






第一章:绪论


事前分析法估算算法运行时间:
算法运行时间=每条语句频度*该语句执行一次的时间
但由于语句执行一次的时间由软硬件决定与算法无关,所以算法运行时间可以约等于每条语句频度。
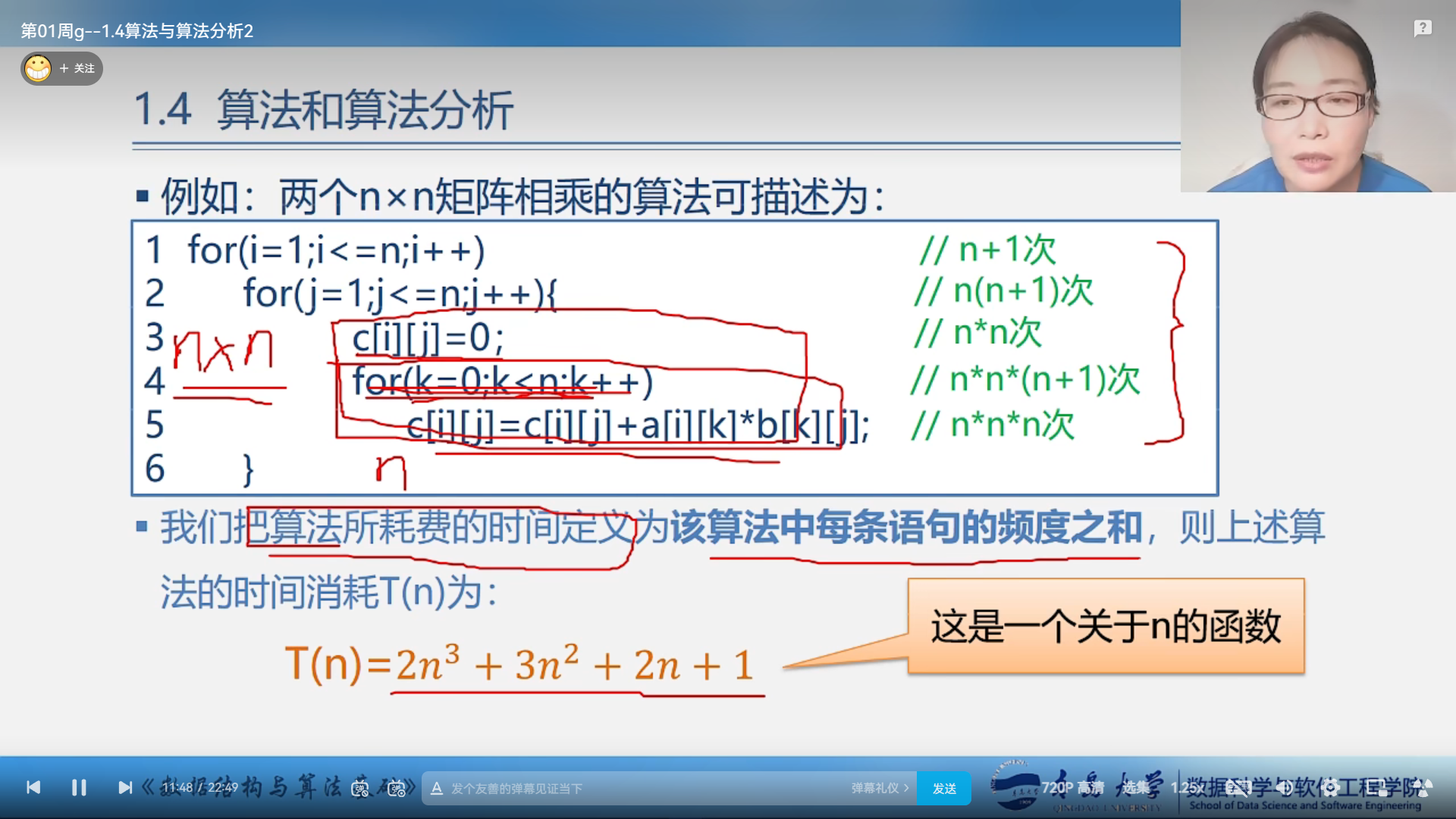
外层的for循坏是要比内层的for循环多循环一次的,因为最后一次外层的for循坏要跳出循环而不能进入内层的循环。
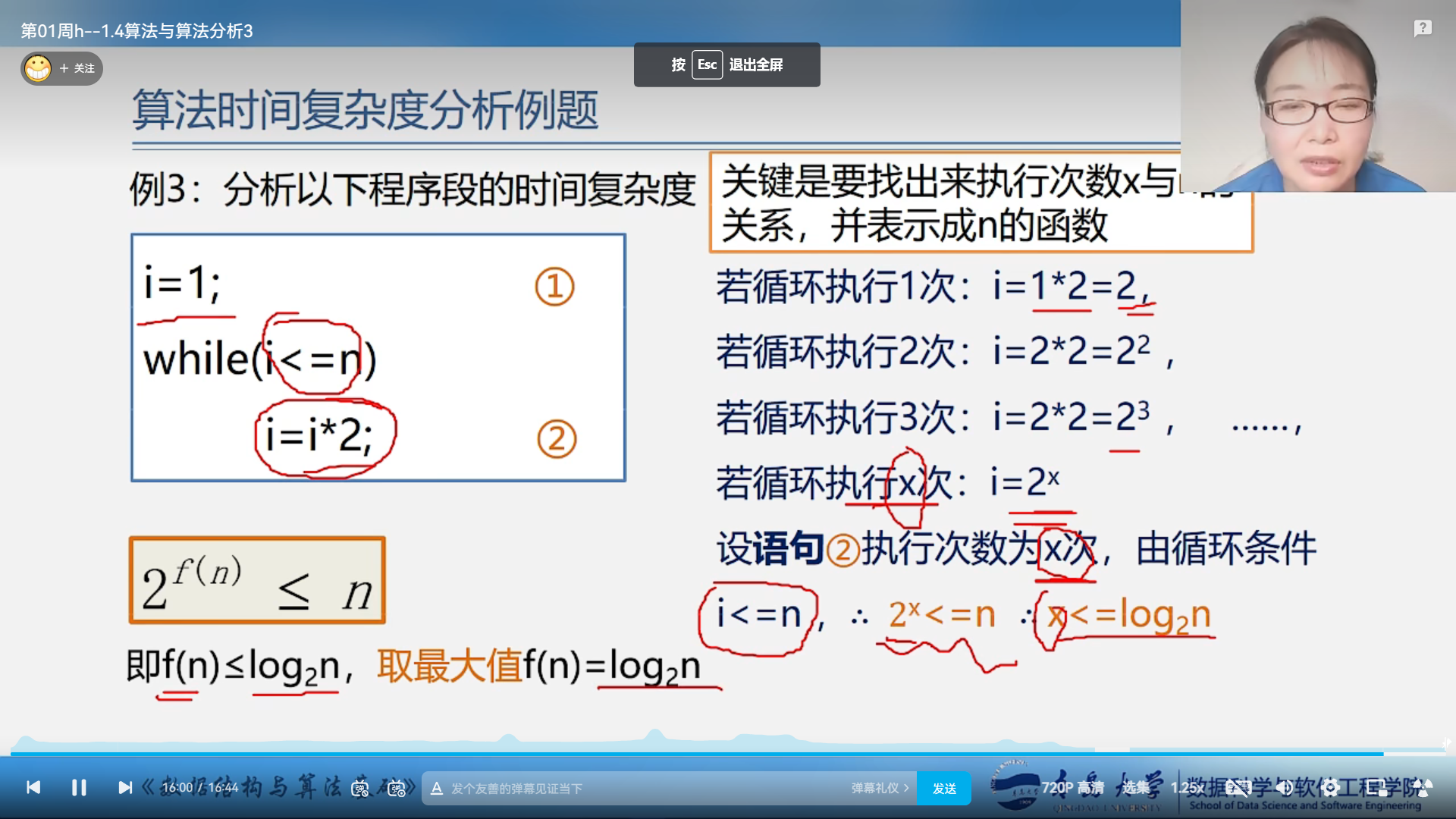
比较算法的效率一般比较函数数量级 10 *n的平方 < 5 * n的三次方


f(n)即最大的数量级
渐进时间复杂度:它表示随着n的增大,算法执行的增长率和f(n)的增长率相同
整个算法某些操作贡献率比较小,没必要考虑所有操作的执行次数,只考虑基本操作执行的次数

最里面那层是k从1到j也就是一开始是1 然后k++,2,k++,一直到j
第二层是就从1开始到i,由于k一直在增加,所以就是1+2+3+4一直加到i
后面根据高数计算即可
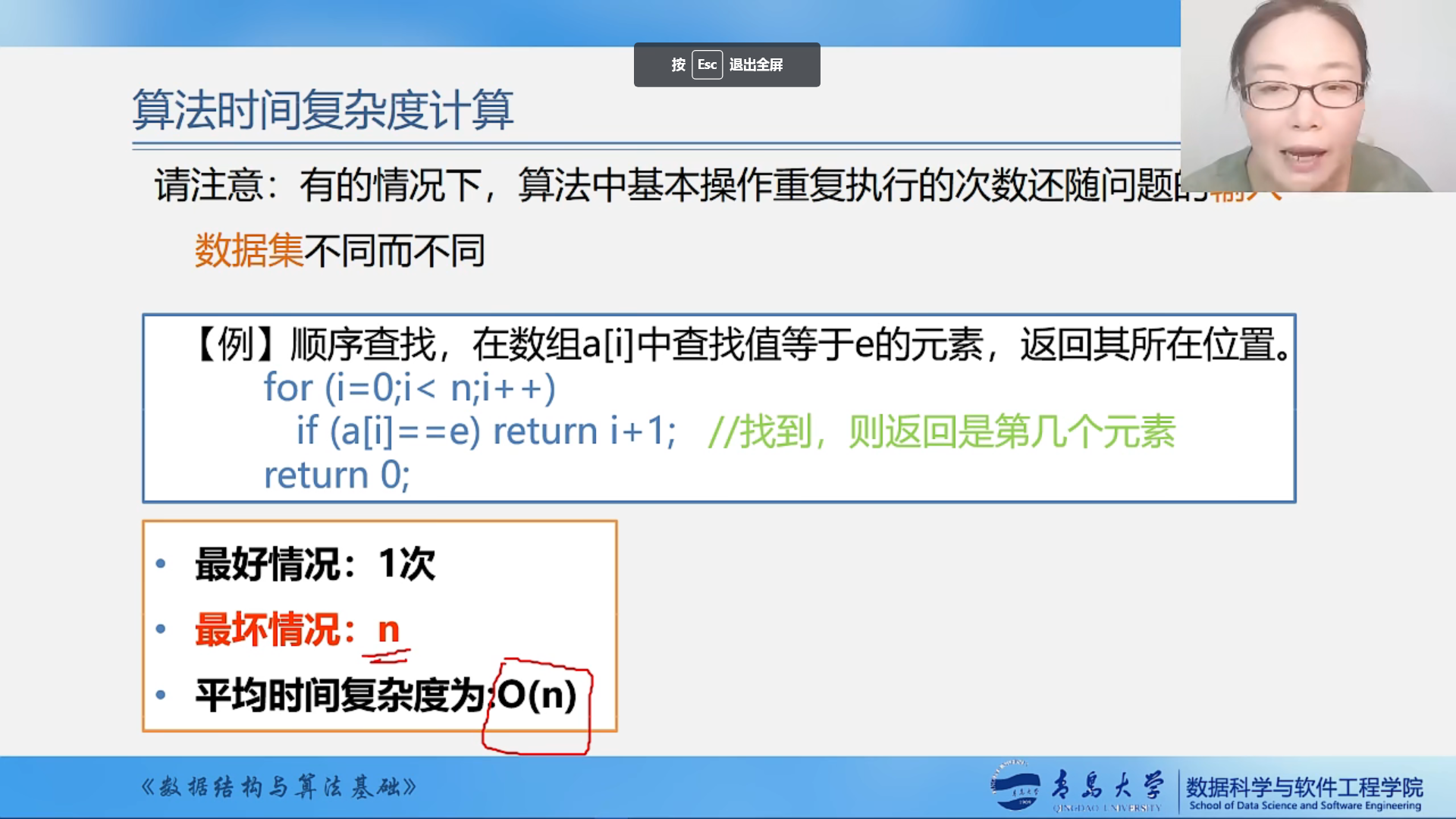
时间复杂度还可能与输入数据集不同而不同
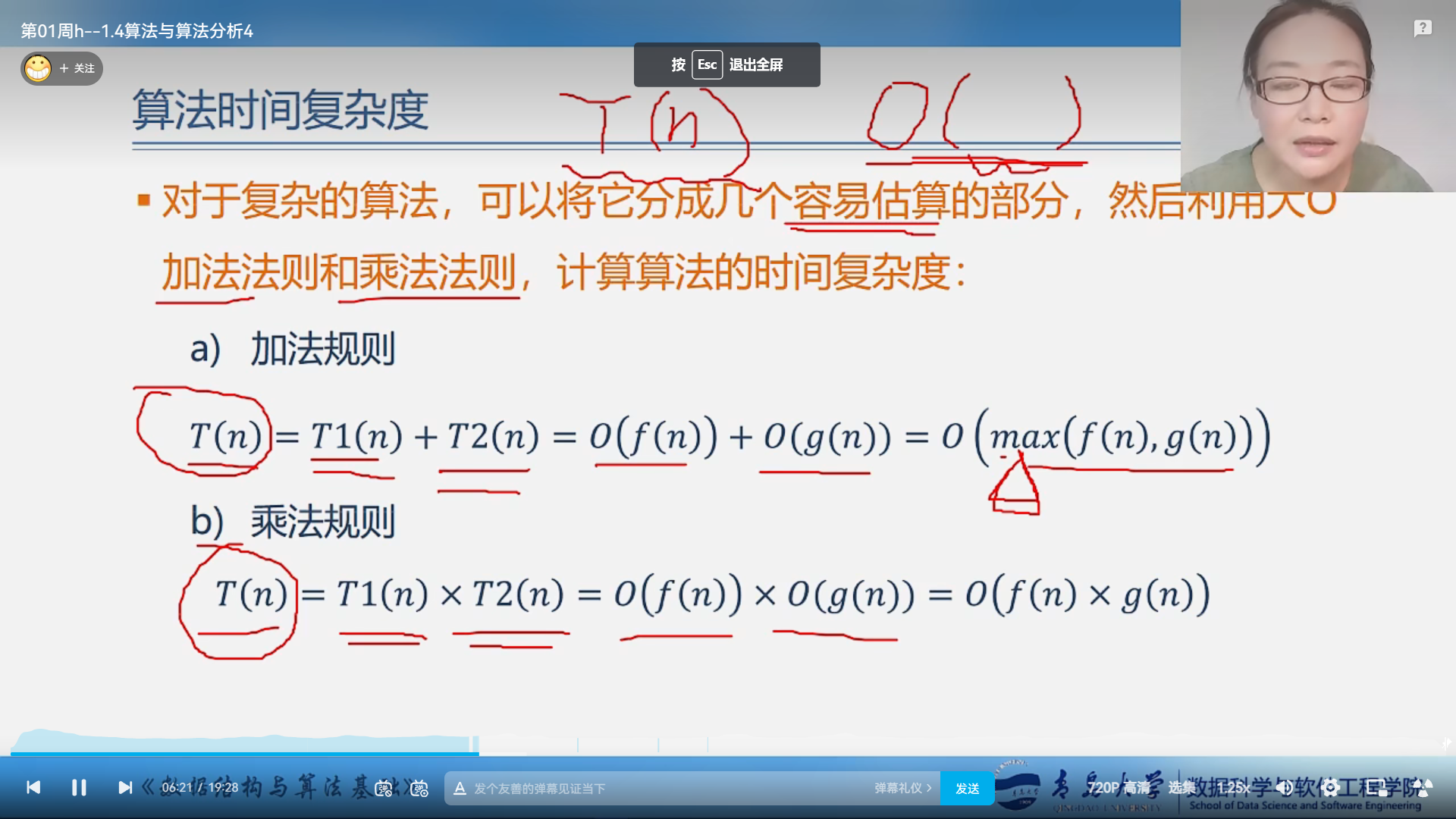
算法的效率是由时间效率和空间效率决定的,下面来介绍空间复杂度

算法1的思路是将数组里的第一个元素与最后一个元素交换,第二个元素与倒二个元素交换,这样一直到交换完成
算法2的思路是额外拿出一个数组b,将数组a的内容倒叙输入至数组b中,再将数组b中的内容复制到数组a中
显然算法2比较麻烦,算法1的空间复杂度为o(1),原地工作,算法2的空间复杂度为o(n),我这里的理解是算法1只需要一个格子来放,相当于暂存区,而算法2的暂存区时一个长度为n的数组。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









