






目录
最后通过分页的详解(后端)就到这里,祝大家在敲代码的路上一路通畅!
一.通用分页
1.1.通用分页是什么?
- 通用分页(Universal Pagination)是一种在网页浏览器中用于显示和浏览大量内容的技术。它允许用户通过在网页上滚动而不是点击页面链接来浏览连续的数据。
- 传统的网页浏览中,当需要展示大量内容时,通常会把内容划分为多个页面或者使用无限滚动的方式。而通用分页通过在同一个页面上显示和加载数据来改进用户的浏览体验。
- 通用分页通常使用滚动加载(infinite scrolling)技术,即当用户滚动到页面底部时,会自动加载更多数据,并把新加载的内容追加到页面尾部。这样一来,用户可以连续滚动浏览不同的数据,而不需要翻页或点击加载更多按钮。
- 通用分页技术对于许多网站和应用程序而言,特别是那些需要展示大量数据的社交媒体、电子商务和新闻网站等非常有用。它可以提供更流畅的用户体验,节省用户的点击和加载时间,并且更方便地呈现连续的内容。
1.2. 为什么使用通用分页
使用通用分页有以下几个主要原因:
提高用户体验:通用分页通过减少翻页和点击加载的需求,提供了更流畅和连续的浏览体验。用户可以无需等待页面加载或翻转页面,而是通过滚动即可加载和浏览更多内容。
节省操作时间:传统的分页方式需要用户手动点击翻页或加载更多按钮,而通用分页则自动加载数据,减少了用户的操作步骤和时间消耗。
适应大量内容:对于包含大量数据的网站和应用程序,通用分页是一种更好的展示方式。它可以处理大量数据的加载和显示,而不会给页面带来过多的负担和加载时间。
方便数据导航:通用分页对于用户来说更容易导航和定位到感兴趣的内容。用户可以快速滚动,逐渐浏览数据并进行筛选或搜索,而无需在不同页面之间切换。
适应移动设备:通用分页也适用于移动设备,如智能手机和平板电脑。在小屏幕上,通过滚动浏览远比点击翻页更为方便和友好。
总之,通用分页技术通过提供无缝的浏览体验、节省操作时间和方便数据导航,为用户展示大量内容提供了更好的解决方案,特别适用于那些需要连续浏览和快速访问内容的网站和应用程序。
1.3.通用分页在哪些方面使用
通用分页可以在许多不同的应用和领域中使用。以下是通用分页应用的一些常见领域:
社交媒体平台:社交媒体平台如Facebook、Instagram、Twitter等,通常需要展示大量的动态内容,包括用户发表的帖子、照片、视频等。通过使用通用分页,可以让用户以非常流畅的方式浏览和滚动浏览这些内容,从而提高用户的浏览体验。
新闻和内容聚合网站:新闻媒体和内容聚合网站如Reddit、Hacker News等,通常都有大量的文章和帖子需要展示。通过使用通用分页,可以让用户连续滚动浏览不同的内容,而不需要翻页或点击加载更多按钮。
电子商务平台:在线零售商和电子商务平台常常需要展示大量的产品和商品信息。通过使用通用分页,用户可以无缝地滚动浏览和比较不同的产品,从而提高购物体验。
博客和论坛:博客和论坛网站通常有大量的文章和帖子需要浏览。通过使用通用分页,用户可以方便地连续浏览不同的帖子或文章,而无需翻页或加载新页面。
图像和视频分享平台:图像分享平台如Imgur、500px以及视频分享平台如YouTube、Vimeo等,通过使用通用分页,用户可以无缝地滚动浏览大量的图像和视频内容。
总的来说,通用分页可以用于任何需要展示大量内容,并希望提供流畅、连续浏览体验的应用和网站中。它能够提高用户体验,节省操作时间,并适应不同设备和屏幕尺寸的要求。
二.工具类介绍
2.1 DBAccess
DBAccess是一个通用数据库访问工具或库的名称。它是用于在应用程序中与数据库进行通信和交互的工具,提供了简单和方便的方式来执行数据库操作,如查询、插入、更新和删除等。
DBAccess通常提供了一个API(应用程序编程接口),使开发者可以使用编程语言(如Java、Python、C#等)中的特定方法和函数来执行数据库操作。通过这些API,开发者可以连接到数据库服务器,发送SQL查询或命令,读取和写入数据,以及处理数据库事务等。
DBAccess的主要功能包括:
数据库连接管理:提供建立和管理与数据库服务器的连接的能力,包括连接的创建、打开、关闭和池化等。
数据库查询和操作:允许开发者执行各种数据库操作,如执行查询语句、插入新数据、更新和删除数据等。
数据库事务处理:支持事务操作,可以确保一系列数据库操作的原子性,即要么全部成功执行,要么全部回滚。
数据库错误处理:提供异常处理和错误消息的机制,以便开发者能够有效捕捉和处理在数据库操作过程中可能出现的错误。
数据库性能优化:通过提供一些性能优化功能,如查询缓存、预编译语句、连接池等,来加速数据库访问和提高应用程序的响应性能。
DBAccess可以与各种类型的数据库系统配合使用,例如关系型数据库如MySQL、Oracle、SQL Server,以及NoSQL数据库如MongoDB、Redis等。它在开发各种类型的应用程序中都很有用,包括Web应用、移动应用、桌面应用等,以简化数据库操作并提高开发效率。
代码如下 :
package com.junlinyi.util;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* 提供了一组获得或关闭数据库对象的方法
*
*/
public class DBAccess {
private static String driver;
private static String url;
private static String user;
private static String password;
static {// 静态块执行一次,加载 驱动一次
try {
InputStream is = DBAccess.class
.getResourceAsStream("config.properties");
Properties properties = new Properties();
properties.load(is);
driver = properties.getProperty("driver");
url = properties.getProperty("url");
user = properties.getProperty("user");
password = properties.getProperty("pwd");
Class.forName(driver);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
/**
* 获得数据连接对象
*
* @return
*/
public static Connection getConnection() {
try {
Connection conn = DriverManager.getConnection(url, user, password);
return conn;
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
public static void close(ResultSet rs) {
if (null != rs) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
public static void close(Statement stmt) {
if (null != stmt) {
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
public static void close(Connection conn) {
if (null != conn) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
public static void close(Connection conn, Statement stmt, ResultSet rs) {
close(rs);
close(stmt);
close(conn);
}
public static boolean isOracle() {
return "oracle.jdbc.driver.OracleDriver".equals(driver);
}
public static boolean isSQLServer() {
return "com.microsoft.sqlserver.jdbc.SQLServerDriver".equals(driver);
}
public static boolean isMysql() {
return "com.mysql.cj.jdbc.Driver".equals(driver);
}
public static void main(String[] args) {
Connection conn = DBAccess.getConnection();
System.out.println(conn);
DBAccess.close(conn);
System.out.println("isOracle:" + isOracle());
System.out.println("isSQLServer:" + isSQLServer());
System.out.println("isMysql:" + isMysql());
System.out.println("数据库连接(关闭)成功");
}
}
2.2. 过滤器
package com.junlinyi.util;
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* 过滤器
* 中文乱码处理
*
*/
public class EncodingFiter implements Filter {
private String encoding = "UTF-8";// 默认字符集
public EncodingFiter() {
super();
}
public void destroy() {
}
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse res = (HttpServletResponse) response;
// 中文处理必须放到 chain.doFilter(request, response)方法前面
res.setContentType("text/html;charset=" + this.encoding);
if (req.getMethod().equalsIgnoreCase("post")) {
req.setCharacterEncoding(this.encoding);
} else {
Map map = req.getParameterMap();// 保存所有参数名=参数值(数组)的Map集合
Set set = map.keySet();// 取出所有参数名
Iterator it = set.iterator();
while (it.hasNext()) {
String name = (String) it.next();
String[] values = (String[]) map.get(name);// 取出参数值[注:参数值为一个数组]
for (int i = 0; i < values.length; i++) {
values[i] = new String(values[i].getBytes("ISO-8859-1"),
this.encoding);
}
}
}
chain.doFilter(request, response);
}
public void init(FilterConfig filterConfig) throws ServletException {
String s = filterConfig.getInitParameter("encoding");// 读取web.xml文件中配置的字符集
if (null != s && !s.trim().equals("")) {
this.encoding = s.trim();
}
}
}
2.3. 分页工具类
分页工具类是指用于处理分页逻辑的工具类或库。它提供了一系列方法和函数,用于计算分页相关的参数,生成分页查询语句,以及将查询结果按照指定的分页规则进行切片和返回。
通常,一个分页工具类包含以下功能:
计算分页参数:提供方法用于计算总记录数、总页数等分页参数,基于传入的每页记录数和总记录数。
生成分页查询语句:根据传入的页码和每页记录数,生成相应的数据库查询语句,以获取对应页的数据。
执行分页查询:执行查询语句,并将查询结果按照分页规则进行切片,返回当前页的数据。
处理边界情况:处理第一页、最后一页、无数据等特殊情况,以确保分页逻辑的正确性和健壮性。
提供其他辅助方法:提供其他辅助方法,如计算起始行号、结束行号,判断是否存在上一页、下一页,生成分页链接等。
分页工具类可以根据具体的编程语言和框架来实现,并根据不同的需求提供不同的特性和定制化选项。在Java中,常见的分页工具类有Spring Data JPA的
Pageable和MyBatis的PageHelper。使用分页工具类可以简化分页操作的实现,使开发人员能够更方便地处理分页逻辑,同时提供了一致性和可复用性的解决方案,以适应不同的应用场景和需求。
代码如下 :
package com.junlinyi.util;
/**
* 分页工具类
*
*/
public class PageBean {
private int page = 1;// 页码
private int rows = 10;// 页大小
private int total = 0;// 总记录数
private boolean pagination = true;// 是否分页
public PageBean() {
super();
}
public int getPage() {
return page;
}
public void setPage(int page) {
this.page = page;
}
public int getRows() {
return rows;
}
public void setRows(int rows) {
this.rows = rows;
}
public int getTotal() {
return total;
}
public void setTotal(int total) {
this.total = total;
}
public void setTotal(String total) {
this.total = Integer.parseInt(total);
}
public boolean isPagination() {
return pagination;
}
public void setPagination(boolean pagination) {
this.pagination = pagination;
}
/**
* 获得起始记录的下标
*
* @return
*/
public int getStartIndex() {
return (this.page - 1) * this.rows;
}
@Override
public String toString() {
return "PageBean [page=" + page + ", rows=" + rows + ", total=" + total + ", pagination=" + pagination + "]";
}
}
2.4.字符串工具类
StringUtils是一个常见的字符串操作工具类,它是Apache Commons Lang 库中的一个类。该工具类提供了一系列静态方法,用于处理字符串的各种操作和转换。
StringUtils类提供了丰富的字符串处理方法,包括但不限于以下几个方面:
字符串判空和空格处理:提供了判断字符串是否为空或null的方法,以及去除字符串中的空格或空白字符的方法。
字符串比较和匹配:提供了比较字符串是否相等的方法,忽略大小写或考虑大小写。还提供了判断字符串是否以指定字符开头或结尾的方法,以及判断字符串是否包含指定字符的方法。
字符串截取和分割:提供了截取字符串的方法,可以根据指定的起始位置和长度来获取子字符串。还可以根据指定的分隔符将字符串分割为字符串数组的方法。
字符串替换和填充:提供了替换字符串中指定内容的方法,可以是指定的字符、子字符串或正则表达式。还提供了将字符串按照指定格式进行填充和格式化的方法。
字符串大小写转换:提供了将字符串转换为大写或小写形式的方法,以便对字符串进行大小写敏感的操作。
StringUtils类还提供了其他与字符串相关的辅助方法,例如将对象转换为字符串的方法,字符串的截取和补齐方法,字符串的反转和去除指定字符等。
使用StringUtils类可以简化字符串操作和处理的实现,减少冗余的代码,提高开发效率,并提供一致性和可复用性的解决方案。注意,需要在项目中引入Apache Commons Lang库才能使用StringUtils类的方法。
代码如下 :
package com.junlinyi.util;
/**
* 字符串工具类
* @author: 君临沂
*
*/
public class StringUtils {
// 私有的构造方法,保护此类不能在外部实例化
private StringUtils() {
}
/**
* 如果字符串等于null或去空格后等于"",则返回true,否则返回false
*
* @param s
* @return
*/
public static boolean isBlank(String s) {
boolean b = false;
if (null == s || s.trim().equals("")) {
b = true;
}
return b;
}
/**
* 如果字符串不等于null或去空格后不等于"",则返回true,否则返回false
*
* @param s
* @return
*/
public static boolean isNotBlank(String s) {
return !isBlank(s);
}
}
2.5.配置类
配置类是指在软件开发中用于管理应用程序配置项的类。它通常用于存储和获取应用程序的配置信息,包括数据库连接信息、日志级别、服务器端口、外部服务的API密钥等。
配置类的主要作用是集中管理应用程序的配置参数,使得在不同的环境中(例如开发、测试、生产)能够方便地修改和管理这些配置,而不
代码如下:
#oracle9i
#driver=oracle.jdbc.driver.OracleDriver
#url=jdbc:oracle:thin:@localhost:1521:orcl
#user=scott
#pwd=123
#sql2005
#driver=com.microsoft.sqlserver.jdbc.SQLServerDriver
#url=jdbc:sqlserver://localhost:1433;DatabaseName=test1
#user=sa
#pwd=123
#sql2000
#driver=com.microsoft.jdbc.sqlserver.SQLServerDriver
#url=jdbc:microsoft:sqlserver://localhost:1433;databaseName=unit6DB
#user=sa
#pwd=888888
#mysql
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/mybatis_ssm?useUnicode=true&characterEncoding=UTF-8&useSSL=false
user=root
pwd=123456
2.6.实体类
package com.junlinyi.entity;
public class Book {
private int bid;
private String bname;
private float price;
@Override
public String toString() {
return "Book [bid=" + bid + ", bname=" + bname + ", price=" + price + "]";
}
public int getBid() {
return bid;
}
public void setBid(int bid) {
this.bid = bid;
}
public String getBname() {
return bname;
}
public void setBname(String bname) {
this.bname = bname;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
public Book() {
// TODO Auto-generated constructor stub
}
public Book(int bid, String bname, float price) {
super();
this.bid = bid;
this.bname = bname;
this.price = price;
}
}
三. 反射完成通用查询功能
使用反射实现通用查询功能是在运行时通过分析类的结构来构造查询的一种技术。通过反射,可以获取类的字段、方法、注解等信息,并根据这些信息动态构建查询条件、执行查询操作。
下面是一个简单示例,展示如何使用反射实现通用查询功能:
public class BookDao extends BaseDao<Book>{ public List<Book> list1(Book book, PageBean pageBean) throws Exception { // 实例化 List<Book> list = new ArrayList<Book>(); // 拿到连接对象 Connection conn = DBAccess.getConnection(); // 编写sql语句 String sql = "select * from t_mvc_book where 1=1"; String bname = book.getBname(); // 判断字符串是不是空 if (StringUtils.isNotBlank(bname)) { sql += "and bname like '%" + bname + "%' "; // 拿到预定义对象 PreparedStatement ps = conn.prepareStatement(sql); // 拿到结果集 ResultSet rs = ps.executeQuery(); // 创建表对应的实体类对象 // 将查询出来的结果集添加到实例化对象的属性中 // 已经被对象填充的实体对象加入到集合中 while (rs.next()) { list.add(new Book(rs.getInt("bid"), rs.getString("bname"), rs.getFloat("price"))); } } return list; } public List<Book> list2(Book book, PageBean pageBean) throws Exception { // 编写sql语句 String sql = "select * from t_mvc_book where 1=1"; String bname = book.getBname(); // 判断字符串是不是空 if (StringUtils.isNotBlank(bname)) { sql += "and bname like '%" + bname + "%' "; } return super.executeQuery(sql, Book.class, pageBean); } public static void main(String[] args) throws Exception { BookDao bookDao = new BookDao(); Book book = new Book(); PageBean pageBean = new PageBean(); List<Book> list = bookDao.list1(book, pageBean); for (Book b : list) { System.out.println(b); } } }效果图:
需要注意的是,这只是一个简单示例,实际应用中,可能需要根据具体的查询需求和数据访问框架进行更复杂的构建和操作。同时,使用反射的效率较低,因此在性能要求较高的场景中,应慎重使用。
四.junit单元测试
4.1.什么是junit
JUnit是一个用于Java编程语言的单元测试框架。单元测试是一种软件测试方法,旨在验证应用程序中最小可测试单元(通常是单个方法)的正确性。JUnit提供了一些工具和注解,使得编写和执行单元测试变得更加容易和自动化。
4.2.JUnit的特点和优势包括:
简单易用:JUnit提供了一组易于理解和使用的API,使得编写单元测试变得简单和直观。
自动化执行:JUnit测试用例可以被自动执行,无需人工干预,从而提高了测试的效率和准确性。
快速反馈:通过JUnit可以快速运行单元测试,并及时获得测试结果和报告,帮助开发人员快速发现和调试代码中的问题。
可重复性:JUnit测试用例具有高度的可重复性,测试结果在不同的环境和条件下都应该保持一致。
4.3常见的JUnit注解包括:
- @Test:用于标记测试用例方法。
- @Before:在每个测试方法之前执行,用于初始化测试数据。
- @After:在每个测试方法之后执行,用于清理测试数据。
- @BeforeClass:在类中的所有测试方法之前执行,通常用于准备资源或加载数据。
- @AfterClass:在类中的所有测试方法之后执行,通常用于释放资源或清理数据。
JUnit还提供了一些常用的断言方法,用于验证测试结果的正确性,例如assertEquals、assertTrue、assertFalse等。
以下是一个JUnit测试用例示例:
@Test
public void text1() throws Exception {
System.out.println("text1.....");
BookDao bookDao = new BookDao();
Book book = new Book();
PageBean pageBean = new PageBean();
List<Book> list = bookDao.list1(book, pageBean);
for (Book b : list) {
System.out.println(b);
}
}这里需要注意的是:如果我们在写代码时@Test快捷键出不来的话,就需要进行配置。
配置如下:
首先点击你写的项目如图:
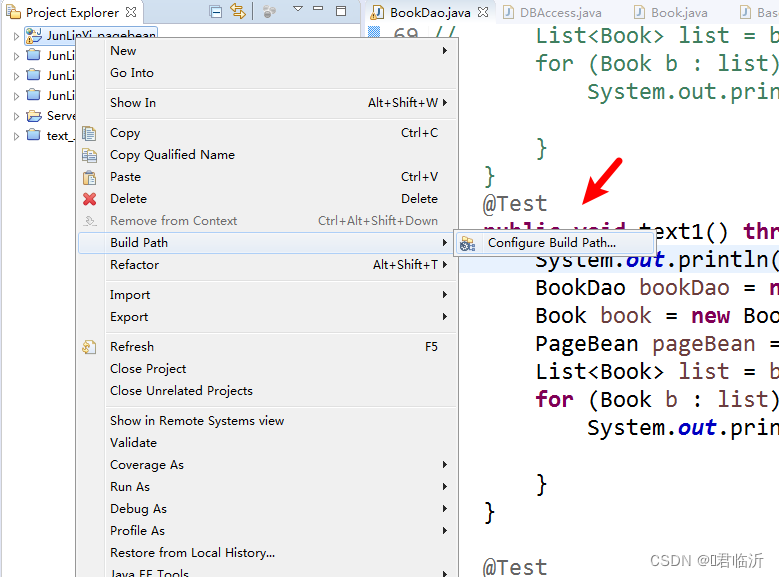
再点击Libraries,再点击如图:
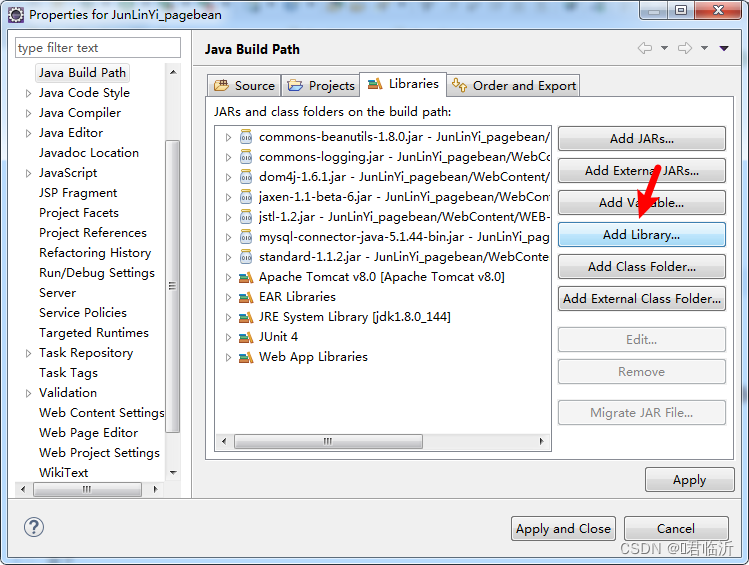
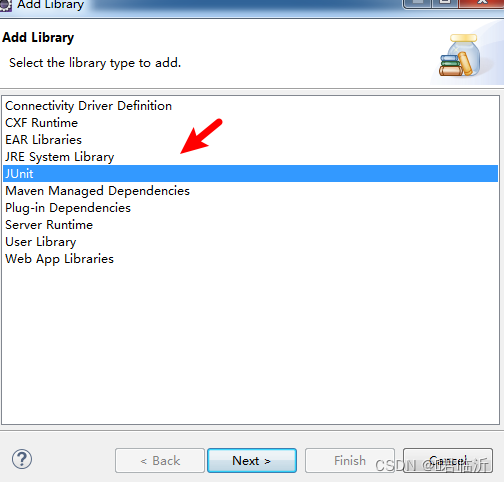
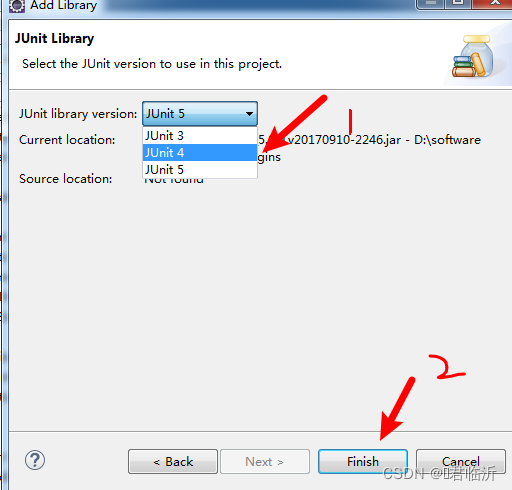
到这就结束了,恭喜你配置成功
通过JUnit可以对应用程序的各个单元进行快速且自动化的测试,并能够提供可靠的测试结果和报告。这种单元测试方法有助于发现和解决代码中的问题,提高软件质量和开发效率。
4.4.通用查询带分页
通用查询带分页是指在数据查询操作中,通过一种通用的方法实现查询结果的分页显示。这种方法可以用于各种查询场景,无论是关系型数据库、NoSQL数据库还是其他数据存储方式。
通用查询带分页的实现通常包含以下几个关键步骤:
构建查询条件:根据查询需求,构建查询条件,可以根据实体类的属性进行查询条件的设定。
执行查询:根据设定的查询条件,执行相应的查询操作,获取满足条件的查询结果。
分页处理:根据传入的页码和每页记录数,计算出查询结果的起始索引和结束索引,然后截取查询结果中的指定范围的数据作为分页结果。
返回分页结果:将分页结果返回给调用者,一般以列表形式或其他适当的数据结构进行返回。
在实际实现中,可以使用各种数据库访问框架或持久化工具来执行查询操作。例如,使用JDBC执行SQL查询,使用ORM框架(如Hibernate或MyBatis)进行对象关系映射查询等。
以下是一个通用查询带分页的示例代码:
BaseDao类:
package com.junlinyi.dao;
import java.lang.reflect.Field;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import com.junlinyi.util.DBAccess;
import com.junlinyi.util.PageBean;
public class BaseDao<T> {
/**
*
* @param sql
* @param cls Book.class
* @param pageBean
* @return
* @throws Exception
*/
public List<T> executeQuery(String sql,Class cls, PageBean pageBean) throws Exception {
// 实例化
List<T> list = new ArrayList<T>();
// 拿到连接对象
Connection conn = null;
// 拿到预定义对象
PreparedStatement ps = null;
// 拿到结果集
ResultSet rs = null;
if(pageBean !=null && pageBean.isPagination()) {
String countSQL = getCounSQL(sql);
conn = DBAccess.getConnection();
ps = conn.prepareStatement(countSQL);
rs = ps.executeQuery();
if(rs.next()) {
pageBean.setTotal(rs.getObject("n").toString());
}
String pageSQL = getPageSQL(sql,pageBean);
conn = DBAccess.getConnection();
ps = conn.prepareStatement(pageSQL);
rs = ps.executeQuery();
}else {
conn = DBAccess.getConnection();
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
}
// 创建表对应的实体类对象
// 将查询出来的结果集添加到实例化对象的属性中
// 已经被对象填充的实体对象加入到集合中
while (rs.next()) {
T t=(T) cls.newInstance();
// 拿到cls对应的所有属性
Field[] fields = cls.getDeclaredFields();
for (Field f : fields) {
f.setAccessible(true);
// System.out.println(f.getName());
f.set(t,rs.getObject(f.getName()));
}
// list.add(new Book(rs.getInt("bid"), rs.getString("bname"), rs.getFloat("price")));
list.add(t);
}
return list;
}
/**
* 拼接出最终展示出的数据sql
* @param sql 原生SQL
* @param pageBean
* @return
*/
private String getPageSQL(String sql, PageBean pageBean) {
return sql+"limit "+pageBean.getStartIndex()+","+pageBean.getRows();
}
/**
* 拼接出查询符合条件的总及记录数
* @param sql
* @return
*/
private String getCounSQL(String sql) {
return "SELECT count(1) as n from ("+sql+") t";
}
}
Dao类 :
@Test
public void test3() throws Exception {
System.out.println("test3...");
BookDao bookDao = new BookDao();
Book book = new Book();
book.setBname("圣墟");
PageBean pageBean = new PageBean();
pageBean.setPage(2);
List<Book> list = bookDao.list2(book, pageBean);
for (Book b : list) {
System.out.println(b);
}
最后通过分页的详解(后端)就到这里,祝大家在敲代码的路上一路通畅!
感谢大家的观看 !!!!!!
















 2537
2537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









