









由来: KMP由克努特(Knuth)、莫里斯(Morris)和普拉特(Pratt)共同设计,名字由来取自他们各自名字的首字母。
改进: 每当一趟匹配过程出现字符不相等时,无需回溯主串的指针,而是利用已经得当的“部分匹配”的结果将模板串向右滑动尽可能远的一段距离,继续进行比较。
名字: 前缀:包含首字母,除了最末尾的字符按顺序所构成的所有字符串。如:aabs的前缀有a,aa,aab。
后缀:包含最末尾的字母,除去首字母按顺序所构成的所有字符串。如:aabs的后缀有 s,bs,abs。
最长相等前后缀(自己取的):一般用ne[i]存储,表示有i个字符时的最长相等前后缀。
如a的最长相等前后缀为0,aa为1,aab为0,aaba为1,ababa为3.
例题
# 【模板】KMP字符串匹配
## 题目描述
给出两个字符串 $s_1$ 和 $s_2$,若 $s_1$ 的区间 $[l, r]$ 子串与 $s_2$ 完全相同,则称 $s_2$ 在 $s_1$ 中出现了,其出现位置为 $l$。
现在请你求出 $s_2$ 在 $s_1$ 中所有出现的位置。
定义一个字符串 $s$ 的 border 为 $s$ 的一个**非 $s$ 本身**的子串 $t$,满足 $t$ 既是 $s$ 的前缀,又是 $s$ 的后缀。
对于 $s_2$,你还需要求出对于其每个前缀 $s'$ 的最长 border $t'$ 的长度。
## 输入格式
第一行为一个字符串,即为 $s_1$。
第二行为一个字符串,即为 $s_2$。
## 输出格式
首先输出若干行,每行一个整数,**按从小到大的顺序**输出 $s_2$ 在 $s_1$ 中出现的位置。
最后一行输出 $|s_2|$ 个整数,第 $i$ 个整数表示 $s_2$ 的长度为 $i$ 的前缀的最长 border 长度。
## 样例 #1
### 样例输入 #1
```
ABABABC
ABA
```
### 样例输出 #1
```
1
3
0 0 1
```
## 提示
### 样例 1 解释
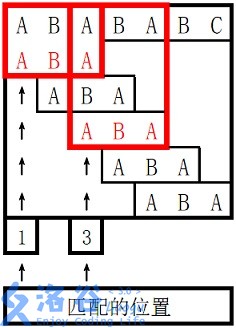。
对于 $s_2$ 长度为 $3$ 的前缀 `ABA`,字符串 `A` 既是其后缀也是其前缀,且是最长的,因此最长 border 长度为 $1$。
### 数据规模与约定
**本题采用多测试点捆绑测试,共有 3 个子任务**。
- Subtask 1(30 points):$|s_1| \leq 15$,$|s_2| \leq 5$。
- Subtask 2(40 points):$|s_1| \leq 10^4$,$|s_2| \leq 10^2$。
- Subtask 3(30 points):无特殊约定。
对于全部的测试点,保证 $1 \leq |s_1|,|s_2| \leq 10^6$,$s_1, s_2$ 中均只含大写英文字母。


哎呦,第一次用c++!!!
有来有往,才能长久以往,所以点个赞吧。















 3307
3307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









