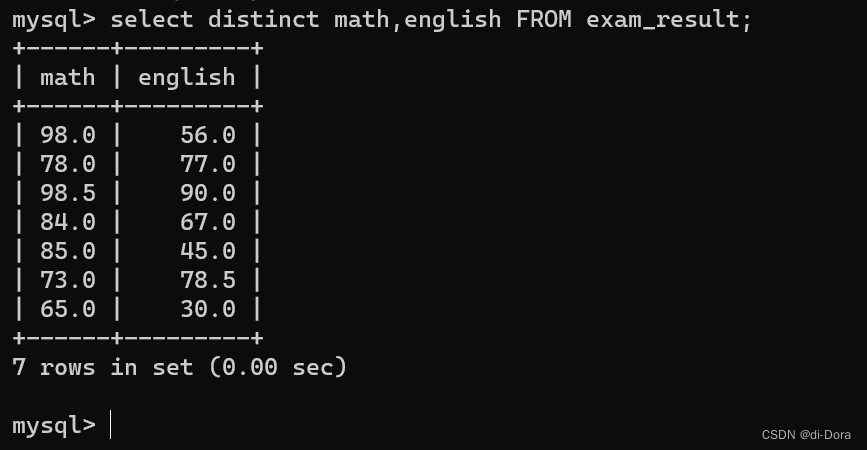
SELECT DISTINCT math FROM exam_result;
DISTINCT 可以应用于一个或多个列,以便根据这些列的组合来去除重复行:
SELECT DISTINCT math,english FROM exam_result;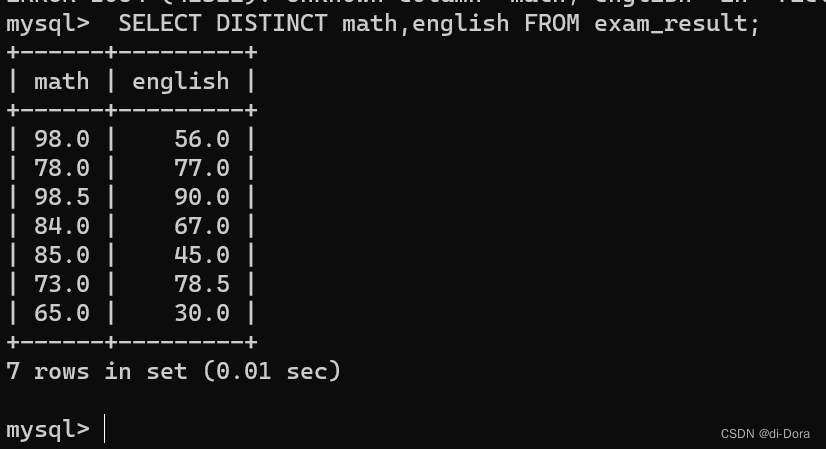
我天我天,怎么回事?为啥math里面重复的98并没有被去掉?去重操作没生效吗?
不是没生效,而是此处DINSTINCT修饰的是多个列,它要求多个列的组合在同一行的数据都相同才会去重。这意味着它会根据指定的多个列的唯一组合来去除重复行。
此时我们新增一条数据,然后再去重操作: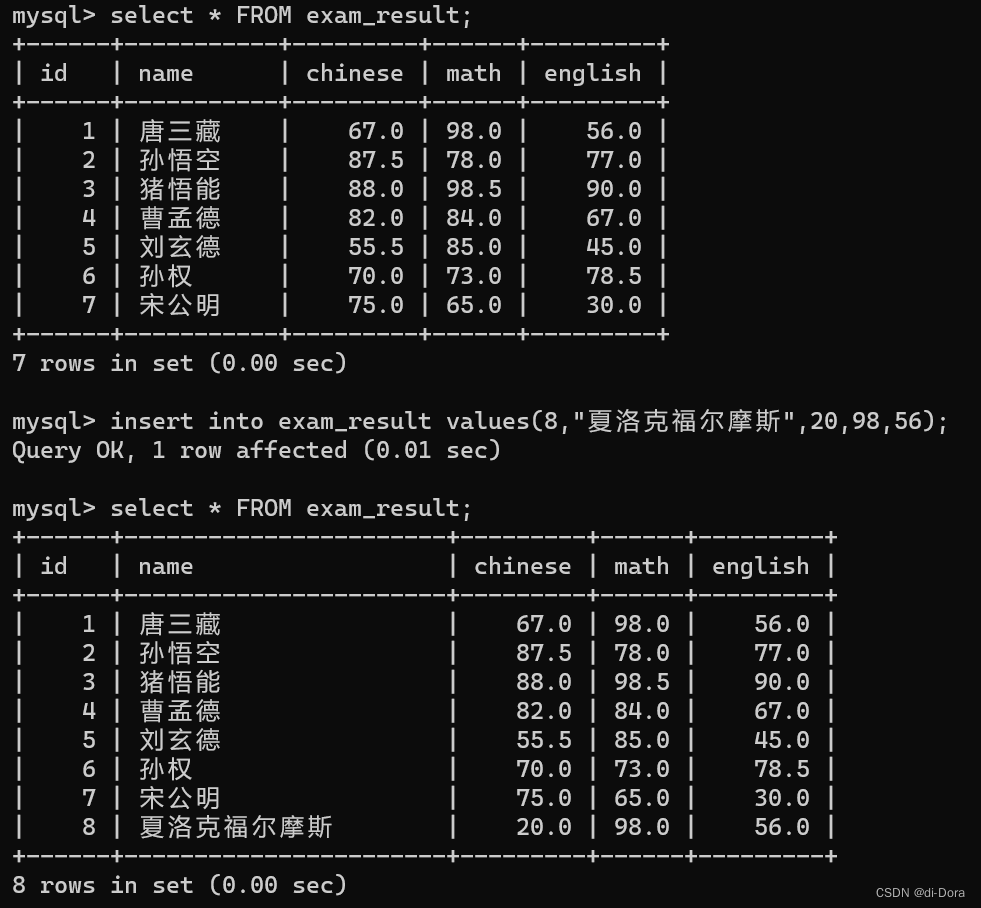
去重操作其实算是一个比较低效的操作,找到每一行都会去查看这一行是否在之前存在过。
排序:ORDER BY(对行)
ORDER BY 是 SQL 查询中的一个子句,用于对查询结果进行排序。具体来说,ORDER BY 子句允许我们指定一个或多个列,以便按照这些列的值对查询结果的行进行排序。
这里的排序仍然是针对临时数据来展开的,此处的排序不影响原有数据在MySQL服务器上存储的顺序。
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
- SELECT 语句用于选择要检索的列,是针对行的排序。
- FROM 语句用于指定要从中检索数据的表。
- ORDER BY 语句用于指定排序顺序的列,可以是一个或多个列,每个列都可以附带排序方向(升序 - ASC,降序 - DESC)。
1. 没有 ORDER BY 子句的查询,返回的顺序是未定义/不确定/无序的,永远不要依赖这个顺序 。毕竟当前只是在我们自己的机器上进行了简单的操作,虽然好像看起来顺序没变,但是如果进行的是一些更复杂的操作,结果就不一定了;
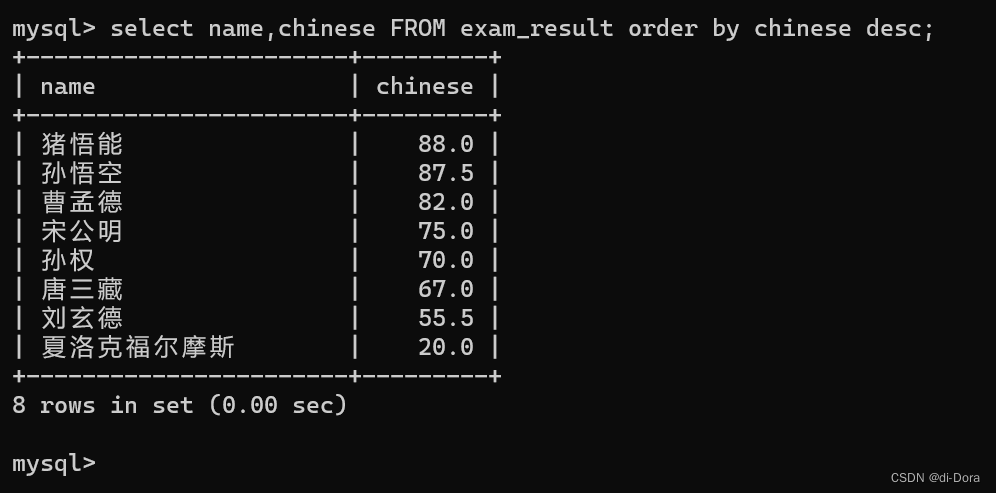
2. NULL 数据排序,视为比任何值都小,升序出现在最上面,降序出现在最下面 。

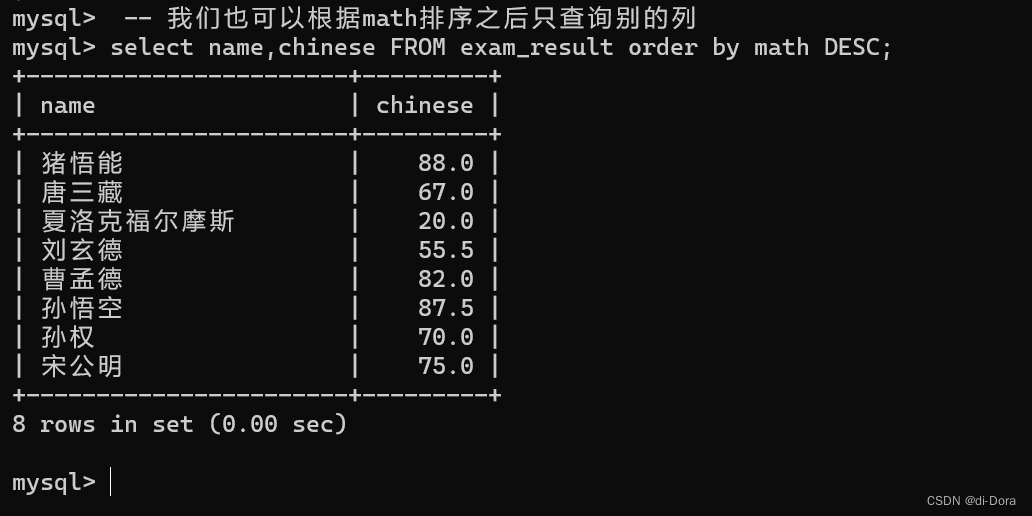
3. 使用表达式及别名排序
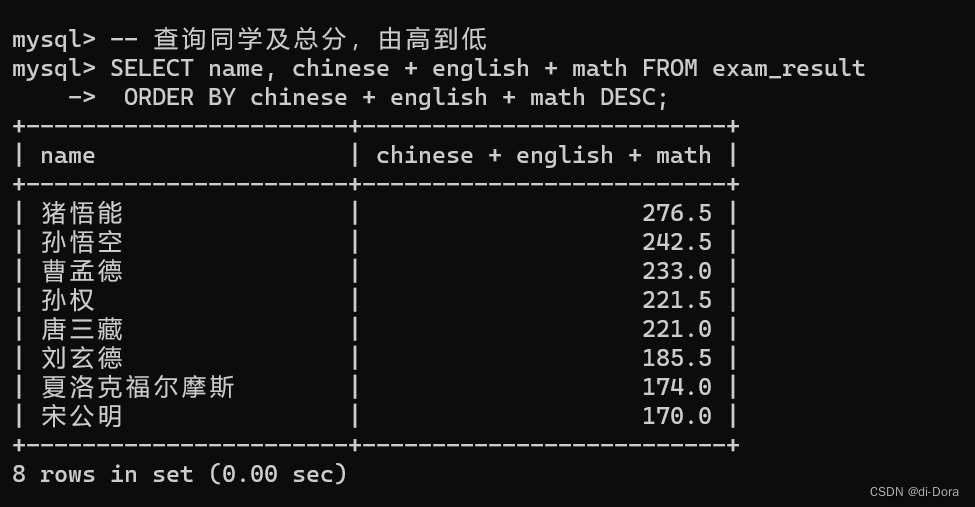
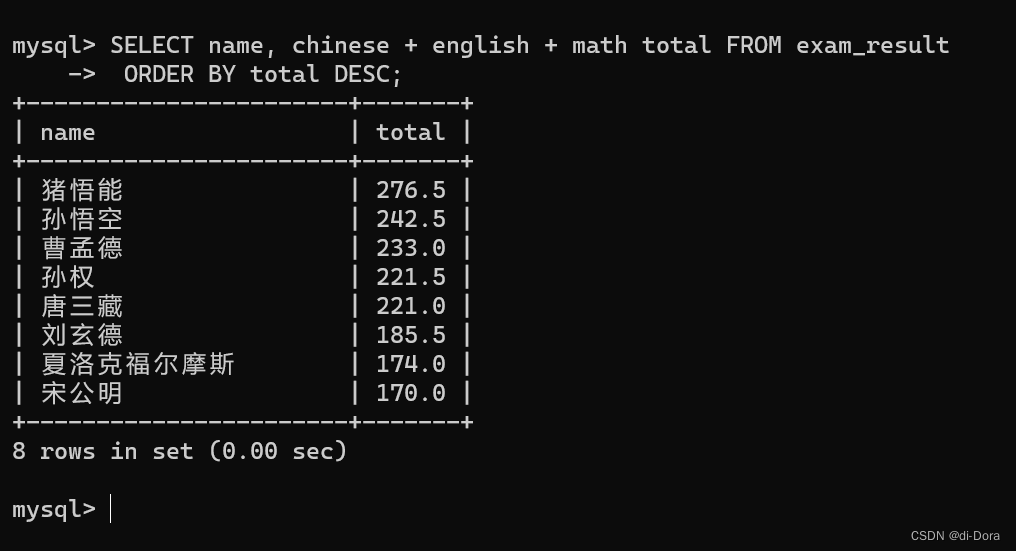
4. 可以对多个字段进行排序,排序优先级随书写顺序 (先按照数学成绩降序排序,数学成绩相同再按照英语成绩升序排序,英语成绩相同再按照语文成绩升序排序)
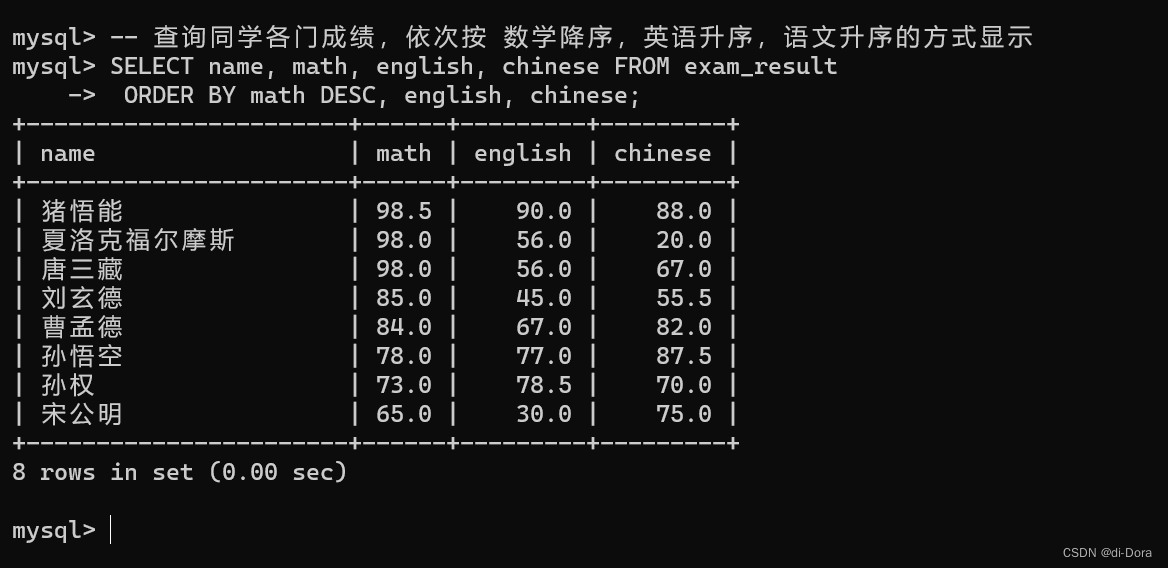
条件查询:WHERE
在 SQL 查询中,WHERE 是一个用于筛选数据的关键字,它用于指定一个条件,只有符合条件的行将包含在查询结果中。
WHERE 子句允许我们在执行查询时指定条件,以便从数据库表中选择满足这些条件的行。
我们可以制定具体的条件,按照条件针对数据进行筛选。
然后MySQL会遍历这个表中的每一行记录,把每一行的数据分别带入条件中。如果条件成立,这个记录就会被放入结果集合中;如果条件不成立,这个记录就pass。
SELECT column1, column2, ...
FROM table_name
WHERE condition;
比较运算符:
- >:大于运算符。用于比较一个值是否大于另一个值。例如,column1 > column2 表示 column1 的值必须大于 column2 的值才会返回 TRUE。
- >=:大于等于运算符。用于比较一个值是否大于或等于另一个值。例如,column1 >= column2 表示 column1 的值必须大于或等于 column2 的值才会返回 TRUE。
- <:小于运算符。用于比较一个值是否小于另一个值。例如,column1 < column2 表示 column1 的值必须小于 column2 的值才会返回 TRUE。
- <=:小于等于运算符。用于比较一个值是否小于或等于另一个值。例如,column1 <= column2 表示 column1 的值必须小于或等于 column2 的值才会返回 TRUE。
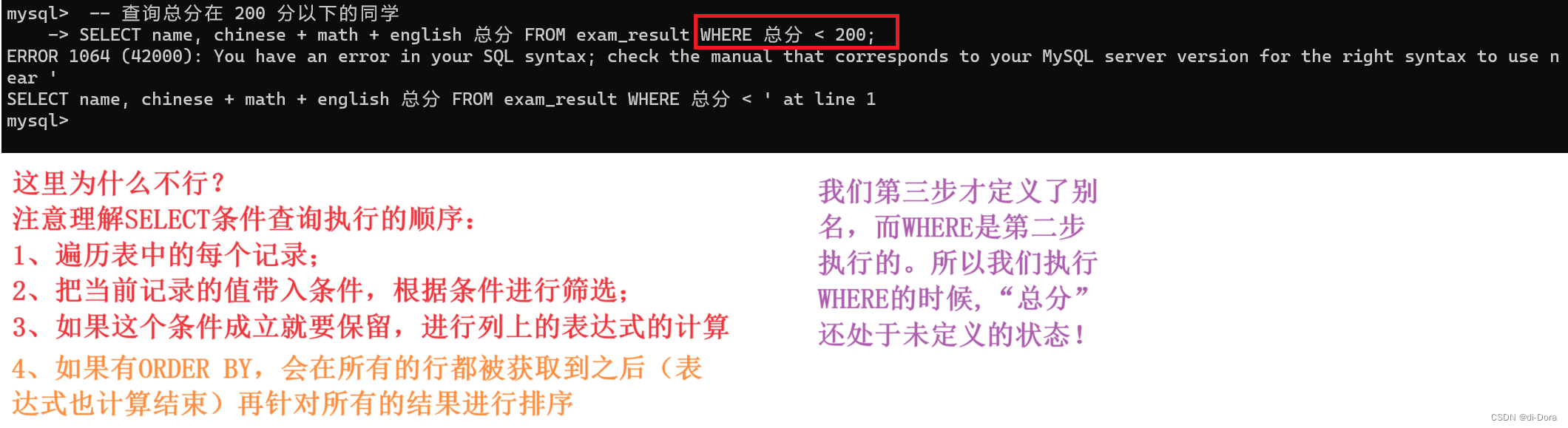
-- 查询英语不及格的同学及英语成绩 ( < 60 ) SELECT name, english FROM exam_result WHERE english < 60; -- 查询语文成绩好于英语成绩的同学 SELECT name, chinese, english FROM exam_result WHERE chinese > english; -- 查询总分在 200 分以下的同学 SELECT name, chinese + math + english 总分 FROM exam_result WHERE chinese + math + english < 200;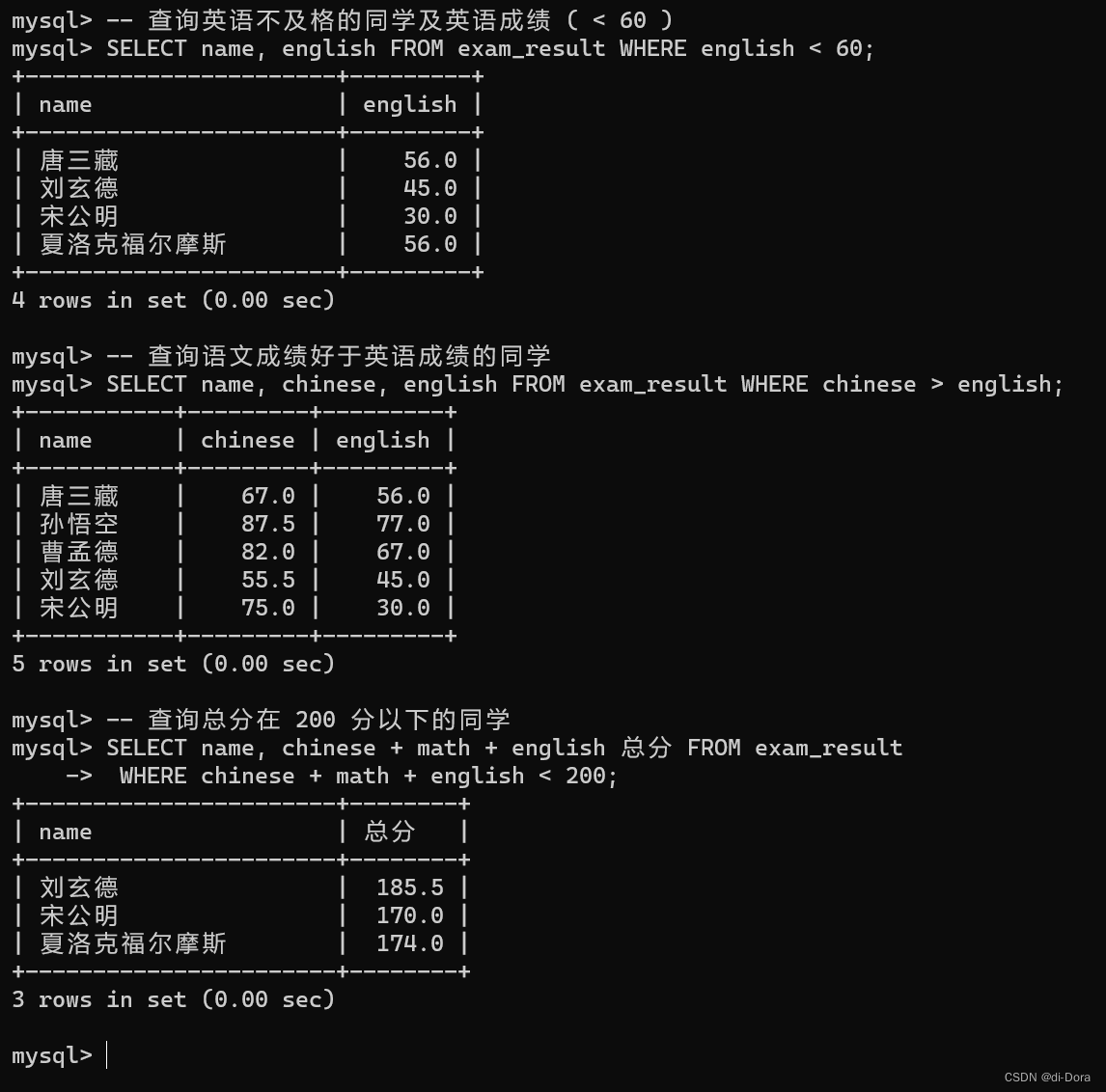
- =:等于运算符(NULL 不安全)。用于比较两个值是否相等。请注意,对于 NULL 值,使用 = 进行比较通常不会返回 TRUE,因为 NULL 去参与各种计算或者与任何其他值的比较,结果都是 NULL。例如,column1 = column2 表示 column1 的值必须等于 column2 的值才会返回 TRUE。而 NULL = NULL 的结果是 NULL。
- <=>:等于运算符(NULL 安全)。与普通的 = 运算符不同,<=> 运算符在比较 NULL 值时会返回 TRUE(1)。例如,NULL <=> NULL 返回 TRUE(1)。如下:这里是无法查询到math为空的对象的。因为我们需要使用NULL = NULL 的结果是 NULL,是被认为错误的,无法查到。

-- 需要使用这种写法: select * from exam_result where math <=> null; - != 或 <>:不等于运算符。用于比较两个值是否不相等。例如,column1 != column2 表示 column1 的值必须不等于 column2 的值才会返回 TRUE。
- BETWEEN a0 AND a1:范围匹配运算符。用于检查一个值是否在指定范围内。如果值在 [ a0, a1 ] 的范围内(包括 a0 和 a1),则返回 TRUE。
-- 查询语文成绩在 [80, 90] 分的同学及语文成绩 SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90; -- 使用 AND 也可以实现 SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;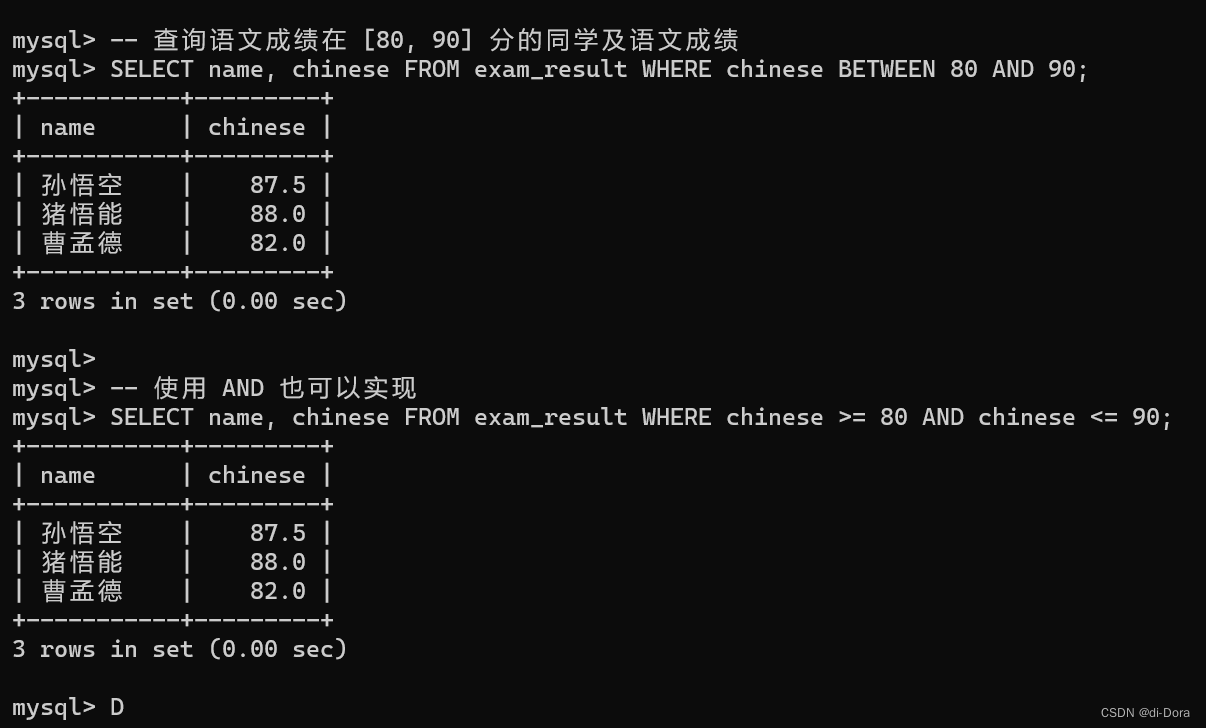
- IN (option, ...):IN 运算符。用于检查一个值是否等于括号内列举的多个离散的选项中的任何一个。如果值等于其中任何一个选项,返回 TRUE。
-- 查询数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩 SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99); -- 使用 OR 也可以实现 SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math = 98 OR math = 99;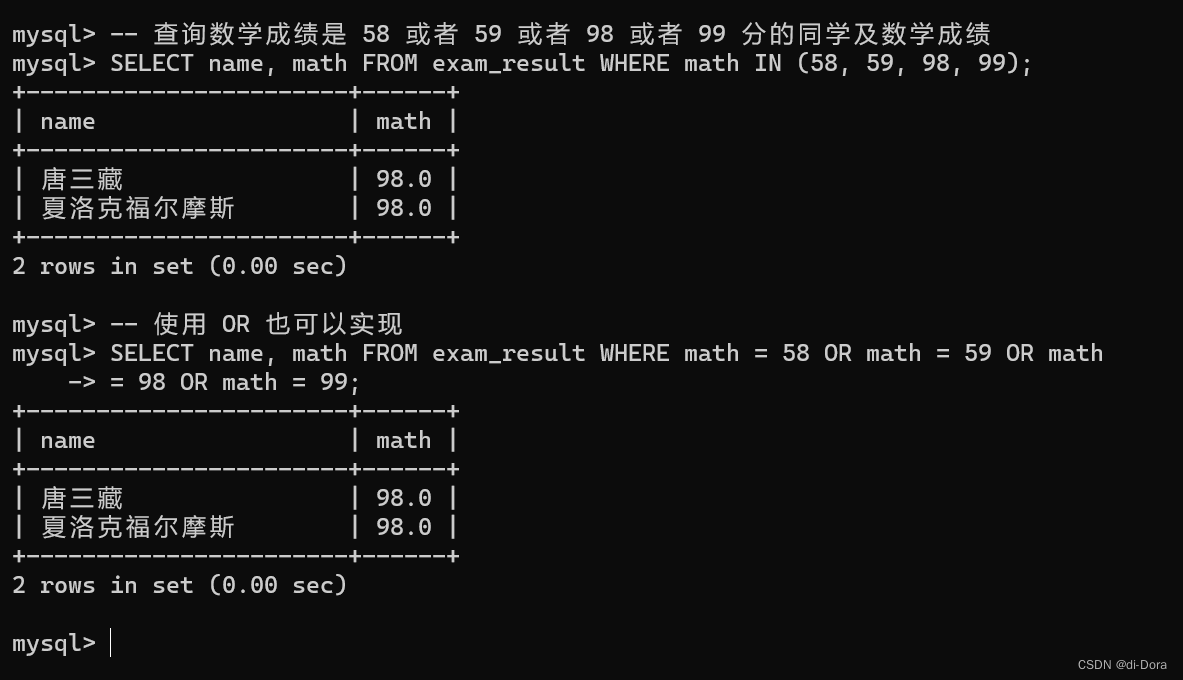
- IS NULL:用于检查一个值是否为 NULL。
- IS NOT NULL:用于检查一个值是否不是 NULL。
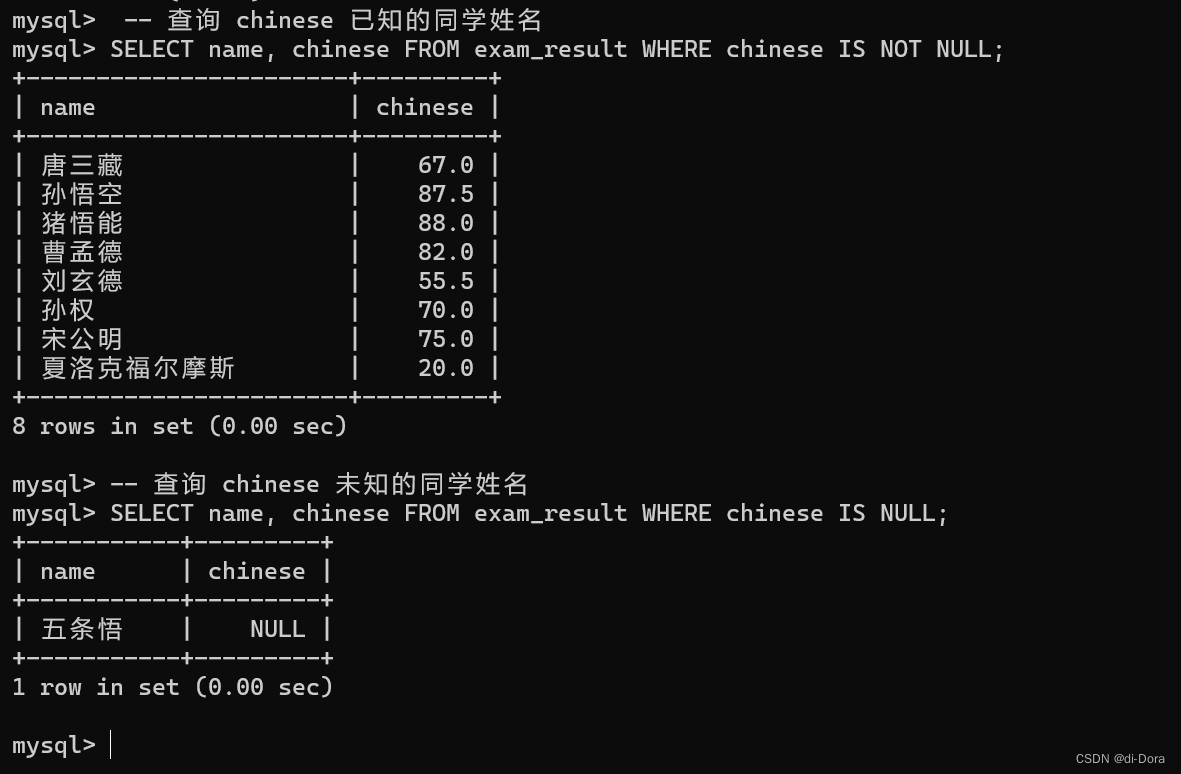
-- 查询 chinese 已知的同学姓名 SELECT name, chinese FROM exam_result WHERE chinese IS NOT NULL; -- 查询 chinese 未知的同学姓名 SELECT name, chinese FROM exam_result WHERE chinese IS NULL;
- LIKE:模糊匹配运算符。模糊匹配就是通过一些特殊符号描述出规则/特征,再去查找后续哪些值能够符合上述特征。通常与通配符 % 和 _ 一起使用,用于比较一个字符串是否与模式匹配。% 表示任意多个(包括 0 个)字符,_ 表示任意一个字符。
-- 匹配以特定字符开头的文本: SELECT * FROM customers WHERE first_name LIKE 'J%'; -- 这个查询将选择 "customers" 表中 "first_name" 列以字母 "J" 开头的所有行。 匹配包含特定字符串的文本: SELECT * FROM products WHERE product_name LIKE '%apple%'; 这个查询将选择 "products" 表中 "product_name" 列包含 "apple" 字符串的所有行。 -- 匹配特定字符数的文本: SELECT * FROM orders WHERE order_number LIKE 'ODR_'; -- 这个查询将选择 "orders" 表中 "order_number" 列以 "ODR_" 开头并且后面跟着一个字符的所有行。 -- 使用多个通配符: SELECT * FROM employees WHERE last_name LIKE 'Sm_th'; -- 这个查询将选择 "employees" 表中 "last_name" 列以 "Sm" 开头、然后是任意一个字符,接着是 "th" 的所有行,例如 "Smith"。 SELECT * FROM employees WHERE last_name LIKE 'Sm%th'; -- 这个查询将选择 "employees" 表中 "last_name" 列以 "Sm" 开头、 "th" 结尾的所有行,例如 "Smooth"。-- % 匹配任意多个(包括 0 个)字符 SELECT name FROM exam_result WHERE name LIKE '孙%';-- 匹配到孙悟空、孙权 -- _ 匹配严格的一个任意字符 SELECT name FROM exam_result WHERE name LIKE '孙_';-- 匹配到孙权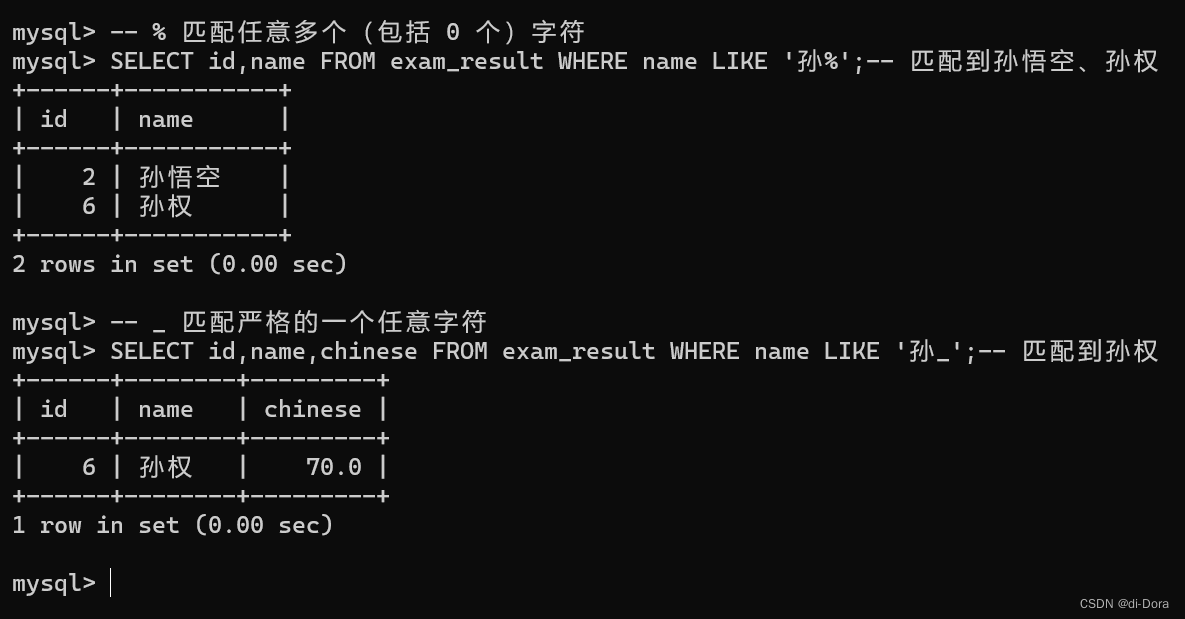
逻辑运算符:
逻辑运算符用于在 SQL 查询中组合和操作多个条件,以便构建更复杂的查询条件。
1、AND:逻辑与运算符。用于连接多个条件,要求所有连接的条件都必须为 TRUE(1),结果才会为 TRUE(1)。如果其中任何一个条件为 FALSE(0),则结果将为 FALSE(0)。
SELECT *
FROM table_name
WHERE condition1 AND condition2;
在这个查询中,只有当 condition1 和 condition2 同时为 TRUE 时,结果才会包括满足条件的行。
2、OR:逻辑或运算符。用于连接多个条件,只要其中任何一个条件为 TRUE(1),结果就会为 TRUE(1)。如果所有条件都为 FALSE(0),则结果将为 FALSE(0)。
SELECT *
FROM table_name
WHERE condition1 OR condition2;
在这个查询中,只要 condition1 或 condition2 中有一个为 TRUE,结果就会包括满足条件的行。
3、NOT:逻辑非运算符。用于对一个条件的结果进行取反,即如果条件为 TRUE(1),则结果为 FALSE(0),如果条件为 FALSE(0),则结果为 TRUE(1)。
SELECT *
FROM table_name
WHERE NOT condition;
在这个查询中,只有当 condition 为 FALSE 时,结果才会包括满足条件的行。
-- 查询语文成绩大于80分,且英语成绩大于80分的同学
SELECT * FROM exam_result WHERE chinese > 80 and english > 80;
-- 查询语文成绩大于80分,或英语成绩大于80分的同学
SELECT * FROM exam_result WHERE chinese > 80 or english > 80;
-- 观察AND 和 OR 的优先级:
SELECT * FROM exam_result WHERE chinese > 80 or math>70 and english > 70;
SELECT * FROM exam_result WHERE (chinese > 80 or math>70) and english > 70;
注意:
1. WHERE条件可以使用表达式,但不能使用别名。
2. AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
3、MySQL的模糊查询的功能是有限的。在计算机中进行模糊匹配字符串的还有“正则表达式”
正则表达式(Regular Expressions,通常称为正则表达式或正则式)提供了更强大和灵活的字符串匹配和搜索功能。正则表达式提供了强大的文本匹配和搜索功能,可以用于处理更复杂的模糊匹配需求,例如查找特定模式的字符串、搜索电话号码、电子邮件地址等等。
但需要注意的是,正则表达式的语法相对复杂,因此需要一些学习和熟悉的时间。不同的数据库管理系统可能在正则表达式的支持和语法上有些差异,因此在使用正则表达式时我们需要查阅相应数据库的文档以了解详细信息。
但是我们使用正则表达式一般都是现查的,光靠死记硬背很容易搞错。
4、“<=>”可以针对两个列来比较,但是 IS NOT 只能操作一个列。
分页查询:LIMIT
我们之前说 select * 这种方式查询是比较危险的,需要保证一次查询不能查出太多的东西。
而 limit 分页查询就是一种有效保证,能够限制一次查询最多能查的结果。
LIMIT 是 SQL 查询中的一个关键字,用于限制查询结果集中返回的行数。它允许我们从查询结果中选择指定数量的行,从而实现分页查询或限制结果集的大小。
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页:
-- 第 1 页
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 0;
-- 第 2 页
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 3;
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 6;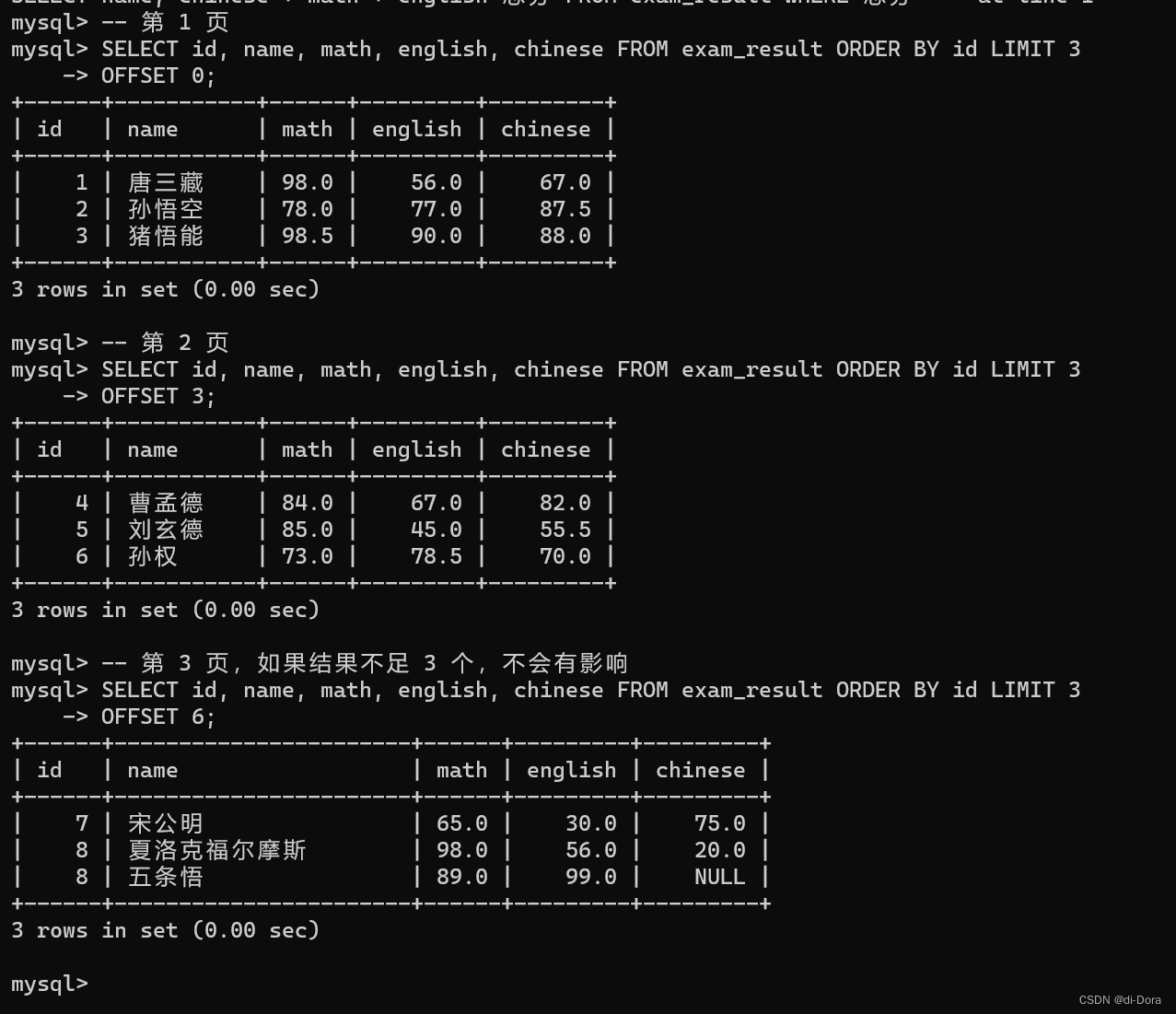
修改(Update)
在SQL中,“修改”(Update)是一种操作,用于更新数据库表中现有数据的值。
它通常用于将表中的一行或多行数据的某些列的值更改为新的值,以便反映数据的更新或更正。
Update语句的基本语法如下:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]-- 将孙悟空同学的数学成绩变更为 80 分
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
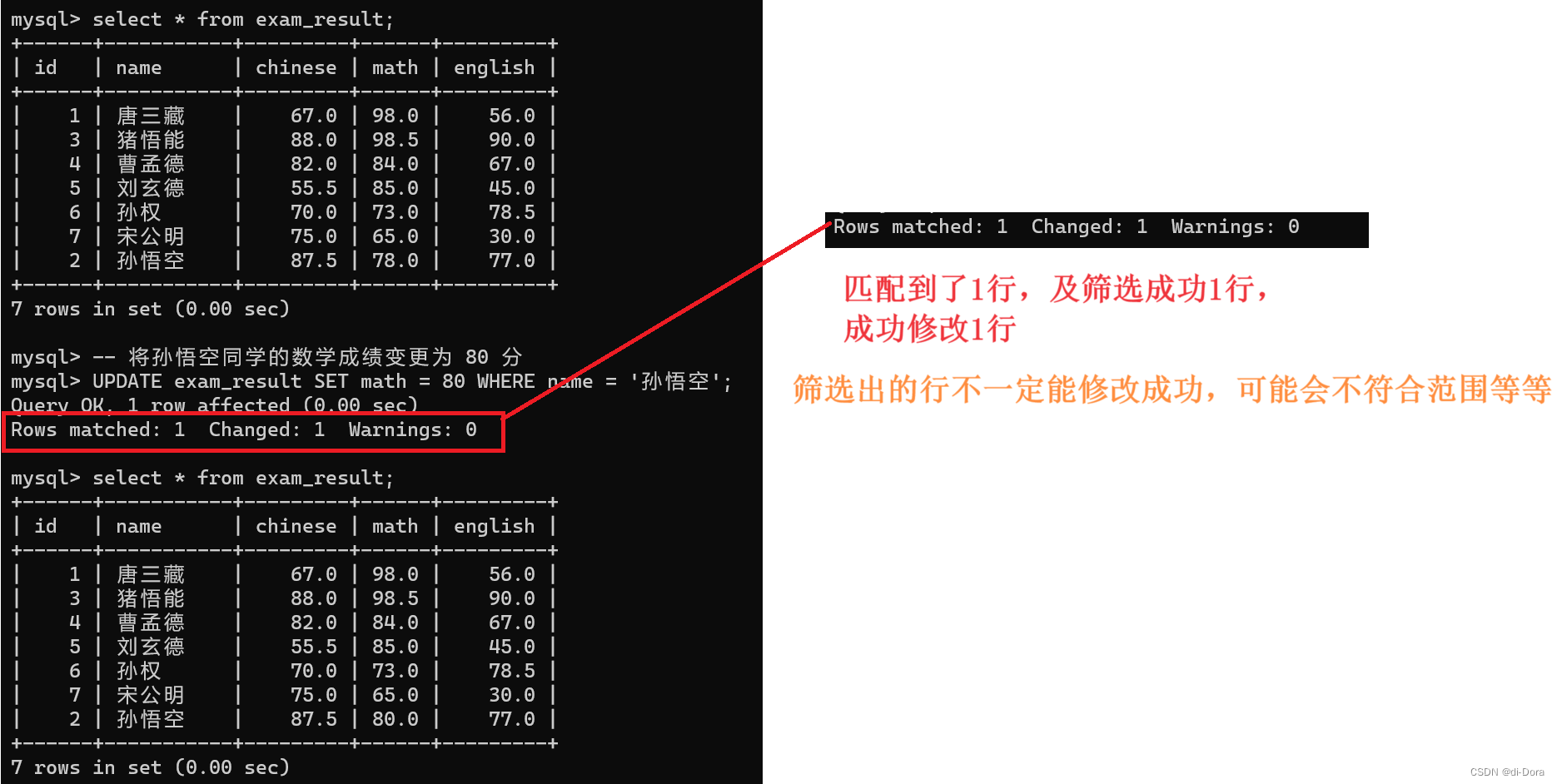
update是可以一次修改多个列的: 此处的“ = ”就不再代表相等,而是赋值。
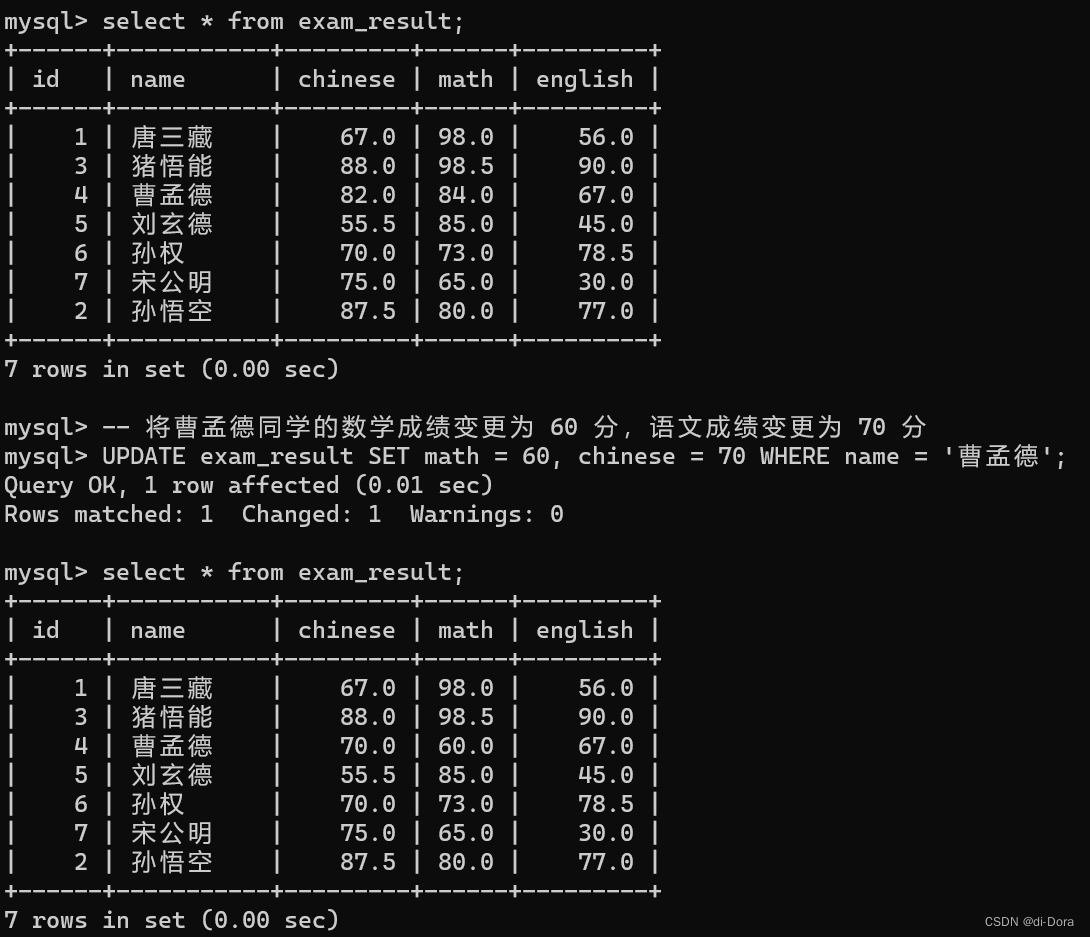
-- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
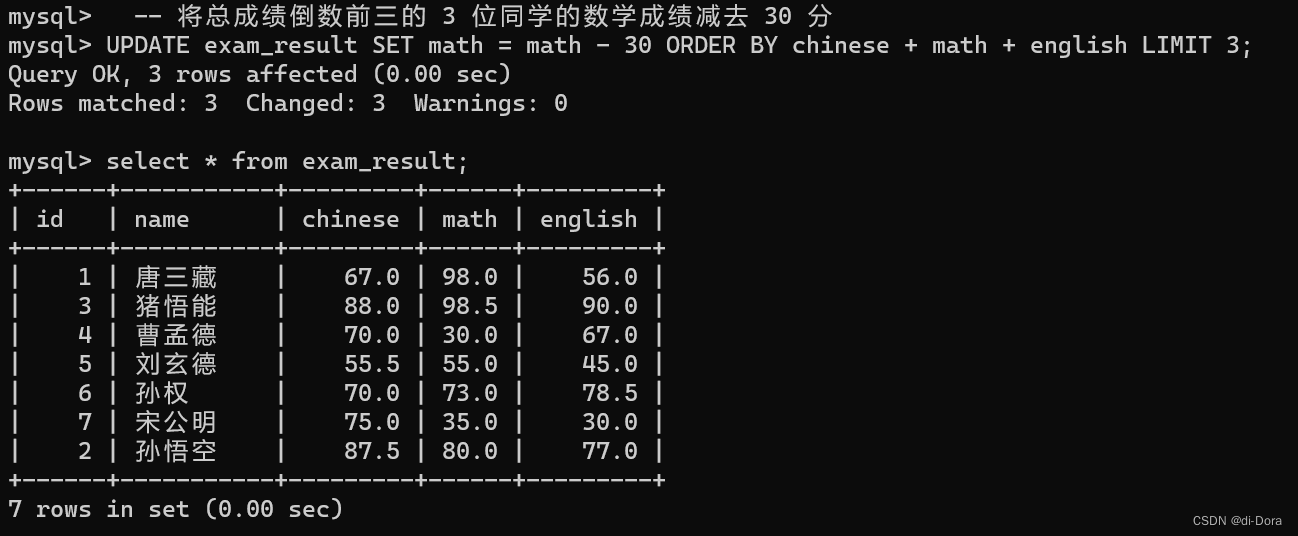
-- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT 3;
 这里出问题的原因是修改后的值超出范围了,不符合 decimal(3,1)的要求了。
这里出问题的原因是修改后的值超出范围了,不符合 decimal(3,1)的要求了。
所以我们换一下:
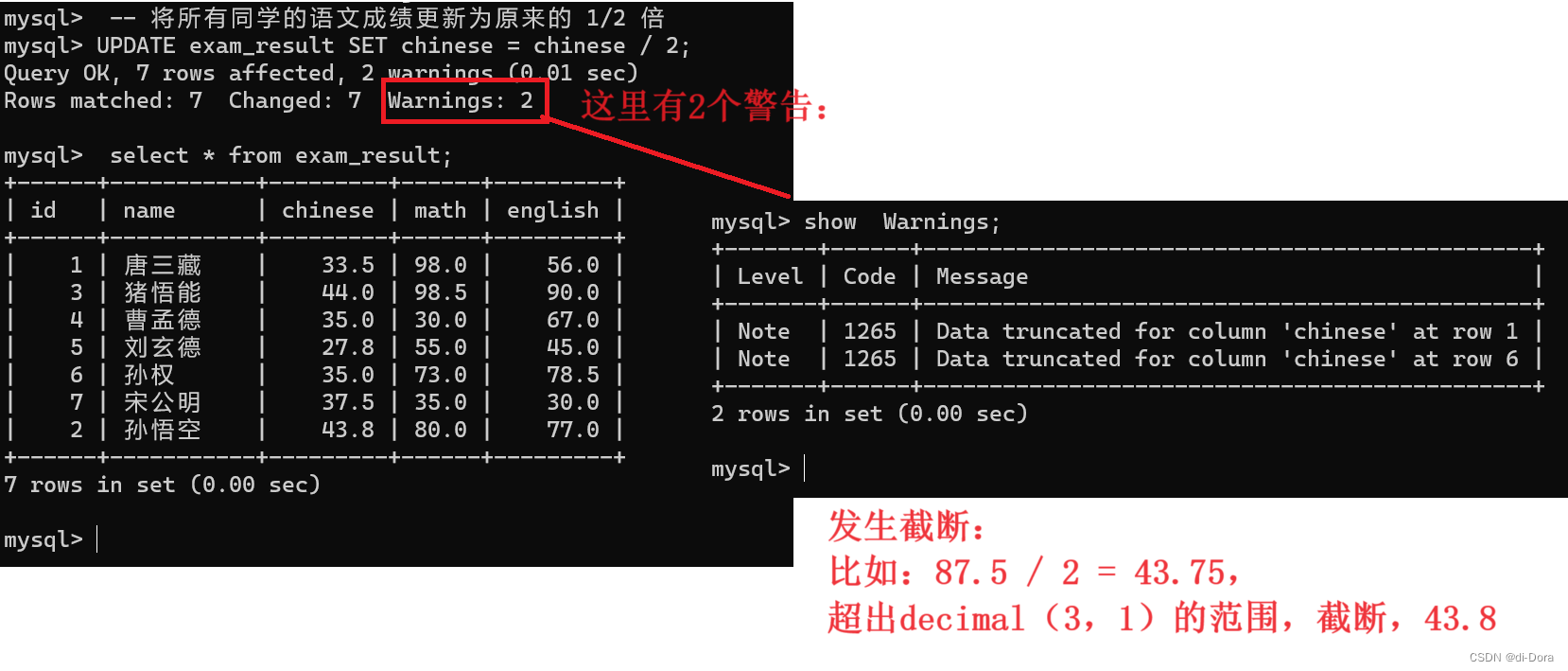
-- 将所有同学的语文成绩更新为原来的 2 倍
UPDATE exam_result SET chinese = chinese * 2;如果 update 后面不写任何条件,就是针对所有行进行修改!
同理,超出范围了:

那么稍微改一下:
删除(Delete)
"删除"(Delete)是一种操作,用于从数据库表中删除符合条件的一行或多行数据。这个操作通常用于删除不再需要的数据、纠正错误的数据或执行其他数据清理任务。删除操作会永久性地从数据库中删除指定的数据行。
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]-- 删除孙悟空同学的考试成绩
DELETE FROM exam_result WHERE name = '孙悟空';

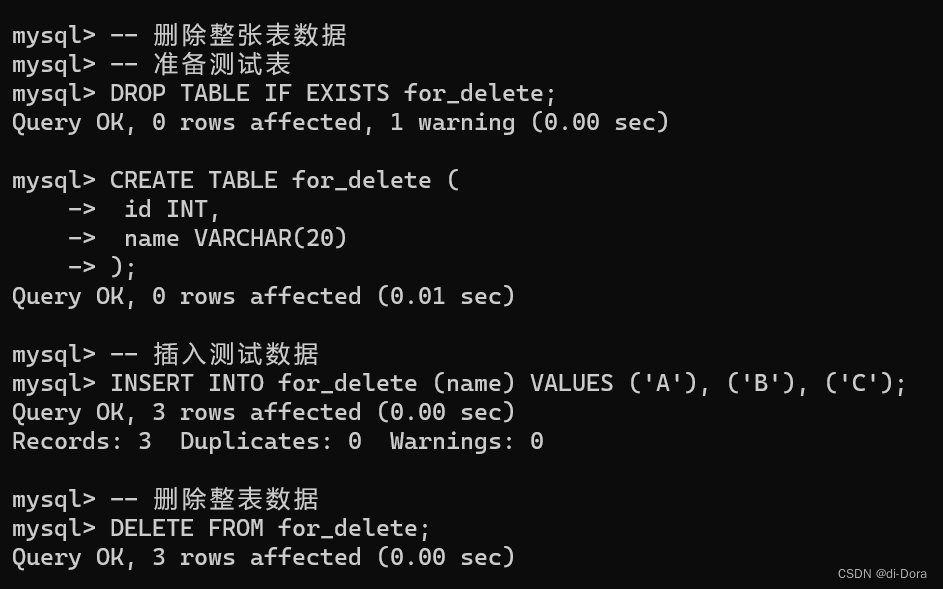
-- 删除整张表数据
-- 准备测试表
DROP TABLE IF EXISTS for_delete;
CREATE TABLE for_delete (
id INT,
name VARCHAR(20)
);
-- 插入测试数据
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
-- 删除整表数据
DELETE FROM for_delete;不指定任何条件就是删除整张表。

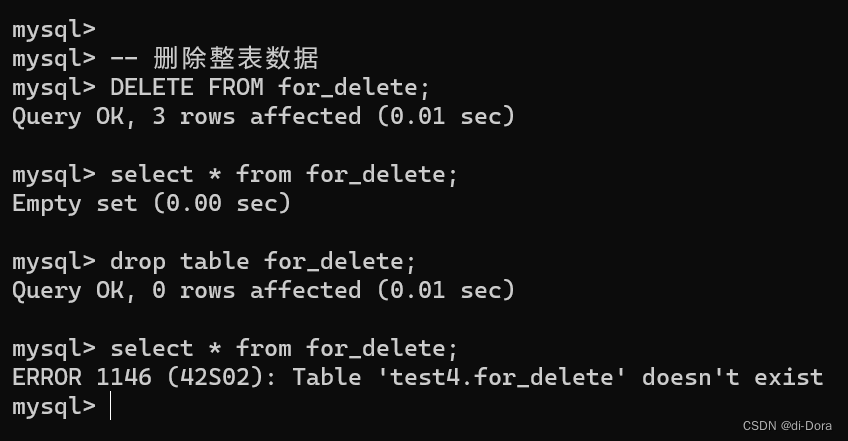
这里 DELETE FROM for_delete; 和 drop table 还不太一样。
-
DELETE FROM:
- DELETE FROM 用于删除表中的数据行,而不是删除整个表格。
- 它仅删除表中的数据,不删除表本身。表结构和表定义仍然存在,只是数据被删除了。
- 表结构保持不变,表仍然存在,但变成了一个空表(没有数据行)。
-
DROP TABLE:
- DROP TABLE 用于完全删除数据库中的表,包括表的结构和定义以及表中的所有数据。
- 它删除整个表格,包括表格的结构和数据,表格不再存在于数据库中。
我们的 DELETE 和 UPDATE 操作都是非常危险的操作!!!
这里的删除和修改都是持久生效的,都会影响到数据库服务器硬盘中的数据。
















 1990
1990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









