







大家好,我是怒码少年小码。
想象你开了一家水果店,里面有1000种水果,顾客来购买水果问你价格,你是在一条长长的清单中逐个查找商品的名称和价格还是立刻报出商品的价格?毫无疑问你肯定是后者。
在计算机中,前者的清单就是用单纯的数组实现的,那么我们就要一个个遍历直到找到目标,不是哥们,那等你找到顾客早都走了。

有没有一种方法直接实现这个水果->价格的对应过程呢?
当然有了!这个方法就是——哈希函数。
哈希函数
Hash(音译——哈希,不是人名),有把…弄乱的意思,所以哈希函数又被称为散列函数、杂凑函数。
功能
根据输入的数据(包括但不限于字符串)生成一个整数,这个整数也叫哈希值。
主要特点
- 输入不同的参数->得到不同的整数
- 输入相同的参数->得到相同的整数
这个很好理解吧,例如苹果和桃子这两种不同的水果的价格不一样,又例如某一顾客多次问西瓜多少钱?你每次的答案都会是相同的(不会吧不会吧,你不会是黑心老板吧😉)
借助Hash函数就可以实现数据到存储位置的一对一映射,从而把数据(水果)的属性(价格)放在一张表里,这种表就叫哈希表,也叫散列表。
补充:python中的字典(dict)也用到了哈希表。
使用
西瓜调用哈希函数,得到一个整数21,于是在哈希表的21单元存入西瓜的价格3.0,就这样一直把1000种水果对应的价格的哈希表搞定。这时有一个人过来买水果:
- 老板,来一个西瓜。
西瓜调用哈希函数得到整数21,找到21单元,直接读出哈希表中的价格。
- 你:3.0
这个过程一瞬间完成,这效率,刚刚的👍!
碰撞现象
看到这里你一定觉得哈希函数酷毙了,你可能也会有一个这样的疑问:师傅你这函数保熟吗?额不,你这函数保不重复吗🤔?也就是你这个函数输入不同的参数,能保证返回的整数都不同吗?
我的答案是:我不能保证。事实上任何算法在理论上都不能保证。这种参数不同,结果却相同的现象学名叫做碰撞(也叫冲突)。但是也不必太担心,有解决办法滴~
碰撞处理
常见的方法有开放定址法(Java里的Threadlocal),链地址法(Java里的ConcurrentHashMap),再哈希法和建立公共溢出区。后面两种用的个比较少,我们重点研究前两个。
开放定址法
开放定址法的思想就是:一旦发生冲突,就去寻找下一个空的地址。只要哈希表足够大,一定会找到空闲的地方。
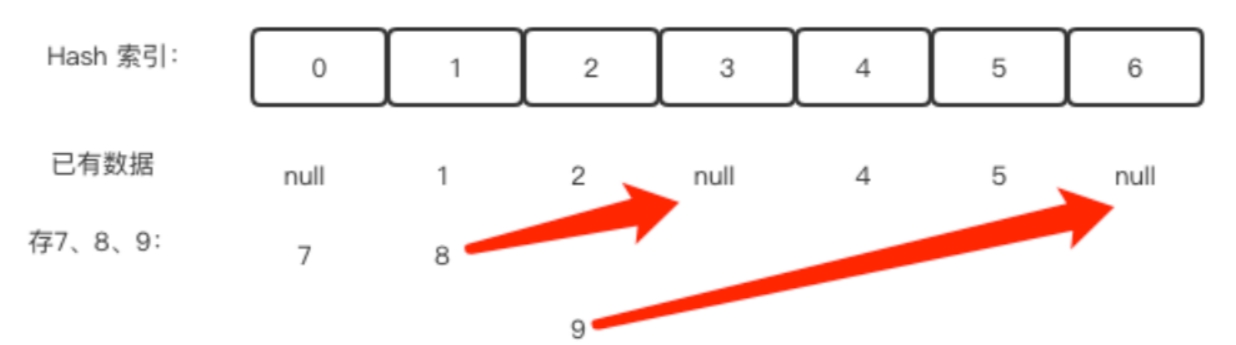
例如,上图中的哈希表要继续存放7、8、9,7放在0好位置上可以,但是8不能放在1的位置上,于是继续往后找,找到3位置有空闲,就把8放在3的位置上,以此类推。
通过什么方法寻找下一个空地址呢,有这样一个公式(Hash(key) + d) % m,当发生冲突时,冲突元素按照d序列挨个往后找空地址存入,那么d怎么取呢,这里有三种方法:
- 线性探测法——d为1,2,3…m-1线性序列
- 二次探测法——d为1²,-1²,2²,-2²,…二次序列
- 伪随机数法——d为伪随机数
链地址法(拉链法)
这种方法的基本思想是将哈希表的每个单元作为链表的头结点,将冲突的数据插入到以该单元为头结点的链表后面。例如下面这道题目:

这道题的哈希函数使用hash(key)=key%13实现,也就是某一个数字的hash值是它本身和13取余的余数。7%13=7,所以把7插入以7单元为头结点的链表中,20%13=7,也就是7和20所生成的hash值冲突了,就把20插入以7单元为头结点的链表中,以此类推。
同时我们注意到,hash表储存的是每个单链表的头指针。因为是和13取余,所以余数(这里叫m)的范围也即是hash值的范围是0-12。hash表的大小是m。
如果还不明白的话,可以看看这个视频讲解:链地址法讲解
队列的基础知识
队列具有先进先出特点(FIFO)。队列的实现方式有链表和数组两种,这篇我们先讲链表的实现方法,数组实现方法我们下篇再讲。
队列的链表实现方式
//用链表实现队列
struct Node{
int data;
Node* next;
};
struct LinkQueue {
Node* front;
Node* rear;
int size;
};
//创建链表
LinkQueue* createLinkQueue(){
LinkQueue* queue = new LinkQueue;
queue->front = nullptr;
queue->rear = nullptr;
queue->size = 0;
return queue;
}
//入队
void push(LinkQueue* queue,int value) {
//创建新节点
Node* newNode = new Node;
newNode->data = value;
newNode->next = nullptr;
//判断队列是否为空,入队是从队尾入,所以用尾指针判断
if (queue->rear == nullptr) {
/*如果队列为空,即 rear 为 nullptr,
则将新节点设置为队列的首节点和尾节点,即 front 和 rear 均指向新节点。
*/
queue->front = newNode;
queue->rear = newNode;
}
else {
/*如果队列不为空,即 rear 不为 nullptr,
将当前 rear 节点的 next 指针指向新节点,将新节点设置为队列的尾节点,
即更新 rear 指针所指向的节点为新节点。
*/
queue->rear->next = newNode;
queue->rear = newNode;
}
//更新队列大小
queue->size++;
}
//出队
int pull(LinkQueue* queue) {
//判断队列是否为空,入队是从队头出,所以用头指针判断
if (queue->front== nullptr) {
cout << "队列已经空了" << endl;
return 0;
}
Node* firstNode = queue->front;
int value = firstNode->data;
//更新头指针
queue->front = firstNode->next;
//删除第一个结点
delete firstNode;
queue->size--;
//如果出队操作后队列为空(即 front 为 nullptr),则将队列的 rear 指针也更新为 nullptr。
if (queue->front == nullptr) {
queue->rear = nullptr;
}
return value;
}
//遍历队列
void traverse(LinkQueue* queue) {
Node* temp = queue->front;
while (temp != nullptr) {
cout << temp->data <<",";
temp = temp->next;
}
cout << endl;
}
测试用例:
int main() {
LinkQueue* queue = createLinkQueue();
push(queue, 1);
push(queue, 2);
push(queue, 3);
traverse(queue);//1,2,3,
pull(queue);
traverse(queue);//2,3,
}
END
这一篇可以说是收获满满了,之前看到hash就害怕,现在看来也还可以,呼~















 90
90











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









