







学习机器学习的过程之中,记录自己的学习笔记;
也希望有大佬纠正不对的地方,自己也会不断学习。
代价函数
什么是代价函数
代价函数,通常也被称为损失函数或成本函数,在机器学习和统计学中发挥着核心作用,它定义了模型预测值与实际值之间的差异,这种差异通常以数学公式表示,用于衡量模型的好坏。
代价函数是针对整个训练集定义的,它计算了所有样本误差的平均值,这与损失函数不同,后者是定义在单个样本上的,计算的是单个样本的误差。在机器学习模型训练过程中,目标是优化或最小化代价函数,通过这种方法,模型学习如何最好地拟合数据,代价函数不仅包括用于评估模型性能的经验风险,还可能包括一个正则化项,以防止过拟合并优化结构风险。
以下是一些常见的代价函数公式:
- 均方误差(Mean Squared Error, MSE):
常用于回归问题。公式为:
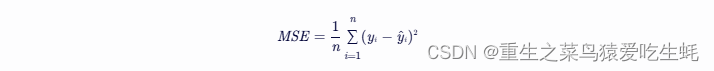
其中,yi 是实际值,y^i 是模型预测值,n 是样本数量。
- 交叉熵损失(Cross-Entropy Loss):
常用于分类问题,特别是在神经网络中。对于二分类问题,其公式为:

其中,yi 是实际标签(0或1),y^i 是模型预测的概率值,n 是样本数量。
讲解代价函数
其实个人通过b站学习的时候,感受到的十分明显的知识是线性代数和高数为依赖的,进行的学习,所以如果这部分非常薄弱的话,可能需要自己去补充一下自己的知识量。不过也不用太担心,讲解的比较入门,只需要对于基础的一些概念有认识。
下面给到大家一个样例去看看线性回归模型,以及代价函数。主要也是讲解过程之中一个例子。利于大家观看去理解。
从中截取的图片可能有些难以理解,但其实数据主要是来源于个人的一些编辑,然后做出线性回归函数,可能有些不太严谨,但主要的目的是通过这个样例,来向大家讲解。

房子的大小与售价之间的图像反应
该样例主要运用的是均分误差公式

图片来源于up主啥都会一点的研究生 视频
代价函数的作用
- 评估模型性能:通过计算代价函数的值,我们可以量化模型在训练数据上的表现。一个较小的代价函数值通常意味着模型能够更准确地预测数据。
- 指导参数调整:在机器学习的训练过程中,我们的目标是找到一组参数(\theta),使得代价函数(J(\theta))的值最小。这通常通过优化算法(如梯度下降法)来实现,该算法会不断地调整参数以减小代价函数的值。
- 防止过拟合与欠拟合:通过选择合适的代价函数和正则化项,我们可以在一定程度上防止模型过拟合或欠拟合训练数据。例如,在代价函数中加入正则化项可以帮助控制模型的复杂度,从而避免过拟合。
为什么梯度学习能优化算法
-
方向性优化:梯度表示函数在某一点的最陡上升或下降方向。在优化代价函数时,我们希望找到使代价函数值最小的参数。通过计算代价函数关于参数的梯度,我们可以确定在哪个方向上调整参数能够最快地减小代价函数的值。梯度下降法正是利用这一点,沿着梯度的反方向(即代价函数下降最快的方向)更新参数。
-
迭代逼近:梯度下降法通过迭代的方式逐步逼近最优解。在每一步迭代中,它都会根据当前的梯度信息来更新参数,使代价函数的值逐渐减小。通过多次迭代,算法可以逐渐收敛到代价函数的最小值点(或局部最小值点)。
-
自适应性:梯度下降法可以根据当前的梯度大小自动调整参数更新的步长。在梯度较大的地方,步长会相对较大,以便快速接近最优解;而在梯度较小的地方,步长会相对较小,以避免在最优解附近产生过大的震荡。这种自适应性使得梯度下降法能够高效地搜索最优解。
-
通用性:梯度下降法是一种通用的优化方法,可以应用于各种不同的代价函数和模型。只要能够计算出代价函数关于参数的梯度,就可以使用梯度下降法进行优化。这种通用性使得梯度下降法在机器学习领域具有广泛的应用。
-
计算效率:相比于其他优化方法,梯度下降法通常具有较高的计算效率。它只需要计算一阶导数(即梯度),而不需要计算更高阶的导数,从而降低了计算的复杂度。此外,梯度下降法还可以与其他技术(如动量法、Adam等)结合使用,以进一步提高优化效率和稳定性。
本次学习就到这里,后续也会补充对于优化的一个梯度下降法的学习。















 910
910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









