






一、相关网站
二、查看robots.txt
三、查看小说主页面url,获取小说章节名称和href
(1).相关代码
import requests
from lxml import etree
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
url = 'https://www.quanben.so/94_94335/'
response = requests.get(headers=headers,url=url)
# print(response.status_code)
result = etree.HTML(response.text)
urls = result.xpath('//div/dl/dd[position() >= 13]/a/@href')
titles = result.xpath('//div/dl/dd[position() >= 13]/a/text()')
print(urls,titles)(2).获取的结果

四、获取每章节小说内容
(1).相关代码
import requests
from lxml import etree
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
url = 'https://www.quanben.so/94_94335/67871925.html'
response = requests.get(headers=headers,url=url)
# print(response.status_code)
result = etree.HTML(response.text)
# content = result.xpath('//div[@id="content"]/br/following-sibling::text()')
"""
# 注意:这可能会返回包含所有文本节点的列表,包括换行符、空格等
texts = result.xpath('//div[@id="content"]/text()')
# 将列表中的文本节点连接成一个字符串
content = ''.join(texts).strip() # 使用strip()去除字符串两端的空白字符
"""
# content = ''.join(result.xpath('//div[@id="content"]/text()')).strip()
content = '\n'.join(result.xpath('//div[@id="content"]/text()')).strip()
print(content)(2).获取的结果

五、网页拼接,获取每章节小说的名称和url
(1).相关代码
import requests
from lxml import etree
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
url = 'https://www.quanben.so/94_94335/'
response = requests.get(headers=headers, url=url)
result = etree.HTML(response.text)
urls = result.xpath('//div/dl/dd[position() >= 13]/a/@href')
titles = result.xpath('//div/dl/dd[position() >= 13]/a/text()')
base_url = 'https://www.quanben.so/94_94335/'
for title, url in zip(titles, urls):
full_url = base_url + url
print(f'{title} === {full_url}')(2).获取的结果

六、完善代码,将获取内容保存到txt文件中
(1).相关代码
import os
import time
import requests
from lxml import etree
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
url = 'https://www.quanben.so/94_94335/'
response = requests.get(headers=headers, url=url)
result = etree.HTML(response.text)
urls = result.xpath('//div/dl/dd[position() >= 13]/a/@href')
titles = result.xpath('//div/dl/dd[position() >= 13]/a/text()')
base_url = 'https://www.quanben.so/94_94335/'
# 创建目录
directory = "神印王座II皓月当空"
if not os.path.exists(directory):
os.makedirs(directory)
for title, url in zip(titles, urls):
full_url = base_url + url
response = requests.get(headers=headers, url=full_url)
result = etree.HTML(response.text)
content = '\n'.join(result.xpath('//div[@id="content"]/text()')).strip()
# 将标题中的非法字符替换为下划线
title = title.replace(':', '_').replace('?', '_')
# 将内容写入文件
file_name = os.path.join(directory, f"{title}.txt")
with open(file_name, "w", encoding="utf-8") as f:
f.write(content)
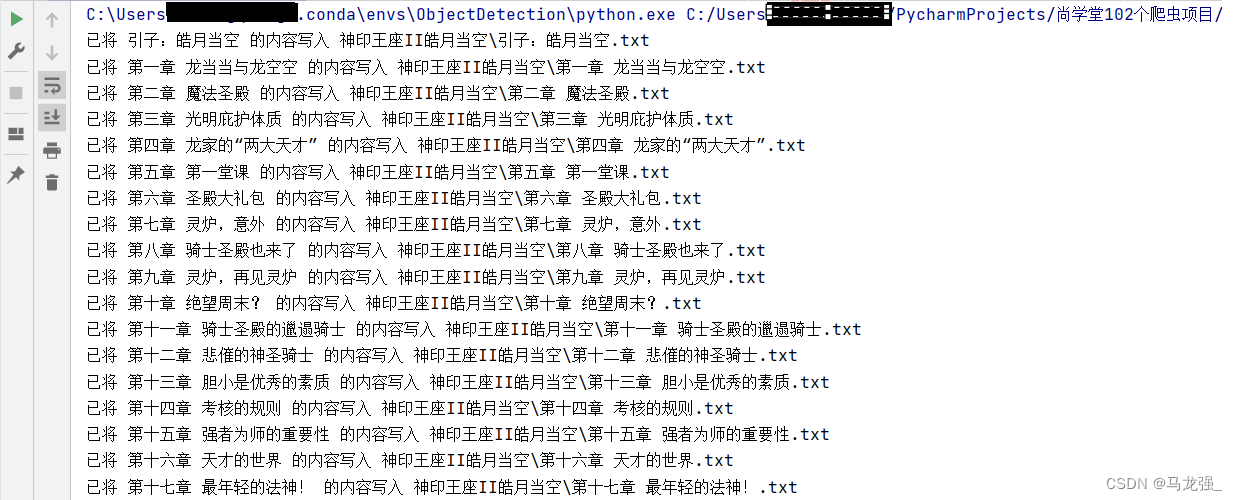
print(f"已将 {title} 的内容写入 {file_name}")
# 由于网站限制,每爬取一章节,睡眠2秒
time.sleep(2)(2).获取的结果
| 版权声明和免责声明 本博客提供的所有爬虫代码和相关内容(以下简称“内容”)仅供参考和学习之用。任何使用或依赖这些内容的风险均由使用者自行承担。我(博客所有者)不对因使用这些内容而产生的任何直接或间接损失承担责任。 严禁将本博客提供的爬虫代码用于任何违法、不道德或侵犯第三方权益的活动。使用者应当遵守所有适用的法律法规,包括但不限于数据保护法、隐私权法和知识产权法。 如果您选择使用本博客的爬虫代码,您应当确保您的使用行为符合所有相关法律法规,并且不会损害任何人的合法权益。在任何情况下,我(博客所有者)均不对您的行为负责。 如果您对本声明有任何疑问,或者需要进一步的澄清,请通过我的联系方式与我联系。 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











