







对于一个算法(或者程序)来说,我们一般会去衡量这个算法(或者程序)好坏,而衡量标准,就是他的复杂度
用斐波那契数列来举例子
long long Fib(int N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}
通过这个代码可以看到,虽然代码量很少,但是真的要运行,花费的时间会非常的多,所以我们会通过两个复杂度来判断他的好坏:
- 时间复杂度
- 空间复杂度
时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。
在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。
所以接下来我们重点探究时间复杂度
时间复杂度
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间(是一个函数式)
一个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度
简单来说:找到某条语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度
用一个例子来说明:
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count;
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
提问:这个Func1函数的语句运行了多少次?
从这里我们可以看到,这个函数里有一个嵌套for循环,一个for循环和一个while循环
他们的条件分别是:i < N; j < N; k < 2 * N; M--
我们知道,只有当一个函数内的所有语句执行完之后才算该函数执行完毕
所以对于这个函数而言,要满足嵌套for循环,for循环和while循环的条件才能执行完毕
以N为时间复杂度函数为参数而言,该函数式为:
F(N) = N ^ 2 + 2 * N + 10
但是假如N非常之大的话,站在影响的角度来说:
N ^ 2 对于F(N)的影响最大 ,其次是 2 * N,最小是 10
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这里我们使用大O的渐进表示法。
大O的渐进表示法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号(一个估算)
它的使用方法如下:
1、用常数1取代运行时间中的所有加法常数
2、在修改后的运行次数函数中,只保留最高阶项
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶
由于只是计算大概的执行次数,我们便可以只取对次数影响最大的项(最高阶项)来表示
遵守规则使用大O的渐进表示法以后,上面代码的Func1的时间复杂度为:
O(N^2)
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数
再看几串代码
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 100; ++k)
{
++count;
}
printf("%d\n", count);
}这个代码for循环满足条件是k >=100,所以我们会认为表达方式是O(100)
但是根据大O表示法的规则,常数的表达方式为1,所以这里应该为:
O(1)
对于这里,1不是执行的次数,而是常数次
也就意味着,不管条件如何变化,满足条件都只有一种,也就是k>=100
再看一个函数
const char * strchr ( const char * str, int character )
{
int N = strlen(str);
for(int i 0 ; i < N; i++)
{
if(*str + i == character)
return character;
}
}strchr 是一个内置函数,用来寻找目标字符串内的一个character字符
对于这个函数的时间复杂度而言,我们不好下判断
由于不知道在什么时候会找到,有可能第一个字符就是所要寻找的,也有可能最后一个才是
所以
有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
对于这种,我们一般认为:
在实际中一般情况关注的是算法的最坏运行情况
所以字符串中搜索数据时间复杂度为:
O(N)
下面来几个例子帮助我们更好地理解
void Func3(int N)
{
int count = 0;
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}对于Func3而言,只存在一个for循环和while循环,一般会认为是O(2 * N)
但是根据大O表示法的规则,这里得出时间复杂度为:
O(N)
void Func4(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++k)
{
++count;
}
for (int k = 0; k < N; ++k)
{
++count;
}
printf("%d\n", count);
}
对于Func4而言,此处有两个for循环,需分别满足M与N的条件,由于不知道M与N的具体值,不可用常量来表示,所以相加这里得出时间复杂度为:
O(M+N)
(如果有说明M远大于N或者N远大于M,可以忽略不计小的数)
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}此处是冒泡排序法的实现原理代码,操作执行最好N次,最坏执行了(N*(N+1)/2次
通过大O表示法的规则,得出时间复杂度为:
O(N^2)
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n - 1;
while (begin <= end)
{
int mid = begin + ((end - begin) >> 1);
if (a[mid] < x)
begin = mid + 1;
else if (a[mid] > x)
end = mid - 1;
else
return mid;
}
return -1;
}此处是二分查找法的实现原理代码,根据二分查找法的原理,我们可以知道每次循环都会令数组变为上一次的一半,若数组总长度为N,则最大能执行的次数为 N / 2 / 2 / 2/ ... / 2 = 1
假设找了x次,那么除了x个2,由于顺着思路来想的话,2 ^ x = N
那么倒过来想,x即为x = log N,所得时间复杂度为:
O(log N)
long long Fac(size_t N)
{
if(0 == N)
return 1;
return Fac(N-1)*N;
}对于这种递归函数而言,我们可以通过画图更好的理解他的原理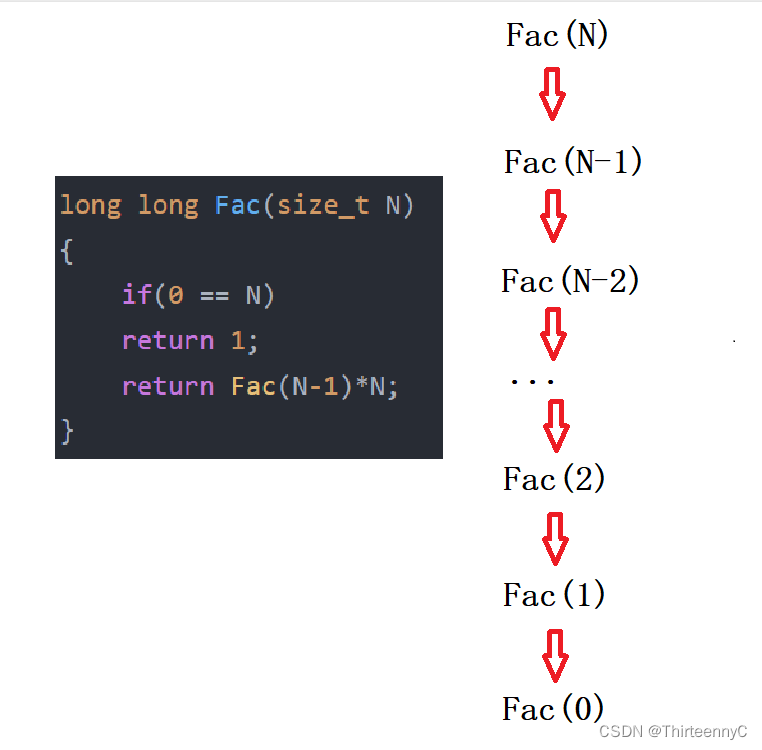
函数每次递进,N - 1, 直到N == 0时,递进结束,开始回推,根据上图我们可以得出
该函数递归执行了N+1次(因为当N为0时也会进行一次调用)
再根据大O表示法的规则,所得时间复杂度为:
O(N)
long long Fib(size_t N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}可以看出,这是一个斐波那契数列,对于这个函数而言,他的时间复杂度如何求呢?
我们把它的函数调用过程画出来:
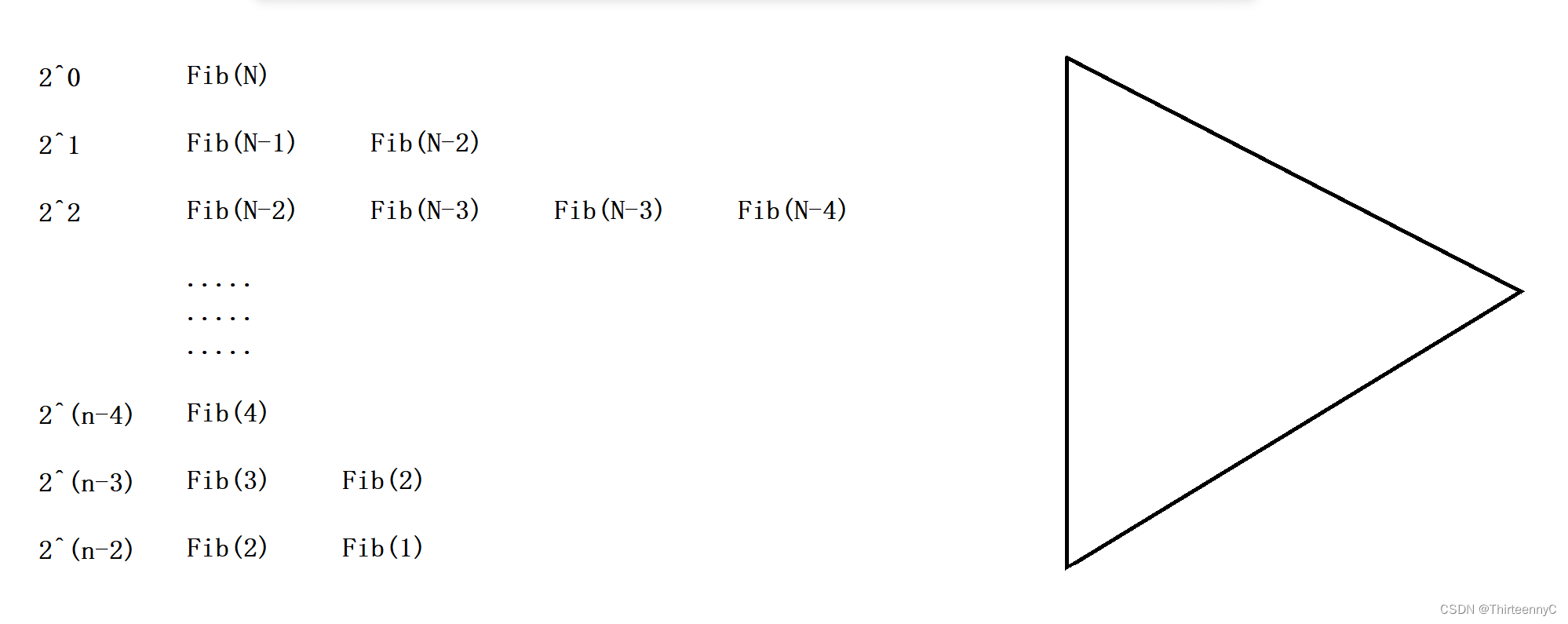
左边为每一行和的,中间为函数调用示意图,右边为抽象函数调用图形三角形
由于斐波那契数列求和也是等比数列求和
所以我们可以通过等比数列的错位相减法来求出和
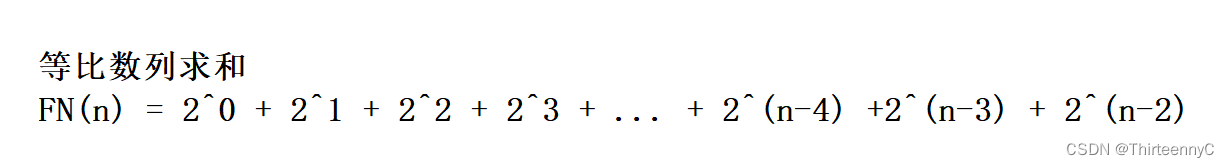
使用错位相减法:
所得最终和为:
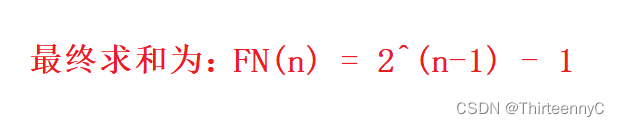
遵循大O表示法,所以斐波那契数列求和的时间复杂度为:
O(2^N)















 2121
2121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









