







一、引言
论文地址: arXiv: https://arxiv.org/abs/2103.10360
官网:https://chatglm.cn/blog
Github:https://github.com/THUDM/ChatGLM-6B
在日益增多的开源大模型中,由清华大学研发的开源大模型 GLM 由于效果出众而受到大众关注,而且清华大学开源了基于 GLM 架构研发的基座模型:ChatGLM-6B以及GLM-130B。
2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测2,GLM-130B 是亚洲唯一入选的大模型。在与 OpenAI、谷歌大脑、微软、英伟达、脸书的各大模型对比中,评测报告显示 GLM-130B 在准确性和恶意性指标上与 GPT-3 175B (davinci) 接近或持平,鲁棒性和校准误差在所有千亿规模的基座大模型(作为公平对比,只对比无指令提示微调模型)中表现不错。
GLM-130B可能是当前开源ChatGPT复现中中文效果最好的基础模型。
本文就GLM的基础构架和预训练方式,深入浅出地分析GLM为何实现如此出众的效果。
Note: 为控制篇幅,本文仅介绍GLM的基础构架和预训练; GLM-130B和ChatGLM的升级等会在part2再介绍
二、背景
2.1 主流NLP任务
NLP 任务通常分为三类:
- **自然语言理解(NLU):**这类任务主要关注从给定文本中提取信息和理解其含义(例如:文本分类、情感分析、分词、句法分析、信息抽取等)
- **有条件生成任务(Cond.Gen.):**这类任务根据给定的输入或上下文生成文本,属于序列到序列的任务(例如:翻译任务、问答系统等)
- **无条件生成任务:**用预训练模型直接生成内容,这类任务关注从头开始生成文本,而不需要特定的输入条件
这些分类有助于更好地了解 NLP 任务的目标和方法。但随着研究的深入和新技术的发展,任务之间的界限变得模糊。例如,预训练语言模型(如 GPT3.5)已经证明可以在多种 NLP 任务中实现高性能,包括自然语言理解和生成任务。
2.2 主流预训练模型
预训练模型根据架构,也分为三类,分别是:自编码 (auto-encoding)、编码解码 (encoder-decoder)、自回归 (auto-regressive)。三种训练模型分别对应前面三种任务,具体如下图:
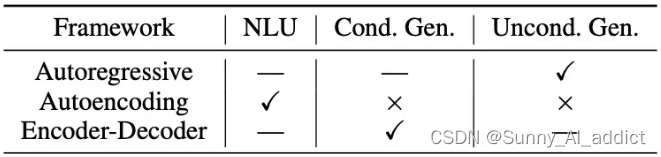
- 自编码 (auto-encoding):
通过去噪目标(即通过覆盖句中的单词,或者对句子做结构调整,让模型复原单词和词序,从而调节网络参数)学习双向上下文的编码器,例如掩码语言模型 (MLM) 。自编码模型擅长自然语言理解NLU任务,常用于生成句子的上下文表示,但是不能直接用于文本生成。
代表模型如BERT、RoBERTa、ALBERT
- 自回归 (auto-regressive):
从左往右学习的模型,根据句子中前面的单词,预测下一个单词。例如,通过“LM is a typical task in natural language ____”预测单词“processing”。
在长文本的生成能力很强,缺点就是单向的注意力机制在 NLU 任务中,不能完全捕捉 token 的内在联系。
代表模型如:GPT系列、GPT-2、GPT-3
编码解码 (encoder-decoder):
编码器使用双向注意力,解码器使用单向注意力,并且有交叉注意力连接两者,在有条件生成任务(seq-seq)中表现良好,比如生成摘要、生成式问答、机器翻译
代表模型MASS、BART、PALM
三种预训练框架各有利弊,没有一种框架在以下三种领域的表现最佳:自然语言理解(NLU)、无条件生成以及条件生成。
以前的工作尝试通过多任务学习(Dong 等人,2019;Bao 等人,2020;例如T5)结合它们的目标来统一不同的框架。然而,由于自编码和自回归目标在本质上是不同的,简单的统一不能充分继承两个框架的优势。
三、GLM预训练框架
基于以上的原因,清华研究团队提出了一种基于“自回归空白填充”的预训练框架,名为 GLM(通用语言模型)。
GLM可以通过改变空格的数量和长度来对不同类型的任务进行预训练,结合了自编码和自回归预训练的优点。在NLU、条件生成和无条件生成的广泛任务中,在相同模型大小和数据的情况下,GLM优于BERT、T5和GPT。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









