






进程地址空间的概念
理解进程地址空间的现象
我们先通过代码来感受一个奇怪现象:
运行起来:
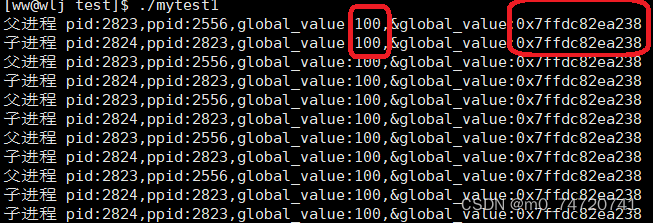
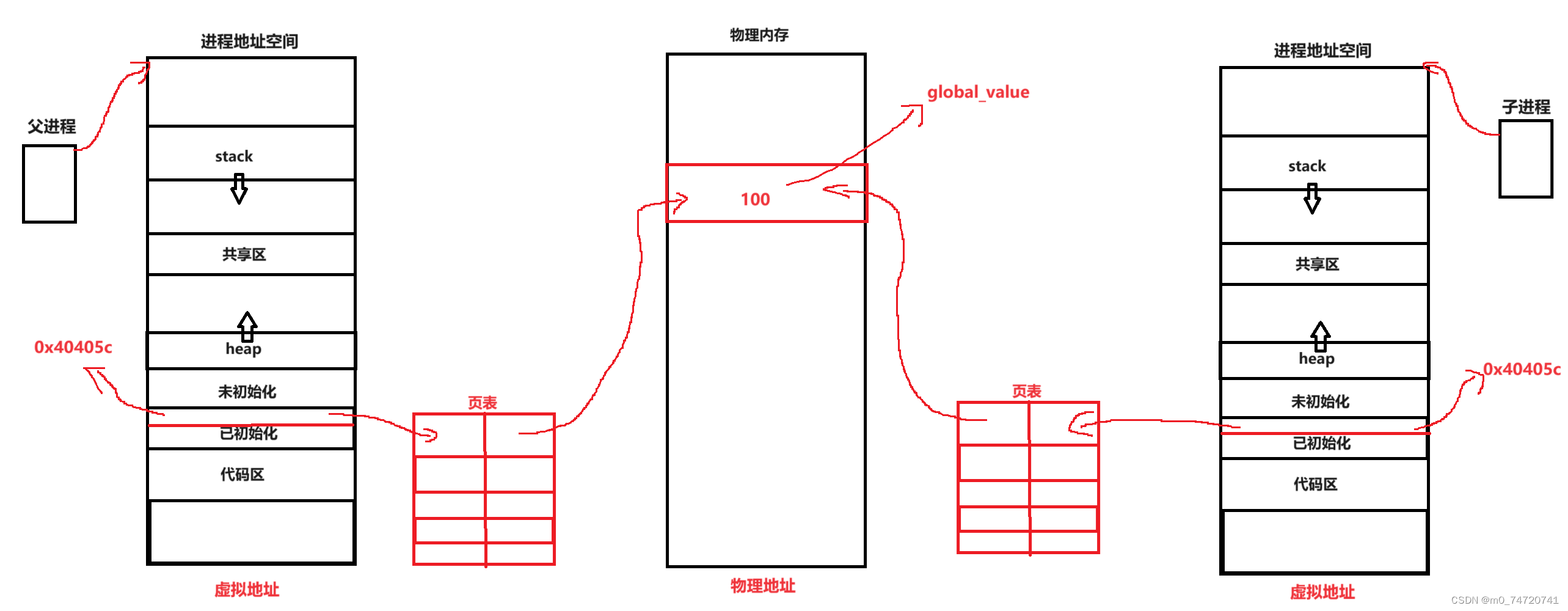
可以清楚地发现:父进程与子进程的变量global_value的地址相同,进而global_value的值也理所应当的相同。但如果我们把子进程中的global_value值修改而父进程的global_value值不修改,会有什么现象?
修改代码如下:
我们可以看到一个奇怪现象,在我们学习C/C++中地址相同,访问的空间不就是同一个吗?为什么会出现地址相同且值不相同的情况呢?
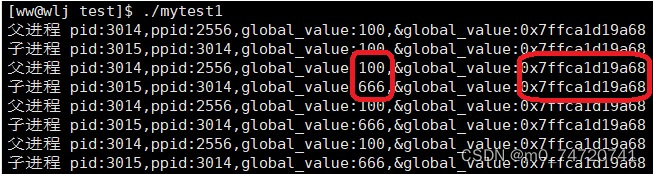
由此我们可以得出以下结论
- 父子进程输出的值不相同,所以输出的绝对不是同一个值
- 地址不变,所以这里的地址绝对不是物理地址,而是虚拟地址或者线性地址。
- 我们在C/C++语言中所说的地址,都不是物理地址,而是虚拟地址。
- 物理地址一般都由操作系统OS管理的,我们用户基本看不到。
进程地址空间本质就是一个内核数据结构struct mm_struct(4GB)

这里是每一个区域的开始数值和结束数值。例如总共有200份空间 code部分[1(code_start),50(code_end)]......
区域划分调整
所谓的heap && stack 的区域调整,本质就是修改各个区域的end和start。
定义局部变量,malloc、new堆空间——>实际上就是扩大栈区或者堆区 函数的调用完毕,free、delete——>实际上就是缩小栈区或者堆区
如何从虚拟地址转化为物理地址
现在我们创建了一个char c=100;&c取的是虚拟地址。下面示意图解释了如何找到c对应的物理地址。

通过c的虚拟地址这里假设(0x1234 5678)到页表映射到对应的物理地址这里假设(0x1111 2222),找到在物理内存中存放值的地址。
解释进程地址空间的现象
初步了解了如何从虚拟地址转化为物理地址之后,我们可以进一步解释开头的现象
在我们子进程中值还未修改时的图:
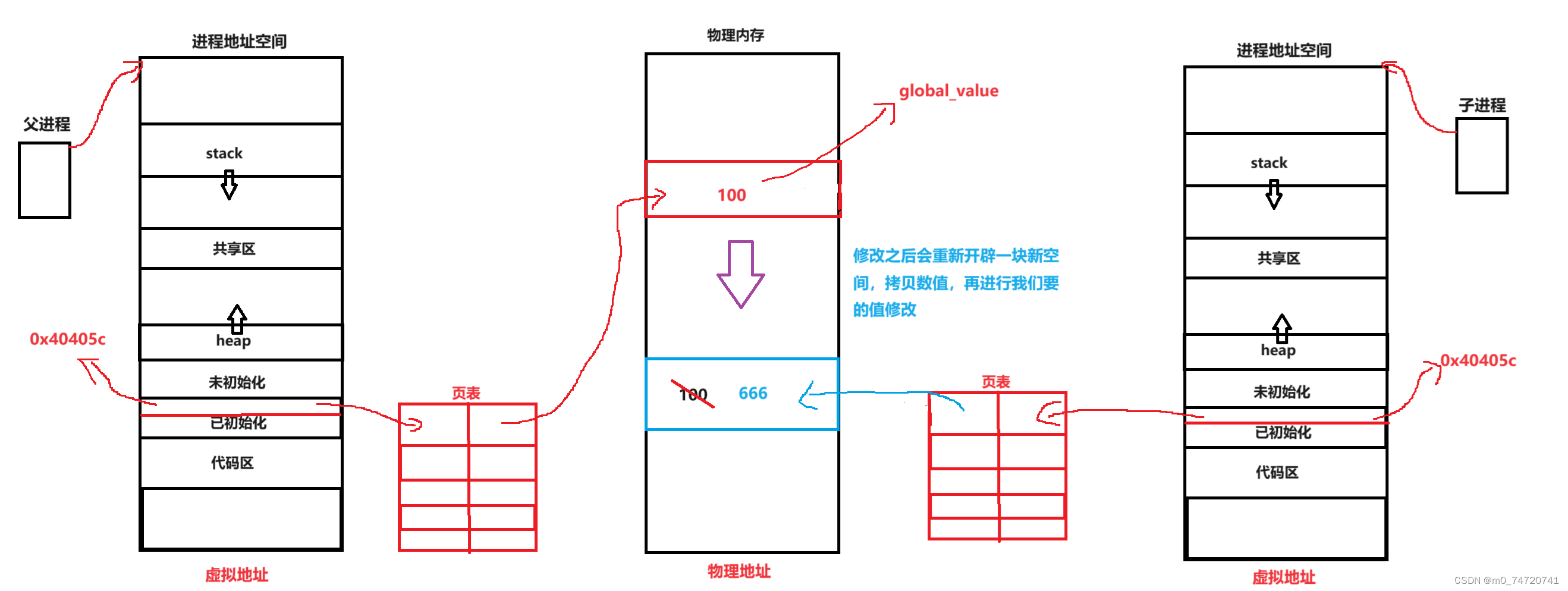
修改之后,操作系统为了保证进程的独立性,两个进程之间互不干扰,将在内存中重新开辟一块空间,拷贝数值后,再进行对应的修改。并且把子进程的页表映射位置的地址区域修改为新的地址空间,在个过程叫做写实拷贝。我们可以看到在这个过程中,进程地址空间中的虚拟地址是没有变化的。
为什么存在进程地址空间?
- 如果让进程直接访问物理内存,万一进程越界非法操作,是非常不安全的。所以因为由页表的存在,所有的映射通过页表只会映射到合法的空间。
- 进程地址空间的存在,可以更方便的进行进程与进程的数据代码的解耦,保证了进程独立性的特征。
- 让进程以统一的视角来看待进程对应的代码的数据等各个区域,方便使用。编译器也以统一的视角来进行编译代码。
重新理解进程地址空间
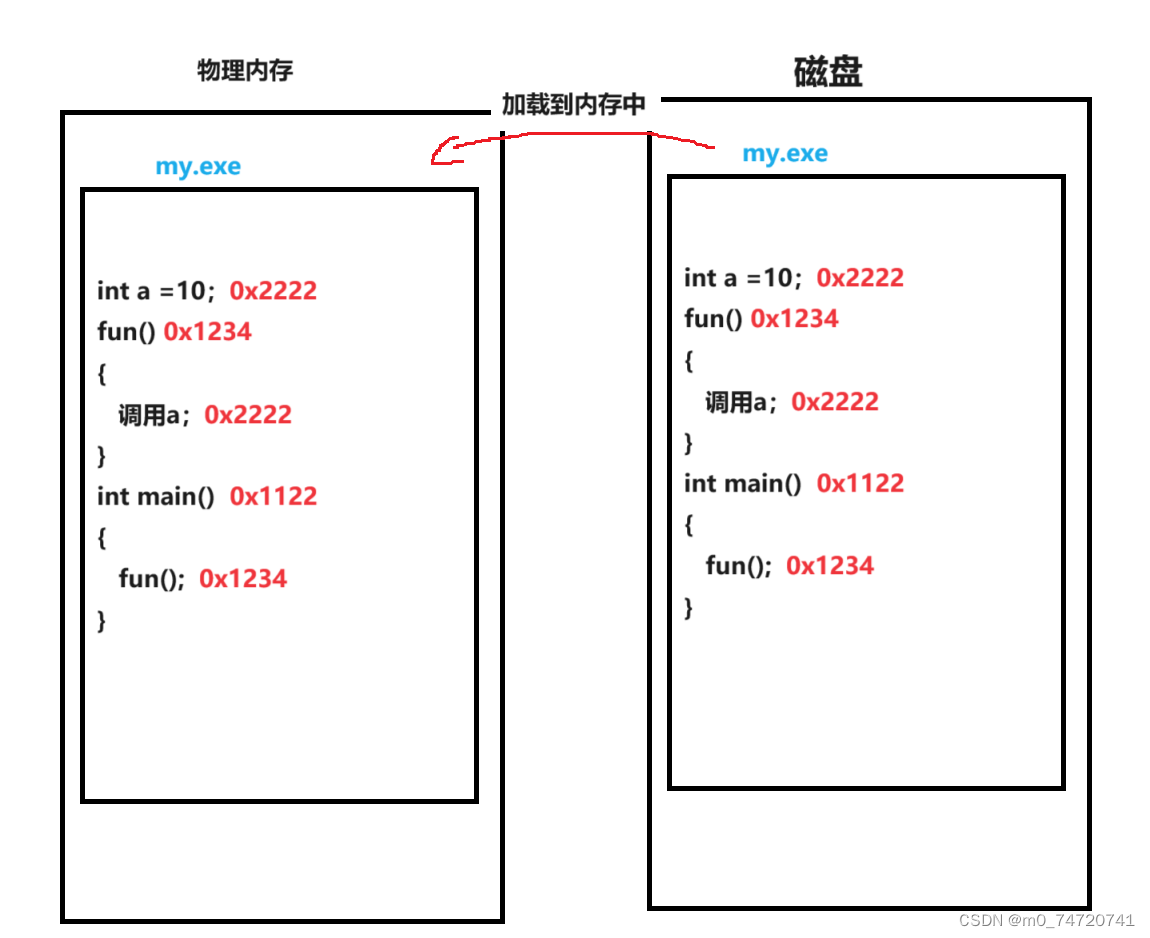
最后在重新规整的理解一次几次地址空间。首先第一个问题,在没有被加载到内存中时,你的可执行程序里面有没有地址?
答案是有的,在可执行程序在被编译后,就已经在磁盘中分配好了地址逻辑地址(虚拟地址)。编译器在编译你的代码时,就是按照虚拟地址空间的方式进行对我们代码和数据进行编址的。图示如下。

加载到内存中后,现在有了两套地址:
- 表示物理地址中代码的数据的地址。
- 在程序内部互相跳转时的虚拟地址。
cpu取到main函数地址开始执行,main函数中要调用fun(),fun()函数中又调用了变量a。cpu中的寄存器将逐个读取指令(地址)。cpu读取进来的都是指令,指令内部都有地址(虚拟地址)。
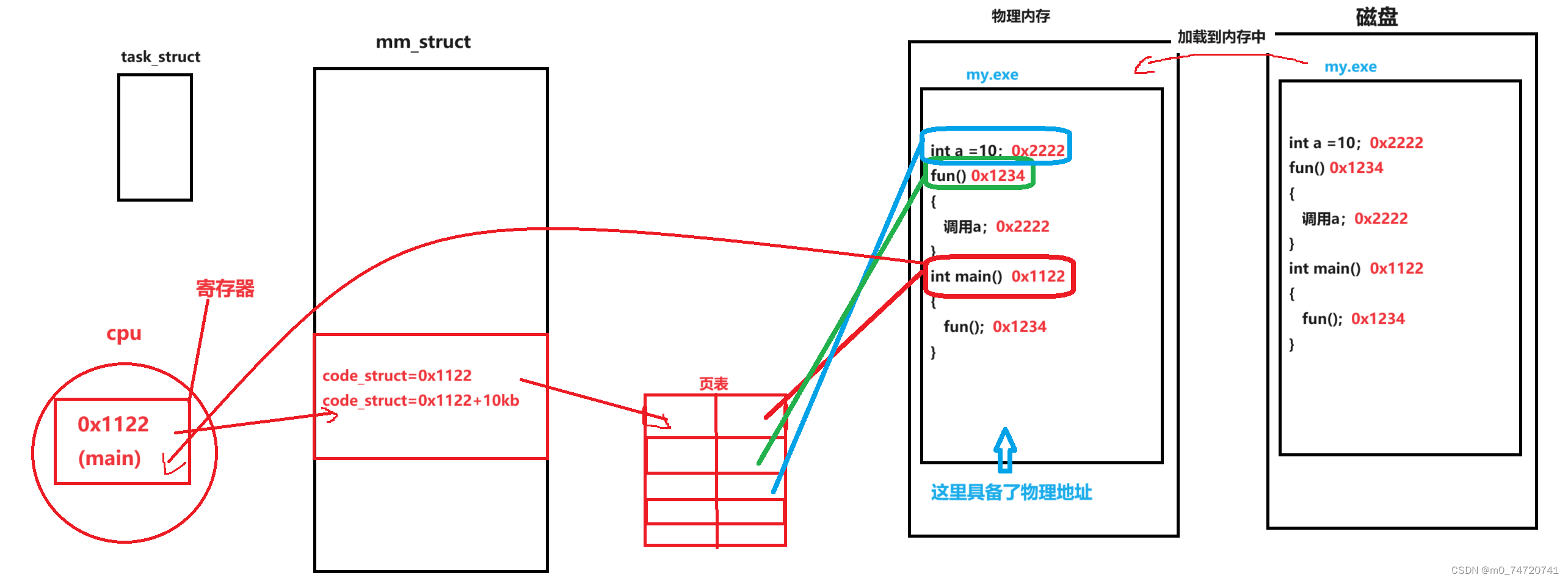
这就是可执行程序加载的全过程。















 6920
6920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









