







selenium
一、前期准备
1、概述
selenium本身是一个自动化测试工具。它可以让python代码调用浏览器。并获取到浏览器中加载的各种资源。 我们可以利用selenium提供的各项功能。 帮助我们完成数据的抓取。
2、学习目标
- 掌握 selenium发送请求,加载网页的方法
- 掌握 selenium简单的元素定位的方法
- 掌握 selenium的基础属性和方法
- 掌握 selenium退出的方法
3、安装
安装:pip install selenium
它与其他库不同的地方是他要启动你电脑上的浏览器, 这就需要一个驱动程序来辅助.
这里推荐用chrome浏览器
chrome驱动地址:
https://googlechromelabs.github.io/chrome-for-testing/#stable
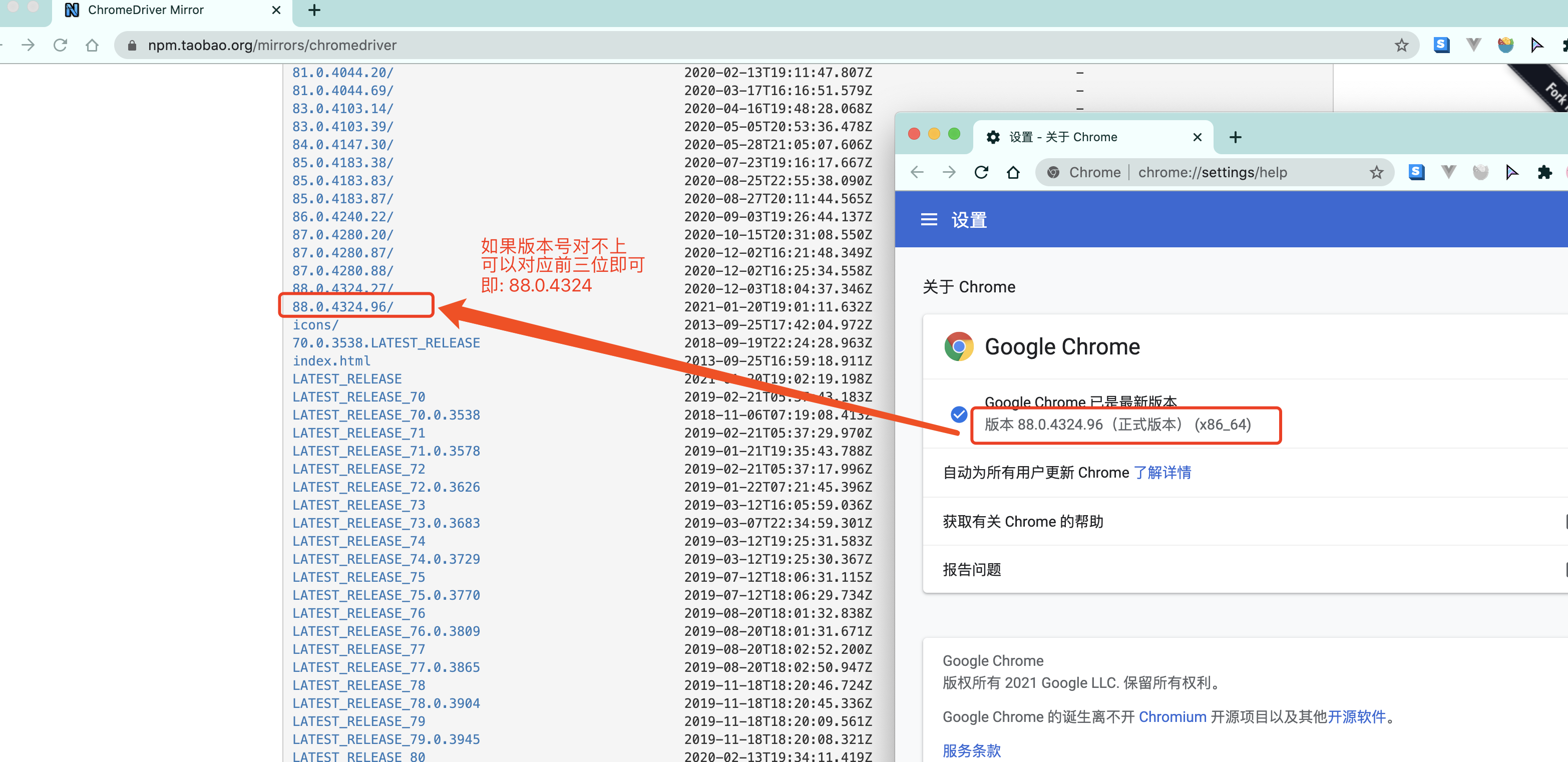
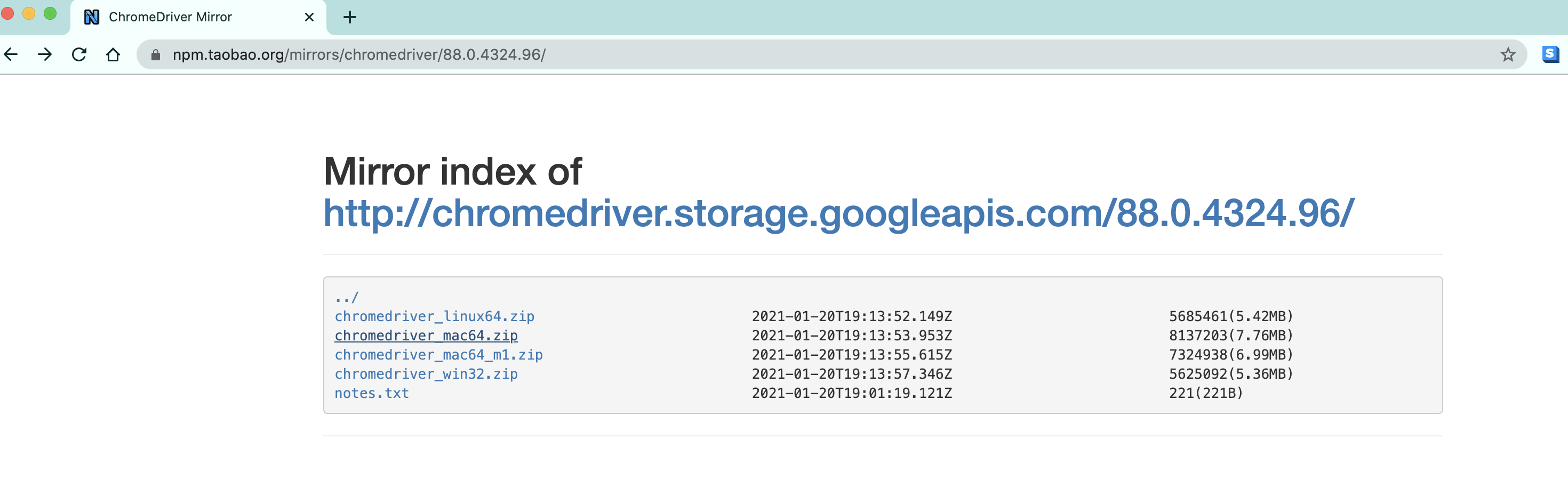
根据你电脑的不同自行选择吧. win64选win32即可.
然后关键的来了. 把你下载的浏览器驱动放在python解释器所在的文件夹
Windows: py -0p 查看Python路径
Mac: open + 路径
例如:open /usr/local/bin/
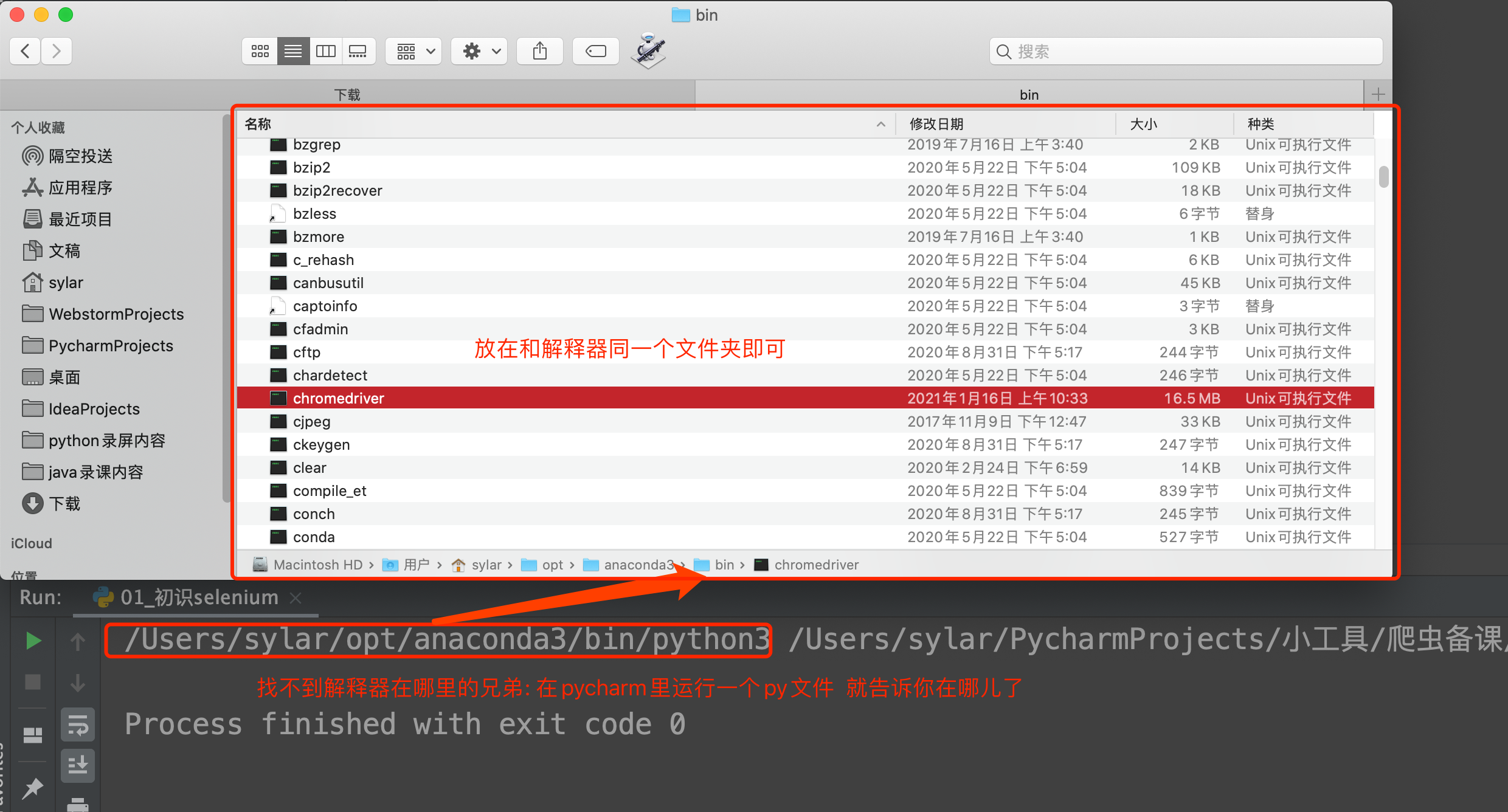
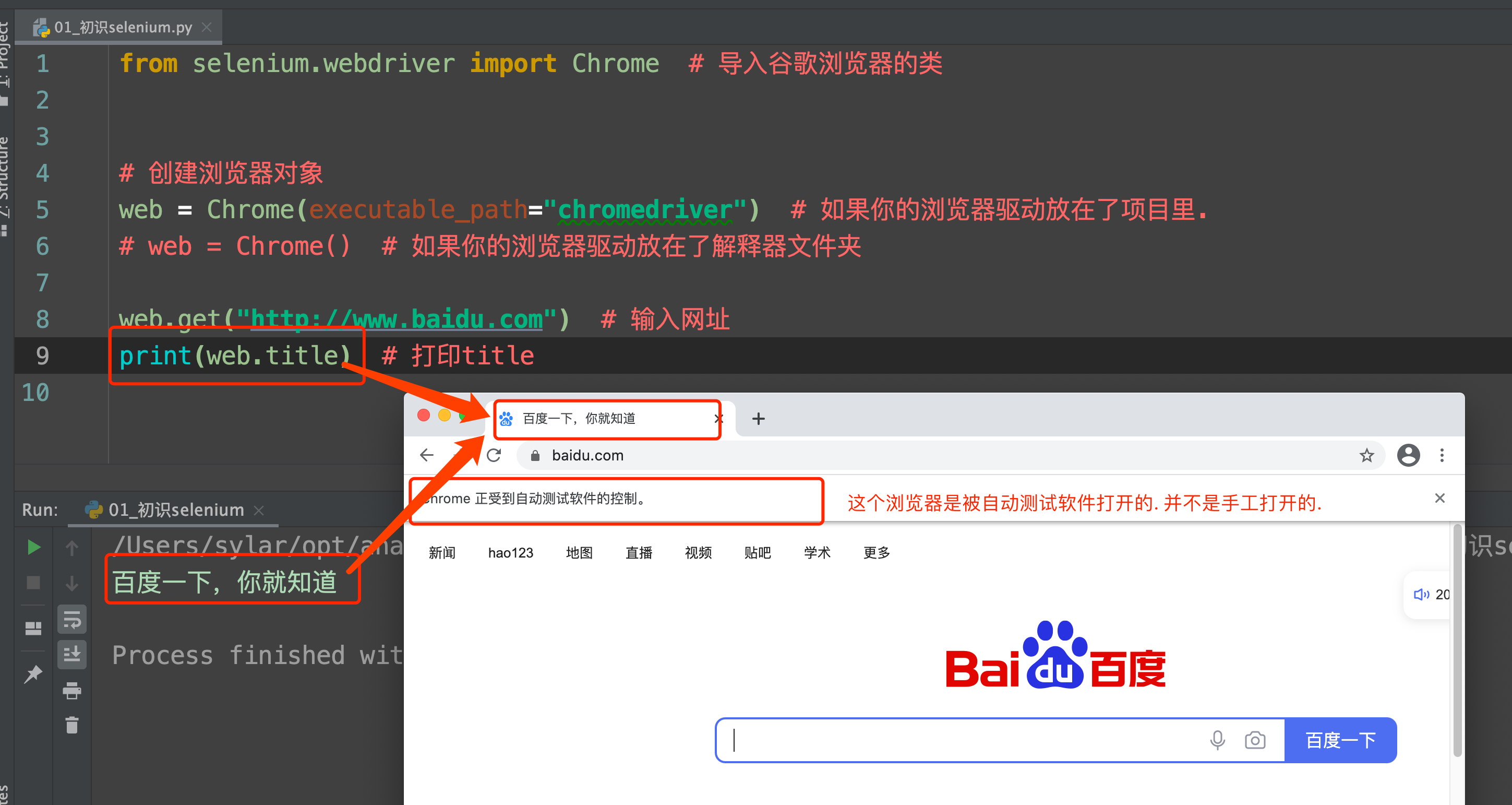
前期准备工作完毕. 上代码看看 感受一下selenium
from selenium.webdriver import Chrome # 导入谷歌浏览器的类
# 创建浏览器对象
web = Chrome() # 如果你的浏览器驱动放在了解释器文件夹
web.get("http://www.baidu.com") # 输入网址
print(web.title) # 打印title
运行一下你会发现神奇的事情发生了. 浏览器自动打开了. 并且输入了网址. 也能拿到网页上的title标题.
二、selenium的基本使用
1、加载网页:
selenium通过控制浏览器,所以对应的获取的数据都是elements中的内容
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# 访问百度
driver.get("http://www.baidu.com/")
# 截图
driver.save_screenshot("baidu.png")
2、定位和操作:
# 搜索关键字 杜卡迪
driver.find_element(By.ID, "kw").send_keys("杜卡迪")
# 点击id为su的搜索按钮
driver.find_element(By.ID, "su").click()
3、查看请求信息:
driver.page_source # 获取页面内容
driver.get_cookies()
driver.current_url
4、退出
driver.close() # 退出当前页面
driver.quit() # 退出浏览器
小结
- selenium的导包:
from selenium import webdriver - selenium创建driver对象:
webdriver.Chrome() - selenium请求数据:
driver.get("http://www.baidu.com/") - selenium查看数据:
driver.page_source - 关闭浏览器:
driver.quit() - 根据id定位元素:
driver.find_element_by_id("kw")/driver.find_element(By.ID, "kw") - 操作点击事件:
click() - 给输入框赋值:
send_keys()
三、元素定位的方法
学习目标
- 掌握 selenium定位元素的方法
- 掌握 selenium从元素中获取文本和属性的方法
通过selenium的基本使用可以简单定位元素和获取对应的数据,接下来我们再来学习下 定位元素的其他方法
1、selenium的定位操作
-
元素定位的两种写法:
-
直接调用型
el = driver.find_element_by_xxx(value) # xxx是定位方式,后面我们会讲,value为该方式对应的值 -
使用By类型(需要导入By) 建议使用这种方式
# 直接掉用的方式会在底层翻译成这种方式 from selenium.webdriver.common.by import By driver.find_element(By
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











