






 文章介绍了二叉树的层序遍历、自底向上层序遍历以及右视图的实现方法,同时展示了如何使用SQL中的窗口函数分析餐馆营业额的增长趋势。
文章介绍了二叉树的层序遍历、自底向上层序遍历以及右视图的实现方法,同时展示了如何使用SQL中的窗口函数分析餐馆营业额的增长趋势。
1二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:
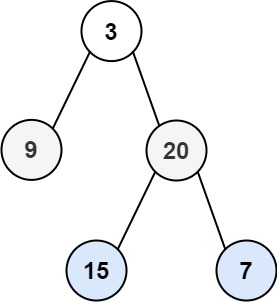
输入:root = [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]]
示例 2:
输入:root = [1] 输出:[[1]]
示例 3:
输入:root = [] 输出:[]
提示:
- 树中节点数目在范围
[0, 2000]内 -1000 <= Node.val <= 1000
思路:
解题思路是使用队列来辅助进行层序遍历,首先将根节点加入队列中,然后循环遍历队列,每次处理当前层的节点,并将它们的值存储在一个vector中。在处理当前层节点时,需要使用固定大小的size来遍历当前层的所有节点,而不是直接使用que.size(),因为que.size()会不断变化。对于每个节点,将其值加入当前层的vector中,然后将其左右子节点(如果存在)加入队列中。最后将当前层的节点值vector存储在结果vector中,并继续处理下一层节点,直到队列为空。最终返回整个层序遍历的结果。
代码:
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> que; // 创建一个队列用于层序遍历
if (root != NULL) que.push(root); // 如果根节点不为空,则将根节点加入队列
vector<vector<int>> result; // 用于存储层序遍历的结果
while (!que.empty()) { // 当队列不为空时循环
int size = que.size(); // 获取当前层的节点个数
vector<int> vec; // 用于存储当前层的节点值
// 使用固定大小size,不要使用que.size(),因为que.size是不断变化的
for (int i = 0; i < size; i++) {
TreeNode* node = que.front(); // 获取队列首节点
que.pop(); // 弹出队首节点
vec.push_back(node->val); // 将节点值加入当前层的vector中
if (node->left) que.push(node->left); // 如果该节点有左子节点,则加入队列
if (node->right) que.push(node->right); // 如果该节点有右子节点,则加入队列
}
result.push_back(vec); // 将当前层的节点值vector加入结果vector中
}
return result; // 返回层序遍历结果
}
};2二叉树的层序遍历 II
给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
示例 1:
输入:root = [3,9,20,null,null,15,7] 输出:[[15,7],[9,20],[3]]
示例 2:
输入:root = [1] 输出:[[1]]
示例 3:
输入:root = [] 输出:[]
提示:
- 树中节点数目在范围
[0, 2000]内 -1000 <= Node.val <= 1000
思路:
实现从底向上对二叉树进行层次遍历。首先创建一个队列,将根节点加入队列。然后进入循环,每次循环处理一层节点。在循环中,先获取当前层的节点数量,然后遍历当前层的所有节点,将它们的值存储在一个vector中。对于每个节点,将其值加入当前层的vector中,并将其左右子节点(如果存在)加入队列中。处理完当前层所有节点后,将存储当前层节点值的vector加入结果vector中。最后将整个结果vector进行反转,即可得到从底向上的层次遍历结果。这样可以实现从树的底部往上按层次输出节点值的功能。
代码:
class Solution {
public:
vector<vector<int>> levelOrderBottom(TreeNode* root) {
queue<TreeNode*> que; // 创建一个队列用于层序遍历
if (root != NULL) que.push(root); // 如果根节点不为空,则将根节点加入队列
vector<vector<int>> result; // 用于存储层序遍历的结果
while (!que.empty()) { // 当队列不为空时循环
int size = que.size(); // 获取当前层的节点个数
vector<int> vec; // 用于存储当前层的节点值
// 使用固定大小size,不要使用que.size(),因为que.size是不断变化的
for (int i = 0; i < size; i++) {
TreeNode* node = que.front(); // 获取队列首节点
que.pop(); // 弹出队首节点
vec.push_back(node->val); // 将节点值加入当前层的vector中
if (node->left) que.push(node->left); // 如果该节点有左子节点,则加入队列
if (node->right) que.push(node->right); // 如果该节点有右子节点,则加入队列
}
result.push_back(vec); // 将当前层的节点值vector加入结果vector中
}
reverse(result.begin(), result.end()); // 反转结果vector
return result; // 返回层序遍历的结果(自底向上)
}
};给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例 1:
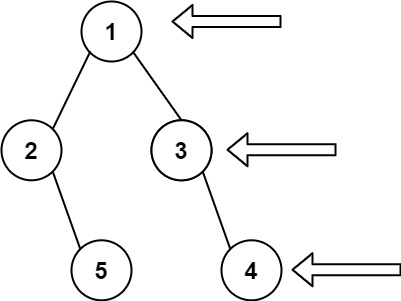
输入: [1,2,3,null,5,null,4] 输出: [1,3,4]
示例 2:
输入: [1,null,3] 输出: [1,3]
示例 3:
输入: [] 输出: []
提示:
- 二叉树的节点个数的范围是
[0,100] -100 <= Node.val <= 100
思路:获取二叉树的右视图节点值。其思路是通过层次遍历的方式,每次将每层的最后一个节点的值存储在结果数组中,即右视图的节点值。具体步骤是创建一个队列,将根节点加入队列,然后循环遍历队列,每次处理当前层的节点,将该层最后一个节点的值存储在结果数组中。在处理当前层节点时,将其左右子节点加入队列。最终返回存储右视图节点值的结果数组。
代码:
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
queue<TreeNode*> que; // 创建一个队列用于辅助层次遍历
if (root != NULL) que.push(root); // 将根节点加入队列
vector<int> result; // 用于存储右视图结果的数组
while (!que.empty()) { // 遍历队列直到为空
int size = que.size(); // 获取当前层节点的数量
for (int i = 0; i < size; i++) {
TreeNode* node = que.front(); // 获取队列首节点
que.pop(); // 弹出队列首节点
if (i == (size - 1)) result.push_back(node->val); // 将每一层的最后元素放入result数组中,即右视图的节点值
if (node->left) que.push(node->left); // 将左子节点加入队列
if (node->right) que.push(node->right); // 将右子节点加入队列
}
}
return result; // 返回右视图结果数组
}
};4. 餐馆营业额变化增长
表: Customer
+---------------+---------+ | Column Name | Type | +---------------+---------+ | customer_id | int | | name | varchar | | visited_on | date | | amount | int | +---------------+---------+ 在 SQL 中,(customer_id, visited_on) 是该表的主键。 该表包含一家餐馆的顾客交易数据。 visited_on 表示 (customer_id) 的顾客在 visited_on 那天访问了餐馆。 amount 是一个顾客某一天的消费总额。
你是餐馆的老板,现在你想分析一下可能的营业额变化增长(每天至少有一位顾客)。
计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。average_amount 要 保留两位小数。
结果按 visited_on 升序排序。
返回结果格式的例子如下。
示例 1:
输入: Customer 表: +-------------+--------------+--------------+-------------+ | customer_id | name | visited_on | amount | +-------------+--------------+--------------+-------------+ | 1 | Jhon | 2019-01-01 | 100 | | 2 | Daniel | 2019-01-02 | 110 | | 3 | Jade | 2019-01-03 | 120 | | 4 | Khaled | 2019-01-04 | 130 | | 5 | Winston | 2019-01-05 | 110 | | 6 | Elvis | 2019-01-06 | 140 | | 7 | Anna | 2019-01-07 | 150 | | 8 | Maria | 2019-01-08 | 80 | | 9 | Jaze | 2019-01-09 | 110 | | 1 | Jhon | 2019-01-10 | 130 | | 3 | Jade | 2019-01-10 | 150 | +-------------+--------------+--------------+-------------+ 输出: +--------------+--------------+----------------+ | visited_on | amount | average_amount | +--------------+--------------+----------------+ | 2019-01-07 | 860 | 122.86 | | 2019-01-08 | 840 | 120 | | 2019-01-09 | 840 | 120 | | 2019-01-10 | 1000 | 142.86 | +--------------+--------------+----------------+ 解释: 第一个七天消费平均值从 2019-01-01 到 2019-01-07 是restaurant-growth/restaurant-growth/ (100 + 110 + 120 + 130 + 110 + 140 + 150)/7 = 122.86 第二个七天消费平均值从 2019-01-02 到 2019-01-08 是 (110 + 120 + 130 + 110 + 140 + 150 + 80)/7 = 120 第三个七天消费平均值从 2019-01-03 到 2019-01-09 是 (120 + 130 + 110 + 140 + 150 + 80 + 110)/7 = 120 第四个七天消费平均值从 2019-01-04 到 2019-01-10 是 (130 + 110 + 140 + 150 + 80 + 110 + 130 + 150)/7 = 142.86
思路:
解题思路是计算每个日期前6天内的总金额,并计算出平均金额。具体步骤如下:
- 首先从
customer表中选取不同的访问日期visited_on,并在子查询中计算每个日期前6天内的总金额,使用窗口函数sum(amount) over (order by visited_on range interval 6 day preceding)来实现。 - 在外部查询中,筛选出符合条件的日期(从第7天开始),即使用
where datediff(visited_on, (select min(visited_on) from customer)) >= 6。 - 最终在SELECT语句中显示选择的访问日期、总金额和平均金额(总金额除以7天)
窗口函数是一种高级SQL操作,通常用于在结果集中执行聚合、排序或分析操作,而不会改变原始查询结果的行数。在这个例子中,窗口函数sum(amount) over (order by visited_on range interval 6 day preceding)被用来计算每个日期前6天内的总金额。窗口函数的关键部分是over()子句,其中可以指定窗口的排序规则以及参考范围,比如在这里按照visited_on字段排序,并且取前6天的数据进行计算
语法:
[你要的操作] OVER ( PARTITION BY <用于分组的列名> ORDER BY <按序叠加的列名> ROWS|RANGE <窗口滑动的数据范围> )
<窗口滑动的数据范围> 用来限定 [你要的操作] 所运用的数据的范围,具体有如下这些:
当前 - current row
之前的 - preceding
之后的 - following
无界限 - unbounded
表示从前面的起点 - unbounded preceding
表示到后面的终点 - unbounded following
代码:
select distinct visited_on, -- 选择不同的访问日期
sum_amount as amount, -- 总金额
round(sum_amount/7, 2) as average_amount -- 平均金额(总金额除以7)
from (
select visited_on, sum(amount) over ( order by visited_on range interval 6 day preceding ) as sum_amount -- 计算每个日期前6天内的总金额
from customer) t
-- 最后手动地从第7天开始
where datediff(visited_on, (select min(visited_on) from customer)) >= 6 -- 筛选满足条件的日期(从第7天开始)














 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









