






前言:Hello,大家好,我是心跳sy😘,本节我们介绍c语言的两种基本的内置数据类型:数值类型和字符类型在内存中的储存方法,并对大小端进行详细介绍(附两种大小端判断方法),文章每个例题和知识点都会有详细的解释,友友们放心食用,我们一起来看看吧~!!
1、⭐️数据类型介绍⭐️

1.1、💫整型家族
👉我们之前已经了解过 int、short、long、longlong、float、double、char这几种基本的c语言内置数据类型。其中 int、short、long、char类型是整型家族,其中char虽为字符型类型,但是它的ASCII码在内存中保存为整型,所以也可以归为整型家族(这里我们为了方便介绍整型和浮点型在内存中的储存规则),也把它纳入整型之中。
👉整型家族里面的每个数据类型也都拥有有符号(signed)和无符号(unsigned)两种类型情况,其中char类型的有无符号与编译器有关。数据在内存的储存与有无符号息息相关。
1.2、💫浮点型家族
👉浮点型家族包括 float和 double类型,有趣的是这两个浮点型数据类型都没有无符号的情况,这是为什么呢❓我们知道,整型是采用二进制储存在内存中的,而浮点数却是按照整数部分、小数部分、指数部分存放的,运算也是分开来运算的,所以unsigned无法作用于float与double这种浮点型。
1.3、💫构造类型
👉由表中我们可以看到,构造类型由数组类型、结构体类型、共用体类型(联合类型) 以及枚举类型组成,构造类型一般可以给予用户非常大的自定义范围,可以同时对一个对象定义不同的变量,比如可以做到同时定义一个人的性别、年龄等等。(对四个构造类型的详细介绍我们后面都会单独写一篇文章,会统一收录到c语言专栏中)
1.4、💫指针类型
👉指针类型包括整型指针、浮点型指针、字符指针、数组指针、函数指针、空指针(void*)等等。 指针类型的作用是存放变量的地址,可以通过指针来改动变量。 指针作为一个变量是有大小的,其大小在32位平台是4个字节,64位平台上是8个字节,大小与指针的类型无关。(我们以后会对指针一章详细介绍)
1.5、💫空类型
👉空类型是指没有定义类型的数据类型,也称为void类型,在C语言中,空类型可以省略函数的参数列表,也可以修饰函数表示无返回值,通常用作函数指针,表示指向没有返回值的函数的指针。 空类型和其他类型之间的转换通常需要通过类型转换操作符进行。
记住以下3个规则:
⭕️如果函数无参数,应声明其参数为void类型。如:
int function(void)
{
return 1;
}👉若此时在调用function(2),在c语言编译器中不会报错,但是在c++编译器中将会不合法报错,所以无论在哪种编译器中,一定养成良好习惯,若函数不接受任何参数,一定要指明参数为void。
⭕️如果函数没有返回值,那么一定要声明为void类型。
⭕️如果函数的参数可以是任意类型的指针,那么应该声明其参数为void*,比如内存操作函数memset的函数原型为:
void*memset(void*buffer,int c,size_t num);2、⭐️插叙:原码、反码、补码的介绍⭐️
👉我们知道,计算机底层只认识0和1,所以所有整型和浮点型数据到了底层都会通过转换成二进制形式(0和1的形式)来储存。计算机整数的表示方式有3种,即原码、反码、补码。3种表示方式均有符号位和数值位两部分,而所有整型数据在内存中都会以补码的形式储存。我们要了解整型的内存结构就需要先知道原码、反码、补码的知识。
⚠️先来看看3个码的基本概念:
⭕️原码是指一个数的二进制表示,第一位是符号位,正数为0,负数为1;
比如32位下-5的二进制,其原码为:1000 0000 0000 0000 0000 0000 0000 0101
⭕️反码是指将原码中除符号位以外每一位取反后得到的二进制数;
其反码为:1111 1111 1111 1111 1111 1111 1111 1010
⭕️补码是指将反码加1后得到的二进制数。
其补码为:1111 1111 1111 1111 1111 1111 1111 1011
👉在整型中我们可以分成两大类记忆理解:
正整数:原码、反码、补码相同。
比如:5的原码、反码、补码都为:
0000 0000 0000 0000 0000 0000 0000 0101
负整数:原码、反码、补码需进行计算得到,计算方式见概念。
🌈计算方式总结(针对负整数):
⭕️从原码——>补码:原码符号位不变,其他位按位取反,再加1;
⭕️从补码——>原码:补码符号位不变,其他位按位取反,再加1;(也可以先减1,再符号位不变,其他位按位取反)
3、⭐️整型数据在内存中的存储⭐️
👉我们前面提到,整型数据都是以补码的形式储存在内存中的。其原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理,(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路,比如原码到补码需取反加一,补码到原码也只需取反加一即可。
⭕️我们来看一个简单的整型数据内存例子:
int main()
{
int i = 5;
int j = -10;
return 0;
}可以看到i,j变量在x86环境下的内存显示如下:

👉从此例子中可以证明整型数据在内存中都是以补码的形式储存的,正整数5的原、反、补相同,负整数20以补码的十六进制形式储存。
❓但是我们又会发现一个问题,它们储存的顺序有些奇怪,我们知道,变量 i被分配4字节的内存,其中5只占一个字节,其他3个字节都为0, 而数据5被放置在第一个字节的位置,这放置的顺序是按照什么规则来的吗❓这里就要介绍大小端的知识点了~
3.1、💫大小端介绍(附两种证明方法)
❓为什么会有大小端之分呢
👉这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short 型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端储存模式。
👉先看概念:
大端模式:指数据的高字节存储在内存的低地址处,而数据的低字节储存在内存的高地址中;
小端模式:指数据的高字节存储在内存的高地址处,而数据的低字节存储在内存的低地址中。
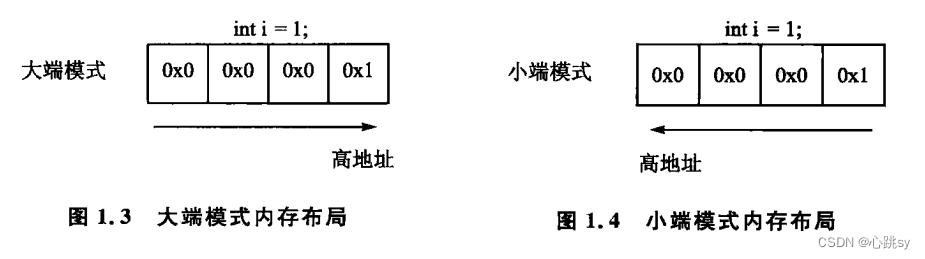
⭕️如果现在还不是很明白,没关系,我们再来针对实例解释:
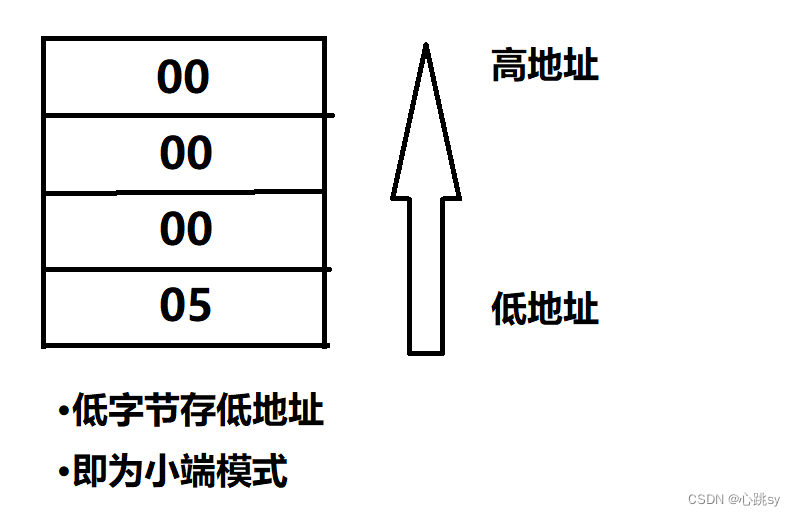
👉我们就看看5的存储模式:
5的补码为(记住正整数原反补相同):0000 0000 0000 0000 0000 0000 0000 0101
化为16进制表示为:0x00 00 00 05(其中05是低字节,往前依次为高字节)
🌈(一)、大端模式情况:可以看到低字节05存储在高地址处,即为大端模式。

🌈(二)、小端模式情况:可以看到低字节存储在低地址处,即为小端模式。
❓那么怎么才能知道自己的编译器用的是哪种模式呢,我们这里介绍两种方法:
🌈方法一:通过union关键字来实现
👉我们先介绍一下union关键字的用法:union的用法与struct非常相似,只不过union维护足够空间来放置多个数据成员中的一种,而不是为每个数据成员都分配空间。在union中所有的数据成员共用一个空间,同一时间内只能储存其中一个数据成员,所有的数据成员都具有相同的起始地址。
👉一个union只配置一个足够大的空间来容纳最大长度的数据成员,union关键字在c++中主要用来压缩空间,如果一些数据不可能在同一时间被用到,则可以使用。
⭕️我们可以利用union类型“所有数据成员的起始地址一致”为特点来证明大小端:
int Check_ram()
{
union check
{
int i;
char ch;
}c;
c.i = 1;
return (c.ch == 1);
}
int main()
{
if (Check_ram() == 0)
{
printf("是大端模式\n");
}
else
printf("是小端模式\n");
return 0;
}代码分析:
👉我们设置一个函数来判断大小端,函数中定义两个数据成员变量,一个是int类型变量i,一个是char类型变量ch,我们给i赋值为1,这时内存分配一个可以容纳最大长度数据成员的内存(此时分配4字节,最大数据类型是int),函数返回char类型变量是否为一的值,若为1,则返回1,若不为1,则返回0。主函数中接收返回值,如果返回值为0则是大端模式(因为成员起始地址一样,int型为4字节,char类型变量只有一字节,所以利用1所在的1字节位置在哪来判断大小端),若返回值等于1则是小端模式。
👉可以看到输出结果为小端模式,证明函数返回值为1,因为i变量的1肯定为低字节(见上文分析),并且int类型的内存分配是由低地址到高地址的,union中数据成员起始地址又一样,所以如果ch中的值也为1,那么一定是小端模式。

🌈方法二:普通方法强制类型转换实现
int Check_ram()
{
int i = 1;
return (*(char*)&i);
}
int main()
{
if (Check_ram()== 1)
{
printf("是小端模式\n");
}
else
{
printf("是大端模式\n");
}
return 0;
}👉输出结果与上面一样,都为小端模式,我们同样设计函数实现,只需定义一个int型变量,只不过函数的返回值是将i的地址强制类型转换为char*后解引用的值,返回的类型就改为char了,与上面方法是同种道理,不明白的友友可以参照上述解释。
3.2、💫signed与unsigned关键字对整型取值的影响
👉我们知道,计算机底层只认识0和1,任何数据到了底层都必须转换为0和1,那么负数怎么储存呢?我们前面了解了计算机整数的3种表示方法原码、反码、补码,均有符号位和数值位两部分组成,数据类型的最高位是用来存符号的,约定若这个数为整数,则最高位为0,否则为1,其值为除最高位以外剩余位的值。
👉这样的话,一个32位的 signed int类型整数,其值表示的范围为:-2^31~ (2^31-1);8位的 char类型数,其值表示的范围为:-2^7~(2^7-1)。一个 32 位的 unsigned int类型整数,其值表示的范围为:0~(2^32-1);8位的 unsigned char 类型数,其值表示的范围为:0~(2^8-1)。需要说明的是,signed 关键字也很宽宏大量,你也可以完全当它不存在,缺省情况下(默认条件下),编译器默认数据为signed类型 (char类型数据除外)。
🌈看了上面的概念,相信你已经有了自己的理解,我们通过下面一道看似简单的题目康康你真的懂了吗😜
int main()
{
signed char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}输出结果如下:

这个结果和你想的是否一样呢?如果不一样没关系,我们一起来看看分析过程:


👉由上面的分析过程,我们知道a[0]-a[254]里面对应的值都不是0,而到a[255]时值为0,strlen函数时用来计算字符串长度的,遇到‘\0’,则认为字符串结束读取,所以到现在我们就能明白了为什么计算字符串长度是255了吧,这个问题的关键就是要明白signed char的取值范围为[-128~127],而超出这个范围就会产生溢出必须截断,之后就会产生循环。
🌈重点:我们总结一个有符号char的范围规律,可以画图看到其范围可以形成一个圆,从0开始不断+1,直到新的循环。

⭕️看了一个signed char类型的例题,我们再来看一个unsigned char类型的例题,猜一下结果会是多少呢?
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
🌈重点:输出结果是死循环输出hello world,我们用一张图来解释:
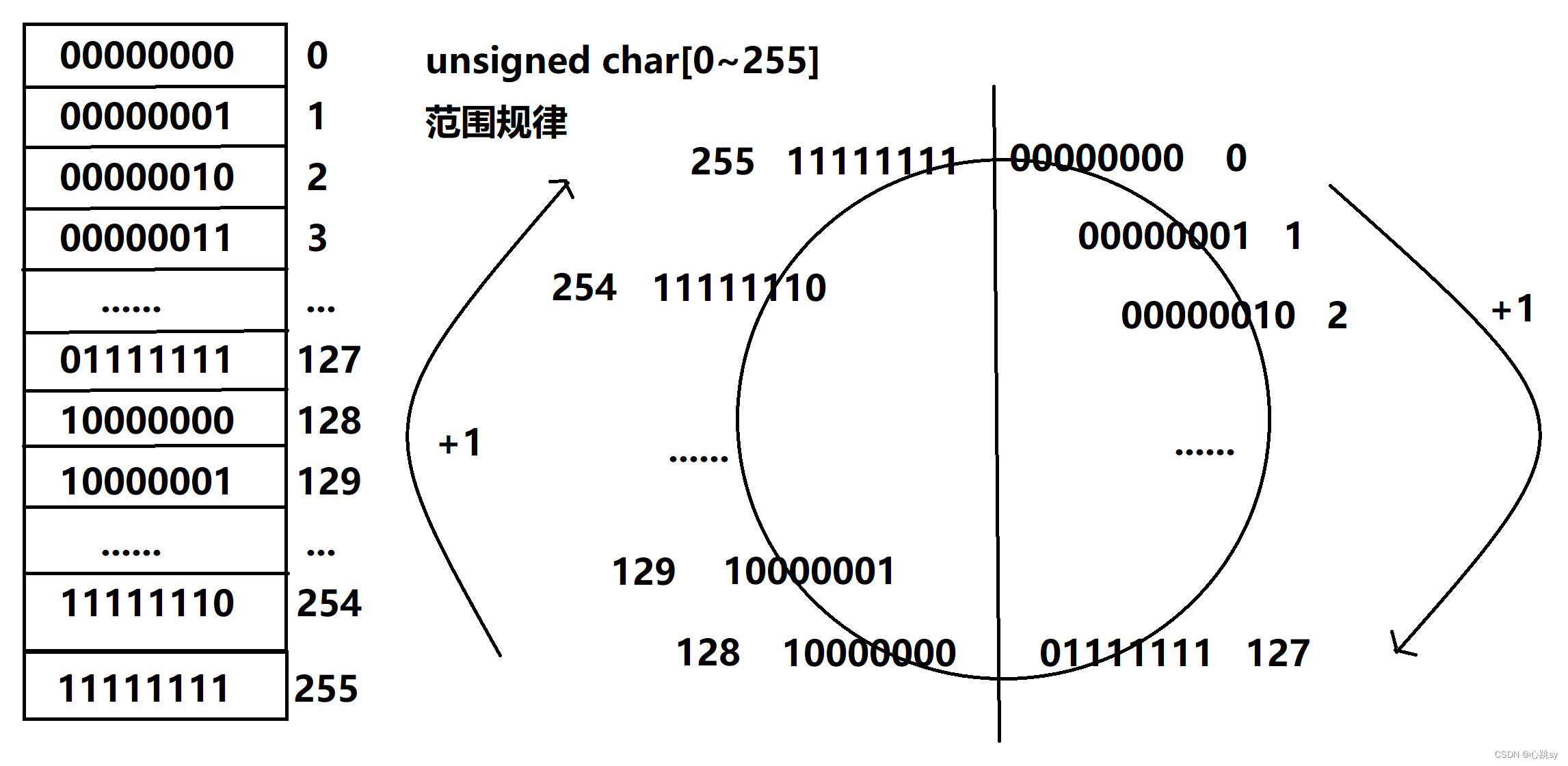
👉我们看到,unsigned char类型范围为[0~255],他因为是无符号的,所以8位中的最高位符号位变为数值位,参与数的大小计算,从画图可以得到,当到255时为11111111,当到256时,发生内存溢出,最高位被截去,又会变成0,循环又一次开始,所以上述例子中,当i=256时,i变成0,继续循环,死循环hello world。
4、⭐️浮点型数据在内存中的储存⭐️
👉整数类型并不适用于所有应用,有些时候需要变量能存储带小数点的数,或者能存储极大数或极小数。而这类数可以用浮点格式(小数点是浮动的)进行储存,C语言提供了3种浮点格式。
浮点数家族包括:float(单精度浮点数)、double(双精度浮点数)、long double(扩展精度浮点数)类型
常见的浮点数:3.14159 1E10(1*10^10)
👉我们来看看浮点数在内存中的存储方法(大多数现代计算机遵循IEEE 754标准(即IEC 60559)规范)
👉IEEE 754标准提供了两种主要的浮点数格式:单精度(32位)和双精度(64位)。数值以科学计数法的形式存储,每一个数都由3部分组成:符号、指数和小数。指数部分的位数说明了数值的可能大小程度,而小数部分的位数说明了精度。
👉单精度格式中,指数长度为8位(E 指数位),而小数部分占了23位(有效数字M),因此单精度数可以表示的最大值约是3.40*10^38,其中精度是6个十进制数字。
🌈见下图:
👉双精度格式中,指数长度为11位(E指数位),而小数部分占了52位(有效数字M)
🌈见下图:


🌈任意一个二进制浮点数 V 可以表示为下面形式:

比如:十进制的5.0,写成二进制是 101.0 ,相当于 1.01×2^2 。
👉那么,按照上面V的格式,可以得出S=0,M=1.01,E=2。
十进制的-5.0,写成二进制是 -101.0 ,相当于 -1.01×2^2 。
👉那么,S=1,M=1.01,E=2。
🌸⚠️对于M(有效数字)和E(指数位),IEEE有一些特别规定:
🔴对于M:
前面提到, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的 xxxxxx部分。
比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字 。
🔴对于E:(情况比较复杂)
·首先,E为一个无符号整数。

由此,浮点数存储规则结束。
感谢大家花费宝贵的时间阅读本文章,制作不易,希望大家多多支持呀😘😘😘,如有任何问题欢迎各位大佬在评论区批评指正!!!
















 9336
9336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









