






一、相关网页(网页链接:https://www.acfun.cn/v/ac36564705)
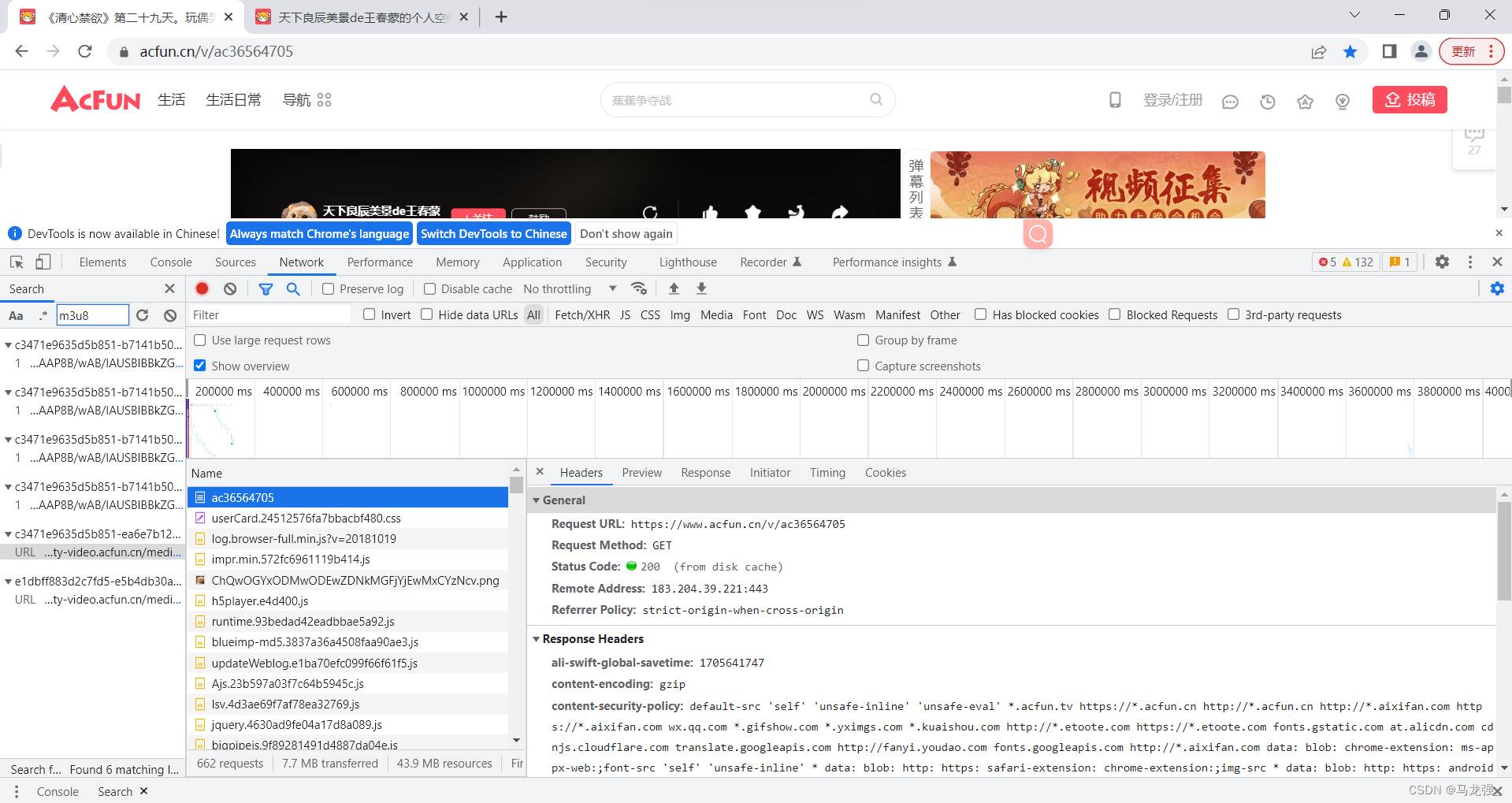 二、多视频采集网页(找出每个视频ID)
二、多视频采集网页(找出每个视频ID)
三、相关代码(代码含有注释)
# @Time: 2024/1/18 22:57
# @Author: 马龙强
# @File: 对m3u8视频进行批量采集.py
# @software: PyCharm
"""
网址:https://www.acfun.cn/v/ac36564705
数据:视频内容
数据包地址:https://www.acfun.cn/v/ac36564705(视频详情页)
多个视频采集() ——> 多页视频采集
https://www.acfun.cn/u/29946310
1.分析请求链接变化规律
https://www.acfun.cn/v/ac36564705(视频详情页)
视频ID --> 获取所有视频ID(目录页面获取)
页面链接:
https://www.acfun.cn/u/29946310?quickViewId=ac-space-video-list&reqID=14&ajaxpipe=1&type=video&order=newest&page=2&pageSize=20&t=1705649684246
1.发送请求
2.获取数据
3.解析数据
"""
#url = 'https://tx-safety-video.acfun.cn/mediacloud/acfun/acfun_video/c3471e9635d5b851-ea6e7b122d2d54d64693965aed559baa-hls_360p_hevc_1.m3u8?pkey=ABCFUkjmqkt-agD7xyW6wFIm-mYTdxYRB75ZOyemp5aoFUJNm9DAVYVc5nqQkdQP-FJad2s-yd92ypUuPakRanYHaOFpm0aRsJc5D1rx9p9DgNop9FsUtA1MSBDk6vnM8iiRJn_zzu7rgoUmYhh1vpQ5OF_JaTTlEfIiu-KnqY3TERCMWXPB0ar6eP2oIq3RUKhvYz_Hx-_rKfT2FdxKM3B7ThniqMjFLkXFyYYeCocClw&safety_id=AAL1xBzfE8H4NudKAOEFPJXV'
import requests
import json
import re
from pprint import pprint
#模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# page_link = ''
link = 'https://www.acfun.cn/u/29946310?quickViewId=ac-space-video-list&reqID=14&ajaxpipe=1&type=video&order=newest&page=2&pageSize=20&t=1705649684246'
#发送请求获取数据
link_data = requests.get(url=link,headers=headers).text
# print(link_data)
#提取视频ID
video_id_list = re.findall('"atomid.*?":.*?"(\d+).*?"',link_data)
# pprint(link_data)
# print(video_id_list)
for video_id in video_id_list:
#请求网址
url = f'https://www.acfun.cn/v/ac{video_id}'
#发送请求
response = requests.get(url=url,headers=headers)
#获取数据
html_data = response.text
#打印数据
#提取标题
title = re.findall('"title":"(.*?)",',html_data)[1]
# print(title)
#提取m3u8 json格式 -> 字符串
info = re.findall('window.videoInfo =(.*?);',html_data)[0]
#转成字典 -> 键值对取值(根据冒号左边的内容,提取冒号右边的内容)
# m3u8 = json.loads(json.loads(info)['currentVideoInfo']['ksPlayJson'])['adaptationSet'][0]['representation'][0]['backupUrl'][0]
m3u8 = json.loads(json.loads(info)['currentVideoInfo']['ksPlayJson'])['adaptationSet'][0]['representation'][0]['url']
# print(m3u8)
# print(info)
# pprint(m3u8)
# print(html_data)
"""
二次请求
"""
#发送请求 获取数据
m3u8_data = requests.get(url=m3u8,headers=headers).text
#提取ts链接
ts_list = re.findall(',\n(.*?)\n#',m3u8_data,re.S)
print(title)
# print(title)
# print(m3u8)
# print(m3u8_data)
# print(ts_list)
#for循环遍历
for ts in ts_list:
#https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/
ts_url = 'https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/'+ts
# print(ts_url)
"""
第三次请求:获取视频内容
把所有视频片段合成一个完整的视频内容
"""
ts_content = requests.get(url=ts_url,headers=headers).content
with open('video\\'+ title + '.mp4',mode='ab') as f:
f.write(ts_content)
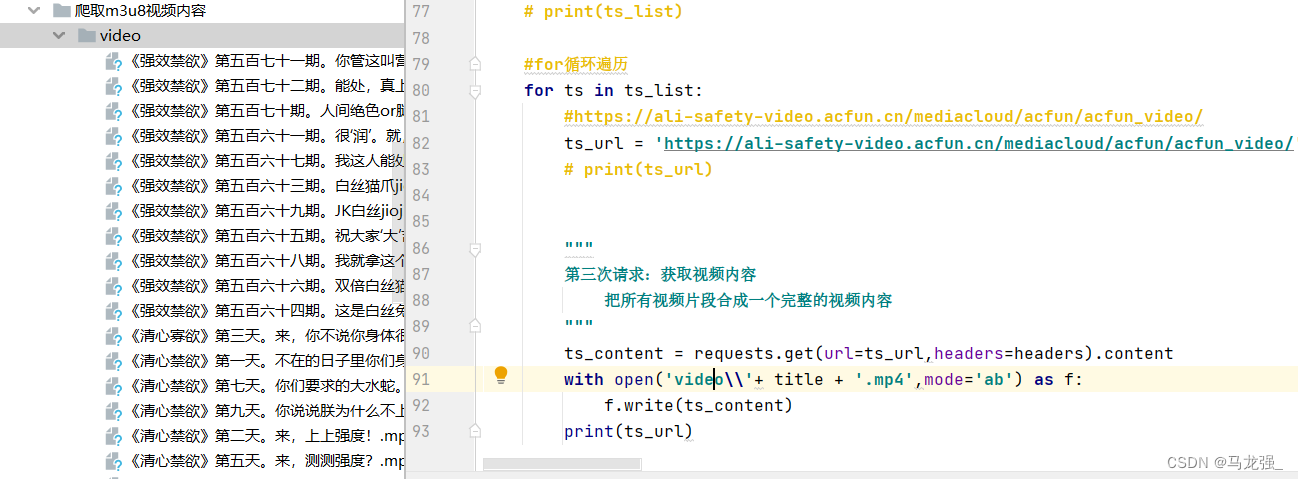
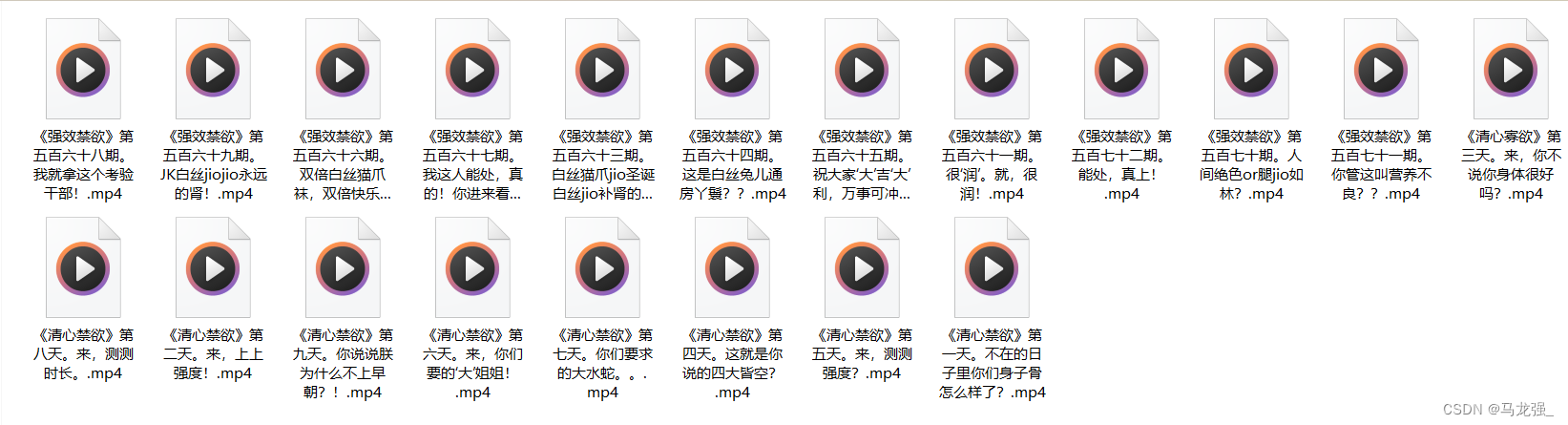
print('保存完毕!')四、爬取结果(mp4文件)
| 版权声明和免责声明 本博客提供的所有爬虫代码和相关内容(以下简称“内容”)仅供参考和学习之用。任何使用或依赖这些内容的风险均由使用者自行承担。我(博客所有者)不对因使用这些内容而产生的任何直接或间接损失承担责任。 严禁将本博客提供的爬虫代码用于任何违法、不道德或侵犯第三方权益的活动。使用者应当遵守所有适用的法律法规,包括但不限于数据保护法、隐私权法和知识产权法。 如果您选择使用本博客的爬虫代码,您应当确保您的使用行为符合所有相关法律法规,并且不会损害任何人的合法权益。在任何情况下,我(博客所有者)均不对您的行为负责。 如果您对本声明有任何疑问,或者需要进一步的澄清,请通过我的联系方式与我联系。 |















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











