






 本文介绍了InternLM2的多版本模型设计,从7B到20B不等,强调了在超长上下文处理、对话和创作能力等方面的优势。文章还详细阐述了模型选型、应用流程,以及书生浦语全链路开源体系,包括数据集、训练框架和部署方案等。
本文介绍了InternLM2的多版本模型设计,从7B到20B不等,强调了在超长上下文处理、对话和创作能力等方面的优势。文章还详细阐述了模型选型、应用流程,以及书生浦语全链路开源体系,包括数据集、训练框架和部署方案等。
InternLM 实战营笔记-1-书生浦语全链路介绍
InterLM2 体系结构
InternLM2根据不同应用场景和使用需求,提供了多个版本的模型。
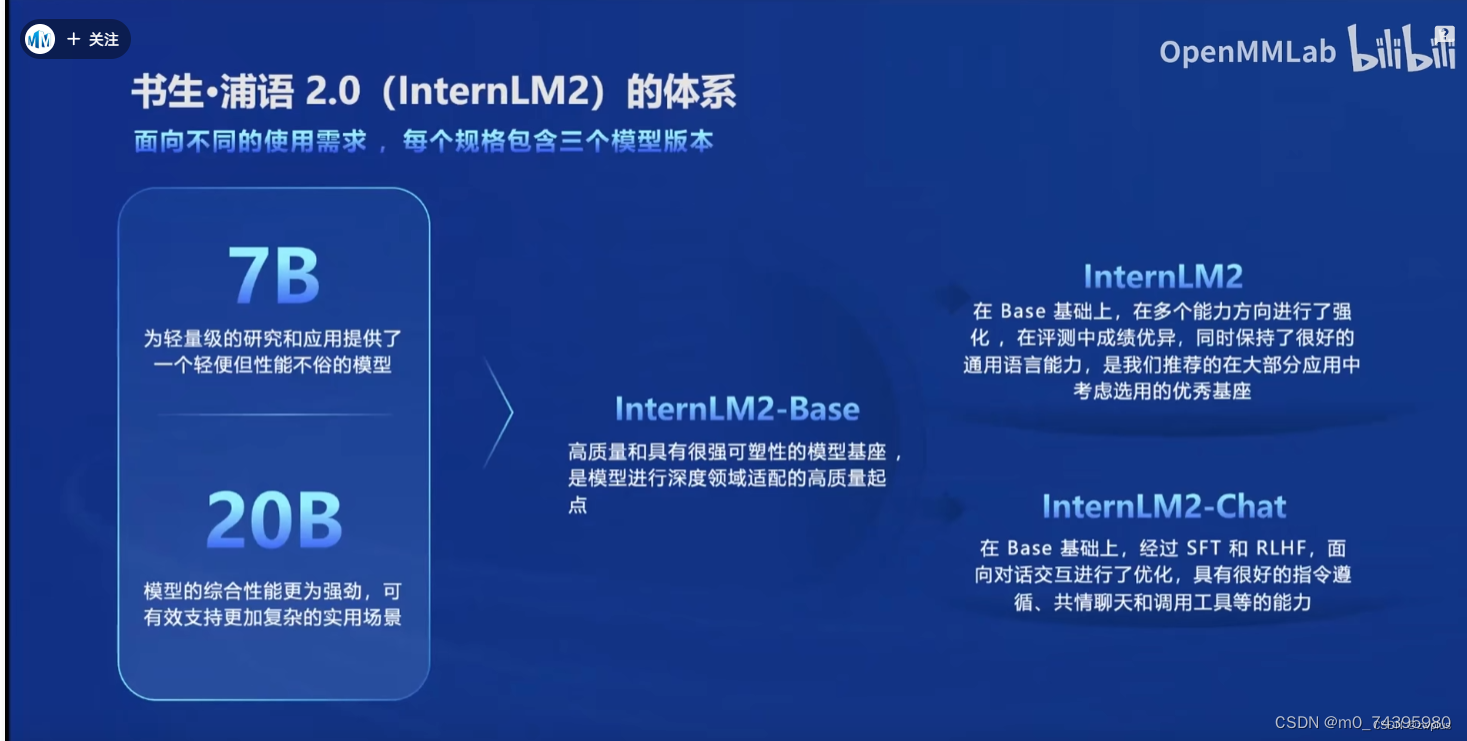
- 在模型大小方面,InterLM2提供了7B和20B参数量的两个模型,前者主要为一些简单任务和一些轻量级研究做服务,后者则是用于处理一些更加复杂的现实场景下的任务,但是相应的部署和运行成本会比较高InternLM2在7B和20B两种模型规格下,又分别根据不同的使用需求提供了三种细化版本的模型
- InternLM2-Base:基础版本模型,根据论文来看应该是只进行了4k Context Training和Long Context Training的模型,便于通过后续微调等训练方式来适配特定任务领域中。
- InternLM2:根据论文来看,其应该是在Base模型的基础上增加了Capability Specific Enhancement Training,以此提高其在多个特定任务上的表现,主要用于在特定任务进行深度定制化的开发,对于那些被包括在Capability Specific Enhancement Training中的任务,使用这个模型作为基础进行开发,理论上应该会更加简单。
- InternLM2-Chat:根据论文来看,这个版本的模型应该是在之前预训练的基础增加了SFT和RLHF训练来对齐人类偏好得到的模型,在这两个训练过程中更多地都是模拟人体对话的场景,因此最接近于我们平时使用到大模型那种状态,能够更加清楚的理解人类的问题,做出回答也会更符合人类偏好。
InterLM2 亮点
- InterLM2在超长上下文方面处理方面优秀,在200K超长的上下文条件下依旧有着非常优秀的表现。根据论文的描述,为了实现这一点,InterLM2在预训练阶段以及后面微调阶段(SFT和RLHF)都使用了超长文本作为训练数据。
- 在推理、数学以及代码等多个任务上的性能比肩chatgpt。(对应论文Capability Specific Enhancement Training和SFT以及RLHF)
- 优秀的对话和创作体验,精确的指令跟随,丰富的结构化创作。(SFT以及RLHF)
- 工具调用能力整体升级,支持复杂智能体的搭建。(对应论文中的General Tool Calling)
- 数理能力和数据分析能力得到全面增强。(对应论文中的Code Interpreter)
从模型到应用流程
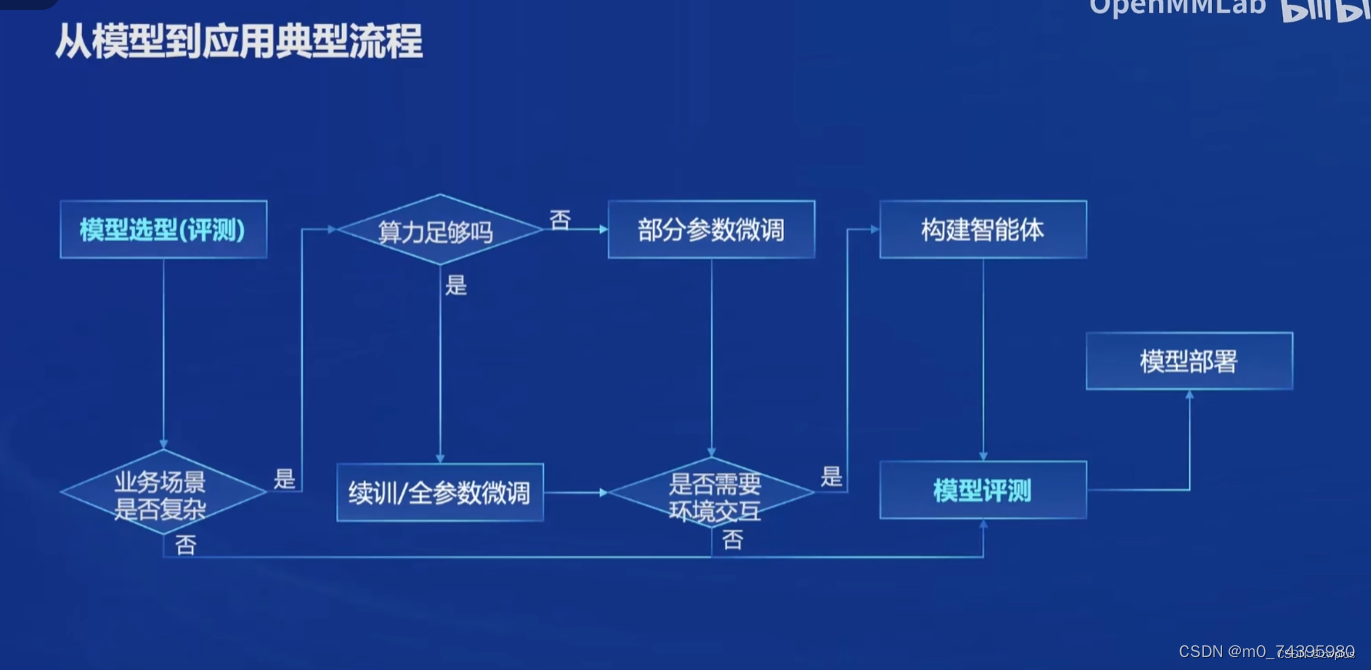
- 模型选型:依据业务需求和需要解决的问题选择最适合的机器学习模型
- 业务场景分析:根据具体业务场景判断是否需要对选择模型进行二次开发(即进一步训练)。
- 模型训练:如果业务场景较为复杂,需要对模型进行进一步优化,则需要根据现有算力判断是进行部分参数微调还是对模型进行全量训练或微调。
- 构建智能体:在得到适合业务场景下的模型,根据业务场景是否设计到与其他工具以及环境的交互来判断是否需要构建相应的智能体。
- 模型测评:在完成针对业务场景模型开发完善工作后,在模型正式上线前要进行详细模型测评,评估模型各项能力是否满足最终需求,如果不满足需求则可能需要根据情况回到1-4步中重新开发。
- 模型部署:如果开发的模型通过模型测评,则可以对模型进行部署。
书生浦语全链路开源体系
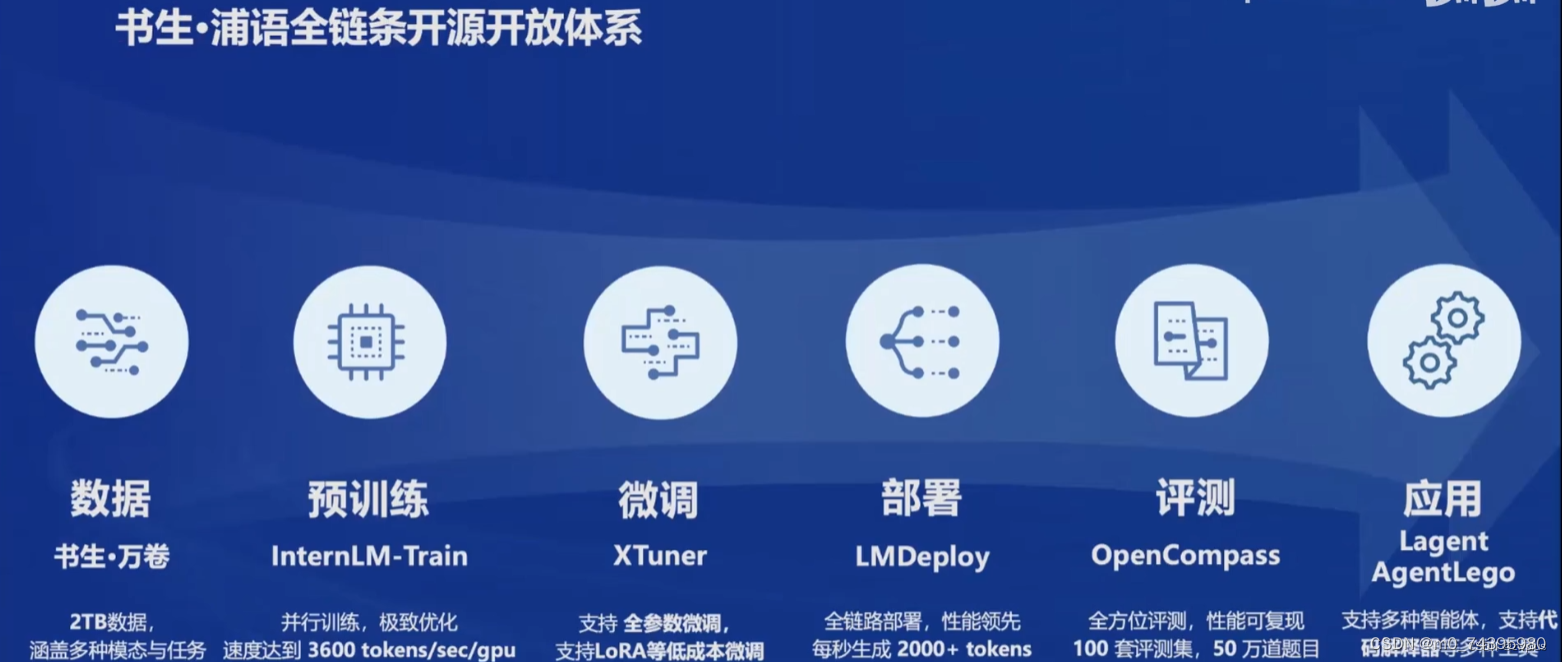
书生万卷:涵盖多模态和多种任务的大规模训练数据集,在论文有很大部分章节关于这些数据的清洗和处理工作。
InternLM-Train:大规模预训练框架,相较deepseed等训练框架能显著提高训练阶段的显卡利用率
XTuner:提供增量续训和有监督微调两种常见的训练方式,便于模型应用到下游任务中。
LMDeploy:一套模型部署方案,对模型推理阶段做了多种优化。
OpenCompass:能够对大模型进行系统的评测,对模型能力做出全名的评估。
LagentAgentLego:支持多种智能体和多种工具,能够显著降低相关智能体的开发难度


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









