







字符移动问题
这道题的描述是这样的:输入一个字符串,将其中的数字字符移动到非数字字符之后,并保持数字字符和非数字字符输入时的顺序。例如:输入字符串“ab4f35gr#a6”,输出为“abfgr#a4356”。
以下使我试着敲的代码,思路很简单,遍历两遍字符串,第一遍把非数字的排好,第二遍再把数字排好。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
char str[100];
char temp[100];
gets(str);
int len=strlen(str);
int i=0,q=0;
while(q<len){
if(str[q]>'9'&&str[q]<'0'){
temp[i++]=str[q];
}
q++;
}
q=0;
while(q<len){
if(str[q]<='9'&&str[q]>='0')temp[i++]=str[q];
q++;
}
puts(temp);
return 0;
}
但是这段代码运行结果并不令我满意:

查询发现我犯了一个严重错误:
字符范围判断错误:条件str[q] > '9' && str[q] < '0'是逻辑上不可能的,因为在ASCII码中,'0'到'9'之间没有其他字符,因此这个条件永远不会为真。这意味着第一个while循环实际上不会把任何字符放进temp
因此作出修改:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
char str[100];
char temp[100];
gets(str);
int len=strlen(str);
int i=0,q=0;
while(q<len){
if(str[q]>'9'||str[q]<'0'){
temp[i++]=str[q];
}
q++;
}
q=0;
while(q<len){
if(str[q]<='9'&&str[q]>='0')temp[i++]=str[q];
q++;
}
for(i=0;i<len;i++){
printf("%c",temp[i]);
}
printf("\n");
return 0;
}
这样就可以了。同时做出的更改还有将输出字符串从puts()函数改成了printf()函数,原因是就算结果是正确的,我所输出的结果后还跟着一长串‘烫’字,不知道什么原因。。。
查询得到有可能是因为:
初始化与结尾处理:由于字符数组temp没有被明确地终止,因此在输出时可能包含未初始化的字符,导致出现乱码。
尝试改回去,在temp数组末尾加‘\0’。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
char str[100];
char temp[100];
gets(str);
int len=strlen(str);
int i=0,q=0;
while(q<len){
if(str[q]>'9'||str[q]<'0'){
temp[i++]=str[q];
}
q++;
}
q=0;
while(q<len){
if(str[q]<='9'&&str[q]>='0')temp[i++]=str[q];
q++;
}
temp[i]='\0';
puts(temp);
return 0;
}
这样也是正确的。
字母统计问题(一)
题目描述:输入一行字符串,计算其中A-Z大写字母出现的次数
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
char str[100];
int len;
int i;
char c;
while(scanf("%s",str)!=EOF){
len=strlen(str);
int count[26]={0};
for(i=0;i<len;i++){
if(str[i]>='A'&&str[i]<='Z')count[str[i]-'A']++;
}
for(i=0,c='A';c<='Z';c++){
printf("%c:%d\n",c,count[i++]);
}
}
return 0;
}
字母统计问题(二)
题目描述:统计一个给定字符串中指定的字符出现的次数。
输入样例:测试输入包含若干测试用例,每个测试用例包含2行,第1行为一个长度不超过5的字符串,第2行为一个长度不超过80的字符串。注意这里的字符串包含空格,即空格也可能是要求被统计的字符之一。当读到'#'时输入结束,相应的结果不要输出。
这个问题遇到了几个问题。
第一个问题在于字符串的输入会默认空格作为结束符,为了解决这一问题,我搜索了许多种方法,目前成功的有以下这种:
//c和str是我定义的字符数组
scanf("%[^\n]%*c",c);
if(c[0]=='#')break;
scanf("%[^\n]%*c",str);当使用scanf函数时,格式化字符串中的%[^\n]和%*c代表了特定的输入格式。
-
%[^\n]:这表示扫描字符序列直到遇到换行符(\n)为止。换行符不会被读入并且不会终止输入,而是留在输入缓冲区中。这个格式说明符允许读取带有空格的字符串,直到换行符出现为止。这在读取一行字符串时很有用。 -
%*c:这表示扫描并消耗一个字符,但不进行赋值操作。星号(*)表示该输入项会被扫描但不会被存储到变量中。在这里,它的作用是消耗并丢弃换行符(\n),以便进行下一次输入。
这个问题解决之后我就放网上运行了,结果一直提醒我运行超时。以下是第一遍没成功运行的代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
int main() {
char c[7];
char str[82];
int i,j,len;
while(true){
scanf("%[^\n]%*c",c);
if(c[0]=='#')break;
scanf("%[^\n]%*c",str);
int count;
//int count[5]={0};
len=strlen(str);
for(i=0;i<strlen(c);i++){
count=0;
for(j=0;j<len;j++){
if(str[j]==c[i]){
count++;
}
}
printf("%c %d\n",c[i],count);
}
memset(c, 0, sizeof(c));
memset(str, 0, sizeof(str));
}
return 0;
}所以第二个问题就是提升算法效率。
查找了许多别人的代码以及自行研究之后,发现问题在于没使用哈希表(数据结构没学好)。
人工智能chatGPT是这样回答我的:
在你的代码中,使用了两层循环来统计每个字符在字符串中出现的次数,这种方法的时间复杂度为 O(n*m),其中 n 是字符串的长度,m 是要统计的字符的个数。对于较长的字符串和多个字符的情况下,可能会导致超时。
一种更简单且效率更高的算法是使用一个字符数组来统计字符出现的次数。具体步骤如下:
- 初始化一个长度为 128 的整型数组
count,表示 ASCII 码范围内的所有字符。 - 读取第一行的字符,将其转换为对应的 ASCII 码,然后在
count数组中将该位置的值加 1。 - 读取第二行的字符串,遍历字符串中的每个字符,将其转换为对应的 ASCII 码,然后在
count数组中将该位置的值加 1。 - 遍历
count数组,输出每个字符及其出现的次数(当字符出现次数大于 0 时)。
所以,第二遍运行的代码就更改为以下这样:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
int main() {
char c[7];
char str[82];
int i,j,len;
int count[128]={0};
memset(c, 0, sizeof(c));
memset(str, 0, sizeof(str));
while(true){
scanf("%[^\n]%*c",c);
if(c[0]=='#')break;
scanf("%[^\n]%*c",str);
len=strlen(str);
for(j=0;j<len;j++){
count[str[j]]++;
}
for(i=0;i<strlen(c);i++){
printf("%c %d\n",c[i],count[c[i]]);
}
memset(count,0,sizeof(count));
}
return 0;
}仍然运行超时(o(╥﹏╥)o),也不知道是个什么事??
求解答。
首字母大写问题
题目描述:对一个字符串中的所有单词,如果单词的首字母不是大写字母,则把单词的首字母变成大写字母。 在字符串中,单词之间通过空白符分隔,空白符包括:空格(' ')、制表符('\t')、回车符('\r')、换行符('\n')。
真的会被字符串的题的细节坑到。。。
上代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
char str[100];
int len;
int i;
char c;
while(scanf("%s",str)!=EOF){
len=strlen(str);
c=' ';
for(i=0;i<len;i++){
if(c==' '||c=='\t'||c=='\n'||c=='\r'){
if(str[i]<='z'&&str[i]>='a'){
str[i]=str[i]-'a'+'A';
}
}
c=str[i];
}
puts(str);
/*
for(i=0;i<len;i++){
printf("%c",str[i]);
}
printf("\n");
*/
}
return 0;
}
给看一下这段代码的运行结果:
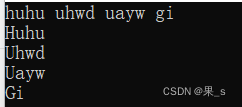
是的,它把每一个空格隔开的字符串当成完全独立的字符串了o(╥﹏╥)o
搜索得知:
在C语言中,使用fgets函数可以安全地读取带有空格的字符串,并且你可以指定一个最大的字符数来防止缓冲区溢出。此外,可以检查字符串中是否包含换行符来确定用户是否按下了回车键。
char *fgets(char *str, int n, FILE *stream);fgets 是 C 语言中用于从指定的输入流读取字符串的函数。常用来读取标准输入 (stdin) 或从文件读取数据。
这里解释一下每个参数的含义:
-
str:指向一个字符数组的指针,这个数组用于存储从输入流读取的字符串。这个数组应该足够大,以存储读取到的字符串以及字符串终止符\0。 -
n:要读取的最大字符数(包括字符串终止符\0)。fgets最多会读取n-1个字符,并且会在末尾加上一个字符串终止符。这样做是为了确保读取的字符串是正确终止的。 -
stream:指定要读取的输入流。在读取标准输入时,这个参数是stdin,也可以是指向文件流的指针,用于从文件读取数据。
在读取字符串后,fgets 会返回 str,如果遇到错误或到达文件末尾,则返回 NULL。
完整可运行代码如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
char str[105];
int len;
int i;
char c;
while(fgets(str, sizeof(str), stdin) != NULL){
len=strlen(str);
str[--len]='\0';//清除掉末尾'\0'前的回车符'\r'
c=' ';
for(i=0;i<len;i++){
if(c==' '||c=='\t'||c=='\n'||c=='\r'){
if(str[i]<='z'&&str[i]>='a'){
str[i]=str[i]-'a'+'A';
}
}
c=str[i];
}
puts(str);
}
return 0;
}
统计单词的问题
题目描述:编一个程序,读入用户输入的,以“.”结尾的一行文字,统计一共有多少个单词,并分别输出每个单词含有多少个字符。 (凡是以一个或多个空格隔开的部分就为一个单词)
不知道为什么,这段代码可以在牛客上运行成功,但在n诺上不行:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
char str[105];
int len;
int i, count;
char c;
while (fgets(str, sizeof(str), stdin) != NULL) {
len = strlen(str);
str[--len] = '\0'; //清除掉末尾'\0'前的回车符'\r'
i = 0;
c = ' ';
while (i < len) {
count = 0;
c = str[i];
while ((str[i] >= 'A' && str[i] <= 'Z') || (str[i] >= 'a' && str[i] <= 'z')) {
count++;
c = str[i];
i++;
}
if ((str[i] == ' ' || str[i] == '.') && c != ' ')printf("%d ", count);
i++;
}
printf("\n");
}
return 0;
}
又研究了一下,发现n诺上的代码测试中有的样例没有在句子后面加‘.’,因此这段代码才会出错,只需修改一行就行了:
if((str[i]==' '||str[i]=='.'||str[i]=='\0')&&c!=' ')printf("%d ",count);删除字符串问题
题目描述:
给你一个字符串S,要求你将字符串中出现的所有"gzu"(不区分大小写)子串删除,输出删除之后的S。
就是说出现“Gzu”、“GZU”、“GZu”、"gzU"都可以删除。
代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
char str[105];
char temp[105];
int len;
int i,count;
char c;
while(fgets(str, sizeof(str), stdin) != NULL){
len=strlen(str);
count=0;
str[--len]='\0';//清除掉末尾'\0'前的回车符'\r'
for(i=0;i<len;){
if((str[i]=='g'||str[i]=='G')&&(str[i+1]=='z'||str[i+1]=='Z')&&(str[i+2]=='u'||str[i+2]=='U')){
i+=3;
continue;
}
temp[count++]=str[i++];
}
temp[count]='\0';
puts(temp);
}
return 0;
}
这里的字符串问题都比较简单,没有牵扯较难的算法。在机试当中,很多时候都会考到字符串相关的问题,尤其是查找和删除。之后我会学习解决更多关于字符串的问题。















 3766
3766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









