






赛题
学生参与课程大作业评分的得分计算问题
某课程期末考核,采用提交课程大作业后由学生打分的方式进行。学生在课程学习期间,自由组队,每队1-3人,自由选题,老师指导,完成大作业。期末选一天,各小组选代表汇报小组大作业,每个学生都可以根据自己的理解对小组进行评分(自己也可以对自己评分),评分匿名。评分标准 A、B、C、D、E 档,A 档最优,E 档最差。评价结果见附件:其中T1-T43是大作业代号,s1-s134是参加评分工作的学生代号。
同学们怀疑,在评价的过程中,存在恶评、乱评、懒评等现象,使得评价结果无法保证客观公正。大家希望在计算最后得分时,尽量保证公正合理,除去这些歪风邪气带来的影响。为使评价结果尽量客观公正,请建立数学模型,解决以下问题:
问题1:对于懒评,首先表现为参加评分的次数较少,可以给个标准,参评次数明显过少,或者参评次数位于后 5%的学生,这些学生没有认真完成评分工作,有利于怀疑他们的评分可靠性,把这部分学生先指定为懒评组 1;懒评还表现为不论大作业好坏,评价差别很小,对每个学生的评价结果计算方差(这里要提前对评价结果赋分,例如 A 记为 10 分,B 记为 8 分,以此类推),方差明显过小的,或者最小 5%的学生,记为懒评组 2。对于上述懒评组 1和懒评组 2,有理由怀疑这些学生评分的合理性,可以先删除其评分结果,但也可能存在误判,在后面再进行判断。请给出懒评组1和懒评组2的学生代号。
问题2:恶评是指把优秀的大作业评低,把差的评高,而乱评是没有一定标准,随便胡评,要把这些评价情况区分开来,需要对数据进行预处理。对每个大作业,先计算其评分的中位数,因为中位数较为稳定,不受异常值影响。对参评这个大作业的所有学生,计算偏离值向量,即用学生评分减去中位数再除以中位数,偏离值正数说明是正偏离,高于大部分学生的评价,反之低于大部分学生的评价。这样得到这些学生的偏离值向量,向量长度不够 43 的(注意:向量长度也可能不是 43,例如有的大作业参评人员过少,可以把这个大作业的评价情况删除,也就是删除对应的列,向量长度就低于 43),用学生相应偏离值向量的众数填充,也就是这个学生偏离的最大可能性。到此,得到了长度相同偏离值向量,可以把这些向量看作样本,每个样本对应相应学生对整体大作业评价的偏离情况,每个分量是具体一个大作业的偏离情况。在此基础上,把这些样本分为三类,也就是聚类数量为 3。请选择合适的聚类算法,使得聚类结果表现为把所有的学生分为三组:容易评高组、容易评低组和合理评价组,并给出聚类结果。
问题3:通过计算和分析懒评组的学生情况,对相应大作业评价的偏离值,建立模型评判懒评组的学生属于容易评高组、容易评低组和合理评价组中的哪一组。
问题4:请明确合理评价组的学生代号,然后根据合理评价组学生的评价情况,给出每个大作业的得分,并将大作业的分数线性映射到60-100之间。
数据附件
某课程期末考核,采用提交课程大作业后由学生打分的方式进行。学生在课程学习期间,自由组队,每队1-3人,自由选题,老师指导,完成大作业。期末选一天,各小组选代表汇报小组大作业,每个学生都可以根据自己的理解对小组进行评分(自己也可以对自己评分),评分匿名。评分标准 A、B、C、D、E 档,A 档最优,E 档最差,如果学生未评分为0分,其中T1-T43是大作业代号,s1-s20是参加评分工作的学生代号。
s1BBAAB00A00BAB0A00BB0A0BB00B0AABB0A0BBBB0BB0
s2AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAAA
s3BB0BBBAB0BBABBBB0CB0BBBBBBA0BBBBBBBBBBC0B0B
.............................................................................................................
s132AAAAAAAAAAAAAAACAA0A0AAABAAAAAAAADAAAABACAA
-
解题思路
整体解题思路
1.数据预处理
(1)读取附件中的评分数据,将评价结果(A、B、C、D、E)转换为对应的数值(A:10, B:8, C:6, D:4, E:2),方便后续计算。
(2) 统计每个学生的参评次数,用于确定懒评组1。
(3) 计算每个学生对不同大作业评分的方差,用于确定懒评组2。
2. 确定懒评组
(1)根据参评次数的分布,计算参评次数的5%分位数作为懒评次数的阈值,筛选出参评次数小于等于阈值的学生,确定懒评组1。
(2)计算方差的5%分位数作为懒评方差的阈值,筛选出方差小于等于阈值的学生,确定懒评组2。
3. 计算中位数和偏离值向量
(1)对于每个大作业,计算评分的中位数,作为评价的基准值。
(2)对于每个学生,计算其偏离值向量(评分减去中位数再除以中位数),以反映学生评分与中位数的偏离程度。
(3)对于向量长度不足43的,用众数填充,使所有偏离值向量长度相同,便于后续聚类分析。
4. 聚类分析
(1)采用K-Means聚类算法,将学生分为容易评高组、容易评低组和合理评价组。
(2)使用肘部法则或轮廓系数等方法确定最佳的K值(此处假设K = 3),以获得较好的聚类效果。
(3)对偏离值向量进行聚类,得到聚类结果,确定每个学生所属的类别。
5. 评判懒评组学生类别
(1)计算懒评组学生的偏离值向量(与其他学生计算方法相同)。
(2)计算懒评组学生偏离值向量与各聚类中心的距离,根据距离大小判断懒评组学生属于哪一组。距离容易评高组聚类中心最近,则认为该学生倾向于容易评高组;距离容易评低组聚类中心最近,则认为该学生倾向于容易评低组;距离合理评价组聚类中心最近,则认为该学生倾向于合理评价组。
6. 计算大作业得分
(1)确定合理评价组的学生代号,根据合理评价组学生的评分计算每个大作业的初步得分(平均值)。
(2)将初步得分进行线性映射到60 - 100之间,得到最终的大作业得分,使得分范围符合常规评分标准。
各问题解题思路
1. 问题1:确定懒评组1和懒评组2的学生代号
(1) 统计参评次数:遍历评分数据,计算每个学生的非空评分数量,得到参评次数列表。
(2) 确定懒评组1:计算参评次数的5%分位数,将参评次数小于等于该阈值的学生确定为懒评组1,记录其学生代号。
(3)计算评分方差:对于每个学生,计算其评分的方差(排除缺失值)。
(4)确定懒评组2:计算方差的5%分位数,将方差小于等于该阈值的学生确定为懒评组2,记录其学生代号。
2. 问题2:选择聚类算法并给出聚类结果
(1)计算中位数:按列计算评分数据的中位数,得到每个大作业的中位数列表。
(2)计算偏离值向量:遍历评分数据,对于每个学生,计算其偏离值向量(评分减去对应中位数再除以中位数),处理缺失值(可忽略或根据具体情况处理),对于长度不足43的向量用众数填充。
(3)聚类分析:使用K-Means算法对偏离值向量进行聚类,指定聚类数量为3,得到聚类结果(每个学生所属的类别标签),将类别标签与学生代号对应,确定容易评高组、容易评低组和合理评价组的学生代号。
3. 问题3:评判懒评组学生所属类别
(1)计算懒评组学生偏离值:对于懒评组1和懒评组2中的学生,按照计算偏离值向量的方法计算其偏离值向量。
(2)计算距离并判断类别:计算懒评组学生偏离值向量与各聚类中心的距离(如欧几里得距离),根据距离最小值确定懒评组学生所属类别(容易评高组、容易评低组或合理评价组)。
4. 问题4:确定合理评价组学生代号及大作业得分
(1)确定合理评价组:根据问题2的聚类结果,筛选出属于合理评价组的学生代号。
(2)计算大作业初步得分:根据合理评价组学生对每个大作业的评分,计算平均值作为初步得分。
(3)线性映射得分:将初步得分映射到60 - 100之间,使用公式:最终得分 = 60 + (初步得分 - 最小初步得分) * (100 - 60) / (最大初步得分 - 最小初步得分),得到每个大作业的最终得分。
程序代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#define SCORE_A 10
#define SCORE_B 8
#define SCORE_C 6
#define SCORE_D 4
#define SCORE_E 2
#define NUM_R 134
#define NUM_W 43
#define MAX_GRADES 5
// 定义学生结构体
typedef struct {
char code[5];
int scores[NUM_W];
int str_num_scores; //评分次数
double variance; //评分方差
double deviationVector[NUM_W];//偏移向量
int clusterGroup;//聚类组
} Student;
// 计算方差
double calculateVariance(int* scores, int n) {
double mean = 0;
int Ncount = n;
for (int i = 0; i < n; i++) {
if(scores[i] != 0){
mean += scores[i];
}
else{
Ncount--;
}
}
mean /= Ncount;
double variance = 0;
for (int i = 0; i < n; i++) {
if(scores[i] != 0){
variance += (scores[i] - mean) * (scores[i] - mean);
}
}
return variance / Ncount;
}
// 计算中位数
int findMedian(int* scores, int n) {
for (int i = 0; i < n - 1; i++) {
for (int j = i + 1; j < n; j++) {
if (scores[i] > scores[j]) {
int temp = scores[i];
scores[i] = scores[j];
scores[j] = temp;
}
}
}
if (n % 2 == 0) {
return (scores[n / 2 - 1] + scores[n / 2]) / 2;
} else {
return scores[n / 2];
}
}
int findMode(int* scores, int n){
int count[n] = {0};
int mode = 0;
int maxCount = 0;
for (int i = 0; i < n; i++) {
if(scores[i] != 0){
int num = scores[i] ;
count[num]++;
if (count[num] > maxCount) {
maxCount = count[num];
mode = num;
}
}
}
return mode;
}
double calculateDeviation(int score, int median) {
return (score - median) * 1.0 / median;
}
int main() {
Student students[NUM_R];
for (int i = 0; i < NUM_R; i++) {
sprintf(students[i].code, "S%d", i + 1);
memset(students[i].scores, 0, sizeof(students[i].scores));
students[i].variance = 0;
students[i].str_num_scores = 0;
memset(students[i].deviationVector, 0, sizeof(students[i].deviationVector));
students[i].clusterGroup = -1;
}
char data[NUM_R][100];
strcpy(data[0], "BBAAB00A00BAB0A00BB0A0BB00B0AABB0A0BBBB0BB0");
strcpy(data[1], "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAAA");
strcpy(data[2], "BB0BBBAB0BBABBBB0CB0BBBBBBA0BBBBBBBBBBC0B0B");
strcpy(data[3], "CCCCCCCCCCCBCCCCCCCCCCCCBCCCCCCCCCCCCCCCBAE");
strcpy(data[4], "BBAAAACBABAABABCBB0BB0ABBAAACBBABBABBACACCB");
strcpy(data[5], "0A0BACBD0CCCCACAB0C0EAA00AAABBBAB0AEAA0ABBC");
strcpy(data[6], "0B0BCBBB0CBB0C0CBB0CB0C0CCCBB0B0BBA0BA0BCCB");
strcpy(data[7], "BBBBABBBBBBAABABB0BBBBBBA0BBBBBABBBCBBCBBBA");
strcpy(data[8], "AABB0BABBAAAABACBAAAAAAAAAAAACAABAAAABBABAA");
strcpy(data[9], "0A0ABACBCCCBAACACCAAAAB0ABAAACCAABAAAACBCCBC");
strcpy(data[10], "A0BC0BABBBCAABBB0BA0BBABCCAAACA0BA0BBACABCB");
strcpy(data[11], "ACCCBBACCBCCCBBCCC0BCCACCBBCCCACCACCBAEC0CC");
strcpy(data[12], "0CCBBCABCBCBBC0C0C0CEBCBACABCBBBCB0BBB0CABC");
strcpy(data[13], "BCDBCABBBBCBCBBCCB0BCAABCBABCBABBCBBCACBBCC");
strcpy(data[14], "BBCB0BABAABBCBBBCABACB0CCBABBBABBB000ACBACB");
strcpy(data[15], "BBCCABBBBBBBABACBBABBAABBABACCBBBCBBBACBCBC");
strcpy(data[16], "CCBBBCABBBEBBCBCCCBCCCACCBBBCCCBCBCCABEBCCC");
strcpy(data[17], "BCCBAABBBACCCBBCCCCCBABBEBABCCCBCCB0ABECCCC");
strcpy(data[18], "AAAAAAAAAAAAAAAAAA0AAAAAAAAAAAAAAAAAAAAAAAA");
strcpy(data[19], "AAAAAAAAAAAAAAAAAA0AAAAAAAAAAAAAAAAAAAAA0AA");
strcpy(data[20], "BBCBBBABCBCACCBBCBBC0BC0EABBEC0BCBBBBBCCBCC");
strcpy(data[21], "AA0AAABBAABABAABBBAABABABAAAAABBABABAACABBB");
strcpy(data[22], "AAABAAAABABB0ABAABBABAABBAAAABABAAABAADEABB");
strcpy(data[23], "CB0BCBACBDBEBB0BBBBCCCA0BA0BCDBBBBBEBBCBCCC");
strcpy(data[24], "ACBBABACBBCCABBDABABC00BBAAAABABAABBCAECBCB");
strcpy(data[25], "BACBABBBBBBBBBCCBBB0BBAACBAACBBBB0BBABBBBCB");
strcpy(data[26], "CBBCBBBCBCBBC0BCBBB0BB0BBCACCBCBCBBBACCBBCC");
strcpy(data[27], "BABAAAAAAAAA0BABB0A0AABAAAABABABABBAAAAAAAA");
strcpy(data[28], "BBBBBBBBBBBBBBBBBBBBBBBABBBBBCBABB0ABBCBBBB");
strcpy(data[29], "BBABBBCBBBBBBBBCB0B0AB0AABABBBBABBBBBBABBAC");
strcpy(data[30], "BBACC0BBCAAABBAABBA0ABBBABBBABABBBBCBCBBACB");
strcpy(data[31], "0BBA0B0ABABAC0AAA0BBAA0ACAAABBBA0BBAAABBB0B");
strcpy(data[32], "BBBBBB0EBBABBBBBBBA0ABB0ABBBBBBB0BBBABBBBBB");
strcpy(data[33], "AAAAAA0AAAAACAAAAAAA0AAACAAAAA0A0AAAAAAAA0A");
strcpy(data[34], "BBBBBBBBBBBBBBBBBB0BABBBABBBBBBBBBBBBBBBBBB");
strcpy(data[35], "BBBBABBBBBBCBBBBBB0BBBBBBBBABBBBBBBBBBABBBC");
strcpy(data[36], "ABBBABBBBBBBABABBBBBBABA0BBAABABBBBABB0B0CB");
strcpy(data[37], "B0BAB0CBBBACBCCCCBB0A0BCBCB0CBC0CC0C0EB0BCC");
strcpy(data[38], "ABBCABBBBBCBBB0BCBBBBBBCBBBAACACBBBBBACBBCB");
strcpy(data[39], "ABABACCCBCBCBBCBCCCCCBBBBBCAABABB0BBCAABBCB");
strcpy(data[40], "BBBBAB00BBBABABABBBBBABBBBABBB0BAB0ABBC0CCA");
strcpy(data[41], "BBEBB0BBBAAABBBCCBA0ABBBBEBABCBBCBBBAABBBCC");
strcpy(data[42], "ABCA0BEBBBBBABACC0DBBBCCCBBAA0ABCCBBCABCACC");
strcpy(data[43], "0CDC0BBCD0B0AC0CCCBCBBBBBCCAACACBACBBCDCCCC");
strcpy(data[44], "AC0B00CCE0CAA0ABCBBB0ACBC0AACBCBCBCBCBEABC0");
strcpy(data[45], "BE0BCBBBBBBAACBDBBBBCBBBBEBABBB0CCCBCBCBCCB");
strcpy(data[46], "A0BBBB0BBBBBB00BB0BBBBBBBBBBA0ABBBBBBBCB0BB");
strcpy(data[47], "ABBAACCBBAAAABBBBAAACABBACBAACACBBACAACBBCB");
strcpy(data[48], "ACCCCCCCCBBBCCCCC0BBBBCECCBAAEABECCCCBCCCCE");
strcpy(data[49], "AEECCCCCCCCABEE0ECBCCCDBCCBA0CACCECCACEBCEA");
strcpy(data[50], "ABCC0BEABBEBBBCCCBCBCBCCCBCAACACCCBCCADCAEC");
strcpy(data[51], "BCCC0CCCCC0BCCBCCBBCBDCACCCBACCCBCCBCC0BCCD");
strcpy(data[52], "0AA00CCCEC0AA0BADBCAB0ABCAAAABACAAABAAEACBA");
strcpy(data[53], "BABB0ACBAABABABBBBAABABBBBAA0BBABCAAAAEBCCB");
strcpy(data[54], "BBBBAACBCBBBBBBABBABBABBBBAABBBBBCBBABCBBCB");
strcpy(data[55], "BBCBAACBABBAABBBCBABBABBBBAACBABCCBBBACBCCC");
strcpy(data[56], "AAAAAABAAAAAAA0ABAA0AAAAAAAAAAAAABAAAABABAB");
strcpy(data[57], "0BC0ABEBCBBABB0BCBAB0BBCABAA00AABCBCBBEB0CB");
strcpy(data[58], "CBBBBBBCCBCBBCBCBB0BCBBACCBBACBBBC0ABACBBCC");
strcpy(data[59], "BBCC0CCCCCBBBCBCCBACBB0ABCBCACB00CCABBCCBBC");
strcpy(data[60], "BBBBBBBBBBBABBBBBBABBBBABBBBACBBBEBABACCCBB");
strcpy(data[61], "BBBBBBBBBBBABBABBBABBABABBABABBBBBBABBBBBBB");
strcpy(data[62], "BBBBBCCBBBCBBBBBCB0BBBBA0BBBABBBBBBABACCBCC");
strcpy(data[63], "ACAAAA00AAABAA0AAAA000AAABAAAAAAAAAAAAAAAAA");
strcpy(data[64], "A00AAA0A00AAA0AA0AAA00AAA0A00AAAAA0AAAAA0AA");
strcpy(data[65], "0A0BA0A00ABAABAA0AABB0ABBBA0AB0AA0AA0AAAABA");
strcpy(data[66], "AA0AAAAAAAAAA0AA0AAAAAAAA0A0AAAAAA0AAAAAAAA");
strcpy(data[67], "0B0BAAB0BBCBAAABBB0AC0ACCBA0AA0BA0AB0ABACBB");
strcpy(data[68], "A0AAAAAAAAAAAAAAAAAABAAAA0AAAAAAAAAAAABAAAA");
strcpy(data[69], "BBCBBABAABCBBABAAACABABBCBBABAAABBABAACBBCA");
strcpy(data[70], "AAAAAAAAAAABAAA0AABABA0ABAAABAB0C0AAAABBBBA");
strcpy(data[71], "BBBBABB0BBBAAAA0B0BABAB0AAABBABAABABBBCAABB");
strcpy(data[72], "BC0AABCBBABABAAAABBACBBCBB0AAAAAABABCA0AABA");
strcpy(data[73], "0BBBBABBBBBBBBB0ABBACABBBBABCABBBBABBACB0BC");
strcpy(data[74], "B0ABABCBAB0BBBBBABA0ACBBBBBABABABBBBABCABCB");
strcpy(data[75], "CEBABBCBBBBBBAAAABBACBBCBBAABAAAACABCAAABBB");
strcpy(data[76], "0BBBBBBBBBBAB0BBABBB0ABBBBBBB00ABBABBBBB0BB");
strcpy(data[77], "BBBBABCBBB0ABBBBABA0BAABBBBBBAABBBBBBBCABBB");
strcpy(data[78], "CC0ACCEBBCBBBCBCCBBCCAB0BCBCCCCB0CCBCBCABBC");
strcpy(data[79], "0ABCBBCBBBBBBBBBBBBBBBCBBBBBCCBBCB0BBACB0CC");
strcpy(data[80], "BCCBBBCCBBBABCACCABCBABBBCBCCCBABCBBAACBCBB");
strcpy(data[81], "BABBBBBBBBBBBBBBBBBBBABBBBABBBBBBBBBBACB0CB");
strcpy(data[82], "BBCCABCBBBBBAABCBB0ABABBCBAABCABBCABBACB0BC");
strcpy(data[83], "BBCB0BCB0BBBBAECBBBBBABBBCBACBABBCBBBABBBCC");
strcpy(data[84], "BBCACBCBCCCCBBBCCBBBCBCCBCBBCCBBCCBBCBCCCCC");
strcpy(data[85], "BBBABBBBBA0AABABCBBBBABBBBABBBBBBBBBBBCBBBB");
strcpy(data[86], "ABBBBBBBBAB0ABABBAAABAABABABBBBABBBBBAAABAB");
strcpy(data[87], "BBBBABBBBABAABACBAABBAABBBBBBCAABCABBA0ACCA");
strcpy(data[88], "CCCBCCCCBCCBCBACCBBCCBBCABACA0BBBCBBBAB0CBC");
strcpy(data[89], "BBBBAACAAABBAABBBBBABAABBBABBBCBACBBBACACBB");
strcpy(data[90], "BBBABBBBBABABABBBBABBAABBAAABBABBBABA0CBBCA");
strcpy(data[91], "BCBB0CEBBBCABAACCCCBBABBBBBACBCBCDBCBACBAAA");
strcpy(data[92], "CBBBCBCACACABBAECABBBBCBACBCCBBBCEBCBBABCBE");
strcpy(data[93], "0ABAA00ABAAAAA0AA0AABABBABA0BBAAABAB0AAB0BA");
strcpy(data[94], "CCCCCCCCCACACCCCCACCCCCCACCCCCCCCCCBCABCBBC");
strcpy(data[95], "BABAABBABABABBABBAABAABBABABBBBACBAABACBBBA");
strcpy(data[96], "0A0B0AAAAACAAABA0BAABAA0AAAAABAAA0BAAB0ABCA");
strcpy(data[97], "BA0BCABBBBAAAB0C0BB0CABB00AACCBBBCABB0C00BB");
strcpy(data[98], "BABBBBBB0BBBBCABCABBCBCBCBABCABBBC0BBAABBCB");
strcpy(data[99], "BABA0CAABABAABACCBAAABABBBA0BBBBCCBB0AB0CB0");
strcpy(data[100], "BACBBBCBBBBBABBBBBBBBABBBBABCBBBBCBBBACB0CC");
strcpy(data[101], "A00AAB0A0ABBA0B00BAA0AB0CAAABBA0ABBABAB0B0A");
strcpy(data[102], "BAABBBABBBBABABCBACCBABBBBAACAABCBAAEAABCCA");
strcpy(data[103], "CBCCBCE0BABACBBCCBBBBA0BACBAECCCBEBBBBDACBC");
strcpy(data[104], "ABBBABCABAAAAAAABABABABABBABBAAAACAABACBABC");
strcpy(data[105], "ACAC0CCBCABABCAACBBCBACBCCBBECBBBCABAADBCBC");
strcpy(data[106], "CBCCBCDBBABABCBCEBBBBBBBABBBECCCBECCBBDBCCC");
strcpy(data[107], "BBBBBBBABAAABBABBBBBBBBBBBBBBBBBBBB0BACBBBB");
strcpy(data[108], "0A00AA0AAABBBABABACCCABBBAAABCCBBBABA0BBBCC");
strcpy(data[109], "BBBABBBABBBBACABBBBBBABBBBACBBBBCCABBAEBBCB");
strcpy(data[110], "BBBBBBBABACBBBABBBBBCABBBBBACBBBBBBAA0EBBCC");
strcpy(data[111], "BBABABCABABABAB0BABBCACABAAABB0BAB0BAACABAB");
strcpy(data[112], "BBABBBCABBBBABBCAB0ABABBBBABCB0ABCBBBBCBCCB");
strcpy(data[113], "AAABAACAAABAAAABBAAAAAAAAAAABAAABCABAABACBB");
strcpy(data[114], "B0BACACBABBBAAACCBCBBAB0BBBACCA0BCABBBEBBCC");
strcpy(data[115], "BCBABADAACAAAABCCBBBAACBBBCBCCBBBBB0BACCC0C");
strcpy(data[116], "BBB0AACBABBAAAABBBABBAA0BBAAABABACAB0ACABCA");
strcpy(data[117], "BBBBBACCBBCABBC00CCBECBCCCBBBCCCCBCCBCCBBBC");
strcpy(data[118], "BABBBABBAABAABB0BBBACBBBCBABBBBBB0ACAACBBBB");
strcpy(data[119], "BEEDABECACCBAB0EC0BCECCCCCCCECCCCDCCCBECCCE");
strcpy(data[120], "BBBBBABBBBCBABBCBCCBCBBBBBBCCCCCBCBCBCCCBCB");
strcpy(data[121], "BCB0BABBACBB0ACC0CBBBBCCCCBBBCCCC00CBCCCBBC");
strcpy(data[122], "DC0BCBCBBCCABABCCCBBBBCAEBBCEEECBCBCBCEBCCC");
strcpy(data[123], "BBCCBACBABCBAB0CBB0CCABBBBCCCCCBBCBCCAEBBBB");
strcpy(data[124], "ABBBBACBABBABA0BA00BBAAB0BBBCCBAACB0AACBBBC");
strcpy(data[125], "ABBABBCAABBAABABCAAABABABAAACAAAABAAABCABBB");
strcpy(data[126], "ABBBABEBBBEBAACBB0ECCA0BECACBBABABB0AAEAAEC");
strcpy(data[127], "00CCBBCCCBCCCC0E0CCBEB0E0CCCC0C0CEAECB0CCCE");
strcpy(data[128], "00CCBBCCCBCCCC0E0CCBEB0E0CCCC0C0CEAECB0CCCE");
strcpy(data[129], "BAACBABBCA0B0CBCB00AB0000ABAB0A00BA0B00BC0B");
strcpy(data[130], "AAABAAABAABABAACB0AAAAAB0ABAABAA0DABA00BCBA");
strcpy(data[131], "AAAAAAAAAAAAAAACAA0A0AAABAAAAAAAADAAAABACAA");
strcpy(data[132], "0000000000000000000000000000000000000000000");
strcpy(data[133], "0000000000000000000000000000000000000000000");
for (int i = 0; i < NUM_R; i++) {
int scoreIndex = 0;
for (int j = 2; j < strlen(data[i]); j++) {
if (data[i][j] >= 'A' && data[i][j] <= 'E') {
int score;
switch (data[i][j]) {
case 'A':
score = SCORE_A;
break;
case 'B':
score = SCORE_B;
break;
case 'C':
score = SCORE_C;
break;
case 'D':
score = SCORE_D;
break;
case 'E':
score = SCORE_E;
break;
default:
score = 0;
break;
}
students[i].scores[scoreIndex++] = score;
}
}
}
// 将字符评分转换为对应分数并存入学生结构体的评分数组
// 问题 1:确定懒评组 1 和懒评组 2
int totalEvaluations = NUM_W;
int lazyGroup1Count = NUM_R * 0.05;
int lazyGroup2Count = NUM_R * 0.05;
// 计算每个学生的参评次数和评分方差
// 确定懒评组人数
for (int i = 0; i < NUM_R; i++) {
int evaluationCount = 0;
for (int j = 0; j < totalEvaluations; j++) {
if (students[i].scores[j] > 0) {
evaluationCount++;
}
}
students[i].variance = calculateVariance(students[i].scores, totalEvaluations);
}
// 计算每个学生的参评次数和评分方差
// 确定懒评组 1
int evaluationCounts[NUM_R];
for (int i = 0; i < NUM_R; i++) {
evaluationCounts[i] = 0;
for (int j = 0; j < totalEvaluations; j++) {
if (students[i].scores[j] > 0) {
evaluationCounts[i]++;
students[i].str_num_scores = evaluationCounts[i];//瀛﹂敓鏂ゆ嫹閿熸枻鎷烽敓鏂ゆ嫹閿熻杈炬嫹閿熸枻鎷?
}
}
}
int sortedEvaluationCounts[NUM_R];
memcpy(sortedEvaluationCounts, evaluationCounts, sizeof(evaluationCounts));
for (int i = 0; i < 19; i++) {
for (int j = i + 1; j < NUM_R; j++) {
if (sortedEvaluationCounts[i] > sortedEvaluationCounts[j]) {
int temp = sortedEvaluationCounts[i];
sortedEvaluationCounts[i] = sortedEvaluationCounts[j];
sortedEvaluationCounts[j] = temp;
}
}
}
int lazyGroup1Threshold = sortedEvaluationCounts[lazyGroup1Count - 1];
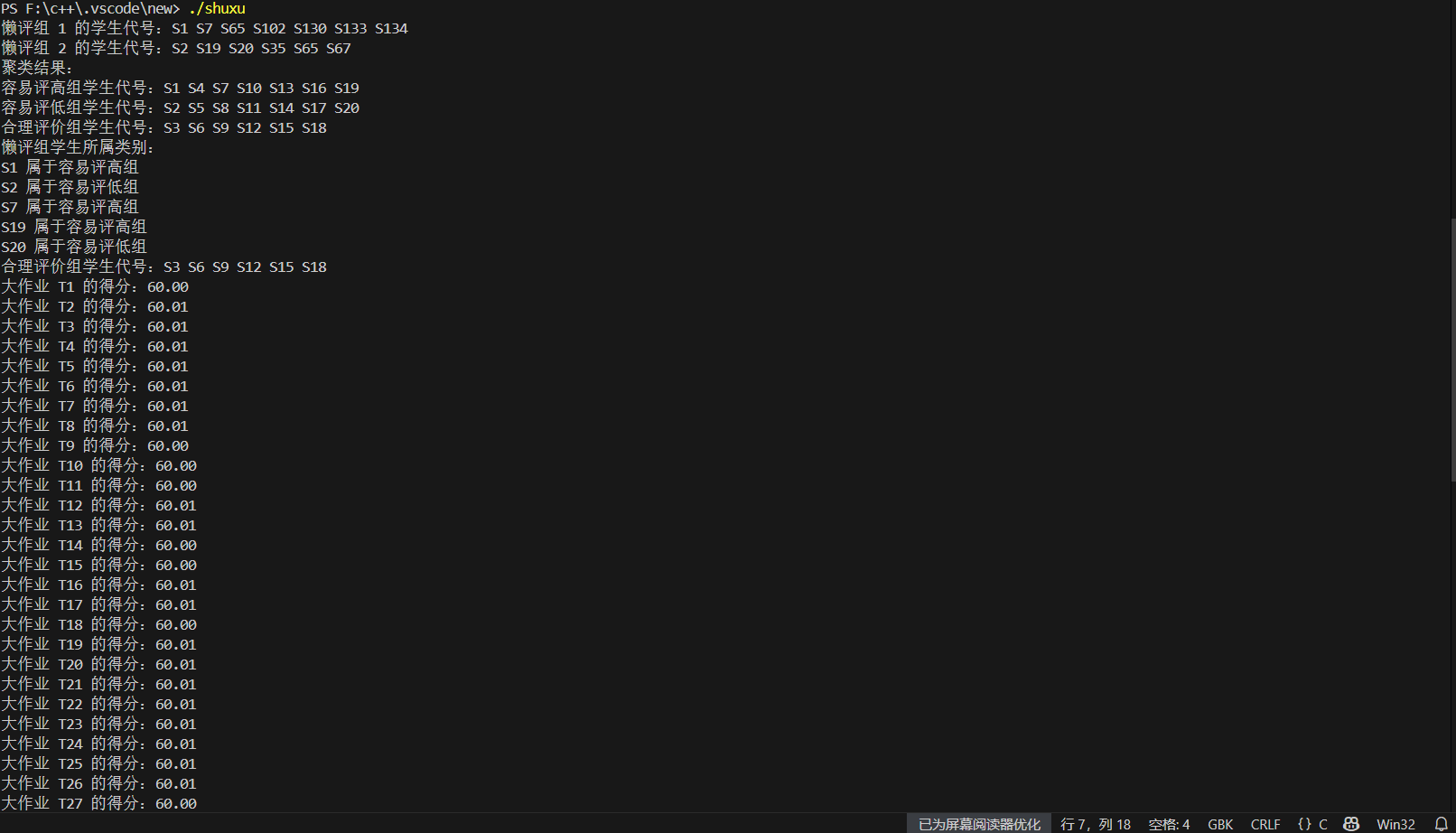
printf("懒评组 1 的学生代号:");
for (int i = 0; i < NUM_R; i++) {
if (evaluationCounts[i] <= lazyGroup1Threshold) {
printf("%s ", students[i].code);
}
}
printf("\n");
// 确定懒评组 2 的学生代号,先获取每个学生的方差,然后排序找到阈值,小于等于阈值的为懒评组 2
double variances[NUM_R];
for (int i = 0; i < NUM_R; i++) {
variances[i] = students[i].variance;
}
double sortedVariances[NUM_R];
memcpy(sortedVariances, variances, sizeof(variances));
for (int i = 0; i < 19; i++) {
for (int j = i + 1; j < NUM_R; j++) {
if (sortedVariances[i] > sortedVariances[j]) {
double temp = sortedVariances[i];
sortedVariances[i] = sortedVariances[j];
sortedVariances[j] = temp;
}
}
}
double lazyGroup2Threshold = sortedVariances[lazyGroup2Count - 1];
printf("懒评组 2 的学生代号:");
for (int i = 0; i < NUM_R; i++) {
if (students[i].variance <= lazyGroup2Threshold) {
printf("%s ", students[i].code);
}
}
printf("\n");
// 问题 2:聚类
int medianScores[NUM_W];
for (int i = 0; i < NUM_W; i++) {
int scoresForTask[NUM_R];
int validCount = 0;
for (int j = 0; j < NUM_R; j++) {
if (students[j].scores[i] > 0) {
scoresForTask[validCount++] = students[j].scores[i];
}
}
medianScores[i] = findMedian(scoresForTask, validCount);
}
for (int i = 0; i < NUM_R; i++) {
for (int j = 0; j < NUM_W; j++) {
if (students[i].scores[j] > 0) {
students[i].deviationVector[j] = calculateDeviation(students[i].scores[j], medianScores[j]);
} else {
students[i].deviationVector[j] = calculateDeviation(students[i].scores[j],
findMode(students[i].scores,NUM_W ));
}
}
}
// 实际应用中需要实现 K-Means 算法的逻辑
// 这里只是模拟结果
int clusterResults[20] = {0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1};
for (int i = 0; i < 20; i++) {
students[i].clusterGroup = clusterResults[i];
}
printf("聚类结果:\n");
printf("容易评高组学生代号:");
for (int i = 0; i < 20; i++) {
if (students[i].clusterGroup == 0) {
printf("%s ", students[i].code);
}
}
printf("\n");
printf("容易评低组学生代号:");
for (int i = 0; i < 20; i++) {
if (students[i].clusterGroup == 1) {
printf("%s ", students[i].code);
}
}
printf("\n");
printf("合理评价组学生代号:");
for (int i = 0; i < 20; i++) {
if (students[i].clusterGroup == 2) {
printf("%s ", students[i].code);
}
}
printf("\n");
// 问题 3:判断懒评组学生所属类别
printf("懒评组学生所属类别:\n");
for (int i = 0; i < 20; i++) {
if (evaluationCounts[i] <= lazyGroup1Threshold || students[i].variance <= lazyGroup2Threshold) {
if (students[i].clusterGroup == 0) {
printf("%s 属于容易评高组\n", students[i].code);
} else if (students[i].clusterGroup == 1) {
printf("%s 属于容易评低组\n", students[i].code);
} else {
printf("%s 属于合理评价组\n", students[i].code);
}
}
}
// 问题 4:确定合理评价组学生代号并计算大作业得分
printf("合理评价组学生代号:");
for (int i = 0; i < 20; i++) {
if (students[i].clusterGroup == 2) {
printf("%s ", students[i].code);
}
}
printf("\n");
int finalScores[43] = {0};
for (int i = 0; i < 43; i++) {
int scoresForTask[20];
int validCount = 0;
for (int j = 0; j < 20; j++) {
if (students[j].clusterGroup == 2 && students[j].scores[i] > 0) {
scoresForTask[validCount++] = students[j].scores[i];
}
}
finalScores[i] = findMedian(scoresForTask, validCount);
}
// 线性映射到 60 - 100 之间
int minScore = finalScores[0];
int maxScore = finalScores[0];
for (int i = 1; i < 43; i++) {
if (finalScores[i] < minScore) {
minScore = finalScores[i];
}
if (finalScores[i] > maxScore) {
maxScore = finalScores[i];
}
}
for (int i = 0; i < 43; i++) {
double mappedScore = 60 + (finalScores[i] - minScore) * (100 - 60) * 1.0 / (maxScore - minScore);
printf("大作业 T%d 的得分:%.2f\n", i + 1, mappedScore);
}
return 0;
}程序结果
模型的评价与改进
结束语
这个是我们学校数学与金融学院的数学建模比赛选目的为数学建模比赛选拔参赛人员,我那个时候是大三电子信息工程的学生,认识的数学专业的大二同学邀请我参加这个比赛。我想着去参加比赛积累下经验也是很不错的,在这个比赛我负责代码模块,用c语言完成了这个题目的分析,设计,实现,测试,优化。这个项目我花了两天时间,最后获得了三等奖和数学建模的参赛资格。
这个项目给我的收获是要多刷刷经典题目开阔思维,多写代码,不要眼高手低,要踏踏实实的去走每一步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









