






 本文介绍了特征工程的基本步骤,包括特征提取、预处理、降维、选择和组合,以及如何解决anaconda安装中的问题。此外,详细讲解了KNN算法的工作原理、常见距离度量(如欧氏距离)、K值的选择及其在回归问题中的应用实例。
本文介绍了特征工程的基本步骤,包括特征提取、预处理、降维、选择和组合,以及如何解决anaconda安装中的问题。此外,详细讲解了KNN算法的工作原理、常见距离度量(如欧氏距离)、K值的选择及其在回归问题中的应用实例。
一、特征工程概念入门
特征工程、特征工程子领域
特征工程:利用专业背景知识和技巧处理数据,让机器学习算法效果最好。这个过程就是特征。
特征工程一般分为五步。
1、特征提取。2、特征预处理。3、特征降维。4、特征选择。5、特征组合。
特征提取:原始数据中提取与任务相关的特征,构成特征向量。例如: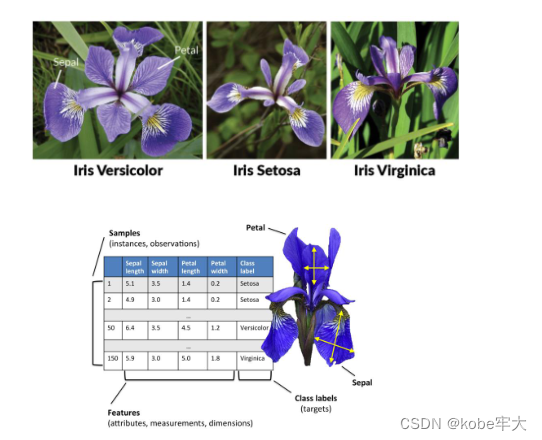
特征预处理:因量纲问题,有些对模型影响大,有些影响小。
类似简单的公式:f=ax+by+cz+dg
特征降维:将原始数据降维,一般会对原始数据产生影响。例如将3D变为2D。
特征选择:原始数据特征很多,与任务相关是其中一个特征集合子集,不会改变原数据。
特征组合:把多个的特征合并成一个特征。利用乘法或加法来完成。
二、anaconda安装
刚开始安装anaconda会遇到许多问题,例如安装python包一直报超时问题。

解决方法如下:
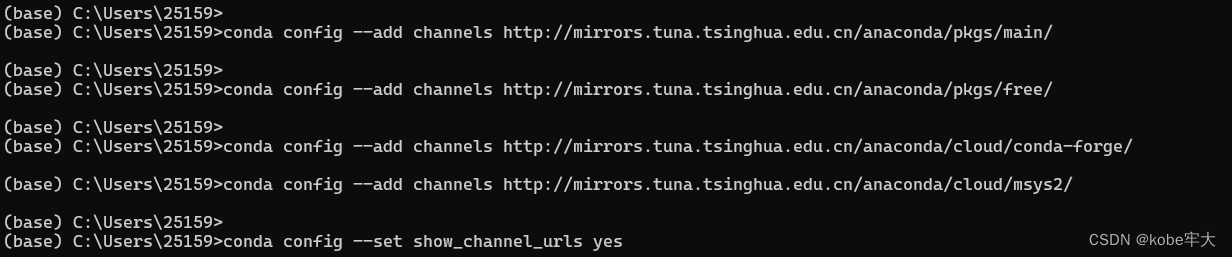
更换清华园的镜像,找到.contrac的文件,用记事本打开,删除-defults这一行。
这是就可以完美解决这个问题啦。
三、KNN算法
KNN算法思想:如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。
最常见的距离公式是:欧氏距离公式(距离差的平方和开根号)
核心思想:分类问题是离散的,回归问题是连续的。
关于K值:
K值过小:过拟合
K值过大:欠拟合
交叉:网格搜索
KNN解决什么问题?
1)KNN:K Nearest Neighbor。
即解决的是寻找与未知样本 __最进邻_____ 的K个样本,并对未知样本所属的分类或者属性进行预测的问题。
2)距离度量:
空间中两个样本的距离通过 __欧氏距离_______ 来度量的。
KNN中k=5是什么意思?(被老师提问了)
答:在K最近邻(KNN)算法中,参数"k=5"表示在进行分类或回归时,算法会考虑与待分类/回归样本最接近的5个邻居。具体来说,对于分类任务,KNN算法会查找在特征空间中与待分类样本最接近的5个训练样本,并通过投票或其他方法来确定待分类样本的类别。对于回归任务,KNN算法会查找与待回归样本最接近的5个训练样本,并根据它们的值来预测待回归样本的值。
KNN算法API使用 - 回归问题
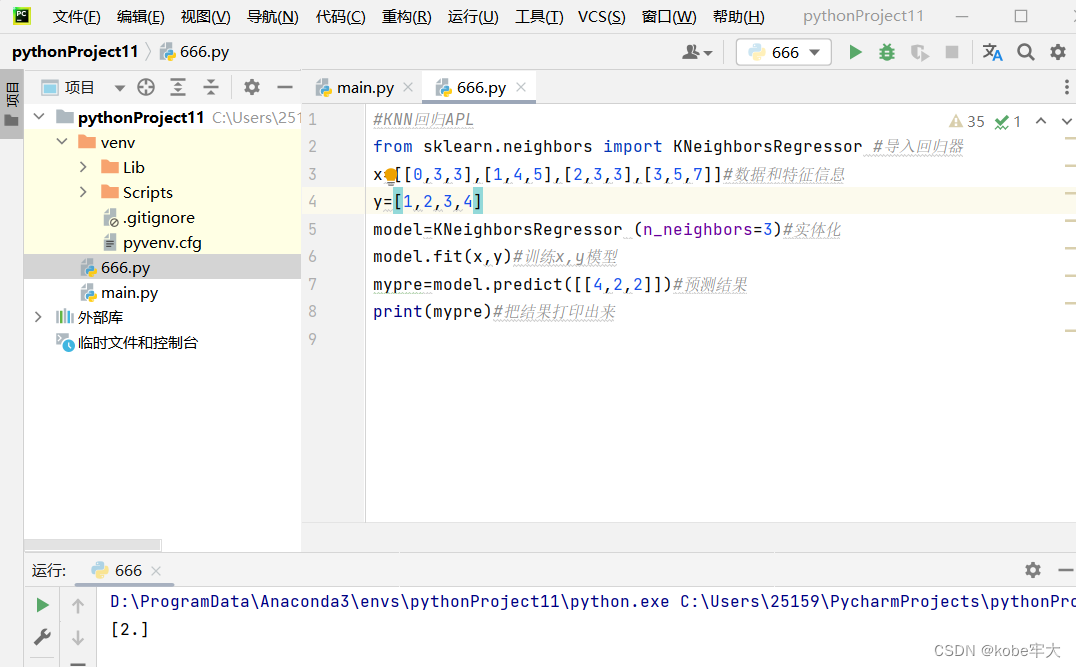
from sklearn.neighbors import KNeighborsRegressor ##(导入Scikit-learn库中的K最近邻回归器。)
def dm02_knnapi_回归():##(定义一个回归函数)
estimator = KNeighborsRegressor(n_neighbors=2)##(用最近的2个邻居进行预测)
X = [[0, 0, 1], [1, 1, 0], [3, 10, 10], [4, 11, 12]]##(四个样本,每组样本有三个特征信息)
y = [0.1, 0.2, 0.3, 0.4] ##(回归的目标值)
estimator.fit(X, y)
myret = estimator.predict([[3, 11, 10]]) ##(使用训练好的模型对新的特征值 [[3, 11, 10]] 进行回归预测,得到预测结果存储在 myret 变量中。)
print('myret-->', myret) ##最后得出结果
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









