







原文件下载路径:爬虫技术常见反爬虫策略及应对方法总结:面试题整理与解决方案设计
1. 常见的反爬虫和应对方法?
1. 基于身份识别进行反爬
(1) 用户请求的headers
- headers知识补充:
- host:提供了主机名及端口号
- Referer 提供给服务器客户端从那个页面链接过来的信息(有些网站会据此来反爬)
- Origin:Origin字段里只包含是谁发起的请求,并没有其他信息.(仅存于post请求)
- User agent: 发送请求的应用程序名(一些网站会根据UA访问的频率间隔时间进行反爬)
- proxies:代理,一些网站会根据ip访问的频率次数等选择封ip.
- cookie:特定的标记信息,一般可以直接复制,对于一些变化的可以选择构造.
(2) 通过请求参数来反爬
常见的有:
- 通过headers中的User-Agent字段来反爬、通过referer字段或者是其他字段来反爬。如果Python写的爬虫不加入User-Agent,在后台服务器是可以看到服务器的类型pySpider。
- 通过cookie限制抓取信息,比如我们模拟登陆之后,想拿到登陆之后某页面信息,千万不要以为模拟登陆之后就所有页面都可以抓了,有时候还需要请求一些中间页面拿到特定cookie,然后才可以抓到我们需要的页面。
- 最为经典的反爬虫策略当属“验证码”了。最普通的是文字验证码,因为是图片用户登录时只需输入一次便可录成功,而我们程序抓取数据过程中,需要不断的登录,手动输入验证码是不现实的,所以验证码的出现难倒了一大批人。当然还有滑块的,点触的的(比如12306的点触验等)。
- 另一种比较常见的反爬虫模式当属采用JS渲染页面了。就是返回的页面并不是直接请求得到,而是有一部分由JS操作DOM得到,所以那部分数据我们也拿不到咯。
2. 基于爬虫行为进行反爬
(1) 基于请求频率或总请求数量的反扒,这是一种比较恶心又比较常见的反爬虫策略当属封ip和封账号,当你抓取频率过快时,ip或者账号被检测出异常会被封禁。被封的结果就是浏览器都无法登陆了,但是换成ip代理就没有问题。
问题:爬虫如何避免被封IP呢?
- 降低访问频率:反爬虫一般是在规定时间内IP访问次数进行的限制,可以限制每天抓取的页面数量和时间间隔。既能满足采集速度,也能不被限制IP。
- 多线程采集:反爬虫一般是在规定时间内IP访问次数进行的限制,可以限制每天抓取的页面数量和时间间隔。既能满足采集速度,也能不被限制IP。
- 使用代理IP:反爬虫一般是在规定时间内IP访问次数进行的限制,可以限制每天抓取的页面数量和时间间隔。既能满足采集速度,也能不被限制IP。
- 对IP进行伪装:虽然大多网站都有反爬虫,但有一些网站对这方便比较忽略,这样就可以对IP进行伪装,修改X-Forwarded-for就可以避过。但如果想频发抓取,还是需要多IP。
(2) 通过js实现跳转来反爬,js实现页面跳转,无法在源码中获取下一页url,需要多次抓包获取条状url,分析规律。
(3) 通过蜜罐(陷阱)获取爬虫ip(或者代理ip),进行反爬。蜜罐的原理:在爬虫获取链接进行请求的过程中,爬虫会根据正则,xpath,css等方式进行后续链接的提取,此时服务器端可以设置一个陷阱url,会被提取规则获取,但是正常用户无法获取,这样就能有效的区分爬虫和正常用户。
(4) 通过假数据反爬,向返回的响应中添加假数据污染数据库,通常假数据不会被正常用户看到。
3. 基于数据加密进行反爬
(1) 对响应中含有的数据进行特殊化处理(通常的特殊化处理主要指的就是css数据偏移/自定义字体/数据加密/数据图片/特殊编码格式等)。
(2) 有一些网站的内容由前端的JS动态生成,由于呈现在网页上的内容是由JS生成而来,我们能够在浏览器上看得到,但是在HTML源码中却发现不了。这就需要解析关键js,获得数据生成流程,模拟生成数据。一般获取的数据是通过AJAX获取的,返回的结果是Json,然后解析Json获取数据。
(3) 通过编码格式进行反爬,不适用默认编码格式,在获取响应之后通常爬虫使用utf-8格式进行解码,此时解码结果将会是乱码或者报错。解决思路:根据源码进行多格式解码,或者真正的解码格式。
2. JavaScript 基本类型:
number, string, boolean, symbol, undefind, null, Object
3. 网络七层协议:
应用层: HTTP FTP DNS TFTP
表示层: 数据加密
会话层: SQL RPC
传输层: TCP UDP
网络层: IP IPX
数据链路层: ATM
物理层: 电路
4. 如何实现全站数据爬取?
基于手动请求发送+递归解析
基于CrwalSpider(LinkExtractor,Rule)
5. 爬取速度过快出现了验证码怎么处理?
- 控制抓取速度,定时或随机sleep
- 定时或定量切换ip地址
- 绕过验证码;在爬虫的时候遇到各种需要登录网址,也有验证码。就会手工的把cookie信息复制下来,加到请求头上就可以了。
- 将许多验证码解算器集成到他的爬虫系统中(验证码识别服务供应商 Death by CAPTCHA 和 Bypass CAPTCHA 都允许用户通过调用API服务来进行自动打码,从而在抓取数据过程中自动解决验证码。)
- 将验证码返回打码,可采用人工或者打码平台。
6. 写爬虫是用多进程好?还是多线程好?为什么?
IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率;
单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率。
在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程,更多情况下爬虫适合多线程,爬虫是对网络操作属于 io 密集型操作适合使用多线程或者协程。
7. 什么是深度优先和广度优先?
默认情况下scrapy是深度优先;
- 深度优先:占用空间大,但是运行速度快
- 广度优先:占用空间少,运行速度慢
8. 简述 requests模块的作用及基本使用?
作用:使用requests可以模拟浏览器发送的请求。
基本使用:
- 发送get请求:requests.get()
- 发送post请求:requests.post()
- 读取请求返回内容:requests.text()
- 保存cookie:requests.cookie()
9. 协程的适用场景?
当程序中存在大量不需要CPU的操作时(即IO使用较多情况下)。
10. 解析网页的解析器使用最多的是哪几个?
re正则匹配
python自带的html.parser模块
第三方库BeautifulSoup(重点学习)
以及lxml库
11. hashlib 密码加密
def get_hex(value):
md5_ = hashlib.md5()
md5_.update(value.encode('utf-8'))
return md5_.hexdigest()
12. 解释在多任务异步协程中事件循环(loop)的作用是什么?
可以将注册在其内部的任务对象表示的特定操作进行异步执行;
13. 代理失效了怎么处理?
设置一个代理池(一个列表放了多个代理服务器的ip),实现代理切换等操作,来实现实时使用新的代理 ip,来避免代理失效的问题。
14. 关于 response.text 乱码问题
response的常用属性:
- 获取字符串类型的响应正文:response.text
- 获取bytes类型的响应正文:response.content
- 响应正文字符串编码:response.encoding
- 状态码:response.status_code
- 响应头:response.headers
15. 列出你知道header的内容以及信息
Accept: text/html,image/* -- 浏览器接受的数据类型
Accept-Charset: ISO-8859-1 -- 浏览器接受的编码格式
Accept-Encoding: gzip,compress --浏览器接受的数据压缩格式
Accept-Language: en-us,zh- --浏览器接受的语言
Host: www.it315.org:80 --(必须的)当前请求访问的目标地址(主机:端口)
Referer: http://www.it315.org/index.jsp -- 当前请求来自于哪里
User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) --浏览器类型
Cookie:name=eric -- 浏览器保存的cookie信息
Connection: close/Keep-Alive -- 浏览器跟服务器连接状态。close: 连接关闭 keep-alive:保存连接。
16. HTTP协议和HTTPS协议的区别?
HTTP协议是使用明文数据传输的网络协议,明文传输会让用户存在一个非常大的安全隐患。端口80
HTTPS协议可以理解为HTTP协议的安全升级版,就是在HTTP的基础上增加了数据加密。端口443
HTTPS协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议要比HTTP协议安全。
17. 关于响应常见的响应码?
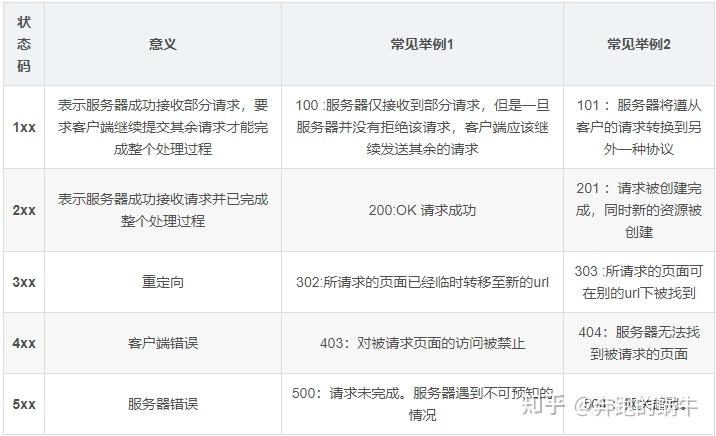
18. 实现模拟登录的方式有哪些?
- 直接使用已知的Cookie访问
先用浏览器登录,获取浏览器里的cookie字符串,然后封装至请求头。
- 模拟登录后用session保持登录状
使用session模拟登陆后,就会自动存储一个cookie次从而保持住登录状态。
- 使用Selenium+PhantomJS访问
Selenium库提供了find_element(s)_by_xxx的方法来找到网页中的输入框、按钮等元素。
其中xxx可以是id、name、tag_name(标签名)、class_name(class),也可以是xpath(xpath表达式)等等。当然还是要具体分析网页源代码。
19. 用的什么框架,为什么选择这个框架?
scrapy
基于twisted异步io框架,是纯python实现的爬虫框架,性能是最大的优势
可以加入request和beautifulsoup
方便扩展,提供了很多内置功能
内置的cssselector和xpath非常方便
默认深度优先
pyspider:爬虫框架,基于PyQuery实现的
- 优势:
可以实现高并发的爬取数据, 注意使用代理
提供了一个爬虫任务管理界面, 可以实现爬虫的停止,启动,调试,支持定时爬取任务;
代码简洁
- 劣势:
可扩展性不强;
整体上来说一些结构性很强的,定制性不高,不需要太多自定义功能时用pyspider即可,一些定制性高的,需要自定义一些功能时则使用 Scrapy。
20. scrapy的去重原理 (指纹去重到底是什么原理?)
需要将dont_filter设置为False开启去重,默认是False;
对于每一个url的请求,调度器都会根据请求的相关信息加密得到一个指纹信息,并且将指纹信息和set()集合中得指纹信息进行比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中。如果set()集合中没有,就将这个Request对象放入队列中,等待被调度。
21. scrapy中间件有几种类?你用过哪些中间件?
scrapy的中间件理论上有三种(SchdulerMiddleware,SpiderMiddleware,DownloaderMiddleware)
在应用上一般有以下两种:
- 爬虫中间件SpiderMiddleware: 主要功能是在爬虫运行过程中进行一些处理;
- 下载器中间件DownloaderMiddleware: 主要功能在请求到网页后,页面被下载时进行一些处理;
22. scrapy如何实现持久化存储?
解析数据—将解析的数据封装到item中—将item提交管道—在管道中持久化存储—开启管道
23. scrapy 和 scrapy-redis 有什么区别?为什么选择 redis 数据库?
主要区别:
- scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。
- scrapy-redis一套基于redis数据库、运行在scrapy框架之上的组件,可以让scrapy支持分布式策略,Slaver端共享Master端redis数据库里的item队列、请求队列和请求指纹集合。
选择 redis 数据库:
- 因为redis支持主从同步,而且数据都是缓存在内存中的,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高。
24. scrapy-redis组件中如何实现的任务的去重?
a. 内部会使用以下配置进行连接Redis
# REDIS_HOST = 'localhost' # 主机名
# REDIS_PORT = 6379 # 端口
# REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置)
# REDIS_PARAMS = {} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}
# REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块 默认:redis.StrictRedis
# REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8'
b. 去重规则通过redis的集合完成,集合的Key为:
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
默认配置:
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
c. 去重规则中将url转换成唯一标示,然后在redis中检查是否已经在集合中存在
from scrapy.utils import request
from scrapy.http import Request
req = Request(url='http://www.cnblogs.com/wupeiqi.html')
result = request.request_fingerprint(req)
print(result) # 8ea4fd67887449313ccc12e5b6b92510cc53675c
PS:
- URL参数位置不同时,计算结果一致;
- 默认请求头不在计算范围,include_headers可以设置指定请求头
示例:
from scrapy.utils import request
from scrapy.http import Request
req = Request(url='http://www.baidu.com?name=8&id=1',callback=lambda x:print(x),cookies={'k1':'vvvvv'})
result = request.request_fingerprint(req,include_headers=['cookies',])
print(result)
req = Request(url='http://www.baidu.com?id=1&name=8',callback=lambda x:print(x),cookies={'k1':666})
result = request.request_fingerprint(req,include_headers=['cookies',])
print(result)
25. 通用爬虫的工作流程
抓取网页:通过搜索引擎将待爬取的URL加入到通用爬虫的URL队列中,进行网页内容的爬取。
数据存储:将爬取下来的网页保存到本地,这个过程会有一定的去重操作,如果某个网页的内 容大部分内容都会重复,搜索引擎可能不会保存。
预处理:提取文字,中文分词,消除噪音(比如版权声明文字,导航条,广告等)。
设置网站排名,为用户提供服务。
26. 有GLF锁为什么还要有互斥锁?
- 为什么设计GLF锁?
Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是GIL锁能保证同一时刻只有一个线程在运行。
- 宏观微观考虑GLF锁?
GIL是宏观的操作。比如在一个4核的环境下,只有一个核是运行着线程,而其他三个核是空的。GIL是线程锁,针对线程,而不是进程
27. 死锁问题
- 同一个线程先后两次调用lock,在第二次调用时,由于锁已经被自己占用,该线程会挂起等待自己释放锁,由于该线程已被挂起而没有机会释放锁,因此 它将一直处于挂起等待状态,变为死锁;
- 线程A获得了锁1,线程B获得了锁2,这时线程A调用lock试图获得锁2,结果是需要挂起等待线程B释放锁2,而这时线程B也调用lock试图获得锁1,结果是需要挂起等待线程A释放锁1,于是线程A和B都在等待对方释放自己才释放,从而造成两个都永远处于挂起状态,造成死锁。
28. MongoDB和传统的关系型数据库区别?
- 传统数据库特点是存储结构化数据,数据以行为单位,每行的数据结构和类型相同
- MongoDB存储的是文档,每个文档得结构可以不相同,能够更便捷的获取数据。
- MongoDB的集合不需要提前创建,可隐式创建,而关系型数据库的表需要提前定义
- mongo第三方支持丰富。(这是与其他的NoSQL相比,MongoDB也具有的优势)
- mongodb不支持事务操作
- mongodb支持大容量的存储,占用空间过大
29. 移动端数据如何抓取?
- fiddler
- 查尔斯
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











