







Artificial Neural Network
Example
•AASTOCKS.com
使用递归神经网络对未来股票价格进行 5 天预测
•Sport betting
使用神经网络预测比赛结果(1=胜,0=负)
还有在线房地产估价师--联邦住房贷款抵押公司(房地美)使用神经网络为全美各地的房屋自动进行估价
H(human)NN,或者叫做BNN,生物神经网络
在人脑中,神经网络约有 1011 个高度互联的神经元并行运作--在接收到来自其他神经元的电化学信号后,该神经元被激活并向其他神经元发送信号
基本理念--将输入信息整合到复杂而灵活的神经网络 "模型 "中--在迭代过程中不断调整模型 "系数"--网络在分类和预测方面的临时表现为后续调整提供依据
网络结构
多层--输入层(原始观测数据)--隐藏层
输出层--节点--权重(与系数类似,需进行迭代调整)--偏置值(也与系数类似,但无需进行迭代调整)
input layer----------hidden layers----------output layer(all of them called mutiple layer)
人工神经元
隐节点中的组合函数--如线性
隐节点中的激活函数--如线性、逻辑、RBF
输出节点中的输出激活函数--如线性、符号
多层感知器(MLP)--最广泛使用的前馈神经网络--线性组合函数--Tanh 激活函数
激活函数的举例
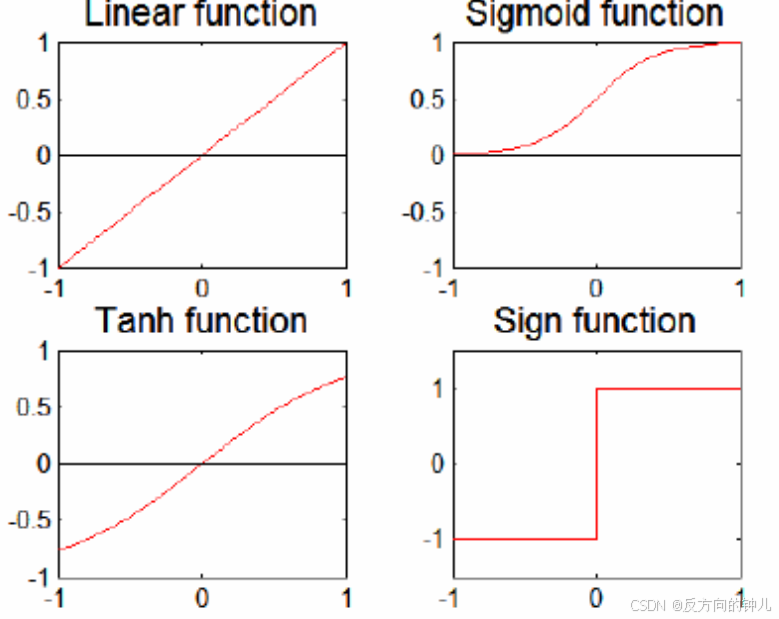

三种常见的激活函数,它们在神经网络中用于引入非线性特性,使网络能够学习复杂的模式
1. Logistic 或 Sigmoid 函数
- 这个函数的输出范围在0到1之间,常用于二分类问题中,因为它可以输出一个概率值。
2. 双曲正切(Hyperbolic tangent)函数:
- 输出范围在-1到1之间。这个函数相比Sigmoid函数,输出更接近于0,这有助于解决梯度消失问题。
3. Softmax 函数:
用于多分类问题,其中输出节点j代表m个类别中的一个。Softmax函数将输入的向量转换为概率分布,使得所有输出的和为1,每个输出值在0到1之间。
- 为了识别,我们设置 ,这通常用于归一化,使得其中一个类别的概率为基准。
这些函数在神经网络的输出层中非常重要,因为它们决定了网络如何将原始输出转换为最终的预测结果。
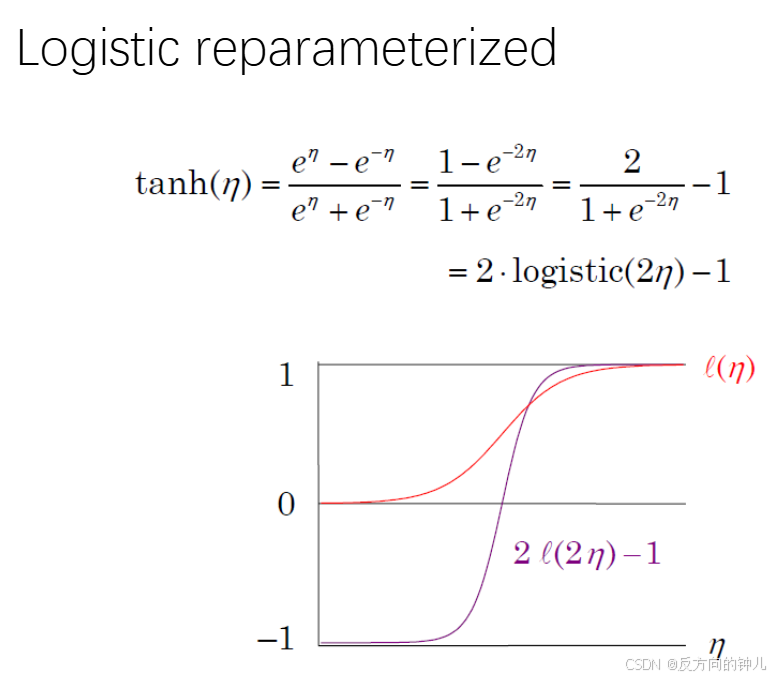
直观的看待tanh和logistics的数学关系
单隐层 ANN(ANN with single hidden layer)和双隐层
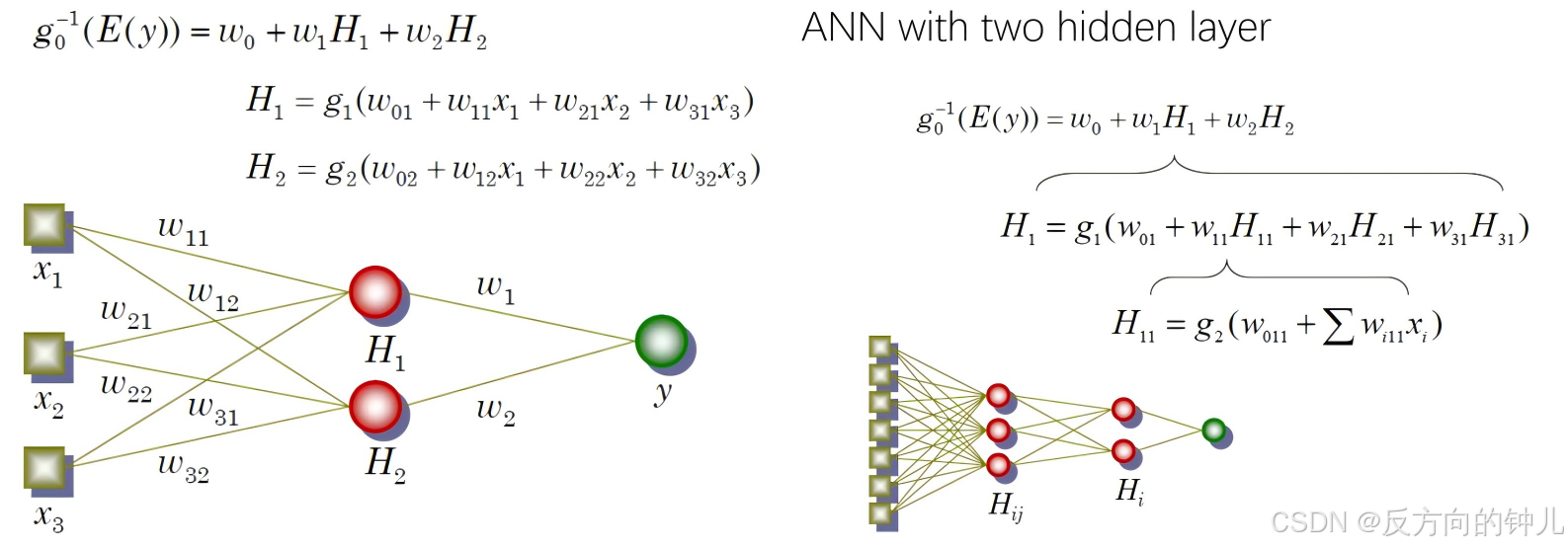
初始通过网络
目标:找到能产生最佳预测结果的权重--对所有记录重复上述过程--在每条记录上比较预测结果和实际结果--差值即为输出节点的误差
误差被传回并分配给所有隐藏节点,用于更新它们的权重
成本函数和权重更新

The BP Algorithm
反向传播算法(Backpropagation,简称BP算法)是一种用于训练人工神经网络的常见方法,它结合了梯度下降等优化技术来调整网络中的权重和偏置,以最小化损失函数。BP算法的核心在于通过计算损失函数的梯度,并利用这些梯度信息来更新网络参数,从而减少预测输出与真实值之间的误差。
BP算法的学习过程包括两个主要部分:正向传播和反向传播。在正向传播过程中,输入信号从输入层经过每一层神经元处理后传递到输出层,生成预测结果。如果输出层的实际输出与期望输出不符,则进入反向传播阶段。在反向传播阶段,误差信号从输出层反向传递回输入层,沿途计算每层神经元的误差贡献,并据此更新每层神经元的权重和偏置。
具体来说,BP算法的实施步骤如下:
1. 初始化网络中的权重和偏置。
2. 进行前向传播,计算各层的输出和最终的损失函数值。
3. 在反向传播阶段,计算损失函数对每个权重和偏置的偏导数,即梯度。
4. 利用梯度下降法更新权重和偏置,以减少损失函数的值。
5. 重复步骤2-4,直到网络输出的误差减少到可接受的程度,或达到预设的训练迭代次数。
BP算法的重要性在于它为深度学习的发展提供了基础,使得复杂神经网络的训练成为可能。它不仅提高了神经网络的训练效率,还因其通用性被广泛应用于各种类型的神经网络,如卷积神经网络(CNN)、循环神经网络(RNN)等,并在图像识别、自然语言处理、推荐系统等多个领域取得了显著成果。
案例更新
每条记录通过网络运行后,权重都会更新--通过网络完成所有记录为一个纪元(也称为扫频或迭代)--完成一个纪元后,返回到第一条记录并重复该过程
批量更新
在更新之前,先将训练集中的所有记录输入网络-在这种情况下,用于更新的误差是所有记录误差的总和
为何有效--大误差导致权重发生大变化--小误差使权重相对不变--经过数千次更新,给定权重不断变化,直到与该权重相关的误差可以忽略不计,此时权重变化很小
时间序列神经网络 Neural Networks for Time Series
线性自回归
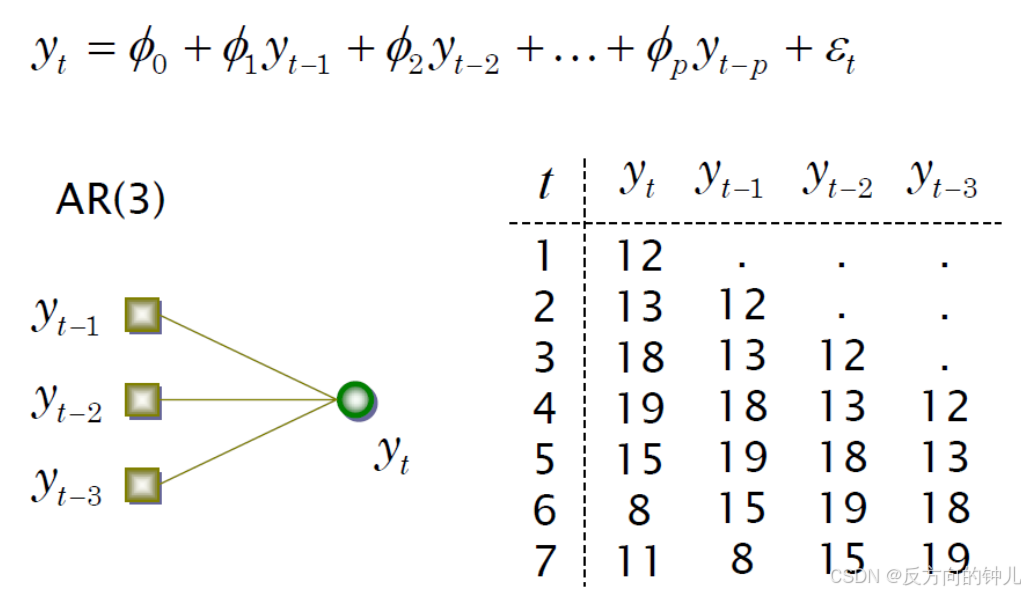
AR-MLP
AR-MLP(Attention ResNet-Multilayer Perceptron)是一种结合了自注意力机制和多层感知机(MLP)的神经网络架构。根据搜索结果,AR-MLP被提出用于人脸反欺诈检测方法,该方法能够处理多模态人脸图像,包括RGB图像、深度图像和红外图像。在这个方法中,AR-MLP网络通过堆叠耦合输入进行人脸图像处理,实现多模态特征融合,并通过转置、整形等操作提取不同人脸区域的特征。这些特征张量随后被送入集成了卷积和注意力机制的ACMix模块中。在AR-MLP中,每个块的MLP和跨块的全局MLP混合后,送入分类器进行特征分类,最终得到真实人脸或欺诈人脸的分类结果。
AR-MLP的核心优势在于其能够将多模态图像输入网络后进行深度特征融合,这使得模型在人脸反欺诈检测方面表现出色。通过这种方式,AR-MLP能够有效地识别和区分真实人脸和欺诈人脸,提高了人脸认证系统的安全性和可靠性。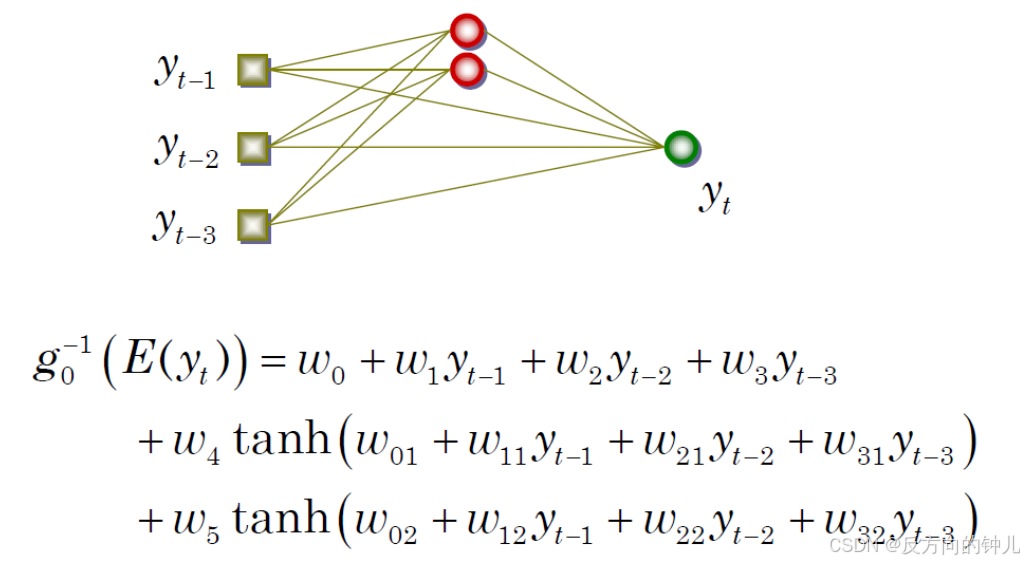
向量自回归
ANN缺点
被认为是一种 "黑箱 "预测机,无法深入了解预测因子与结果之间的关系-没有变量选择机制,因此在选择变量时必须谨慎-如果变量较多,则计算要求较高(额外的变量会大大增加需要计算的权重)。
拟合 ANN 的问题--数据准备
预处理步骤-将变量刻度为 0-1-分类变量-如果类别相等,则映射到 0-1 范围内的等距区间点-否则,创建虚拟变量-转换(如对数)倾斜变量
权重--权重 b 和 w 通常初始化为 -0.05 至 +0.05 范围内的随机值--相当于一个随机预测模型(换句话说,没有预测价值)--这些初始权重用于第一轮训练--学习率--低值会在每次迭代时 "降低 "来自误差的新信息的权重--这会减慢学习速度,但会降低过度拟合局部结构的趋势。
指定网络结构隐藏层数-最常用-一个隐藏层隐藏层节点数-节点越多越复杂,但会增加过拟合的几率输出节点数-对于分类,每类一个节点(二进制情况下也可使用一个节点)-对于数值预测,使用一个节点
有多少个隐藏节点--隐藏节点的数量取决于:
输入和输出节点的数量--训练案例的数量--目标中的噪音量--要学习的功能或分类的复杂性。 -如果隐藏节点太少,由于拟合不足和统计偏差过大,将导致训练误差和测试误差过高。
网络结构,续。"学习率 "l--低值 "降低 "了每次迭代中来自错误的新信息的权重--这减慢了学习速度,但降低了过度拟合局部结构的趋势。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









