







登录官网:https://dataverse.harvard.edu/

2. 服务器URL:
服务器URL通常是Dataverse实例的网址,例如https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/VIJFPK
这个网站,URL就是https://dataverse.harvard.edu
3. 数据集的持久标识:
点击数据集页面上的“Cite”按钮,在弹出的窗口中可以看到数据集的持久标识(Persistent Identifier),通常以“doi:”开头,例如我下面要下载的数据doi.org/10.7910/DVN/VIJFPK,它对应的Persistent Identifier就是doi:10.7910/DVN/VIJFPK
也可以在HL中点击元数据metadata中查看Persistent Identifier
4. 下载数据的版本(针对Harvard dataverse):
点击数据的version,可以查看可以下载的版本
2. 下载:
1. 官网例子:
export API_TOKEN=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
export SERVER_URL=https://demo.dataverse.org
export PERSISTENT_ID=doi:10.70122/FK2/N2XGBJ
curl -L -O -J -H “X-Dataverse-key:$API_TOKEN” S E R V E R U R L / a p i / a c c e s s / d a t a s e t / : p e r s i s t e n t I d / ? p e r s i s t e n t I d = SERVER_URL/api/access/dataset/:persistentId/?persistentId= SERVERURL/api/access/dataset/:persistentId/?persistentId=PERSISTENT_ID
官网的例子是连接到一个测试网站的,不能直接使用,原因是:其中的SERVER_URL不是我们要的。
此时改对URL后部分小文件已经可以使用了,但对于大文件,即便我们写对了也可竟会出现重定位然后SHELL脚本中断的情况,我们可以在curl后加上-v输出它的运行情况,如下图出现重定位,可以直接wget这个新路径(以下为我的SHELL脚本,可以输出我们需要的URL,也可以直接在脚本里启动下载):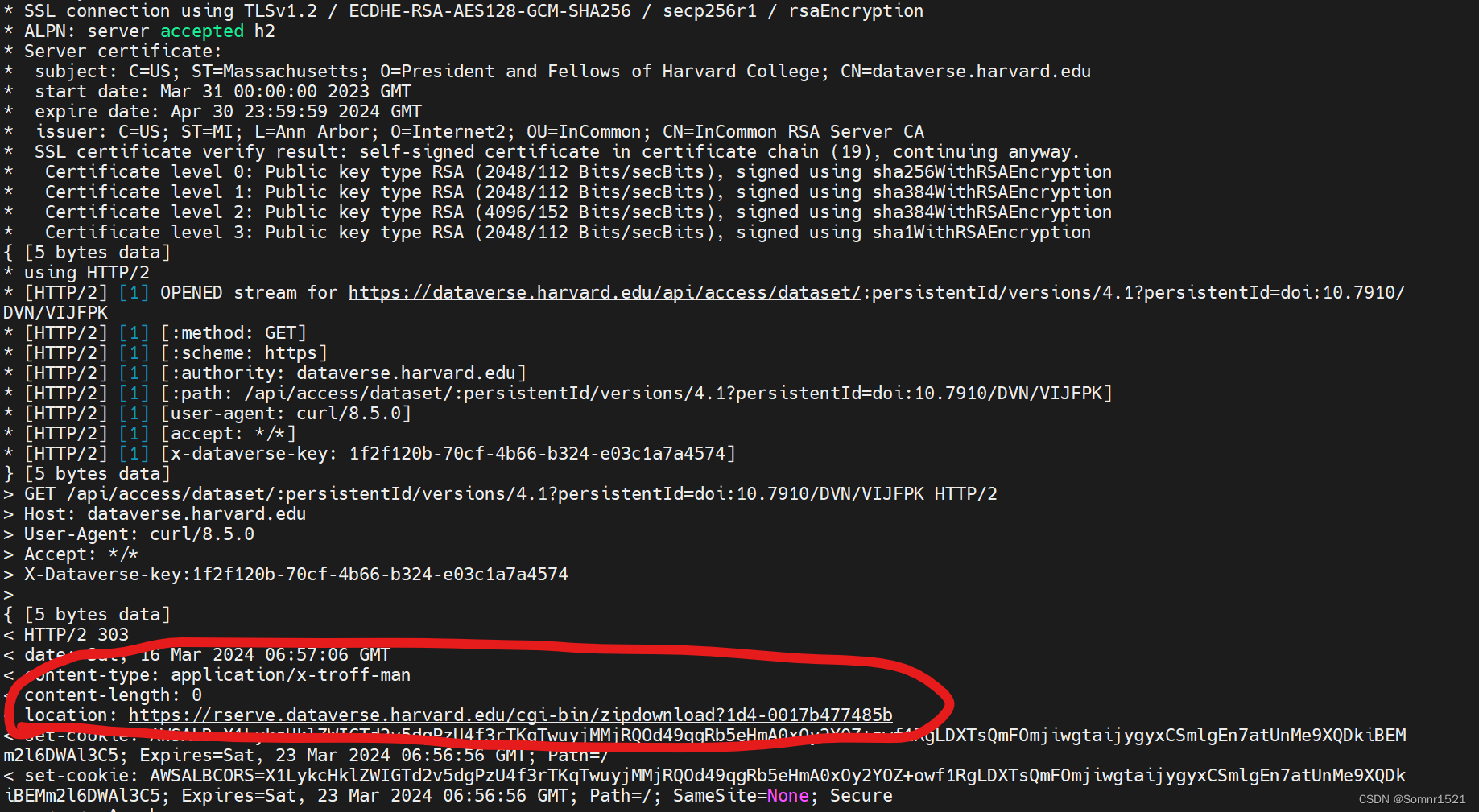
export API_TOKEN=*****************************************
export SERVER_URL=https://dataverse.harvard.edu
export PERSISTENT_ID=doi:10.7910/DVN/VIJFPK
export VERSION=4.1
发起curl请求获取重定向链接
Store the response headers in a variable
response= ( c u r l − s − D − − H " X − D a t a v e r s e − k e y : (curl -s -D - -H "X-Dataverse-key: (curl−s−D−−H"X−Dataverse−key:API_TOKEN" --insecure “ S E R V E R U R L / a p i / a c c e s s / d a t a s e t / : p e r s i s t e n t I d / v e r s i o n s / SERVER_URL/api/access/dataset/:persistentId/versions/ SERVERURL/api/access/dataset/:persistentId/versions/VERSION?persistentId=$PERSISTENT_ID”)
Extract the redirect URL from the Location header
download_link= ( e c h o " (echo " (echo"response" | grep -i ‘Location’ | awk ‘{print $2}’)
echo $download_link
2. python下载:(支持重定位)
所需库:request
关键:request.get
request.get的API认证:有些API使用API密钥作为认证方式。API密钥通常作为请求头的一部分发送。
import requests
url = ‘http://example.com/api’
api_key = ‘your_api_key’
headers = {‘Authorization’: f’Bearer {api_key}'}
response = requests.get(url, headers=headers)
下载程序:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)


感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
[外链图片转存中…(img-EPsrD5rt-1712662727787)]














 1025
1025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









