






针对于Mysql的安装与配置等等,百度。
写这个的目的是为了 学习SQL注入准备,方便自己忘了再来复习。
Mysql版本:5.7.26
Part 01 数据库的展示与选择
1.show
1. 返回可用数据库的一个列表;
SHOW DATABASES;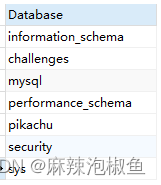
2. 返回当前选择数据库内可用表的列表(此前已选择 pikachu 库)
SHOW TABLES;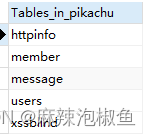
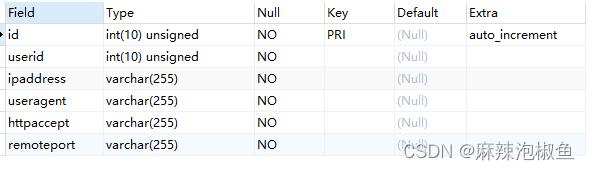
3. 显示表列。对每个字段返回一行,行中包含字段名、数据类型、是否允许NULL、键信息、默认值以及其他信息(如字段 id 的 auto_increment)。
SHOW COLUMNS FROM httpinfo;也可以使用 describe 关键字 实现相同效果
DESCRIBE httpinfo;
4.其他操作
1.显示广泛的服务器状态信息
SHOW STATUS;结果列太长只截取部分

2.显示创建特定数据库的Mysql语句
SHOW CREATE DATABASE `pikachu`;
3.显示创建特定数据表的Mysql语句
SHOW CREATE TABLE httpinfo; 
4. 显示授权用户的权限
SHOW GRANTS;
5.显示服务器错误消息
SHOW ERRORS;
6.显示服务器警告消息
SHOW WARNINGS; 
当然还有其他的,后续视情况再补充。
2.use
USE pikachu;使用 pikachu 数据库
Part 02 检索数据
1.select
使用时注意查什么?从哪个表查?
1.检索单个列
SELECT username FROM member;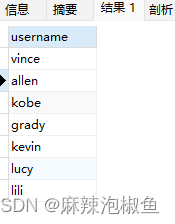
2.检索多个列
SELECT username,pw,sex FROM member;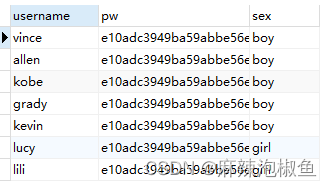
3. 检索所有列
SELECT * FROM member;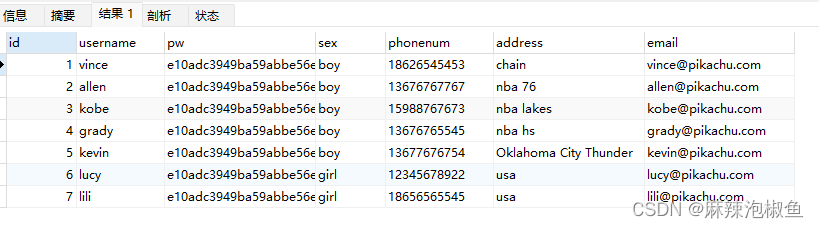
4.检索不同的行
SELECT DISTINCT username FROM member;这个表示 从 member 表中 查询 所有不同 的 username (说白了就是去重)
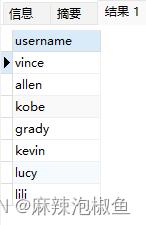
但有一点需注意:SELECT DISTINCT username,pw FROM member; 这个表示 除非 username 与 pw 列 都不相同,否则 所有行都将被检索出来(即哪怕 username 相同,但 pw 不相同,那这几个相同 username 的 行记录都会显示出来)
5.限制结果(limit 关键字)
1.检索单列,返回 前 5 行 (行0开始的 5行)
SELECT username FROM member LIMIT 5;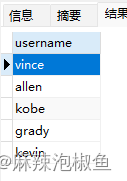
2.检索单列,返回 行3 开始的 5 行 (第一行为 行0)
SELECT username FROM member LIMIT 3,5;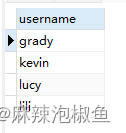
3. 针对于上一条的 替代语法 (offset 关键字)
返回 行 2 开始的 5行 ,相当于 limit 2,5
SELECT username FROM member LIMIT 5 OFFSET 2;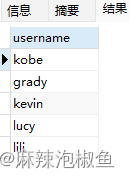
6.使用完全限定的表名
从 member 表中 查询 member 表的 username 列 (列名完全限定)
SELECT member.username FROM member;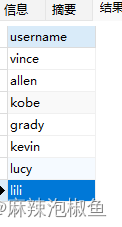
表名也可以完全限定,此处不列举。
Part 03 排序检索数据(order by字句)
1.按单列排序
SELECT username FROM member ORDER BY username;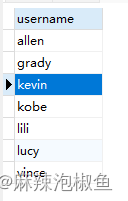
2.按多列排序
先按 username 排序,然后按 id 排序 (注意先后顺序)
SELECT id,username,address,email FROM member ORDER BY username,id;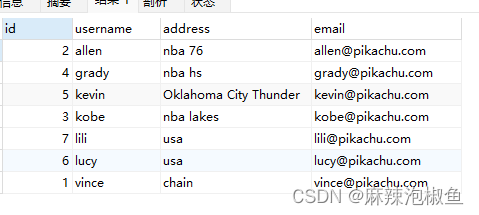
3.指定排序方向(desc 关键字)
排序默认升序,使用降序 需要指定 desc 关键字
SELECT id,username,address,email FROM member ORDER BY id DESC;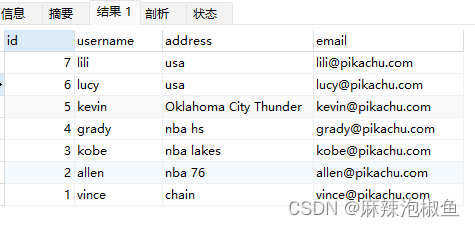
如果需要多列指定降序,需要对每个列指定 desc 关键字。
与 desc 相对的关键字 asc,在升序排序时可以指定它,但升序是默认的,没什么用处。
小结:order by 子句必须位于 from 子句之后;如果使用 limit,它必须位于order by子句之后。
Part 04 过滤数据
1.where子句
在 select 语句中,数据根据 where 子句中指定的搜索条件进行过滤。where子句在表名(from子句)之后给出。
查询 id 为 2 的 行(部分信息)
SELECT id,username,address,email FROM member WHERE id = 2;
注:同时使用 where 与 order by 时,where 子句需在前
1.where子句操作符
| 操作符 | 说明 |
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| BETWEEN | 在指定的两个值之间 |
2.between
查询 id 为 1-5之间的 行记录
SELECT * FROM member WHERE id BETWEEN 1 AND 5;
3.null
查询地址为空的记录
SELECT * FROM member WHERE address IS NULL;
注:null 与 不匹配问题:在过滤出 不具有特定值的行时,你可能希望返回具有 null 值的行。但是,不行。因为,null 代表未知,具有特殊含义。数据库不知道是否匹配,所以在匹配过滤或者 不匹配过滤时 不返回它们。
所以,在 过滤数据的时候,一定要验证 返回数据中 确实给出了 被过滤列具有 null 的行
2.组合 where 子句
mysql允许给出多个 where子句,但需要使用 and 子句 或 or 子句。
查询 id < 5 且 地址非空的记录。
SELECT * FROM member WHERE id < 5 AND address IS NOT NULL ;
注:where 子句可包含 任意数量的 and 和 or 操作符,允许两者结合进行复杂和高级的过滤。但需要注意的是 sql 会优先处理 and 操作符
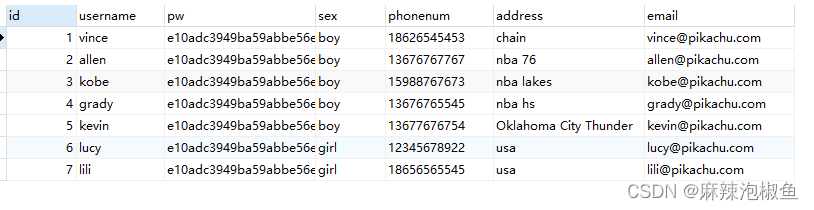
示例:
SELECT * FROM member WHERE address IS NOT NULL or sex IS NOT NULL AND id < 5; 执行时会表示 : 查询 (id<5 且 sex 非空 ) 或者 address 非空 的记录
为了看得更显眼,加一个括号进行对比
SELECT * FROM member WHERE (address IS NOT NULL or sex IS NOT NULL) AND id < 5; 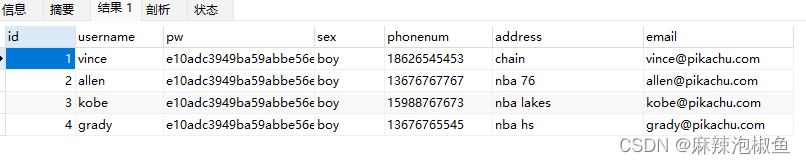
3.in
in 操作符用于指定条件范围,范围中每个条件都可以进行匹配。
查询 id 为 3 和 5 的记录,且按 username 排序
SELECT * FROM member WHERE id IN (3,5) ORDER BY username; 
Part 05 使用通配符过滤
1.like操作符
在搜索子句中使用通配符·,必须使用 like (技术上来说,like 是 谓词 而不是操作符,即便最终结果相同)
1.%
查询 username 以 ke 开头的 记录(%可以匹配 0个、1个、多个字符,除了不匹配 null)
SELECT * FROM member WHERE username LIKE 'ke%'; 
2.下划线(_)通配符
与 % 用途一样,但 下划线 只匹配单个字符 而不是 多个字符
SELECT * FROM member WHERE username LIKE '_r__y'; 
注:
- 优先使用操作符,尽量避免使用通配符(相对慢)
- 除非必要,不要把它们用在搜索模式的开始处,这样会很慢
- 通配符位置要准确,放错地方可能结果就错了
Part 06 使用正则表达式搜索
正则表达式用于匹配文本,将一个模式(正则表达式)与一个文本串进行比较。
Mysql 仅支持 多数正则表达式实现的一个很小的子集。
1.基本字符匹配
查询 username 列 包含 字符 a 的所有行,按 username 列排序
SELECT * FROM member WHERE username REGEXP 'a' ORDER BY username;  regexp 是可以通过 ^ 和 $ 定位符 实现与 like 相同的作用。
regexp 是可以通过 ^ 和 $ 定位符 实现与 like 相同的作用。
另外,mysql 的正则表达式匹配不区分大小写,如果你需要区分,可以使用 binary 关键字,如 where username regexp binary 'aBcD';
2.or匹配
为搜索两个串之一,使用 |
查询 username 包含 a 或 u 字符的记录,按 username排序
SELECT * FROM member WHERE username REGEXP 'a|u' ORDER BY username; 
3.匹配几个字符之一
匹配任何单一字符,但如果只想要匹配 特定字符,可以通过 指定一组用 [和] 括起来的字符完成
查询 username 包含 by 或 cy 或 dy 字符的记录 ,按 username排序
SELECT * FROM member WHERE username REGEXP '[bcd]y' ORDER BY username; 
[bcd] 表示匹配 b 或 c 或 d,等价于 [b|c|d]。
[^bcd] 表示 除了 b、c、d 之外的任何东西
4.匹配范围
[0123456789] 等价于 [0-9]
[a-z] 匹配任意字母字符
5.匹配特殊字符
必须使用 \\ 为前导。
\\- 表示查找 -
\\. 表示查找 .
\\ 也用来引用元字符(具有特殊含义的字符)
| 元字符 | 说明 |
|---|---|
| \\f | 换页 |
| \\n | 换行 |
| \\r | 回车 |
| \\t | 制表 |
| \\v | 纵向制表 |
匹配 \ ,需使用 \\\
多数正则表达式实现使用单个反斜杠转义特殊字符,但 mysql 要求两个反斜杠(mysql自己解释一个,正则表达式解释另一个)
6.匹配字符类
预定义的字符集
| 类 | 说明 |
|---|---|
| [:alnum:] | 任意字母和数字(同 [a-zA-Z0-9] ) |
| [:alpha:] | 任意字符(同 [a-zA-Z] ) |
| [:blank:] | 空格和制表(同 [\\t] ) |
| [:cntrl:] | ASCII控制字符(ASCII 0 到 31 和 127) |
| [:digit:] | 任意数字(同 [0-9]) |
| [:graph:] | 与 [:print:] 相同,但不包括空格 |
| [:lower:] | 任意小写字母(同 [a-z]) |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在 [:alnum:] 又不在 [:cntrl:] 中的任意字符 |
| [:space:] | 包括空格在内的任意空白字符(同 [\\f\\n\\r\\t\\v] ) |
| [:upper:] | 任意大写字母(同 [A-Z]) |
| [:xdigit:] | 任意十六进制数字(同 [a-fA-F0-9] ) |
7.匹配多个实例
这个需要重复元字符
| 元字符 | 说明 |
|---|---|
| * | 0个或多个匹配 |
| + | 1个或多个匹配(等于{1,}) |
| ? | 0个或1个匹配(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定书目的匹配 |
| {n,m} | 匹配数目的范围(m不超过255) |
示例:[0-9]{3} 表示 连在一起的三位数,[0-9]表示 任意数, {3}表示 三位(出现三次)
8.定位符
到目前为止都是匹配 一个串中任意位置的 文本。
为了匹配 特定位置的 文本,需要使用 定位符。
| 元字符 | 说明 |
|---|---|
| ^ | 文本的开始 |
| $ | 文本的结尾 |
| [[:<:]] | 词的开始 |
| [[:>:]] | [词的结尾 |
例如:[^0-9\\.] 表示 以一个数(包括以小数点开始的数)开始的 记录。^ 匹配串的开始。
这里应该注意到,前面 也使用 ^ 在集合中(用 [和] 定义)否定该集合;而这里,用来指串的开始处。这是 ^ 双重用途,前者优先。
利用 定位符,通过 ^ 开始每个表达式,用 $ 结束每个表达式,可以使 regexp 的作用与 like 一样。
Part 07 创建计算字段
1.concat() 拼接串
SELECT CONCAT(username,phonenum) FROM member ORDER BY username; 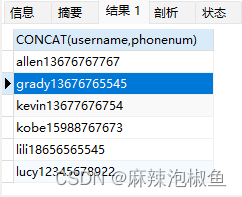
2.rtrim() 删除右侧多余空格
ltrim()删除左侧多余空格
3.as别名
SELECT CONCAT(RTRIM(id),RTRIM(address)) AS result FROM member ORDER BY username; 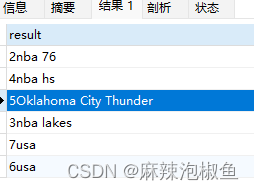
4.执行算数计算
| 操作符 | 说明 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
例如
SELECT 2*3 AS result;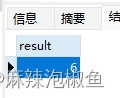
Part 08 使用数据处理函数
函数没有 sql 的可移植性强。
大多数都支持以下几种:
- 处理文本串(删除与填充,转换大小写等)的文本函数
- 数值数据进行算术操作(如绝对值,代数运算)的数值函数
- 处理日期和时间值并从中提取特定成分(如两个日期差,检查日期有效性等)的日期和时间函数
- 返回DBMS正使用的特殊信息(如用户登录信息,检查版本细节)的系统函数
1.文本处理函数
| 函数 | 说明 |
|---|---|
| left() | 返回串左边的字符 |
| right() | 返回串右边的字符 |
| length() | 返回串的长度 |
| locate() | 找出串的一个子串 |
| lower() | 将串转小写 |
| upper() | 将串转大写 |
| ltrim() | 去掉串左边的空格 |
| rtrim() | 去掉串右边的空格 |
| soundex() | 返回串的soundex值 |
| substring() | 返回子串的字符 |
soundex 是一个 将任何文本串 转换为 描述其语音表示的字母数字模式的算法。soundex 考虑了类似的发音字符和音节,使得能对串进行发音比较而不是字母比较。虽然 soundex 不是sql 概念,但 mysql 都提供 soundex 的支持。
2.日期和时间处理函数
| 函数 | 说明 |
|---|---|
| adddate() | 增加一个日期(天、周等) |
| addtime() | 增加一个时间(时、分等) |
| curdate() | 返回当前日期 |
| curtime() | 返回当前时间 |
| date() | 返回日期时间的日期部分 |
| datediff() | 计算两个日期之差 |
| data_add() | 高度灵活的日期运算函数 |
| data_format() | 返回一个格式化的日期或时间串 |
| day() | 返回一个日期的天数部分 |
| dayofweek() | 对于一个日期,返回对应的星期几 |
| hour() | 返回一个时间的小时部分 |
| minute() | 返回一个时间的分钟部分 |
| month() | 返回一个日期的月份部分 |
| now() | 返回当前日期和时间 |
| second() | 返回一个时间的秒部分 |
| time() | 返回一个日期时间的时间部分 |
| year() | 返回一个日期的年份部分 |
3.数值处理函数
| 函数 | 说明 |
|---|---|
| abs() | 返回一个数的绝对值 |
| cos() | 返回一个角度的余弦 |
| exp() | 返回一个数的指数值 |
| mod() | 返回除操作的余数 |
| pi() | 返回圆周率 |
| rand() | 返回一个随机数 |
| sin() | 返回一个角度的正弦 |
| sqrt() | 返回一个数的平凡根 |
| tan() | 返回一个角度的正切 |
Part 09 汇总数据
1.聚集函数
| 函数 | 说明 |
|---|---|
| avg() | 返回某列的平均值 |
| count() | 返回某列的行数 |
| max() | 返回某列的最大值 |
| min() | 返回某列的最小值 |
| sum() | 返回某列值之和 |
sum()函数忽略列值为 null 的行
【此处标题记录】
mysql 还支持一系列的 标准偏差聚集函数,后续收录。
2.聚集不同值
以上聚集函数都可以如下使用:
- 对所有的行执行计算,指定all参数或不给参数(all是默认行为)
- 只包含不同的值,指定 distinct 参数
注:若指定列名,则 distinct 只能用于 count()。distinct 不能用于 count(*),因此不允许使用 count(distinct),否则会产生错误。类似地,distinct 必须使用列名,不能用于 计算或表达式。
3.组合聚集函数
select 可根据需要包含多个聚集函数。
Part 10 分组数据(group by)
group by 必须在 where 之后,order by 之前。
注:
- group by可以包含任意数目的列
- 如果在group by子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换而言之,指定所有列一起计算(不能从个别列取回数据)
- group by子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在select 中使用表达式,则必须在 group by 字句中指定相同的表达式。不能使用别名
- 除聚集计算语句之外,select 语句中的每个列都必须在 group by 子句中给出
- 如果分组列中具有null 值,则 null 将作为 一个分组返回。如果列中有多行 null 值,它们将分为一组
使用 with rollup 关键字,可以得到每个分组以及每个分组汇总级别(针对每个分组)的值。
示例语句:select id,count(*) as nums from pro group by id with rollup;
过滤分组
where 过滤行,having子句过滤分组,having 支持 where 所有操作符
Part 11 使用子查询
在 select 语句中,子查询总是 从内向外处理。
嵌套子查询不要太多,否则会很慢。推荐创建计算字段使用子查询
Part 12 联结表
注意 外键 的概念
1.等值联接
SELECT username,email_id FROM users,emails WHERE users.id = emails.id ORDER BY users.username;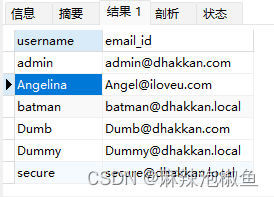
2.inner join... on ...
SELECT username,email_id FROM users INNER JOIN emails ON users.id = emails.id;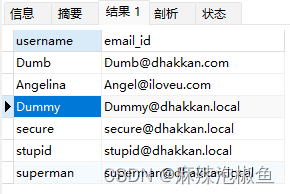
3.自联接
SELECT id,`password` FROM users WHERE id = (SELECT id FROM users WHERE username = 'admin');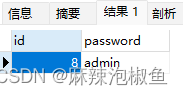
4.外联接
SELECT u.id,e.email_id FROM users as u RIGHT OUTER JOIN emails as e ON u.id = e.id; 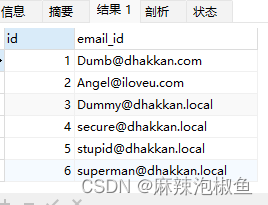
right outer join 表示从 outer join 右边的表中选择所有行。
Part 13 组合查询
执行多个查询,将结果作为单个结果集返回,这些组合查询通常称为并(union)或复合查询(compound query)
使用场景:
- 在单个查询中从不同的表返回类似结构的数据
- 对单个表执行多个查询,按单个查询返回数据
后续待补充优化……















 2191
2191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









