






前言:配置一个主节点两个从节点实现hadoop
一、准备
1、VMware Workstation (我使用的是pro17版本)
2、镜像文件(我使用的是CentOS7)
3、远程登陆虚拟机软件(我使用的是Xshell 8)
4、文件传输软件(我使用的是Xftp 8)
5、jdk安装包
6、hadoop安装包
二、创建虚拟机
以管理员身份运行VM,主页创建新的虚拟机
下一步
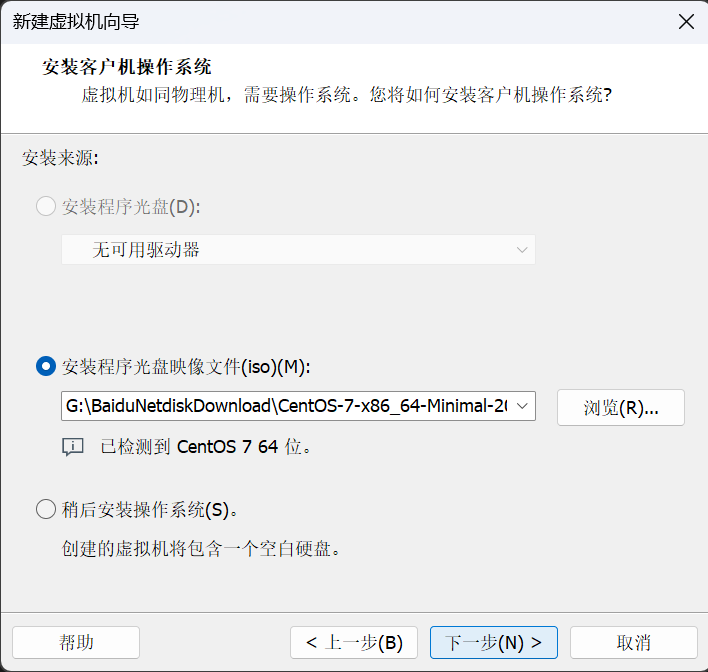
找到准备好的CentOS7镜像文件,下一步
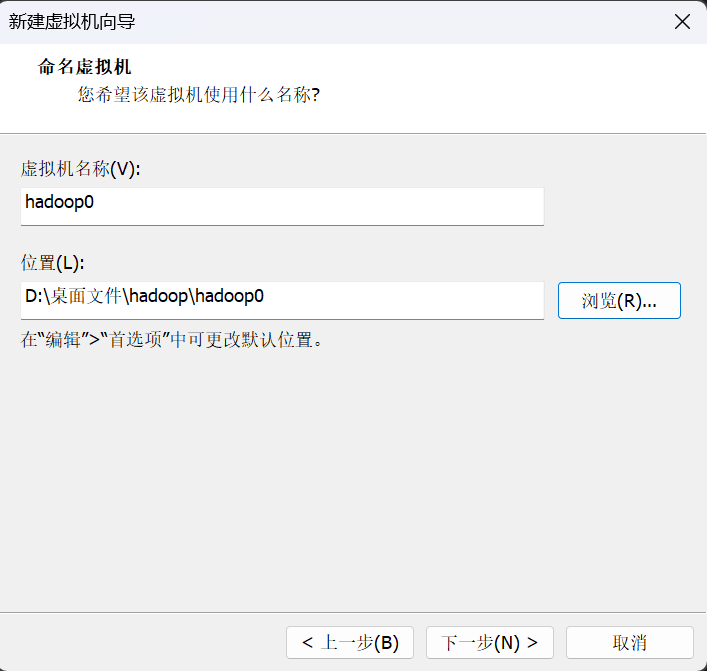
设置虚拟机名称以及保存路径,下一步
下一步
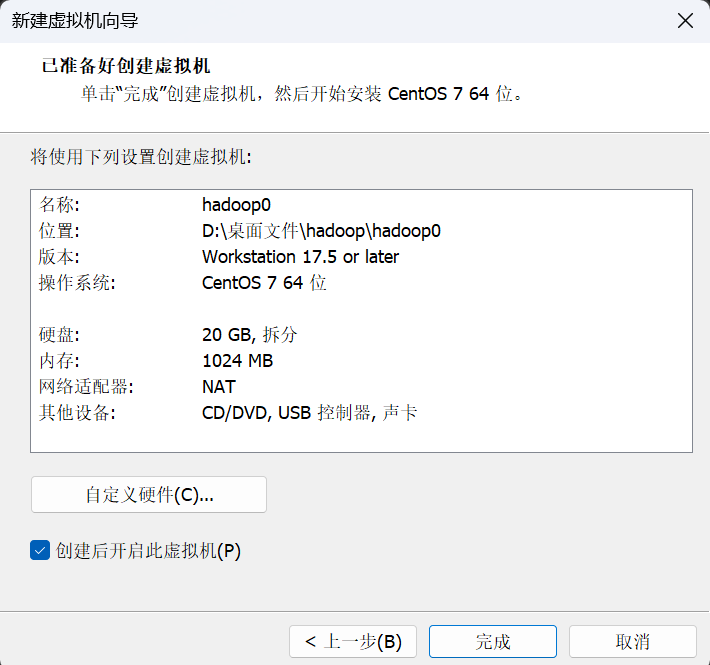
自定义硬件
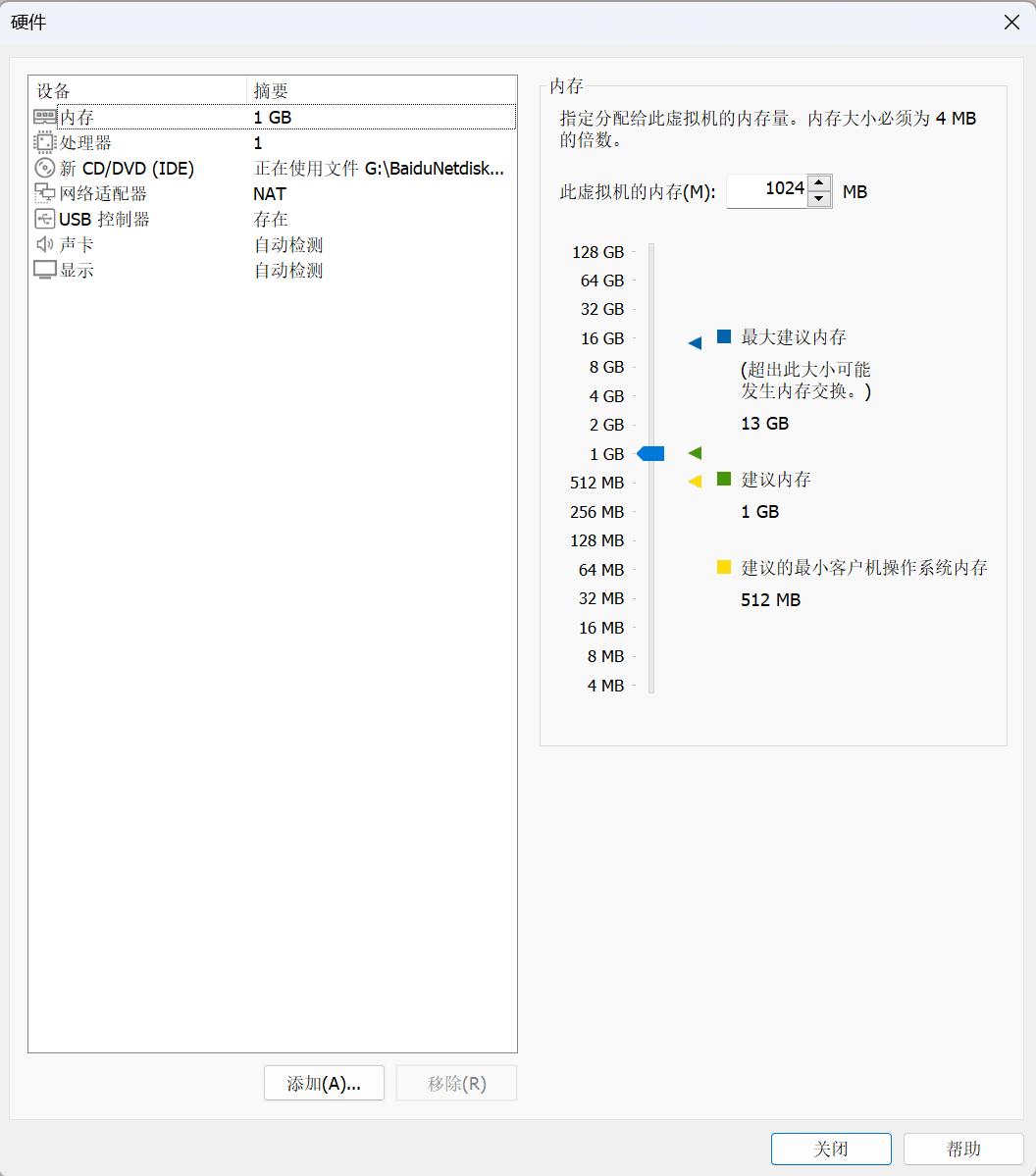
网络适配器,选择桥接模式
移除USB控制器、声卡(有些版本还会出现打印机也要删除)
设置好后,点击关闭
点击完成
启动虚拟机

选择中文简体或English
点继续
向下滑动
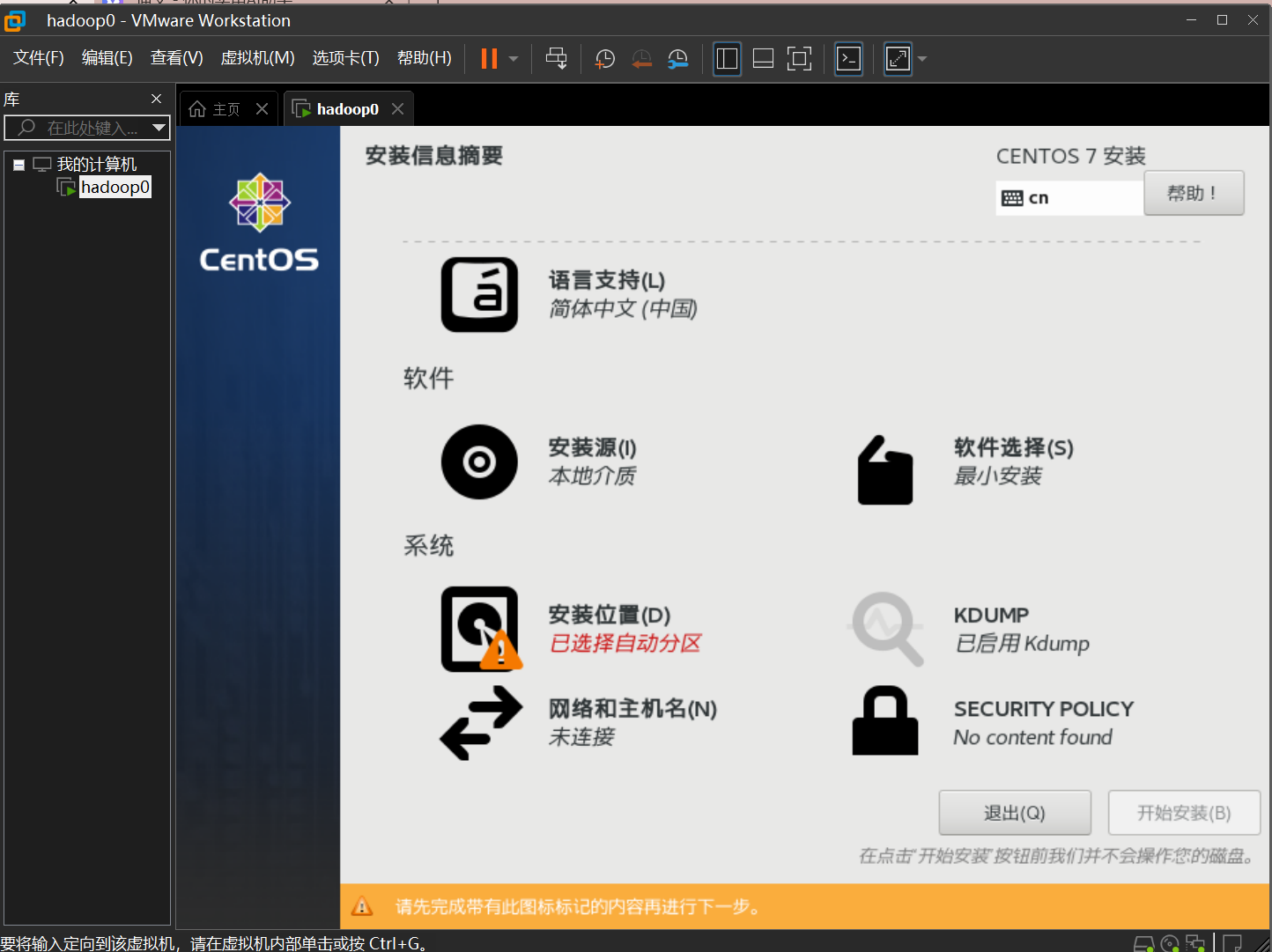
设置安装位置
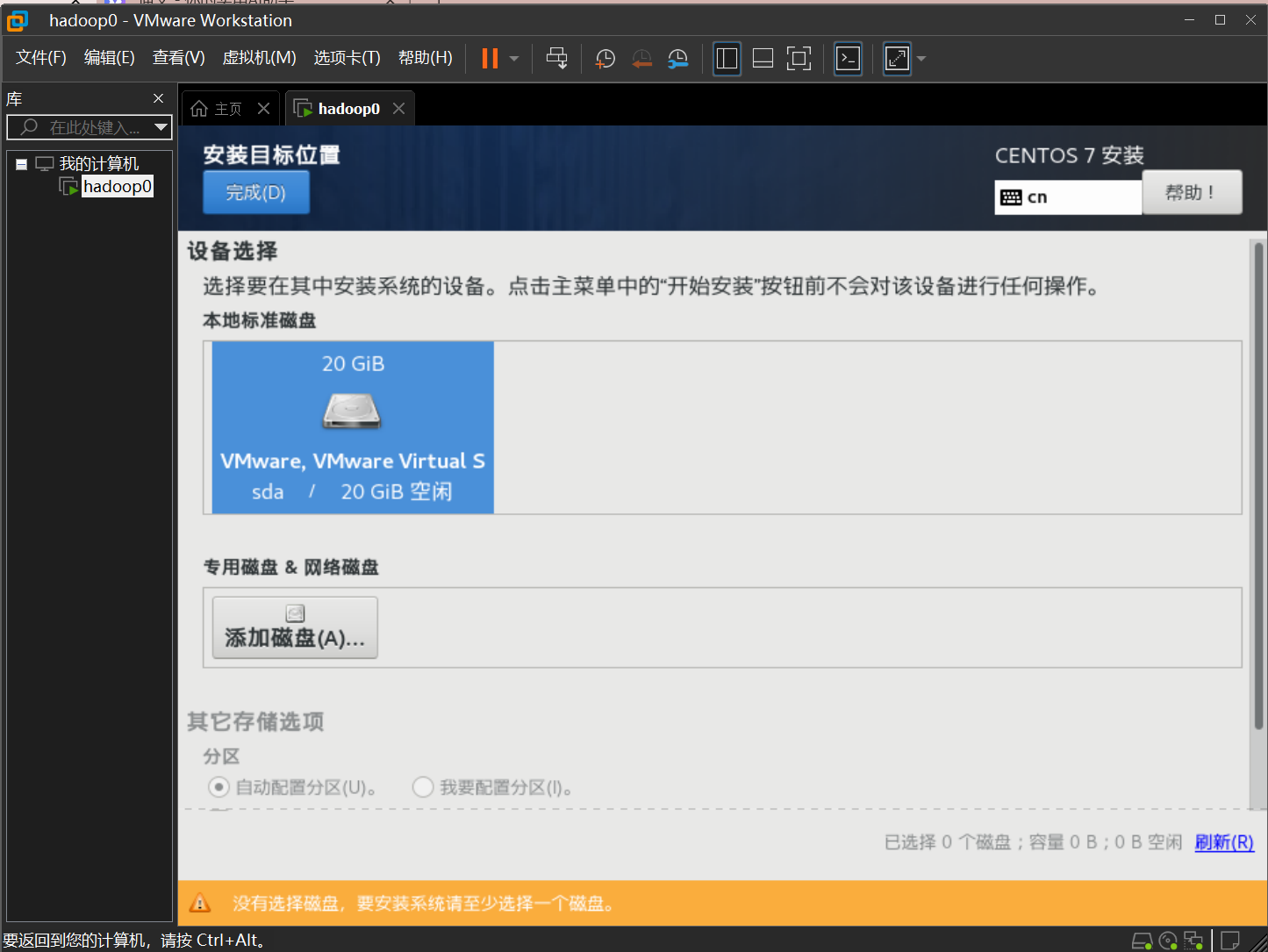
单击空闲磁盘,点击完成
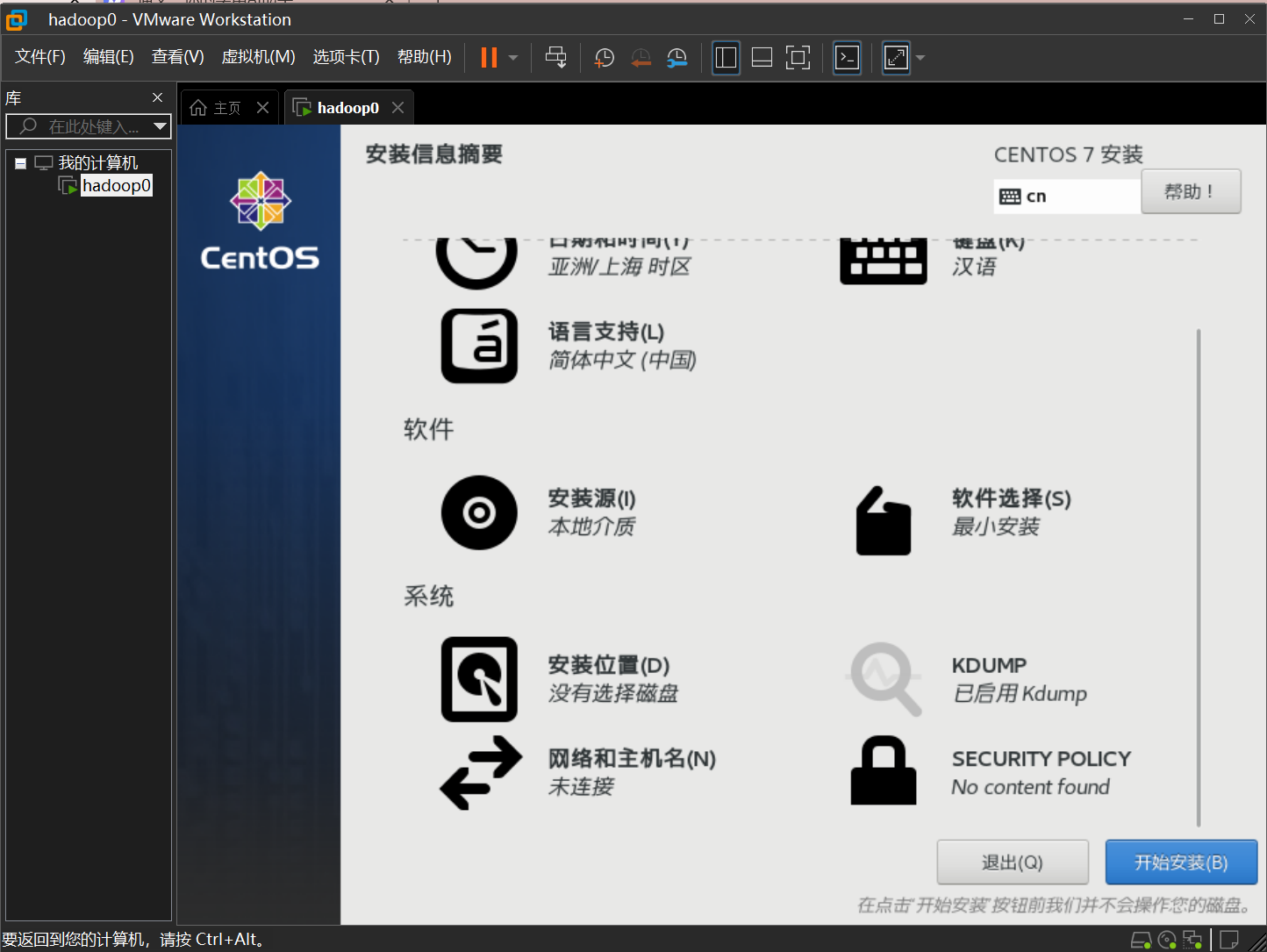
点击开始安装
设置root密码
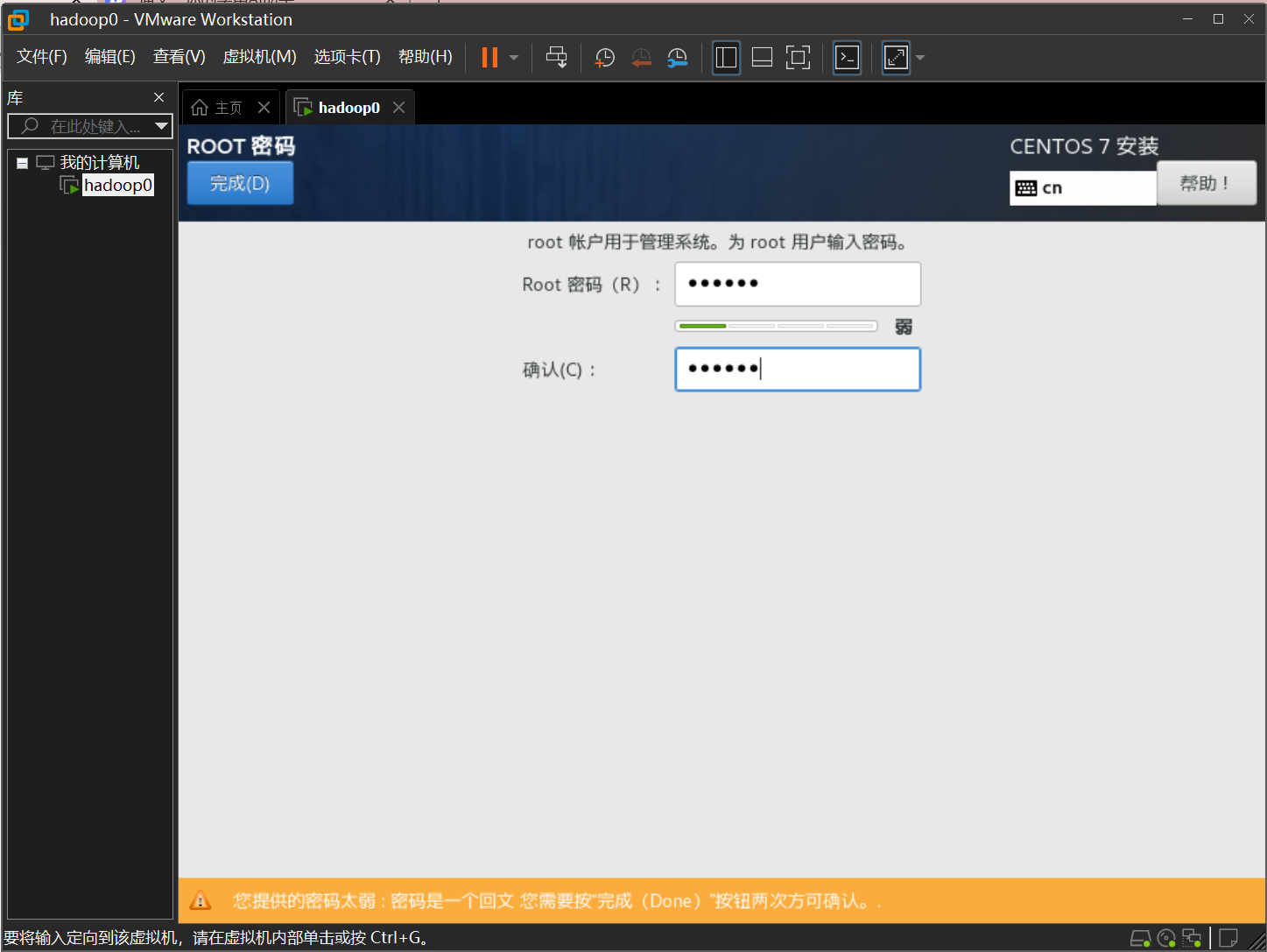
根据提示点击两次完成
等待安装成功,提示重启
点击重启
输入root回车
输入设置的密码(注意密码不会显示出来)
成功登陆
三、配置虚拟机
(1)网络配置
①键盘Win+R 输入cmd 回车打开命令行
(注意鼠标要移动到Windows窗口)
输入:
ipconfig找到:
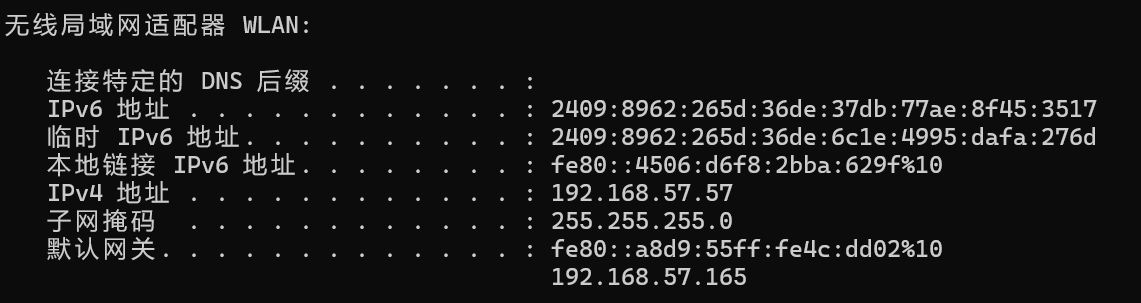
(注意:每个地址都不同,一定要查看自己电脑的地址,并且对于WLAN每次重新联网都有可能发生改变)
类似于以下格式:
192.168.xxx.xxx
要找一个没有主机使用的ip地址
以我现在的IPv4地址:192.168.57.xxx为例
输入:
ping 192.168.57.100
若显示:

则说明该地址:192.168.57.100 没有主机在使用
可以把该地址作为虚拟机hadoop0的IP地址
②更改虚拟机网络文件
(回到虚拟机窗口)
输入
cd /etc/sysconfig/network-scriptsls显示

这个ifcfg-ens32就是需要更改的文件
输入:
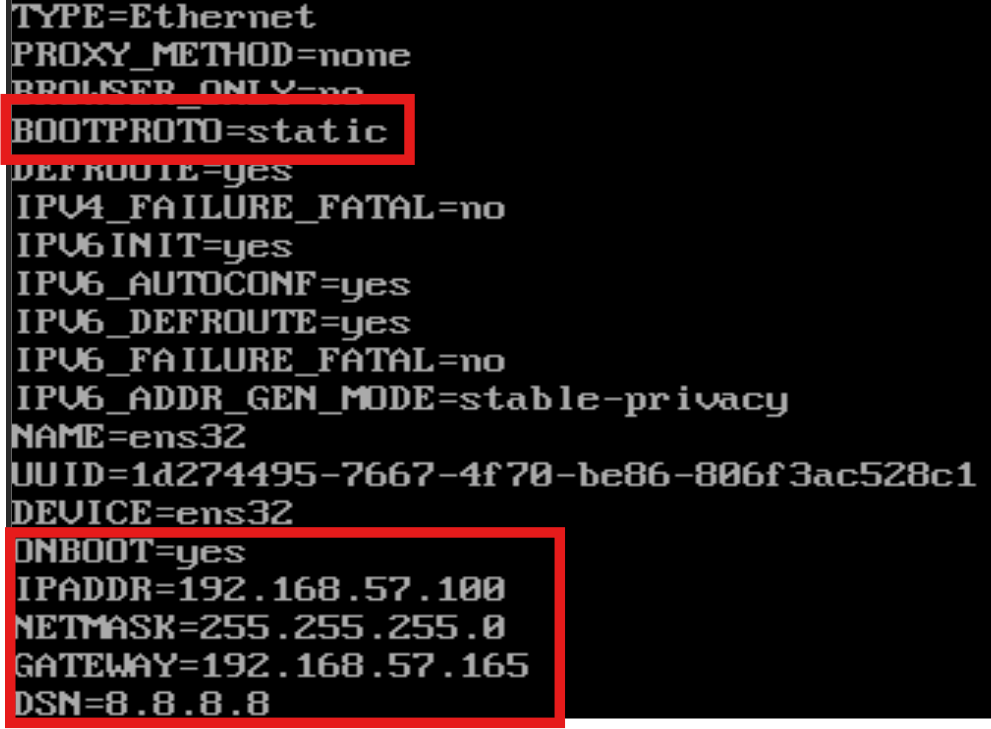
vi ifcfg-ens32更改以及添加:
BOOTPROTO=static
ONBOOT=yes
IPADDR=(虚拟机IP地址)
NETMASK=(主机子网掩码)
GATEWAY=(主机默认网关)
DSN=8.8.8.8
如图:
(注意:进入文件后,需要点i进入输入模式,保存退出需要先点ESC 输入:wq回车,不保存退出需要点击ESC输入q!回车)
③重启网络服务
输入
service network restart显示

输入:
ping www.baidu.com测试网络连接是否成功
若显示:

则成功
也可以在windows命令行中 执行
ping 192.168.57.100结果显示:
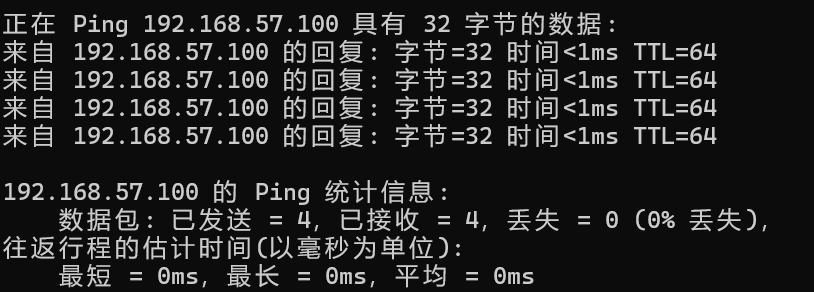
也说明网络连接成功
(2)/etc/hostname
在虚拟机命令行中执行
vi /etc/hostname更改主机名,重启发现
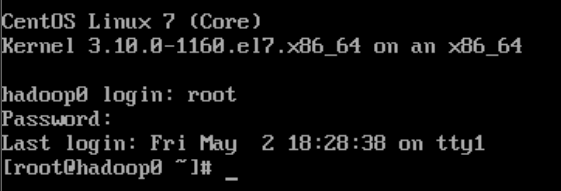
主机名改变
(3)关闭防火墙
通过两条命令关闭防火墙
systemctl stop firewalld
systemctl disable firewalld显示:
(4)关闭SELINUX
输入:
cd /etc/selinuxls找到config文件
vi config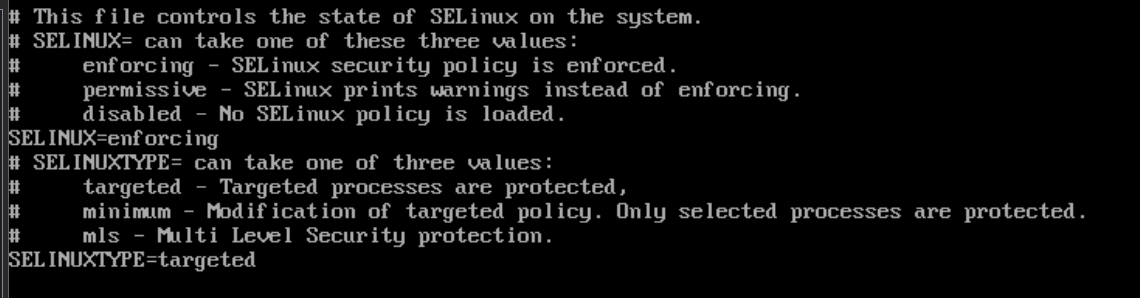
把SELINUX=enforcing更改为SELINUX=disabled,保存退出
关闭虚拟机
(5)克隆虚拟机
右键hadoop0,选择管理,选择克隆
下一页
下一页
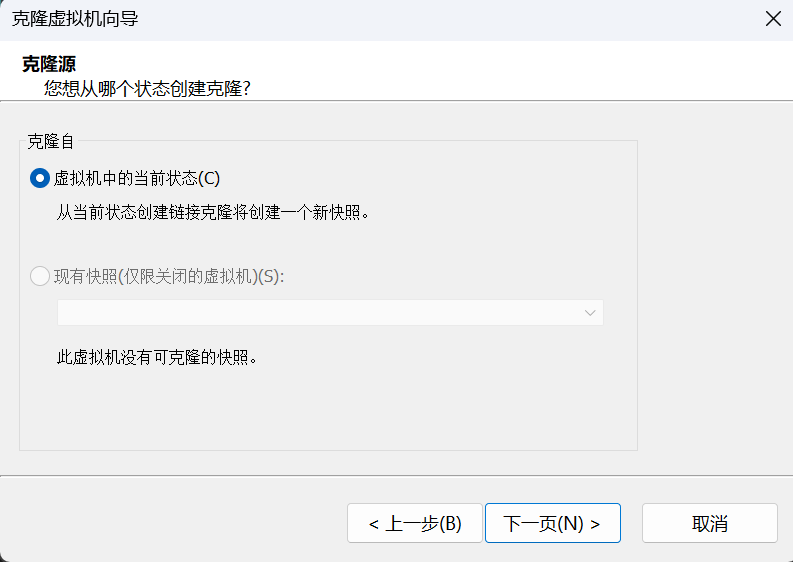
选择创建完整克隆,下一页
设置名称和存放路径,点击完成
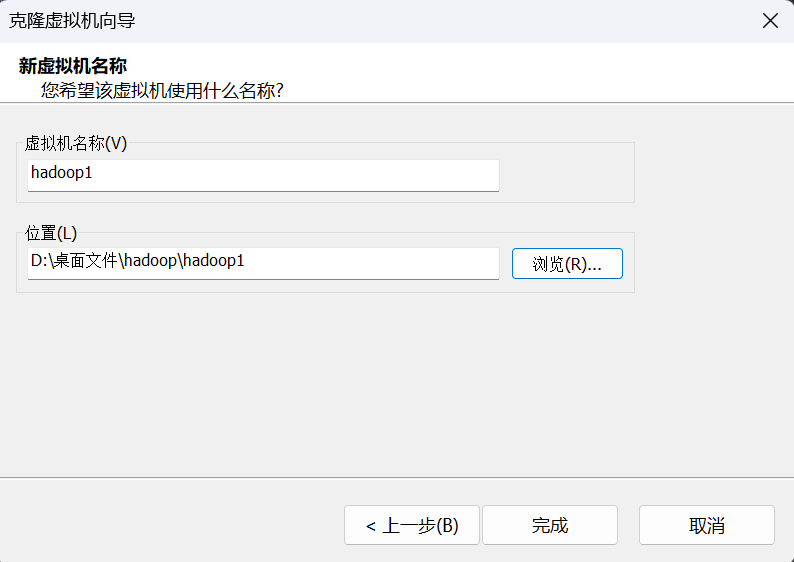
同理,克隆出hadoop2
启动三个虚拟机
按照(1)网络配置更改IPADDR即虚拟机地址
(2)/etc/hostname 更改克隆机的主机名
(6)使用XShell同时处理三个虚拟机
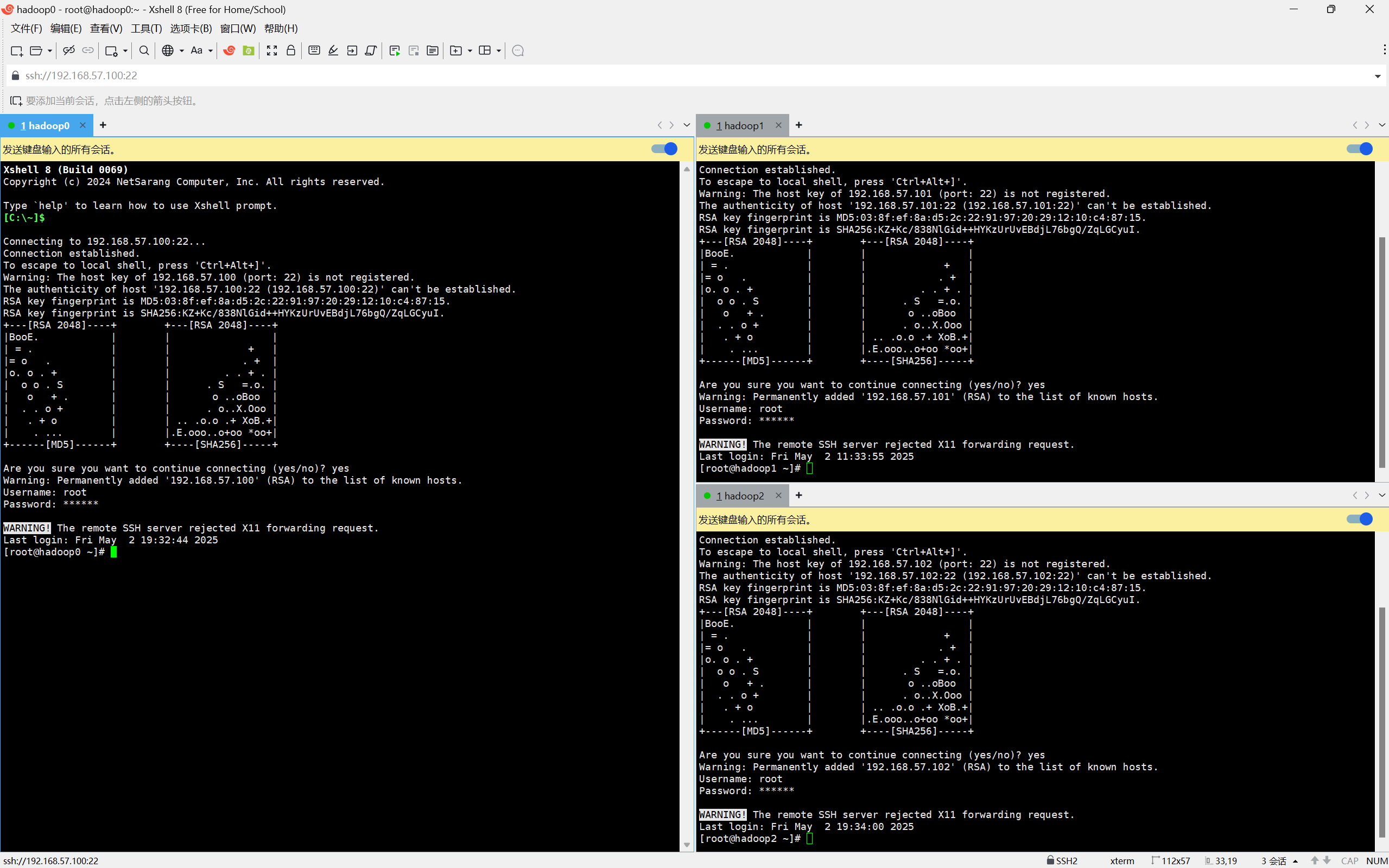
右键以管理员身份运行XShell,输入名称、主机号添加三个虚拟机,连接
直接拖动标签,可以分区
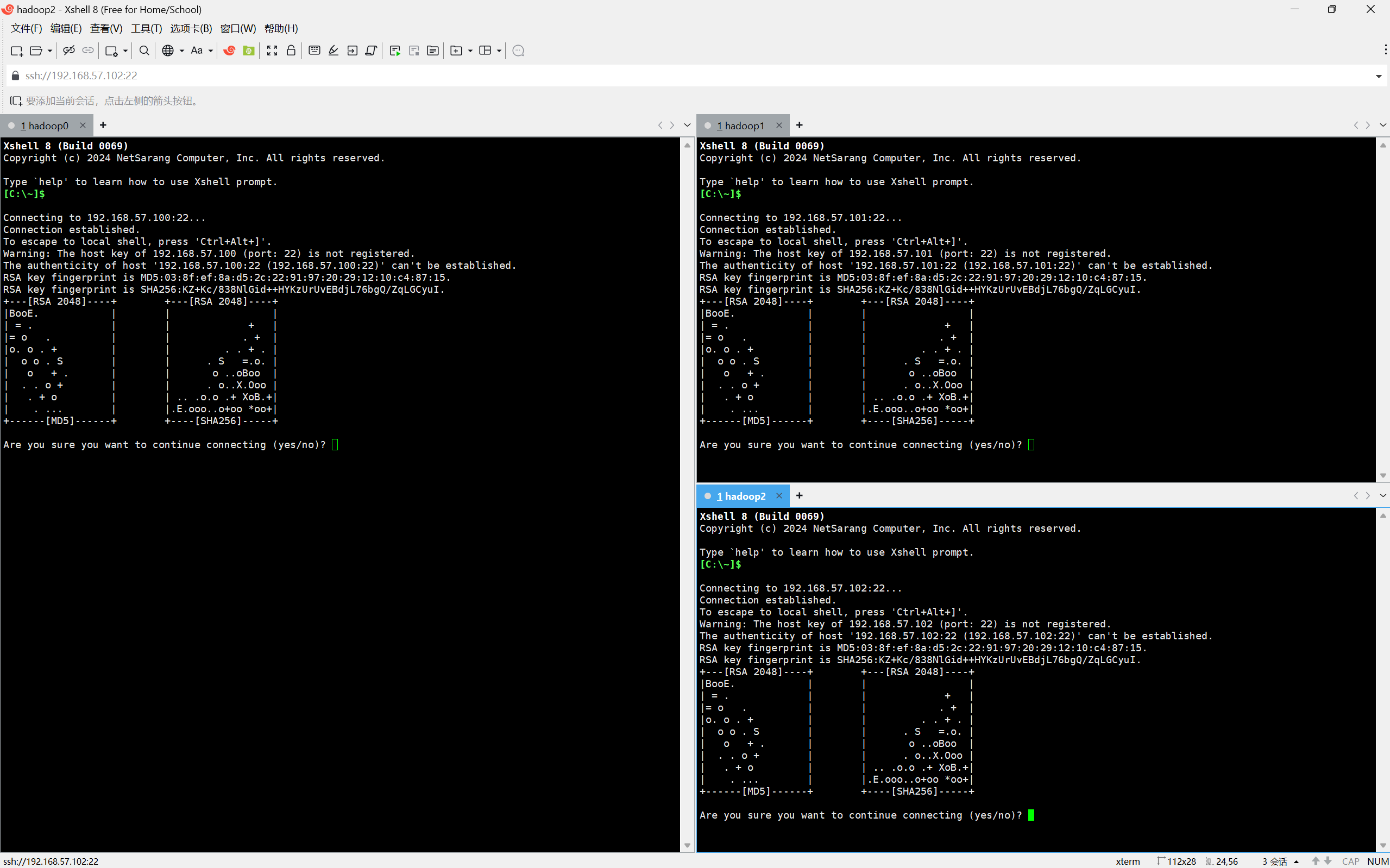
菜单栏→工具→发送键输入到→所有会话 三个页面可以同时操作
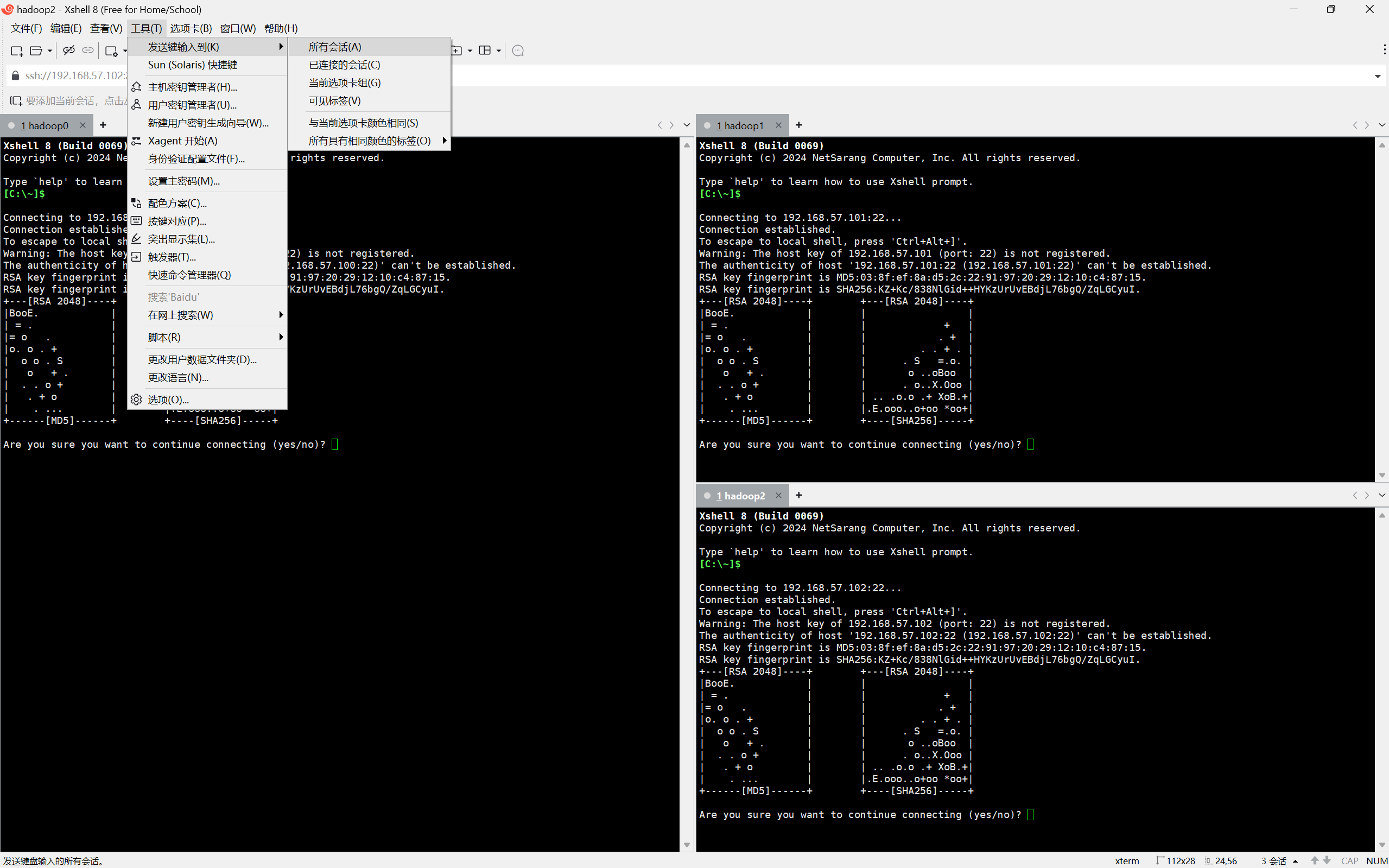
输入yes 用户名root 密码即可进入虚拟机命令行
(7)修改/etc/hosts
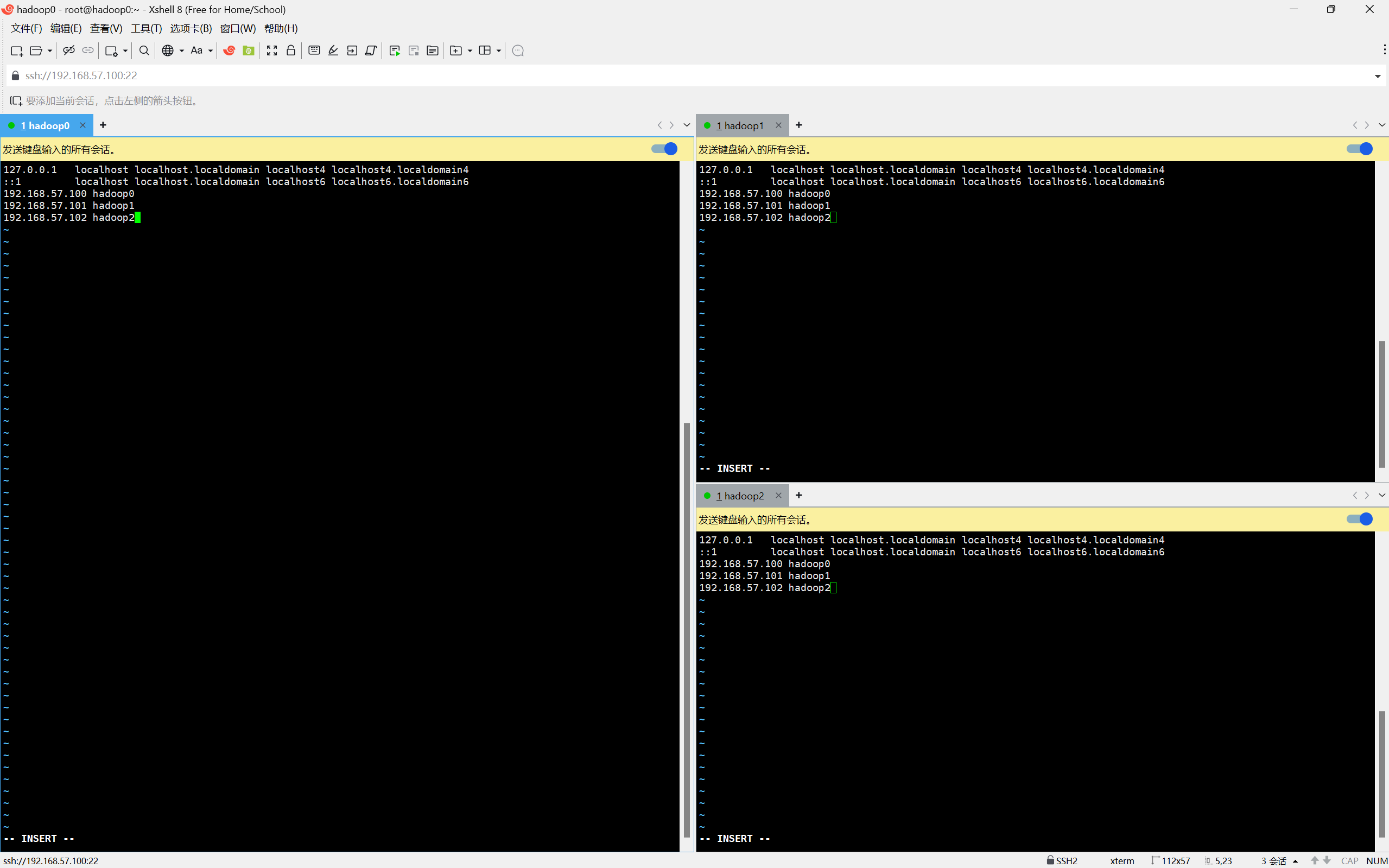
vi /etc/hosts添加所有节点的主机地址及主机名
(8)免密登录
①获取密码
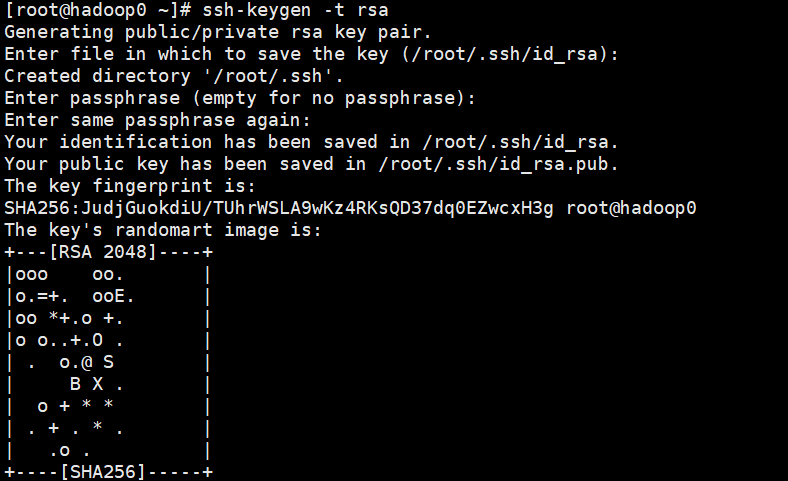
ssh-keygen -t rsa经过几次回车,成功获取
②分发密码
ssh-copy-id hadoop0
ssh-copy-id hadoop1
ssh-copy-id hadoop2根据要求输入yes以及对应节点的密码
③验证是否成功
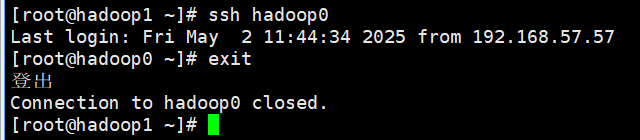
ssh hadoop0显示登入hadoop0命令行即为成功,退出输入exit
四、压缩包安装jdk
(1)首先把三个节点登陆进入Xftp
之后找到空白文件夹/opt
把jdk压缩包粘贴到/opt
然后回到XShell
cd /opt
ls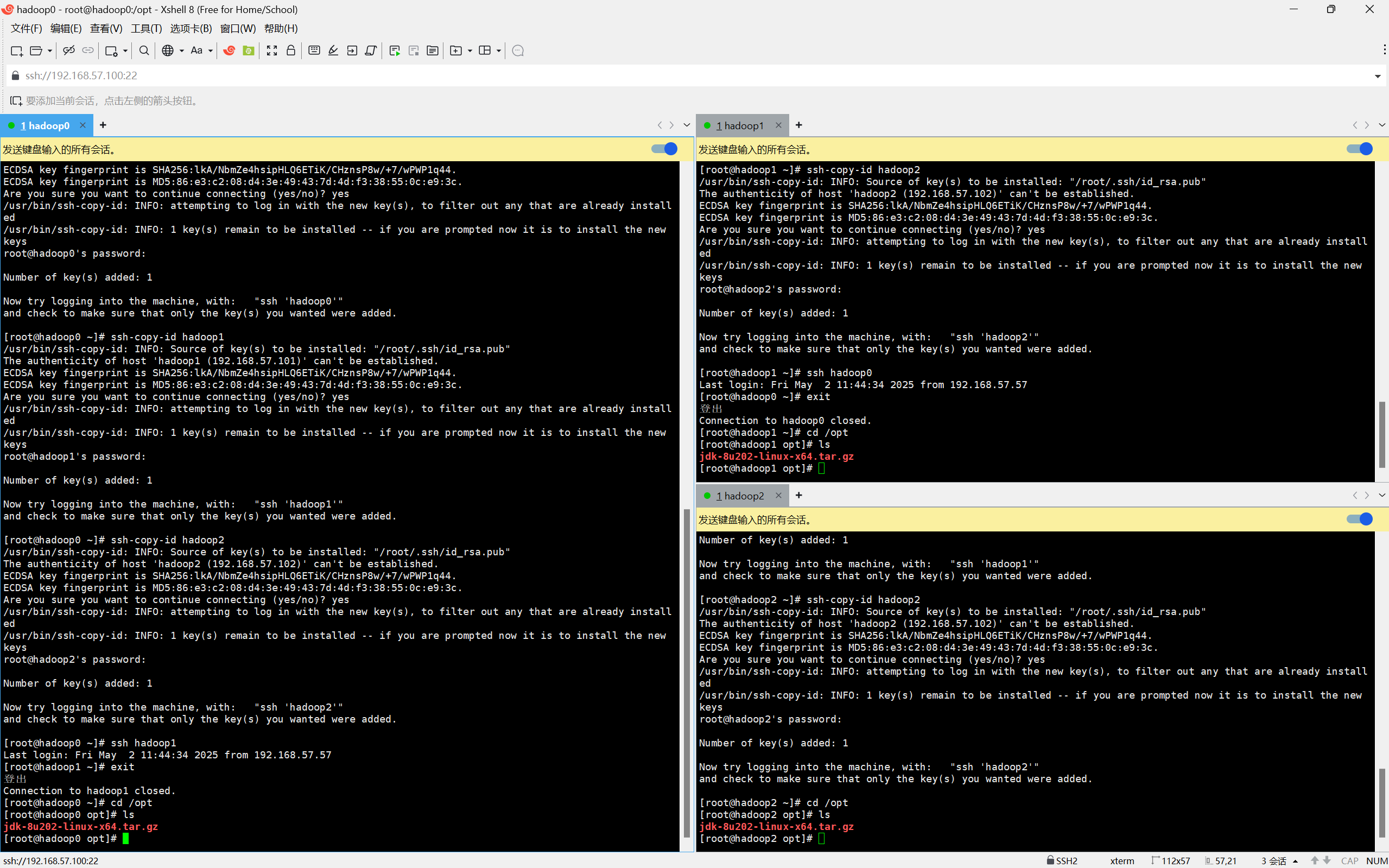
可以看到在/opt中有一个jdk压缩包
执行解压命令
tar -zxvf <安装包名称>执行重命名命令
mv <文件夹名> <新文件名>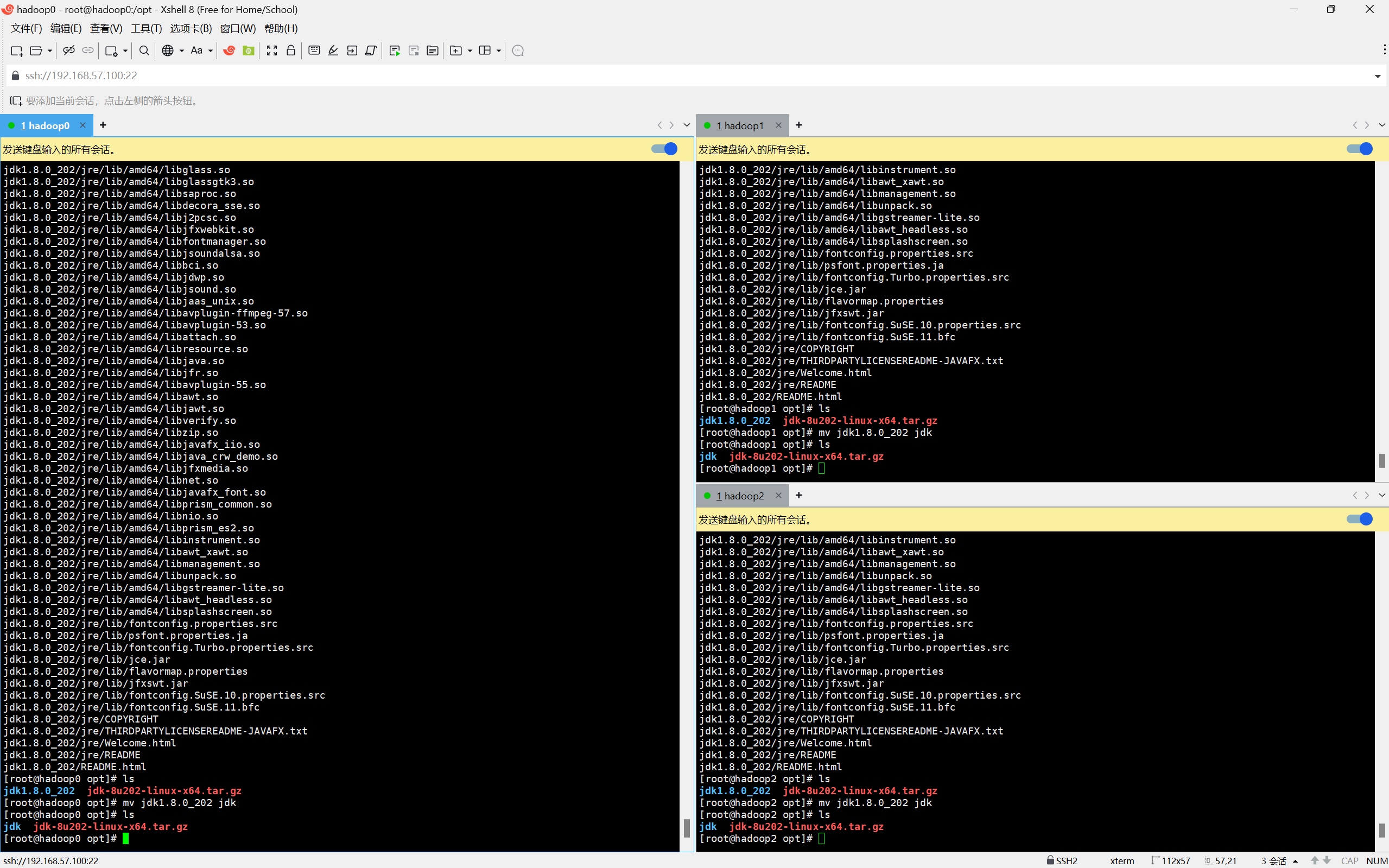
(2)配置环境文件
vi /etc/profile把下列文字添加到profile开头
export JAVA_HOME=/opt/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar(注意:文件路径根据自己的文件写)
保存文件后执行
source /etc/profile使环境文件生效
(3)查看是否安装成功
执行
java -version成功安装会显示当前安装的jdk版本

五、压缩包安装hadoop
(1)把hadoop压缩包放入/opt并解压
![]()
执行解压命令
tar -zxvf <安装包名称>执行重命名命令
mv <文件夹名> <新文件名>
(2)配置环境文件
vi /etc/profileexport HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile(3)配置hadoop相关文件(/opt/hadoop/etc/hadoop)
①core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
</configuration>②hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hdfs/datanode</value>
</property>
</configuration>③mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>④yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>⑤workers
hadoop1
hadoop2⑥hadoop-env.sh
export JAVA_HOME=/opt/jdk
# 定义 HDFS 服务用户
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
# 定义 YARN 服务用户(如果之后启动 YARN 遇到类似问题也能解决)
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root(4)初始化(仅在主节点执行即hadoop0)
hdfs namenode -format(5)启动hadoop集群(仅在主节点执行即hadoop0)
start-dfs.sh
start-yarn.sh六、成功实现
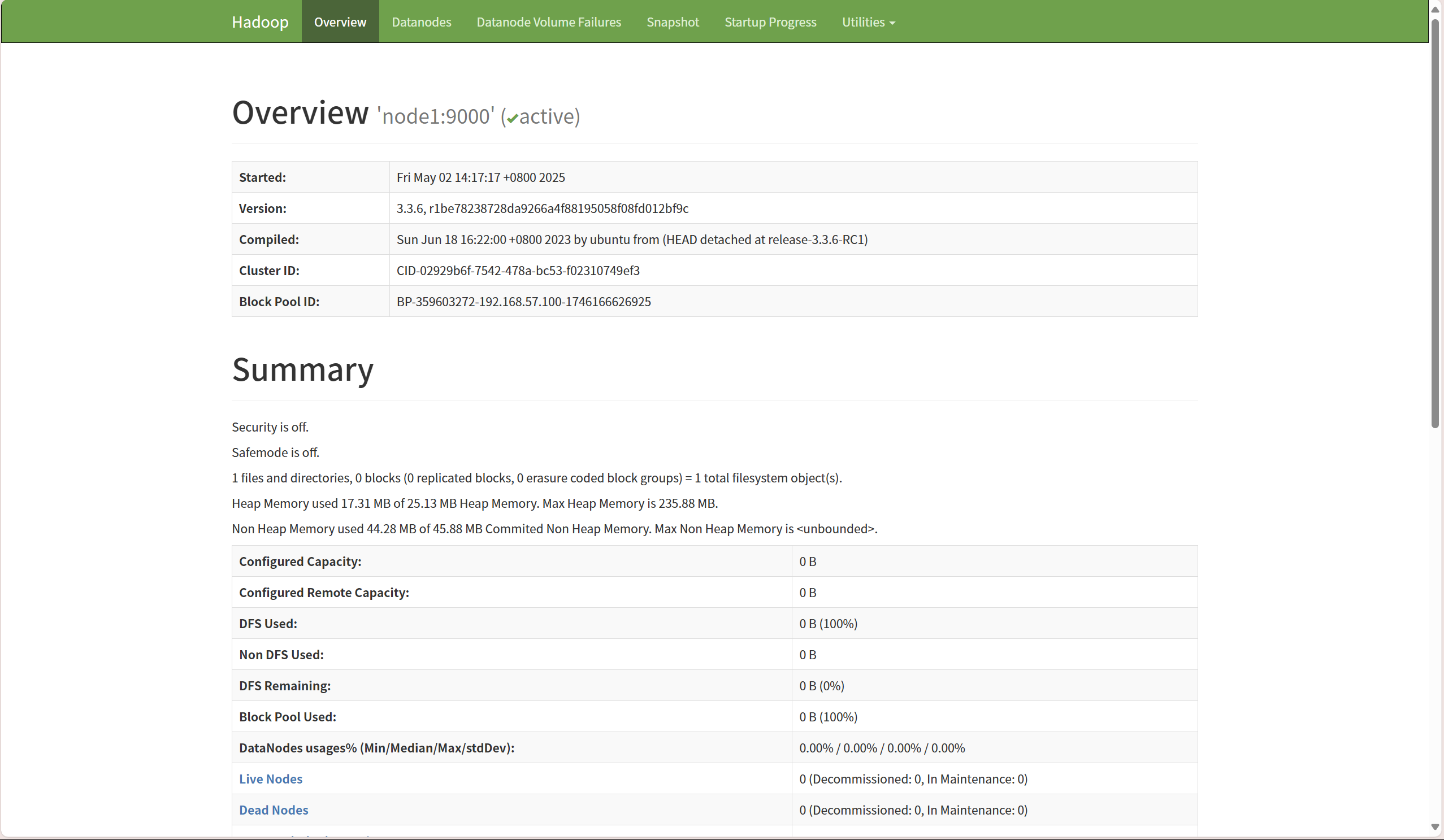
主机地址:8088
主机地址:9870
网址搜索,出现下面的界面
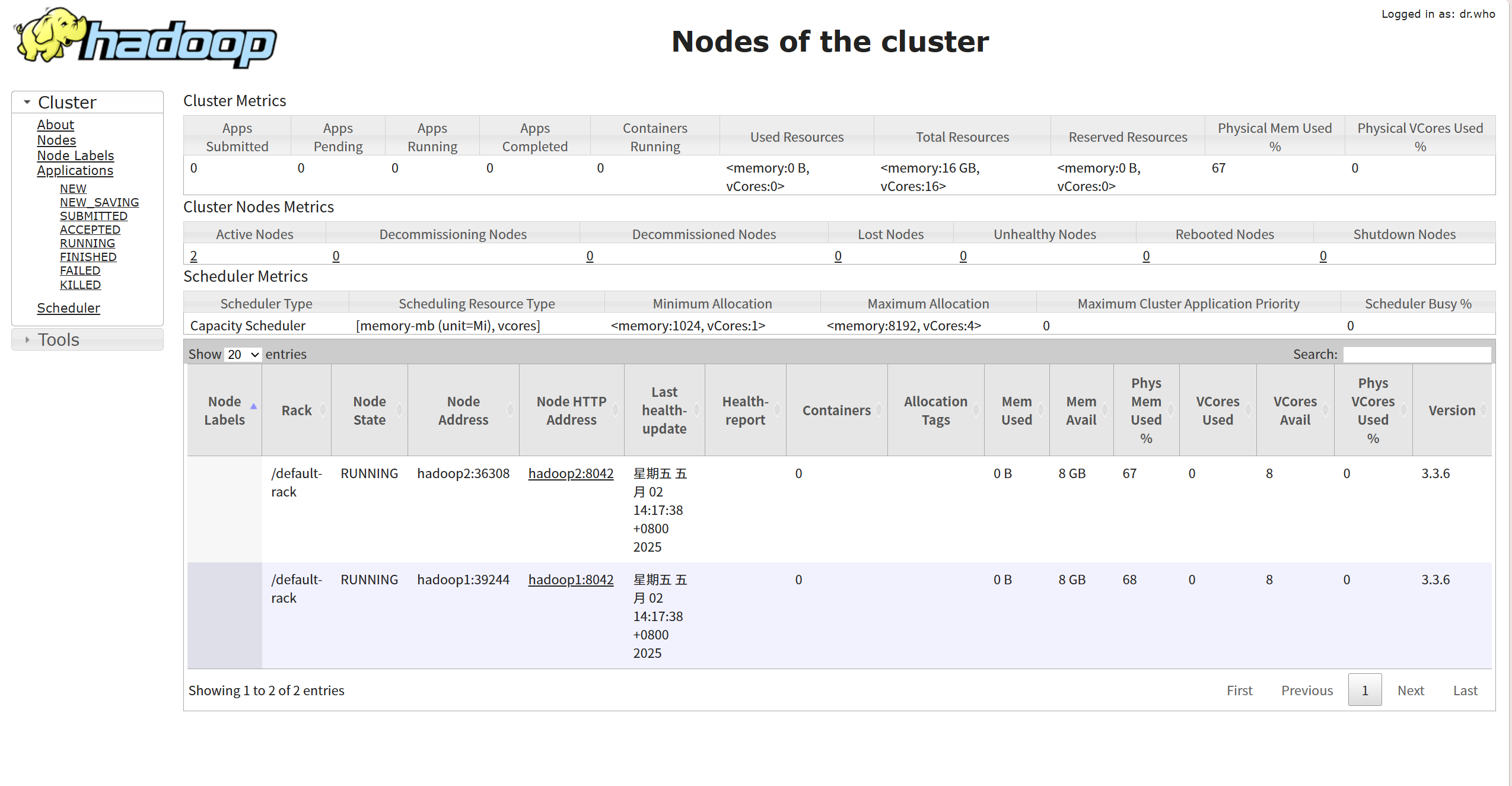


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









