






(一)需求和规格说明
问题描述:问题求解2个字符串的最长公共子串。输入的2个字符串可以从键盘读入,也可以从两个文本文件中读入。
编程任务:
求解2个字符串的最长公共子串。
(二)设计
1.问题分析
这道题目可以采用动态规划的算法来实现,将求解2个字符串的最长公共子串转化为二维DP的问题,而对于动态规划问题,我们需求解出其状态转移方程,经过分析可以知道,对于两个字符串之间的最长公共子串,可以以空间换取时间,制作一个DP表记录最长公共子串的长度,如果两个字符相同,则当前DP表值为上对角线DP值加一,代表最长公共子串的长度加一。
即状态转移方程如下:
if (str1[i - 1] == str2[j - 1])
dp[i][j] = dp[i - 1][j - 1] + 1;
然后如果当前DP表值比之前记录的最长子串的长度max还长则进行替换。
if (dp[i][j] > max)
{
max = dp[i][j];
start = i - max;
}
此动态规划问题的难点是想到利用DP表来记录最长公共子串长度的思路,但代码实现并不难。到这里最长公共子串问题的分析就结束了。
而与之相似的是LCS问题。最长公共子序列问题,子串与子序列的不同之处在于子串在一个字符串中呈现的状态是连续的,而子序列则未必,只要字符地址是递增的,即便不相邻的几个字符仍然是该字符串的子序列。
举一个例子而言,那就是字符串str=“abcdefghijklmn”,在这之中,abcde是一个子串,同时也是一个子序列;acehj不是子串,但其为一个子序列!
对于LCS问题,我们分析的思路与最长公共子串的分析方式如出一辙,制作一个DP表来记录最长公共子序列的长度,但是这个状态转移方程比最长公共子串复杂一点。
对于两个字符串求最长公共子序列有三种情况,第一种情况是两个字符串的长度都为0,则最长公共子序列的长度也为0,第二种情况是两个字符串的首元素相同,那么这个字符一定在最长公共子序列内,第三种情况又分为两种子情况,如果首元素不同:第一种是去掉序列1的头与序列2进行向下比对,第二种是去掉序列2的头与序列1进行向下比对。转换到DP数组中求解。
也就是状态转移方程的思路为:若字符相等,当前DP值为上斜对角+1,若不等,当前DP值取左方向、上方向最大值(即第三种情况)。
if (s1[i - 1] == s2[j - 1])
{
a[i][j] = a[i - 1][j - 1] + 1;
}
else
{
a[i][j]=max( a[i - 1][j] , a[i][j - 1]);
}
当我们将DP表构建好以后就可以通过递归回溯的方式来获取最长公共子序列。
void LCS(int i,int j)
{
if (i == 0 || j == 0) return;
if (s1[i - 1] == s2[j - 1])
{
LCS(i - 1, j - 1);
cout << s1[i - 1];
}
else if (a[i][j - 1] > a[i - 1][j])
{
LCS(i, j - 1);
}
else
{
LCS(i - 1, j);
}
}
这是因为我们在构建DP表时,是有DP值增大的路径的,而增大一定是通过斜对角DP值加一增大的,这种情况就对应着有元素相等,这个元素一定属于最长公共子序列,所以我们递归回溯DP表中数值增大的路径就可以得到最长公共子序列。
那么到这里,LCS问题的分析也结束了,我不得不佩服这个算法的精妙。
算法立足于生活,为了巩固我对于最长公共子串和最长公共子序列问题的认知,我决定制作一个简单的LCS机制的字段查重工具软件,将这个精妙的算法封装在程序中。下面是该程序的设计思想。
2.设计思想
(1)首先构思一下该软件的各个方面的大致实现,以及规划一下需要设计的类及模块。我们的任务就是将LCS算法抑或是最长公共子串算法封装在该程序中,所以我们要想办法调整算法适应程序。
(2)思路是设置两个文本框来接收要比较的两个字符串,然后直接内部调用调整过后的LCS算法,来输出重复字段并进行查重率的计算。
3. 设计表示
主要分成ui设计和LCS算法的封装。

(1)下面是简易的ui设计:
在文本一中输入测试文本,在文本二中输入标准文本,其实这里我认为后续可以使用MySQL数据库来存放大量字段,用户只需要在文本一中输入测试文本就好了,之后会在网络上找一找相关数据集,争取可以改进。
(2)LCS算法的封装:
虽然在问题分析进行过较为细致的分析,但是在QT中还需要进行一些调整。
首先我在window类下面加了两个成员,一个是计数器k(用来记录后续递归的次数),一个是结果字符串。
private:
Ui::MainWindow *ui;
int k=0;
QString result;
这一步就是DP数组的构建。将表做出来。
int leng(QString s1, QString s2, int dp[][N])
{
if (s1.length()==0 || s2.length()==0)
{
return 0;
}
for (int i = 1; i <= s1.length(); i++)
{
for (int j = 1; j <= s2.length(); j++)
{
if (s1[i - 1] == s2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else
{
if(dp[i-1][j]>dp[i][j-1])
dp[i][j]=dp[i-1][j];
else
dp[i][j]=dp[i][j-1];
}
}
}
return dp[s1.length()][s2.length()];
}
将表做出来后就可以回溯去找最长公共子序列了。
其实现代码如下:我让这个函数继承了Mainwindow类,以此调用计数器k和result结果字符串。
void MainWindow::LCS(int i,int j)
{
QString s1=ui->textEdit->toPlainText();
QString s2=ui->textEdit_2->toPlainText();
// if(s1.length()<s2.length())
// swap(s1,s2);
if (i == 0 || j == 0)
return;
if (s1[i - 1] == s2[j - 1])
{
LCS(i - 1, j - 1);
result += s1[i-1];
}
else if (dp[i][j - 1] > dp[i - 1][j])
{
LCS(i, j - 1);
}
else
{
LCS(i - 1, j);
}
k++;
//qDebug()<<k;
if(k==s1.length())
{
double l1=result.length();
qDebug()<<l1;
double l2=s1.length();
qDebug()<<l2;
double jieguo = l1/l2*100;
qDebug()<<jieguo;
QString jie = QString::number(jieguo,'f',4);
ui->textBrowser->append(result);
ui->textBrowser->append("简易查重率:"+jie+"%");
}
}
经过分析我们可以知道LCS递归函数的内部执行过程是这样的:
函数在到达递归出口之前是截止到k++;这一语句前进行递归的,也就是说LCS函数不断在DP表中进行搜索移动,在这一过程中数据一直在入栈,直到走到表的左上角递归出口,就像是爆炸一般又开始不断地出栈,这一出栈的过程不断执行k++,当我的计数器k等于s1的长度时,函数就结束了,这时我可以输出累加好的result。而result就是最长公共子序列。
以上就是算法的核心实现
下面是程序是如何持续运行
void MainWindow::on_pushButton_clicked()
{
for(int i=0;i<N;i++)
for(int j=0;j<N;j++)
dp[i][j]=0;
s1=ui->textEdit->toPlainText();
s2=ui->textEdit_2->toPlainText();
leng(s1, s2, dp);
LCS(s1.length(),s2.length());
result="";
k=0;
s1="";
s2="";
}当点击查重按钮时,首先DP表会先重置为0,接着用leng函数更新DP表,然后用LCS函数获取最长公共子序列并计算查重率,最后将计数器k、字符串s1、s2归零,处理文档时同理。
4. 核心算法
(1)最长公共子串算法
(2)最长公共子序列算法
以上两种算法就是本次课程设计重点研究的算法。也都在问题分析中进行了逐个分析了状态转移方程、代码实现。
(三)用户手册
(1)本程序不可以实现大量文本复杂精确地查重,用户仅可以使用该程序检测两个字段的相似程度。
(2)不能实现大量文本查重是因为会爆栈、不能实现复杂精确查重是因为只使用LCS过于简单,存在一些纰漏。
(四)调试及测试
1. 部分程序运行截图
主界面截图:

中文测试截图(答辩视频中文件和字段结果略有差别是因为文本框没删干净):

英文测试截图:
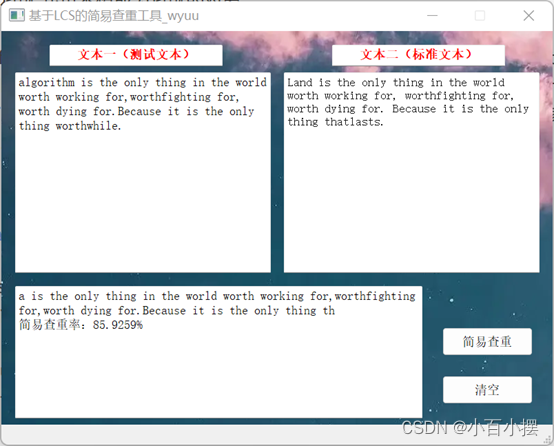
最长公共子串截图:
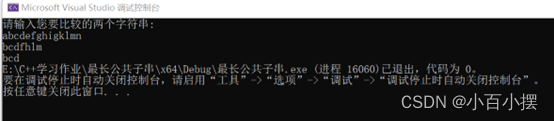
上面是在VS中进行测试的最长公共子串算法的实现。
4. 进一步改进
(1)算法不能处理大量文本,可能会导致爆栈
(2)只使用了LCS算法,精准度综合性欠缺。
(3)用户自己输入标准文档,应借助数据库简化这一流程。
(4)引入数据库后还要改进查询和LCS的策略,需要进一步思考。
(五) 感想
算法源自于生活。
经过查阅可知常见的查重算法包括以下几种:
(1)基于字符串匹配的算法:
如最长公共子序列(Longest Common Subsequence,LCS)、最长公共子串(Longest Common Substring)等。这些算法通过比较文本字符串之间的相似性来进行查重。
(2)基于哈希的算法:
如SimHash和MinHash算法。这些算法将文本转换为哈希值,并比较哈希值之间的相似度来进行查重。
(3)基于向量空间模型的算法:
如TF-IDF(Term Frequency-Inverse Document Frequency)和余弦相似度。这些算法将文本表示为向量,在向量空间中计算相似度来进行查重。
(4)基于机器学习的算法:
如文档嵌入模型和神经网络模型。这些算法利用机器学习方法训练模型,然后使用模型来判断文本之间的相似度和重复程度。
这些算法各有特点和适用场景,我们可以根据实际需求选择合适的算法来进行查重。在实际应用中,通常会结合多种算法来提高查重的准确性和效果。
而在本次课程设计程序中,我们实现时只采取了第一种查重算法,但也分别了解了其他几种查重算法以及他们在工业界中的应用。
比如我们人人知晓的中国几乎是最大的论文网站“知网”的查重算法,
其最重要的查重逻辑是每13个字符,包括汉字、数字、英文等,与数据库进行比对,比对重复就算重复。另外还有相似段落识别,如果相似度较高就改用6个字符进行比对。
配套模糊计算、分章节检测,设定5%的阈值等等多种手段。
于是我又查阅了模糊算法的相关资料:
模糊算法是一类用于处理模糊查询或近似匹配的算法。它们可以在输入数据与目标数据之间进行相似度比较,并根据相似度来确定它们是否匹配或相关。
以下是几种常见的模糊算法:
(1)编辑距离(Edit Distance)算法:编辑距离是衡量两个字符串间相似程度的指标,表示从一个字符串转换为另一个字符串所需的最少编辑操作次数。常见的编辑操作包括插入、删除、替换字符等。
(2)基于特征向量的相似度算法:这种算法将文本或其他数据转化为向量形式,并计算向量之间的相似度。常见的方法有余弦相似度、欧氏距离、Jaccard相似系数等。
(3)N-Gram算法:N-Gram将文本切分成连续的N个字符或词组,然后计算N-Gram之间的相似性。通常使用的是2-Gram(又称为bigram)或3-Gram(trigram)。
(4)模糊查找算法:比如模糊匹配(Fuzzy Matching)算法和正则表达式等。它们通过允许一定程度上的差异或模糊性,来实现对模式的匹配和查找。
这些算法都有不同的实现方式和适用场景,具体选择哪个算法取决于具体的需求和数据特点。在实际应用中,常常需要结合多种算法来达到更好的模糊匹配效果。
在这一过程中,我考虑到编辑距离算法的操作思路与我们的最大公共子串和最大公共子序列应该是相同的。
下面是我对模糊算法中的编辑距离算法的分析:
这个问题的解决方案同样是制作DP表,然后求解。
制作DP表的动态转移方程转换为代码如下:
for (i = 1; i <= s1.length(); i++)
{
for (j = 1; j <= s2.length(); j++)
{
if (s1[i - 1] == s2[j - 1])
{
con = 0;
}
else
{
con = 1;
}
del = a[i - 1][j] + 1;
ins = a[i][j - 1] + 1;
sub = a[i - 1][j - 1] + con;
a[i][j] = get_min(del, ins, sub);
}
}
这里都是使用了动态规划的思想,对DP数组进行操作
这里的动态规划方程是:
del = a[i - 1][j] + 1;(这是删除的情况)
ins = a[i][j - 1] + 1;(这是添加的情况)
sub = a[i - 1][j - 1] + con;(这是替换的情况)
a[i][j] = get_min(del, ins, sub);
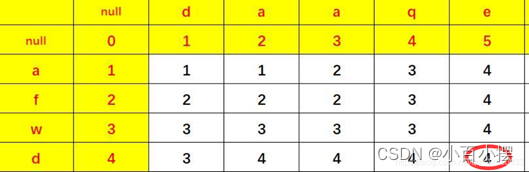
如果两个字符是相同的,那么con=0,意味着可以减少一步操作(因为这个位置上已经相同了,不需要增删替换了)所以操作数可以少1。
上面是我在大佬博客上看到的一张图:
解释一下:
当两个字符串都为空的时候,操作数是0,所以(0,0)是0步操作,(1,1)之所以是1,是因为由d变为a,所需要的操作是一步!接下来进行拓展,解释(1,2)是怎么来的:由于a与a相同,所以左上角是1+0=1;
左边是1+1=2,上边是2+1=3;所以我们选择最小的1,可以这么理解,左上角的1是指a加上d变成da,左边的2是指a添加一个d,变成da,上边的3是指da先变为null,最后再添加一个a,怎么说呢,某个字符通过对应的直角拐角转化为对应的字符,然后+1,当有相同元素时就可以少一步操作。
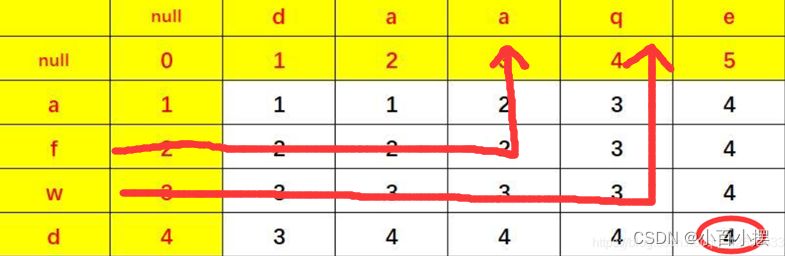
这张图就是说af最少经过2步转为daa,afw最少经过3步转为daaq。
这就实现了最短编辑距离的计算。
有了最短编辑距离后我们可以进一步确定两个字段的相似性,刚才提到知网借助13个字符为依据查重,为了防止有人使用虽然、但是等连接词蒙混过关,还会进行相似段落检测,其中就用到了上面的编辑距离算法,若编辑距离较短,则相似性高,启用6个字符为依据查重,对比重复则重复。
但是由于我知识的浅薄,不清楚相似段落的编辑距离的具体指标,不能应用在我的查重工具中了。不过下面是我查阅得到的编辑距离算法的可以设置的指标:
编辑距离算法通常用于衡量两个字符串之间的相似程度,它可以被扩展到判断相似段落或文本的指标。以下是一些常见的指标:
(1)相似度得分(Similarity Score):编辑距离算法可以计算两个段落之间的最小编辑操作次数,比如插入、删除和替换字符的次数。通过将最小编辑操作次数归一化为一个0到1的范围,可以获得相似度得分,表示两个段落之间的相似程度。得分越接近1,表示两个段落越相似。
(2)相似度阈值(Similarity Threshold):在某些场景中,可以根据编辑距离来设置一个相似度阈值,用于判断两个段落是否相似。如果两个段落的编辑距离低于预先设定的阈值,则可以认为它们相似;否则,它们不相似。
(3)重复词汇(Repeated Vocabulary):编辑距离算法还可以用于检测段落中是否存在重复的词汇。通过比较段落中每个单词与其他单词的编辑距离,可以找出相似的词汇对。如果两个词汇的编辑距离低于某个阈值,则可以认为它们是重复的词汇。
需要注意的是,编辑距离算法仅考虑字符串之间的编辑操作次数,而对于语义上的相似性并不敏感。在判断相似段落时,可能还需要结合其他的自然语言处理技术,如词向量表示、文本分类等,以获得更准确和全面的结果。
最后总结一下本次课设的研究历程:
首先实现了最长公共子串的算法,接着实现了最长公共子序列的算法,并将LCS算法应用在程序中,制作了一个简易的查重工具,然后在研究上述两个算法在工业界应用时,了解且实现了关于相似段落检测的编辑距离算法。
感谢观看!
求最长公共子串代码:
#include <iostream>
#include <string>
using namespace std;
const int N = 101;
int dp[N][N];
int main()
{
string str1;
string str2;
cout << "请输入您要比较的两个字符串:" << endl;
cin >> str1;
cin >> str2;
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
dp[i][j] = 0;
int len1 = str1.length(); int len2 = str2.length(); int max = 0; int start = 0;
for(int i=1;i<=len1;i++)
for (int j = 1; j <= len2; j++)
{
if (str1[i - 1] == str2[j - 1])
dp[i][j] = dp[i - 1][j - 1] + 1;
if (dp[i][j] > max)
{
max = dp[i][j];
start = i - max;
}
}
cout << str1.substr(start, max);
}
查重程序的代码(基于LCS):
头文件
#ifndef MAINWINDOW_H
#define MAINWINDOW_H
#include <QMainWindow>
#include <string>
#include <QString>
#include <cmath>
#include <QFile>
#include <QFileDialog>
#include <QMessageBox>
#include <QTextStream>
#include <QDebug>
using namespace std;
QT_BEGIN_NAMESPACE
namespace Ui { class MainWindow; }
QT_END_NAMESPACE
class MainWindow : public QMainWindow
{
Q_OBJECT
public:
MainWindow(QWidget *parent = nullptr);
void LCS(int i,int j);
~MainWindow();
private slots:
void on_pushButton_clicked();
void on_pushButton_2_clicked();
void on_pushButton_3_clicked();
void on_pushButton_4_clicked();
void on_pushButton_5_clicked();
private:
Ui::MainWindow *ui;
int k=0;
QString result;
QString path1;
QString path2;
QString s1;
QString s2;
};
#endif // MAINWINDOW_H
Cpp文件
#include "mainwindow.h"
#include "ui_mainwindow.h"
MainWindow::MainWindow(QWidget *parent)
: QMainWindow(parent)
, ui(new Ui::MainWindow)
{
ui->setupUi(this);
setWindowTitle("基于LCS的简易查重工具_wyuu");
setFixedSize(800,600);
}
MainWindow::~MainWindow()
{
delete ui;
}
const int N = 1024;
int dp[N][N];
int get_min(int a, int b, int c) {
if(a>b){
if(b>c)
return c;
else
return b;
}
else{
if(a>c)
return c;
else
return a;
}
}
int leng(QString s1, QString s2, int dp[][N])
{
if (s1.length()==0 || s2.length()==0)
{
return 0;
}
for (int i = 1; i <= s1.length(); i++)
{
for (int j = 1; j <= s2.length(); j++)
{
if (s1[i - 1] == s2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else
{
if(dp[i-1][j]>dp[i][j-1])
dp[i][j]=dp[i-1][j];
else
dp[i][j]=dp[i][j-1];
}
}
}
return dp[s1.length()][s2.length()];
}
void MainWindow::LCS(int i,int j)
{
// QString s1=ui->textEdit->toPlainText();
// QString s2=ui->textEdit_2->toPlainText();
// if(s1.length()<s2.length())
// swap(s1,s2);
if (i == 0 || j == 0)
return;
if (s1[i - 1] == s2[j - 1])
{
LCS(i - 1, j - 1);
result += s1[i-1];
}
else if (dp[i][j - 1] > dp[i - 1][j])
{
LCS(i, j - 1);
}
else
{
LCS(i - 1, j);
}
k++;
//qDebug()<<k;
if(k==s1.length())
{
double l1=result.length();
qDebug()<<l1;
double l2=s1.length();
qDebug()<<l2;
double jieguo = l1/l2*100;
qDebug()<<jieguo;
QString jie = QString::number(jieguo,'f',4);
ui->textBrowser->append(result);
ui->textBrowser->append("简易查重率:"+jie+"%");
}
}
void MainWindow::on_pushButton_4_clicked()
{
path1 = QFileDialog::getOpenFileName(this,"打开文件","此电脑");
ui->textEdit->setText(path1);
}
void MainWindow::on_pushButton_5_clicked()
{
path2 = QFileDialog::getOpenFileName(this,"打开文件","此电脑");
ui->textEdit_2->setText(path2);
}
void MainWindow::on_pushButton_2_clicked()
{
ui->textEdit->setText("");
ui->textEdit_2->setText("");
ui->textBrowser->setText("");
}
QString read(QFile& file)
{
file.open(QIODevice::ReadOnly);
QByteArray array;
while(!file.atEnd())
{
array+=file.readLine();
}
QString str=QString(array);
return str;
}
void MainWindow::on_pushButton_clicked()
{
for(int i=0;i<N;i++)
for(int j=0;j<N;j++)
dp[i][j]=0;
s1=ui->textEdit->toPlainText();
s2=ui->textEdit_2->toPlainText();
leng(s1, s2, dp);
LCS(s1.length(),s2.length());
result="";
k=0;
s1="";
s2="";
}
void MainWindow::on_pushButton_3_clicked()
{
for(int i=0;i<N;i++)
for(int j=0;j<N;j++)
dp[i][j]=0;
QString fileone=ui->textEdit->toPlainText();
QString filetwo=ui->textEdit_2->toPlainText();
QFile testtext(fileone);
if(!testtext.open(QIODevice::ReadOnly))
{
QMessageBox::information(NULL,QString("error!"),QString("测试文件无法打开"));
return;
}
QFile stdtext(filetwo);
if(!stdtext.open(QIODevice::ReadOnly))
{
QMessageBox::information(NULL,QString("error!"),QString("标准文件无法打开"));
return;
}
s1=read(testtext);
s2=read(stdtext);
leng(s1, s2, dp);
LCS(s1.length(),s2.length());
result="";
k=0;
s1="";
s2="";
}
以及实现编辑距离算法的代码:
#include<iostream>
#include<vector>
using namespace std;
int get_min(int a, int b, int c) {
return min(a, min(b, c));
}
void get_way(string s1, string s2, vector<vector<int> > a)
{
int i, j;
int con, del, ins, sub;
a[0][0] = 0;
for (i = 1; i <= s1.length(); i++)
{
a[i][0] = i;
}
for (j = 1; j <= s2.length(); j++)
{
a[0][j] = j;
}
for (i = 1; i <= s1.length(); i++)
{
for (j = 1; j <= s2.length(); j++)
{
if (s1[i - 1] == s2[j - 1])
{
con = 0;
}
else
{
con = 1;
}
del = a[i - 1][j] + 1;
ins = a[i][j - 1] + 1;
sub = a[i - 1][j - 1] + con;
a[i][j] = get_min(del, ins, sub);
}
}
cout << "需要的最少次数为:" << endl << a[s1.length()][s2.length()] << endl;
}
int main(void)
{
string s1, s2;
cout << "输入第一个字符串" << endl;
cin >> s1;
cout << "输入第二个字符串" << endl;
cin >> s2;
vector<vector<int> > a(s1.length() + 1, vector<int>(s2.length() + 1));
get_way(s1, s2, a);
return 0;
}














 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









