






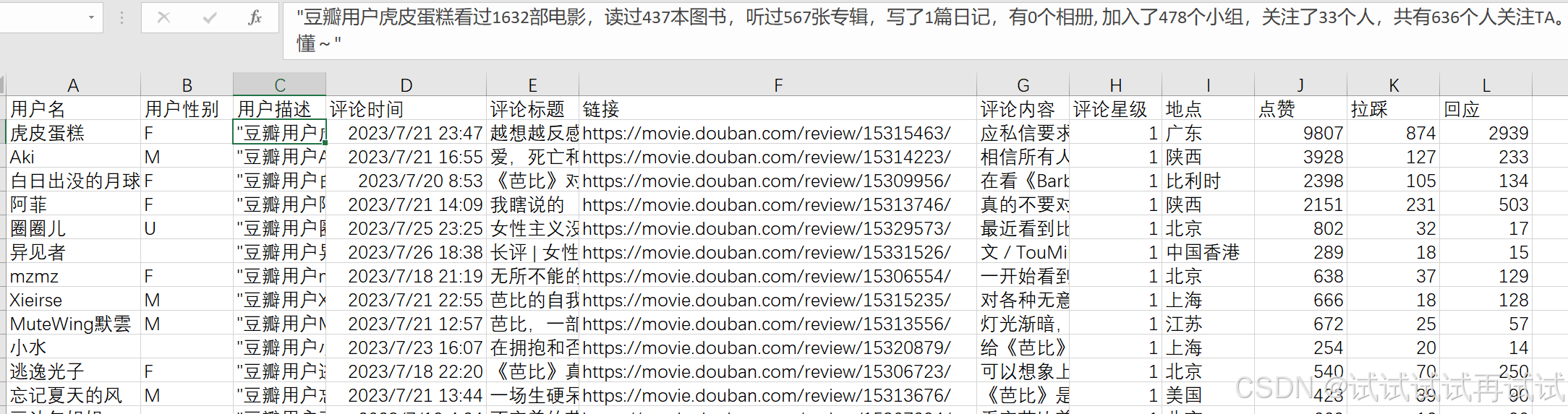
本次爬取的网页是豆瓣长评,主要涉及评论用户的信息(用户名、用户性别、用户描述),评论信息(评论时间、评论标题、评论链接、评论内容、评论星级、评论发布地点、对评论的点赞、拉踩和回应)
涉及的库
import requests
from lxml import etree
import time
import json
import re
import csv运行完整代码
import requests
from lxml import etree
import time
import json
import re
import csv
movie_id ='' #请输入电影ID:
cookies=''
cookiesm=''
ua=''
# 设定文件名并检查文件是否存在,添加新内容或创建新文件
output_file_path = r'电影长评.csv'
title = [ '用户名','用户性别','用户描述','评论时间','评论标题','链接','评论内容','评论星级','地点','点赞','拉踩','回应']
csv_file= open(output_file_path, mode='w', newline='', encoding='utf-8-sig')
writer = csv.writer(csv_file)
writer.writerow(title)
for n in range(0,187):
print(n)
time.sleep(1.1)
url = f'https://movie.douban.com/subject/{movie_id}/reviews?start='+str(n*20)
print(url)
count = 0
headers = {'cookie': cookies,'user-agent': ua,}
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8-sig'
# 使用lxml解析数据
tree = etree.HTML(response.text)
print('解析成功,开始提取数据')
time.sleep(0.7)
items=tree.xpath('//*[@id="content"]/div/div[1]/div[1]/div')
# 提取评论数据
for item in items:
count+=1
link = item.xpath('.//div/div/h2/a/@href')[0]
#提取评论内容
comment_id=link[-2:-10:-1][::-1] #[::-1]语法将其逆序排列
response_comment = requests.get(url=str(link), headers=headers)
response_comment.encoding = 'utf-8-sig'
time.sleep(0.4)
try:
tree_comment = etree.HTML(response_comment.text)
print('评论链接:', link,'etree成功')
comment = tree_comment.xpath(f'//*[@id="link-report-{comment_id}"]/div[1]/p/text()')
content='\n'.join(comment)
#print(content)
times = tree_comment.xpath(f'//*[@id="{comment_id}"]/header/div/span[1]')[0].text
print('评论时间:', times)
location = tree_comment.xpath(f'//*[@id="{comment_id}"]/header/div/span[3]')[0].text
print('评论地点:', location)
rate = tree_comment.xpath(f'//*[@id="{comment_id}"]/header/span[1]/@title')
if rate in ['力荐','推荐','还行','较差','很差']:
rates = 5 if rate == '力荐' else 4 if rate == '推荐' else 3 if rate == '还行' else 2 if rate == '较差' else 1
else:
rates='未评'
print('评论星级:', rates)
ups=item.xpath('.//div/div/div[3]/a[1]/span')[0].text.replace('\n','').replace(' ','')
print('点赞:',ups)
downs = item.xpath('.//div/div/div[3]/a[2]/span')[0].text.replace('\n','').replace(' ','')
print('拉踩:', downs)
replys = item.xpath('.//div/div/div[3]/a[3]')[0].text[:-2]
print('回应:',replys)
title = item.xpath('.//div/div/h2/a')[0].text
print('评论标题:', title)
# 提取用户数据
user_profile_pc =tree_comment.xpath(f'//*[@id="{comment_id}"]/header/a[1]/@href')[0]
time.sleep(0.3)
user_page = user_profile_pc.replace('www', 'm',1)
print(user_page)
headers1 = {'cookie': cookiesm, 'user-agent': ua, 'Referer': 'https://m.douban.com/'}
response_user = requests.get(url=user_page, headers=headers1)
text1 = response_user.text
user_info = re.search(r"var __INITIAL_STATE__ =(.*?).*?\n.*?\n", text1).group()
# 使用正则表达式提取 JSON 部分
json_str = re.search(r'\{.*\}', user_info).group()
# 将字符串转换为有效的 JSON
json_str = json_str.replace('user:', '"user":')
# 解析 JSON
data = json.loads(json_str)
# 用户名、性别、描述
user_name = data['name']
print('用户名是:', user_name)
user_gender = data['gender']
print('用户性别是:', user_gender)
user_des = re.search(r'<meta name="description" content="([^"]+)"', text1).group().replace(
'<meta name="description" content=', '')
# print('用户描述是:', user_des)
position = (user_name,user_gender,user_des,times,title,link,content,rates,location,ups,downs,replys)
writer.writerow(position)
print(f'====={count}条评论保存成功=====')
except Exception as e:
# 处理所有异常
print(f"发生错误: {e}")
else:
print('!!!!!报错', response.status_code)
print(f'{count}条评论保存成功')
csv_file.close()
print('已保存文件')运行结果

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









