






实验二 动态分区分配方式模拟
一、实验目的
(1)掌握动态分区分配方式使用的数据结构和分配算法
(2)进一步加深对动态分区分配管理方式及其实现过程的理解
二、实验内容及原理
编写C语言程序,模拟实现首次、最佳和最坏适应算法的内存块分配和回收,要求每次分配和回收后显示出空闲分区和已分配分区的情况。假设初始状态下,可用的内存空间为640KB。
三、实验设备与环境(实验用的软硬件环境)
Microsoft Windows [版本 10.0.22631.4602]
Visual Studio Code 1.96.2
gcc version 12.2.0
四、方法与实验步骤
1、实验要求部分
(1)数据结构设计
已分配分区表、空闲分区表

(2)分配算法设计
各个算法有共通的部分,在此写作fundationFit函数。

首次适应分配算法:firstFit函数
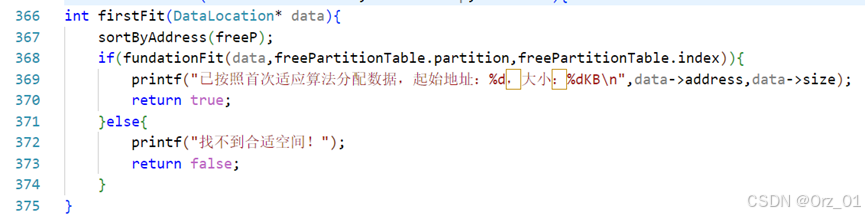
最佳适应分配算法:bestFit函数
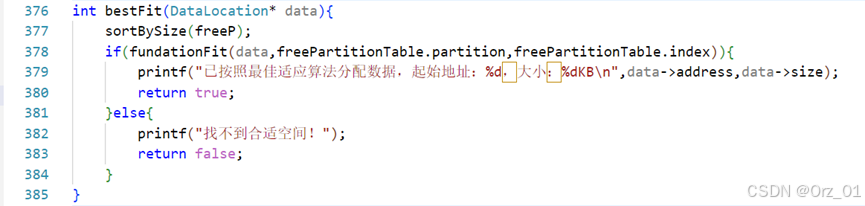
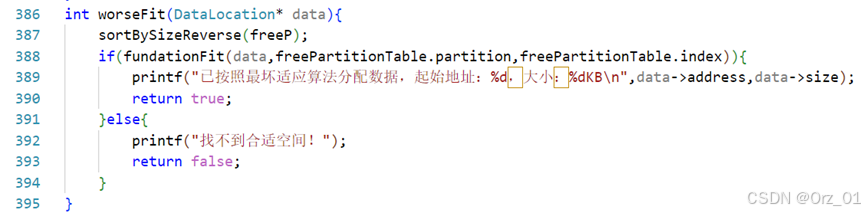
最差适应分配算法:worseFit函数
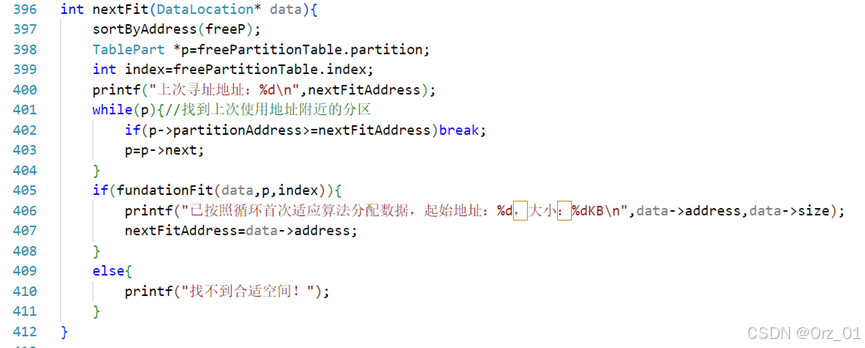
循环首次适应分配算法:nextFit函数
测试数据如下:

先打印一遍根据分配算法决定空闲分区表的排序,再打印一遍按地址升序排序。
其中按地址升序排序只对最佳和最坏适应分配算法是有意义的。
实验结果如下:
★★★★★★★★★★已预设数据★★★★★★★★★★
排序后打印:
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 5 20 30
2 70 50 4 70 120
3 140 190 3 10 330
4 80 340 2 110 420
5 20 530 1 90 550
************************************************************************
★★★★★★★★★★算法测试★★★★★★★★★★
已按照首次适应算法分配数据,起始地址:50,大小:40KB
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 5 60 30
2 30 90 4 70 120
3 140 190 3 10 330
4 80 340 2 110 420
5 20 530 1 90 550
************************************************************************
排序后打印:
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 5 60 30
2 30 90 4 70 120
3 140 190 3 10 330
4 80 340 2 110 420
5 20 530 1 90 550
************************************************************************
已按照最佳适应算法分配数据,起始地址:530,大小:20KB
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 90 4 60 30
2 30 0 3 70 120
3 80 340 2 10 330
4 140 190 1 220 420
************************************************************************
排序后打印:
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 4 60 30
2 30 90 3 70 120
3 140 190 2 10 330
4 80 340 1 220 420
************************************************************************
已按照最坏适应算法分配数据,起始地址:190,大小:20KB
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 120 210 4 60 30
2 80 340 3 90 120
3 30 0 2 10 330
4 30 90 1 220 420
************************************************************************
排序后打印:
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 4 60 30
2 30 90 3 90 120
3 120 210 2 10 330
4 80 340 1 220 420
************************************************************************
上次寻址地址:190
已按照循环首次适应算法分配数据,起始地址:210,大小:20KB
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 4 60 30
2 30 90 3 110 120
3 100 230 2 10 330
4 80 340 1 220 420
************************************************************************
排序后打印:
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 4 60 30
2 30 90 3 110 120
3 100 230 2 10 330
4 80 340 1 220 420
************************************************************************
上次寻址地址:210
已按照循环首次适应算法分配数据,起始地址:230,大小:20KB
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 4 60 30
2 30 90 3 130 120
3 80 250 2 10 330
4 80 340 1 220 420
************************************************************************
排序后打印:
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 4 60 30
2 30 90 3 130 120
3 80 250 2 10 330
4 80 340 1 220 420
************************************************************************(3)回收算法设计
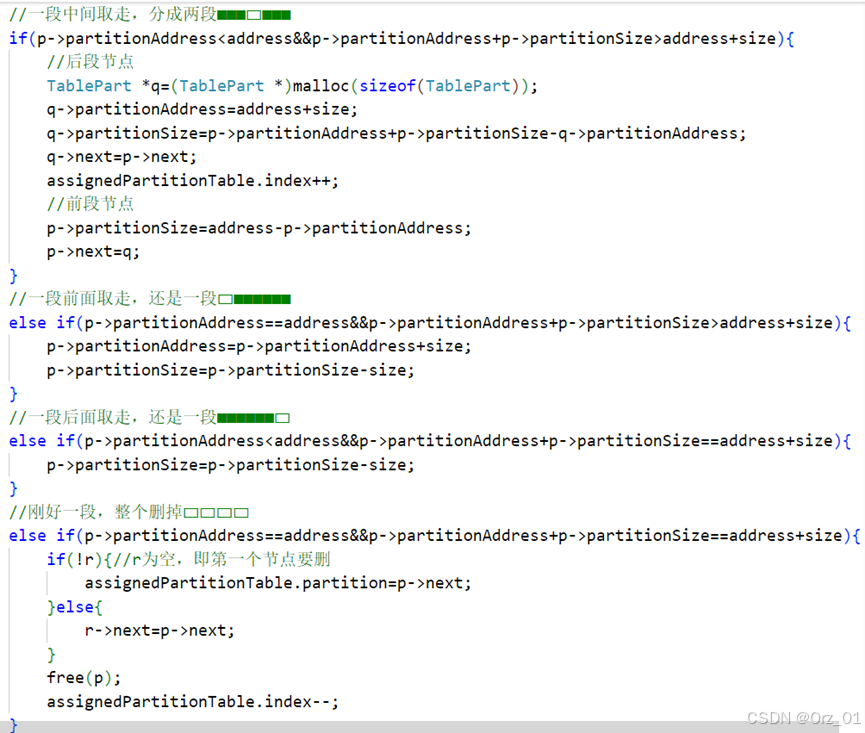
考虑回收区所属的四种情况,有上空分区无下空分区、无上空分区有下空分区、上下分区都为空分区,上下都无空分区,根据情况来决定回收区的处理。
算法实现:思考和细节都在注释里了
我认为面对这样画面感很强的多种情况,画图理解会更好,在注释里画▭■也非常方便。
算法测试:
已从已分配分页表取出数据,起始地址:230,大小:20KB
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 4 60 30
2 30 90 3 110 120
3 100 230 2 10 330
4 80 340 1 220 420
************************************************************************
排序后打印:
************************************************************************
空闲分区表 已分配分区表
分区号 分区大小 分区起址 分区号 分区大小 分区起址
1 30 0 4 60 30
2 30 90 3 110 120
3 100 230 2 10 330
4 80 340 1 220 420
************************************************************************2、具体实现细节(代码)
包含数据结构、全局变量、函数声明、函数实现、main函数内容
#include <stdio.h>
#include <stdlib.h>
#define null 0
#define true 1
#define false 0
#define M 10
#define DATASIZE 640
/*1.数据结构*/
//表一行的结构
typedef struct TablePart{
int partitionSize;
int partitionAddress;
struct TablePart* next;//链表指向下一个节点的指针,首节点有数据
}TablePart;
//表头
typedef struct Table{
TablePart *partition;
int state; //状态:已分配1;空闲0
int index; //元素数量,方便查找
}Table,FreePartitionTable,AssignedPartitionTable;//空闲分区表、已分配分区表
typedef struct DataLocation{
int address; //没在已分配分区表时为-1
int size; //自带属性
}DataLocation;
/*2.全局变量*/
FreePartitionTable freePartitionTable;
AssignedPartitionTable assignedPartitionTable;
FreePartitionTable *freeP;
AssignedPartitionTable *assignedP;
int nextFitAddress;//记录首次循环适应算法上次所寻地址
//测试数据,单位为KB,初始地址为无(以-1表示)
DataLocation testData[M]={
{-1,100},{-1,40},{-1,30},{-1,90},{-1,200},
{-1,30},{-1,60},{-1,50},{-1,20},{-1,66}};
/*3.声明函数*/
//初始化全局变量freePartitionTable和assignedPartitionTable:
//初始化为空
void myInit0();
//初始化全局变量freePartitionTable和assignedPartitionTable:
//初始化并在空闲表添加一行,大小为DATASIZE
void myInit();
//找到链尾
TablePart* myFind(Table* table);
//往表中添加一行(尾插法)
void myAdd(Table* table,int size,int address);
//带合并的添加
void myAddPlus(Table* table,int size,int address);
//取出已分配分区表指定数据,成功返回true,失败返回false
int myRemove(DataLocation* data);
//打印指定表
void myPrint(Table* table);
//打印两个表
void myPrint1();
//打印两个表,按地址升序排序后打印
void myPrint2();
//按partitionAddress升序排序
void sortByAddress(Table* table);
//按partitionSize升序排序
void sortBySize(Table* table);
//按partitionSize降序排序
void sortBySizeReverse(Table* table);
//传入测试数据,改变全局变量freePartitionTable和assignedPartitionTable
//返回0:找到合适空间,返回1:找不到合适空间
int fundationFit(DataLocation* data,TablePart *p,int index);
/*实验(1)
从链首开始顺序查找,直到找到一个大小能满足要求的空闲分区为止
空闲分区链以地址递增的次序链接
*/
int firstFit(DataLocation* data);
/*实验(2)
搜索整个序列,找到适合条件的最小的分区进行分配
空闲分区按其容量从小到大的顺序链接
*/
int bestFit(DataLocation* data);
/*实验(3)
搜索整个序列,寻找最大的分区进行分配
空闲分区按其容量从大到小的顺序链接
*/
int worseFit(DataLocation* data);
/*实验(4)
从上次找到的空闲分区的下一个空闲分区开始查找,直到找到一个能满足要求的空闲分区
*/
int nextFit(DataLocation* data);
/*4.实现函数*/
void myInit0(){
//初始化全局变量assignedPartitionTable
freePartitionTable.state=false;
freePartitionTable.index=0;
freePartitionTable.partition=null;
//初始化全局变量assignedPartitionTable
assignedPartitionTable.state=true;
assignedPartitionTable.index=0;
assignedPartitionTable.partition=null;
//初始化全局变量指针freeP,assignedP
freeP=&freePartitionTable;
assignedP=&assignedPartitionTable;
}
void myInit(){
//初始化全局变量freePartitionTable
freePartitionTable.state=false;
freePartitionTable.index=1;//目前只有一个元素
freePartitionTable.partition=(TablePart*)malloc(sizeof(TablePart));
freePartitionTable.partition->partitionSize=DATASIZE;//初始状态下可用内存空间为640KB
freePartitionTable.partition->partitionAddress=0;//从0开始的地址
freePartitionTable.partition->next=null;
//初始化全局变量assignedPartitionTable
assignedPartitionTable.state=true;
assignedPartitionTable.index=0;
assignedPartitionTable.partition=null;
//初始化全局变量指针freeP,assignedP
freeP=&freePartitionTable;
assignedP=&assignedPartitionTable;
}
TablePart *myFind(Table* table){
TablePart *p=table->partition;
if(p==null) return p;
while(p->next!=null){
p=p->next;
}
return p;
}
void myAdd(Table* table,int size,int address){
table->index++;
TablePart *node=(TablePart*)malloc(sizeof(TablePart));
node->partitionSize=size;
node->partitionAddress=address;
node->next=null;
TablePart *p=myFind(table);
//找到空,即表为空,直接赋值第一行
if(p==null){
table->partition=node;
}
else{
p->next=node;
}
}
void myAddPlus(Table* table,int size,int address){
//遍历分区,查看是否有刚好可以合并的块
TablePart *q=table->partition;
int flag=true;
while(q){
if(q->partitionAddress+q->partitionSize==address||address+size==q->partitionAddress){
//新加入块连接了原来两块
if(q->next!=null&&q->partitionAddress+q->partitionSize==address
&&address+size==q->next->partitionAddress){
TablePart *r=q->next;
q->partitionSize=q->partitionSize+r->partitionSize+size;
q->next=r->next;
free(r);
table->index--;
}
//新加入块刚好接到已有块后,但后续无块接入
else if(q->partitionAddress+q->partitionSize==address){
q->partitionSize+=size;
}
//新加入块刚好后续有块接入,但开头无块接上
else if(address+size==q->partitionAddress){
q->partitionAddress-=size;
q->partitionSize+=size;
}
flag=false;
}
q=q->next;
}
//增加空闲分区
if(flag) myAdd(table,size,address);
}
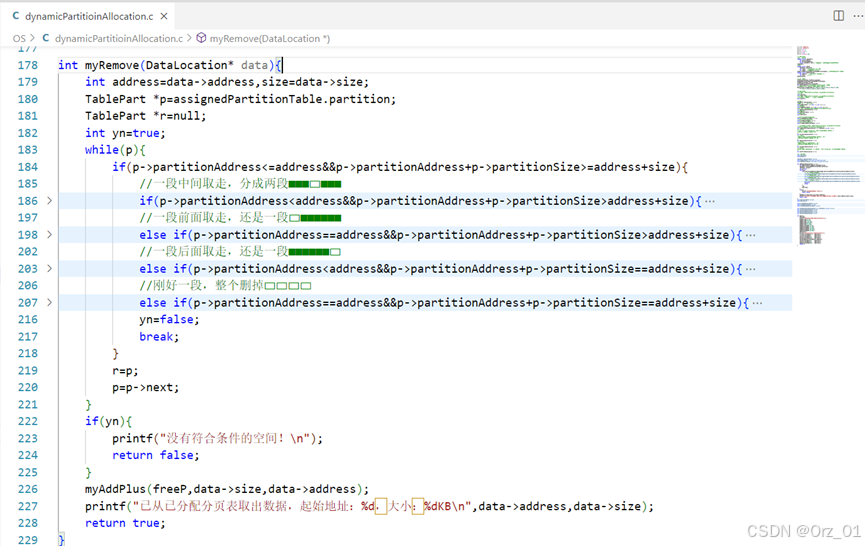
int myRemove(DataLocation* data){
int address=data->address,size=data->size;
TablePart *p=assignedPartitionTable.partition;
TablePart *r=null;
int yn=true;
while(p){
if(p->partitionAddress<=address&&p->partitionAddress+p->partitionSize>=address+size){
//一段中间取走,分成两段■■■▭■■■
if(p->partitionAddress<address&&p->partitionAddress+p->partitionSize>address+size){
//后段节点
TablePart *q=(TablePart *)malloc(sizeof(TablePart));
q->partitionAddress=address+size;
q->partitionSize=p->partitionAddress+p->partitionSize-q->partitionAddress;
q->next=p->next;
assignedPartitionTable.index++;
//前段节点
p->partitionSize=address-p->partitionAddress;
p->next=q;
}
//一段前面取走,还是一段▭■■■■■■
else if(p->partitionAddress==address&&p->partitionAddress+p->partitionSize>address+size){
p->partitionAddress=p->partitionAddress+size;
p->partitionSize=p->partitionSize-size;
}
//一段后面取走,还是一段■■■■■■▭
else if(p->partitionAddress<address&&p->partitionAddress+p->partitionSize==address+size){
p->partitionSize=p->partitionSize-size;
}
//刚好一段,整个删掉▭▭▭▭
else if(p->partitionAddress==address&&p->partitionAddress+p->partitionSize==address+size){
if(!r){//r为空,即第一个节点要删
assignedPartitionTable.partition=p->next;
}else{
r->next=p->next;
}
free(p);
assignedPartitionTable.index--;
}
yn=false;
break;
}
r=p;
p=p->next;
}
if(yn){
printf("没有符合条件的空间!\n");
return false;
}
myAddPlus(freeP,data->size,data->address);
printf("已从已分配分页表取出数据,起始地址:%d,大小:%dKB\n",data->address,data->size);
return true;
}
void myPrint(Table* table){
printf("********************************\n");
if(table->state==1){
printf("已分配分区表\n");
}
else{
printf("空闲分区表\n");
}
printf("分区号\t分区大小\t分区起址\n");
TablePart *p=table->partition;
int i=table->index;
if(i==0)return;
int j=1;
while(i--){
printf("%d\t%d\t\t%d\n",j++,p->partitionSize,p->partitionAddress);
p=p->next;
}
printf("********************************\n\n");
}
void myPrint1(){
printf("************************************************************************\n");
printf("空闲分区表\t\t\t\t已分配分区表\n");
printf("分区号\t分区大小\t分区起址\t分区号\t分区大小\t分区起址\n");
TablePart *p=freeP->partition;
TablePart *q=assignedP->partition;
int i=freeP->index,k=assignedP->index;
if(i==0&&k==0)return;
int j=1;
while(i||k){
if(i&&k){
printf("%d\t%d\t\t%d\t\t%d\t%d\t\t%d\n",j,p->partitionSize,p->partitionAddress,
k,q->partitionSize,q->partitionAddress);
p=p->next;
q=q->next;
i--;k--;
}else if(k){
printf("\t\t\t\t\t%d\t%d\t\t%d\n",k,q->partitionSize,q->partitionAddress);
q=q->next;
k--;
}else if(i){
printf("%d\t%d\t\t%d\t\t\t\t\t\n",j,p->partitionSize,p->partitionAddress);
p=p->next;
i--;
}j++;
}
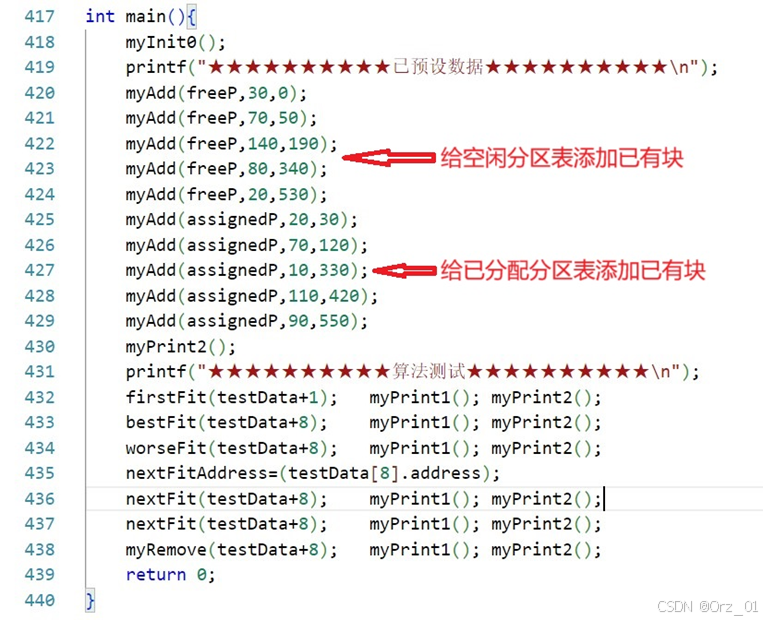
printf("************************************************************************\n\n");
}
void myPrint2(){
printf("排序后打印:\n");
sortByAddress(freeP);sortByAddress(assignedP); myPrint1();
}
void sortByAddress(Table* table){
if(table->index<=1) return;
TablePart *p=table->partition;
TablePart *q=null;
for(int i=0;i<table->index-1;i++,p=p->next){
q=p->next;
for(int j=i+1;j<table->index;j++,q=q->next){
if(p->partitionAddress>q->partitionAddress){
int k=p->partitionAddress;
p->partitionAddress=q->partitionAddress;
q->partitionAddress=k;
k=p->partitionSize;
p->partitionSize=q->partitionSize;
q->partitionSize=k;
}
}
}
}
void sortBySize(Table* table){
if(table->index<=1) return;
TablePart *p=table->partition;
TablePart *q=null;
for(int i=0;i<table->index-1;i++,p=p->next){
q=p->next;
for(int j=i+1;j<table->index;j++,q=q->next){
if(p->partitionSize>q->partitionSize){
int k=p->partitionAddress;
p->partitionAddress=q->partitionAddress;
q->partitionAddress=k;
k=p->partitionSize;
p->partitionSize=q->partitionSize;
q->partitionSize=k;
}
}
}
}
void sortBySizeReverse(Table* table){
if(table->index<=1) return;
TablePart *p=table->partition;
TablePart *q=null;
for(int i=0;i<table->index-1;i++,p=p->next){
q=p->next;
for(int j=i+1;j<table->index;j++,q=q->next){
if(p->partitionSize<q->partitionSize){
int k=p->partitionAddress;
p->partitionAddress=q->partitionAddress;
q->partitionAddress=k;
k=p->partitionSize;
p->partitionSize=q->partitionSize;
q->partitionSize=k;
}
}
}
}
int fundationFit(DataLocation* data,TablePart *p,int index){
//TablePart *p=freePartitionTable.partition;
TablePart *q=null;
while(index){
//找到大小能满足要求的空闲分区
if(p->partitionSize>=data->size){
myAddPlus(assignedP,data->size,p->partitionAddress);
data->address=p->partitionAddress;
//空闲分区表修改
p->partitionSize-=data->size;
p->partitionAddress+=data->size;
if(p->partitionSize==0){//刚好填满第一格
if(p==freePartitionTable.partition){
freePartitionTable.partition=p->next;
free(p);
freePartitionTable.index--;
}else{//刚好填满非第一格
q->next=p->next;
free(p);
freePartitionTable.index--;
}
}
return true;
}
q=p;
p=p->next;
index--;
}
return false;
}
int firstFit(DataLocation* data){
sortByAddress(freeP);
if(fundationFit(data,freePartitionTable.partition,freePartitionTable.index)){
printf("已按照首次适应算法分配数据,起始地址:%d,大小:%dKB\n",data->address,data->size);
return true;
}else{
printf("找不到合适空间!");
return false;
}
}
int bestFit(DataLocation* data){
sortBySize(freeP);
if(fundationFit(data,freePartitionTable.partition,freePartitionTable.index)){
printf("已按照最佳适应算法分配数据,起始地址:%d,大小:%dKB\n",data->address,data->size);
return true;
}else{
printf("找不到合适空间!");
return false;
}
}
int worseFit(DataLocation* data){
sortBySizeReverse(freeP);
if(fundationFit(data,freePartitionTable.partition,freePartitionTable.index)){
printf("已按照最坏适应算法分配数据,起始地址:%d,大小:%dKB\n",data->address,data->size);
return true;
}else{
printf("找不到合适空间!");
return false;
}
}
int nextFit(DataLocation* data){
sortByAddress(freeP);
TablePart *p=freePartitionTable.partition;
int index=freePartitionTable.index;
printf("上次寻址地址:%d\n",nextFitAddress);
while(p){//找到上次使用地址附近的分区
if(p->partitionAddress>=nextFitAddress)break;
p=p->next;
}
if(fundationFit(data,p,index)){
printf("已按照循环首次适应算法分配数据,起始地址:%d,大小:%dKB\n",data->address,data->size);
nextFitAddress=data->address;
}
else{
printf("找不到合适空间!");
}
}
int main(){
myInit0();
printf("★★★★★★★★★★已预设数据★★★★★★★★★★\n");
myAdd(freeP,30,0);
myAdd(freeP,70,50);
myAdd(freeP,140,190);
myAdd(freeP,80,340);
myAdd(freeP,20,530);
myAdd(assignedP,20,30);
myAdd(assignedP,70,120);
myAdd(assignedP,10,330);
myAdd(assignedP,110,420);
myAdd(assignedP,90,550);
myPrint2();
printf("★★★★★★★★★★算法测试★★★★★★★★★★\n");
firstFit(testData+1); myPrint1(); myPrint2();
bestFit(testData+8); myPrint1(); myPrint2();
worseFit(testData+8); myPrint1(); myPrint2();
nextFitAddress=(testData[8].address);
nextFit(testData+8); myPrint1(); myPrint2();
nextFit(testData+8); myPrint1(); myPrint2();
myRemove(testData+8); myPrint1(); myPrint2();
return 0;
}3、思考
(1)以没有头节点的链表形式实现表每行之间的链接,做各种算法实现的时候有诸多不便,要分成两类讨论(是首元节点还是非首元节点),如果要用链表的话可能使用有头节点的链表更好。
(2)同样的,链表进行删除和合并等操作时,需要修改被操作节点的上一个节点的next指针,很麻烦,也许改为使用数组会更好。(做实验早期考虑到空闲分区表和已分配分区表的行数都不固定,担心扩容需要以及频繁增删改所以选择了链表)。
(3)实现最佳和最坏适应分配算法时使用了冒泡排序,且直接将链表中表格数据进行互换而不是直接修改指针,导致效率低下。有三个方向可以改进:
使用效率更优的排序算法;
使用另一个表映射真实表的地址,同样可以实现排序;
排序换位时修改指针而不是修改数据。
(4)DataLocation(表示数据)数据结构本来都使用int类型直接表示数据大小,但老师上课的图片一直印在我脑子里挥之不去,即数据以块状形式排列在空闲分区表中:一块连续的空间可以有几块不同的区域。于是将数据抽象成了以下结构,表示不同数据块的独立性。

五、实验结果分析
-
通过实验,我深刻理解了四种适应分配算法的实质以及它们的共通之处,即使是很简单的思想实现起来也需要很大的工作量,不由得敬佩前辈的伟大。
-
实现回收时自然而然就想到了多种情况,多亏了图片辅助,再一次感受到抽象的重要性。
-
问题一:DataLocation的address属性一直为初始值的-1,没有随着函数内的修改而修改,同样的有TablePart类型和Table类型。
-
原因:传入的虽然是结构体,但C传入的不是指针的话,修改函数内的变量不能影响到传入的实参。
-
解决:将函数传参改为指针。注意辨析C和Java的区别。
-
-
问题二:回收函数myRemove()实现“上下都无空分区”时,测试有发现最后一整个空闲分区都被填满,输出size为0,address为0的情况(正常情况下应该输出空表)。
-
原因:没有考虑到首行删除的情况。(没有头节点的链表导致)。
-
解决:加上判断特殊处理即可。
-


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









