







开篇
说明
本文章是我本人学习tlias项目记下的笔记,主要以后端为主
本文章可以供其他同学从中学习,对知识点有更深层次的理解
本文可以学到:
- 实战中增删改查
- 文件上传
- Springboot中个人总结的常用注解
- JWT令牌个人总结
- 过滤器和拦截器在实战中的运用
- AOP相关
- 从源码入手自动装配
如何学习
个人心得
-
通过实战来熟练技术,而不是先学技术知识点
-
看视频中,记下大概不会的,难点,一章开头用自己话总结
-
先实践入门,再慢慢理解,由浅入深
-
学习编程最好的方式就是先快速入门,然后直接上手写,在实践中学习。
-
遗忘曲线复盘:今天一开始学习
-
碎片化时间
maven
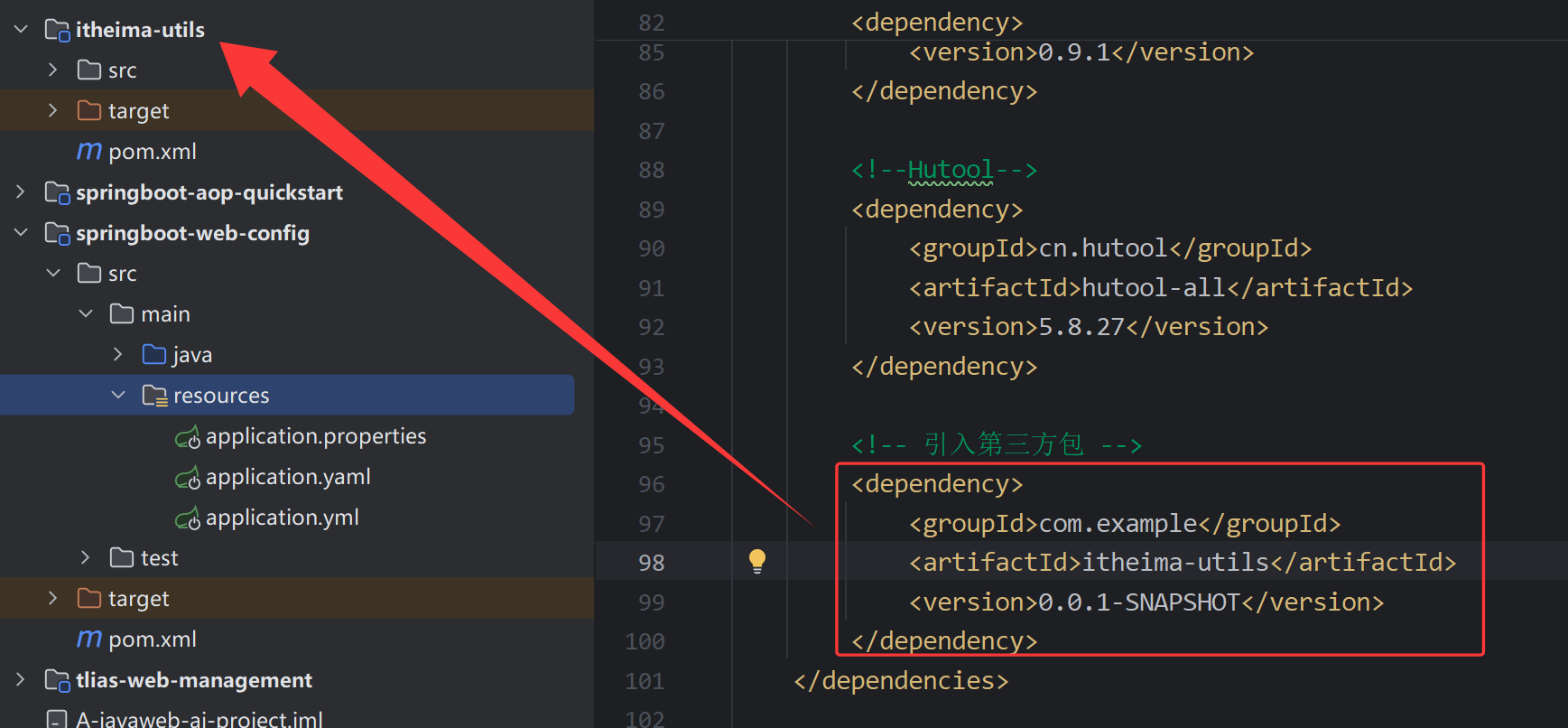
- pom文件中导入的依赖,maven是怎么加载的,底层是maven依赖传递对吧,那这个maven依赖传递原理是啥,知道了对应的组织名,从网上下载吗??
pom.xml 文件中添加一个依赖,Maven 会根据声明的 groupId、artifactId 和 version 信息,从配置的远程仓库中下载相应的 JAR 文件。这些远程仓库可能是 Maven 中央仓库、私有仓库或其他第三方仓库。
前端
HTML:网页结构(页面元素和内容)
CSS:网页表现(页面元素的外观、位置等页面样式,如:颜色、大小等)。
JavaScript(js):网页的行为(交互效果)
- Json: (JavaScript Object Notation),前后端数据交换载体
- Bom: (Browser Object Model),浏览器对象模型,js把浏览器各个组成封装成对象
- Dom: (Document Object Model),文档对象模型,js把文档各个组成封装成对象
- js事件: onclick:on()等
Vue : 简化js中Dom操作Vue (当 message 的值发生变化时,页面上对应的文本内容会自动更新,手动操作 DOM 来更新视图会非常繁琐。Vue 通过数据驱动视图的方式,简化了 DOM 操作,让开发者只需要关注数据的变化,视图会自动更新。)
YAPI :对接口的管理,模拟真实接口的Mock服务
Vue-cli : 脚手架,快速创建vue项目模板,类似spring
NodeJS: Vue-cli的依赖环境,类似jdk
NPM : NPM是Node.js的默认包管理器,可以帮助快速找到资源等
Ajax:(Asynchronous JavaScript And XML),是一种在无需重新加载整个页面的情况下,能够更新部分网页的技术,异步的JavaScript和XML
Axios:是对原生的Ajax进行封装.简化书写, 获取后台数据,获取服务端的数据
后端开发
Springboot篇小问题
为什么用接口而不用实现类?
 1.降低耦合度 2.面向接口是良好的编程习惯,有助于可维护性和可读性
1.降低耦合度 2.面向接口是良好的编程习惯,有助于可维护性和可读性
注解大全
springboot注解
| 注解 | 描述 |
|---|---|
@SpringBootApplication | 组合注解,启用 Spring Boot 应用的各项默认配置 |
@SpringBootConfiguration | 标识该类是一个 Spring Boot 配置类 |
@EnableAutoConfiguration | 启用 Spring Boot 的自动配置机制 |
@ComponentScan | 启用 @Component 注解类的扫描,可指定扫描的包路径 |
@RestController | 组合注解,标识 RESTful 控制器,方法返回值作为响应体 |
@RequestMapping | 映射 HTTP 请求到控制器的处理方法上 |
@GetMapping / @PostMapping/ @PutMapping / @DeleteMapping | 快捷注解,指定 HTTP 方法和请求路径 |
@PathVariable | 从 URL 路径中提取变量 |
@RequestParam | 从请求参数中提取变量 |
@RequestBody | 将请求体中的 JSON 数据绑定到方法参数上 |
@ResponseBody | 将方法的返回值转换为响应体 |
@ResponseStatus | 设置 HTTP 响应的状态码 |
@RestControllerAdvice | 全局异常处理和数据绑定 |
@ExceptionHandler | 处理特定的异常 |
@Value | 从配置文件中注入值 |
@ConfigurationProperties | 从配置文件中绑定属性到 Java 对象 |
@Profile | 根据环境激活或禁用 Bean |
@Bean | 定义一个 Bean |
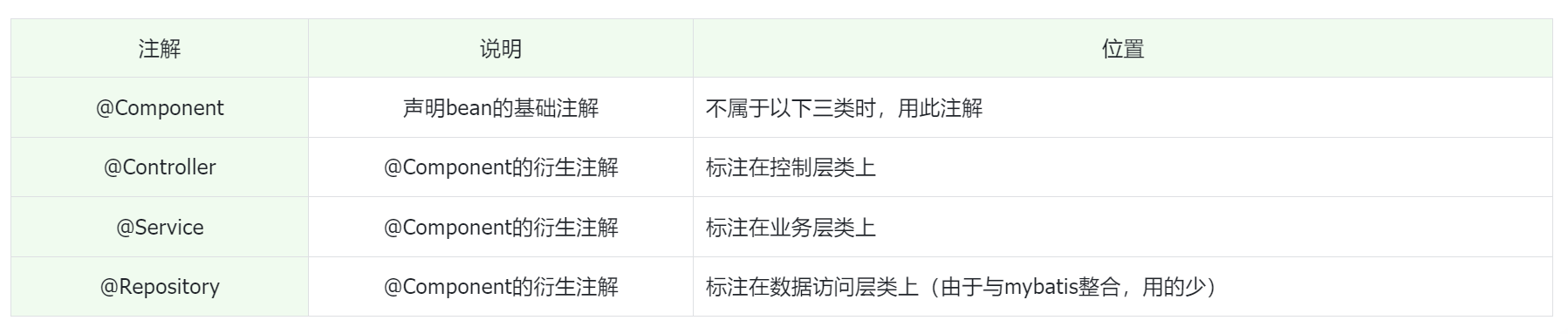
@Service | 标识该类为服务类 |
@Repository | 标识该类为数据访问类 |
@Component | 标识该类为组件类 |
@Autowired | 自动注入依赖 |
@Qualifier | 当出现多个bean要注入得时候,指定注入的具体 Bean |
@Lazy | 延迟加载 Bean |
注解详解:
-
@SpringBootApplication:1.可以生成bean,可以被ioc容器管理 2.根据添加得依赖自动配置spring 3.会扫描当前类所在的包以及子包中的注解类。
- 有@SpringBootConfiguration
+@EnableAutoConfiguration+@ComponentScan组成
- 有@SpringBootConfiguration
-
@RequestMapping:将请求参数映射到处理器方法上
- 还有
@GetMapping、@PostMapping(增加) ,@PutMapping(修改)、@DeleteMapping等快捷注解 - 可以抽取公共路径的提取到类上来写 写个@RequestMapping
- 还有
-
@RestController (通常使用) :1.处理 HTTP 请求 2.将方法返回值作为 HTTP 响应体返回给前端:
- 有@Controller和@ResponseBody组成
-
@ResponseBody:把后端方法返回值作为HTTP响应体返回给前端
-
@Controller:处理HTTP请求
接收不同类型参数注解
-
@RequestParam:接收url参数
-
不能省略情况:1.形参不是简单类型时候() 2.接收参数和形参名不一致
eg: 复杂类型springmvc会通过其它方式请求注解,导致报错
请求参数样例:
/emps?ids=1,2,3
public Result delete(@RequestParam List ids){} -
默认值时候(defaultValue):@RequestParam(defaultValue = “1”
eg:public Result page(@RequestParam(defaultValue = “1”) Integer page ){}
-
参数必须传递时(value=“参数名”,required=false):默认为true必须传递参数
-
-
@PathVariable :接收路径参数(“/emps/1这种”)
-
@RequestBody:接收json等复杂数据结构参数
| 特性 | @RequestParam | @PathVariable | @RequestBody |
|---|---|---|---|
| 用途 | 获取URL查询参数 | 获取URL路径参数(/users/{id}这种) | 接收请求体中的复杂数据结构 |
| 常用请求方法 | 主要用于GET、DELETE,也可用于POST、PUT | 可用于任何请求方法 | 主要用于POST、PUT |
| 数据来源 | 请求的查询字符串或表单数据 | URL路径 | 请求的body |
| 数据格式 | 简单类型(如字符串、数字)或字符串集合 | 路径变量,通常是简单类型 | JSON、XML或其他序列化数据 |
| 参数位置 | URL中或表单数据中 | URL路径中 | 请求体中 |
| 示例 | @RequestParam("id") int id | @PathVariable("id") int id | @RequestBody MyObject obj |
| 请求路径(网址中的) | /emps | /emps/{id} /emps/2 网址中输入这样 | /emps |
| 请求参数样例 | 1. /emps 2. /emps?ids=1,2,3(复杂类型)这个注解不能省略 | 请求参数样例/emps/1 | application/json |
注:
-
还有接收多个参数,但是这个不是json的时候,就不需要写@RequestParam这些注解
- Spring Boot支持将请求参数自动绑定到一个对象中
-
请求路径PK参数:http://localhost:8080/depts?id=1 像这种, /depts是请求路径 id=1是参数
-
请求路径(一般在查询回显修改操作中)
-
/users/{id} ,{id}只是一个占位符,要被1 2这些代替,但是网址中要输入 /users/1
-
路径参数的请求参数样这样 /depts/1
-
-
@RequestParam
-
中当传递的参数名和形参名称相同的时候,这个注解可以省略
-
但是当形参不是简单类型的时候@RequestParam不能省略 如?ids = 1,2,3 数组类型
-
eg:public Result delete(@RequestParam List ids){}
- 注意:@RequestBody和@ResponseBody区别
mybatis注解
springboot案例
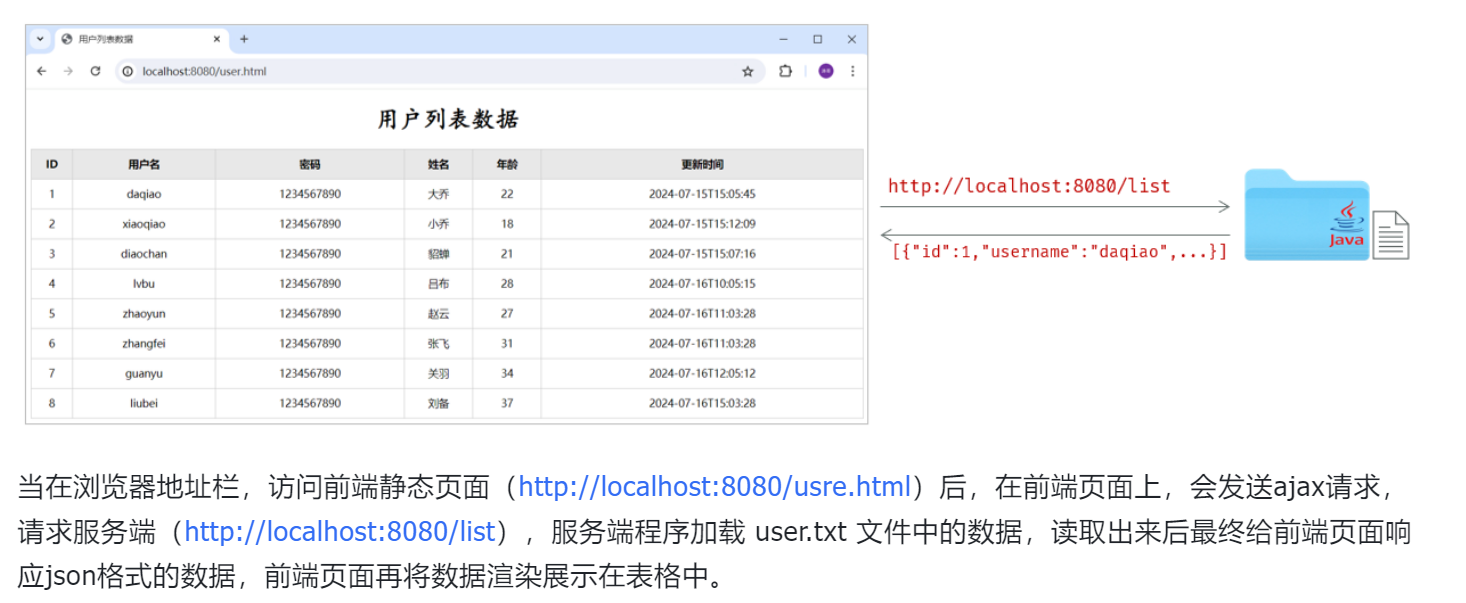
游览器通过链接访问客户端 -> 客户端对文件进行读取并转换json格式返回给游览器
1.创建User类对象存储user.txt文件中内容
2.通过创建流(可以理解就是操作文件的),读取user.txt文件中内容
3.然后把user.txt文件中内容存储到User类对象中
4.前端代码user.html
5.启动springboot -> 通过http://localhost:8080/user.html访问user.html ->user.html会跳转访问/list
注:这里复杂的是流的操作
@RestController //启动类
public class UserController1 {
@RequestMapping("/list") //访问url
public List<User> list(){
//InputStream in=new FileInputStream("C:\\Users\\23515\\Desktop\\user.txt");
//读取文件,转换成流的方式
//这里通过class字节码文件.类加载器.类加载器的资源url中加载数据
InputStream in=this.getClass().getClassLoader().getResourceAsStream("user.txt");
//通过util工具,提取流中每行数据
ArrayList<String> lines=IoUtil.readLines(in,StandardCharsets.UTF_8,new ArrayList<>());
List<User>userlist=lines.stream().map(line->{
String [] parts=line.split(",");
Integer id = Integer.parseInt(parts[0]);
String username = parts[1];
String password = parts[2];
String name = parts[3];
Integer age = Integer.parseInt(parts[4]);
LocalDateTime updateTime=LocalDateTime.parse(parts[5],DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
return new User(id, username, password, name, age, updateTime);
}).toList();
return userlist;
}
}
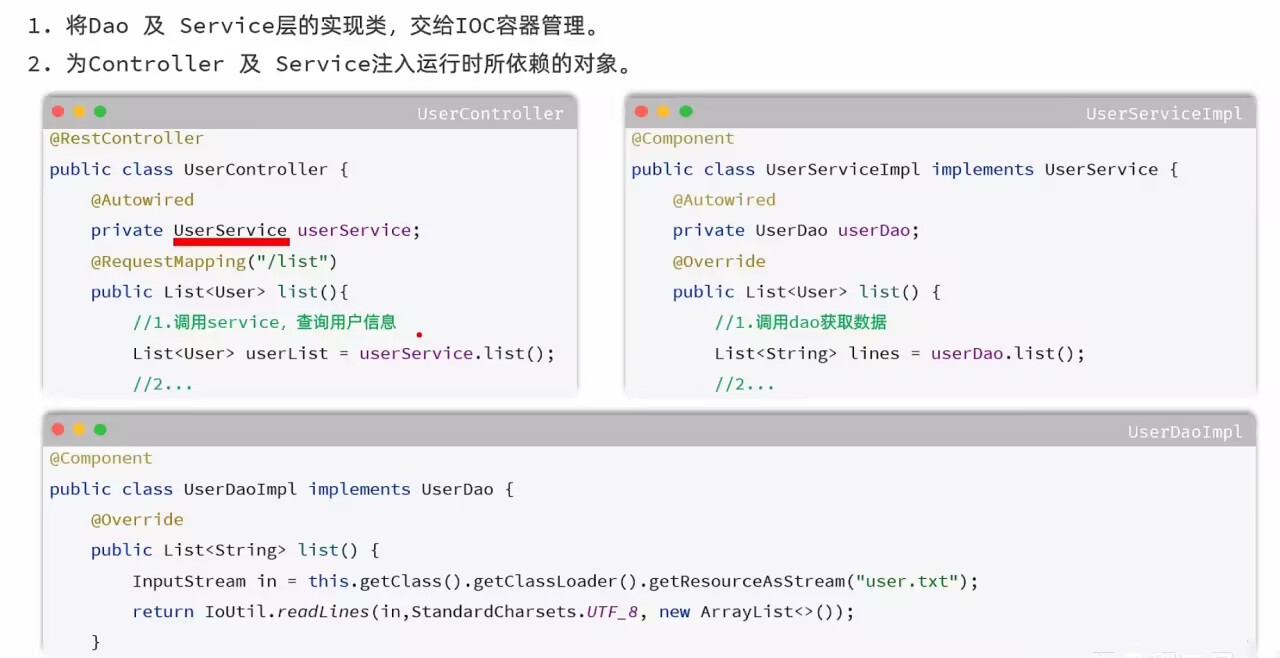
三层架构
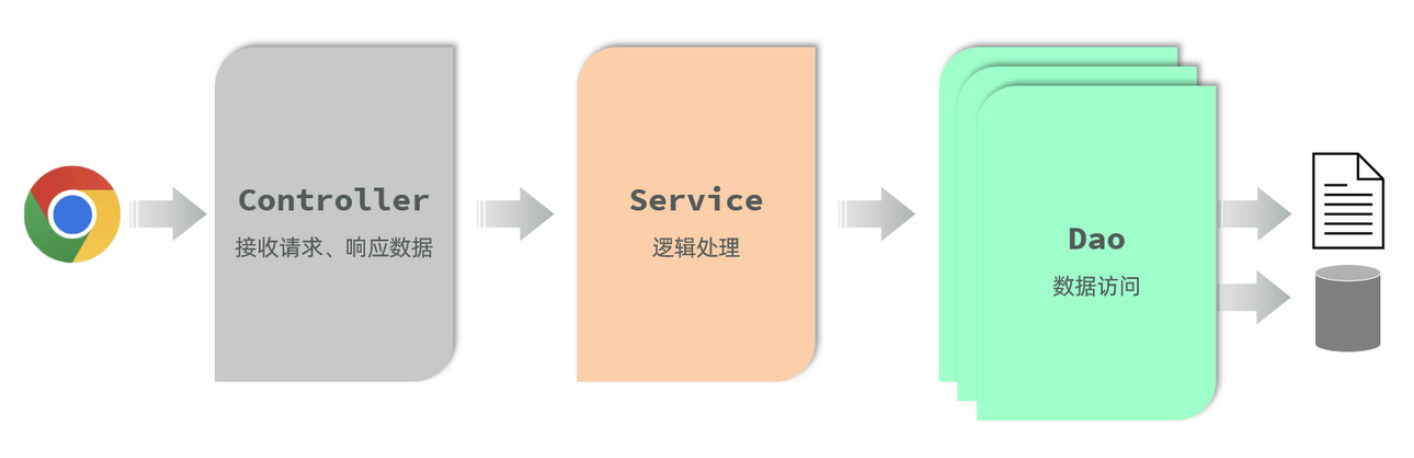

分层解耦
- 耦合:各个模块之间的关联
- 内聚:一个模块中功能都是类似的
设计原则:高内聚低耦合
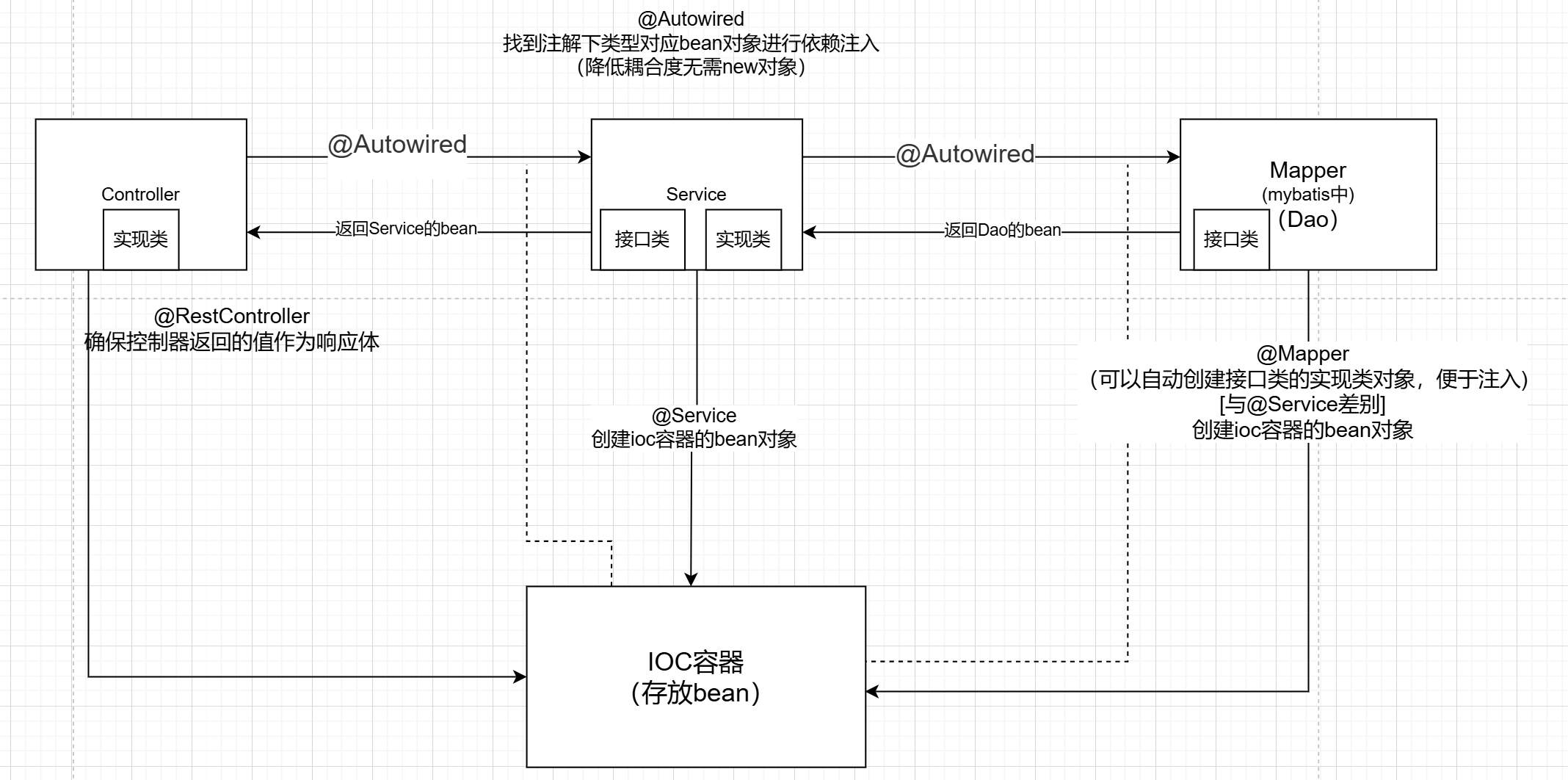
!重要-IOC/DI入门
通过ioc容器(ioc,控制反转)实现解耦
(通过不使用new对象而通过ioc容器来实现降低耦合)
重要知识
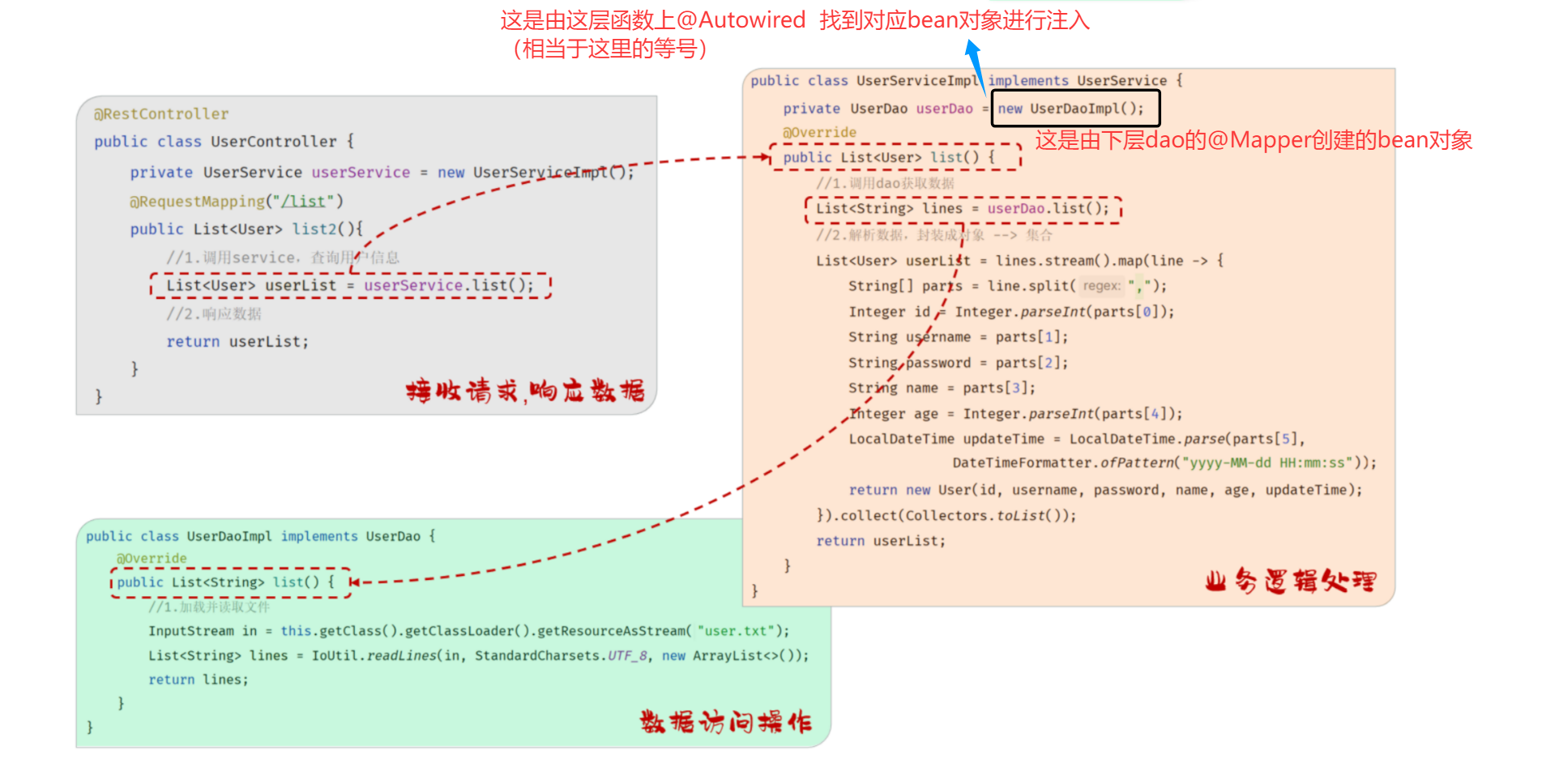

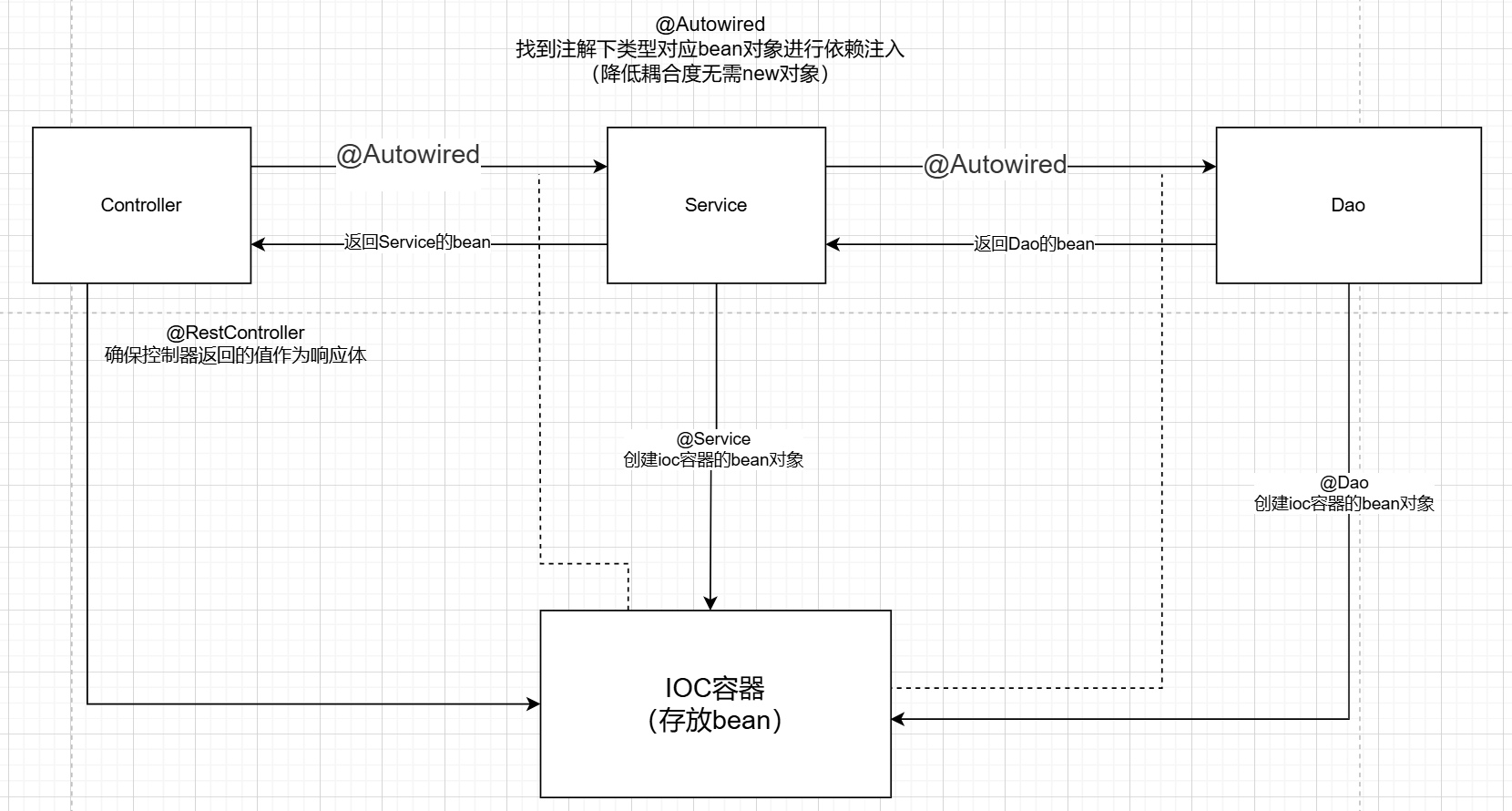
---------------------------------------------------------------上下两个图片结合--------------------------------------------------
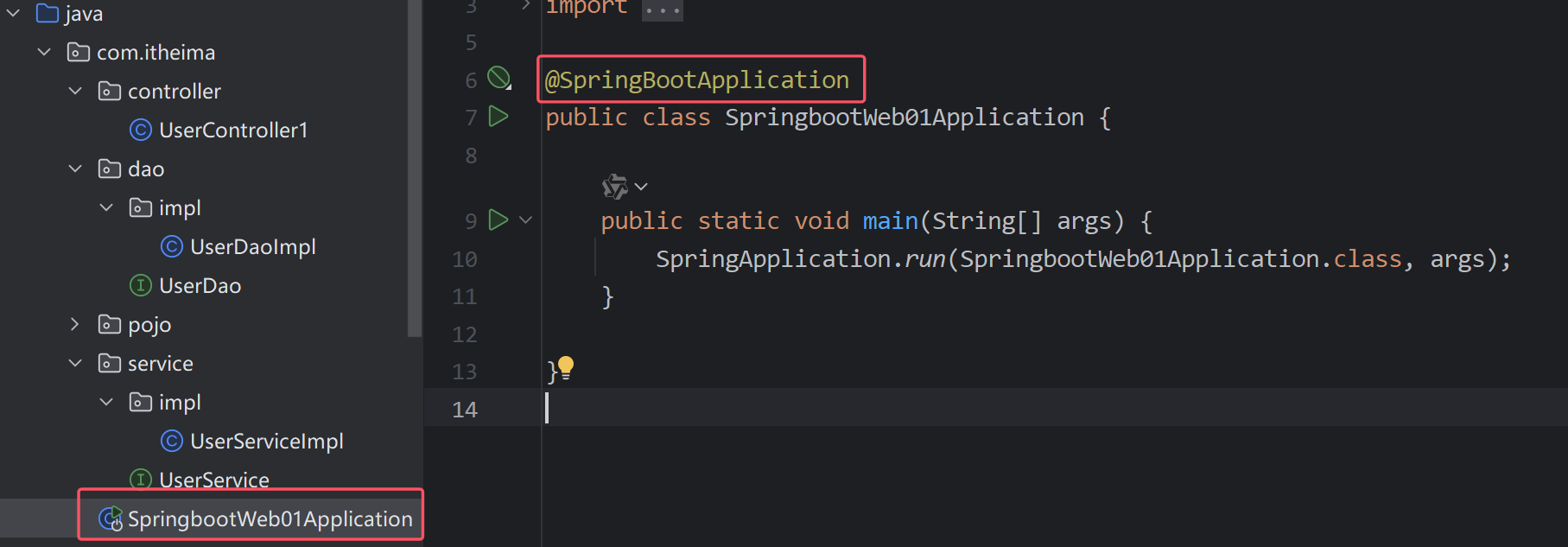
@Autowired 从容器中找出这个类型的bean对象并且复制给这个对象(通过注解下方函数名找到对应类型在容器中的对象)
@RestController //为了返回JSON数据 ,还给ioc容器管理
public class UserController {
@Autowired
private UserService userService;
@RequestMapping("/list") //HTPP的请求路径
public List<User> list(){
//1.调用Service
List<User> userList = userService.findAll();
//2.响应数据
return userList;
}
}
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;
@Override
public List<User> findAll() {
List<String> lines = userDao.findAll();
List<User> userList = lines.stream().map(line -> {
String[] parts = line.split(",");
Integer id = Integer.parseInt(parts[0]);
String username = parts[1];
String password = parts[2];
String name = parts[3];
Integer age = Integer.parseInt(parts[4]);
LocalDateTime updateTime = LocalDateTime.parse(parts[5], DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
return new User(id, username, password, name, age, updateTime);
}).collect(Collectors.toList());
return userList;
}
}
@Repository
public class UserDaoImpl implements UserDao {
@Override
public List<String> findAll() {
InputStream in = this.getClass().getClassLoader().getResourceAsStream("user.txt");
ArrayList<String> lines = IoUtil.readLines(in, StandardCharsets.UTF_8, new ArrayList<>());
return lines;
}
}
总结:@Repository这几个注解 -> 表示通过创建ioc容器的bean对象(通过函数名小写)
@Autowired -> 表示依赖注入,找到注解下对应类型bean对象进行依赖注入
@SpringBootApplication //扫描子包及其所在的包 启动类
DI依赖注入
-
属性(注解)注入
- 构造器注入
-
setter注入
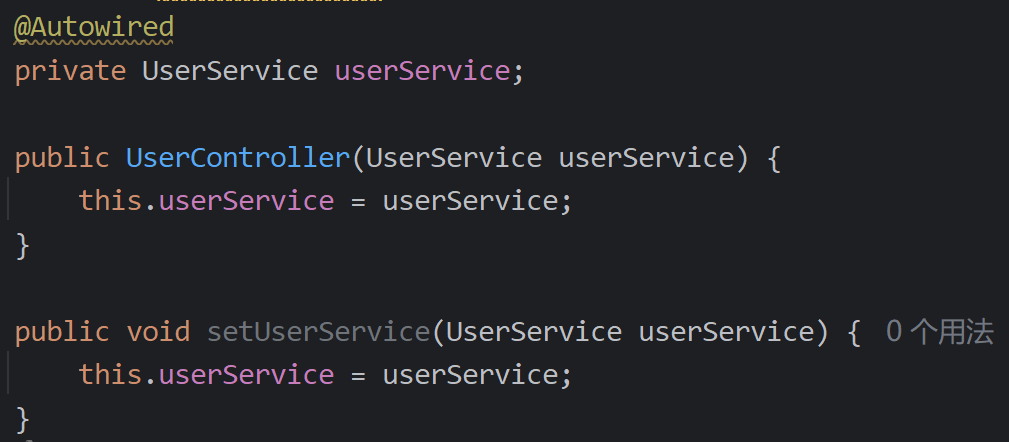
企业开发中通常使用注解注入和构造器注入:
- 注解注入:隐藏了类之间的依赖关系(没有直接显示关系),还破坏封装性(原本private的类型被破坏)
- 构造器注入:代码繁琐,但是提高代码安全性
属性(注解)注入问题:当出现多个bean的时候依赖注入会报错
 解决方法
解决方法
- @Primary:在要先进行注入的bean函数上面加上
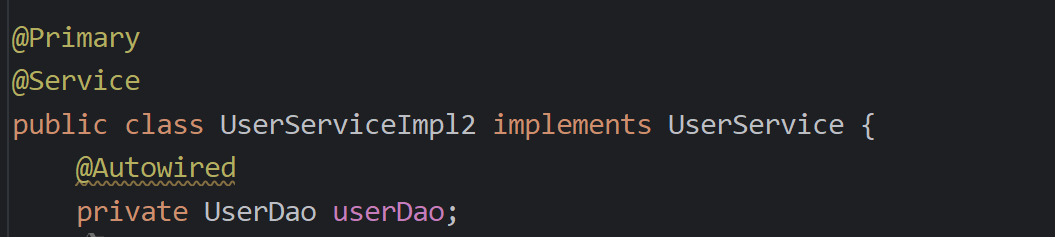
- @Qualifier和@Autowired:在一起使用
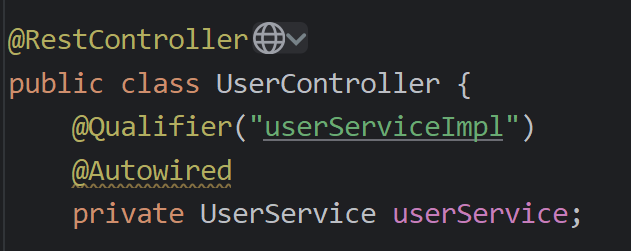
- @Resource:@Resource(name=" ")
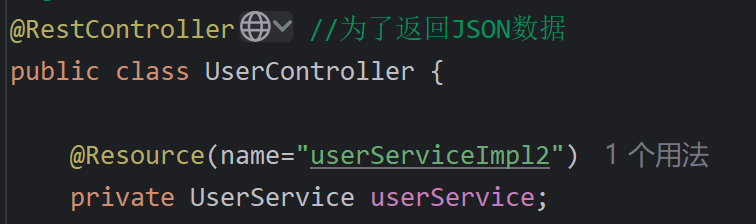
注:@Resource和@Autowired区别
@Autowired是spring框架提供的,@Resource是jdk提供的
@Autowired是按照类型注入,@Resource是按照名称注入的
Mybatis
SQL引用-idea设置技巧:选择SQL语句右键->选择显示上下文操作->选择注入语言或引用->搜索选择mysql


JDBC:通过java代码操作数据库的
mybatis:简化jdbc开发
持久层就是Dao层
#数据库访问的url地址 #这里的web01就是数据库名(表的上一级)
spring.datasource.url=jdbc:mysql://localhost:3306/web01
#数据库驱动类类名
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#访问数据库-用户名
spring.datasource.username=root
#访问数据库-密码
spring.datasource.password=root@1234
# 配置Mybatis日志输出
# mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
 ==>
==>
==>表示向数据库发送
- @Mapper注解:表示是mybatis中的Mapper接口
程序运行时,框架会自动生成接口的实现类对象(代理对象),并给交Spring的IOC容器管理,方便Service层的依赖注入
@Mapper
public interface UserMapper {
@Select("select * from user") //查询有返回值,mybatis会自动封装到方法返回值中
public List<User> findAll();
}
注:先执行findAll()函数然后再执行@Select,最后把返回值返回到方法返回值当中
- 连接池Druid
#{ } 推荐常用 预编译(会将#{ }替换为?),更安全性能高
${ } 拼接形,不安全
查询-增加-更新-删除
//框架自动生成接口实现类对象并给交Spring的IOC容器管理,方便Service层的依赖注入
@Mapper
public interface UserMapper {
@Select("select * from user") //查询有返回值,mybatis会自动封装到方法返回值中
public List<User> findAll();
@Delete("delete from user where id= #{id}")
public void deleteById(Integer id);
@Insert("insert into user(username,password,name,age) values(#{username},#{password},#{name},#{age})")
public void insert(User user1);
@Update("update user set username = #{username},password = #{password},name = #{name},age = #{age} where id = #{id}")
public void update(User user);
@Select("select * from user where username = #{username} and password = #{password}")
public User findByUsernameAndPassword(@Param("username") String username, @Param("password") String password);
//public User findByUsernameAndPassword(String username, String password);
//这里@Param为形参起名字,形参会被?替换,不知道谁是谁的,所以要起名字
//基于官方骨架创建的springboot项目中,接口编译时会保留方法形参名,@Param注解可以省略 (#{形参名})。
}
XML配置文件
1.注解方式 :完成一些简单的增删改查功能
2.XML配置文件**(一般用在mapper数据访问层)**:实现复杂的SQL功能,建议使用XML来配置映射语句。
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:
-
XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
-
namespace:类的全类名
id:函数名
resultType:函数返回值类型(用全类名) -
注:一般注解方式中mapper层指令,先上层先调函数->执行sql语句->sql语句返回值给这个函数返回类型
这个xml配置文件相当于原本的
-
-
XML映射文件的namespace属性为Mapper接口全限定名一致
-
XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。
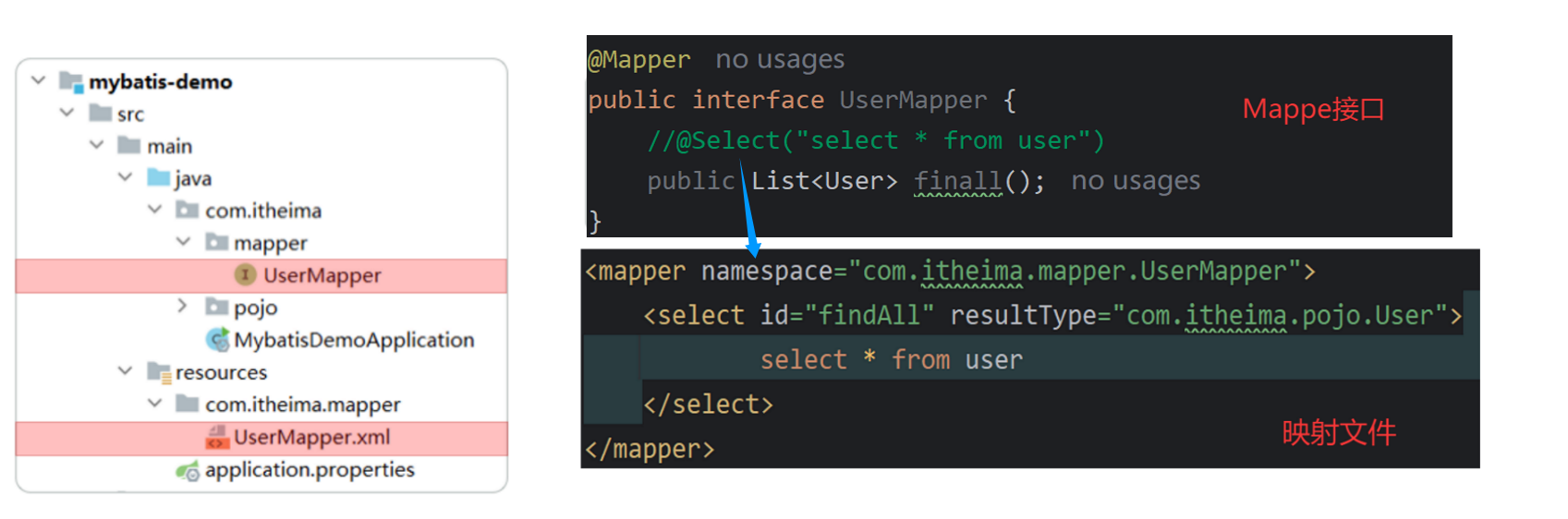
注:
-
resultType属性,指的是查询返回的一条记录所封装的类型。
-
xml配置是替换原本的sql语句,原本的函数还需要
-
配置的sql语句返回类型是单条sql返回的类型全类型,如:List只需要Emp全类名 也可以通过alt+回车
-
还有不同包情况下
SpringBoot项目配置文件-yml格式
配置文件方式:1.properties 2.yml(企业推荐) 3.ymal
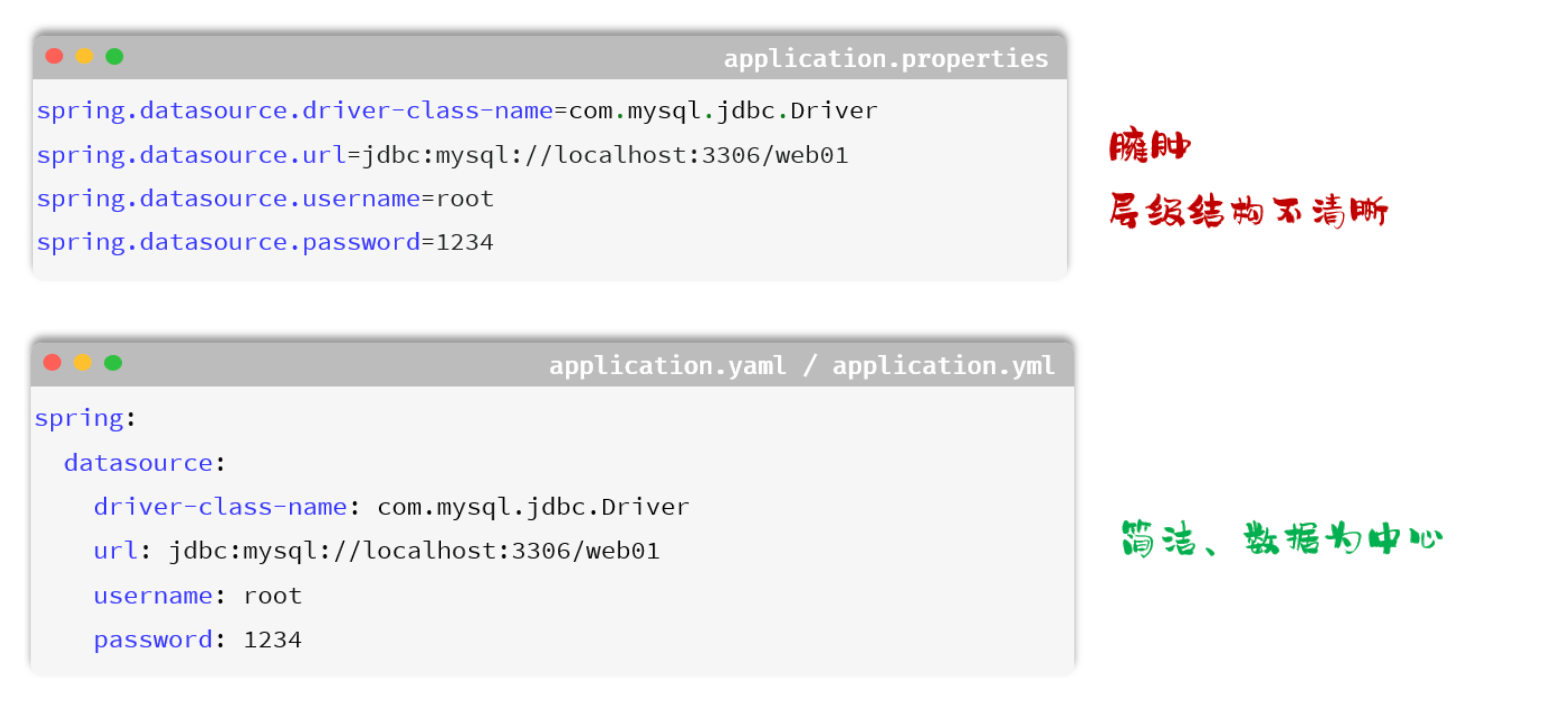
yml基本语法
- 数值前边必须有空格,作为分隔符
- 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格)
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
spring:
application:
name: springboot-mybatis-quickstart
datasource:
url: jdbc:mysql://localhost:3306/web01
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
#mybatis配置
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
yml还可以用来定义数据格式:1.定义对象或Map集合 2.定义数组、list或set集合
部门管理
restful风格(推荐):统一规范,因为不同人员有不同的命名习惯,统一规范
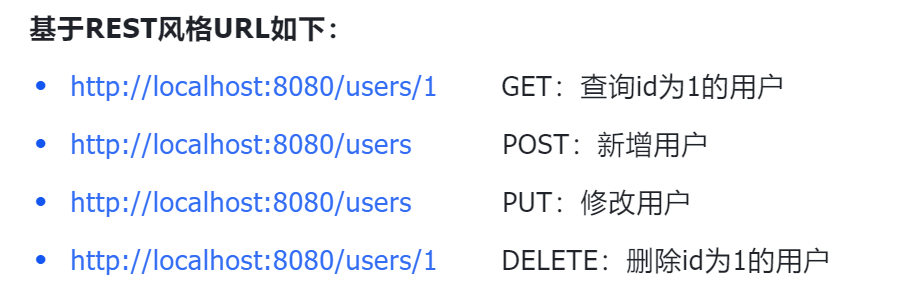
注:描述模块的功能通常使用复数,也就是加s的格式来描述,表示此类资源,而非单个资源。如:users、emps、books…
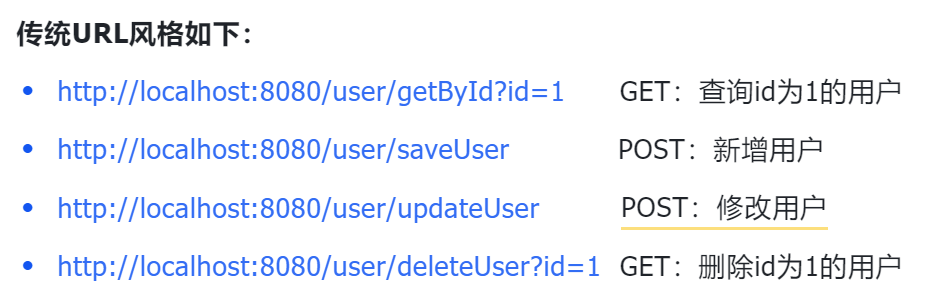
传统url(不推荐)
实战
 **springboot项目格式**
**springboot项目格式**
1.为什么使用接口类:方便,当要更换实现类的时候,只需要更换配置或者注解
2.为什么controller层用实现类,不用接口类:没必要
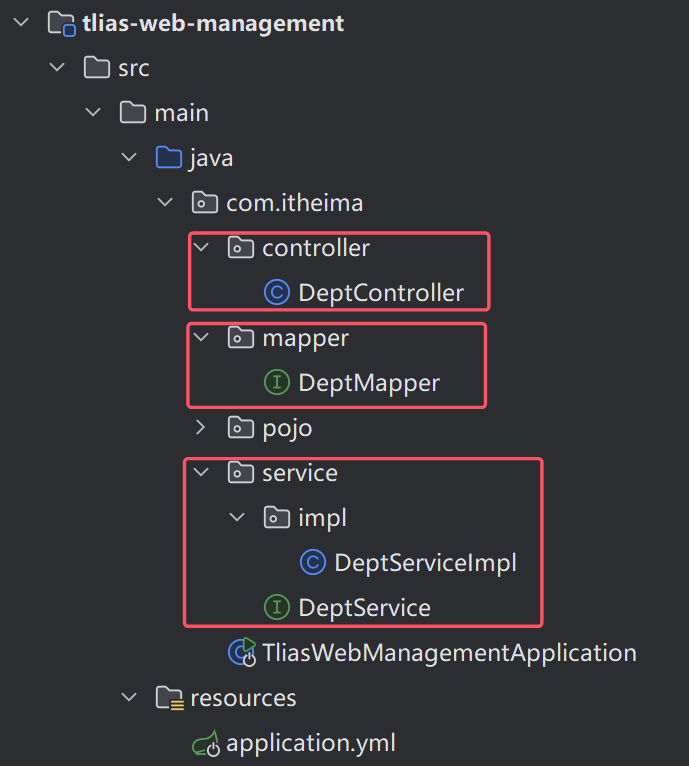
总结:springboot项目
controller层 -> 实现类
service层 -> 实现类 接口类
mapper层(dao层) -> 接口类
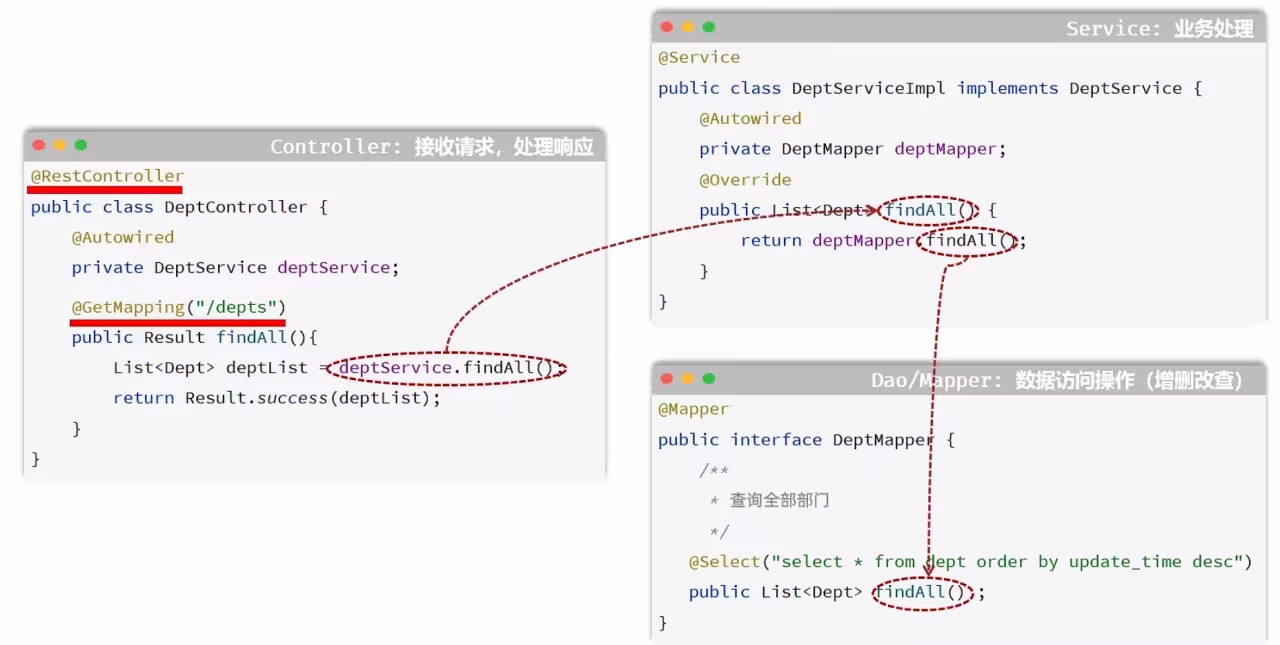
查询部门
重要
@RestController //为了返回json格式
public class DeptController {
@Autowired //依赖注入,相当于new对象的等号=
private DeptService deptService;
//@RequestMapping(value = "/depts",method = RequestMethod.GET)和getMapping效果一样
@GetMapping("/depts") //只能接受get请求,@Mapping接受任何请求
public Result findAll(){
List<Dept> deptList=deptService.findAll();
return Result.success(deptList);
}
}
@Service //创建service层bean
public class DeptServiceImpl implements DeptService {
@Autowired //相当于 =
private DeptMapper deptMapper;
public List<Dept> findAll(){
return deptMapper.findAll();
}
}
@Mapper //自动创建接口类的实现类对象bean
public interface DeptMapper {
@Select("select * from dept order by update_time desc ")
List<Dept> findAll();
}
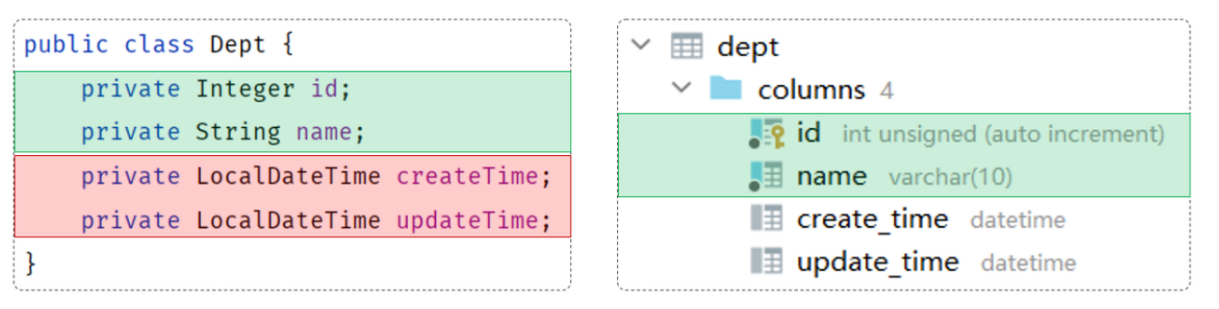
**注:**实体类和数据库变量命名规范 createTime(实体) create_time(数据库)
如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。
解决办法
1.手动结果映射 2.起别名 3.开启驼峰命名(推荐)
2.起别名
@Select("select id, name, create_time createTime, update_time updateTime from dept")
public List<Dept> findAll();
3.驼峰命名
规则: abc_xyz(数据库中属性名) => abcXyz (类中属性名)
在application.yml中做如下配置,开启开关。
mybatis:
configuration:
map-underscore-to-camel-case: true
前后端联调测试-nginx
前端项目部署:将我们之前打包的前端工程dist目录下得内容拷贝到nginx的html目录下
nginx-反向代理
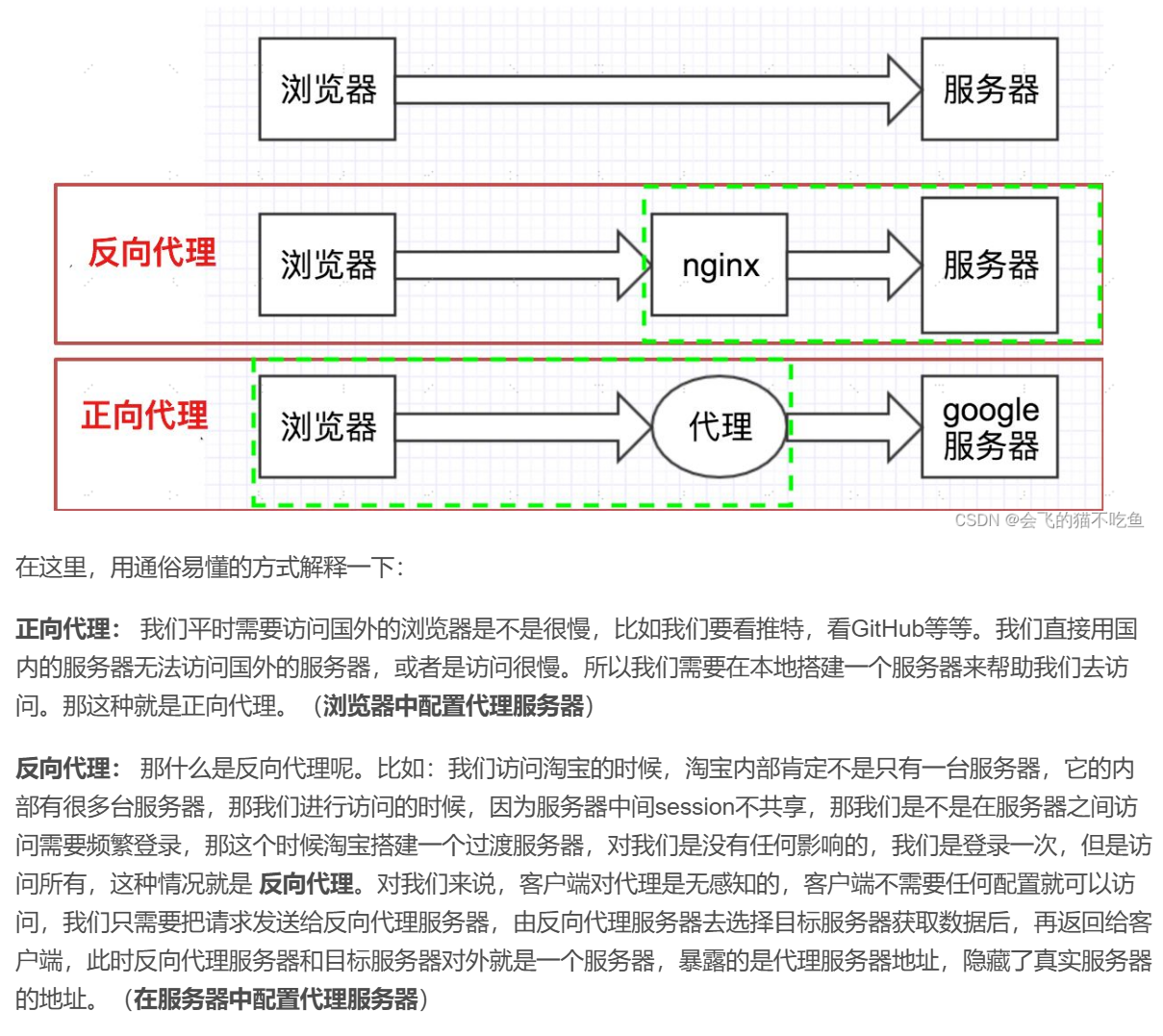
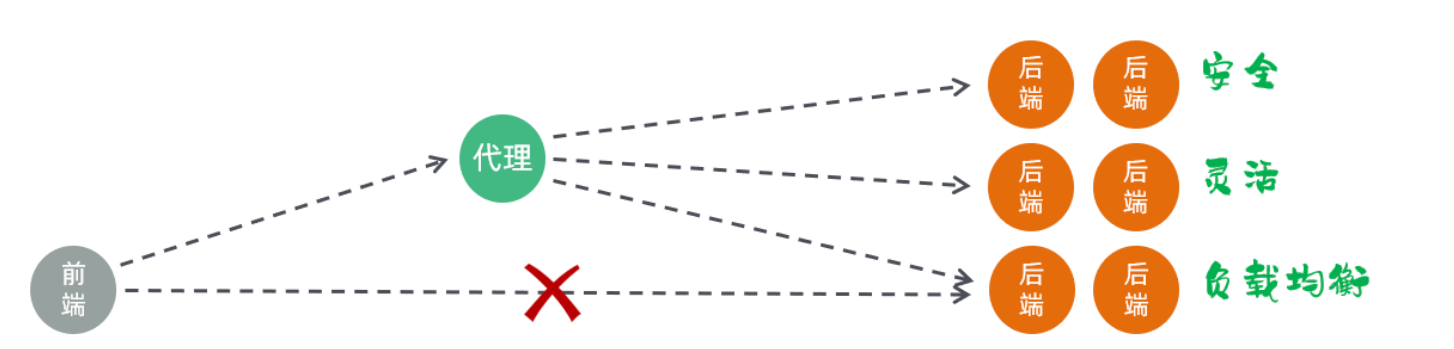
nginx反向代理的好处:
-
提高访问速度:因为nginx本身可以进行缓存,如果访问的同一接口,并且做了数据缓存,nginx就直接可把数据返回,不需要真正地访问服务端,从而提高访问速度。
-
安全:一般后端Tomcat服务器会搭建集群,把Tomcat服务器暴露给前端很危险,现在通过nginx就没有这个问题
-
灵活:基于nginx反向代理,后端增减服务器对于前端是无感知的
-
负载均衡(底层还是基于反向代理):把用户请求合理的分配的服务器上,以避免某台服务器过载,提高系统的整体性能和可靠性(可以很方便的实现后端tomcat的负载均衡操作。)
游览器访问http://localhost:90/dept -(访问的其实是nginx服务器)
->niginx的conf的location重写url为http://localhost:90/api/depts
->rewriter /api/depts 会被重写为 /depts
->proxy_pass 将nginx请求转发到这个服务器 http://localhost:8080
请求转发给后端Tomcat服务器
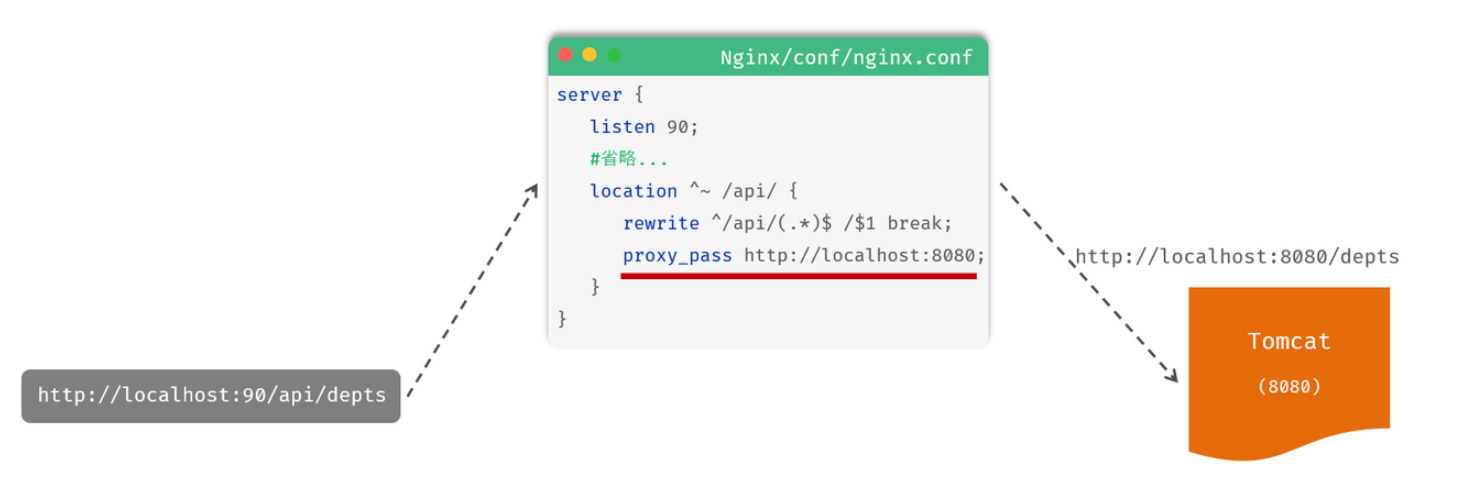
- location:用于定义匹配特定uri请求的规则。
- ^~ /api/:表示精确匹配,即只匹配以/api/开头的路径。
- rewrite:该指令用于重写匹配到的uri路径。
- proxy_pass:该指令用于代理转发,它将匹配到的请求转发给位于后端的指令服务器。
负载均衡是基于反向代理的,负载均衡就是多了多个后端服务器
配置方式
upstream webservers{
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}
server{
listen 80;
server_name localhost;
location /api/{
proxy_pass http://webservers/admin;#负载均衡
}
}
**proxy_pass:**该指令是用来设置代理服务器的地址,可以是主机名称,IP地址加端口号等形式。
**upstream:**如果代理服务器是一组服务器的话,我们可以使用upstream指令配置后端服务器组。
如上代码的含义是:监听80端口号, 然后当我们访问 http://localhost:80/api/…/…这样的接口的时候,它会通过 location /api/ {} 这样的反向代理到 http://webservers/admin,根据webservers名称找到一组服务器,根据设置的负载均衡策略(默认是轮询)转发到具体的服务器。
**注:**upstream后面的名称可自定义,但要上下保持一致。
nginx 负载均衡策略:
| 名称 | 说明 |
|---|---|
| 轮询 | 默认方式 |
| weight | 权重方式,默认为1,权重越高,被分配的客户端请求就越多 |
| ip_hash | 依据ip分配方式,这样每个访客可以固定访问一个后端服务 |
| least_conn | 依据最少连接方式,把请求优先分配给连接数少的后端服务 |
| url_hash | 依据url分配方式,这样相同的url会被分配到同一个后端服务 |
| fair | 依据响应时间方式,响应时间短的服务将会被优先分配 |
如:
upstream webservers{
server 192.168.100.128:8080 weight=90;
server 192.168.100.129:8080 weight=10;
}
删除部门
@RequestParam 请求参数注解
参数接受方式:
1.通过Spring提供的 @RequestParam 注解,将请求参数绑定给方法形参
@DeleteMapping("/depts")
public Result delete(@RequestParam("id") Integer deptId){
System.out.println("根据ID删除部门: " + deptId);
return Result.success();
}
加了@RequestParam注解,参数必须传递,默认为true,要么改默认为false
public Result delete(@RequestParam(value = "id",required = false) Integer deptId){}
- 更加推荐-如果请求参数名与形参变量名相同,直接定义方法形参即可接收。(省略@RequestParam)
@DeleteMapping("/depts")
public Result delete(Integer id){
System.out.println("根据ID删除部门: " + id);
return Result.success();
}
新增部门
@RequestBody :将HTTP请求的body部分绑定到方法参数上 接收json/xml格式
注意查询参数在url后面
post新增/put修改请求参数在请求体当中
注:
@Insert("insert into dept(name,create_time,update_time) values(#{name},#{createTime},#{updateTime})")
void insert(Dept dept);
如果在mapper接口中,需要传递多个参数,可以把多个参数封装到一个对象中。 在SQL语句中获取参数的时候,#{...} 里面写的是对象的属性名【注意是属性名,不是表的字段名】。
@PostMapping("/depts") //添加数据
public Result insert(@RequestBody Dept dept){
//@RequestRody 接收复杂类型 请求在请求体body当中
deptService.insert(dept);
return Result.success();
}
修改部门(查询回显->修改数据)
查询回显
/depts/1,/depts/2 这种在url中传递的参数,我们称之为路径参数
@PathVariable 接收路径参数
修改部门
代码
/*
* 修改部门
* */
@GetMapping("/depts/{id}") //修改数据 (查询回显)
public Result getid(@PathVariable Integer id){
Dept dept=deptService.getid(id);
return Result.success(dept);
}
@PutMapping("/depts") //修改数据 (修改部门)
public Result update(@RequestBody Dept dept){
deptService.update(dept);
return Result.success();
}
public Dept getid(Integer id){
Dept dept=deptMapper.getid(id);
return dept;
}
public void update(Dept dept){
dept.setUpdateTime(LocalDateTime.now());
deptMapper.update(dept);
}
@Select("select * from dept where id=#{id}")
public Dept getid(Integer id);
@Update("update dept set name=#{name},update_time=#{updateTime} where id=#{id} ")
public void update(Dept dept);
把这个公共的路径 /depts 抽取到类上的,那在各个方法上,就可以省略了这个 /depts 路径。 代码如下:

一个完整请求路径:类上的 @RequestMapping 的value属性 拼接上 方法上各自对应@RequestMapping的value属性。
总的代码
//================================ Controller层 ====================================
@RestController
public class DeptController {
@Autowired
private DeptService deptService;
//@RequestMapping(value = "/depts",method = RequestMethod.GET)
@GetMapping("/depts") //查询部门
public Result findAll(){
List<Dept> deptList=deptService.findAll();
return Result.success(deptList);
}
@DeleteMapping("/depts1") //删除数据 参数接收方式
public Result delete1(@RequestParam(value = "id",required = false) Integer idd){
//@RequestParam 接收普通类型参数 请求在url后面
deptService.delete(idd);
return Result.success();
}
@DeleteMapping("/depts") //删除数据
public Result delete(Integer id){ //当参数名和请求名一样,@RequestParam可以省略
deptService.delete(id);
return Result.success();
}
@PostMapping("/depts") //添加数据
public Result insert(@RequestBody Dept dept){
//@RequestRody 接收复杂类型 请求在请求体body当中
deptService.insert(dept);
return Result.success();
}
@GetMapping("/depts/{id}") //修改数据 (查询回显)
public Result getid(@PathVariable Integer id){
Dept dept=deptService.getid(id);
return Result.success(dept);
}
@GetMapping("/depts1/{id}")
public Result getid1(@PathVariable("id")Integer idd){ //当请求参数和属性名不一样,不能省略
Dept dept=deptService.getid(idd);
return Result.success(dept);
}
@GetMapping("/depts2/{id}/{sta}") //当接收多个路径参数
public Result getid(@PathVariable Integer id,@PathVariable Integer std){
Dept dept=deptService.getid(id);
return Result.success(dept);
}
@PutMapping("/depts") //修改数据 (修改部门)
public Result update(@RequestBody Dept dept){
deptService.update(dept);
return Result.success();
}
}
//=============================== Service层 ==============================================
@Service
public class DeptServiceImpl implements DeptService {
@Autowired
private DeptMapper deptMapper;
public List<Dept> findAll(){
return deptMapper.findAll();
}
public void delete(Integer id){
deptMapper.delete(id);
}
public void insert(Dept dept){
dept.setCreateTime(LocalDateTime.now());
dept.setUpdateTime(LocalDateTime.now());
deptMapper.insert(dept);
}
public Dept getid(Integer id){
Dept dept=deptMapper.getid(id);
return dept;
}
public void update(Dept dept){
dept.setUpdateTime(LocalDateTime.now());
deptMapper.update(dept);
}
}
//================================== Mapper层 ==============================================
@Mapper
public interface DeptMapper {
@Select("select * from dept order by update_time desc ")
List<Dept> findAll();
@Delete("delete from dept where id=#{id}")
public void delete(Integer id);
@Insert("insert into dept( name, create_time, update_time) values(#{name},#{createTime},#{updateTime})")
public void insert(Dept dept);
@Select("select * from dept where id=#{id}")
public Dept getid(Integer id);
@Update("update dept set name=#{name},update_time=#{updateTime} where id=#{id} ")
public void update(Dept dept);
}
表明参数从url后面来还是从请求体中来,还是从路径参数中来
get和post
-
注解大全
- @RequestMapping:将请求参数映射到处理器方法上
- 还有
@GetMapping、@PostMapping(增加) ,@PutMapping(修改)、@DeleteMapping等快捷注解 - 可以抽取公共路径的提取到类上来写 写个@RequestMapping
- 还有
- @RestController (通常使用) :1.处理 HTTP 请求 2.将方法返回值作为 HTTP 响应体返回给前端:
- 有@Controller和@ResponseBody组成
- @ResponseBody:把后端方法返回值作为HTTP响应体返回给前端
- @Controller:处理HTTP请求
接收不同类型参数注解
-
@RequestParam:接收url参数
-
不能省略情况:1.形参不是简单类型时候() 2.接收参数和形参名不一致
eg: 复杂类型springmvc会通过其它方式请求注解,导致报错
请求参数样例:
/emps?ids=1,2,3
public Result delete(@RequestParam List ids){} -
默认值时候(defaultValue):@RequestParam(defaultValue = “1”
eg:public Result page(@RequestParam(defaultValue = “1”) Integer page ){}
-
参数必须传递时(value=“参数名”,required=false):默认为true必须传递参数
-
-
@PathVariable :接收路径参数(“/emps/1这种”)
-
@RequestBody:接收json等复杂数据结构参数
- @RequestMapping:将请求参数映射到处理器方法上
| 特性 | @RequestParam | @PathVariable | @RequestBody |
|---|---|---|---|
| 用途 | 获取URL查询参数 | 获取URL路径参数(/users/{id}这种) | 接收请求体中的复杂数据结构 |
| 常用请求方法 | 主要用于GET、DELETE,也可用于POST、PUT | 可用于任何请求方法 | 主要用于POST、PUT |
| 数据来源 | 请求的查询字符串或表单数据 | URL路径 | 请求的body |
| 数据格式 | 简单类型(如字符串、数字)或字符串集合 | 路径变量,通常是简单类型 | JSON、XML或其他序列化数据 |
| 参数位置 | URL中或表单数据中 | URL路径中 | 请求体中 |
| 示例 | @RequestParam("id") int id | @PathVariable("id") int id | @RequestBody MyObject obj |
| 请求路径(网址中的) | /emps | /emps/{id} /emps/2 网址中输入这样 | /emps |
| 请求参数样例 | 1. /emps 2. /emps?ids=1,2,3(复杂类型)这个注解不能省略 | 请求参数样例/emps/1 | application/json |
注:
-
请求路径PK参数:http://localhost:8080/depts?id=1 像这种, /depts是请求路径 id=1是参数
-
请求路径(一般在查询回显修改操作中)
-
/users/{id} ,{id}只是一个占位符,要被1 2这些代替,但是网址中要输入 /users/1
-
路径参数的请求参数样这样 /depts/1
-
-
@RequestParam
-
中当传递的参数名和形参名称相同的时候,这个注解可以省略
-
但是当形参不是简单类型的时候@RequestParam不能省略
-
eg:public Result delete(@RequestParam List ids){}
- 注意:@RequestBody和@ResponseBody区别
@Slf4j
@RequestMapping("/report")
@RestController
/*
* 用来统计员工职位信息
* */
public class ReportController {
@Autowired
private ReportService reportService;
@GetMapping("/empJobData")
public Result getEmpJobData(){
JobOption jobOption =reportService.getEmpJobData();
return Result.success(jobOption);
}
}
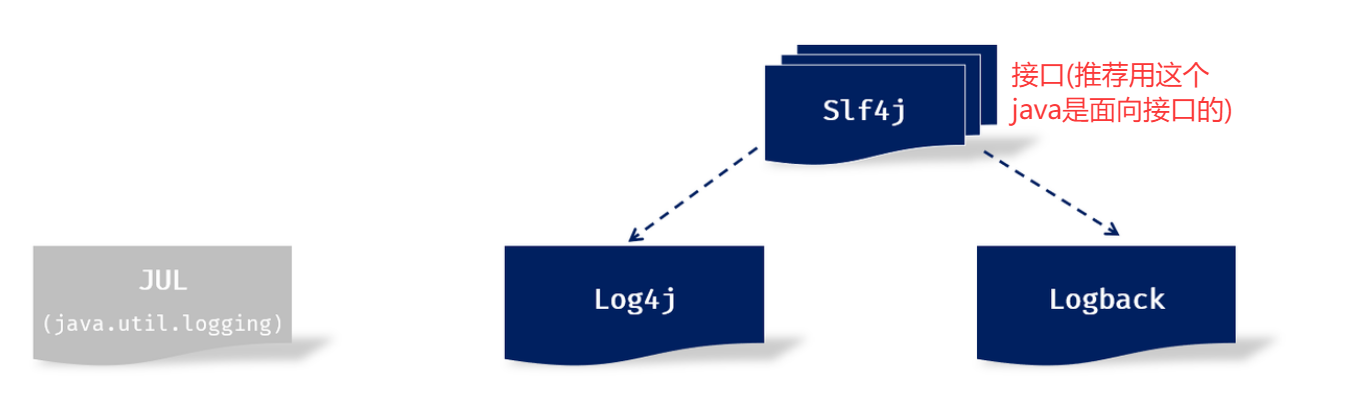
日志技术
- 为什么要在程序中记录日志呢?
- 便于追踪应用程序中的数据信息、程序的执行过程。
- 便于对应用程序的性能进行优化。
- 便于应用程序出现问题之后,排查问题,解决问题。
- 便于监控系统的运行状态。
1. 准备工作:引入logback的依赖(springboot中无需引入,在springboot中已经传递了此依赖)
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.4.11</version>
</dependency>
2.引入配置文件 logback.xml (资料中已经提供,拷贝进来,放在 src/main/resources 目录下; 或者直接AI生成)
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 控制台输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d 表示日期,%thread 表示线程名,%-5level表示级别从左显示5个字符宽度,%logger显示日志记录器的名称, %msg表示日志消息,%n表示换行符 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<!-- <!– 系统文件输出 –>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!– 日志文件输出的文件名, %i表示序号 –>
<FileNamePattern>D:/tlias-%d{yyyy-MM-dd}-%i.log</FileNamePattern>
<!– 最多保留的历史日志文件数量 –>
<MaxHistory>30</MaxHistory>
<!– 最大文件大小,超过这个大小会触发滚动到新文件,默认为 10MB –>
<maxFileSize>10MB</maxFileSize>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!–格式化输出:%d 表示日期,%thread 表示线程名,%-5level表示级别从左显示5个字符宽度,%msg表示日志消息,%n表示换行符 –>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50}-%msg%n</pattern>
</encoder>
</appender>-->
<!-- 日志输出级别 -->
<root level="INFO">
<appender-ref ref="STDOUT" />
<!-- <appender-ref ref="FILE" />-->
</root>
</configuration>
3.记录日志:定义日志记录对象Logger,记录日志
public class A {
private final Logger log= LoggerFactory.getLogger(A.class); //这个是类的字节码文件
@Test
public void testLog(){
log.debug("开始计算...");
int sum = 0;
int[] nums = {1, 5, 3, 2, 1, 4, 5, 4, 6, 7, 4, 34, 2, 23};
for (int i = 0; i < nums.length; i++) {
sum += nums[i];
}
log.info("计算结果为: "+sum);
log.debug("结束计算...");
}
}
日志级别指的是日志信息的类型,日志都会分级别,常见的日志级别如下(优先级由低到高):
| 日志级别 | 说明 | 记录方式 |
|---|---|---|
| trace | 追踪,记录程序运行轨迹 【使用很少】 | log.trace(“…”) |
| debug | 调试,记录程序调试过程中的信息,实际应用中一般将其视为最低级别 【使用较多】 | log.debug(“…”) |
| info | 记录一般信息,描述程序运行的关键事件,如:网络连接、io操作 【使用较多】 | log.info(“…”) |
| warn | 警告信息,记录潜在有害的情况 【使用较多】 | log.warn(“…”) |
| error | 错误信息 【使用较多】 | log.error(“…”) |
可以在配置文件logback.xml中,灵活的控制输出那些类型的日志。(大于等于配置的日志级别的日志才会输出)
<!-- 日志输出级别 -->
<root level="info">
<!--输出到控制台-->
<appender-ref ref="STDOUT" />
<!--输出到文件-->
<appender-ref ref="FILE" />
</root>
springboot中日志应用(springboot提供@Slf4j)
@Slf4j
//springboot提供注解来代替原本的private static Logger log = LoggerFactory. getLogger(Xxx. class);
@RequestMapping("/depts")
@RestController
public class DeptController {
@Autowired
private DeptService deptService;
@GetMapping
public Result list(){
//System.out.println("查询部门列表");
log.info("查询部门列表");
List<Dept> deptList = deptService.findAll();
return Result.success(deptList);
}
@DeleteMapping
public Result delete(Integer id){
//System.out.println("根据id删除部门, id=" + id);
log.info("根据id删除部门, id: {}" , id);
//运行时这个{} 会把后面的id放进{}中
//要写id,保证日志信息的完整性
deptService.deleteById(id);
return Result.success();
}
}
员工管理
分页查询
分页查询插件
原始方式(不推荐)
@Slf4j
@RequestMapping("/emps")
@RestController
public class EmpController {
@Autowired
private EmpService empService;
@RequestMapping
public Result page(@RequestParam(defaultValue = "1") Integer page ,
@RequestParam(defaultValue = "10") Integer pageSize){
log.info("查询员工信息, page={}, pageSize={}", page, pageSize);
PageResult pageResult=empService.page(page,pageSize);
return Result.success(pageResult);
}
}
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpMapper empMapper;
public PageResult page(Integer page,Integer pageSize){
Long total=empMapper.count();
Integer start = (page - 1) * pageSize;
List<Emp> empList = empMapper.list(start, pageSize);
return new PageResult(total,empList);
}
}
@Mapper
public interface EmpMapper {
// @Select("select e.*,d.name as deptName from emp e left join dept d on e.dept_id=d.id;")
// public List<Emp> list();
@Select("select count(*) from emp e left join dept d on e.dept_id=d.id")
public Long count();
@Select("select e.*,d.name as deptName from emp e left join dept d on e.dept_id=d.id order by e.update_time limit #{start},#{pageSize}")
public List<Emp> list(Integer start,Integer pageSize);
}
注:@RequestParam(defaultValue=“默认值”) //设置请求参数默认值
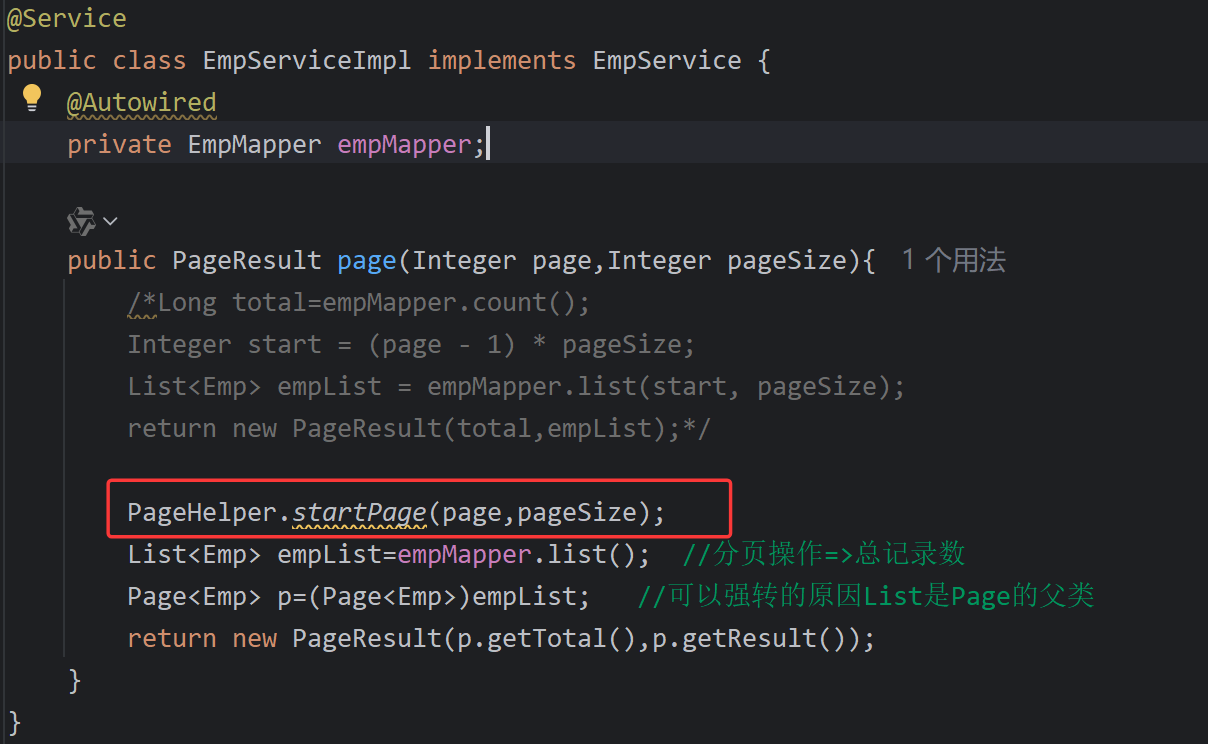
基于PageHelper分页插件完成分页操作(推荐)
PageHelper是第三方提供的Mybatis框架中的一款功能强大、方便易用的分页插件,支持任何形式的单标、多表的分页查询。
对比

步骤
1.配置PageHepler的依赖
<!--分页插件PageHelper-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.7</version>
</dependency>
2.代码
@Slf4j
@RequestMapping("/emps")
@RestController
public class EmpController {
@Autowired
private EmpService empService;
@RequestMapping
public Result page(@RequestParam(defaultValue = "1") Integer page ,
@RequestParam(defaultValue = "10") Integer pageSize){
log.info("查询员工信息, page={}, pageSize={}", page, pageSize);
PageResult pageResult=empService.page(page,pageSize);
return Result.success(pageResult);
}
}
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpMapper empMapper;
public PageResult page(Integer page,Integer pageSize){
PageHelper.startPage(page,pageSize);
List<Emp> empList=empMapper.list(); //分页操作=>总记录数
Page<Emp> p=(Page<Emp>)empList; //可以强转的原因List是Page的父类
return new PageResult(p.getTotal(),p.getResult());
}
}
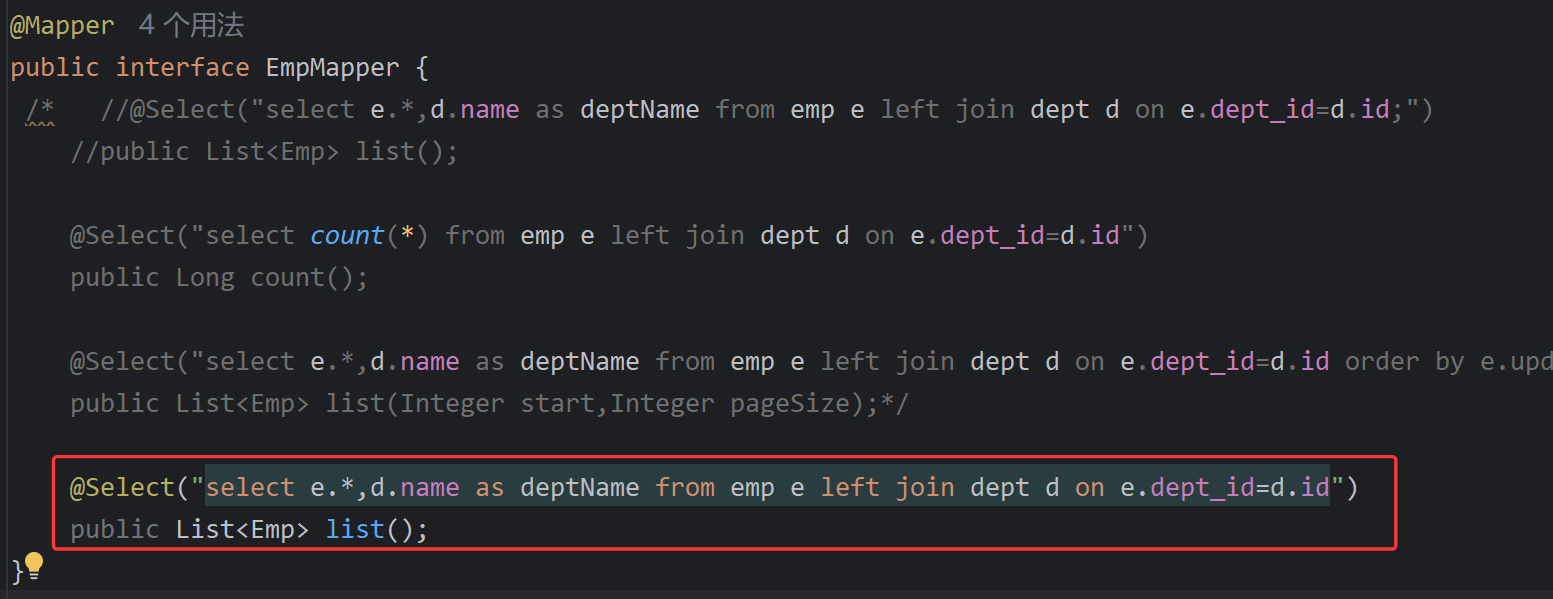
@Mapper
public interface EmpMapper {
@Select("select e.*,d.name as deptName from emp e left join dept d on e.dept_id=d.id")
public List<Emp> list();
}
实现机制
1.在 SQL 执行之前,PageHelper 会根据传入的分页参数(page 和 pageSize)动态修改 SQL。(这两个参数是通过 PageHelper.startPage(page, pageSize) 方法传入的:)
2.拦截SQL语句
3.改造SQL语句,改造对应的总记录数sql和分页sql语句
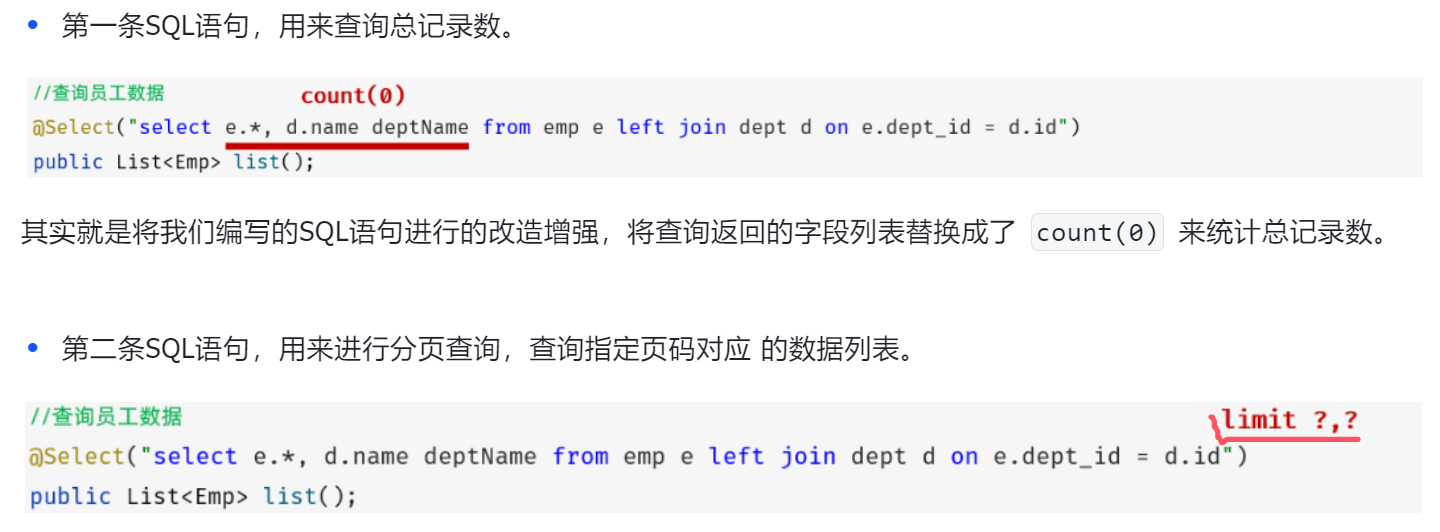 注:所以使用PageHelper的sql语句结尾一定不要加分号(;)因为改造sql语句(如limit)是拼接在原先sql语句之后的
注:所以使用PageHelper的sql语句结尾一定不要加分号(;)因为改造sql语句(如limit)是拼接在原先sql语句之后的
4.把两个sql语句封装在函数返回值当中
注意:
- PageHelper实现分页查询时,SQL语句的结尾一定一定一定不要加分号(😉.。
- PageHelper只会对紧跟在其后的第一条SQL语句进行分页处理。

这部分用到的
条件查询
基础代码-分页+条件查询
@Slf4j
@RequestMapping("/emps")
@RestController
public class EmpController {
@Autowired
private EmpService empService;
/*
* 分页+条件查询
* */
@GetMapping
public Result page(EmpQueryParam empQueryParam){
//1.@RequestParam已经省略 2.通过对象接收较多参数,参数增多,直接修改类就行
PageResult pageResult=empService.page(empQueryParam);
//这一层不操作PageResult类型封装,由service层操作
return Result.success(pageResult);
}
}
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpMapper empMapper;
public PageResult page(EmpQueryParam empQueryParam){ PageHelper.startPage(empQueryParam.getPage(),empQueryParam.getPageSize());
Page<Emp> p=(Page<Emp>) empMapper.list(empQueryParam);
//sql查询结果是List<Emp>类型
//强转为Page<Emp> Page是List子类,所以可以强制转换
/*List<Emp> empList=empMapper.list(empQueryParam);
Page<Emp> p=(Page<Emp>)empList;*/
return new PageResult(p.getTotal(),p.getResult());
//对PageResult类型封装
}
}
@Mapper
public interface EmpMapper {
public List<Emp> list(EmpQueryParam empQueryParam);
}
//============================== xml配置文件 =============================================
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.mapper.EmpMapper">
<select id="list" resultType="com.itheima.pojo.Emp">
select e.*, d.name as deptName
from emp e
left join dept d on e.dept_id = d.id
where e.name like concat('%',#{name},'%') and e.gender=#{gender} and e.entry_date between #{begin} and #{end}
order by e.update_time desc
</select>
</mapper>
小技巧:
配置文件怎么调的
因为sql语句太复杂可以不用注解方式而用xml方式来配置
注:
-
@DateTimeFormat :接收的日期格式
-
‘%#{ }%’ 报错
# 不能出现在 ''
(即:底层 ?不能出现在' '内会报错)
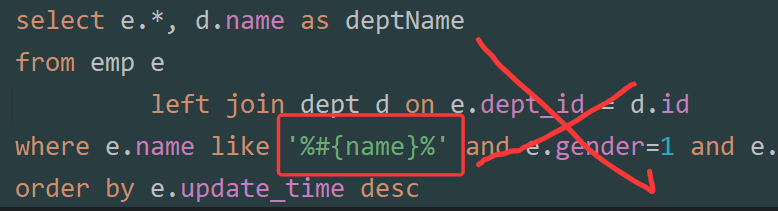 解决办法: concat连接 e.name like concat('%',#{name},'%')
解决办法: concat连接 e.name like concat('%',#{name},'%')
优化代码
1.请求参数太多,通过形参对象
2.基于mybatis提供的动态SQL,提供可选可不选
@Slf4j
@RequestMapping("/emps")
@RestController
public class EmpController {
@Autowired
private EmpService empService;
@GetMapping
public Result page(EmpQueryParam empQueryParam){
//1.@RequestParam已经省略 2.通过对象接收较多参数,参数增多,直接修改类就行
PageResult pageResult=empService.page(empQueryParam);
//这一层不操作PageResult类型封装,由service层操作
return Result.success(pageResult);
}
}
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpMapper empMapper;
public PageResult page(EmpQueryParam empQueryParam){
PageHelper.startPage(empQueryParam.getPage(),empQueryParam.getPageSize());
Page<Emp> p=(Page<Emp>) empMapper.list(empQueryParam);
//sql查询结果是List<Emp>类型
//强转为Page<Emp> Page是List子类,所以可以强制转换
/*List<Emp> empList=empMapper.list(empQueryParam);
Page<Emp> p=(Page<Emp>)empList;*/
return new PageResult(p.getTotal(),p.getResult());
//对PageResult类型封装
}
}
@Mapper
public interface EmpMapper {
// @Select("select e.*,d.name as deptName from emp e left join dept d on e.dept_id=d.id order by e.update_time desc")
public List<Emp> list(EmpQueryParam empQueryParam);
}
//============================== xml配置文件 =============================================
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--全类名-->
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--全类名-->
<mapper namespace="com.itheima.mapper.EmpMapper"> <!-- 同包同名-->
<select id="list" resultType="com.itheima.pojo.Emp">
/* 函数名 + 单挑sql返回的类型全类名*/
select e.*, d.name as deptName
from emp e
left join dept d on e.dept_id = d.id
/* 动态sql
if 判断sql语句是否输出
where 自动化去除and和or
*/
<where>
<if test="name!=null and name!=''">
e.name like concat('%',#{name},'%')
</if>
<if test="gender!=null">
and e.gender=#{gender}
</if>
<if test="begin!=null and end!=null">
and e.entry_date between #{begin} and #{end}
</if>
</where>
order by e.update_time desc
</select>
</mapper>
注:
-
<if>:判断条件是否成立,如果条件为true,则拼接SQL。 -
还有mysql自带if语句 if(条件, 条件为true取值, 条件为false取值) eg: if(gender=1,‘男’,‘女’)
-
<where>:根据查询条件,来生成where关键字,并会自动去除条件前面多余的and或or。
两个日志之间的区别 StdOutImpl PK logback
StdOutImpl更适合开发和测试环境,配置简单,输出到控制台。- Logback 提供更强大的日志管理功能,适用于生产环境,配置灵活,支持多种日志策略
新增员工
这个新增员工要进行两个操作,一个基本信息,一个工作经历,当controller层接收到前端json格式数据后调用service层
service层主要有两个功能,1.调Mapper层 2.保存员工基本信息 3.保存员工工作经历
注: 员工工作经历数据不是从Controller层获取的,而是从员工信息中获取工作经历
Mapper层:进行员工信息增加 进行员工工作经历增加
//========================== Controller ===============================================
@Slf4j
@RequestMapping("/emps")
@RestController
public class EmpController {
@Autowired
private EmpService empService;
//新增员工
@PostMapping
public Result save(@RequestBody Emp emp){ //因为接收的是json
empService.insert(emp);
return Result.success();
}
}
//============================= Service =========================================
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpMapper empMapper;
@Autowired
private EmpExprMapper empExprMapper;
public void insert(Emp emp){
//1.补全基础属性
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//员工基本信息
empMapper.insert(emp); //返回的信息包括 基本信息+工作信息
//员工工作经历
Integer empId=emp.getId();
List<EmpExpr>exprList=emp.getExprList(); //这个是获取工作经历数据 不是从前端直接传递过来的
if(!CollectionUtils.isEmpty(exprList)){ //不为空为false 工作经历可能为空
/* CollectionUtils.isEmpty(函数)
判断函数是否为空, 不为空:false 为空:true
*/
exprList.forEach(empExpr->
empExpr.setEmpId(empId));
empExprMapper.insert(exprList);
}
}
}
//============================= Mapper =========================================
//基本员工信息====================================
@Mapper
public interface EmpMapper {
public List<Emp> list(EmpQueryParam empQueryParam);
/* @Options注解 (mybatis提供的) :用来获取主键的
useGeneratedKeys: 开启功能
keyProperty :获取的主键设置到Emp类型对象中的 id
*/
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into emp(username, name, gender, phone, job, salary, image, entry_date, dept_id, create_time, update_time) " +
"values (#{username},#{name},#{gender},#{phone},#{job},#{salary},#{image},#{entryDate},#{deptId},#{createTime},#{updateTime})")
void insert(Emp emp);
}
//员工工作经历=====================================
@Mapper
public interface EmpExprMapper {
void insert(List<EmpExpr> exprList);
}
//工作经历的xml配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--全类名-->
<mapper namespace="com.itheima.mapper.EmpExprMapper"> <!-- 同包同名-->
<insert id="insert">
insert into emp_expr (emp_id, begin, end, company, job) values
/* foreach标签
collection:集合名称
item:遍历出来的集合名称
separator:遍历出来的分隔符
open:遍历开始前拼接的片段
close:遍历结束后拼接的片段
*/
<foreach collection="exprList" item="expr" separator=",">
(#{expr.empId}, #{expr.begin}, #{expr.end}, #{expr.company}, #{expr.job})
</foreach>
</insert>
</mapper>
批量操作 insert into SQL语句是啥
insert into emp_expr (emp_id, begin, end, company, job)
values
(1, '2024-01-01', '2024-01-13', '12', '132'),
(2, '2024-02-02', '2024-02-23', '232', '232');
工作经历可以为空,所以这里要判断
CollectionUtils.isEmpty(函数)
判断这个集合是否为空 true:为空 false:不为空
mybatis提供的功能
-
@Options注解:获取主键
-
useGeneratedKeys = true告诉MyBatis在插入操作后使用JDBC的getGeneratedKeys方法来获取数据库自动生成的主键值。 -
keyProperty = "id"指定了检索到的主键值应该设置到Employee对象的id属性中。
-
-
标签:循环标签
-
<foreach collection="集合名称" itrm="遍历出来元素名称" separator="遍历后的分隔符"> </foreach> /* open:遍历开始前拼接的片段 close:遍历结束后拼接的片段 */
-
事务管理
为什么需要事务:因为网络等原因导致数据存储异常,为了确保数据的一致性和完整性
完整性: 数据独一无二,主键约束 (实体完整性,参照完整性,用户自定义完整性 )
一致性:要么全都执行,要么一个都不执行 ACID(原子性,一致性,隔离性,持久性)
事务概念:事务是一组操作的集合,要么同时成功,要么同时失败
事务操作
- 在操作之前开启事务 strat transaction/begin
- 所有操作全部执行成功,提交事务 commit
- 这组操作中,有任何一个操作执行失败,都应该回滚事务 rollback
事务四大特性ACID
- 原子性:事务是不可再分的工作单元,要么全做,要么全不做
- 一致性:事务完成之后数据要保持一致性状态
- 如果事务执行成功,那么数据库所有变化将生效
- 如果事务执行失败,那么数据库所有变化将回滚,返回到原始状态
- 隔离性:一个事务不能被其它事务打扰,多个并发执行的事务之间相互隔离
- 持久性:事务一旦提交/回滚,它对数据库的改变是永久性的
当开启事务,执行两个sql语句后,数据不能保存,当执行提交事务语句后,数据才能保存
-- 开启事务
start transaction; / begin;
-- 1. 保存员工基本信息
insert into emp values (39, 'Tom', '123456', '汤姆', 1, '13300001111', 1, 4000, '1.jpg', '2023-11-01', 1, now(), now());
-- 2. 保存员工的工作经历信息
insert into emp_expr(emp_id, begin, end, company, job) values (39,'2019-01-01', '2020-01-01', '百度', '开发'), (39,'2020-01-10', '2022-02-01', '阿里', '架构');
-- 提交事务(全部成功)
commit;
-- 回滚事务(有一个失败)
rollback;
springboot事务管理
注解:@Transactional
**作用:**就是在当前这个方法执行开始之前来开启事务,方法执行完毕之后提交事务。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作。
**位置:**业务层的方法上、类上、接口上
- 方法上:当前方法交给spring进行事务管理(一般用在方法上:一般方法会对数据进行多次操作)
- 类上:当前类中所有的方法都交由spring进行事务管理
- 接口上:接口下所有的实现类当中所有的方法都交给spring 进行事务管理
**注:**一般事务管理用在业务层(Service层),因为业务层处理多个数据
开启事务日志
#spring事务管理日志
logging:
level:
org.springframework.jdbc.support.JdbcTransactionManager: debug
开启事务注解
@Transactional //开启事务,加在方法上
@Override
public void save(Emp emp) {
//1.补全基础属性
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//2.保存员工基本信息
empMapper.insert(emp);
int i = 1/0;
//3. 保存员工的工作经历信息 - 批量
Integer empId = emp.getId();
List<EmpExpr> exprList = emp.getExprList();
if(!CollectionUtils.isEmpty(exprList)){
exprList.forEach(empExpr -> empExpr.setEmpId(empId));
empExprMapper.insertBatch(exprList);
}
}

事务进阶
@Transactional 开启事务
- 异常回滚的属性:
rollbackFor:事务失败后回滚属性(运行异常回滚,编译异常回滚) - 事务传播行为:
propagation
rollbackFor:回滚属性
这个if()下面的代码执行不了,因为向上默认是编译时候异常才回滚
- 在Spring的事务管理中,默认只有运行时异常 RuntimeException才会回滚。
- 如果还需要回滚指定类型的异常,可以通过rollbackFor属性来指定。
@Transactional(rollbackFor = Exception.class) //
@Override
public void save(Emp emp) throws Exception {
//1.补全基础属性
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//2.保存员工基本信息
empMapper.insert(emp);
//int i = 1/0;
if(true){
throw new Exception("出异常啦....");
}
//3. 保存员工的工作经历信息 - 批量
Integer empId = emp.getId();
List<EmpExpr> exprList = emp.getExprList();
if(!CollectionUtils.isEmpty(exprList)){
exprList.forEach(empExpr -> empExpr.setEmpId(empId));
empExprMapper.insertBatch(exprList);
}
}
@Transactional属性 :
propagation:事务的传播行为
什么是事务的传播行为呢?
- 就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制。
| 属性值 | 含义 |
|---|---|
| REQUIRED | 【默认值】需要事务,有则加入,无则创建新事务 |
| REQUIRES_NEW | 需要新事务,无论有无,总是创建新事务 一般用在无论成功失败都要记录 |
案例
**需求:**在新增员工信息时,无论是成功还是失败,都要记录操作日志。
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpExprMapper empExprMapper;
@Autowired
private EmpLogService empLogService;
//事务的传播行为,一个事务方法调用另一个事务方法的
//增加基本员工信息 (基本信息+员工经历)
@Transactional(rollbackFor = Exception.class) //开启事务
//rollbackFor 回滚属性(运行异常回滚,编译异常回滚) Exception 所有异常都回滚
public void insert(Emp emp){
try {
//1.补全基础属性
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//员工基本信息
empMapper.insert(emp); //返回的信息包括 基本信息+工作信息
int i=1/0; //测试事务的
//员工工作经历
Integer empId=emp.getId();
List<EmpExpr>exprList=emp.getExprList(); //这个是获取工作经历数据 不是从前端直接传递过来的
if(!CollectionUtils.isEmpty(exprList)){ //不为空为false 工作经历可能为空
/* CollectionUtils.isEmpty(函数)
判断函数是否为空, 不为空:false 为空:true
*/
exprList.forEach(empExpr->
empExpr.setEmpId(empId));
empExprMapper.insert(exprList);
}
} finally {
EmpLog empLog=new EmpLog(null, LocalDateTime.now(), emp.toString());
empLogService.insertLog(empLog);
}
}
}
@Service
public class EmpLogServiceImpl implements EmpLogService {
@Autowired
private EmpLogMapper empLogMapper;
@Transactional(propagation = Propagation.REQUIRES_NEW)
//@Transactional属性:REQUIRES_NEW 不管有没有事务,都创建新的事务
@Override
public void insertLog(EmpLog empLog) {
empLogMapper.insert(empLog);
}
}
当执行try语句,会执行员工基本信息保存,但是当执行到int i=1/0的时候,会报错,然后执行finally里面的
因为finally里面的方法设置了事务属性为REQUIRES_NEW,所有,不管有没有事务,都会给类EmpLogServiceImpl中方法insertLog创建一个新的事务(因为这里设置的属性是REQUIRES_NEW,不管有没有事务,都创建新的事务)
如果类EmpLogServiceImpl中方法insertLog中事务属性使用的是默认的REQUIRES,那执行当EmpServiceImpl类中方法事务的时候,调用类EmpLogServiceImpl中方法i事务,这时候是默认REQUIRES,不会创建新的事务,两个方法都处于一个事务中,因为事务中有异常所有执行不了
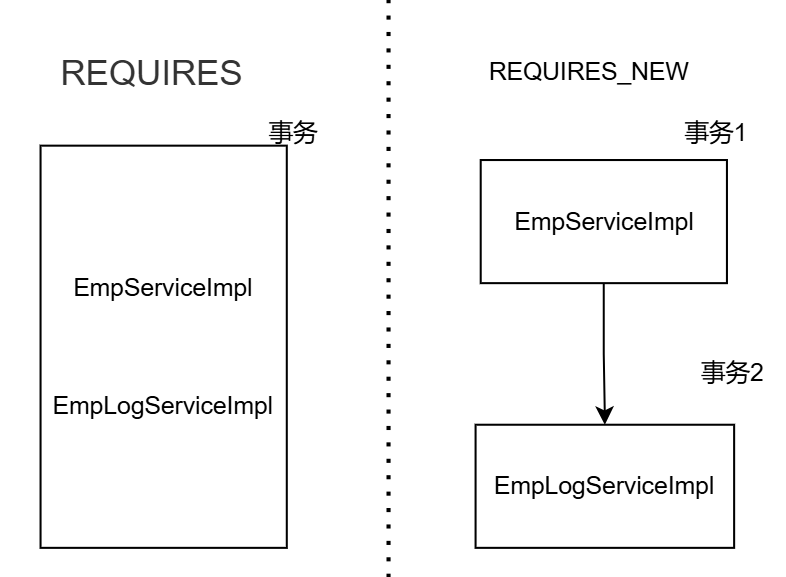 默认REQUIRES:两个方法都处于一个事务中,EmpServiceImpl中有异常导致EmpLogServiceImpl中方法也执行不了
默认REQUIRES:两个方法都处于一个事务中,EmpServiceImpl中有异常导致EmpLogServiceImpl中方法也执行不了
REQUIRES_NEW:两个方法处于各自事务当中,事务1中的异常不影响事务2中的执行
注:
- **REQUIRED:**大部分情况下都是用该传播行为即可。
- **REQUIRES_NEW:**当我们不希望事务之间相互影响时,可以使用该传播行为。比如:下订单前需要记录日志,不论订单保存成功与否,都需要保证日志记录能够记录成功。
操作两张表(基本信息表和工作经历表)会涉及到事务管理
文件上传
总结
项目中使用阿里云OSS
- 使用了配置类+@Bean
使用阿里云OSS
<!--阿里云OSS依赖-->
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.17.4</version>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>1.1.1</version>
</dependency>
<!-- no more than 2.3.3-->
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.3</version>
</dependency>
set OSS_ACCESS_KEY_ID=LTAI5tE3gVp2nBHspAjhTGWL
set OSS_ACCESS_KEY_SECRET=kzKuBTj0rwJWgVKfixkFniWD85rFUa
application.yml
spring:
profiles:
active: dev #设置环境 dev:开发环境 prod:生产环境
#阿里云OSS 参数配置
sky:
aliyun:
oss:
endpoint: ${sky.alioss.endpoint}
access-key-id: ${sky.alioss.access-key-id}
access-key-secret: ${sky.alioss.access-key-secret}
bucket-name: ${sky.alioss.bucket-name}
application-dev.yml
- 数据库连接信息:开发环境可能连接本地数据库,而生产环境连接远程数据库,所以需要dev文件
sky:
alioss:
endpoint: oss-cn-shanghai.aliyuncs.com
access-key-id: LTAI5tE3gVp2nBHspAjhTGWL
access-key-secret: kzKuBTj0rwJWgVKfixkFniWD85rFUa
bucket-name: java-ai-23515
配置
/*
* 阿里云OSS配置属性类
* */
@Component
@ConfigurationProperties(prefix = "sky.alioss")
@Data
public class AliOssProperties {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
}
假设阿里云为第三方,使用@Bean来创建对象
/**
* 阿里云文件上传配置
*/
@Configuration
public class OssConfiguration {
@Bean
public AliOssUtil aliOssUtil(AliOssProperties aliOssProperties){
return new AliOssUtil(aliOssProperties.getEndpoint(),
aliOssProperties.getAccessKeyId(),
aliOssProperties.getAccessKeySecret(),
aliOssProperties.getBucketName());
}
}
阿里云工具类
/**
* 阿里云OSS工具类
*/
@Data
@AllArgsConstructor
@Slf4j
public class AliOssUtil {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
/**
* 文件上传
*
* @param bytes
* @param objectName
* @return
*/
public String upload(byte[] bytes, String objectName) {
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
try {
// 创建PutObject请求。
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(bytes));
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
//文件访问路径规则 https://BucketName.Endpoint/ObjectName
StringBuilder stringBuilder = new StringBuilder("https://");
stringBuilder
.append(bucketName)
.append(".")
.append(endpoint)
.append("/")
.append(objectName);
log.info("文件上传到:{}", stringBuilder.toString());
return stringBuilder.toString();
}
}
使用阿里云
/*
* 通用接口
* */
@RestController
@RequestMapping("/admin/common")
public class CommonController {
@Autowired
private AliOssUtil aliOssUtil;
/**
* 文件上传
* @param file
* @return {@code Result }
*/
@PostMapping("/upload")
public Result upload(MultipartFile file) throws Exception {
String originalFilename= file.getOriginalFilename(); //获取文件名
String endName =originalFilename.substring(originalFilename.lastIndexOf(".")); //获取文件后缀名
String uniqueFileName=UUID.randomUUID().toString()+endName; //(生成随机数+文件名).后缀
String url=aliOssUtil.upload(file.getBytes(),uniqueFileName);
System.out.println("no");
return Result.success(url);
}
}
其它情况使用阿里云OSS
定义实体类AliyunOSSProperties ,并交给IOC容器管理
@Data
@Component
@ConfigurationProperties(prefix = "aliyun.oss")
public class AliyunOSSProperties {
private String endpoint;
private String bucketName;
private String region;
}
AliyunOSSOperator
@Component
public class AliyunOSSOperator {
@Autowired
private AliyunOSSProperties aliyunOSSProperties;
public String upload(byte[] content, String originalFilename) throws Exception {
String endpoint = aliyunOSSProperties.getEndpoint();
String bucketName = aliyunOSSProperties.getBucketName();
String region = aliyunOSSProperties.getRegion();
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Object完整路径,例如2024/06/1.png。Object完整路径中不能包含Bucket名称。
//获取当前系统日期的字符串,格式为 yyyy/MM
String dir = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy/MM"));
//生成一个新的不重复的文件名
String newFileName = UUID.randomUUID() + originalFilename.substring(originalFilename.lastIndexOf("."));
String objectName = dir + "/" + newFileName;
// 创建OSSClient实例。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(content));
} finally {
ossClient.shutdown();
}
return endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + objectName;
}
}
使用阿里云
- 文件名后缀
@Slf4j
@RestController
public class UploadController {
@Autowired
private AliyunOSSOperator liyunOSSOperator;
@PostMapping("/upload")
//这里抛出异常原因:会有磁盘等问题,所以要抛出异常,以免异常
public Result upload(MultipartFile file) throws Exception {
//生成唯一的文件名
String originalFilename =file.getOriginalFilename(); //获取文件原始名
//substring:从指定位置截取字符串到末尾
//lastIndexOf("."):返回最后一个 . 的位置
String endName=originalFilename.substring(originalFilename.lastIndexOf(".")); //剪切文件后缀(如.rng)
String uniqueFileName=UUID.randomUUID().toString()+endName; //(生成随机数+文件名).后缀
//上传文件 借助 工具类 阿里云提供的的 (字节的文件内容,要上传的文件名)
String url=aliyunOSSOperator.upload(file.getBytes(), uniqueFileName);
//生成url: https://java-ai-23515.oss-cn-shanghai.aliyuncs.com/001.jpg 这种
return Result.success(url);
}
}
入门
method方式get和post区别
form action="/upload" 表单提交给服务器端的路径
enctype="multipart/form-data 只有设置了这个,在游览器请求访问后,才能把文件内容信息传递给服务器端(后端)
当你在浏览器中打开 upload.html 页面(http://localhost:8080/upload.html)[这里是找到本地Tomcat服务器上面的upload.html项目],选择一个文件,然后点击“上传”按钮时,会发生以下事情:
浏览器会构建一个HTTP POST 请求(“/upload”),请求的URL 是 http://localhost:8080/upload(假设你的Spring Boot应用运行在本地主机的8080端口上)
浏览器会将你选择的文件(二进制形式)作为请求的一部分发送。因为 enctype 是 multipart/form-data,文件和其他表单字段一起被编码并发送。
这个请求被发送到服务器,Spring Boot应用接收到这个请求。
Spring Boot应用需要有一个处理 /upload 路径的请求的方法。
@PostMapping(“/upload”) 的方法来处理这个请求。
然后UploadController处理头像文件,获取url存储路径
存储路径和员工基本信息一块传到EmpController
前端将获取到的文件路径与其他员工信息(如姓名、年龄等)封装到一个表单或 JSON 对象中
// 提交 员工信息+头像文件 到 EmpController
function submitEmployeeInfo() {
const username = document.getElementById("username").value;
const age = document.getElementById("age").value;
// 将员工信息和头像 URL 封装到 JSON 对象中
const employeeData = {
username: username,
age: age,
avatarUrl: avatarUrl
};
fetch("/emp", { // 假设 EmpController 的路径是 /emp
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify(employeeData)
})
.then(response => response.json())
.then(data => {
if (data.success) {
alert("员工信息提交成功!");
} else {
alert("员工信息提交失败!");
}
})
.catch(error => {
console.error("提交员工信息时出错:", error);
});
}
http://localhost:8080/upload.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>上传文件</title>
</head>
<body>
<!--
action:表单提交时,表单数据要被送到的url地址
method:提交方式 post可以用来传输更大的数据
enctype:编码类型,表单编码类型multipart/form-data(用于文件上传和二进制上传)
<br>: 换行break
submit: 提交
-->
<form action="/upload" method="post" enctype="multipart/form-data">
姓名:<input type="text" name="username"><br>
年龄:<input type="text" name="age"><br>
头像:<input type="file" name="file"><br>
<input type="submit" value="提交">
</form>
</body>
</html>
@Slf4j
@RestController
public class UploadController {
public Result upload(String username, Integer age ,MultipartFile file) {
log.info("上传文件:{}, {}, {}", username, age, file);
return Result.success();
}
}
上传的文件会被临时保存到本地C盘的Temp路径下
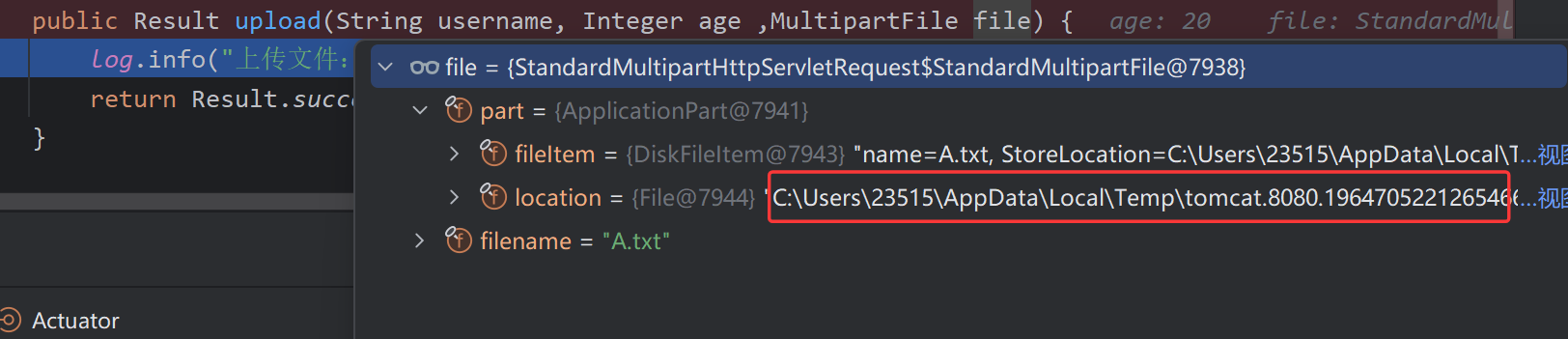
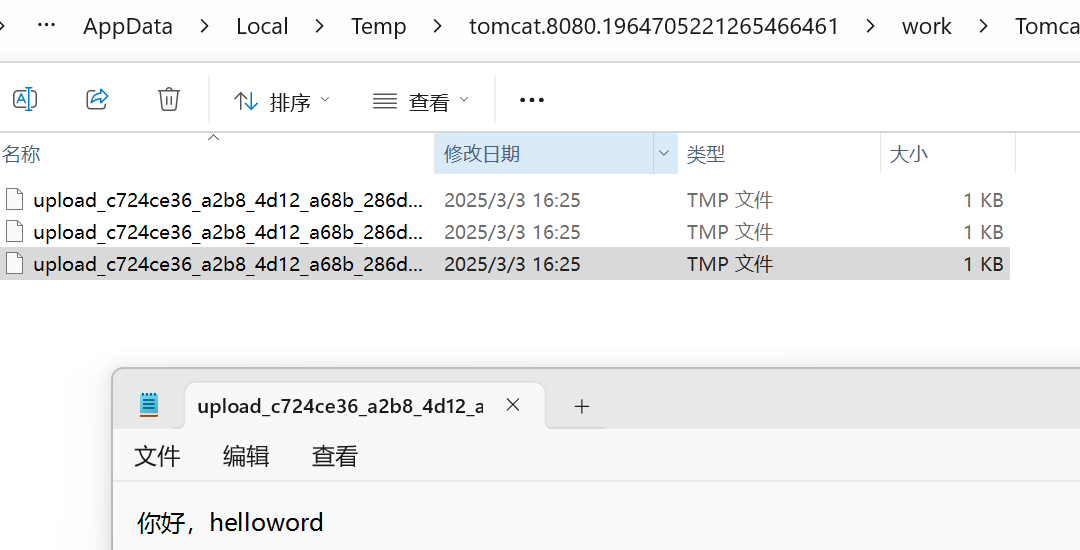
本地存储(不推荐)
为什么会有异常
怎么保存文件到本地
文件上传保存会出现重复覆盖
UUID获取随机数-唯一不重复
UUID.randomUUID().toString()
@Slf4j
@RestController
public class UploadController {
/**
* 上传文件 - 参数名file
*/
@PostMapping("/upload")
//接收游览器传递过来的参数
//MultipartFile类型文件 //这里抛出异常原因:会有磁盘等问题,所以要抛出异常,以免异常
public Result upload(String username, Integer age ,MultipartFile file) throws IOException {
log.info("上传文件:{}, {}, {}", username, age, file);
//获取原文件文件名
String originalFilename =file.getOriginalFilename();
//如果用原本的文件名(如1.img可能出现重复覆盖,所以要用随机数)
/*
substring:从指定位置截取字符串到末尾
lastIndexOf("."):返回最后一个 . 的位置
*/
//获取文件后缀
String fileEnd=originalFilename.substring(originalFilename.lastIndexOf("."));
//产生随机数的文件,保证唯一性
String fileName =UUID.randomUUID().toString()+fileEnd;
//保存文件
//File(文件路径+文件名)
File destinationFile = new File("E:\\A-develop\\test\\"+fileName);
file.transferTo(destinationFile);
return Result.success();
}
}
MultipartFile常见方法:
- getOriginalFilename(); 获取原始文件名字
- transferTo(): 把文件转存到磁盘文件中
文件上传大小设置->yml里面设置
spring:
servlet:
multipart:
#单个文件上传最大
max-file-size: 10MB
#一次上传多个文件总的文件大小
max-request-size: 100MB
阿里云存储(推荐)
开启oss服务
set OSS_ACCESS_KEY_ID=LTAI5tE3gVp2nBHspAjhTGWL
set OSS_ACCESS_KEY_SECRET=kzKuBTj0rwJWgVKfixkFniWD85rFUa
有个上传阿里云代码
package com.itheima.utils;
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
import com.aliyun.oss.common.comm.SignVersion;
import org.springframework.stereotype.Component;
import java.io.ByteArrayInputStream;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.UUID;
@Component
public class AliyunOSSOperator {
private String endpoint = "https://oss-cn-beijing.aliyuncs.com";
private String bucketName = "java-ai";
private String region = "cn-beijing";
public String upload(byte[] content, String originalFilename) throws Exception {
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
//在OSS中存储的文件名
// 填写Object完整路径,例如202406/1.png。Object完整路径中不能包含Bucket名称。
//获取当前系统日期的字符串,格式为 yyyy/MM
String dir = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy/MM"));
//生成一个新的不重复的文件名
String newFileName = UUID.randomUUID() + originalFilename.substring(originalFilename.lastIndexOf("."));
String objectName = dir + "/" + newFileName;
// 创建OSSClient实例。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
//文件上传存储
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(content));
} finally {
ossClient.shutdown();
}
//直接组转要返回的访问OSS存储的文件路径
return endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + objectName;
}
}
在以上代码中,需要替换的内容为:
- endpoint:阿里云OSS中的bucket对应的域名
- bucketName:Bucket名称
- objectName:对象名称,在Bucket中存储的对象的名称
- region:bucket所属区域
阿里云上传文件使用
1.配置xml文件
<!--阿里云OSS依赖-->
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.17.4</version>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>1.1.1</version>
</dependency>
<!-- no more than 2.3.3-->
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.3</version>
</dependency>
2.阿里云上传文件工具类(utils)
/*
* 阿里云上传文件工具类
* */
@Component
public class AliyunOSSOperator {
private String endpoint = "https://oss-cn-shanghai.aliyuncs.com";
private String bucketName = "java-ai-23515";
private String region = "cn-shanghai";
//byte[] content:文件内容(二进制,字节)
//String originalFilename:文件名
public String upload(byte[] content, String originalFilename) throws Exception {
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
//在OSS中存储的文件名
// 填写Object完整路径,例如202406/1.png。Object完整路径中不能包含Bucket名称。
//获取当前系统日期的字符串,格式为 yyyy/MM
String dir = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy/MM"));
//生成一个新的不重复的文件名
String newFileName = UUID.randomUUID() + originalFilename.substring(originalFilename.lastIndexOf("."));
String objectName = dir + "/" + newFileName;
// 创建OSSClient实例。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
//文件上传存储
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(content));
} finally {
ossClient.shutdown();
}
//直接组转要返回的访问OSS存储的文件路径
return endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + objectName;
}
}
3.上传文件UploadController类
借助阿里云工具类AliyunOSSOperator 中 upload()
/*
* 阿里云上传文件
* */
@Autowired
private AliyunOSSOperator aliyunOSSOperator;
@PostMapping("/upload")
//这里抛出异常原因:会有磁盘等问题,所以要抛出异常,以免异常
public Result upload(MultipartFile file) throws Exception {
//生成唯一的文件名
String originalFilename =file.getOriginalFilename(); //获取文件原始名
//substring:从指定位置截取字符串到末尾
//lastIndexOf("."):返回最后一个 . 的位置
String endName=originalFilename.substring(originalFilename.lastIndexOf(".")); //剪切文件后缀(如.rng)
String uniqueFileName=UUID.randomUUID().toString()+endName;
//上传文件 借助 工具类 阿里云提供的的 (字节的文件内容,要上传的文件名)
String url=aliyunOSSOperator.upload(file.getBytes(), uniqueFileName);
//生成url: https://java-ai-23515.oss-cn-shanghai.aliyuncs.com/001.jpg 这种
return Result.success(url);
}
}
@Value和@ConfigurationProperties
这个参数的值在java中写死了,不便于维护和管理
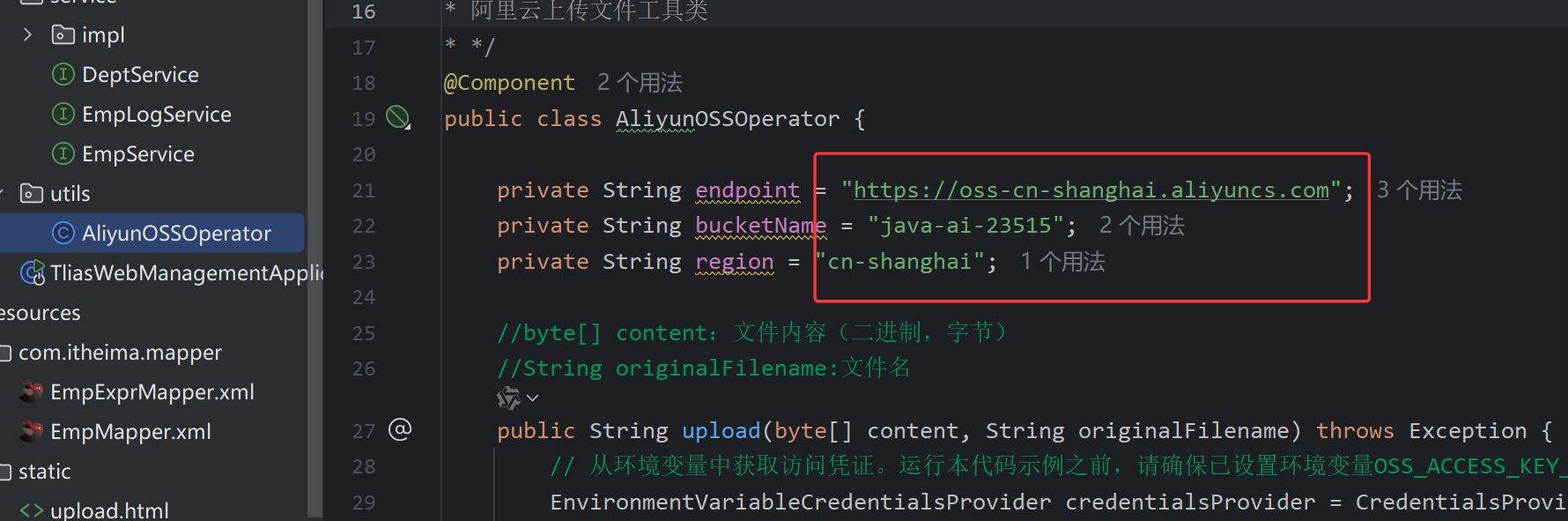
使用@Value注解

- 1.配置yml格式
#阿里云OSS 参数配置
aliyun:
oss:
endpoint: https://oss-cn-shanghai.aliyuncs.com
bucketName: java-ai-23515
region: cn-shanghai
- 2.写入@value注解
//方式2:用@Value注解来注入 :适合注入属性的较少时候
@Value("${aliyun.oss.endpoint}")
private String endpoint;
@Value("${aliyun.oss.bucketName}")
private String bucketName;
@Value("${aliyun.oss.region}")
private String region;
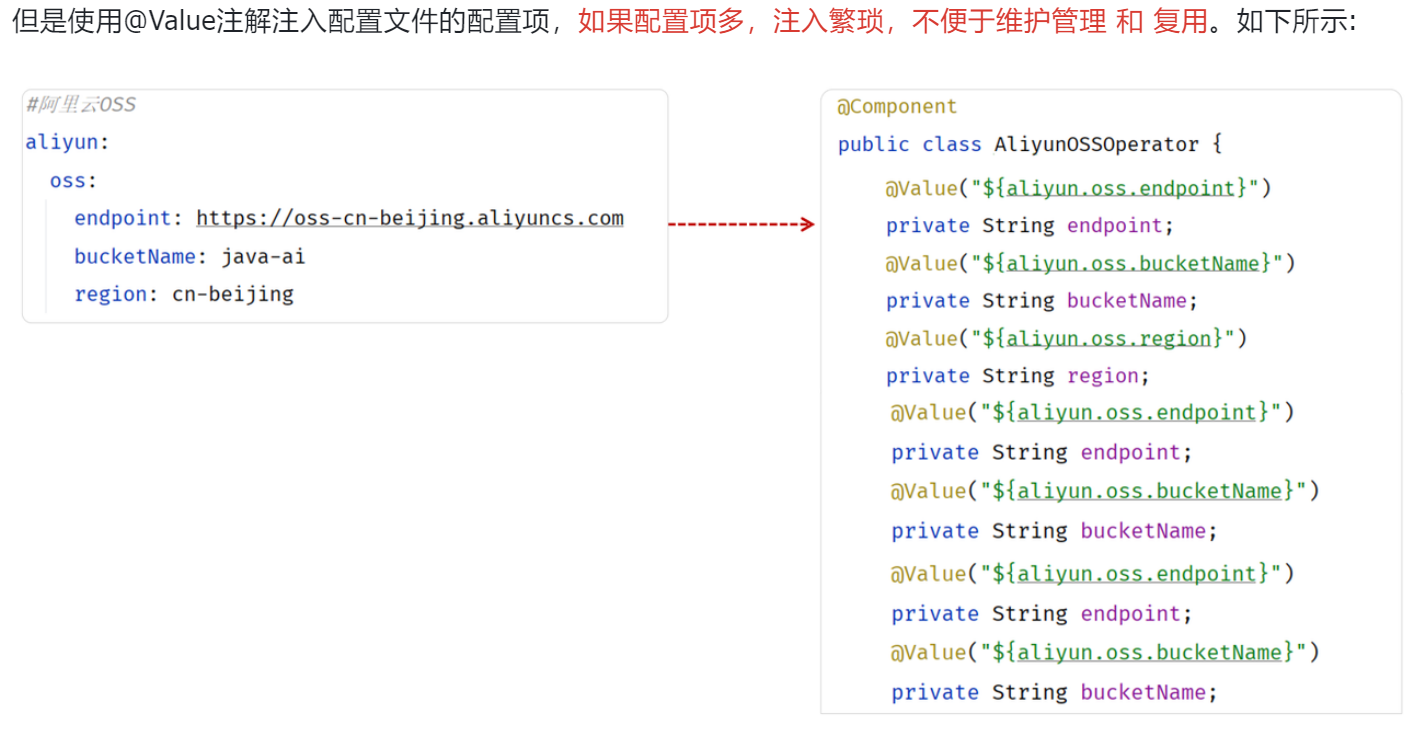
使用@ConfigurationProperties注解
如果属性过多
- 1.配置yml
#阿里云OSS 参数配置
aliyun:
oss:
endpoint: https://oss-cn-shanghai.aliyuncs.com
bucketName: java-ai-23515
region: cn-shanghai
- 2.创建类,交给ioc管理
@Data
@Component
@ConfigurationProperties(prefix = "aliyun.oss")
public class AliyunOSSProperties {
private String endpoint;
private String bucketName;
private String region;
}
-
3.使用@ConfigurationProperties
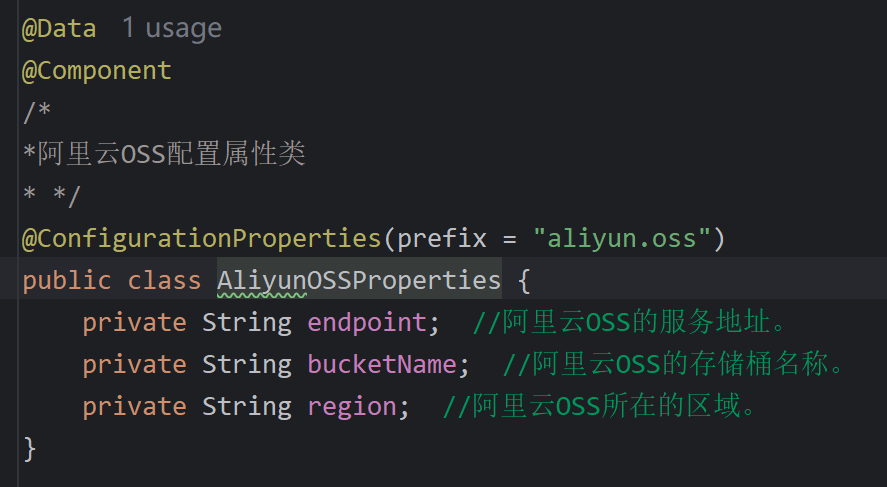
部分代码
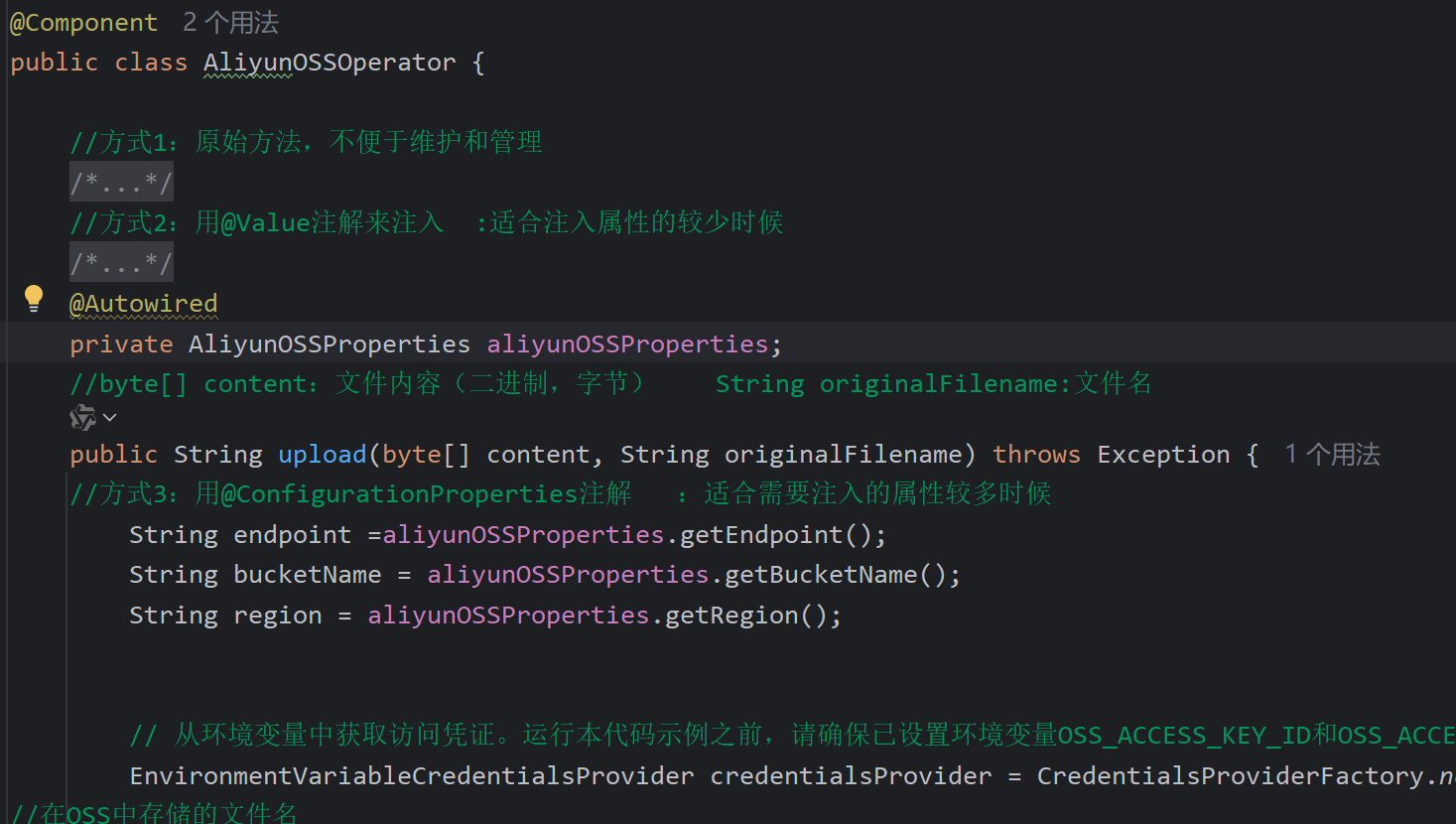
@Component
public class AliyunOSSOperator {
@Autowired
private AliyunOSSProperties aliyunOSSProperties;
//byte[] content:文件内容(二进制,字节) String originalFilename:文件名
public String upload(byte[] content, String originalFilename) throws Exception {
//方式3:用@ConfigurationProperties注解 :适合需要注入的属性较多时候
String endpoint =aliyunOSSProperties.getEndpoint();
String bucketName = aliyunOSSProperties.getBucketName();
String region = aliyunOSSProperties.getRegion();
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
//在OSS中存储的文件名
// 填写Object完整路径,例如202406/1.png。Object完整路径中不能包含Bucket名称。
//获取当前系统日期的字符串,格式为 yyyy/MM
String dir = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy/MM"));
.....................
总结
- 属性较少,使用@Value
- 属性较多,使用@ConfigurationProperties
删除员工
public Result delete(@RequestParam List<Integer> ids) 为什么需要@RequestParam
有多个操纵数据库的sql要怎么办
//删除员工
@DeleteMapping()
//这个是复杂类型,@RequestParam不能省略,当没有这个注解时候,springmvc会通过其它方式请求注解,导致报错
//请求参数样例:/emps?ids=1,2,3
public Result delete(@RequestParam List<Integer> ids){
empService.delete(ids);
return Result.success();
}
@Transactional(rollbackFor = Exception.class) //当涉及多个数据库操作的时候用事务
public void delete(List<Integer> ids){
//删除员工基信息
empMapper.deleteByIds(ids);
//删除工作经历信息
empExprMapper.deleteByEmpIds(ids);
}
<delete id="deleteByIds" >
delete from emp where id in
<foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</delete>
<delete id="deleteByEmpIds">
delete from emp_expr where emp_id in
<foreach collection="empIds" item="empId" separator="," open="(" close=")">
#{empId}
</foreach>
</delete>
修改员工
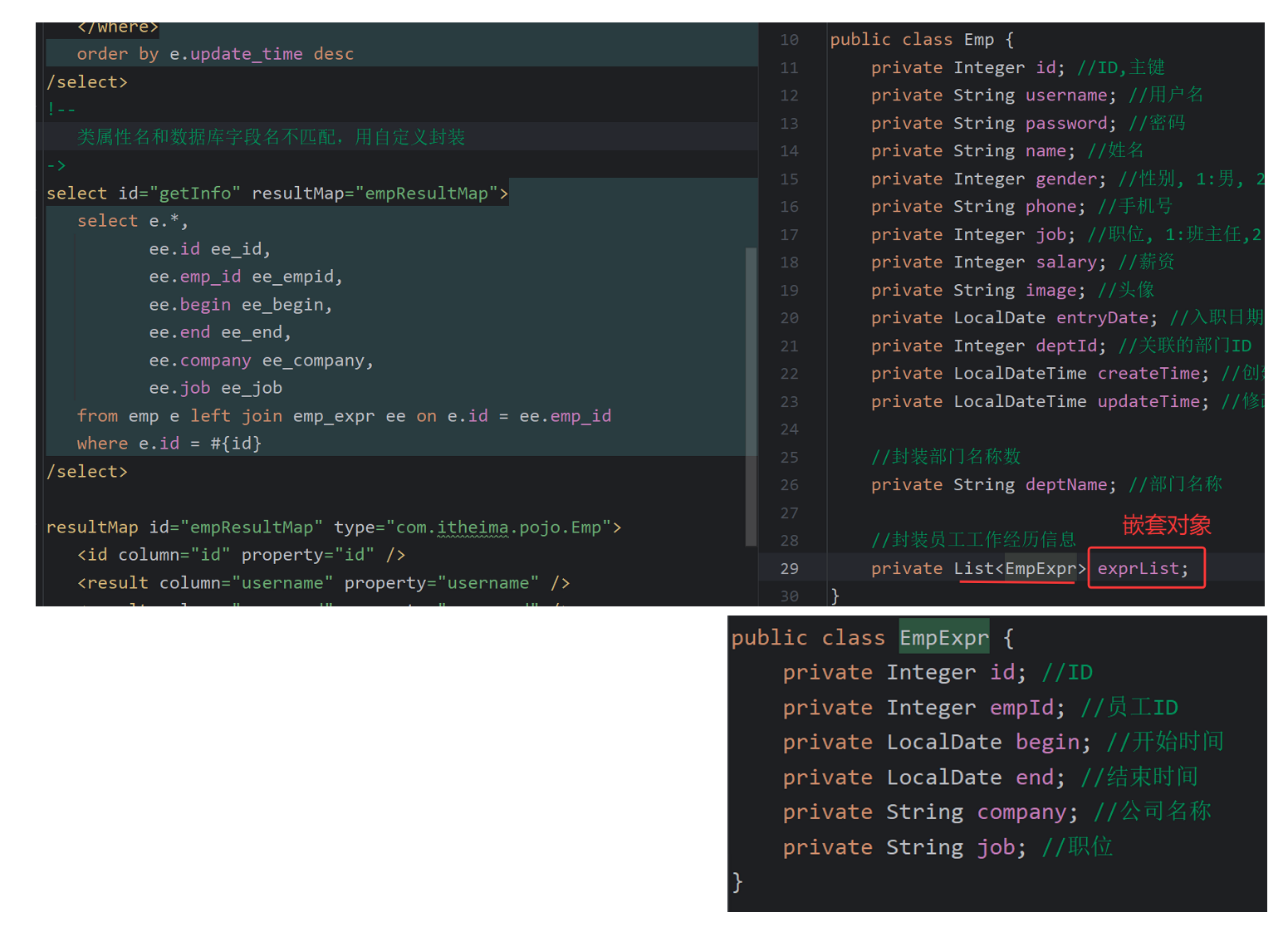
查询回显
resultType 和 resultMap 区别
resultType 和 resultMap 区别
看查询返回的字段名和属性名可不可以直接对应上
-
resultType:用于简单类型,当类的属性名和数据库的字段名能完全匹配
-
resultMap:实体属性较复杂,类的属性名和数据库的字段名能不匹配 嵌套对象等
因为查询返回的结果要封装到emp的属性名当中,所以要保证字段名和属性名完全匹配
//==================== Controller ===================
/*
* 修改员工-查询回显
* */
@GetMapping("{id}")
public Result getInfo(@PathVariable Integer id){
Emp emp=empService.getInfo(id);
return Result.success(emp);
}
//=================== Service ===================
@Override
public Emp getInfo(Integer id) {
return empMapper.getInfo(id);
}
//================== Mapper ====================
Emp getInfo(Integer id);
<!--
类属性名和数据库字段名不匹配,用自定义封装resultMap
-->
<select id="getInfo" resultMap="empResultMap">
select e.*,
ee.id ee_id,
ee.emp_id ee_empid,
ee.begin ee_begin,
ee.end ee_end,
ee.company ee_company,
ee.job ee_job
from emp e left join emp_expr ee on e.id = ee.emp_id
where e.id = #{id}
</select>
<!--自定义封装-->
<resultMap id="empResultMap" type="com.itheima.pojo.Emp">
<id column="id" property="id" />
<result column="username" property="username" />
<result column="password" property="password" />
<result column="name" property="name" />
<result column="gender" property="gender" />
<result column="phone" property="phone" />
<result column="job" property="job" />
<result column="salary" property="salary" />
<result column="image" property="image" />
<result column="entry_date" property="entryDate" />
<result column="dept_id" property="deptId" />
<result column="create_time" property="createTime" />
<result column="update_time" property="updateTime"/>
<!--
collection:集合/数组类型
property:数据库字段名
property:要封装到的类中属性名
ofType:单条数据存放的类型
-->
<collection property="exprList" ofType="com.itheima.pojo.EmpExpr">
<id column="ee_id" property="id"/>
<result column="ee_company" property="company"/>
<result column="ee_job" property="job"/>
<result column="ee_begin" property="begin"/>
<result column="ee_end" property="end"/>
<result column="ee_empid" property="empId"/>
</collection>
</resultMap>
修改员工
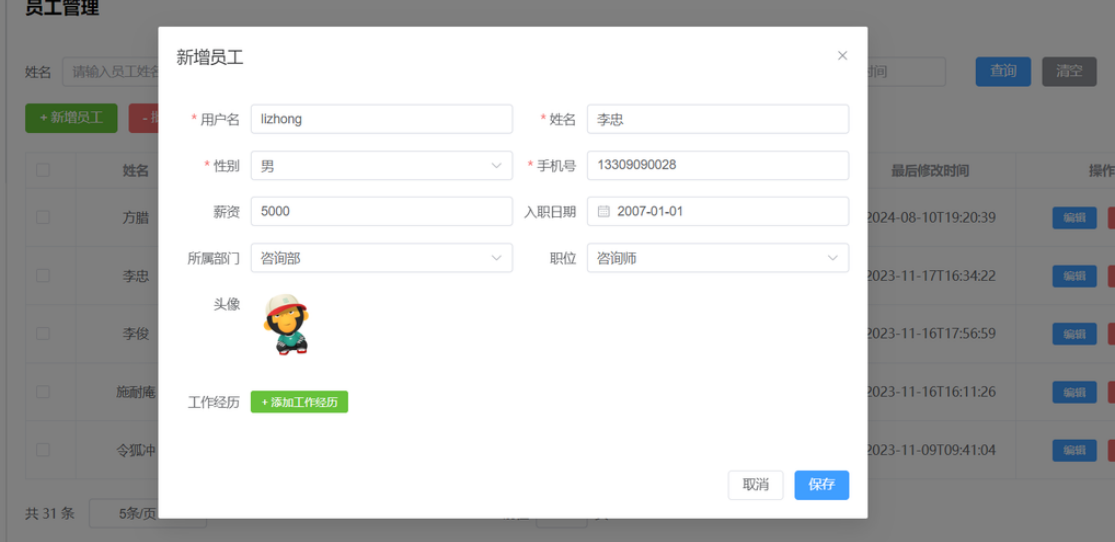
修改工作经历的时候,会有很多种情况,所以采用先删除再添加
//============================== Controller ==================================
/*
* 修改员工-修改
* */
@PutMapping
public Result update(@RequestBody Emp emp){
empService.update(emp);
return Result.success();
}
//============================== Service ==================================
/*
* 修改员工-修改
* */
@Transactional(rollbackFor = Exception.class)
@Override
public void update(Emp emp) {
//修改员工基本信息
emp.setUpdateTime(LocalDateTime.now());
empMapper.updateById(emp);
//修改工作经历 (先删除再添加)
/*List<Integer> arrayList=new ArrayList<>();
arrayList.add(emp.getId());
List<Integer> e=(arrayList);*/
empExprMapper.deleteByEmpIds(Arrays.asList(emp.getId()));
if(!CollectionUtils.isEmpty(emp.getExprList())){
empExprMapper.insert(emp.getExprList());
}
}
//============================== Mapper ==================================
void updateById(Emp emp);
void insert(List<EmpExpr> exprList);
void deleteByEmpIds(List<Integer> empIds);
throughly
<!--============================= empMapper.xml ======================================-->
<update id="updateById">
update emp
<set>
<if test="username!=null and username!='' ">username=#{username},</if>
<if test="password != null and password != ''">password = #{password},</if>
<if test="name != null and name != ''">name = #{name},</if>
<if test="gender != null">gender = #{gender},</if>
<if test="phone != null and phone != ''">phone = #{phone},</if>
<if test="job != null">job = #{job},</if>
<if test="salary != null">salary = #{salary},</if>
<if test="image != null and image != ''">image = #{image},</if>
<if test="entryDate != null">entry_date = #{entryDate},</if>
<if test="deptId != null">dept_id = #{deptId},</if>
<if test="updateTime != null">update_time = #{updateTime},</if>
</set>
where id=#{id}
</update>
<!--============================= empExprMapper.xml ======================================-->
<mapper namespace="com.itheima.mapper.EmpExprMapper"> <!-- 同包同名-->
<delete id="deleteByEmpIds">
delete from emp_expr where emp_id in
<foreach collection="empIds" item="empId" separator="," open="(" close=")">
#{empId}
</foreach>
</delete>
<insert id="insert">
insert into emp_expr (emp_id, begin, end, company, job) values
/* foreach标签
collection:集合名称
item:遍历出来的集合名称
separator:遍历出来的分隔符
open:遍历开始前拼接的片段
close:遍历结束后拼接的片段
*/
<foreach collection="exprList" item="expr" separator=",">
(#{expr.empId}, #{expr.begin}, #{expr.end}, #{expr.company}, #{expr.job})
</foreach>
</insert>
</mapper>
框架底层处理异常会从子类可以找有没有能处理异常的,
异常处理
当有异常(手机号唯一约束,但是手机号填写重复)的时候,想得到以下这种提示
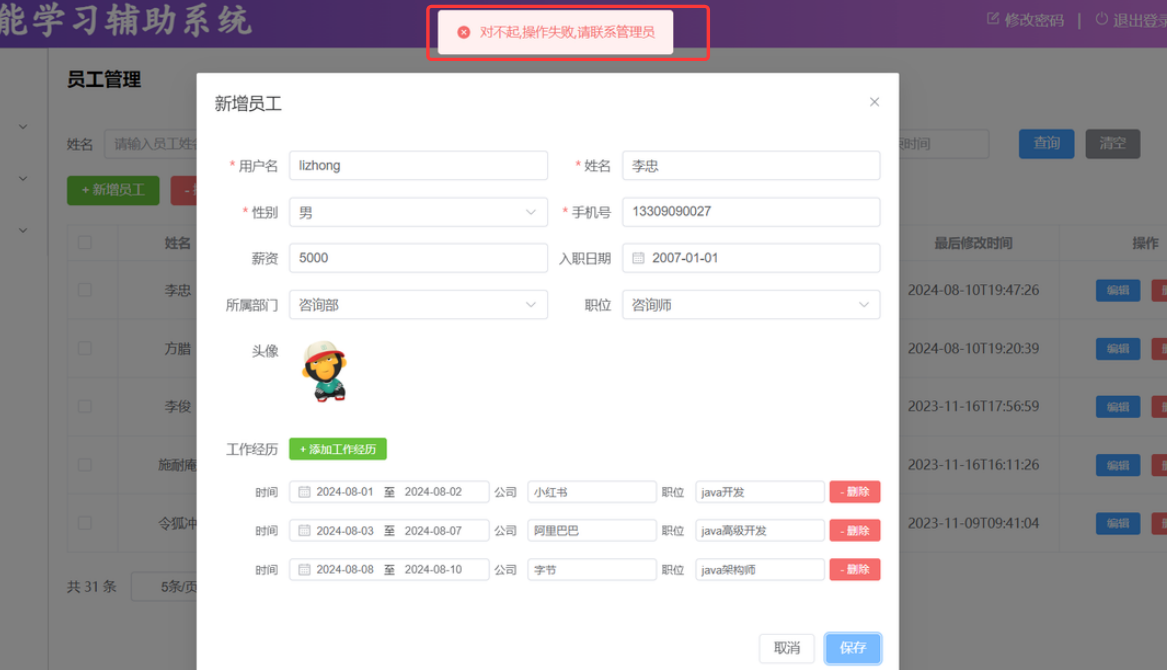
解决方法
方式1:在所有Controller的所有方法中进行try…catch处理,会导致代码臃肿,不推荐
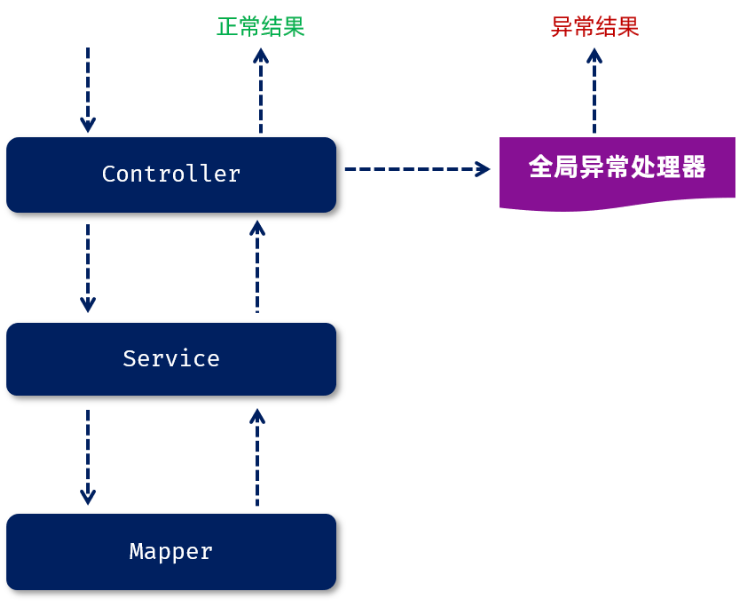
方式2:全局异常处理器处理异常
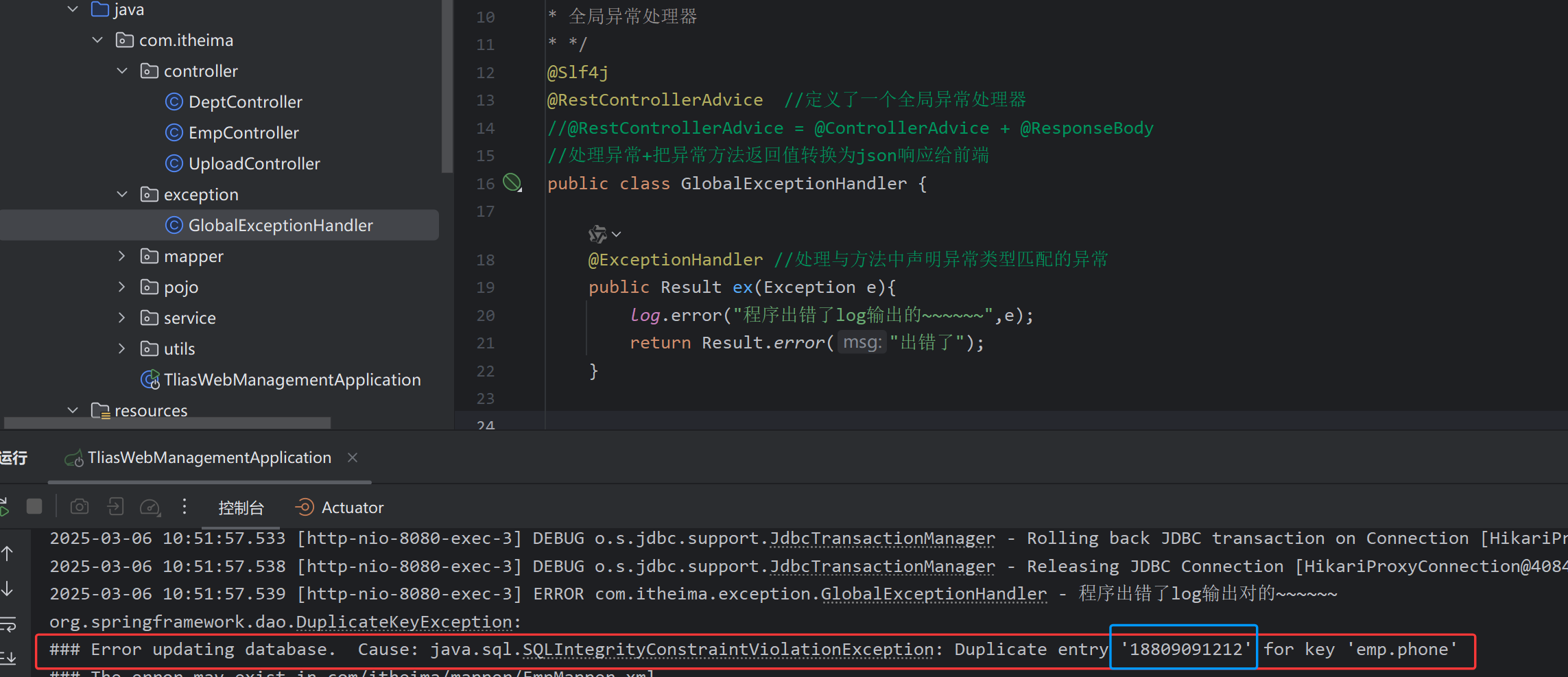
全局异常处理器
/*
* 全局异常处理器
* */
@Slf4j
@RestControllerAdvice //定义了一个全局异常处理器
//@RestControllerAdvice = @ControllerAdvice + @ResponseBody
//处理异常+把异常方法返回值转换为json响应给前端
public class GlobalExceptionHandler {
@ExceptionHandler //处理与方法中声明异常类型匹配的异常
public Result ex(Exception e){
log.error("程序出错了log输出的~~~~~~",e);
return Result.error("出错了");
}
/*
* 捕获唯一约束的异常
* */
@ExceptionHandler
public Result HandlerDuplicateKeyException(DuplicateKeyException e){
String message=e.getMessage(); //拿到报错信息 Error那些
//先获取Duplicate位置 然后截取 Duplicate entry '18809091212' for key 'emp.phone'
String a=message.substring(message.indexOf("Duplicate"));
String []arr=a.split(" "); //以空格截取 arr[2]= '18809091212'
log.error(arr[2]+"重复");
return Result.error(arr[2]+"已经存在");
}
}
注:
- @RestControllerAdvice = @ControllerAdvice + @ResponseBody
- @RestControllerAdvice:定义一个全局异常处理器
- 接收异常+把处理异常方法的返回值转换成json格式返回给前端
- @ExceptionHandler:处理和方法中声明异常类型匹配的异常
int []a={1,2,3,4};
list<Integer> b
mapper层
员工信息统计
员工职位人数统计
sql语句中选择1 2 3对应各个职位,如果选择
报表的制作,主要是前端人员开发,引入对应的组件(比如:ECharts)
//============================== Controller ==================================
@Slf4j
@RestController
@RequestMapping("/report")
/*
* 用来统计员工职位信息
* */
public class ReportController {
@Autowired
private ReportService reportService;
@GetMapping("/empJobData")
public Result getEmpJobData(){
JobOption jobOption =reportService.getEmpJobData();
return Result.success(jobOption);
}
}
//============================== Service ==================================
@Service
public class ReportServiceImpl implements ReportService {
@Autowired
private EmpMapper empMapper;
public JobOption getEmpJobData(){
List<Map<String, Object>> list=empMapper.getEmpJobData(); //接收表格数据
//把表格数据分开存到JobOption对象当中去
//这里用stream流操作,更便捷
//从表格数据list中使用stream流map映射出key=pos中所有的value,然后通过stream流中collect收集转换为List集合
List<Object> jobList=list.stream().map(dataMap->dataMap.get("pos")).collect(Collectors.toList());
List<Object> dataList=list.stream().map(dataMap->dataMap.get("num")).collect(Collectors.toList());
return new JobOption(jobList,dataList);
}
}
//============================== Mapper ==================================
//如果返回类型是Map类型,需要这个注解来指定Key是谁 ,不指定也行
@MapKey("pos")
//存储的是表格,用Map
List<Map<String, Object>> getEmpJobData();
//注:这有个误报,是Mybatisx插件导致的, 所以这里加上@MapKey("pos")
<!-- 方式一:统计员工信息 -->
<select id="getEmpJobData" resultType="java.util.Map">
select (case when job=1 then '班主任'
when job=2 then '讲师'
when job=3 then '学工主管'
when job=4 then '教研主管'
when job=5 then '咨询师'
else '其他' end) pos,
count(*) num from emp group by job order by num;
</select>
<!-- 方式二 -->
<select id="countEmpJobData" resultType="java.util.Map">
select
(case job when 1 then '班主任'
when 2 then '讲师'
when 3 then '学工主管'
when 4 then '教研主管'
when 5 then '咨询师'
else '其他' end) pos,
count(*) total
from emp group by job
order by total
</select>
注:方式一使用更广泛,可以使用范围查询[when job in(1,2,3)]
统计员工性别
//============================== Controller ==================================
@GetMapping("/empGenderData")
public Result getEmpGenderData(){
List<Map> listMap=reportService.getEmpGenderData();
return Result.success(listMap);
}
//============================== Service ==================================
public List<Map> getEmpGenderData(){
List<Map> listMap=empMapper.getEmpGenderData();
return listMap;
}
//============================== Mapper ==================================
List<Map> getEmpGenderData();
<!-- 统计员工性别 -->
<select id="getEmpGenderData" resultType="java.util.Map">
select if(gender=1,'男','女') as name
,count(*) value from emp group by gender;
</select>s
注:
- sql语句中的if和mybatis中的 不同
- sql语句中if语句 if(条件, 条件为true取值, 条件为false取值) eg: if(gender=1,‘男’,‘女’)
map<字段名的类型,内容类型>
List
登录认证
cookie优缺点
登录功能
登录校验
什么是登录校验?
所谓登录校验,指的是我们在服务器端接收到浏览器发送过来的请求之后,首先我们要对请求进行校验。先要校验一下用户登录了没有,如果用户已经登录了,就直接执行对应的业务操作就可以了;如果用户没有登录,此时就不允许他执行相关的业务操作,直接给前端响应一个错误的结果,最终跳转到登录页面,要求他登录成功之后,再来访问对应的数据
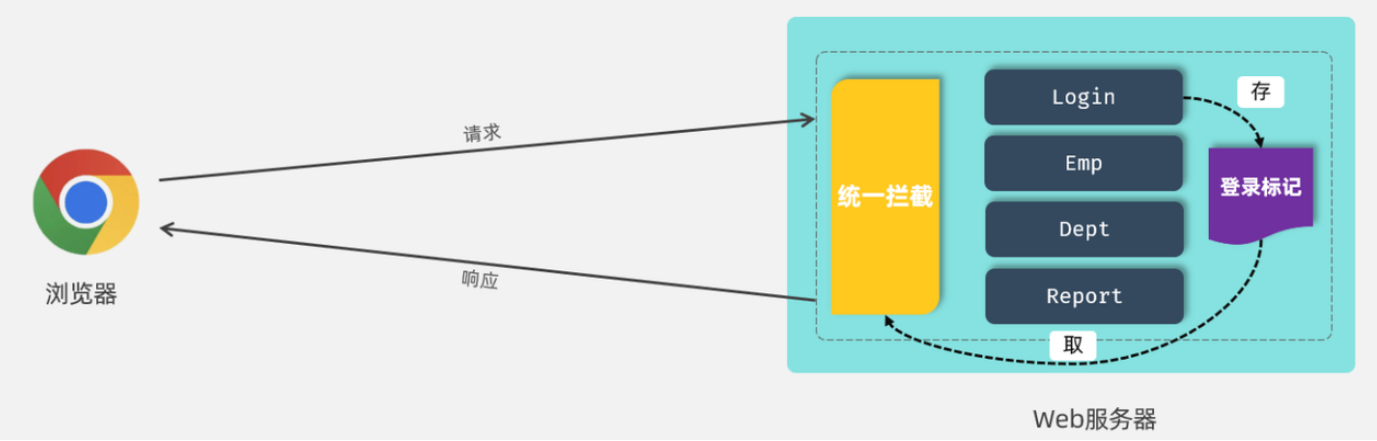
会话技术(JWT令牌)
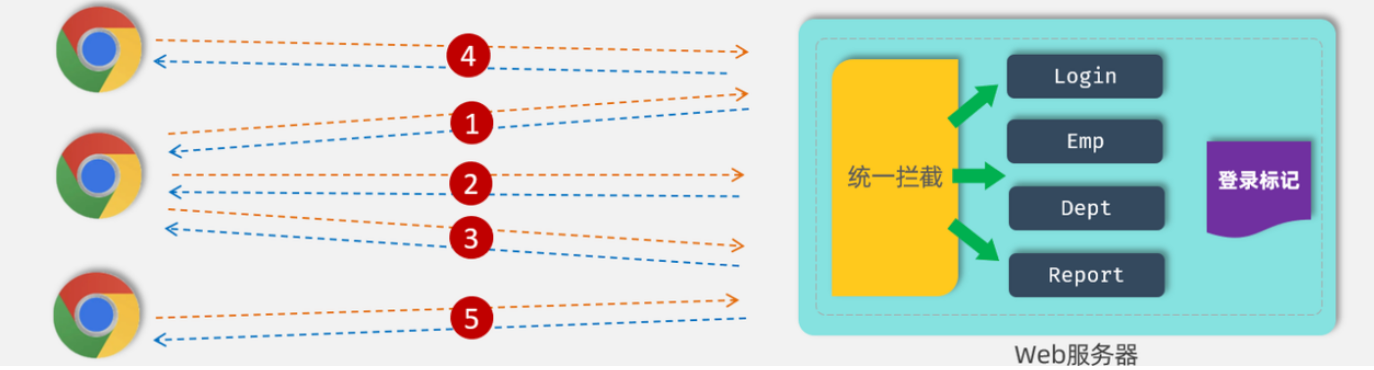
会话:浏览器和服务器之间的一次连接
在用户打开浏览器第一次访问服务器的时候,这个会话就建立了,直到有任何一方断开连接,此时会话就结束了。在一次会话当中,是可以包含多次请求和响应的。
比如:打开了浏览器来访问web服务器上的资源(浏览器不能关闭、服务器不能断开)
- 第1次:访问的是登录的接口,完成登录操作
- 第2次:访问的是部门管理接口,查询所有部门数据
- 第3次:访问的是员工管理接口,查询员工数据
只要浏览器和服务器都没有关闭,以上3次请求都属于一次会话当中完成的
会话跟踪:在会话中,识别多次请求是否来自于同一个浏览器,以便在同一次会话的多次请求中共享数据
cookie(不推荐)
cookie 是客户端会话跟踪技术,它是存储在客户端浏览器的,我们使用 cookie 来跟踪会话,我们就可以在浏览器第一次发起请求来请求服务器的时候,我们在服务器端来设置一个cookie。
比如第一次请求了登录接口,登录接口执行完成之后,我们就可以设置一个cookie,在 cookie 当中我们就可以来存储用户相关的一些数据信息。比如我可以在 cookie 当中来存储当前登录用户的用户名,用户的ID。
服务器端在给客户端在响应数据的时候,会自动的将 cookie 响应给浏览器,浏览器接收到响应回来的 cookie 之后,会自动的将 cookie 的值存储在浏览器本地。接下来在后续的每一次请求当中,都会将浏览器本地所存储的 cookie 自动地携带到服务端。
在 HTTP 协议官方给我们提供了一个响应头和请求头:
- 响应头 Set-Cookie :设置Cookie数据的
- 请求头 Cookie:携带Cookie数据的
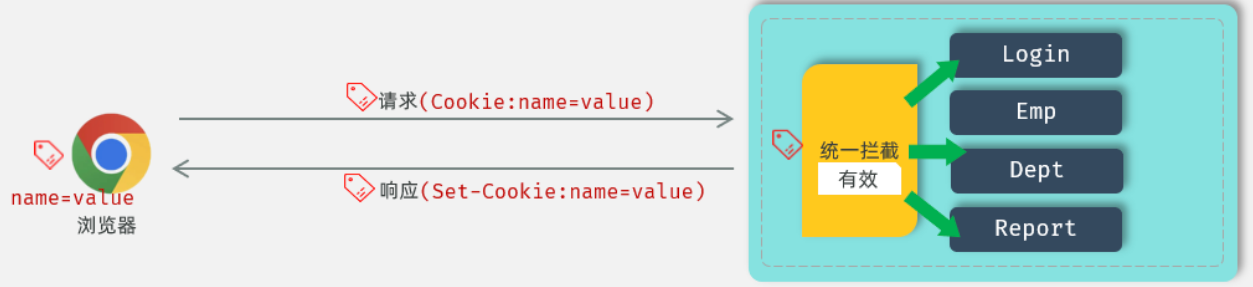
@Slf4j
@RestController
public class SessionController {
//设置Cookie
@GetMapping("/c1")
public Result cookie1(HttpServletResponse response){
response.addCookie(new Cookie("login_username","itheima")); //设置Cookie/响应Cookie
return Result.success();
}
//获取Cookie
@GetMapping("/c2")
public Result cookie2(HttpServletRequest request){
Cookie[] cookies = request.getCookies();
for (Cookie cookie : cookies) {
if(cookie.getName().equals("login_username")){
System.out.println("login_username: "+cookie.getValue()); //输出name为login_username的cookie
}
}
return Result.success();
}
}
A.访问c1接口,设置Cookie
我们可以看到,设置的cookie,通过响应头Set-Cookie响应给浏览器,并且浏览器会将Cookie,存储在浏览器端。
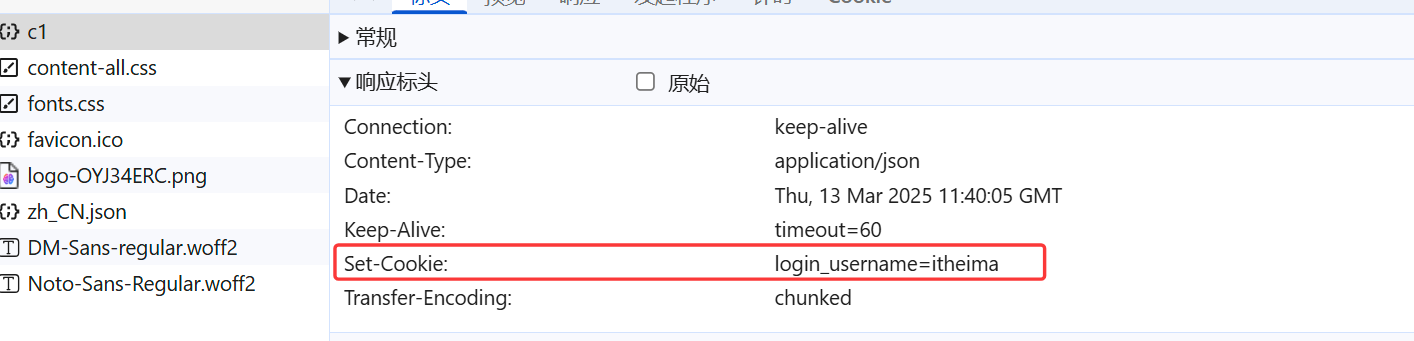
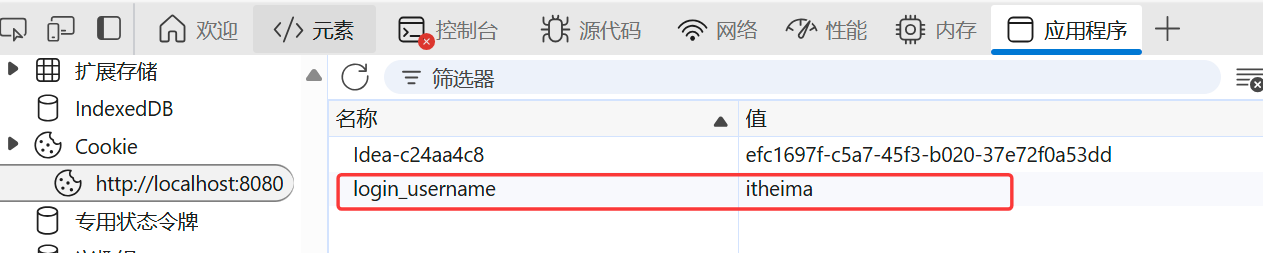
B. 访问c2接口 http://localhost:8080/c2,此时浏览器会自动的将Cookie携带到服务端,是通过请求头Cookie,携带的。
cookie优缺点
优点:HTTP中支持cookie
缺点:
- 不安全,用户可以随便删除游览器中cookie
- 移动端APP无法使用cookie
- cookie不能跨域(现在都是前后端分离的)

session(不推荐)
而 Session (存储在服务器端)的底层其实就是基于我们刚才所介绍的 Cookie(存储在游览器) 来实现的。
负载均衡
集群
public class SessionController {
//设置session
@GetMapping("/s1")
public Result session1(HttpSession session){
log.info("HttpSession-s1: {}", session.hashCode());
session.setAttribute("loginUser", "tom"); //往session中存储数据
return Result.success();
}
//请求session
@GetMapping("/s2")
public Result session2(HttpServletRequest request){
HttpSession session = request.getSession();
log.info("HttpSession-s2: {}", session.hashCode());
Object loginUser = session.getAttribute("loginUser"); //从session中获取数据
log.info("loginUser: {}", loginUser);
return Result.success(loginUser);
}
}
session
优点:session存储在服务器上
缺点:
- 在集群环境下不能使用Session
- cookie所有缺点
- 不安全,用户可以随便删除游览器中cookie
- 移动端APP无法使用cookie
- cookie不能跨域
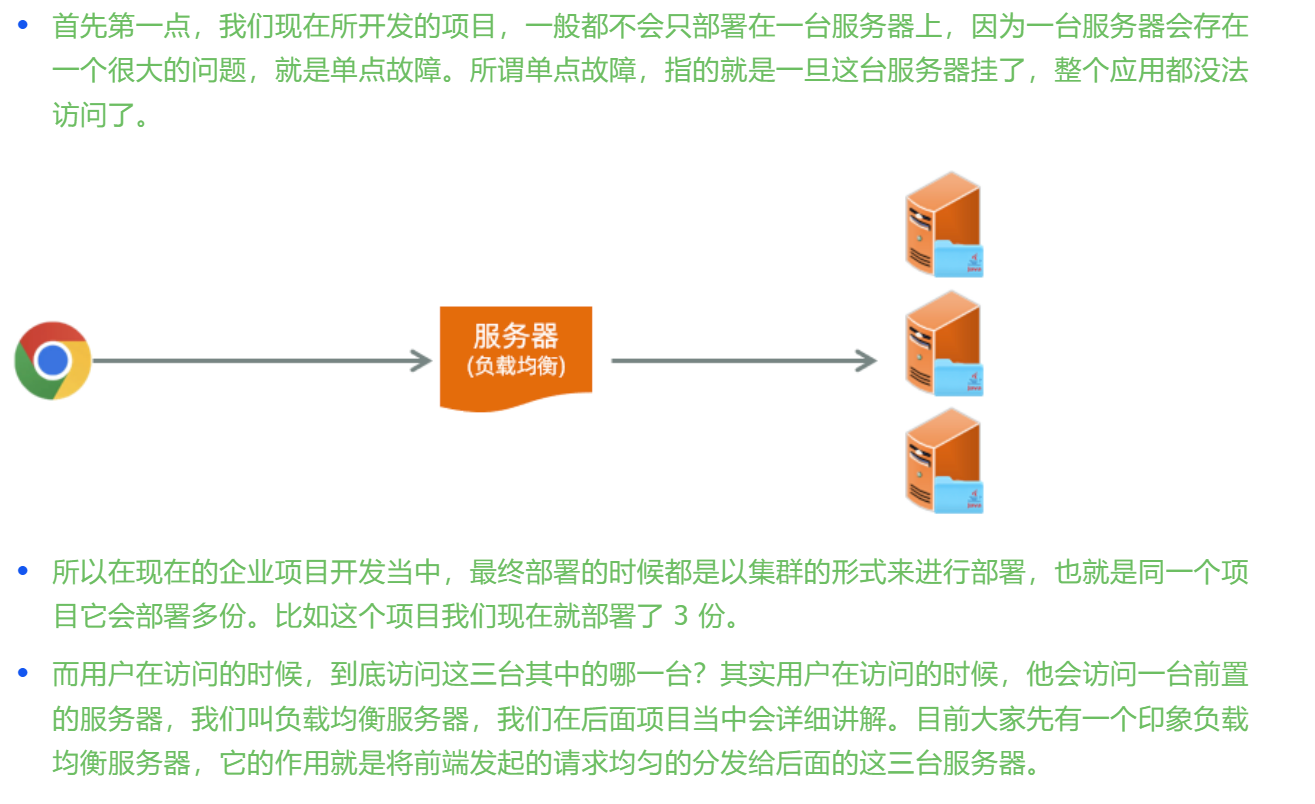
集群和负载均衡(基于反向代理而来)
集群:多个服务器(计算机)组合在一起,协同工作(原本一个计算机工作,现在多个计算机帮忙工作,共同协作)
负载均衡:把用户请求合理的分配的服务器上,以避免某台服务器过载,提高系统的整体性能和可靠性
nginx-反向代理
安全:不把后端tomcat服务器暴露给前端
后端服务器的增减,前端是无感知的
很方便实现负载均衡

令牌优缺点
- 优点:
- 支持PC端、移动端
- 解决集群环境下的认证问题
- 减轻服务器的存储压力(无需在服务器端存储)
- 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验
JWT令牌
JWT ( JSON Web token ):将原始的json格式进行了安全的封装,这样直接基于jwt在通信双方安全中进行信息传输
JWT组成:

-
第一部分Header(头):令牌类型,签名算法
-
第二部分Payload(有效载荷):携带一些自定义信息,默认信息,令牌有效时间等
-
第三部分Signature(签名):第一部分第二部分base64编码后+密钥的共同组成 然后通过签名算法计算后而来
注:
第一部分第二部分密钥都是要base64编码后的结果
JWT是如何将原始的JSON格式数据,转变为字符串的呢?
-
其实在生成JWT令牌时,会对JSON格式的数据进行一次编码:进行base64编码
-
Base64:是一种基于64个可打印的字符来表示二进制数据的编码方式。既然能编码,那也就意味着也能解码。所使用的64个字符分别是A到Z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号
-
需要注意的是Base64是编码方式,而不是加密方式。
-
为了保持编码后的数据长度是 4 的倍数,Base64 编码引入了填充字符
=。
java代码实现JWT令牌生成和校验
1.配置xml
<!-- JWT依赖-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
JWT令牌生成
/*
* JWT令牌生成
* */
public void BuilderJwt(){
Map<String,Object> claims=new HashMap<>();
claims.put("id",10);
claims.put("username","itheima");
String jwt=Jwts.builder()
.signWith(SignatureAlgorithm.HS256,"aXRoZWltYQ==") //signWith(签名算法,密钥) //密钥:要足够安全,较复杂
.addClaims(claims) //添加自定义信息(数据) addClaims(需要Map类型)
.setExpiration(new Date(System.currentTimeMillis()+ 12 * 3600 * 1000)) //设置令牌有效时间一天 当前时间的+一天
.compact(); //.compact();这个作用只是把base64编码后的header、payload 和 signature 部分编码成一个紧凑的字符串形式
System.out.println(jwt);
//输出 eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MTAsInVzZXJuYW1lIjoiaXRoZWltYSIsImV4cCI6MTc0MjA4MzA5Nn0.Pm-oFicKf_e3GZnH3OguBiew4KE3mhe6ifI9AGHGjHg
}
builder paser
JWT令牌的校验解析
/*
* 校验JWT令牌
* */
@Test
public void PaserJwt(){
String token="eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MTAsInVzZXJuYW1lIjoiaXRoZWltYSIsImV4cCI6MTc0MjA4MzA5Nn0.Pm-oFicKf_e3GZnH3OguBiew4KE3mhe6ifI9AGHGjHg";
Claims claims=Jwts.parser()
.setSigningKey("aXRoZWltYQ==") //添加解析校验的 密钥
.parseClaimsJws(token) //添加要解析的JWT令牌
.getBody();
System.out.println(claims);
}
密钥

通过以上测试,我们在使用JWT令牌时需要注意:
- JWT校验时使用的签名秘钥,必须和生成JWT令牌时使用的秘钥是配套的。
- 如果JWT令牌解析校验时报错,则说明 JWT令牌被篡改 或 失效了,令牌非法
具体实现
JWT工具类
public class JwtUtils {
private static String signKey = "SVRIRUlNQQ==";
private static Long expire = 43200000L;
/**
* 生成JWT令牌
*/
public static String generateJwt(Map<String,Object> claims){
String jwt = Jwts.builder()
.addClaims(claims)
.signWith(SignatureAlgorithm.HS256, signKey)
.setExpiration(new Date(System.currentTimeMillis() + expire))
.compact();
return jwt;
}
/**
* 解析JWT令牌
*/
public static Claims parseJWT(String jwt){
Claims claims = Jwts.parser()
.setSigningKey(signKey)
.parseClaimsJws(jwt)
.getBody();
return claims;
}
}
完善 EmpServiceImpl中的 login 方法逻辑, 登录成功,生成JWT令牌并返回
/*
* 登录操作
* Service层:判断
* */
public LoginInfo login(Emp emp){
Emp e =empMapper.selectByUsernameAndPassword(emp);
//判断员工是否存在
if (e!=null){
//生成JWT令牌
Map<String, Object> claims=new HashMap<>();
claims.put("id",emp.getId());
claims.put("username",emp.getUsername());
String jwt=JwtUtils.generateJwt(claims);
return new LoginInfo(e.getDeptId(),e.getUsername(),e.getName(),jwt );
}
else {
return null;
}
}
服务器响应的JWT令牌存储在本地浏览器哪里了呢?
- 在当前案例中,JWT令牌存储在浏览器的本地存储空间
localstorage中了。localstorage是浏览器的本地存储,在移动端也是支持的。
我们在发起一个查询部门数据的请求,此时我们可以看到在请求头中包含一个token(JWT令牌),后续的每一次请求当中,都会将这个令牌携带到服务端。
我们在发起一个查询部门数据的请求,此时我们可以看到在请求头中包含一个token(JWT令牌),后续的每一次请求当中,都会将这个令牌携带到服务端。

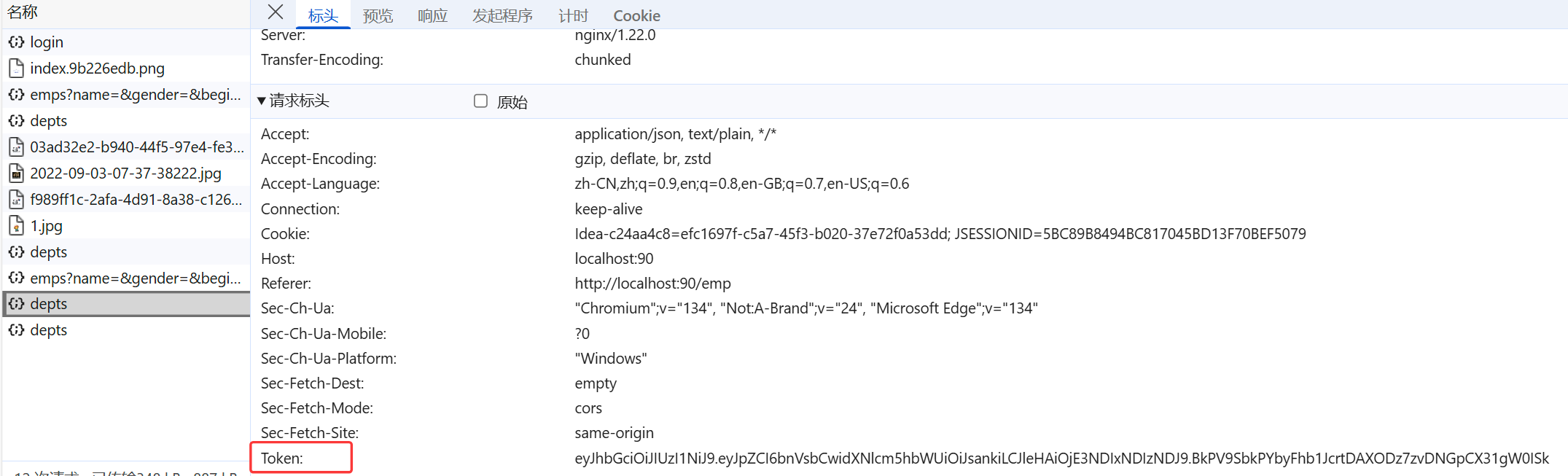
token大多数说的就是JWT令牌
过滤器Filter
过滤器Filter
是 JavaWeb三大组件(Servlet、Filter、Listener)之一。
- 使用了过滤器之后,要想访问web服务器上的资源,必须先经过滤器,过滤器处理完毕之后,才可以访问对应的资源。
@WebFilter(urlPatterns = "/") //配置过滤器要拦截的请求路径( / 表示拦截浏览器的所有请求 )
@ServletComponentScan //开启对Servlet组件的支持
Filter入门案例
1.定义过滤器
实现javaweb自带的Filter接口类
@WebFilter(urlPatterns = "/*") //配置过滤器要拦截的请求路径( /* 表示拦截浏览器的所有请求 )
@Slf4j
public class DemoFilter implements Filter {
@Override
//初始化方法, web服务器启动, 创建Filter实例时调用, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
log.info("==init初始化==");
}
@Override
//拦截到请求时,调用该方法,可以调用多次
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
log.info("==拦截方法===");
//放行请求
//chain.doFilter(request, response);
}
@Override
//销毁方法, web服务器关闭时调用, 只调用一次
public void destroy() {
log.info("==destroy销毁==");
}
}
@ServletComponentScan //开启对Servlet组件的支持
@SpringBootApplication
public class TliasManagementApplication {
public static void main(String[] args) {
SpringApplication.run(TliasManagementApplication.class, args);
}
}
Filter校验JWT
登录校验过滤器
- 所有的请求,拦截到了之后,都需要校验令牌吗 ?
- 答案:登录请求例外(现在不考虑注册)
- 拦截到请求后,什么情况下才可以放行,执行业务操作 ?
- 答案:有令牌,且令牌校验通过(合法);否则都返回未登录错误结果
具体流程
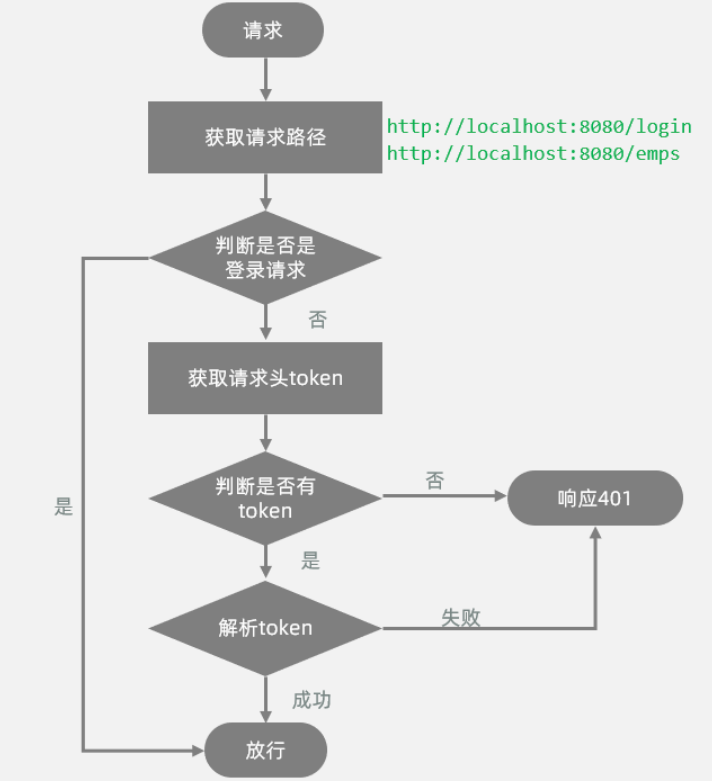
/*
* JWT检验-过滤Filter
* */
@Slf4j
@WebFilter(urlPatterns = "/*")
public class TokenFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
//解析请求路径,判断
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
String url=request.getRequestURI(); //获取URI /login /emps这种
// 判断请求url中是否包含login,如果包含,说明是登录操作,放行。
if(url.contains("login")){
//放行
chain.doFilter(request,response);
return;
}
String token=request.getHeader("token");
// 判断令牌是否存在,如果不存在,返回错误结果(未登录)
if(token==null||token.isEmpty()){
response.setStatus(401); // 401 = HttpStatus.SC_UNAUTHORIZED
return;
}
//解析token,如果解析失败,返回错误结果(未登录)
try {
JwtUtils.parseJWT(token);
} catch (Exception e) {
response.setStatus(401);
return;
}
//放行
chain.doFilter(request,response);
}
}
@ServletComponentScan //开启对Servlet组件的支持
@SpringBootApplication
public class TliasManagementApplication {
public static void main(String[] args) {
SpringApplication.run(TliasManagementApplication.class, args);
}
}
当退出登录后,直接再访问http://localhost:90/emp这个地址就不行了,因为令牌不存在,所以这时候就需要重写登录才能访问
为什么校验令牌用try-catch就能实现,当令牌非法会有异常吗
会有异常,当令牌非法时候:底层进行 JWT 解析和验证时检测到错误而抛出的
程序报错:包括 异常,错误等
过滤器Filter详解
执行流程

过滤器链:配置多个过滤器,多个过滤器组成一个过滤器链
chain.doFilter(request, response); //过滤放行到下一个过滤器,如果没有,就是访问资源
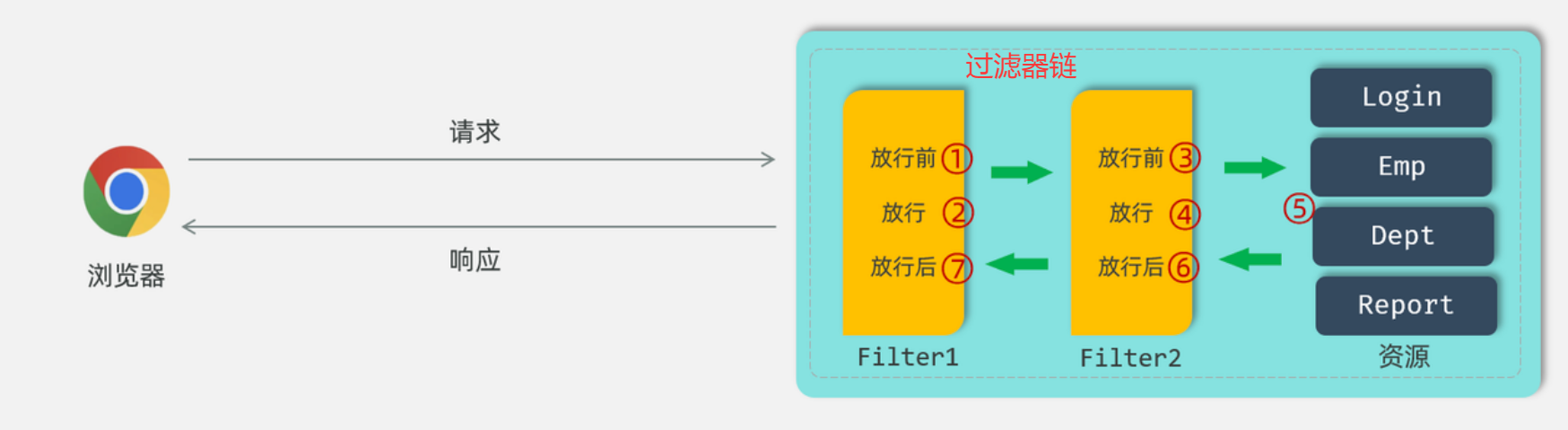 比如:在我们web服务器当中,定义了两个过滤器,这两个过滤器就形成了一个过滤器链。
比如:在我们web服务器当中,定义了两个过滤器,这两个过滤器就形成了一个过滤器链。
而这个链上的过滤器在执行的时候会一个一个的执行,会先执行第一个Filter,放行之后再来执行第二个Filter,如果执行到了最后一个过滤器放行之后,才会访问对应的web资源。
访问完web资源之后,按照我们刚才所介绍的过滤器的执行流程,还会回到过滤器当中来执行过滤器放行后的逻辑,而在执行放行后的逻辑的时候,顺序是反着的。
先要执行过滤器2放行之后的逻辑,再来执行过滤器1放行之后的逻辑,最后在给浏览器响应数据
过滤器链上过滤器的执行顺序:注解配置的Filter,优先级是按照过滤器类名(字符串)的自然排序。 比如:
- AbcFilter
- DemoFilter
这两个过滤器来说,AbcFilter 会先执行,DemoFilter会后执行。
拦截器Interceptor
-
使用:1.定义拦截器配置类
-
配置类中继承WebMvcConfigurer,无需写@Bean
-
重写addInterceptors方法
-
.addPathPatterns :拦截路径 .excludePathPatterns:不拦截路径
-
registry.addInterceptor(要拦截的自定义拦截器对象) //拦截哪个拦截器
-
-
如果涉及到多个拦截器 要有执行顺序 使用 .order(数字越小先执行) 具体点击这
-
-
2.自定义拦截器
- 自定义拦截器中继承 HandlerInterceptor
- 无需@Compoent,因为配置类中registry.addInterceptor()中已经指明,创建好实例了
- 重写preHandle(拦截之前要做的),afterCompletion(拦截后执行完后做的)等方法
- 自定义拦截器中要使用其它注入其它bean对象,只能通过构造器注入 具体点击这
- 因为拦截器是我们手动 new 出来的,而不是由 Spring 容器管理
当您在配置类中通过实现
WebMvcConfigurer接口来注册拦截器时,Spring MVC会自动处理拦截器的创建和依赖注入,因此不需要额外使用@Bean或@Component注解。这种方式简化了拦截器的配置过程,并使得代码更加清晰和易于管理。
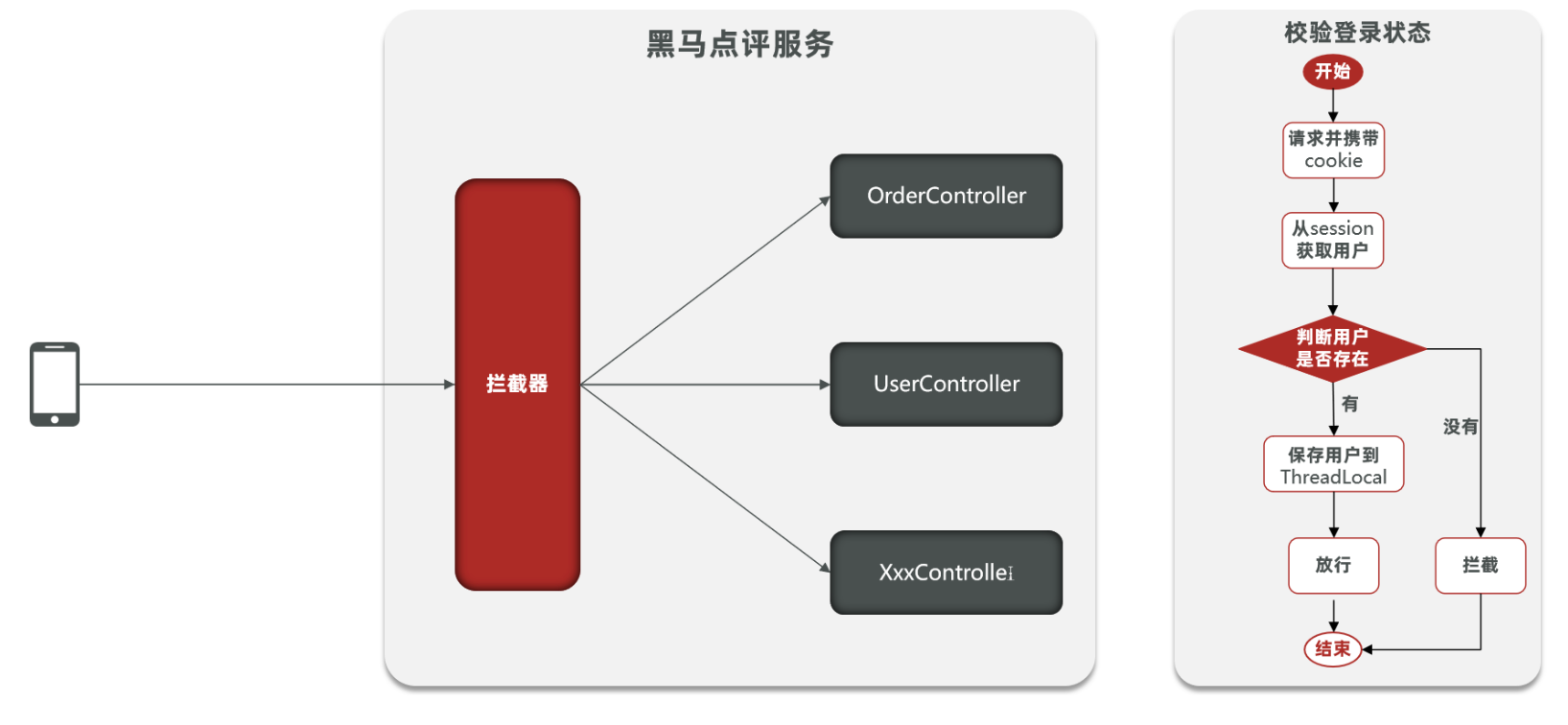
具体代码示例
1).配置拦截器
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginInterceptor(stringRedisTemplate)) //拦截哪个拦截器
.excludePathPatterns( //不拦截的路径
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
); //不拦截的路径
// .addPathPatterns("/**"); //拦截路径
}
}
2).自定义拦截器
public class LoginInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
//自定义拦截器中要使用其它注入其它bean对象,只能通过构造器注入!
public LoginInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
//拦截器 true:放行 false:拦截
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//获取请求头中的token
String token=request.getHeader("authorization");
//基于token从redis中获取用户
String key = LOGIN_USER_KEY + token;
Map<Object, Object> userMap =stringRedisTemplate.opsForHash().entries(key);
//判断用户是否存在
if (userMap.isEmpty()) {
//不存在用户,拦截
response.setStatus(401);
return false;
}
//TODO 有个true 和 false 错误
//将查询到的userMap转换为userDTO
UserDTO userDTO=BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
//存在用户,保存用户到ThreadLocal
UserHolder.saveUser(userDTO);
//更新token有效期
stringRedisTemplate.expire(key,3L, TimeUnit.MINUTES);
//放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
//结束后,删除用户
UserHolder.removeUser();
}
}
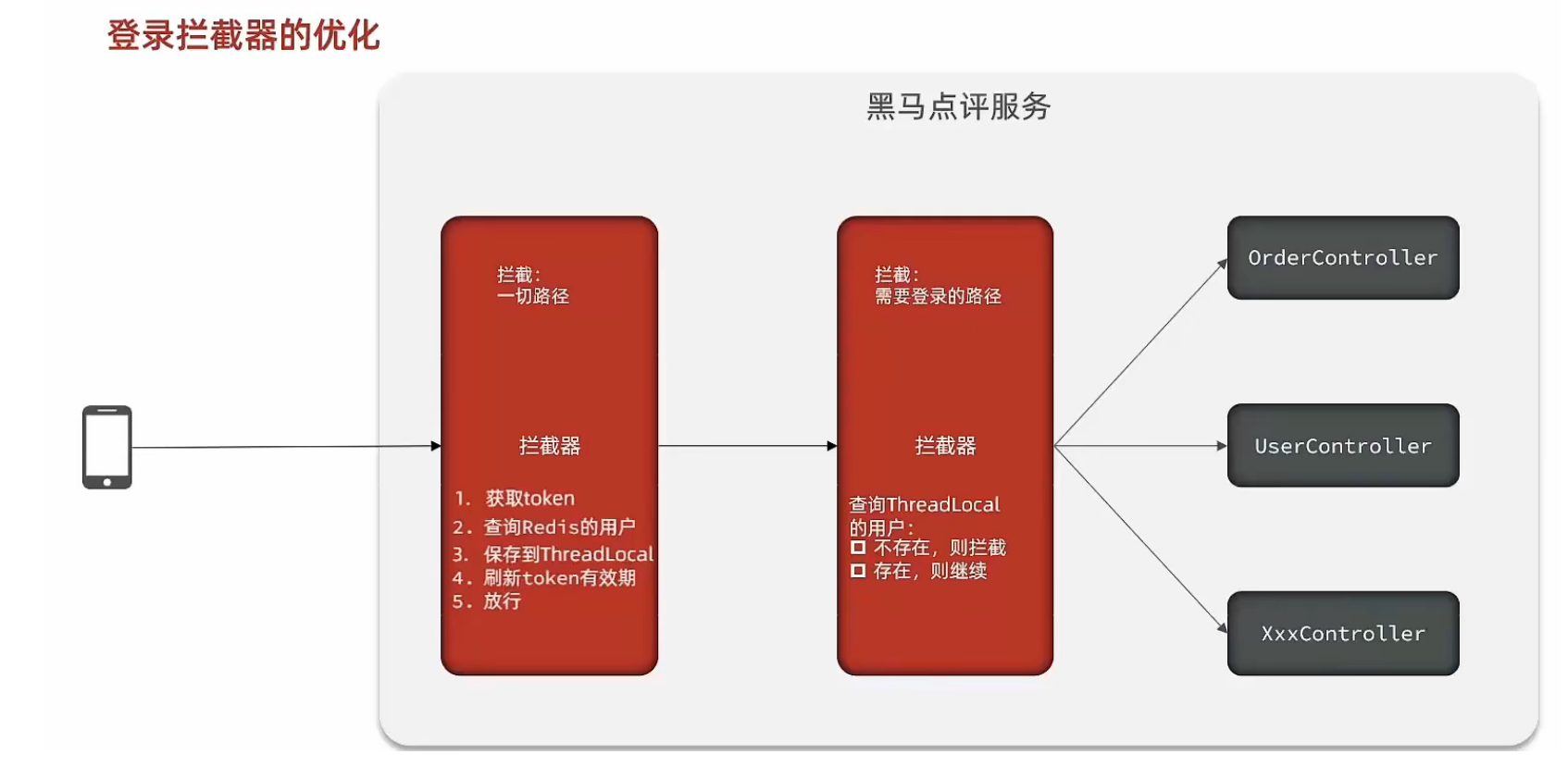
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Override
public void addInterceptors(InterceptorRegistry registry) {
//order(0)先执行 order(1)后执行
registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate))
.addPathPatterns("/**").order(0);
registry.addInterceptor(new LoginInterceptor()) //拦截哪个拦截器
.excludePathPatterns( //不拦截的路径
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
).order(1); //不拦截的路径
// .addPathPatterns("/**"); //拦截路径
}
}
public class RefreshTokenInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
//拦截器 true:放行 false:拦截
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//获取请求头中的token
String token=request.getHeader("authorization");
if (StrUtil.isBlank(token)) {
return true;
}
//基于token从redis中获取用户
String key = LOGIN_USER_KEY + token;
Map<Object, Object> userMap =stringRedisTemplate.opsForHash().entries(key);
//判断用户是否存在
if (userMap.isEmpty()) {
//不存在用户,拦截
return true;
}
//将查询到的userMap转换为userDTO
UserDTO userDTO=BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
//存在用户,保存用户到ThreadLocal
UserHolder.saveUser(userDTO);
//更新token有效期
stringRedisTemplate.expire(key,3L, TimeUnit.MINUTES);
//放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
//结束后,删除用户
UserHolder.removeUser();
}
}
public class LoginInterceptor implements HandlerInterceptor {
@Override
//拦截器 true:放行 false:拦截
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.判断是否需要拦截(ThreadLocal中是否有用户)
if (UserHolder.getUser() == null) {
// 没有,需要拦截,设置状态码
response.setStatus(401);
// 拦截
return false;
}
// 有用户,则放行
return true;
}
}
另外
- spring框架提供的
- 拦截器使用:1.定义自定义拦截器 2.定义拦截器配置类
底层:先执行拦截器配置类,然后执行要拦截的自定义拦截器,最后要拦截的路径
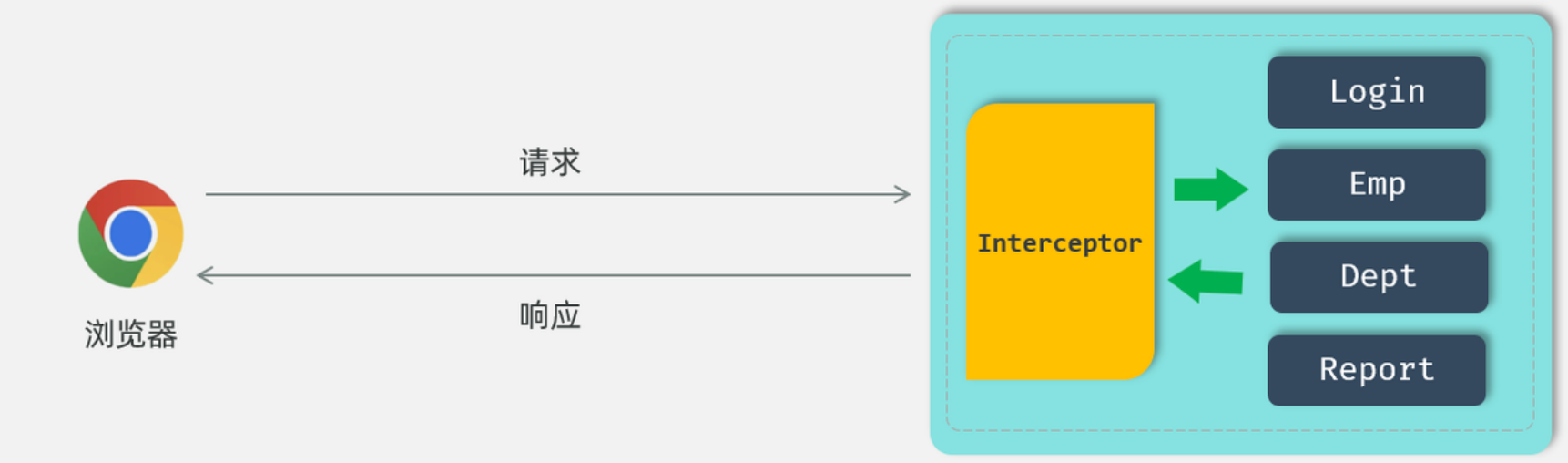
在拦截器当中,我们通常也是做一些通用性的操作,比如:我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(携带JWT令牌且是合法令牌),就可以直接放行,去访问spring当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。
拦截器的使用步骤:1.定义拦截器 2.注册配置拦截器
入门案例步骤
/*
* 自定义拦截器
* */
@Slf4j
@Component
public class DemoInterceptor implements HandlerInterceptor {
//目标资源方法执行前执行。 返回true:放行 返回false:不放行
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
log.info("资源执行前");
return true; //放行
}
//目标资源方法执行后执行
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
log.info("===倒数第二步骤===");
}
//视图渲染完毕后执行,最后执行
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
log.info("===最后===");
}
}
@Configuration //表明是配置类,交给spring管理
public class WebConfig implements WebMvcConfigurer {
@Autowired
private DemoInterceptor demoInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(demoInterceptor) //拦截哪个拦截器
.addPathPatterns("/**"); //拦截路径
}
}
Interceptor校验JWT
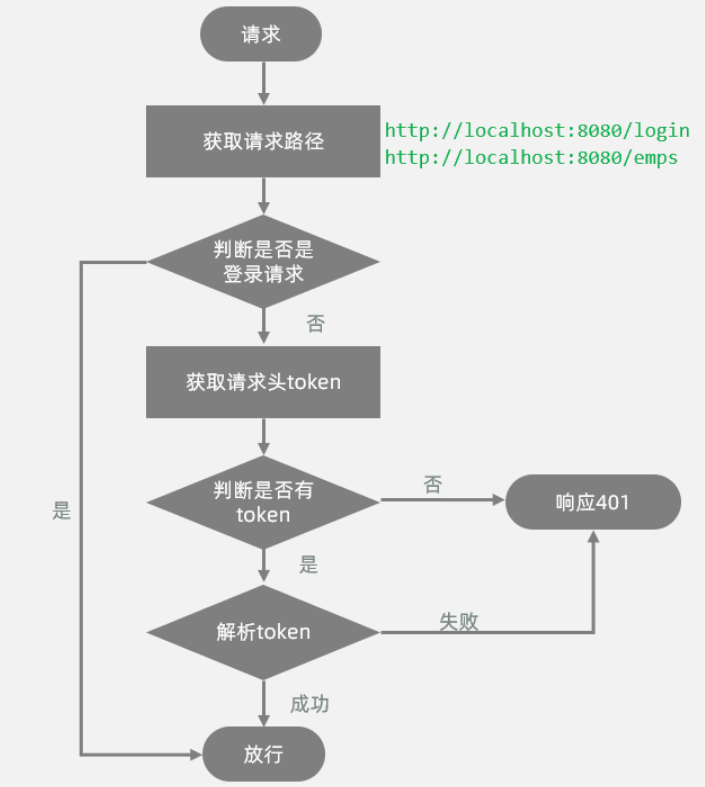
@Slf4j
@Component
public class TokenInterceptor implements HandlerInterceptor {
@Override
//目标资源方法执行前执行。 返回true:放行 返回false:不放行
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String url=request.getRequestURI(); //获取URI /login /emps这种
// 判断请求url中是否包含login,如果包含,说明是登录操作,放行。
if(url.contains("login")){
return true; //放行
}
String token=request.getHeader("token");
// 判断令牌是否存在,如果不存在,返回错误结果(未登录)
if(token==null||token.isEmpty()){
response.setStatus(401); // 401 = HttpStatus.SC_UNAUTHORIZED
return false;
}
//解析token,如果解析失败,返回错误结果(未登录)
try {
JwtUtils.parseJWT(token);
} catch (Exception e) {
response.setStatus(401);
return false;
}
return true;//放行
}
}
@Configuration //表明是配置类,交给spring管理
public class WebConfig implements WebMvcConfigurer {
@Autowired
private TokenInterceptor tokenInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(tokenInterceptor) //拦截哪个拦截器
.addPathPatterns("/**"); //拦截路径
}
}
-
测试
退出登录是否可以访问http://localhost:90/emp
- 不可以访问:拦截成功
- 可以访问:那就是没完成拦截,代码错误什么的
拦截路径
配置类中拦截路径
-
addPathPatterns(“要拦截路径”)
-
excludePathPatterns(“不拦截路径”)
-
/* /**区别
-
拦截路径 含义 举例 /* 一级路径 能匹配/depts,/emps,/login,不能匹配 /depts/1 /** 任意级路径 能匹配/depts,/depts/1,/depts/1/2 /depts/* /depts下的一级路径 能匹配/depts/1,不能匹配/depts/1/2,/depts /depts/** /depts下的任意级路径 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1
-
/*
* 拦截器配置类
* */
@Configuration //表明是配置类,交给spring管理
public class WebConfig implements WebMvcConfigurer {
/*@Autowired
private DemoInterceptor demoInterceptor;*/
@Autowired
private TokenInterceptor tokenInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(tokenInterceptor) //拦截哪个拦截器
.addPathPatterns("/**") //拦截路径
.excludePathPatterns("/login"); //不拦截的路径 不拦截登录请求直接放行
}
}
过滤器PK拦截器
执行流程
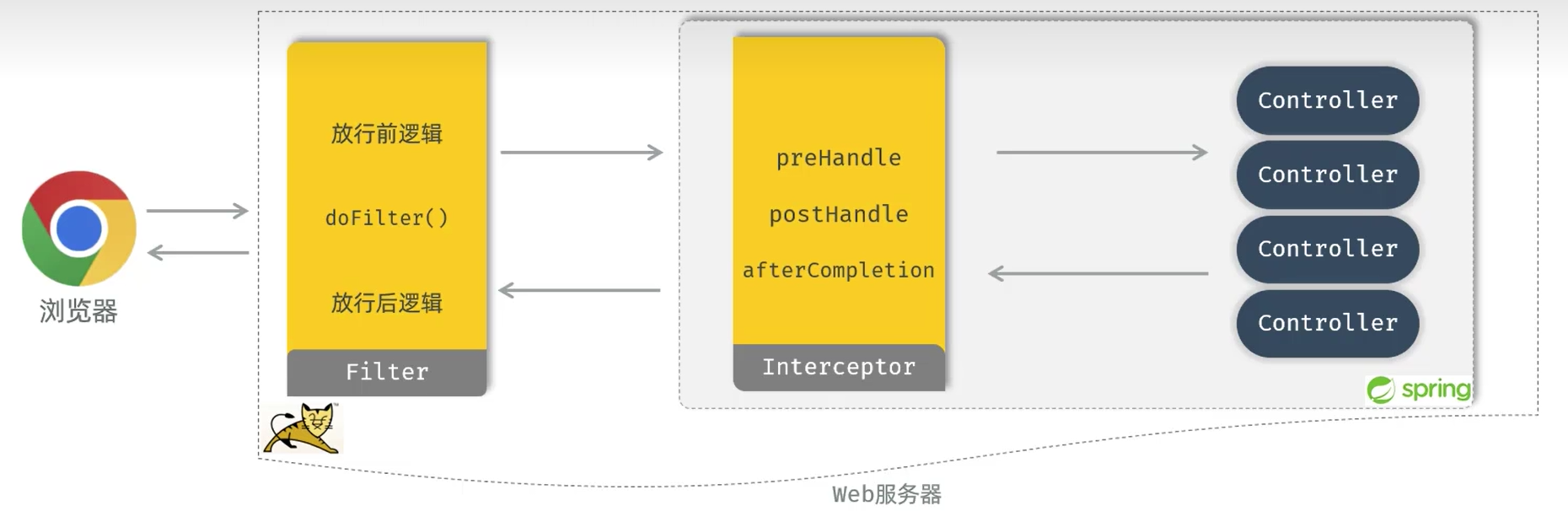
游览器访问后端 -> 执行过滤器(Filter)放行前操作 -> 过滤器放行( doFilter ) -> 执行拦截器(Interceptor)-> 拦截器放行(preHandle)-> 访问Controller -> Controller当中方法执行完 -> 反过来执行拦截器(postHandle和afterCompletion)
-> 执行过滤器方法中放行后的操作 ->最终给浏览器响应数据
过滤器 - 拦截器 区别
- 接口规范不同:过滤器实现Filter接口 ,拦截器实现HandlerInterceptor接口
- 拦截范围不同:过滤器拦截所有资源 , 拦截器只会拦截spring环境中的资源
SpringAOP
基础知识
AOP:Aspect Oriented Programming (面向切面编程)
即:面向切面编程就是面向特定方法编程
比如:我要统计部门管理各个业务层方法执行耗时
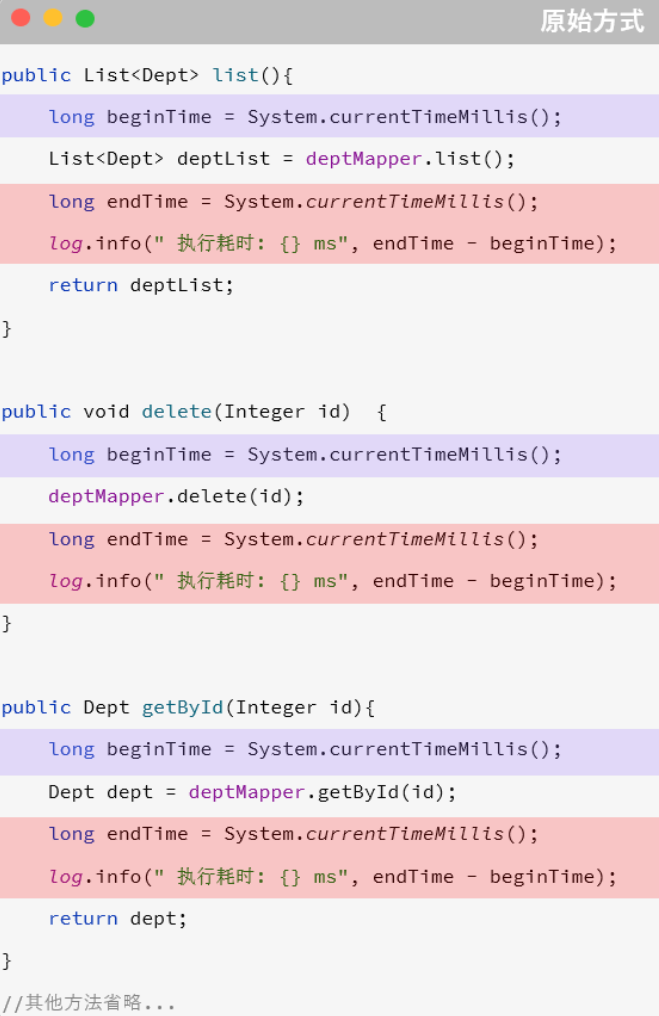
AOP方式
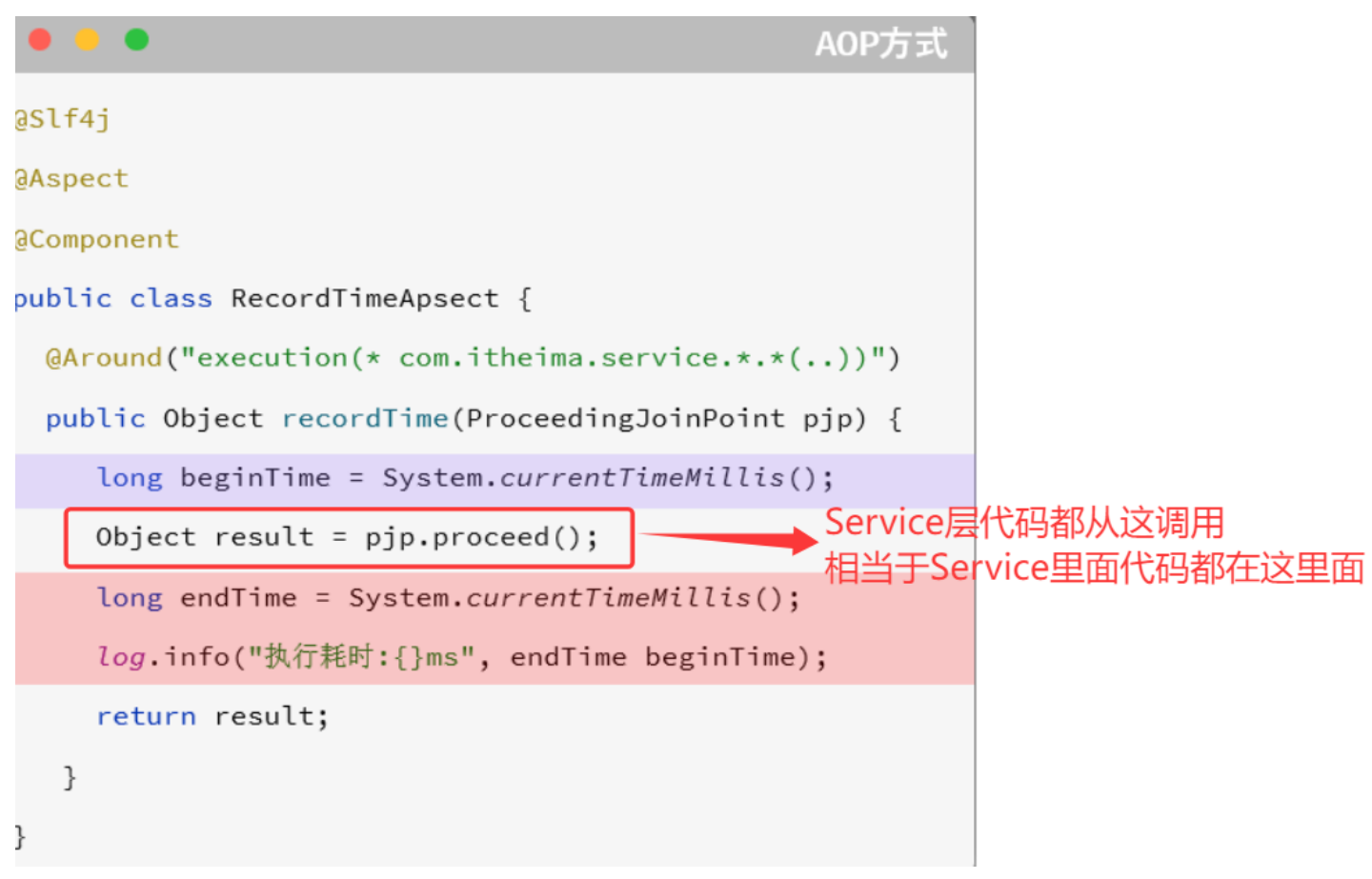
AOP优势:
- 减少代码重复性:不需要在业务方法中定义大量的重复性的代码,只需要将重复性的代码抽取到AOP程序中即可。
- 代码无侵入:在基于AOP实现这些业务功能时,对原有的业务代码是没有任何侵入的,不需要修改任何的业务代码。
- 提高开发效率
- 维护方便
入门程序
1.配置AOP的配置
<!-- AOP起步依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
- 编写AOP程序:针对于特定方法根据业务需要进行编程
/*
* AOP来统计部门管理各个业务层方法执行耗时
* */
@Slf4j
@Aspect //说明当前是AOP切面类
@Component //交给spring管理
public class RecordTimeAspect {
@Around("execution(* com.itheima.service.impl.*.*(..))") //后面会具体说明
public Object recordTime(ProceedingJoinPoint pjp) throws Throwable {
long beginTime=System.currentTimeMillis();
/*
*
* */
Object object=pjp.proceed(); //执行原始方法 AOP面向特定方法的
long endTime=System.currentTimeMillis();
log.info("方法{} 耗时{}",pjp.getSignature(),beginTime-endTime); // pjp.getSignature() :获取pjp中的函数名
return object;
}
}
我们通过AOP入门程序完成了业务方法执行耗时的统计,那其实AOP的功能远不止于此,常见的应用场景如下:
- 记录系统的操作日志
- 权限控制
- 事务管理:我们前面所讲解的Spring事务管理,底层其实也是通过AOP来实现的,只要添加@Transactional注解之后,AOP程序自动会在原始方法运行前先来开启事务,在原始方法运行完毕之后提交或回滚事务
这些都是AOP应用的典型场景。
核心概念
基础概念

切入点:被AOP控制的方法,匹配连接点的条件
目标对象:像通知这里应用DeptServiceImpl对象,所以DeptServiceImpl是目标对象
@Around("execution(* com.itheima.service.impl.DeptServiceImpl.*(..))")
AOP底层-动态代理
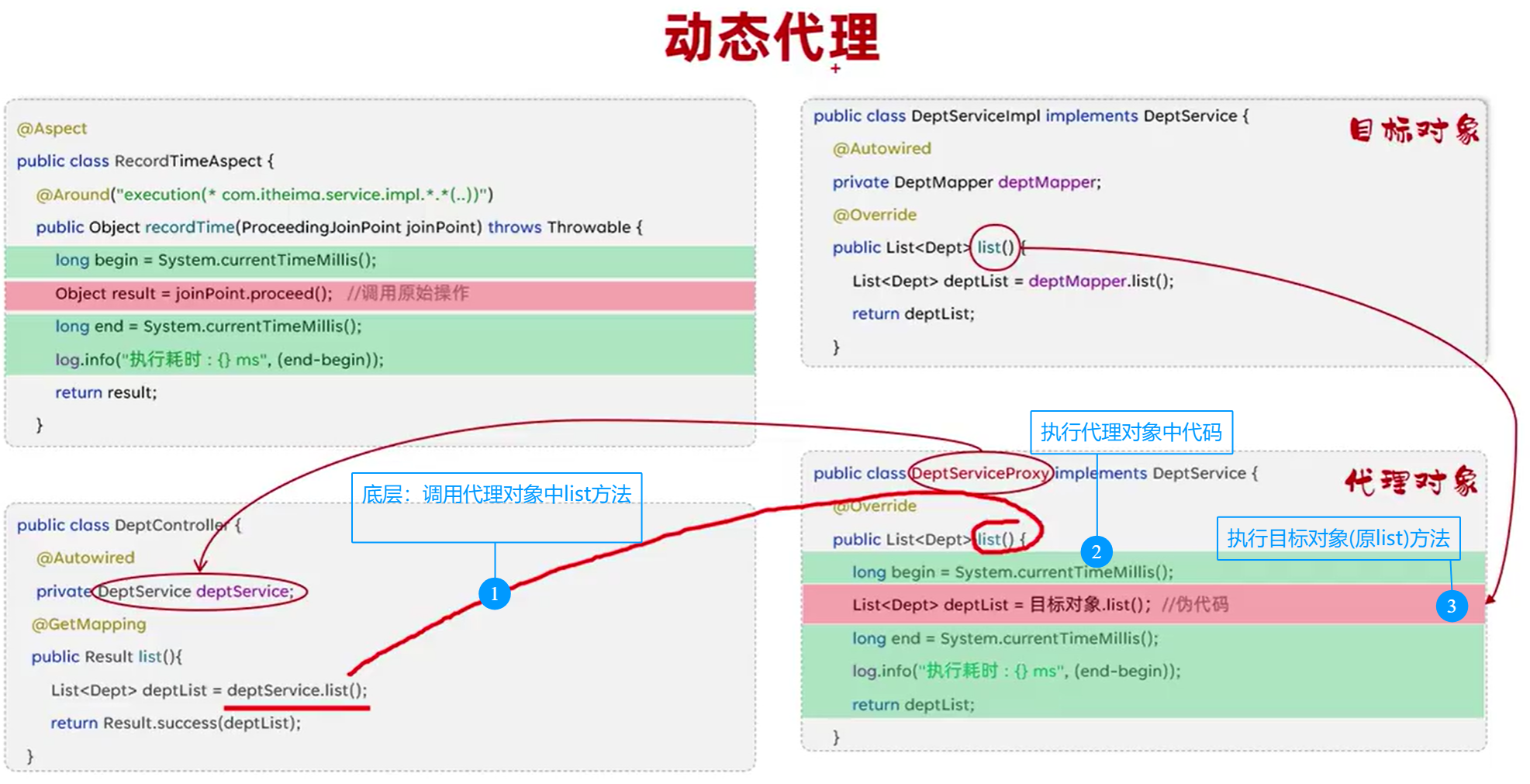
AOP底层:创建一个代理对象
DeptController层中list()调用的底层是代理对象中的list()
通知类型
| Spring AOP 通知类型 | |
|---|---|
| @Around | **环绕通知,此注解标注的通知方法在目标方法前、后都被执行 ** |
| @Before | 前置通知,此注解标注的通知方法在目标方法前被执行 |
| @After | 后置通知,此注解标注的通知方法在目标方法后被执行,无论是否有异常都会执行 |
| @AfterReturning | 返回后通知,此注解标注的通知方法在目标方法后被执行,有异常不会执行 |
| @AfterThrowing | 异常后通知,此注解标注的通知方法发生异常后执行 |
注意事项:
- @Around环绕通知需要自己调用 ProceedingJoinPoint.proceed() 来让原始方法执行,其他通知不需要考虑目标方法执行
- @Around环绕通知方法的返回值,必须指定为Object,来接收原始方法的返回值,否则原始方法执行完毕,是获取不到返回值的。
@Slf4j
@Component
@Aspect
public class MyAspect1 {
//前置通知
@Before("execution(* com.itheima.service.*.*(..))")
public void before(){
log.info("before..");
}
/*
* 最重要
* @Around:1.要调用目标对象方法 2.返回类型为Object
* */
//环绕通知
@Around("execution(* com.itheima.service.*.*(..))")
public Object around(ProceedingJoinPoint pjp) throws Throwable {
log.info("around-before...");
Object object=pjp.proceed();
log.info("around-after...");
return object;
}
//后置通知
@After("execution(* com.itheima.service.*.*(..))")
public void after(JoinPoint joinPoint){
log.info("after ...");
}
//返回后通知,目标方法执行后运行,有异常不会执行
@AfterReturning("execution(* com.itheima.service.*.*(..))")
public void afterReturning(JoinPoint joinPoint){
log.info("afterReturning ...");
}
//有异常后通知,目标方法执行后运行,只有出现异常才会执行
@AfterThrowing("execution(* com.itheima.service.*.*(..))")
public void afterThrowing(JoinPoint joinPoint){
log.info("afterThrowing ...");
}
}

@Pointcut注解

@Slf4j
@Component
@Aspect
public class MyAspect1 {
/*
* 抽取大量切入点表达式中相同的
* */
@Pointcut("execution(* com.itheima.service.*.*(..))")
private void pt(){}
//前置通知
@Before("pt()")
public void before(){
log.info("before..");
}
/*
* 最重要
* @Around:1.要调用目标对象方法 2.返回类型为Object
* */
//环绕通知
@Around("pt()")
public Object around(ProceedingJoinPoint pjp) throws Throwable {
log.info("around-before...");
Object object=pjp.proceed();
log.info("around-after...");
return object;
}
}
需要注意的是:当切入点方法使用private修饰时,仅能在当前切面类中引用该表达式, 当外部其他切面类中也要引用当前类中的切入点表达式,就需要把private改为public,而在引用的时候,具体的语法为:
@Slf4j
@Component
@Aspect
public class MyAspect2 {
//引用MyAspect1切面类中的切入点表达式
@Before("com.itheima.aspect.MyAspect1.pt()")
public void before(){
log.info("MyAspect2 -> before ...");
}
}
IDEA中小图标
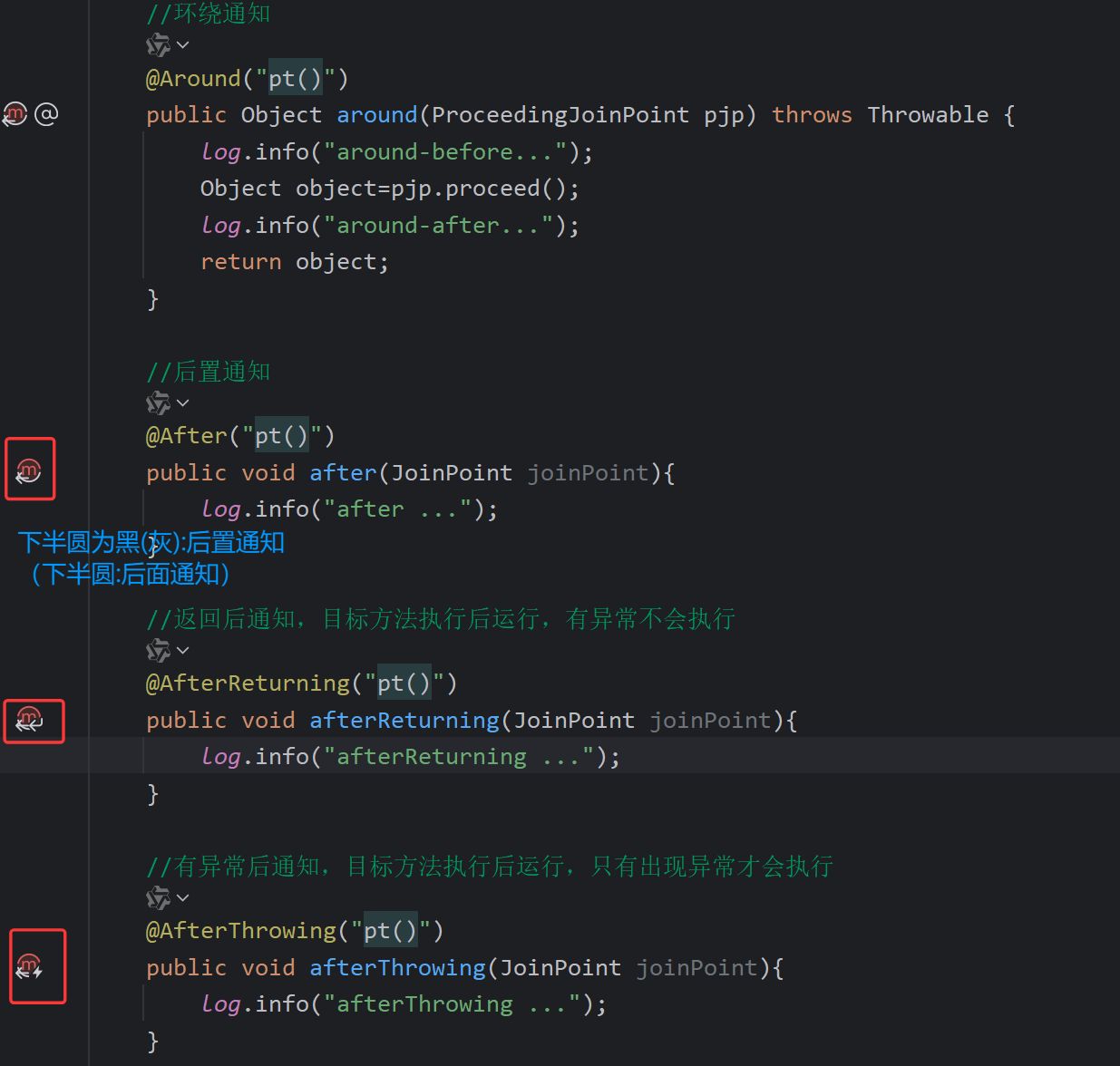
通知顺序
当存在多个切面类的,执行顺序是按照切面类类名字母排序先后执行
- 默认按照切面类的类名字母排序:
- 目标方法前的通知方法:字母排名靠前的先执行
- 目标方法后的通知方法:字母排名靠前的后执行
@Before执行顺序:MyAspect2 -> MyAspect 3 ->MyAspect4
@After执行顺序: MyAspect4 -> MyAspect 3 ->MyAspect2
@Order() 注解
@Slf4j
@Component
@Aspect
@Order(2) //切面类的执行顺序(前置通知:数字越小先执行; 后置通知:数字越小越后执行)
public class MyAspect2 {
//前置通知
@Before("execution(* com.itheima.service.*.*(..))")
public void before(){
log.info("MyAspect2 -> before ...");
}
//后置通知
@After("execution(* com.itheima.service.*.*(..))")
public void after(){
log.info("MyAspect2 -> after ...");
}
}
Spring提供通知执行先后顺序注解 @Order 类上注解,表明存在多个切面类的时候执行顺序
@Before执行顺序: @Order(2) -> @Order(3) -> @Order(4)
@After执行顺序: @Order(4) -> @Order(3) -> @Order(2)
切入点表达式
常见形式:
-
execution():方法签名来匹配
-
@Before("execution(* com.itheima.service.impl.*.*(*))") execution(访问修饰符(可省略) 返回值 包名.类名.(可省略)方法名(方法参数) throws 异常(可省略)) -
com.itheima.service.impl.DeptServiceImpl:指定 具体的类(DeptServiceImpl)。 * 任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分 .. 任意包,任意参数个数
-
-
@annotation:根据注解来匹配
-
@Before("@annotation(com.itheima.annotation.LogOperation)") -
在切入点的目标对象的函数上加上注解
-
execution



@Slf4j
@Component
@Aspect
public class MyAspectExecution {
/*
* execution:根据方法的签名来匹配
* execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throws 异常?)
* */
//@Before("execution(public void com.itheima.service.impl.DeptServiceImpl.delete(java.lang.Integer))")
//@Before("execution(* com.itheima.*.*.delete(*))")
//@Before("execution(* com.itheima.service.*.*(..))")
//@Before("execution(* com.itheima.service.impl.*.delete(*))")
//@Before("execution(* com.itheima..*.*(..))") //itheima包下的所有类的所有方法
//@Before("execution(* com.itheima.service.impl..*.*e(*))")
//使用 且(&&)、或(||)、非(!) 来组合比较复杂的切入点表达式。
//@Before("execution(* com.itheima.service.impl.*.delete(..))||execution(* com.itheima.service.impl.*.list(..))")
@Before("execution(* com.itheima.service.impl.*.*(*))")
public void before(){
log.info("before..");
}
}
@annotation
通过注解来写切入点表达式
自定义注解
/*
* 自定义注解
* */
@Target(ElementType.METHOD) //在方法上生效
@Retention(RetentionPolicy.RUNTIME) //在运行时生效
public @interface LogOperation {
}
@Slf4j
@Component
@Aspect
public class MyAspectExecution {
/*
* @annotation
* 根据(全类名)注解匹配
* */
@Before("@annotation(com.itheima.annotation.LogOperation)")
public void before2(){
log.info("before..");
}
}
连接点
获取连接点信息:方法执行时的相关信息,如目标类名、方法名、方法参数等
- 对于环绕通知@Around,获取连接点信息只能通过ProceedingJoinPoint
- @Around特有的方法 Object object =proceedingJoinPiont.proceed(); //执行原始方法,获取返回值
- 对于其它四种通知,获取连接点信息只能通过JoinPoint

@Slf4j
@Component
@Aspect
public class MyAspectJoinPoint {
/*
* 对于@Around通知
* 获取连接点信息只能通过ProceedingJoinPoint获取
* */
@Around("execution(* com.itheima.service.impl.*.*(..))")
public Object around(ProceedingJoinPoint pjp) throws Throwable {
log.info("around...");
//获取目标对象
Object obj =pjp.getTarget();
log.info("获取目标对象{}",obj);
//获取目标类名
String className=pjp.getTarget().getClass().getName();
log.info("获取目标类名{}",className);
//获取目标方法名
String methodName=pjp.getSignature().getName();
log.info("获取目标方法{}",methodName);
//获取目标参数
Object[] args =pjp.getArgs();
log.info("获取目标参数{}", Arrays.toString(args));
//执行原始方法,获取返回值(@Around特有)
Object object =pjp.proceed();
log.info("执行原始方法,获取返回值{}",object);
return object;
}
/*
* 对于除了@Around外其它四种通知
* 获取连接点信息只能通过JoinPoint
* */
@Before("execution(* com.itheima.service.impl.*.*(..))")
public void before(JoinPoint joinPoint){
log.info("before...");
//获取目标对象
Object object =joinPoint.getTarget();
log.info("获取目标对象{}",object);
//获取目标类名
String className=joinPoint.getTarget().getClass().getName();
log.info("获取目标类名{}",className);
//获取目标方法名
String methodName=joinPoint.getSignature().getName();
log.info("获取目标方法{}",methodName);
//获取目标参数
Object[] args =joinPoint.getArgs();
log.info("获取目标参数{}", Arrays.toString(args));
}
}
AOP案例
- 需求
需求:将案例(Tlias智能学习辅助系统)中增、删、改相关接口的操作日志记录到数据库表中
- 就是当访问部门管理和员工管理当中的增、删、改相关功能接口时,需要详细的操作日志,并保存在数据表中,便于后期数据追踪。
操作日志信息包含:
- 操作人、操作时间、执行方法的全类名、执行方法名、方法运行时参数、返回值、方法执行时长
步骤
简单分析了一下大概的实现思路后,接下来我们就要来完成案例了。案例的实现步骤其实就两步:
- 准备工作
- 引入AOP的起步依赖
- 导入资料中准备好的数据库表结构,并引入对应的实体类
- 编码实现(基于AI实现)
- 自定义注解
@LogOperation - 定义切面类,完成记录操作日志的逻辑
- 自定义注解
1.配置AOP配置文件
<!-- AOP起步依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
2.自定义注解
/*
* 自定义注解
* */
@Target(ElementType.METHOD) //在方法上生效
@Retention(RetentionPolicy.RUNTIME) //在运行时生效
public @interface LogOperation {
}
3.定义切面类
/*
* 切面类-记录日志操作信息上传到数据库中
* */
@Slf4j
@Component
@Aspect
public class log {
@Autowired
private OperateLogMapper operateLogMapper;
@Around("@annotation(com.itheima.annotation.LogOperation)")
public Object OperationAspect(ProceedingJoinPoint joinPoint) throws Throwable {
// 记录开始时间
long startTime = System.currentTimeMillis();
Object result = joinPoint.proceed(); // 执行方法
// 当前时间
long endTime = System.currentTimeMillis();
// 耗时
long costTime = endTime - startTime;
// 构建日志对象
OperateLog operateLog = new OperateLog();
operateLog.setOperateEmpId(getCurrentUserId()); // 需要实现 getCurrentUserId 方法
operateLog.setOperateTime(LocalDateTime.now());
operateLog.setClassName(joinPoint.getTarget().getClass().getName());
operateLog.setMethodName(joinPoint.getSignature().getName());
operateLog.setMethodParams(Arrays.toString(joinPoint.getArgs()));
operateLog.setReturnValue(result.toString());
operateLog.setCostTime(costTime);
// 插入日志
operateLogMapper.insert(operateLog);
return result;
}
// 示例方法,获取当前用户ID
private Integer getCurrentUserId() {
return CurrentHolder.getCurrentId();
}
}
4**.在需要记录的日志的Controller层的方法上,加上注解 @LogOperation
@RestController
public class DeptController {
@LogOperation //自定义注解 -AOP案例中运行-记录操作日志到数据库中
@DeleteMapping("/depts") //删除数据
public Result delete(Integer id){ //当参数名和请求名一样,@RequestParam可以省略
//log.info("删除的id:{}",id);
deptService.delete(id);
return Result.success();
}
@LogOperation //自定义注解 -AOP案例中运行-记录操作日志到数据库中
@PostMapping("/depts") //添加数据
public Result insert(@RequestBody Dept dept){
//@RequestRody 接收复杂类型 请求在请求体body当中
deptService.insert(dept);
return Result.success();
}
}
ThreadLoacl
结论:在同一个线程/同一个请求中,进行数据共享就可以使用 ThreadLocal。
ThreadLoacl:类似平常的储物柜,自己放的东西只能自己拿
ThreadLoacl的应用:同一个线程/请求中,进行数据共享
Thread:线程
内存泄漏等:https://www.bilibili.com/video/BV1BsqHYdEun/?spm_id_from=333.337.search-card.all.click&vd_source=80b03e176499d6909700cc364423f1fe
调用ThreadLocal的set存值的时候,是往Thread线程中ThreadLocalMap中放
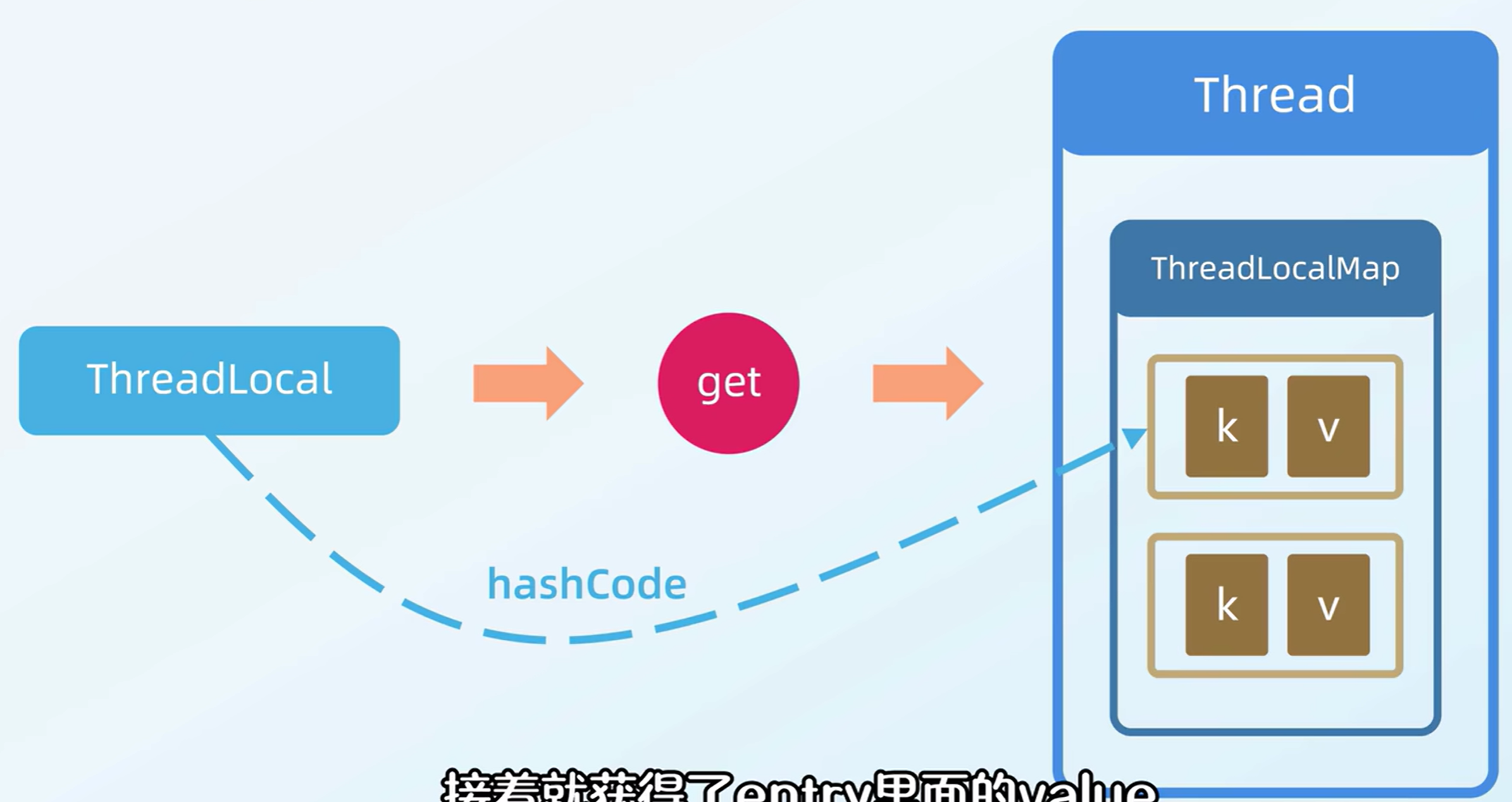
public static void main(String[] args) {
ThreadLocal<String> threadLocal =new ThreadLocal<>();
threadLocal.set("线程1");
System.out.println(threadLocal.get());
new Thread(new Runnable(){ //线程2
@Override
public void run() {
System.out.println(threadLocal.get());
}
}).start();
}
线程池中的线程号
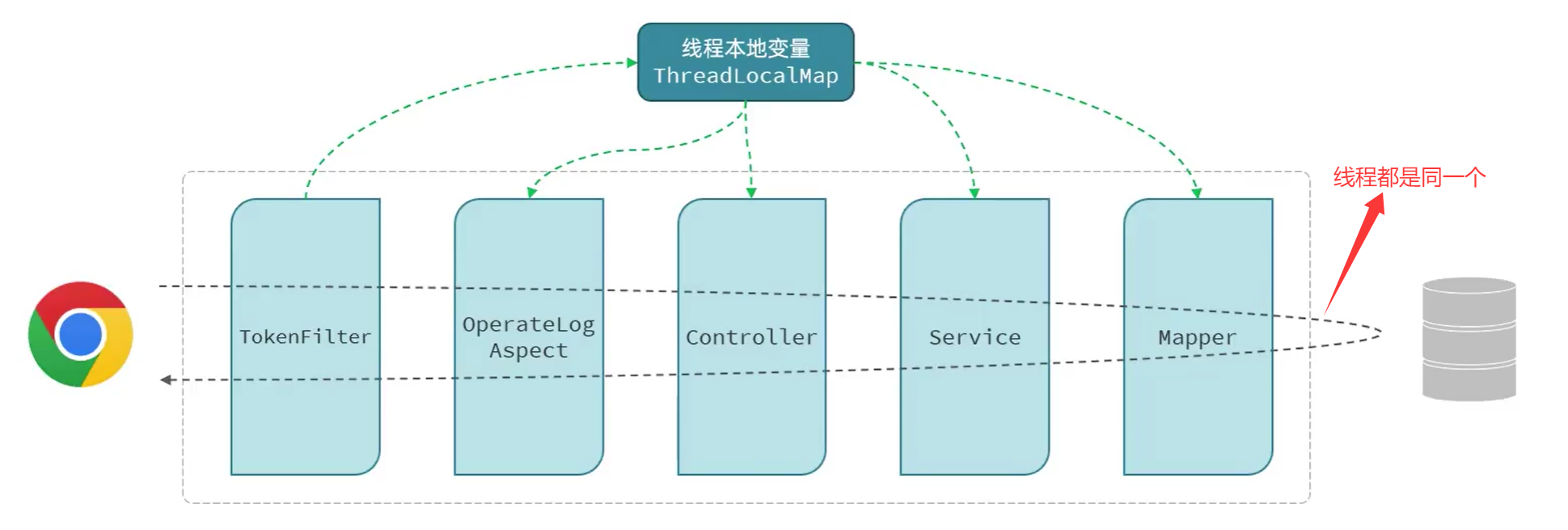
1.定义ThreadLocal操作的工具类,用于操作当前登录员工ID。
在 com.itheima.utils 引入工具类 CurrentHolder
/*
* 同一个线程数据共享-ThreadLocal
* */
public class CurrentHolder {
private static final ThreadLocal<Integer> threadLoacl = new ThreadLocal<>();
public static void setCurrentId(Integer employeeId) {
threadLoacl.set(employeeId);
}
public static Integer getCurrentId() {
return threadLoacl.get();
}
public static void remove() {
threadLoacl.remove();
}
}
2.在TokenFilter中,解析完当前登录员工ID,将其存入ThreadLocal(用完之后需将其删除)
/*
* JWT检验-过滤Filter
* */
@Slf4j
@WebFilter(urlPatterns = "/*")
public class TokenFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
//解析请求路径,判断
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
String url=request.getRequestURI(); //获取URI /login /emps这种
// 判断请求url中是否包含login,如果包含,说明是登录操作,放行。
if(url.contains("login")){
//放行
chain.doFilter(request,response); //过滤放行到下一个过滤器,如果没有,就是访问资源
return;
}
String token=request.getHeader("token");
// 判断令牌是否存在,如果不存在,返回错误结果(未登录)
if(token==null||token.isEmpty()){
response.setStatus(401); // 401 = HttpStatus.SC_UNAUTHORIZED
return;
}
//解析token,如果解析失败,返回错误结果(未登录)
try {
Claims claims=JwtUtils.parseJWT(token); //解析成功,获取数据(第二部分)
/*
* ThreadLocal-同一个线程中共享数据id
* */
/* Object object=claims.get("id"); //因为Claims是map存储,通过key=id,获取value等于什么
Integer empId=Integer.valueOf(object.toString()); //转换id类型
CurrentHolder.setCurrentId(empId); //通过ThreadLoacl线程,共享数据*/
/*Integer empId = Integer.valueOf(claims.get("id").toString());
CurrentHolder.setCurrentId(empId); //存入*/
/*
*
* 就是有了这个所以进入不了部门管理当中
*
*
*
*
*
* =================================================================
* */
} catch (Exception e) {
response.setStatus(401);
return;
}
//放行
chain.doFilter(request,response);
//清空当前线程的绑定,以免内存泄漏
CurrentHolder.remove();
}
}
3.在AOP程序中,从ThreadLocal中获取当前登录员工的ID
/*
* 切面类-记录日志操作信息上传到数据库中
* */
@Slf4j
@Component
@Aspect
public class log {
@Autowired
private OperateLogMapper operateLogMapper;
@Around("@annotation(com.itheima.annotation.LogOperation)")
public Object OperationAspect(ProceedingJoinPoint joinPoint) throws Throwable {
// 记录开始时间
long startTime = System.currentTimeMillis();
Object result = joinPoint.proceed(); // 执行方法
// 当前时间
long endTime = System.currentTimeMillis();
// 耗时
long costTime = endTime - startTime;
// 构建日志对象
OperateLog operateLog = new OperateLog();
operateLog.setOperateEmpId(getCurrentUserId()); // 需要实现 getCurrentUserId 方法
operateLog.setOperateTime(LocalDateTime.now());
operateLog.setClassName(joinPoint.getTarget().getClass().getName());
operateLog.setMethodName(joinPoint.getSignature().getName());
operateLog.setMethodParams(Arrays.toString(joinPoint.getArgs()));
operateLog.setReturnValue(result.toString());
operateLog.setCostTime(costTime);
// 插入日志
operateLogMapper.insert(operateLog);
return result;
}
// 示例方法,获取当前用户ID
private Integer getCurrentUserId() {
return CurrentHolder.getCurrentId();
}
}
Springboot原理
配置优先级
配置tomcat端口号,配置数据库密码等
配置优先级(从底到高):
- application.yaml(忽略)
- application.yml
- application.properties
- java系统属性(-Dxxx=xxx)
- 命令行参数(–xxx=xxx)


在IDEA中指定 java系统属性或者命令行参数属性
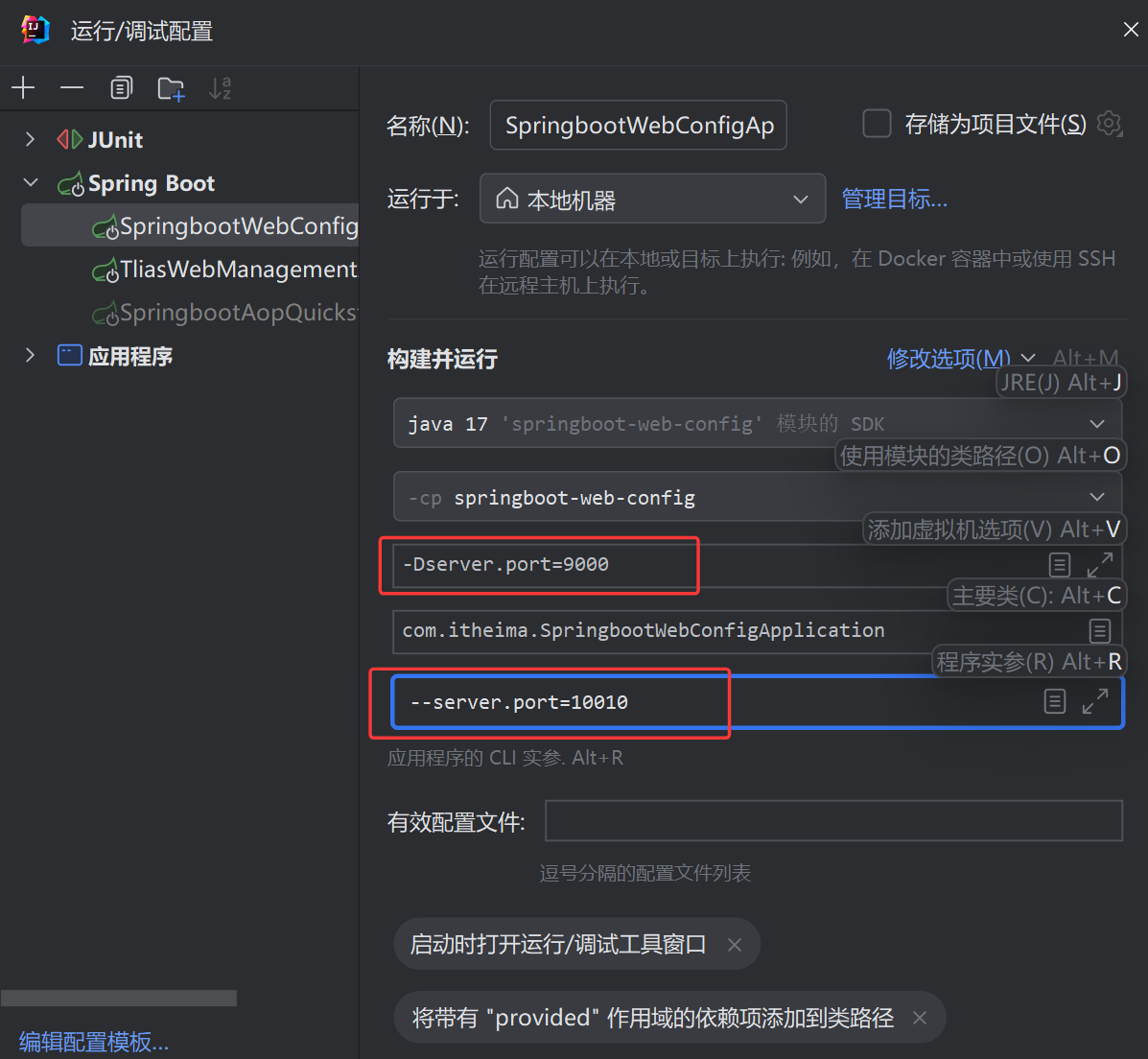
但是IDEA中配置的 java系统属性或者命令行参数属性 在打包后不起作用
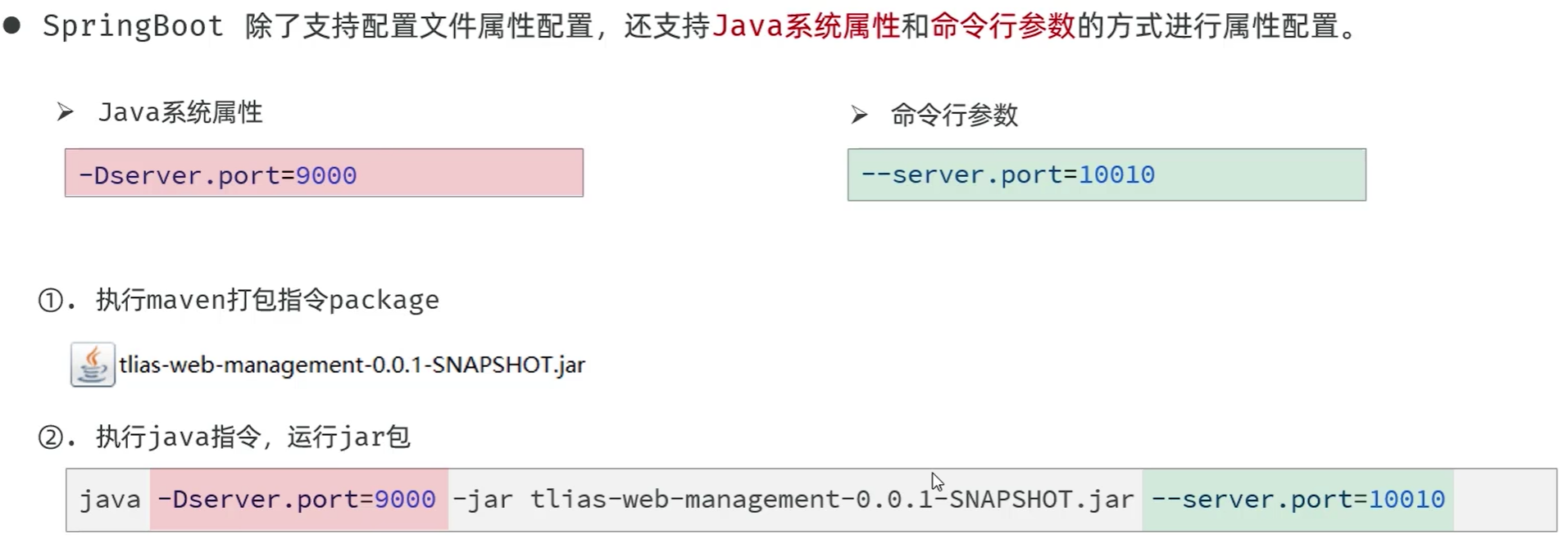
已经部署打包后项目后,如何更改tomcat运行端口号
打包:打包 jar包(Java Archive)
-
pom文件引入插件(基于官网骨架创建项目,会自动添加该插件)
<build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> -
执行maven打包指令package,把项目打成jar文件
-
命令行运行打包后的jar包
命令行指令: 1.执行命令: java -jar “jar包名称” 结束项目运行快捷键: ctrl + c
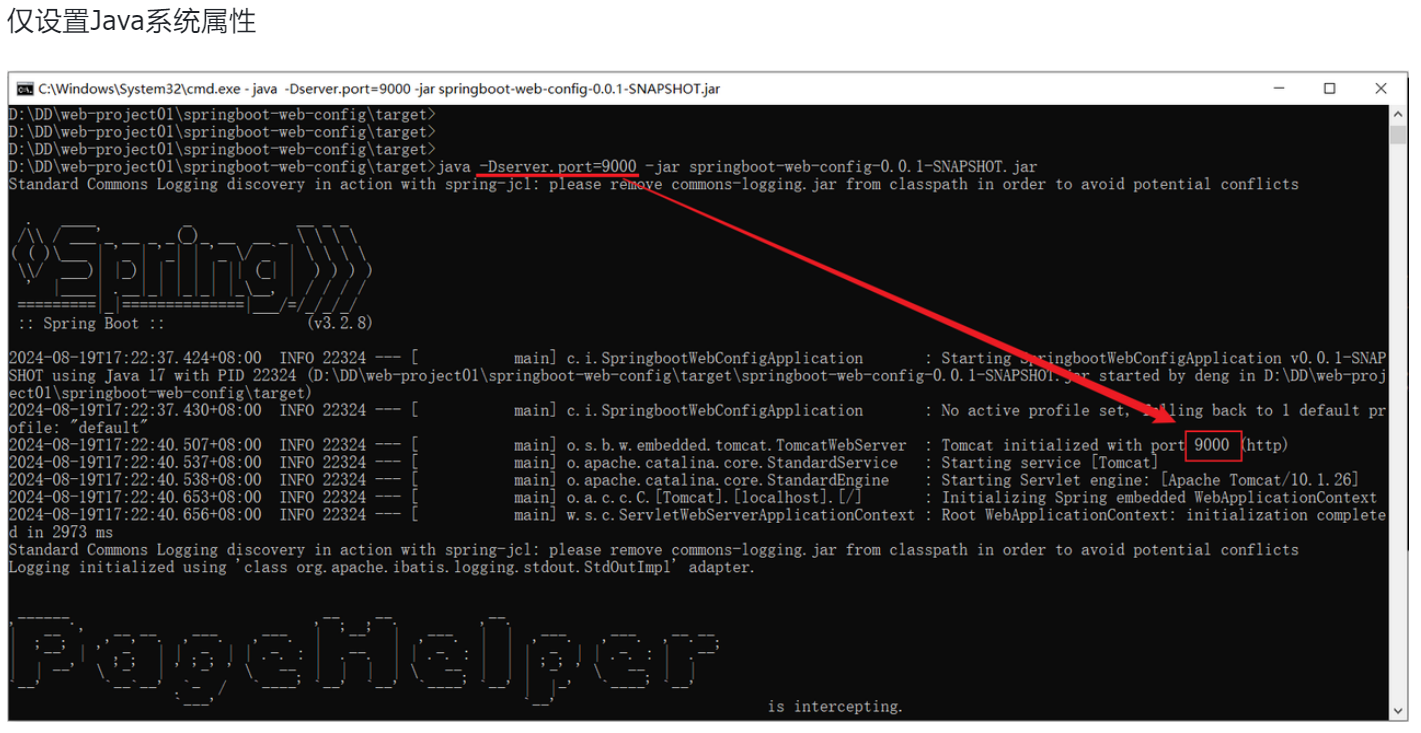
延伸知识:已经部署打包后项目后,如何更改数据库密码?
通过外部优先级大于内部优先级(同理),使用命令行
Bean管理
Bean的作用域
@Lazy //延迟初始化:延迟到第一次使用bean之前创建
@Scope(“prototype”) //创建多例bean
| 作用域 | 说明 |
|---|---|
| singleton(重点,默认情况,常用) | 容器内同名称的bean只有一个实例(单例)(默认) |
| prototype | 每次使用该bean时会创建新的实例(非单例) |
| request | 每个请求范围内会创建新的实例(web环境中,了解) |
| session | 每个会话范围内会创建新的实例(web环境中,了解) |
| application | 每个应用范围内会创建新的实例(web环境中,了解) |
单例bean
@SpringBootTest
class SpringbootWebTests {
@Autowired
private ApplicationContext applicationContext;
@Test
public void testScope(){
//获取bean的,根据bean名字,类名首字母小写
Object object=applicationContext.getBean("deptController");
for(int i=0;i<10;i++){
System.out.println(object);
}
}
}
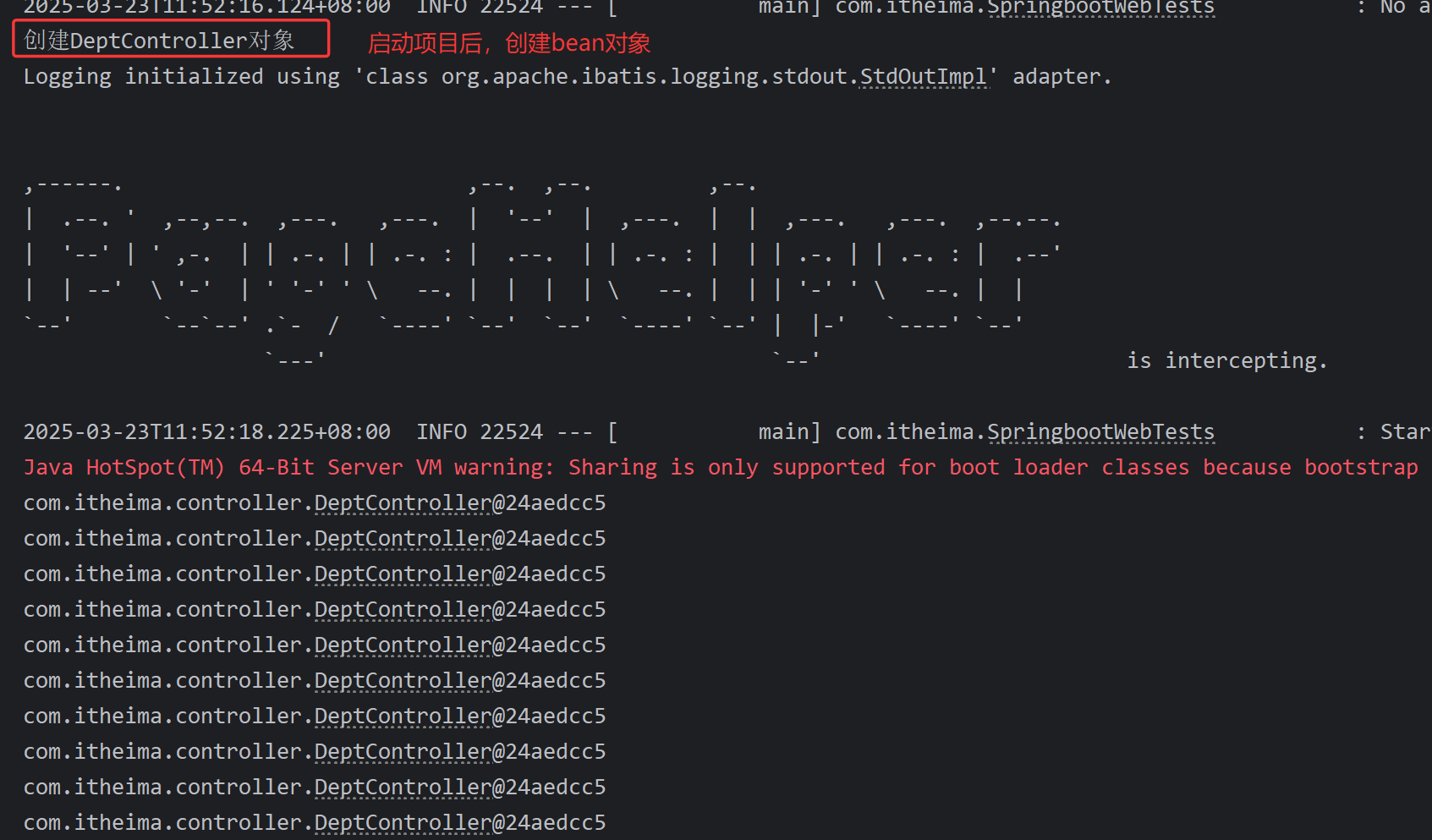
多例bean(我的代码这里不行)
@Scope("prototype") //bean作用域为多例
@RestController
public class DeptController {
@Autowired
private DeptService deptService;
public DeptController(){
System.out.println("DeptController constructor ....");
}
//省略其他代码...
}
bean的名字,首字母小写
bean作用域
-
单例bean:
- 节约资源(特别对于连接数据库这种)
- 高性能
单例多例bean中线程安全吗?
单例无状态(没有数据存储什么的)bean:没有数据,就没有共享数据,所以线程安全
单例有状态bean:内部会有数据处理,多个线程会同时操作该bean,所以线程不安全
多例有状态bean:因为每次都是一个全新的bean,所以线程是安全的
重要

当在配置类上使用 @ComponentScan 注解时,Spring 会自动扫描指定包及其子包中的类,并查找带有 @Component 注解的类。这些类会被注册为 Spring 容器中的 Bean。
但是第三方的启动类扫描不到@Component,所以不能用@Component
@Bean主要用于 手动配置和创建 Bean,尤其适合需要更多控制和灵活性、或者需要为第三方库创建 Bean 时使用。@Component是用于 自动扫描并注册 Bean 的注解,适用于大多数常规的 Spring Bean 创建场景。
| 特性 | @Bean | @Component |
|---|---|---|
| 定义方式 | 显式定义在 @Configuration 类中的方法 | 自动扫描和注册类作为 Spring Bean |
| 使用位置 | 在 @Configuration 类中的方法上 | 在类上(通常是服务层、控制层等) |
| 创建对象的方式 | 通过方法显式返回实例 | Spring 自动实例化该类并作为 Bean 管理 |
| 适用场景 | 需要手动配置或复杂初始化逻辑的对象 | 适用于无须特殊配置的组件 |
| 作用范围 | 默认是全局可用(可以通过 @Bean 的名称进行查找) | 自动扫描指定包及其子包中的类 |
| 生命周期管理 | 由 Spring 容器管理,但可以手动定制生命周期 | 由 Spring 容器管理生命周期 |
总结:
什么时候需要使用@Configuration和@Bean来手动注册这些Bean?
- 如果第三方库中的类没有使用Spring的注解
- 或者不在启动类的扫描范围内
- 或者需要配置更加详细的,需要手动配置Bean的时候
常见的需要配置类总结
在Java后端开发中,除了WebSocket的ServerEndpointExporter之外,还有许多其他组件需要通过@Configuration和@Bean注解来手动注册或配置。以下是一些常见的例子:
- 消息中间件
-
RabbitMQ:需要配置
RabbitTemplate和ConnectionFactory。@Configuration public class RabbitMQConfig { @Bean public ConnectionFactory connectionFactory() { CachingConnectionFactory factory = new CachingConnectionFactory("localhost"); factory.setUsername("guest"); factory.setPassword("guest"); return factory; } @Bean public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) { return new RabbitTemplate(connectionFactory); } } -
Kafka:需要配置
KafkaTemplate。@Configuration public class KafkaConfig { @Bean public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } @Bean public ProducerFactory<String, String> producerFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return props; } }
- 缓存
-
Redis:需要配置
RedisTemplate。@Configuration public class RedisConfig { @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<>(); template.setConnectionFactory(factory); return template; } }
- 数据库连接池
-
HikariCP:需要配置
HikariDataSource。@Configuration public class DataSourceConfig { @Bean public HikariDataSource dataSource() { HikariConfig config = new HikariConfig(); config.setJdbcUrl("jdbc:mysql://localhost:3306/mydb"); config.setUsername("user"); config.setPassword("password"); return new HikariDataSource(config); } }
- 安全相关
-
Spring Security:需要配置安全策略。
@Configuration @EnableWebSecurity public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .antMatchers("/admin/**").hasRole("ADMIN") .antMatchers("/user/**").hasRole("USER") .anyRequest().authenticated() .and() .formLogin(); } }
- 日志相关
-
Logback:可以通过
@Configuration类配置日志。@Configuration public class LogbackConfig { @Bean public Logger logger() { return (Logger) LoggerFactory.getLogger("myLogger"); } }
- Web相关
-
Spring MVC:需要配置拦截器、视图解析器等。
@Configuration @EnableWebMvc public class WebConfig implements WebMvcConfigurer { @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new MyInterceptor()); } }
- 任务调度
-
Spring Task:需要配置定时任务。
@Configuration @EnableScheduling public class TaskConfig { @Scheduled(fixedRate = 5000) public void fixedRateJob() { System.out.println("Fixed rate job"); } }
- 微服务
-
Spring Cloud:需要配置服务发现、配置中心等。
@Configuration @EnableDiscoveryClient public class MicroserviceConfig { }
总结
在Java后端开发中,许多组件需要通过@Configuration和@Bean注解来手动注册或配置,以确保它们能够正确地集成到Spring容器中。这些组件包括消息中间件、缓存、数据库连接池、安全框架、日志框架、Web框架、任务调度和微服务等。通过这种方式,可以实现更灵活、更强大的功能。
不是很理解的
即使你已经在某些类上使用了@Component注解,仍然可能需要使用@Configuration和@Bean来注册某些特殊的Bean,特别是当这些Bean是第三方库提供的,或者需要特殊的初始化逻辑时。对于WebSocket的ServerEndpointExporter,这是一个典型的例子。
为什么需要@Configuration和@Bean?
-
ServerEndpointExporter的特殊性:ServerEndpointExporter是Spring提供的一个特殊的Bean,用于支持JSR-356(Java API for WebSocket)的注解(如@ServerEndpoint)。它负责扫描并注册带有@ServerEndpoint注解的类。- 这个类并不是一个普通的Spring Bean,而是需要通过Spring的上下文来管理的特殊组件。
-
自动扫描的局限性:
- 即使你使用了
@Component注解,Spring的自动扫描机制可能无法自动发现并注册ServerEndpointExporter。这是因为ServerEndpointExporter需要在Spring容器启动时被注册,以确保它能够扫描并管理WebSocket端点。 ServerEndpointExporter的注册需要通过@Bean注解来显式声明,以确保它在Spring容器中被正确初始化。
- 即使你使用了
-
确保WebSocket端点被扫描:
- 通过
@Bean注解声明ServerEndpointExporter,可以确保Spring容器在启动时加载并初始化这个Bean,从而扫描并注册所有带有@ServerEndpoint注解的类。
- 通过
示例代码
以下是一个典型的WebSocket配置类示例,展示了如何通过@Configuration和@Bean注解来注册ServerEndpointExporter:
@Configuration
public class WebSocketConfiguration {
@Bean
public ServerEndpointExporter serverEndpointExporter() {
return new ServerEndpointExporter();
}
}
关键点解释
-
@Configuration:- 标记这是一个配置类,类似于Spring XML配置文件中的
<beans>标签。 - 这个类中的方法可以定义Bean。
- 标记这是一个配置类,类似于Spring XML配置文件中的
-
@Bean:- 标记
serverEndpointExporter方法返回的对象是一个Bean。 - Spring容器会调用这个方法,并将返回的对象注册为一个Bean。
- 标记
-
ServerEndpointExporter:- 这是一个特殊的Bean,用于支持JSR-356的WebSocket注解。
- 它会扫描项目中所有带有
@ServerEndpoint注解的类,并将它们注册为WebSocket端点。
总结
即使你已经使用了@Component注解,某些特殊的Bean(如ServerEndpointExporter)仍然需要通过@Configuration和@Bean注解来显式注册。这是因为这些Bean需要在Spring容器启动时被初始化,以确保它们能够正确地扫描和管理其他组件。通过这种方式,你可以确保WebSocket端点被正确注册并管理。
第三方管理bean
第三方bean:用@Bean注解
自己定义的类:用@Component及其衍生注解
这里我们假设阿里云oss是第三方的类
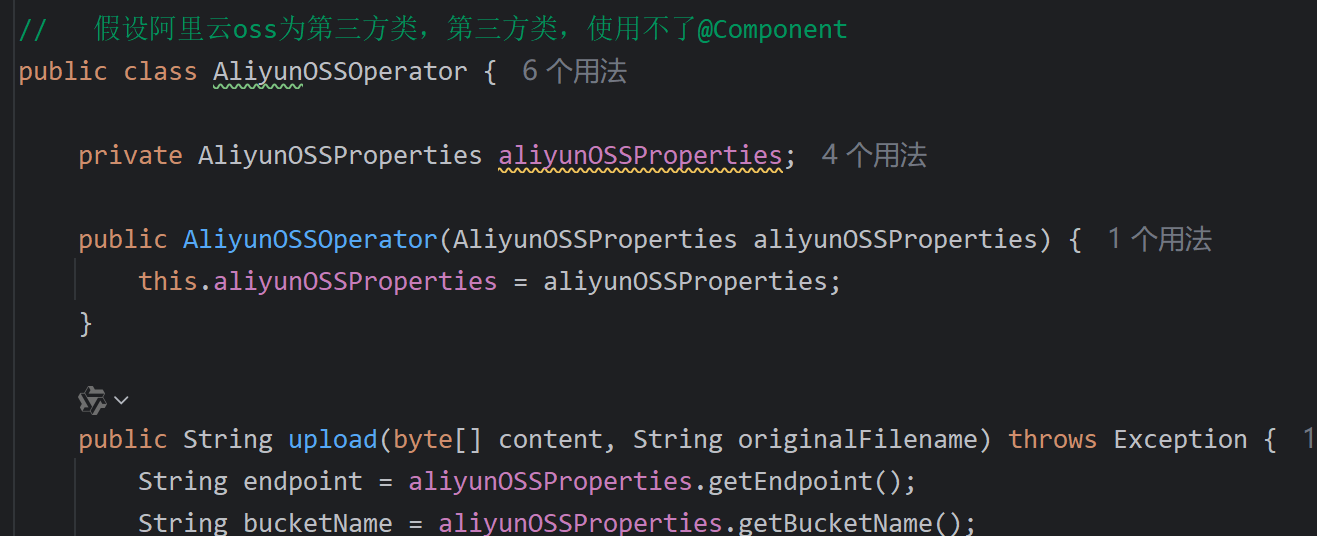
启动类中声明第三方bean的管理
@SpringBootApplication
public class SpringbootWebConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfigApplication.class, args);
}
/*
* 注入第三方bean
* 方法返回值交给ioc管理的bean对象
* 如果第三方bean需要依赖其它bean对象,直接在bean定义的方法中设置(要依赖的bean)形参,容器会自动装配
* 方法的类名就是bean的名字
**/
@Bean
public AliyunOSSOperator aliyunOSSOperator(/*@Autowired(省略了这个)*/ AliyunOSSProperties aliyunOSSProperties){
return new AliyunOSSOperator(aliyunOSSProperties);
}
}
其它bean使用这个第三方bean
@SpringBootTest
class SpringbootWebTests {
/*
* 第三方bean
* */
@Autowired
private AliyunOSSOperator aliyunOSSOperator;
@Test
public void testAliyunOSSOperator() throws Exception {
File file=new File("C:\\Users\\23515\\Desktop\\B.png");
String url =aliyunOSSOperator.upload(FileUtil.readBytes(file),"B.png");
System.out.println(url);
}
}
不在springboot启动类中配置第三方bean
用专门的配置类来声明第三方bean–对上面的改进
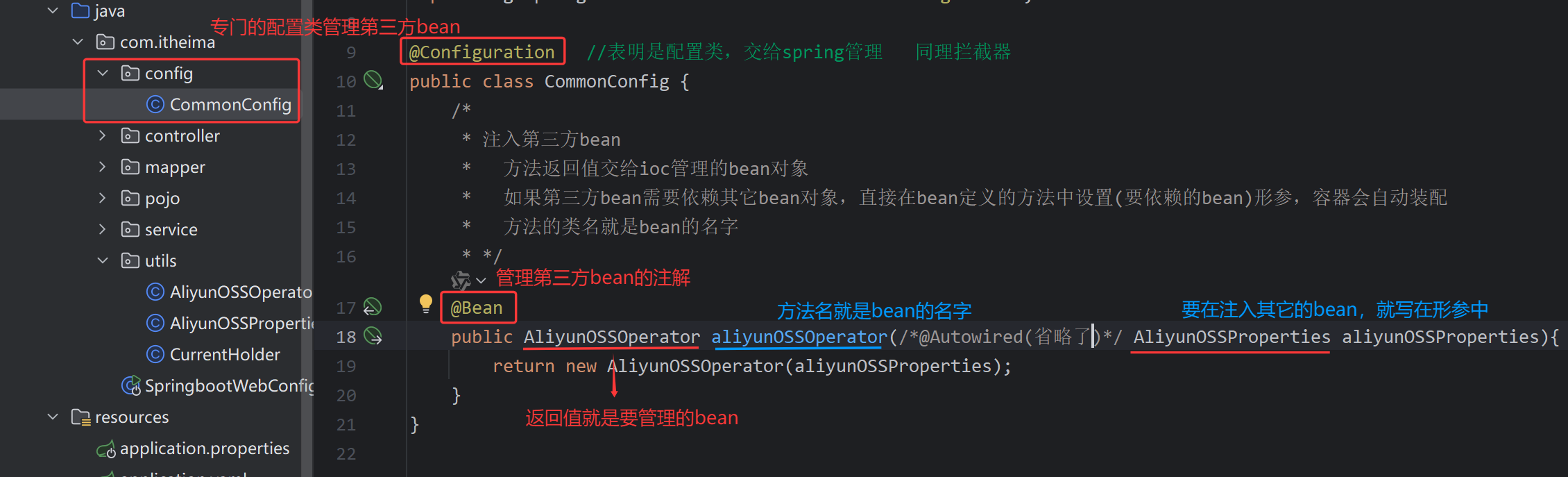
总结
第三方(不是自定义的),是第三方引入的那种,加不了@Component,用@Bean
启动类上面加上@bean注解
方法返回值交给ioc管理的bean对象
方法的类名就是bean的名字
如果第三方bean需要依赖其它bean对象,直接在bean定义的方法中设置(要依赖的bean)形参,容器会自动装配
Spring -> Springboot
通过 SpringBoot来简化Spring框架的开发(是简化不是替代)。我们直接基于SpringBoot来构建Java项目,会让我们的项目开发更加简单,更加快捷。
SpringBoot框架之所以使用起来更简单更快捷,是因为SpringBoot框架底层提供了两个非常重要的功能:一个是起步依赖,一个是自动配置。
起步依赖
springboot起步依赖原理是maven的依赖传递
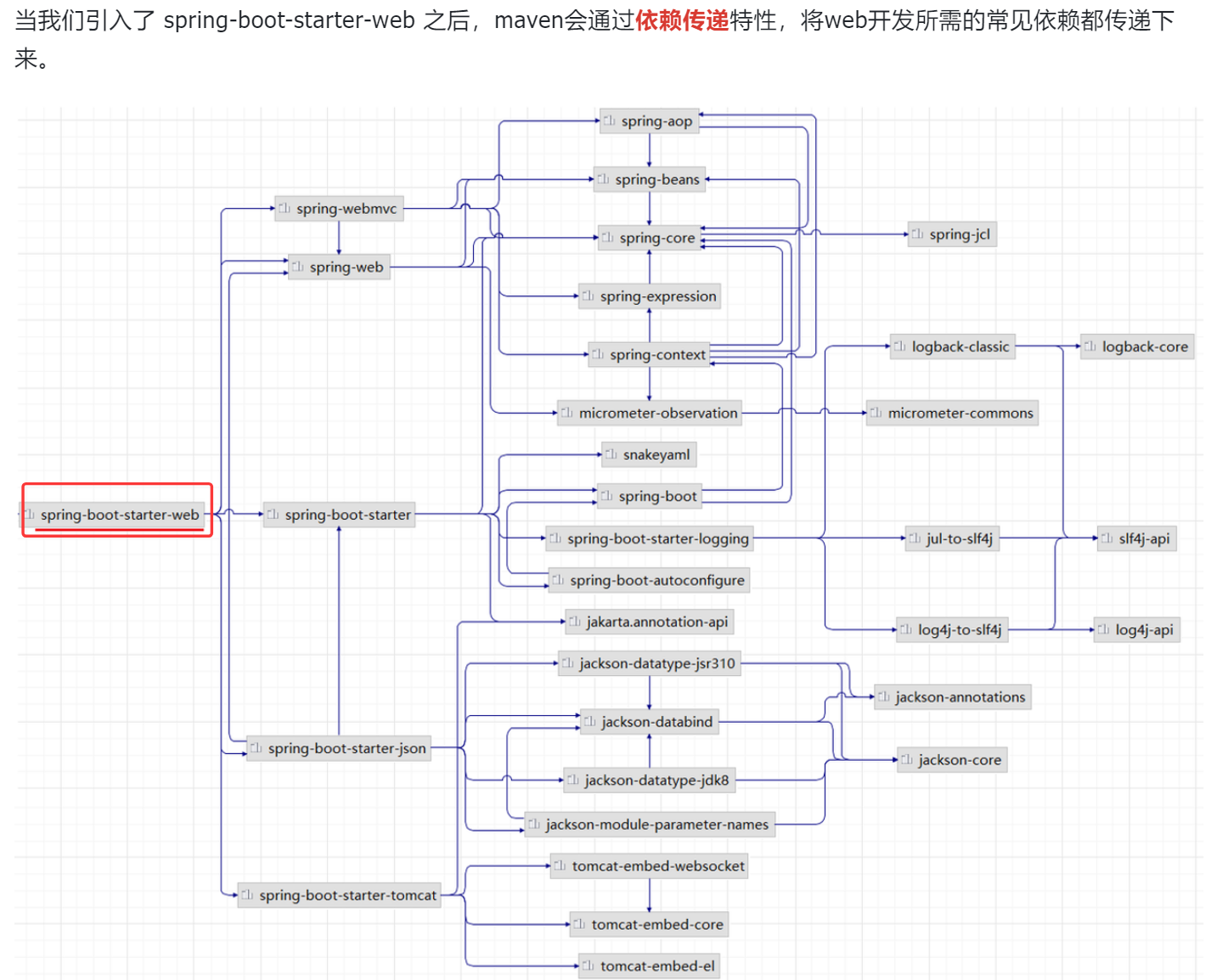
自动装配
自动装配:项目引入的配置/配置类,springboot可以自动创建bean对象存入ioc容器当中去,不需要我们手动去声明bean对象,从而简化开发
实现方案

引入使用第三方包
自定义一些公共组件

步骤
1.引入第三方pom
<!-- 引入第三方包 -->
<dependency>
<groupId>com.example</groupId>
<artifactId>itheima-utils</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
2.引入的 itheima-utils 中配置如下:
@Component
public class TokenParser {
public void parse(){
System.out.println("TokenParser ... parse ...");
}
}
3.在测试类中,添加测试方法
@SpringBootTest
public class AutoConfigurationTests {
/*
* 测试引入的第三方包
* */
@Autowired
private TokenParser tokenParser;
@Test
public void testTokenPase(){
tokenParser.parse();
}
}
为什么没有找到引入的第三方包的bean?
@SpringBootApplication 扫描启动类所在的包及其子包,扫描不了引入的第三方包
解决办法
- 使用@ComponentScan指定扫描的包(不推荐)
@Import导入(使用@Import导入的类会被Spring加载到IOC容器中)
@ComponentScan扫描(不推荐)
//@ComponentScan(basePackages = {"com.example","com.itheima"}) 写法效果相同
@ComponentScan({"com.example","com.itheima"}) //指定要扫描的包
@SpringBootApplication //默认扫描启动类包及其子包
public class SpringbootWebConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfigApplication.class, args);
}
}
@Import导入(也不推荐)
- Impoet导入形式主要有以下几种:
- 导入普通类
- 导入配置类
- 导入ImportSelector接口实现类 --批量导入(后面很有用)
1.导入普通类(会自动创建普通类bean对象并交给ioc管理)
//要导入的普通类
public class TokenParser {
public void parse(){
System.out.println("TokenParser ... parse ...");
}
}
//Import导入普通类
@Import(TokenParser.class) //导入普通类:自动创建普通类的bean对象交给ioc管理 普通类无需@Component
@SpringBootApplication //默认扫描启动类包及其子包
public class SpringbootWebConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfigApplication.class, args);
}
}
//============测试=========
@SpringBootTest
class SpringbootWebTests {
/*
* 测试引入的第三方包
* */
@Autowired
private TokenParser tokenParser;
@Test
public void testTokenPaser(){
tokenParser.parse();
}
}
2.导入配置类
//要导入的配置类
@Configuration
public class HeaderConfig {
@Bean
public HeaderParser headerParser(){
return new HeaderParser();
}
@Bean
public HeaderGenerator headerGenerator(){
return new HeaderGenerator();
}
}
//导入配置类
@Import(HeaderConfig.class) //导入配置类
@SpringBootApplication //默认扫描启动类包及其子包
public class SpringbootWebConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfigApplication.class, args);
}
}
//============测试=========
@SpringBootTest
class SpringbootWebTests {
/*
*@Import导入配置类
* */
@Autowired
private HeaderParser headerParser;
@Test
public void testHeaderParser(){
headerParser.parse();
}
}
3.导入ImportSelector接口实现类
//ImportSelector接口实现类
public class MyImportSelector implements ImportSelector {
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
return new String[]{"com.example.HeaderConfig","com.example.TokenParser"};
}
}
//导入ImportSelector接口实现类
@Import(MyImportSelector.class) //ImportSelector接口实现类 --批量导入
@SpringBootApplication //默认扫描启动类包及其子包
public class SpringbootWebConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfigApplication.class, args);
}
}
//============测试=========(这里IDEA会误报)
@SpringBootTest
class SpringbootWebTests {
/*
*@Import导入配置类
* */
@Autowired
private HeaderParser headerParser;
@Test
public void testHeaderParser(){
headerParser.parse();
}
}
如何看源码
在函数上面会有相关说明
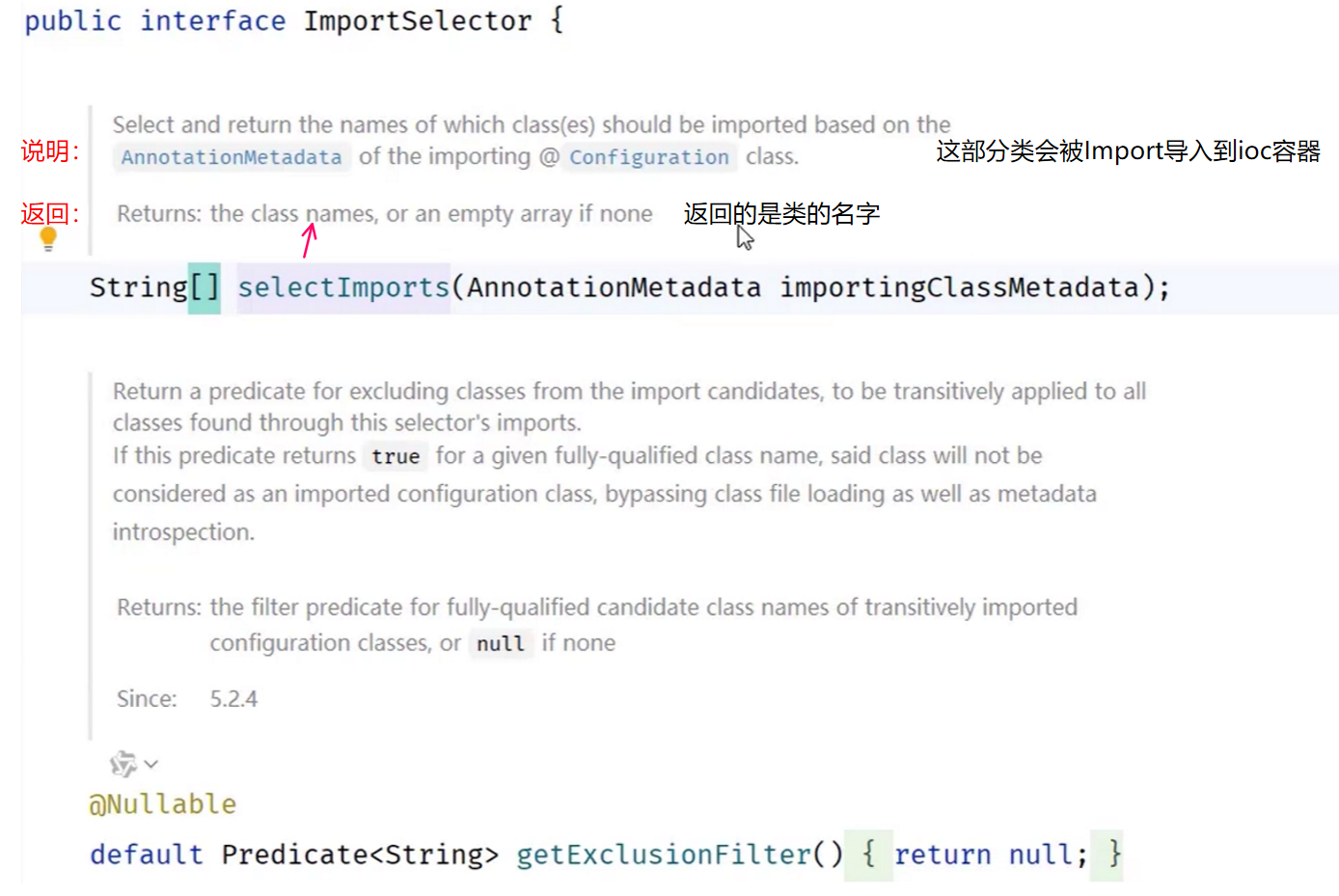
结论:我们不用自己指定要导入哪些bean对象和配置类了,让第三方依赖它自己来指定
第三方依赖会把要使用创建bean对象的用@Import注解封装到一个@Enable开头的注解当中
@EnableXxxxx注解(推荐)

1.第三方依赖提供的注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Import(MyImportSelector.class) //ImportSelector接口实现类 --批量导入
public @interface EnableHeaderConfig {
}
2.在启动类上加上第三方依赖提供的注解
@EnableHeaderConfig //第三方依赖提供的@Enable开头的注解
@SpringBootApplication //默认扫描启动类包及其子包
public class SpringbootWebConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfigApplication.class, args);
}
}
3.测试运行
@SpringBootTest
class SpringbootWebTests {
/*
*@Import导入配置类
* */
@Autowired
private HeaderParser headerParser;
@Test
public void testHeaderParser(){
headerParser.parse();
}
}
总结
引入的第三方依赖,第三方依赖会把我们开发者要使用的类用@Import创建对应bean对象,然后封装到@Enable开头的注解当中
所以:使用第三方依赖,只需要在启动类上加上第三方提供以@Enable开头的注解,即可导入相对应想是使用的bean
自动装配原理
源码跟踪
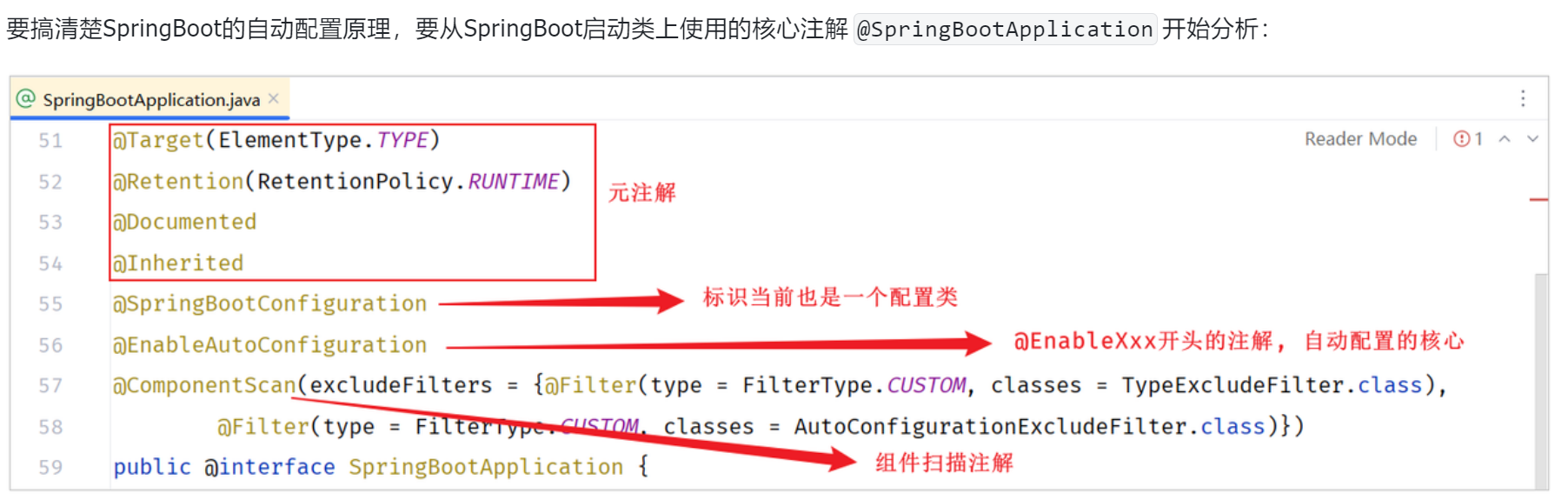
元注解
@Target({ElementType.TYPE}) //表示该注解只能应用于类、接口 @Retention(RetentionPolicy.RUNTIME) //表示该注解不仅在编译时可用,而且在运行时也保留在类文件中,可以通过反射机制读取。 @Documented //它将出现在生成的 JavaDoc 中,提供关于注解的文档说明。 @Inherited //类也会拥有父类的注解,除非子类明确地定义了相同的注解。
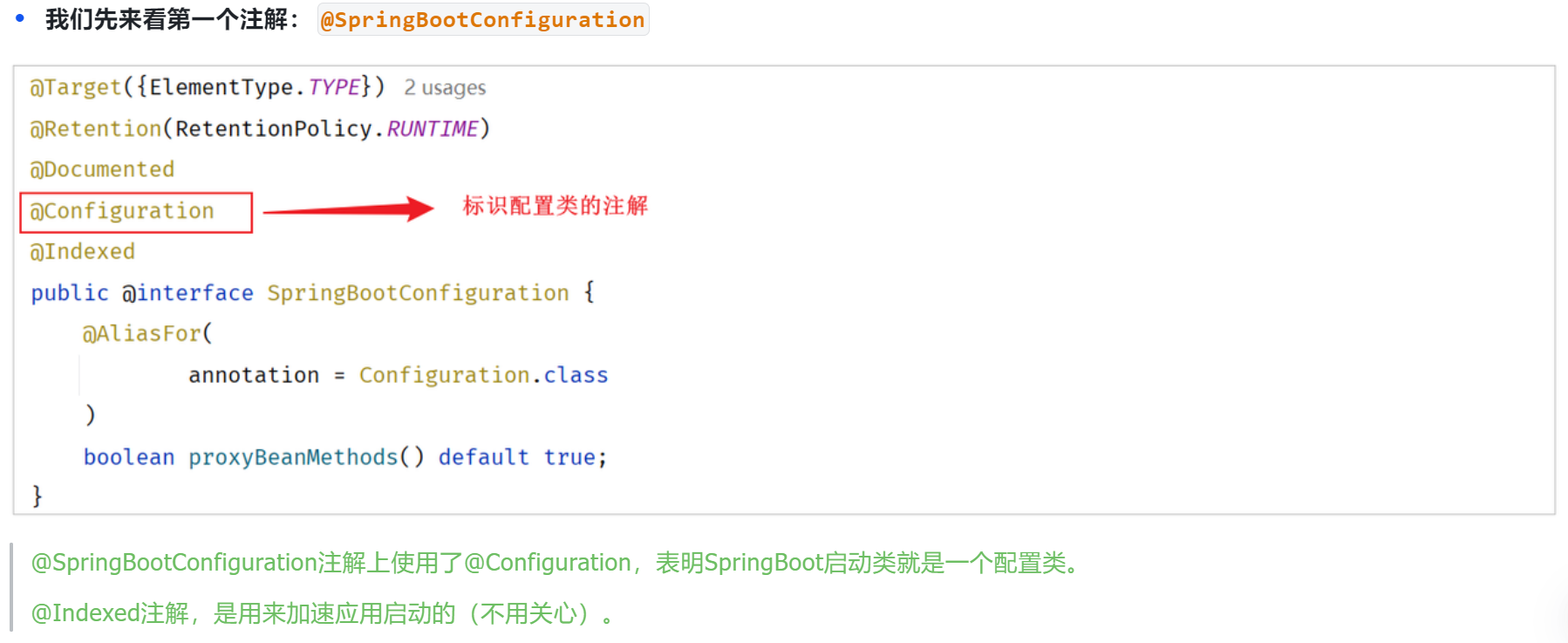
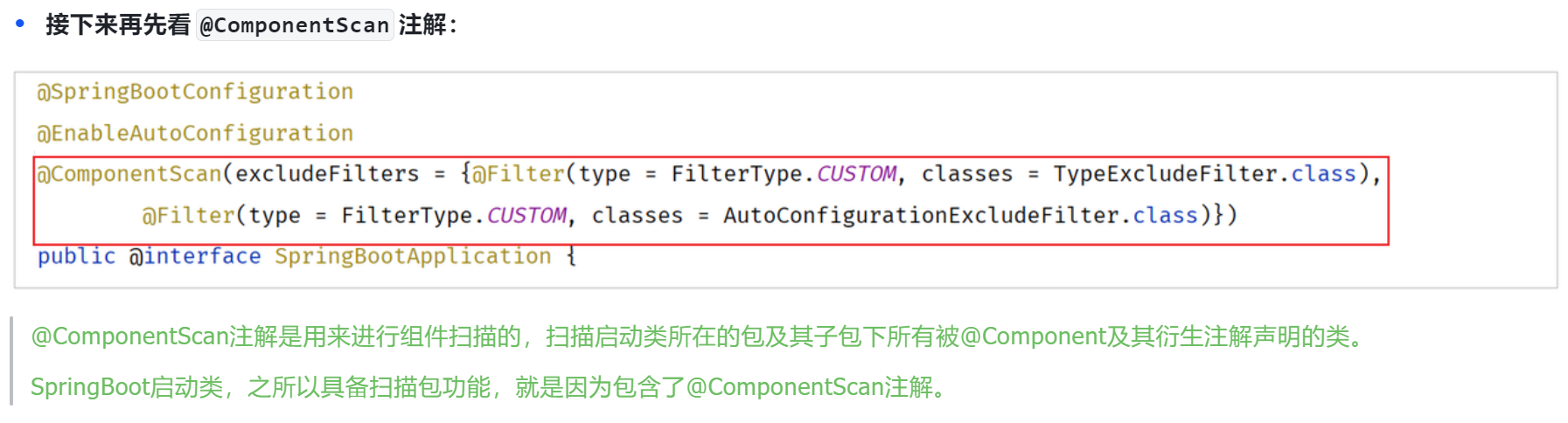
- 最后我们来看看==@EnableAutoConfiguration==注解(自动配置核心注解)
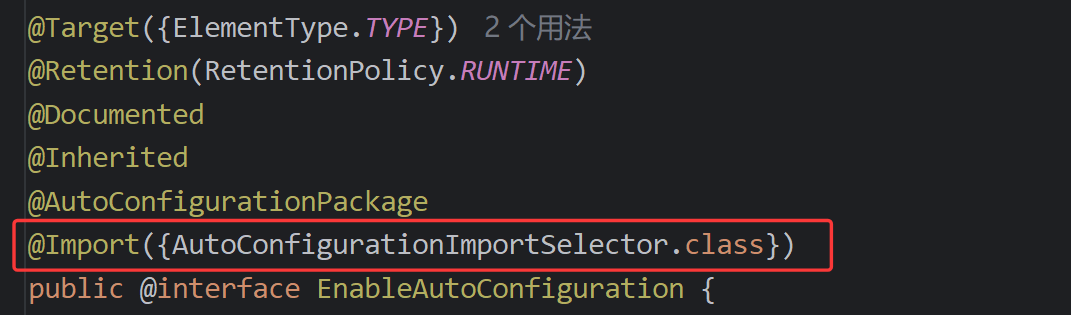
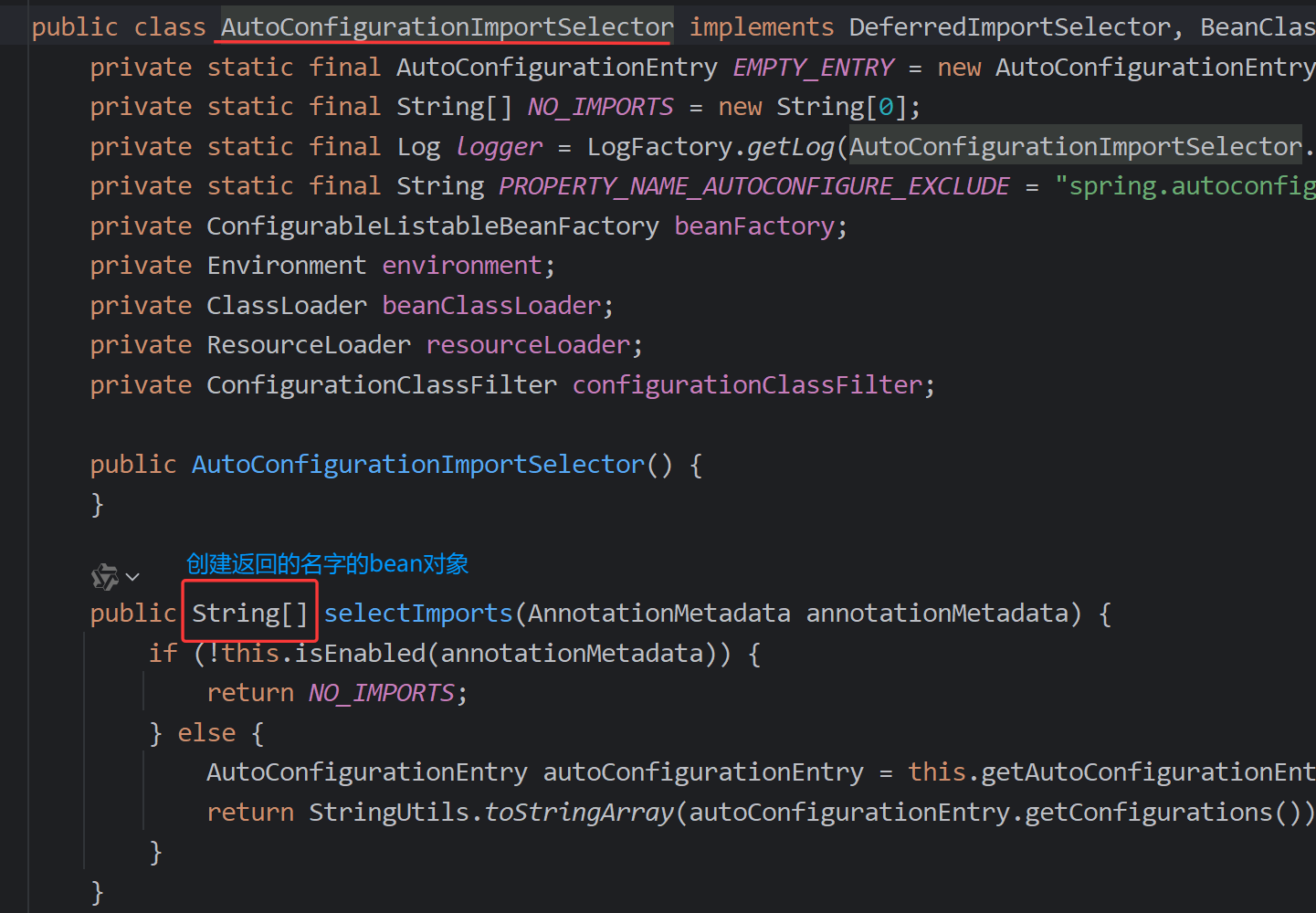
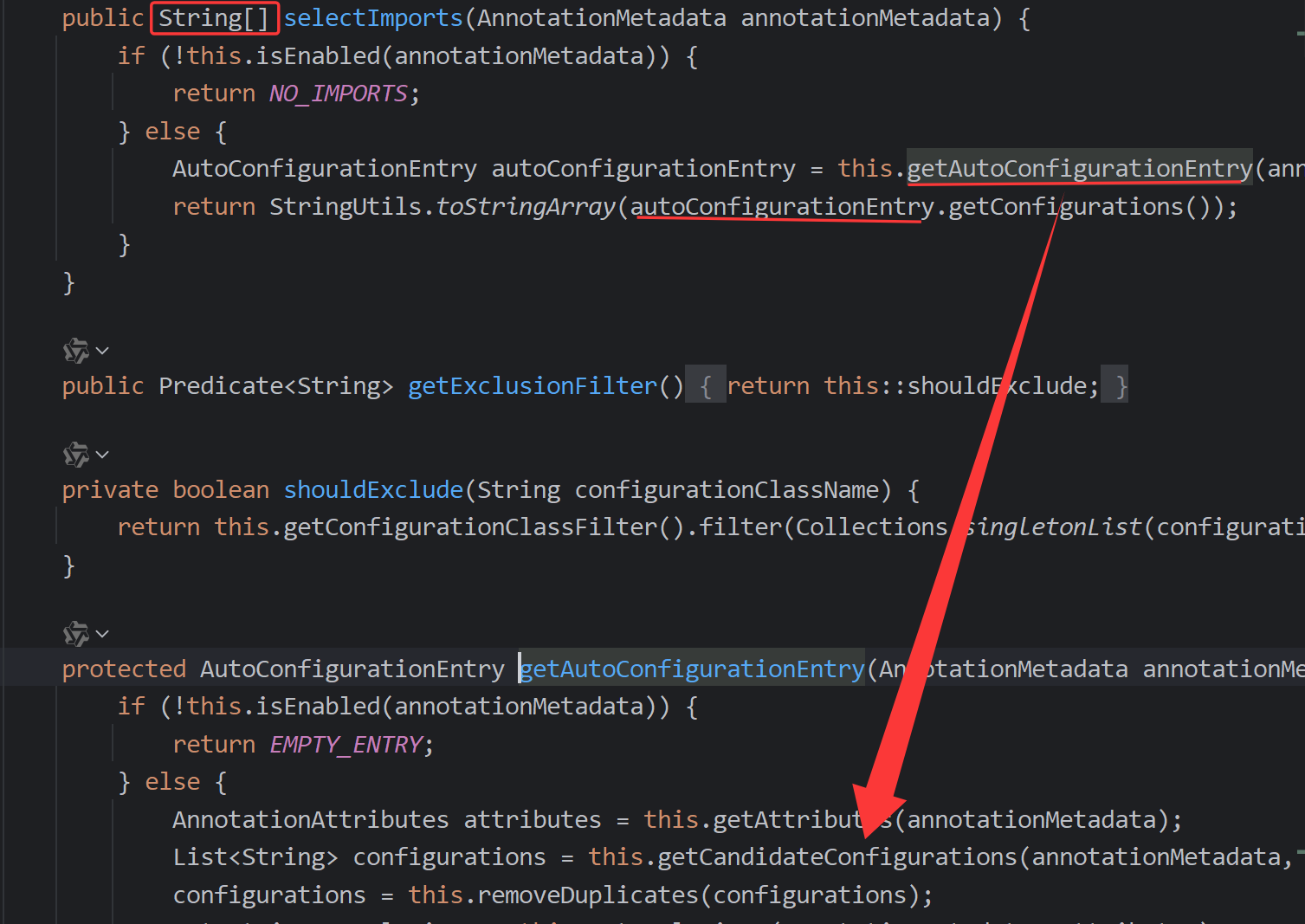  
 
小技巧:找到当前文件的jar包
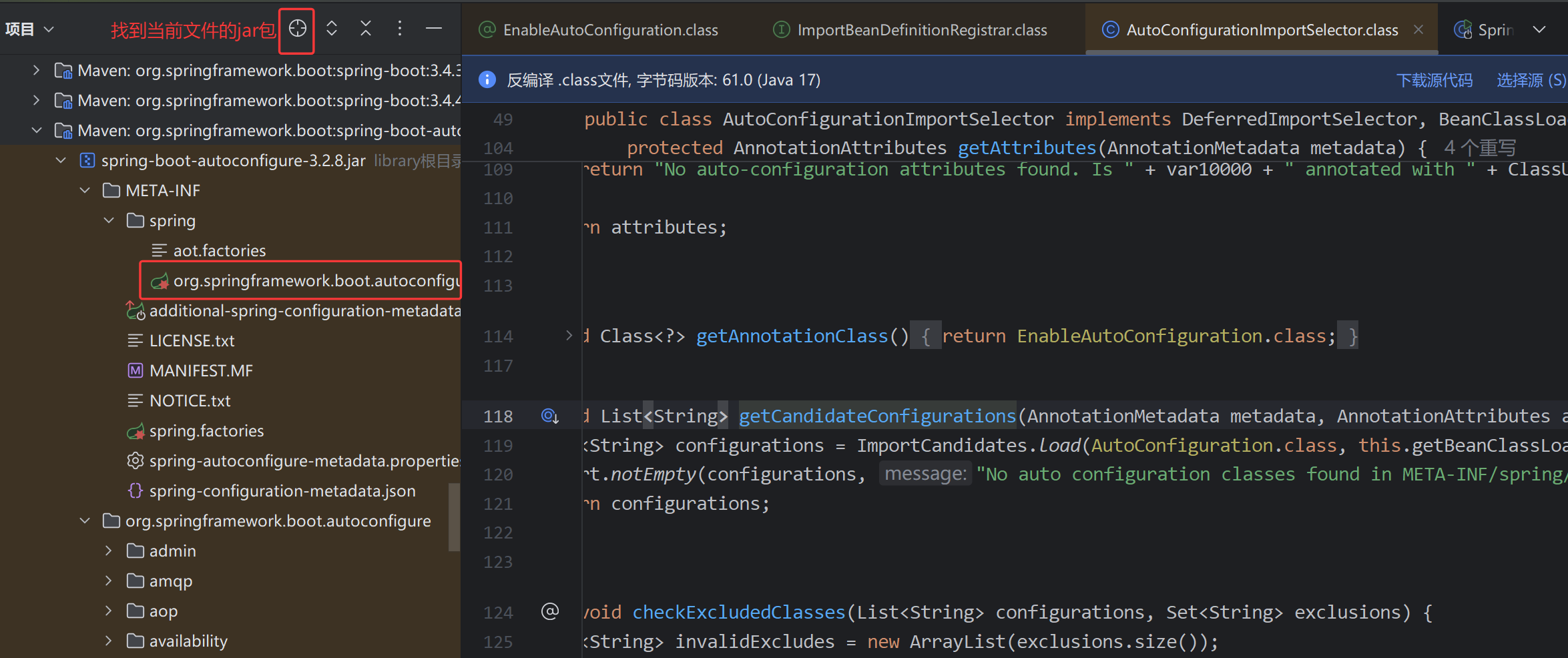
总结
自动配置原理源码入口就是 @SpringBootApplication 注解,在这个注解中封装了3个注解,分别是:
- @SpringBootConfiguration
- 声明当前类是一个配置类
- @ComponentScan
- 进行组件扫描(SpringBoot中默认扫描的是启动类所在的当前包及其子包)
- @EnableAutoConfiguration
- 封装了@Import注解(Import注解中指定了一个ImportSelector接口的实现类)
- 在实现类重写的selectImports()方法,读取当前项目下所有依赖jar包中
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports两个文件里面定义的配置类(配置类中定义了@Bean注解标识的方法)。
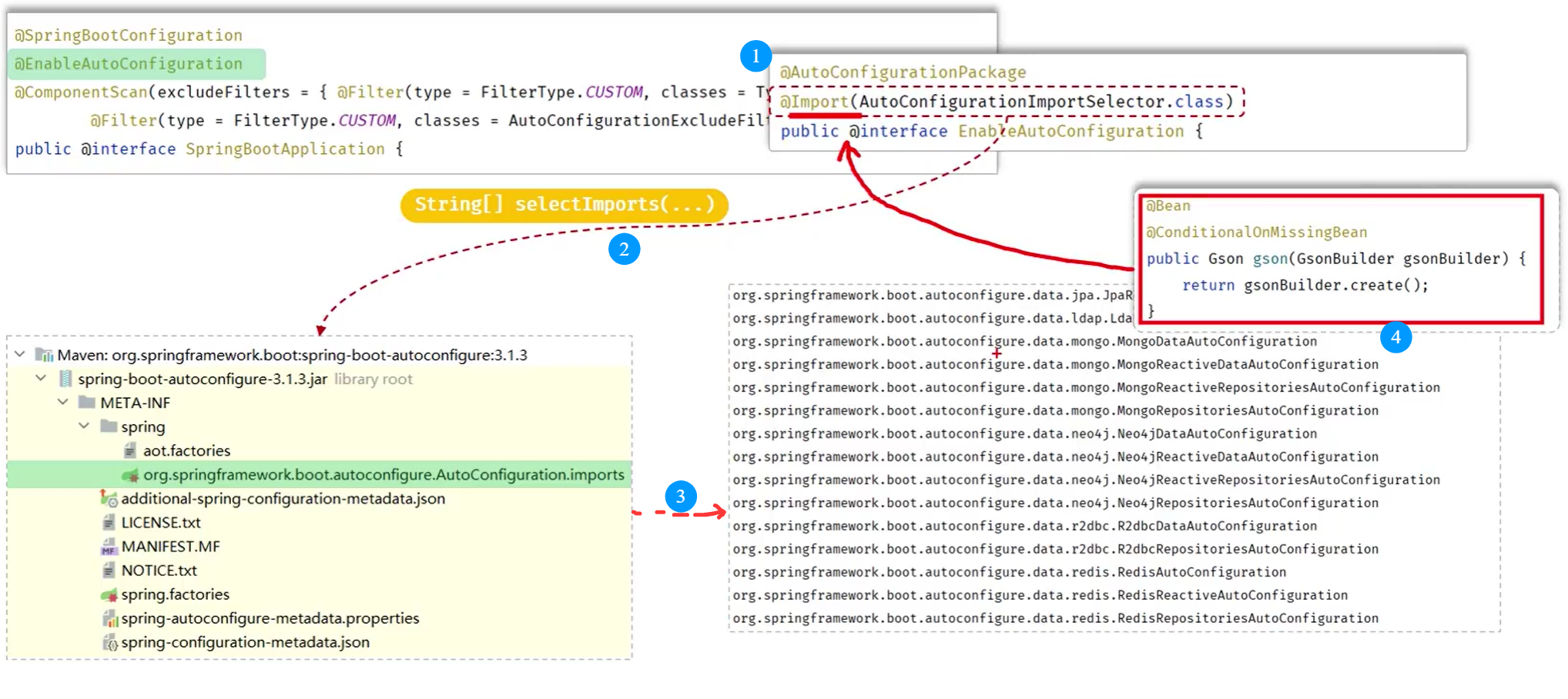
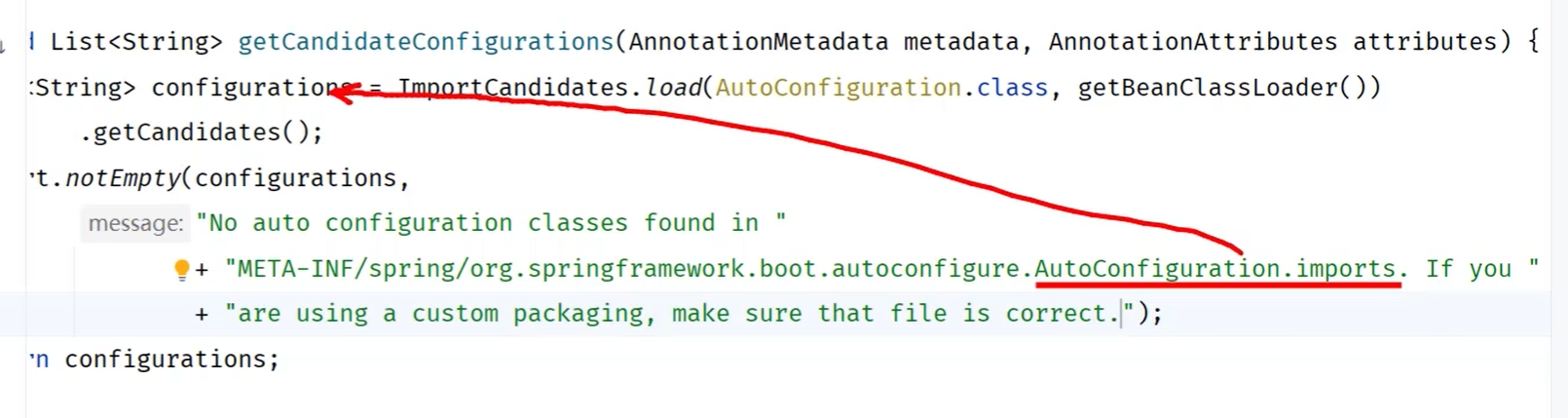
启动类上注解@SpringBootApplication -> @EnableAutoConfiguration -> @Import({AutoConfigurationImportSelector.class})
-> String[] selectImports(…) ->会获取所有叫META-INF/spring/…文件中全类名 -> 返回给String[] 全部对应名字然后创建对应bean
另外的解释:@SpringBootApplication->@EnableAutoConfiguration用了@Import注解 ->@Import导入 ImportSelector接口实现类 String[] SelectImport()
-> 这个实现类返回值的会被创建为bean交给ico ->返回值中的的子类的子类 ->从所有叫META-INF/spring/org…文件中找到要自动装配的类(要被创建bean对象) -> String [ ] selectImports

@Conditional
在类或者方法上,满足给定的条件才会注册对应的bean到ioc容器当中
- @Conditional本身是一个父注解,派生出大量的子注解:
- @ConditionalOnClass:判断环境中有对应字节码文件,才注册bean到IOC容器。
- @ConditionalOnMissingBean:判断环境中没有对应的bean(类型或名称),才注册bean到IOC容器。
- @ConditionalOnProperty:判断配置文件中有对应属性和值,才注册bean到IOC容器。
//@ConditionalOnClass(name = "io.jsonwebtoken.Jwts") //环境中存在这个字节码文件,才注册bean到ioc容器当中 //@ConditionalOnMissingBean //当环境中没有对应的bean,创建对应bean,存入到ioc当中去 //当配置文件(yml)文件中 name中值 等于 havingValue中值 ,等于就创建bean @ConditionalOnProperty(name = "myname",havingValue = "itheima")
@ConditionalOnClass
//第三方要管理创建的bean
@Configuration
public class HeaderConfig {
@Bean
@ConditionalOnClass(name = "io.jsonwebtoken.Jwts")//环境中存在这个字节码文件,才注册bean到ioc容器当中
public HeaderParser headerParser(){
return new HeaderParser();
}
}
@Import(HeaderConfig.class) //导入配置类
@SpringBootApplication //默认扫描启动类包及其子包
public class SpringbootWebConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfigApplication.class, args);
}
}
//============测试=======================
@SpringBootTest
class SpringbootWebTests {
@Autowired
private HeaderParser headerParser;
@Test
public void testHeaderParser(){
headerParser.parse();
}
}
能运行成功,因为存在对应字节码,如下
<!--JWT令牌-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
@ConditionalOnMissingBean
//第三方配置文件
@Configuration
public class HeaderConfig {
@Bean
@ConditionalOnMissingBean //当环境中没有对应的bean,创建对应bean,存入到ioc当中去
public HeaderParser headerParser(){
return new HeaderParser();
}
@Bean
public HeaderGenerator headerGenerator(){
return new HeaderGenerator();
}
}
//=============启动类=========
@Import(HeaderConfig.class) //导入配置类
@SpringBootApplication //默认扫描启动类包及其子包
public class SpringbootWebConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfigApplication.class, args);
}
}
//============测试=======================
@SpringBootTest
class SpringbootWebTests {
@Autowired
private HeaderParser headerParser;
@Test
public void testHeaderParser(){
headerParser.parse();
}
}
@ConditionalOnProperty
添加配置文件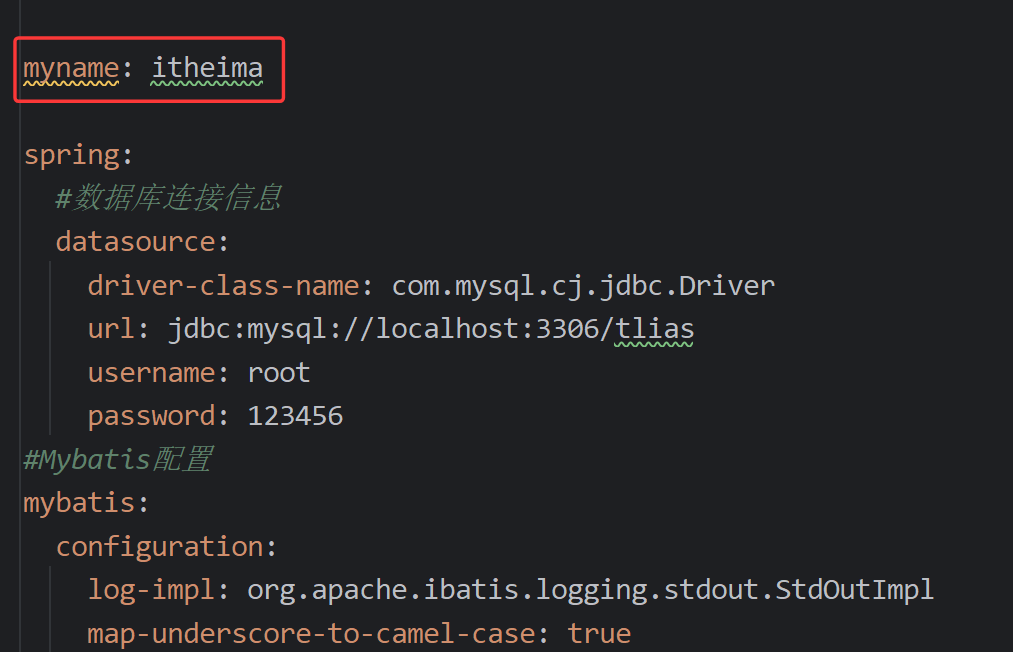
//第三放配置文件
@Configuration
public class HeaderConfig {
@Bean
//当配置文件(yml)文件中 name中值 等于 havingValue中值 ,等于就创建bean
@ConditionalOnProperty(name = "myname",havingValue = "itheima")
public HeaderParser headerParser(){
return new HeaderParser();
}
@Bean
public HeaderGenerator headerGenerator(){
return new HeaderGenerator();
}
}
//=============启动类=========
@Import(HeaderConfig.class) //导入配置类
@SpringBootApplication //默认扫描启动类包及其子包
public class SpringbootWebConfigApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfigApplication.class, args);
}
}
//============测试=======================
@SpringBootTest
class SpringbootWebTests {
@Autowired
private HeaderParser headerParser;
@Test
public void testHeaderParser(){
headerParser.parse();
}
}
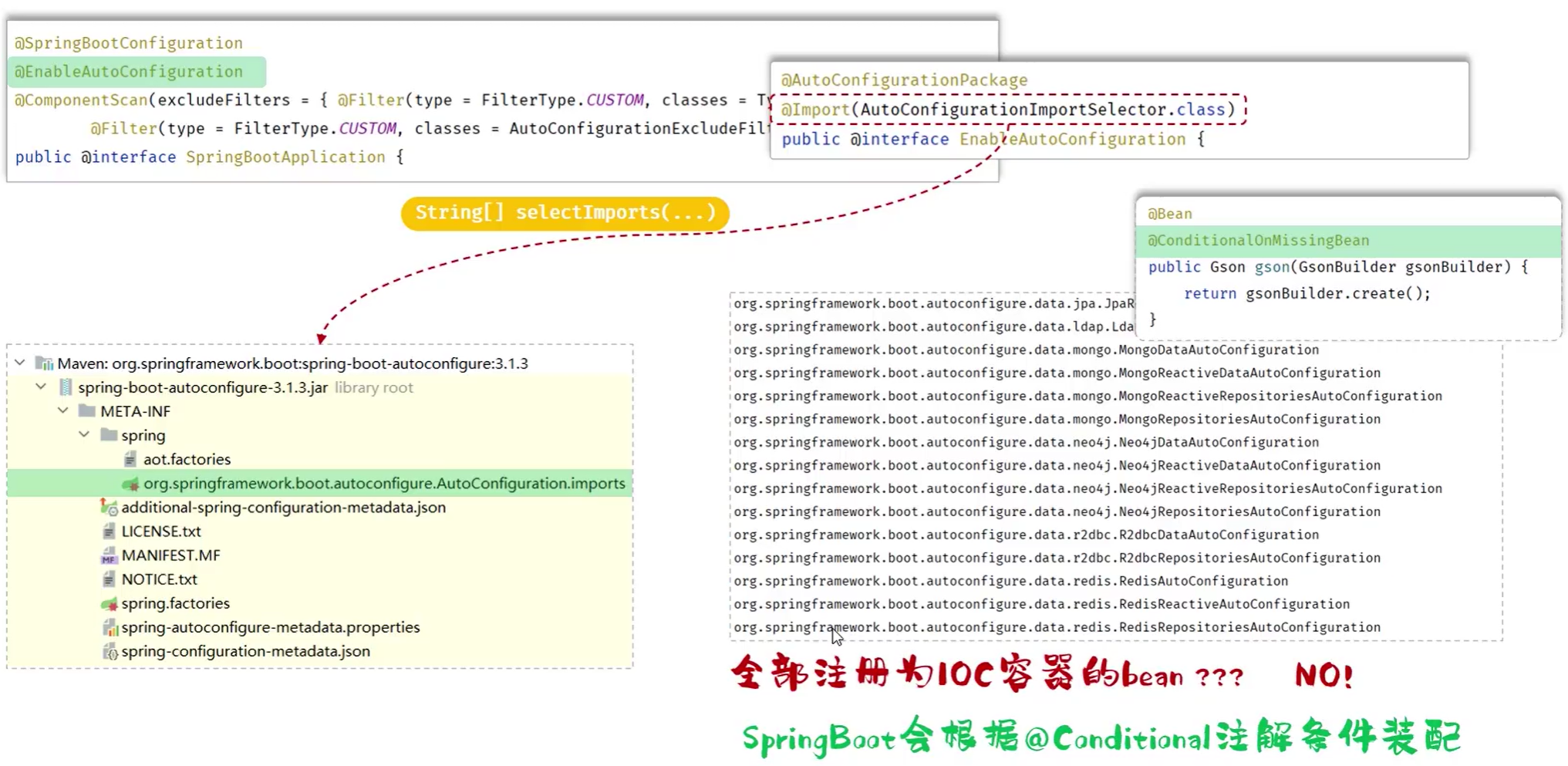

自己定义第三方工具包starter
SpringBoot官方starter命名: spring-boot-starter-xxxx
第三组织提供的starter命名: xxxx-spring-boot-starter
为什么第三方需要自动装配?
那使用第三方,第三方需要自动装配是不是因为启动类扫描不到这个类,不知道第三方所在的包
对于对于经常使用的打包成jar包,给别人使用
分析:
1.第三方组织名
xxxx-spring-boot-starter (依赖传递):starter中依赖引入autoconfigure
xxxx-spring-boot-autoconfigure(自动装配):以下都是完成自动装配
2.使用@Configuration注解配置类,配合@Bean注解注入,把配置类全类名放到META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports(AutoConfiguration.imports)文件中去
即使你的配置类中使用了
@Bean注解,Spring Boot 仍然需要通过AutoConfiguration.imports文件显式地声明这些配置类的存在。这样做的好处包括:
- 提高性能:避免类路径扫描,提高启动速度。
- 模块化和可扩展性:使得配置类可以被独立打包并复用。
- 条件化配置:根据条件自动决定是否应用这些配置。
放到META-INF/spring/…文件中好处?
将自定义工具包中的自动配置类的全名放到
META-INF/spring/...文件中,是为了让 Spring Boot 的自动配置机制能够更高效地识别并加载这些配置类。这种机制简化了自动配置的注册,提高了性能,增强了模块化和可扩展性,并且可以利用 Spring Boot 的条件化配置机制
原理
启动类上注解@SpringBootApplication -> @EnableAutoConfiguration -> @Import({AutoConfigurationImportSelector.class})
-> String[] selectImports(…) ->会获取所有叫META-INF/spring/…文件中全类名 -> 返回给String[] 全部对应名字然后创建对应bean
步骤:
1.完成对阿里云上传文件封装好,方便给别人使用
starter和autoconfigure中引入依赖
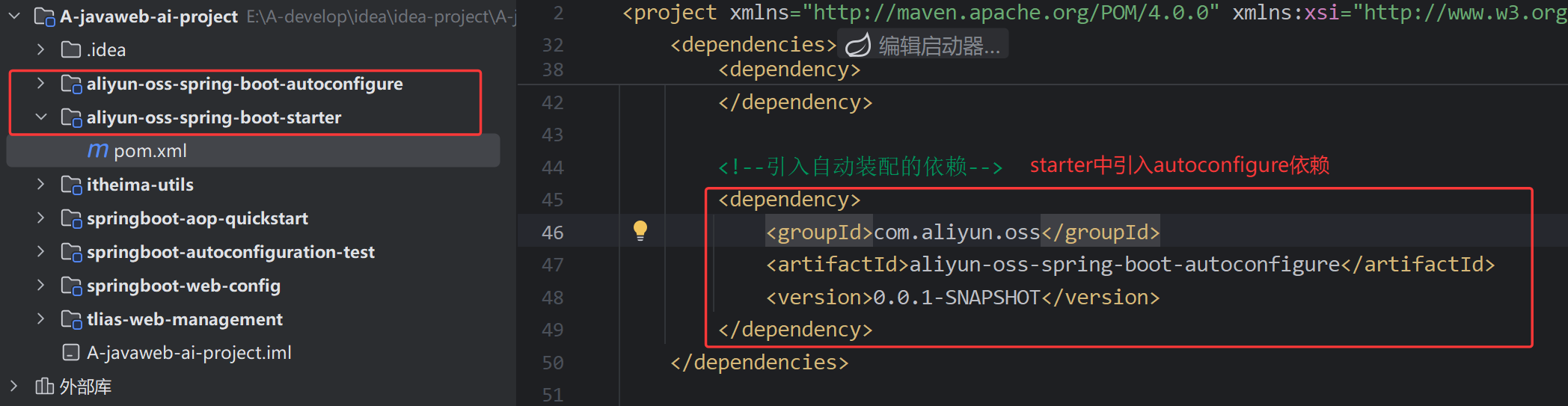
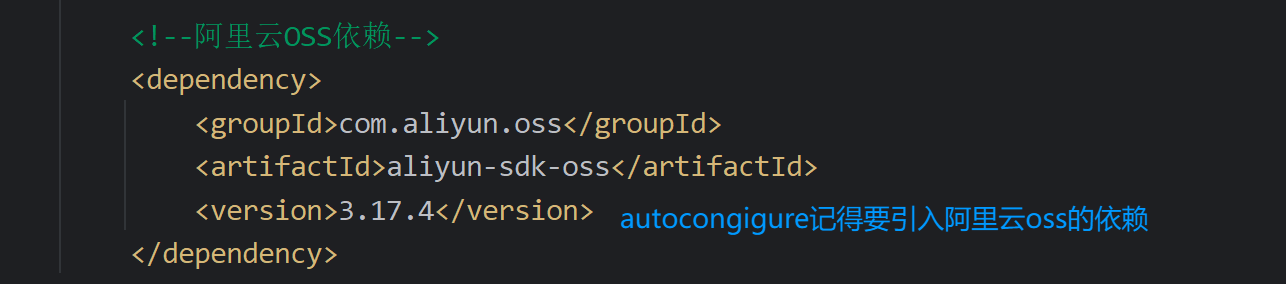
//配置类代码
@EnableConfigurationProperties(AliyunOSSProperties.class) //用来创建AliyunOSSProperties的bean对象
@Configuration
public class AliyunOSSAutoConfiguration {
@Bean
@ConditionalOnMissingBean //当环境中没有对应的bean,创建对应bean,存入到ioc当中去
public AliyunOSSOperator aliyunOSSOperator(AliyunOSSProperties aliyunOSSProperties){
return new AliyunOSSOperator(aliyunOSSProperties);
}
}
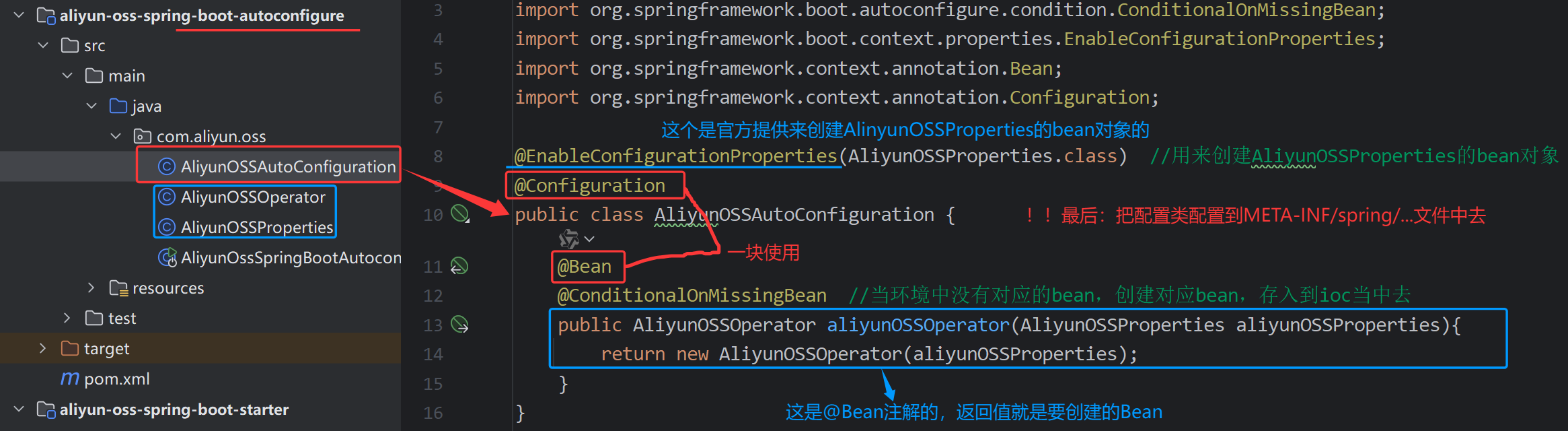
在 aliyun-oss-spring-boot-autoconfigure 模块中的resources下,新建自动配置文件 META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports
将自动配置类的全类名,加入META-INF/spring/…文件当中去
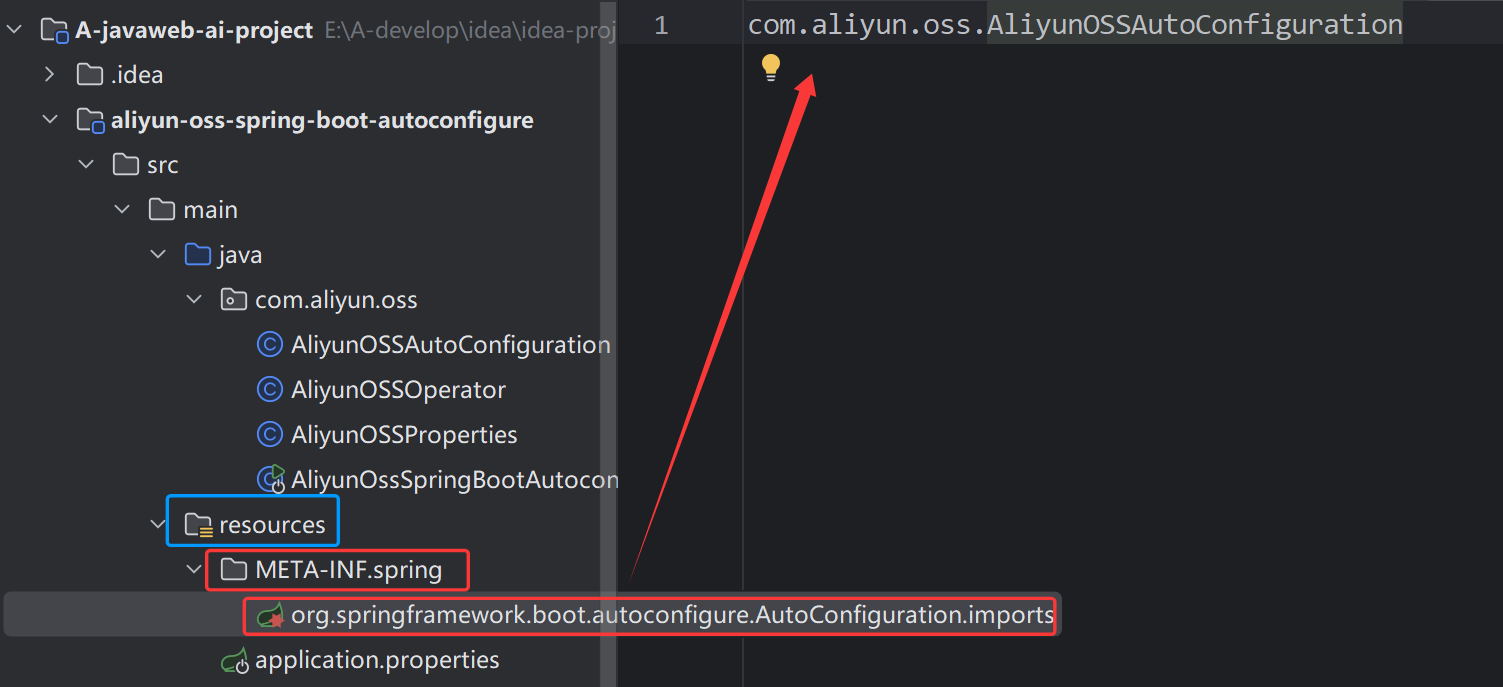
@EnableConfigurationProperties
阿里云上传类
/*
* 阿里云上传文件工具类
* */
//@Component 没有用,别人用这个oss工具依赖,扫描不到,所以这个Component没有用
public class AliyunOSSOperator {
private AliyunOSSProperties aliyunOSSProperties;
//要添加个有参构造函数,为AliyunOSSProperties依赖注入
public AliyunOSSOperator(AliyunOSSProperties aliyunOSSProperties) {
this.aliyunOSSProperties = aliyunOSSProperties;
} //
//省略以下代码,需要的话去文件上传那一节找
}
/*
*阿里云OSS配置属性类
* */
@ConfigurationProperties(prefix = "aliyun.oss") //将配置文件中以 aliyun.oss 为前缀的属性绑定到当前类的字段上。
public class AliyunOSSProperties {
private String endpoint; //阿里云OSS的服务地址。
private String bucketName; //阿里云OSS的存储桶名称。
private String region; //阿里云OSS所在的区域。
public String getEndpoint() {
return endpoint;
}
public void setEndpoint(String endpoint) {
this.endpoint = endpoint;
}
public String getBucketName() {
return bucketName;
}
public void setBucketName(String bucketName) {
this.bucketName = bucketName;
}
public String getRegion() {
return region;
}
public void setRegion(String region) {
this.region = region;
}
}
2.别人使用封装好的阿里云oss上传工具依赖
<!--自己定义好的阿里云oss-->
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-oss-spring-boot-starter</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
aliyun:
oss:
endpoint: https://oss-cn-shanghai.aliyuncs.com
bucketName: java-ai-23515
region: cn-shanghai
@RestController
public class UploadController {
private final AliyunOSSOperator aliyunOSSOperator;
public UploadController(AliyunOSSOperator aliyunOSSOperator) {
this.aliyunOSSOperator = aliyunOSSOperator;
}
@PostMapping("/upload")
public String upload(MultipartFile image) throws Exception {
//上传文件到阿里云 OSS
/*String url = aliyunOSSOperator.upload(image.getBytes(), image.getOriginalFilename());
return null;*/
String url =aliyunOSSOperator.upload(image.getBytes(), image.getOriginalFilename());
return url;
}
}
最后启动启动类
Maven高级
总结
1.分模块
2.继承:
<!-- 父类要用pom打包 -->
<packaging>pom</packaging>
<!-- 子类继承父类 -->
<parent>
<artifactId>sky-take-out</artifactId>
<groupId>com.sky</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<!-- ================================ -->
<properties> <!-- 自己工程中使用< properties >集中管理全部版本问题 -->
<mybatis.spring>2.2.0</mybatis.spring>
</properties>
<dependencyManagement> <!--统一管理子工程工程中的版本,但是子工程依赖组织名那些还是要写,版本不需要写而已-->
<dependencies>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.spring}</version>
</dependency>
</dependencies>
</dependencyManagement>
3.聚合: 在父工程中通过< modules >指定其它模块,把多个模块组织成一个整体,方便进行项目构建(打包清理)
<modules>
<module>sky-common</module>
<module>sky-pojo</module>
<module>sky-server</module>
</modules>
分模块设计
分模块报名前缀要相同!
方便项目的管理维护、拓展,也方便模块键的相互调用、资源共享。
先针对模块功能进行设计,再进行项目开发,不会先将工程开发完毕,然后进行拆分

1.以tlias-web-management为例,按照分模块,把pojo和utils分出来成为模块
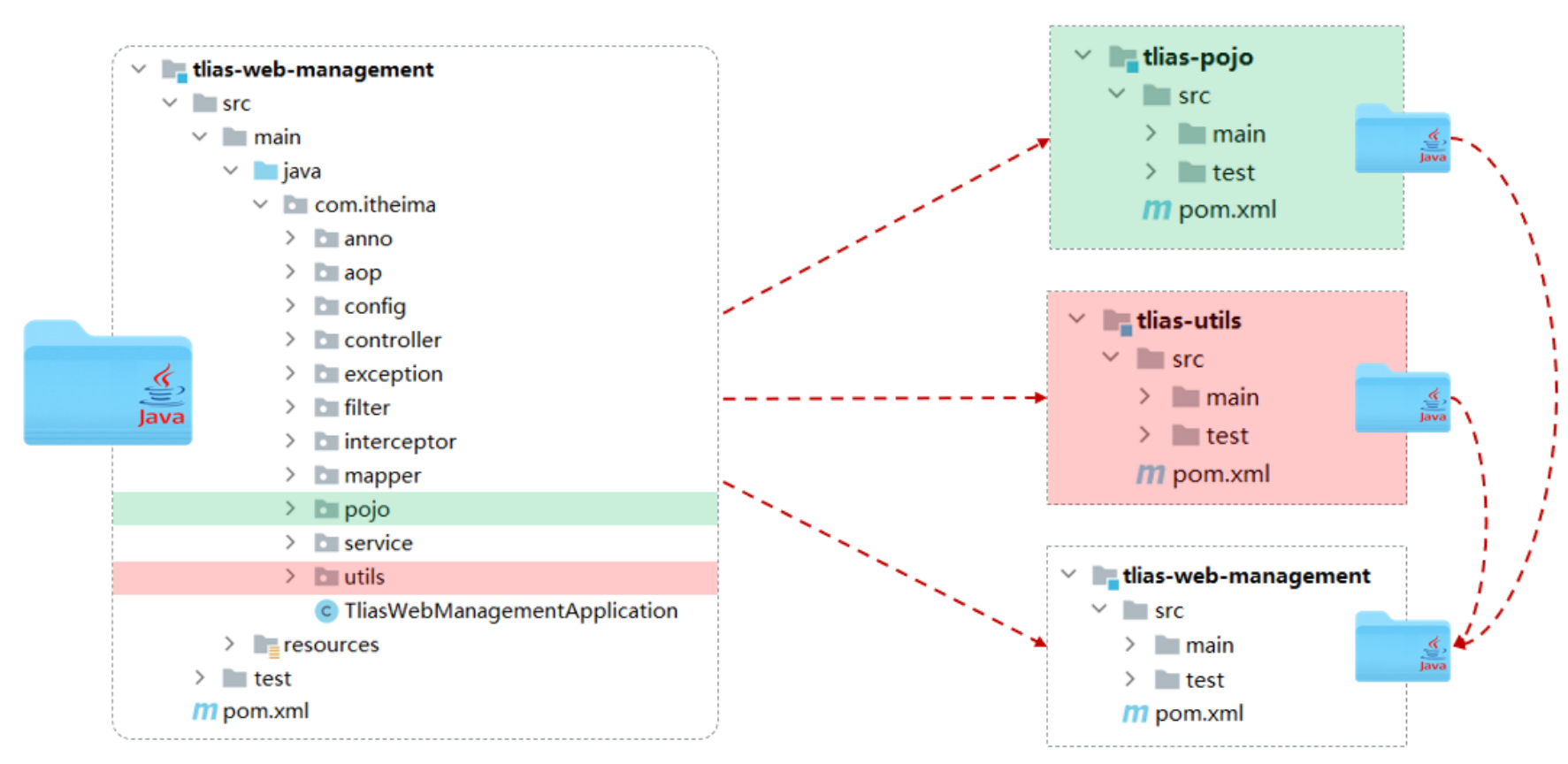
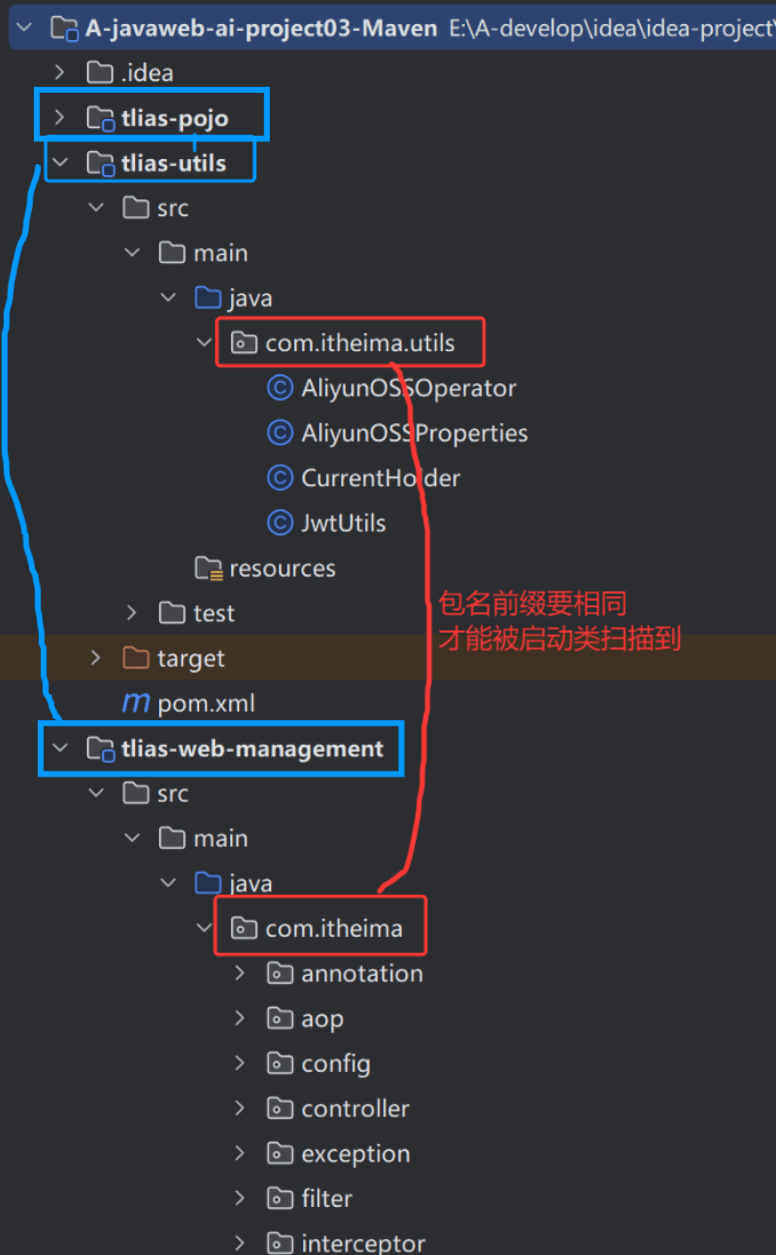
把tlias-pojo和tlias-utils分出来,注意添加各自模块中的依赖
主模块tlias-web-management中引入tlias-pojo和tlias-utils模块依赖
为什么maven分模块中,把utils阿里云上传工具类分模板,不需要自动装配?
因为:分出的utils模块,和 tlias-web-management在同一个包(com.itheima)下,启动类会扫描同包下(com.itheima)下的utils模块
那使用第三方,第三方需要自动装配是不是因为启动类扫描不到这个类,不知道第三方所在的包

继承
继承关系
- 把工程中相同的依赖弄到一个父工程当中去
- 父工程打包方式为pom
- 如果父子工程配置了同一个依赖的不同版本,以子工程为准

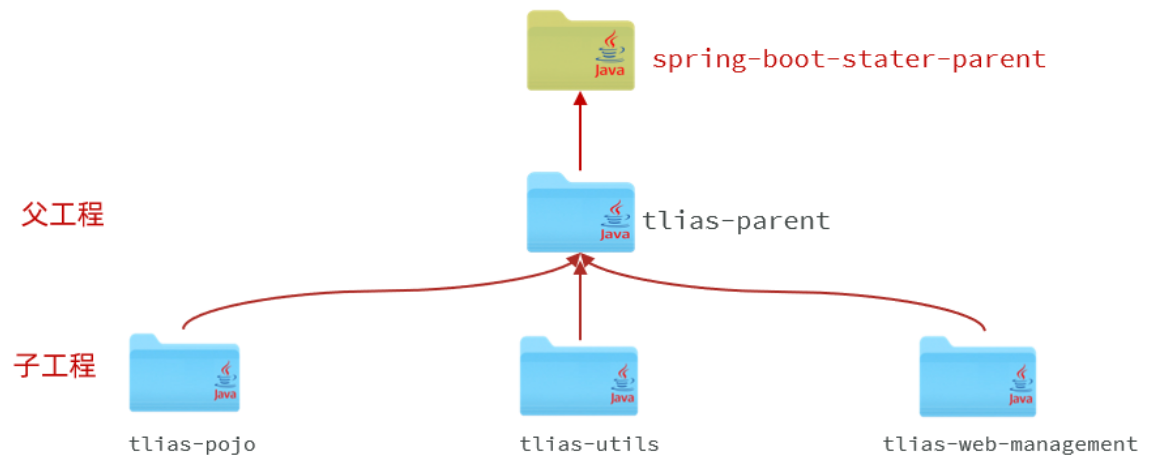
maven支持单继承和多重继承,不支持多继承
单继承(父亲)->(儿子),多继承(父亲,母亲)->(儿子),多重继承(爷爷)->(爸爸)->(孙子)
父工程tlias-parent
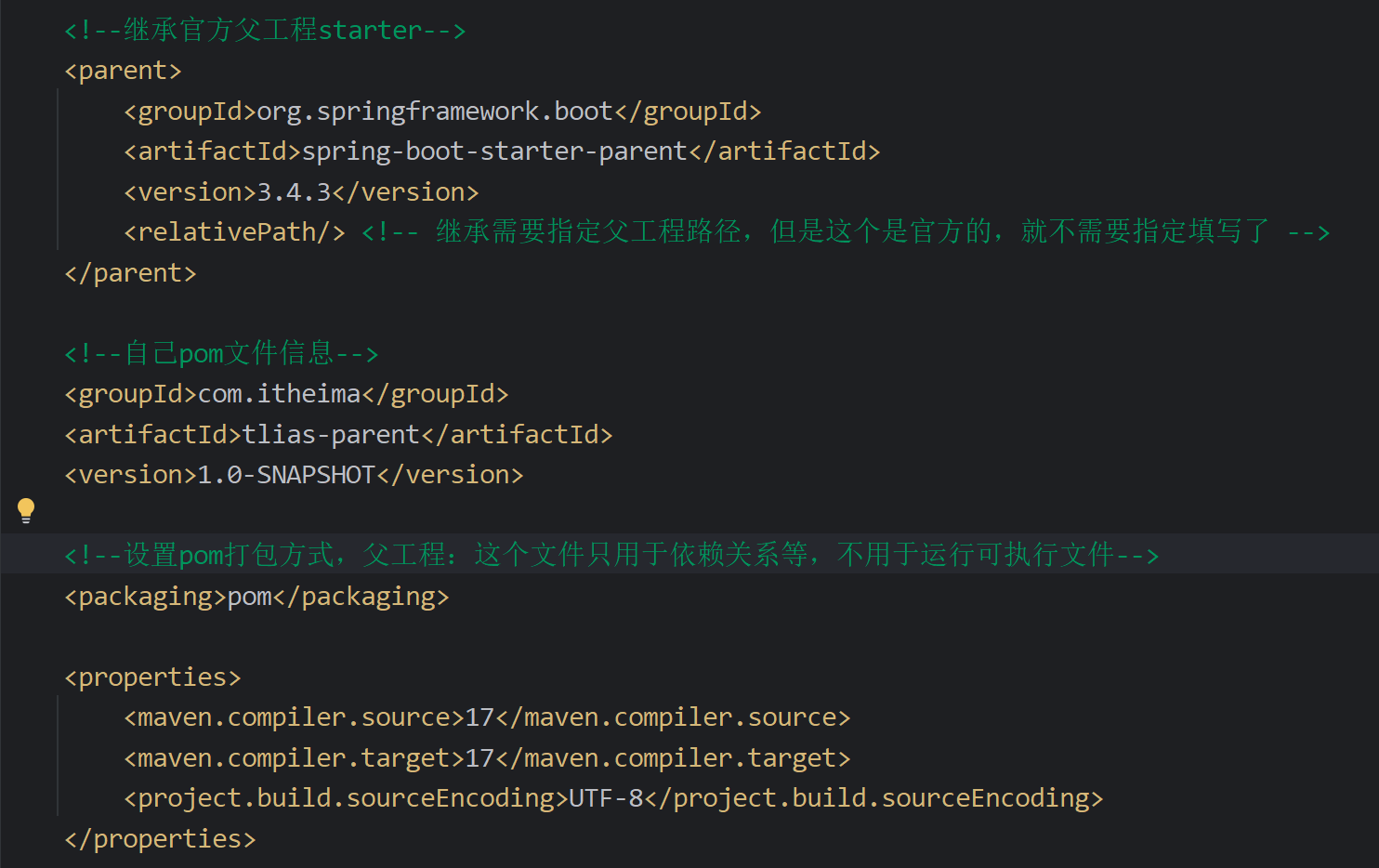
子工程
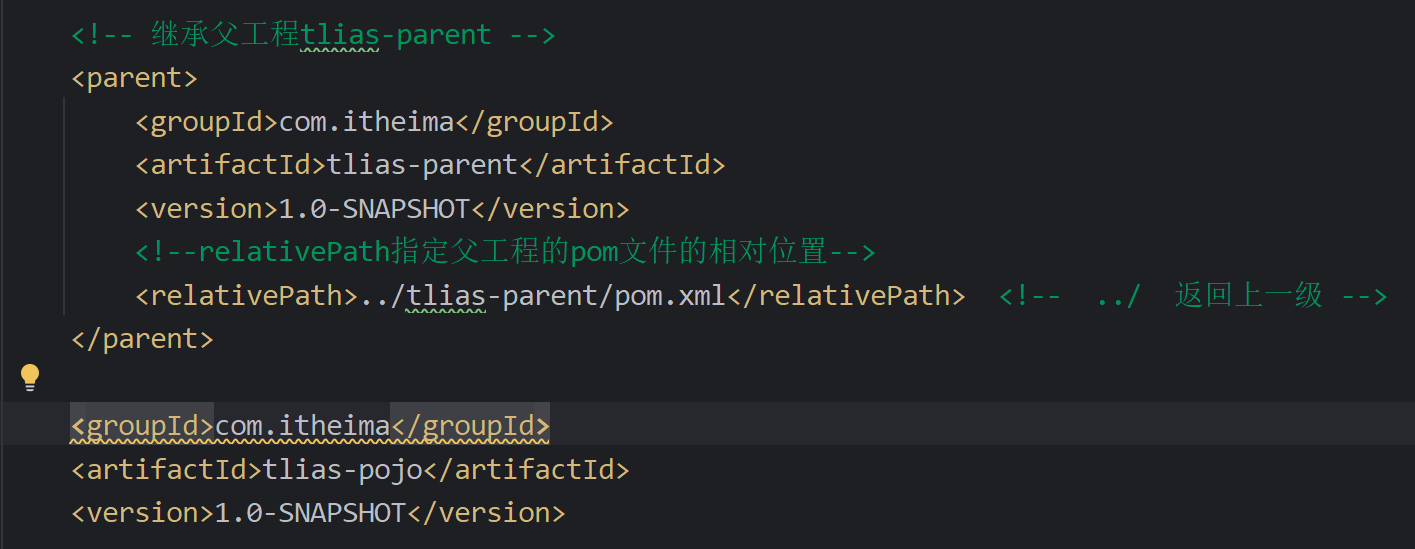
注意:
- 在子工程中,配置了继承关系之后,坐标中的groupId是可以省略的,因为会自动继承父工程的 。
- relativePath指定父工程的pom文件的相对位置(如果不指定,将从本地仓库/远程仓库查找该工程)。
- …/ 代表的上一级目录
为什么打包成pom包?
- pom打包方式本身主要用于父项目,本身不执行任何可执行文件,用于定义项目结构,依赖关系,模块化管理
Maven打包方式:
- jar:普通模块打包,springboot项目基本都是jar包(内嵌tomcat运行)
- war:普通web程序打包,需要部署在外部的tomcat服务器中运行
- pom:父工程或聚合工程,该模块不写代码,仅进行依赖管
版本锁定
在父工程中直接管理子工程中的版本,方便后期维护
-
父工程中使用< dependencyManagement >管理子工程版本
- 使用这个,父工程只是指定版本了,子工程中还是要引入依赖(只是不需要写版本了)
-
自己工程中使用< properties >集中管理全部版本问题(几万行代码,方便集中管理)
-
${ }
-
<lombok.version>1.18.34</lombok.version>
-
<groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version>
-
管理子工程版本**< dependencyManagement >**
父工程pom文件
<dependencyManagement>
<dependencies> <!--统一管理子工程工程中的版本,但是子工程依赖组织名那些还是要写,版本不需要写而已-->
<!-- 令牌JWT依赖 -->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
</dependencies>
</dependencyManagement>
子工程pom文件
<dependencies>
<!-- 令牌JWT依赖 -->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<!--<version>0.9.1</version>--> <!--已经在父工程中指定版本,这里可以删掉-->
</dependency>
</dependencies>
集中管理自己版本 < properties >
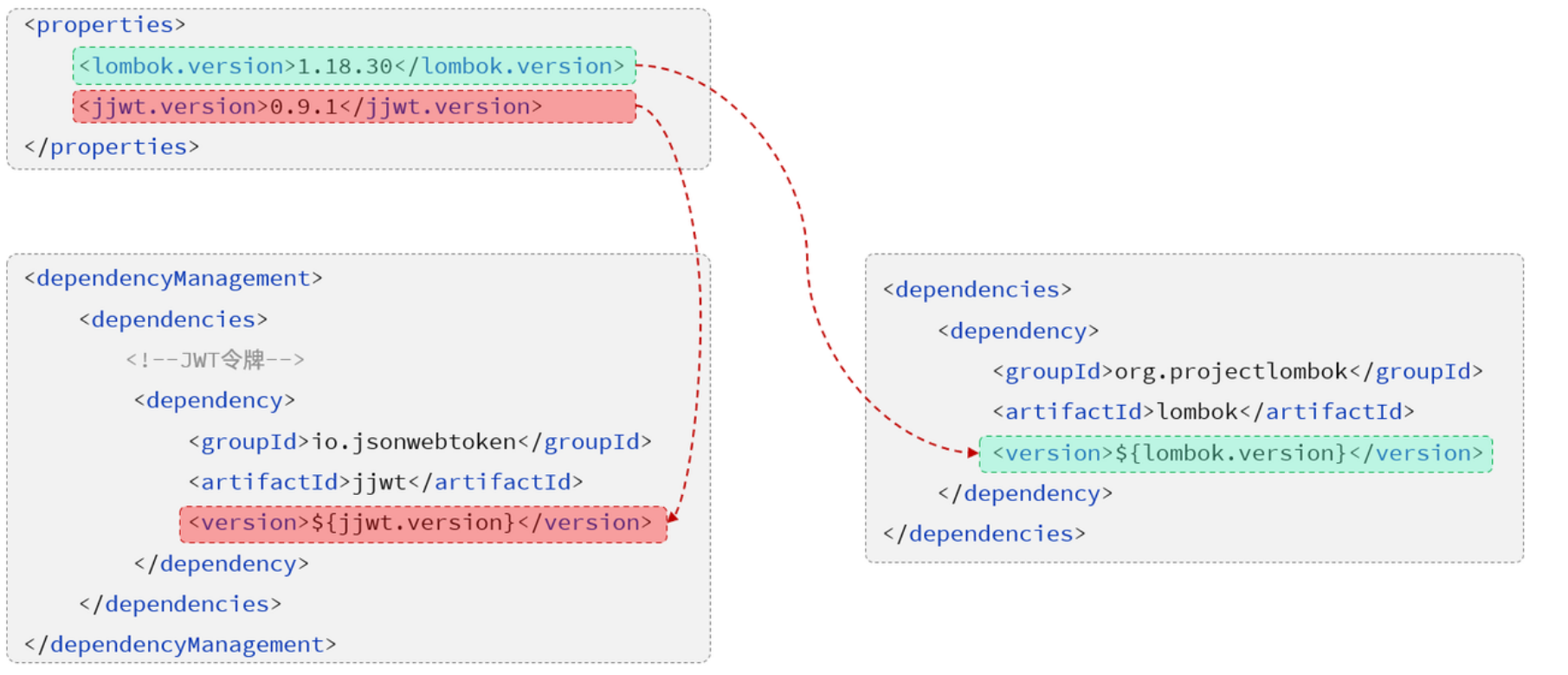
父工程pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!--继承官方父工程starter-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.3</version>
<relativePath/> <!-- 继承需要指定父工程路径,但是这个是官方的,就不需要指定填写了 -->
</parent>
<!--自己pom文件信息-->
<groupId>com.itheima</groupId>
<artifactId>tlias-parent</artifactId>
<version>1.0-SNAPSHOT</version>
<!--设置pom打包方式,父工程:这个文件只用于依赖关系等,不用于运行可执行文件-->
<packaging>pom</packaging>
<properties> <!--管理自己工程中的版本-->
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--自定义属性-->
<sping-boot.version>3.2.8</sping-boot.version>
<lombok.version>1.18.34</lombok.version>
<jwt.version>0.9.1</jwt.version>
<aliyun.oss.version>3.17.4</aliyun.oss.version>
<jaxb.version>2.3.1</jaxb.version>
<javax.activation.version>1.1.1</javax.activation.version>
<jaxb.runtime.version>2.3.3</jaxb.runtime.version>
</properties>
<!--统一管理子工程工程中的版本,但是子工程依赖组织名那些还是要写,版本不需要写而已-->
<dependencyManagement>
<dependencies>
<!--阿里云OSS依赖-->
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>${aliyun.oss.version}</version>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>${jaxb.version}</version>
</dependency>
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>${javax.activation.version}</version>
</dependency>
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>${jaxb.runtime.version}</version>
</dependency>
<!--======== 以上都是阿里云OSS的依赖 ============-->
<!-- 令牌JWT依赖 -->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>${sping-boot.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
</dependencies>
</project>
聚合
- 聚合工程:在父工程中通过< modules >指定其它模块,把多个模块组织成一个整体,方便进行项目构建(打包清理)
- 父工程=聚合工程(一般)
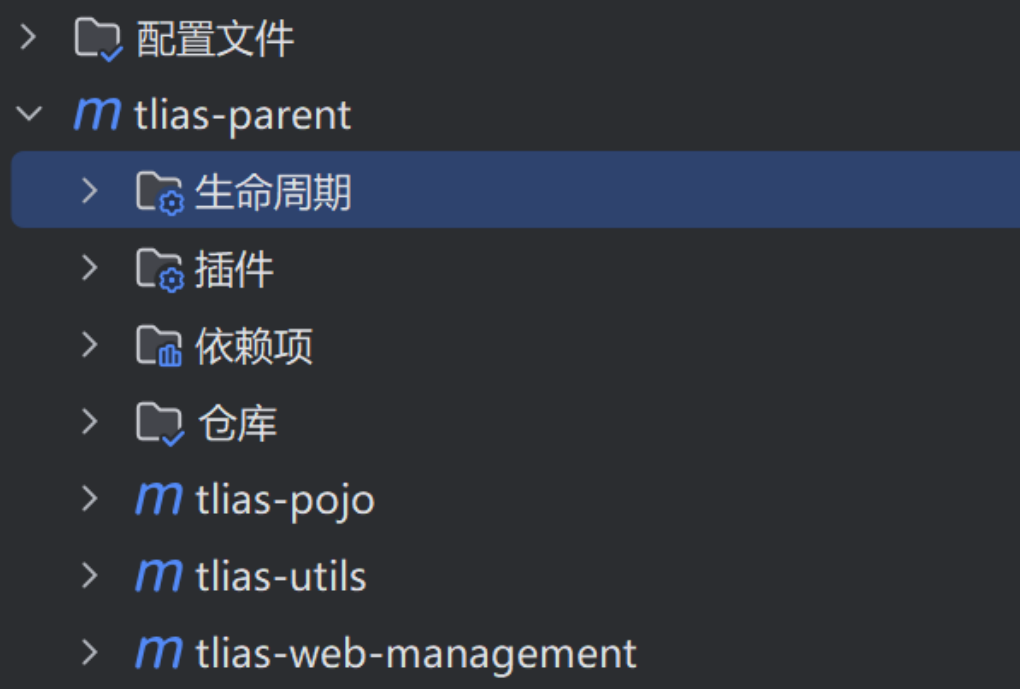
介绍
在进行项目打包时,maven会从本地仓库中来查找
tlias-parent父工程,以及它所依赖的模块tlias-pojo、tlias-utils,而本地仓库目前是没有这几个依赖的,所以我们在打包
tlias-web-management模块前,需要将tlias-parent、tlias-pojo、tlias-utils分别执行install生命周期安装到maven的本地仓库,然后再针对于tlias-web-management模块执行package进行打包操作。很麻烦
所以有了聚合工程
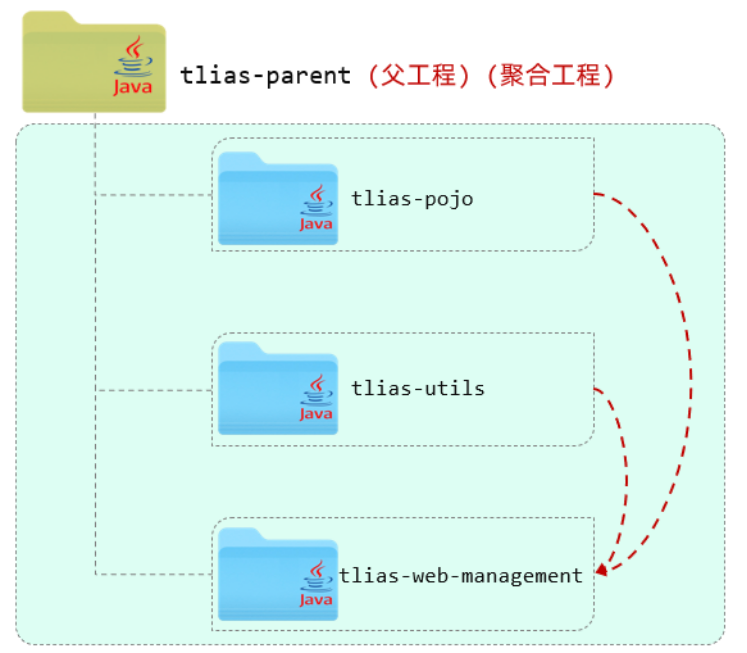
- **聚合:**将多个模块组织成一个整体,同时进行项目的构建。
- **聚合工程:**一个不具有业务功能的“空”工程(有且仅有一个pom文件) 【PS:一般来说,继承关系中的父工程与聚合关系中的聚合工程是同一个】
- **作用:**快速构建项目(无需根据依赖关系手动构建,直接在聚合工程上构建即可)
通过< moudules >在父工程(聚合工程)
<!-- 聚合其他模块 -->
<modules>
<module>../tlias-pojo</module>
<module>../tlias-utils</module>
<module>../tlias-web-management</module>
</modules>

私服
- 开发好的模块,想让在同一个公司其他项目组使用,实现资源共享,通过Maven私服(nexus仓库)
- maven中引入依赖查找顺序:本地仓库 -> 私服 -> 中央仓库
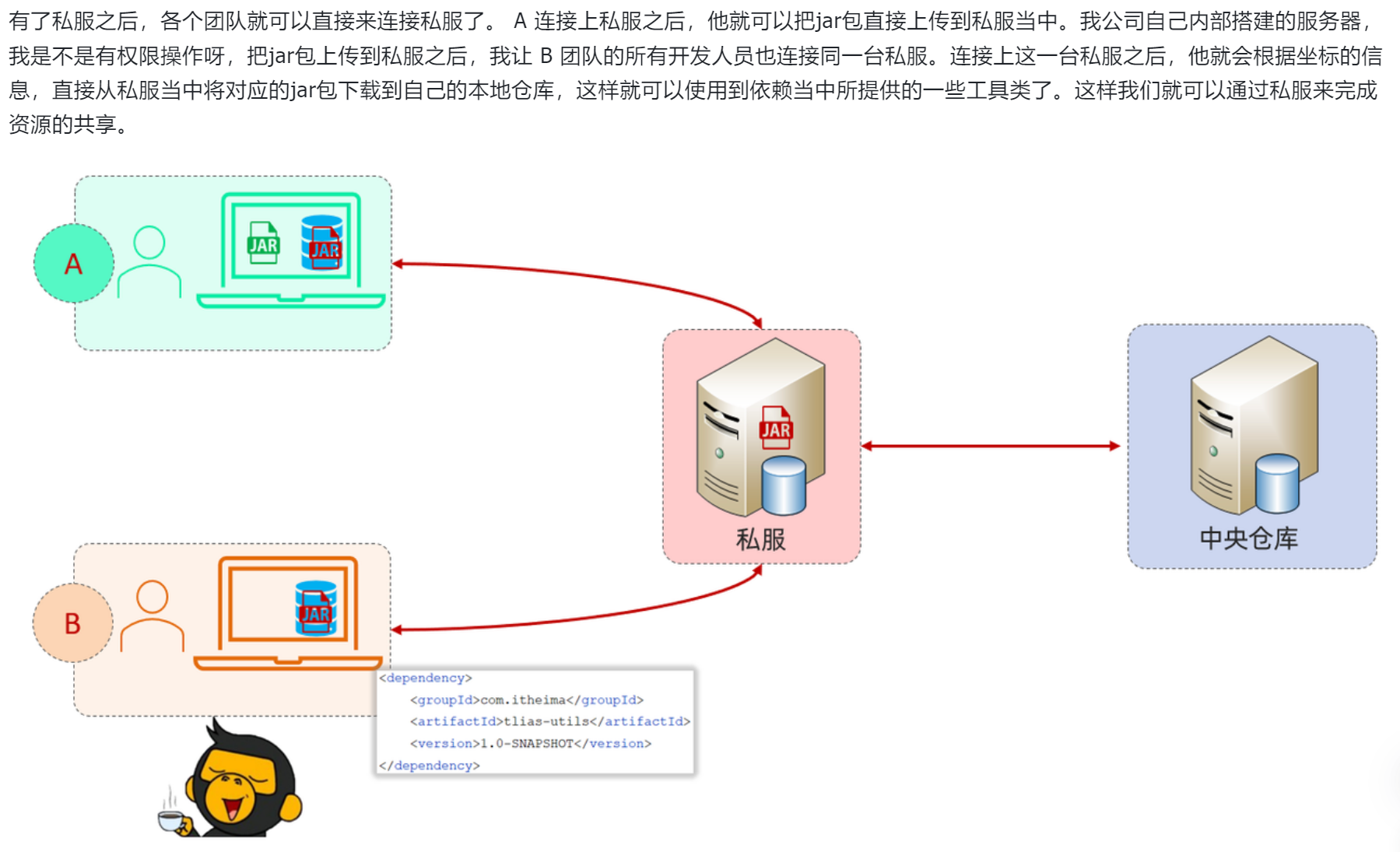
介绍
使用私服就需要设置IDEA和私服的配置
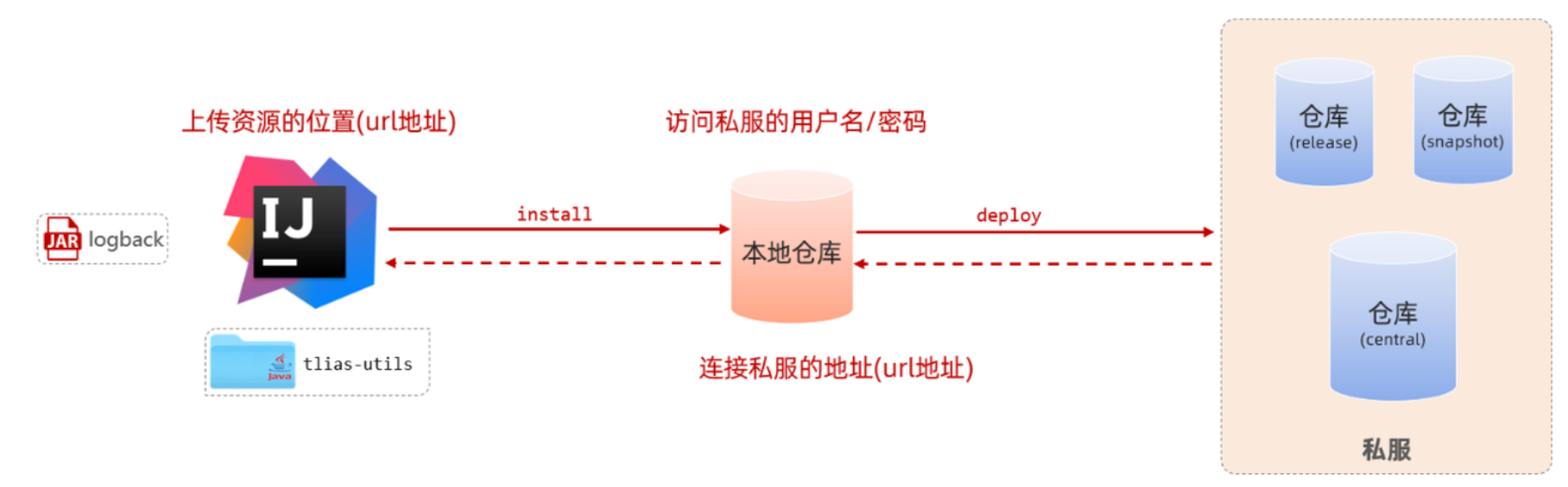
项目版本说明:
- RELEASE(发布版本):功能趋于稳定、当前更新停止,可以用于发行的版本,存储在私服中的RELEASE仓库中。
- SNAPSHOT(快照版本):功能不稳定、尚处于开发中的版本,即快照版本,存储在私服的SNAPSHOT仓库中。
- RELEASE:存储自己开发的RELEASE发布版本的资源。
- SNAPSHOT:存储自己开发的SNAPSHOT发布版本的资源。
- Central:存储的是从中央仓库下载下来的依赖
资源上传与下载,我们需要做三步配置,执行一条指令。
- 第一步配置:在maven的配置文件中配置访问私服的用户名、密码。
- 第二步配置:在maven的配置文件中配置连接私服的地址(url地址)。
- 第三步配置:在项目的pom.xml文件中配置上传资源的位置(url地址)。
- 配置好了上述三步之后,要上传资源到私服仓库,就执行执行maven生命周期:
deploy。
私服服务器:nexus
这里借助本地的(E:\A-develop\nexus\nexus-3.75.1-01\bin)
可以访问私服测试:http://localhost:8081
具体步骤
访问
1. 设置私服的访问用户名/密码(在自己maven安装目录下的 conf/settings.xml中的servers中配置)**
<!-- 配置maven访问私服的用户名和密码 -->
<server>
<id>maven-releases</id>
<username>admin</username>
<password>admin</password>
</server>
<server>
<id>maven-snapshots</id>
<username>admin</username>
<password>admin</password>
</server>
</servers>
2.设置私服依赖下载的仓库组地址(在自己maven安装目录下的conf/settings.xml中的mirrors中配置)
<!-- 配置从私服下载的仓库地址 -->
<mirror>
<id>maven-public</id>
<mirrorOf>*</mirrorOf>
<url>http://localhost:8081/repository/maven-public/</url>
</mirror>
3.设置私服依赖下载的仓库组地址(在自己maven安装目录下的conf/settings.xml中的profiles中配置)
<!-- 配置从私服下载的权限:可以下载releases和releases -->
<profile>
<id>allow-snapshots</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<repositories>
<repository>
<id>maven-public</id>
<url>http://localhost:8081/repository/maven-public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</profile>
4.IDEA的maven工程的pom文件中配置上传(发布)地址(直接在tlias-parent中配置发布地址)
<distributionManagement>
<!-- release版本的发布地址 -->
<repository>
<id>maven-releases</id>
<url>http://localhost:8081/repository/maven-releases/</url>
</repository>
<!-- snapshot版本的发布地址 -->
<snapshotRepository>
<id>maven-snapshots</id>
<url>http://localhost:8081/repository/maven-snapshots/</url>
</snapshotRepository>
</distributionManagement>
其他人要想使用这个工具包,进行以下一二步骤即可(也就是上面其中两部)
- 第一步配置:在maven的配置文件**
settings.xml**中配置访问私服的用户名、密码。 - 第二步配置:在maven的配置文件中配置连接私服的地址(url地址)。
- 引入想要用到私服中的依赖配置
后端开发总结
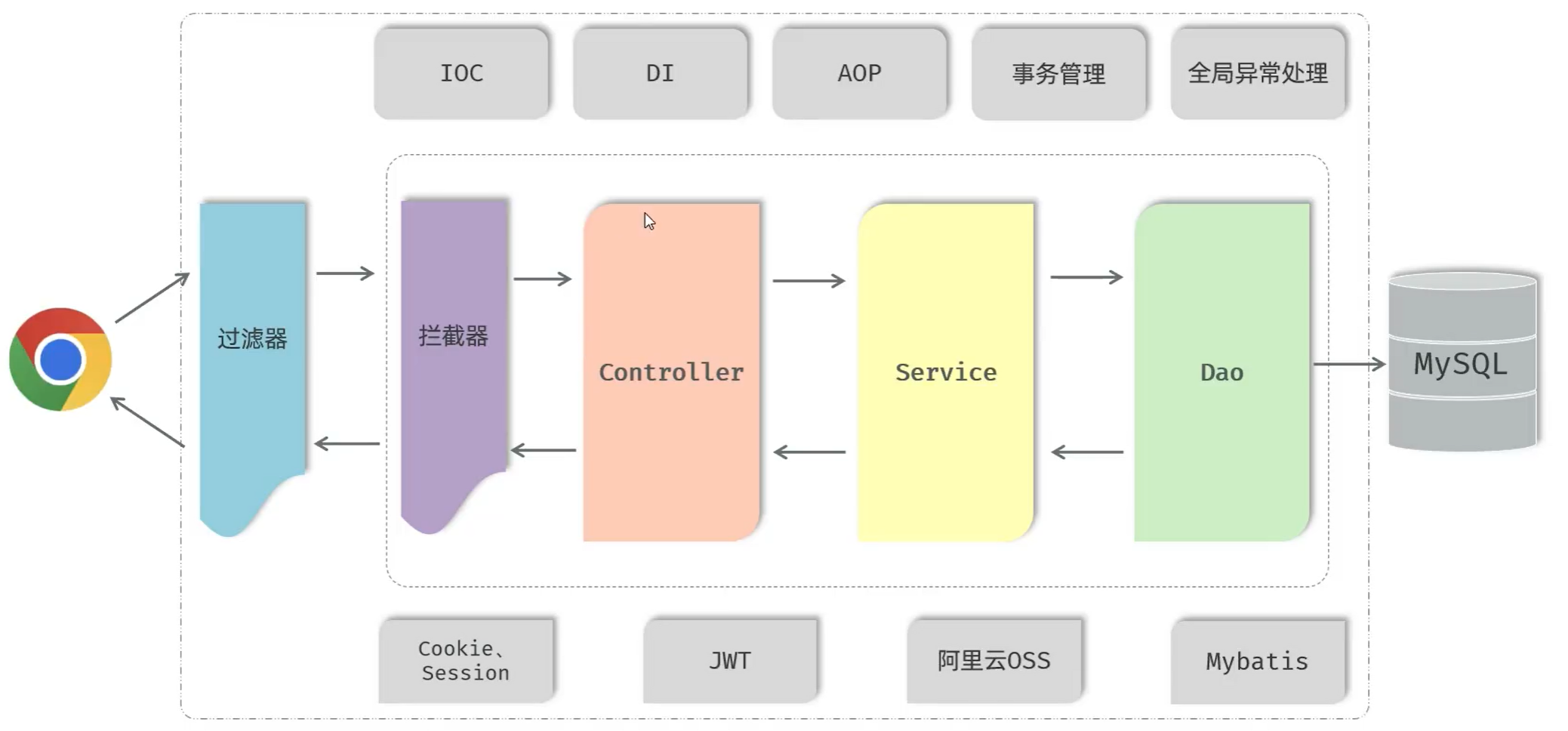



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









